目录
前言:
一、SQL Aggregate 函数
1、AVG() 函数
2、count()函数
3、MAX() 函数
4、MIN() 函数
5、SUM() 函数
6、SQL GROUP BY 语法
7、SQL HAVING 子句
8、SQL EXISTS 运算符
9、SQL UNION 操作符
二、SQL Scalar 函数
1、SQL UCASE() 函数
2、SQL LCASE() 函数
3、SQL MID() 函数
4、SQL LEN() 函数
5、SQL ROUND() 函数
6、 SQL NOW() 函数
7、SQL FORMAT() 函数
前言:
SQL 拥有很多可用于计数和计算的内建函数。大致分为两类:SQL Aggregate 函数计算从列中取得的值,返回一个单一的值。SQL Scalar 函数基于输入值,返回一个单一的值。
一、SQL Aggregate 函数
SQL Aggregate 函数计算从列中取得的值,返回一个单一的值。
有用的 Aggregate 函数:
- AVG() - 返回平均值
- COUNT() - 返回行数
- MAX() - 返回最大值
- MIN() - 返回最小值
- SUM() - 返回总和
1、AVG() 函数
AVG() 函数返回数值列的平均值。
从 "access_log" 表的 "count" 列获取平均值:
SELECT AVG(count) AS CountAverage FROM access_log;选择访问量高于平均访问量的 "site_id" 和 "count":
SELECT site_id, count FROM access_log
WHERE count > (SELECT AVG(count) FROM access_log);2、count()函数
COUNT() 函数返回匹配指定条件的行数。
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入)
SELECT COUNT(column_name) FROM table_name;COUNT(*) 函数返回表中的记录数:
SELECT COUNT(*) FROM table_name;COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目:
SELECT COUNT(DISTINCT column_name) FROM table_name;计算 "access_log" 表中 "site_id"=3 的总访问量:
SELECT COUNT(count) AS nums FROM access_log
WHERE site_id=3;计算 "access_log" 表中不同 site_id 的记录数:
SELECT COUNT(DISTINCT site_id) AS nums FROM access_log;3、MAX() 函数
MAX() 函数返回指定列的最大值。
从 "Websites" 表的 "alexa" 列获取最大值:
SELECT MAX(alexa) AS max_alexa FROM Websites;4、MIN() 函数
MIN() 函数返回指定列的最小值。
从 "Websites" 表的 "alexa" 列获取最小值:
SELECT MIN(alexa) AS min_alexa FROM Websites;5、SUM() 函数
SUM() 函数返回数值列的总数。
查找 "access_log" 表的 "count" 字段的总数:
SELECT SUM(count) AS nums FROM access_log;
6、SQL GROUP BY 语法
GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组
统计 access_log 各个 site_id 的访问量:
SELECT site_id, SUM(access_log.count) AS nums
FROM access_log GROUP BY site_id;统计有记录的网站的记录数量:
SELECT Websites.name,COUNT(access_log.aid) AS nums FROM access_log
LEFT JOIN Websites
ON access_log.site_id=Websites.id
GROUP BY Websites.name;7、SQL HAVING 子句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用,HAVING 子句可以让我们筛选分组后的各组数据。
where 和having之后都是筛选条件,但是有区别的:
(1)where在group by前, having在group by 之后
(2)聚合函数(avg、sum、max、min、count),不能作为条件放在where之后,但可以放在having之后
查找总访问量大于 200 的网站
SELECT Websites.name, Websites.url, SUM(access_log.count) AS nums FROM (access_log
INNER JOIN Websites
ON access_log.site_id=Websites.id)
GROUP BY Websites.name
HAVING SUM(access_log.count) > 200;查找总访问量大于 200 的网站,并且 alexa 排名小于 200。
SELECT Websites.name, SUM(access_log.count) AS nums FROM Websites
INNER JOIN access_log
ON Websites.id=access_log.site_id
WHERE Websites.alexa < 200
GROUP BY Websites.name
HAVING SUM(access_log.count) > 200;8、SQL EXISTS 运算符
EXISTS 运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
查找总访问量(count 字段)大于 200 的网站是否存在。
SELECT Websites.name, Websites.url
FROM Websites
WHERE EXISTS (SELECT count FROM access_log WHERE Websites.id = access_log.site_id AND count > 20EXISTS 可以与 NOT 一同使用,查找出不符合查询语句的记录:
SELECT Websites.name, Websites.url
FROM Websites
WHERE NOT EXISTS (SELECT count FROM access_log WHERE Websites.id = access_log.site_id AND count > 200);9、SQL UNION 操作符
SQL UNION 操作符合并两个或多个 SELECT 语句的结果。
请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
SQL UNION 语法
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
SQL UNION ALL 语法
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;注释:UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
示例:
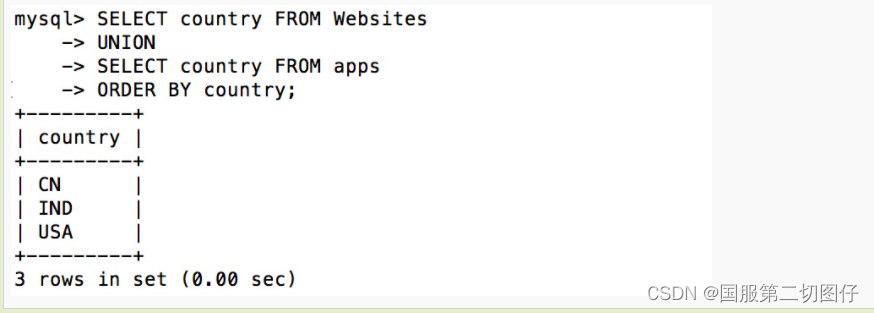
从 "Websites" 和 "apps" 表中选取所有不同的country(只有不同的值):
SELECT country FROM Websites
UNION
SELECT country FROM apps
ORDER BY country;注释:UNION 不能用于列出两个表中所有的country。如果一些网站和APP来自同一个国家,每个国家只会列出一次。UNION 只会选取不同的值。请使用 UNION ALL 来选取重复的值!
