文章目录
- 前言
- 环境
- 下载中文包
- 制作激活词
- 编码实现唤醒
前言
这玩意是干啥的呢,主要的话就是最近有个小项目,需要在ros上面实现一个语音唤醒的操作。同时要求,离线操作,只能使用离线的SDK。然后逛了一圈,发现科大讯飞的不错,可惜,这个平台是arach64的架构的,官网上的如果要在这里部署的话,要重新定制编译,要钱钱。没办法,那就自己玩玩呗。
环境
speech_recognition + PocketSphinx, python3.8。 实测的话,机器占用非常小,当然识别精度非常低,所以这里的话,还需要自己编写一下关键唤醒词。不然中文效果非常差。毕竟,中文不像英文,当然还有个原因也是因为,这个是老外的。
首先,这里需要先安装这两个包,这个的话这里就赘述了,直接pip无脑安装即可。
下载中文包
首先,默认支持的是英文,没有办法,只能先下载一下中文包。
https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/
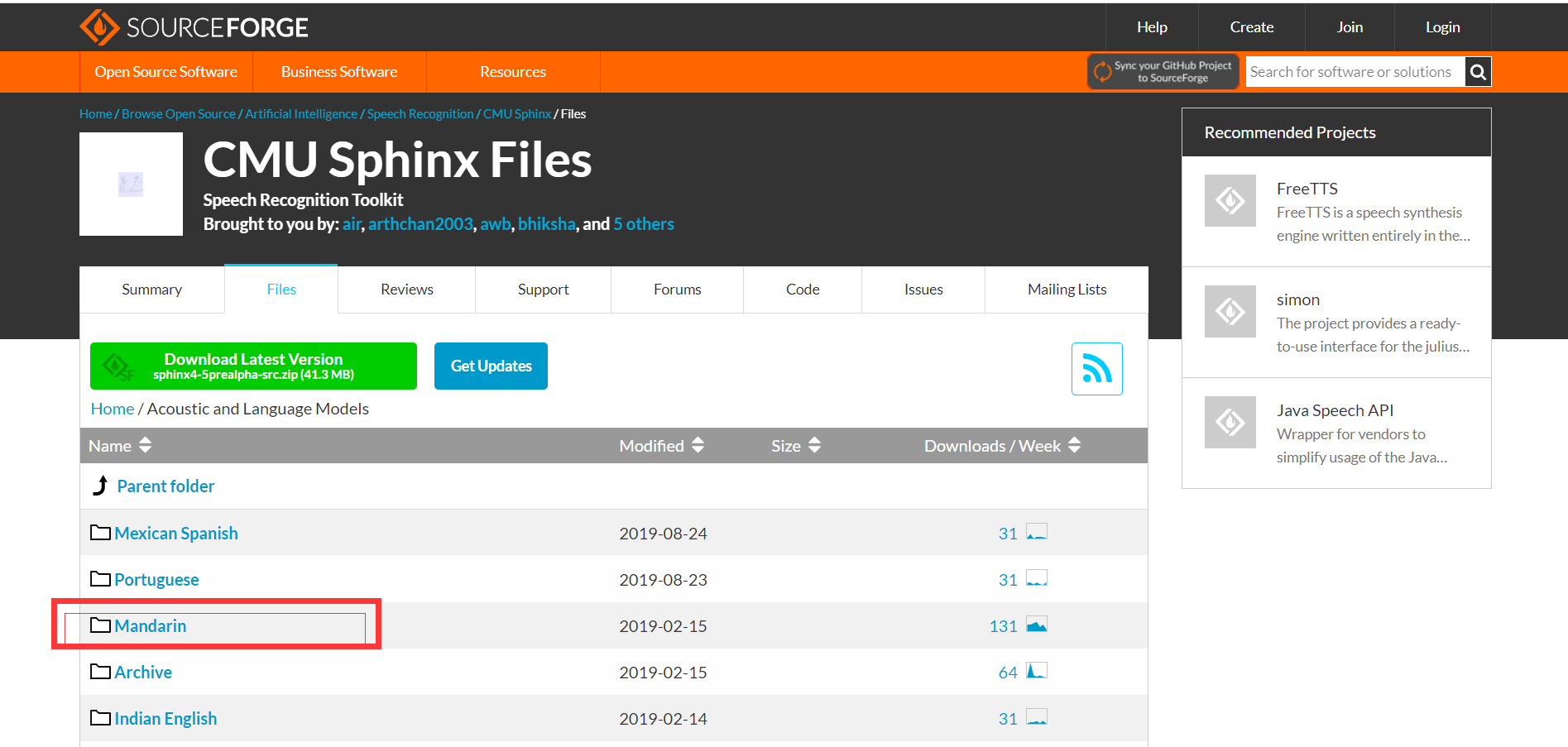
之后进行下载即可。然后进行解压,解压之后的话,需要找到这个目录:
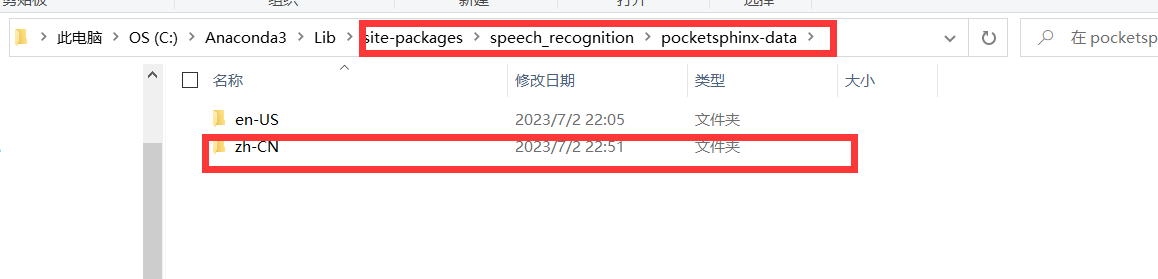
在这里先创建文件夹zh-CN。
然后解压之后,注意还不能直接使用。
还需要改个文件的名字。参照这里:https://github.com/Uberi/speech_recognition/blob/master/reference/pocketsphinx.rst
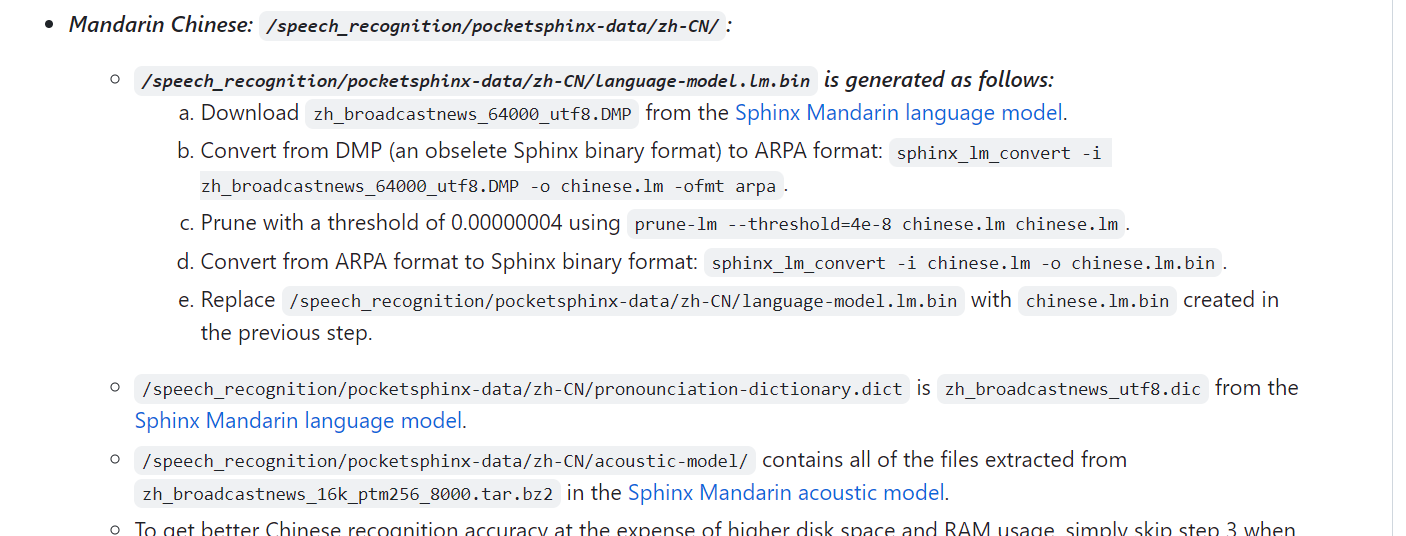
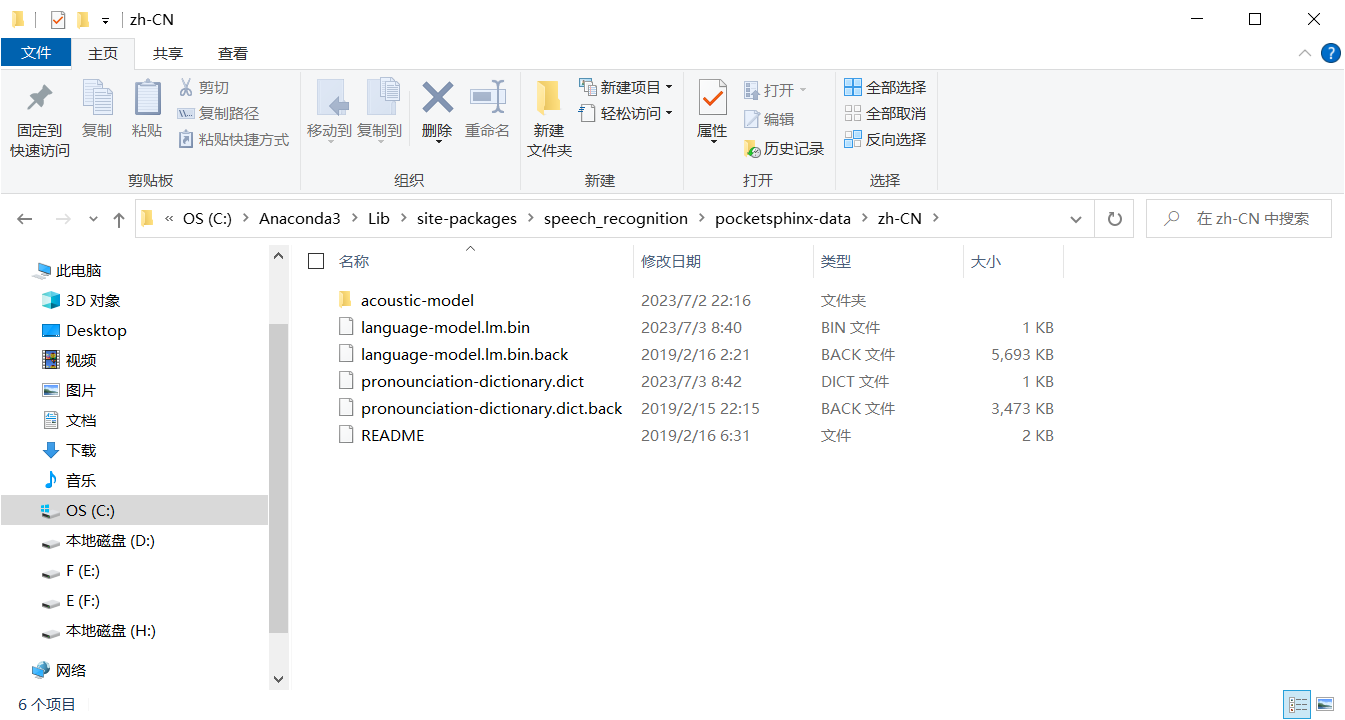
改完名字之后是这样的:(.back后缀的是没有的,是我后面加的)
制作激活词