使用 UNION ALL 从 "Websites" 和 "apps" 表中选取所有的country(也有重复的值)
SELECT country FROM Websites
UNION ALL
SELECT country FROM apps
ORDER BY country;
使用 UNION ALL 从 "Websites" 和 "apps" 表中选取所有的中国(CN)的数据(也有重复的值)
SELECT country, name FROM Websites
WHERE country='CN'
UNION ALL
SELECT country, app_name FROM apps
WHERE country='CN'
ORDER BY country;
二、SQL Scalar 函数
SQL Scalar 函数基于输入值,返回一个单一的值。
有用的 Scalar 函数:
- UCASE() - 将某个字段转换为大写
- LCASE() - 将某个字段转换为小写
- MID() - 从某个文本字段提取字符,MySql 中使用
- SubString(字段,1,end) - 从某个文本字段提取字符
- LEN() - 返回某个文本字段的长度
- ROUND() - 对某个数值字段进行指定小数位数的四舍五入
- NOW() - 返回当前的系统日期和时间
- FORMAT() - 格式化某个字段的显示方式
1、SQL UCASE() 函数
UCASE() 函数把字段的值转换为大写。
从 "Websites" 表中选取 "name" 和 "url" 列,并把 "name" 列的值转换为大写:
SELECT UCASE(name) AS site_title, url
FROM Websites;2、SQL LCASE() 函数
LCASE() 函数把字段的值转换为小写。
从 "Websites" 表中选取 "name" 和 "url" 列,并把 "name" 列的值转换为小写:
SELECT LCASE(name) AS site_title, url
FROM Websites;3、SQL MID() 函数
MID() 函数用于从文本字段中提取字符
从 "Websites" 表的 "name" 列中提取前 4 个字符:
SELECT MID(name,1,4) AS ShortTitle
FROM Websites;4、SQL LEN() 函数
LEN() 函数返回文本字段中值的长度。
从 "Websites" 表中选取 "name" 和 "url" 列中值的长度
SELECT name, LENGTH(url) as LengthOfURL
FROM Websites;5、SQL ROUND() 函数
ROUND() 函数用于把数值字段舍入为指定的小数位数。
ROUND(X): 返回参数X的四舍五入的一个整数。
mysql> SELECT ROUND(-1.23);
-> -1
mysql> SELECT ROUND(-1.58);
-> -2
mysql> SELECT ROUND(1.58);
-> 2ROUND(X,D): 返回参数X的四舍五入的有 D 位小数的一个数字。如果D为0,结果将没有小数点或小数部分。
mysql> SELECT ROUND(1.298, 1);
-> 1.3
mysql> SELECT ROUND(1.298, 0);
-> 16、 SQL NOW() 函数
NOW() 函数返回当前系统的日期和时间。
从 "Websites" 表中选取 name,url,及当天日期:
SELECT name, url, Now() AS date
FROM Websites;7、SQL FORMAT() 函数
FORMAT() 函数用于对字段的显示进行格式化。
从 "Websites" 表中选取 name, url 以及格式化为 YYYY-MM-DD 的日期:
SELECT name, url, DATE_FORMAT(Now(),'%Y-%m-%d') AS date
FROM Websites;




](https://img-blog.csdnimg.cn/f4125da150c448d79014f6d0bb6c465e.png)