由于,这个识别效果太差了,所以,我们需要做个关键的词,也就是激活词。其实就是重新制作它的词典。这样一来,识别语音的时候,就不会乱识别的。因为,你可以看到这个文件:
这个是它的词典
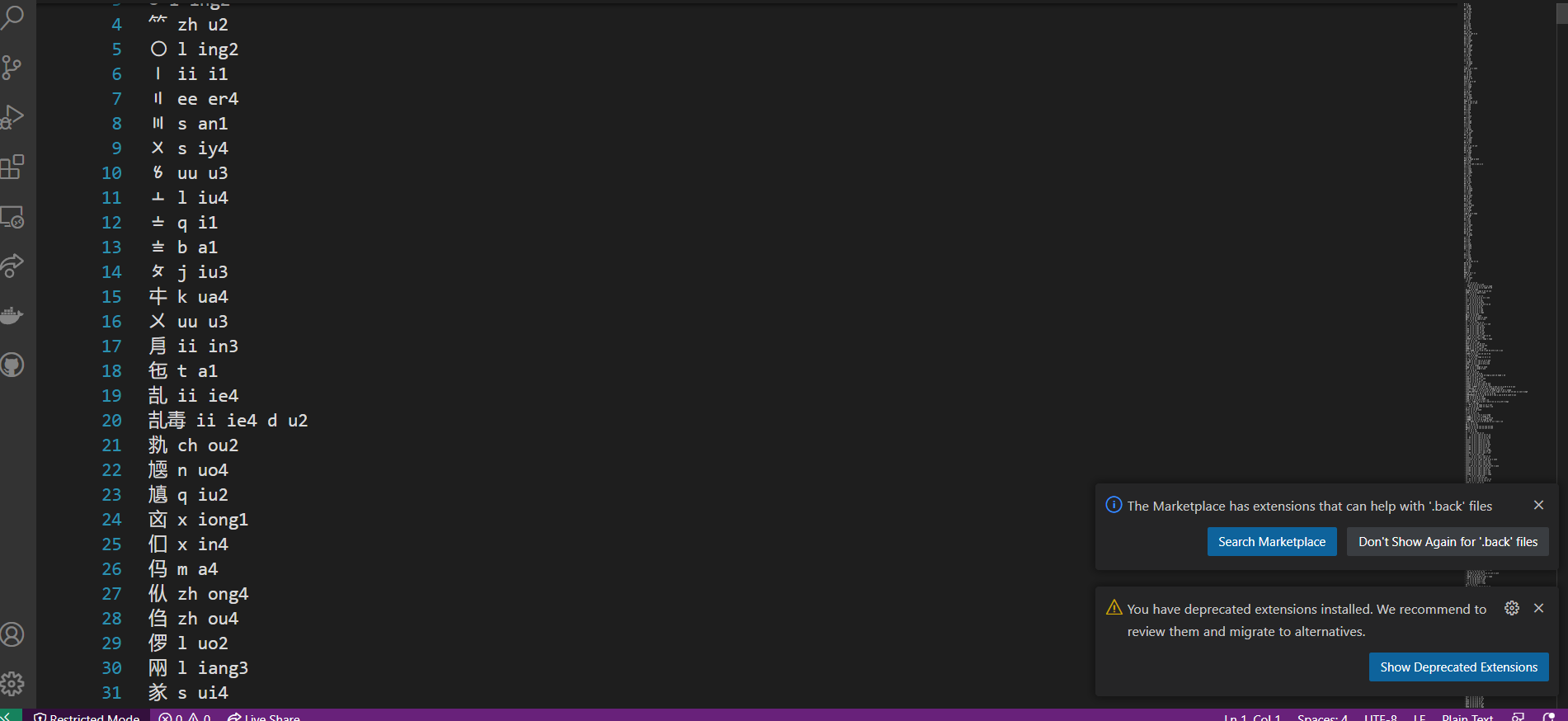
它里面的词汇,可以看到其实很乱。
所以这个时候,我们只要他识别出我想要的东西。
所以这个时候,我们先设计激活词,其实也就是词典。
例如,我的激活词语是:
小坤小坤
你好
你把这个保存在一个文本当中,然后进入这个网站:
http://www.speech.cs.cmu.edu/tools/lmtool-new.html
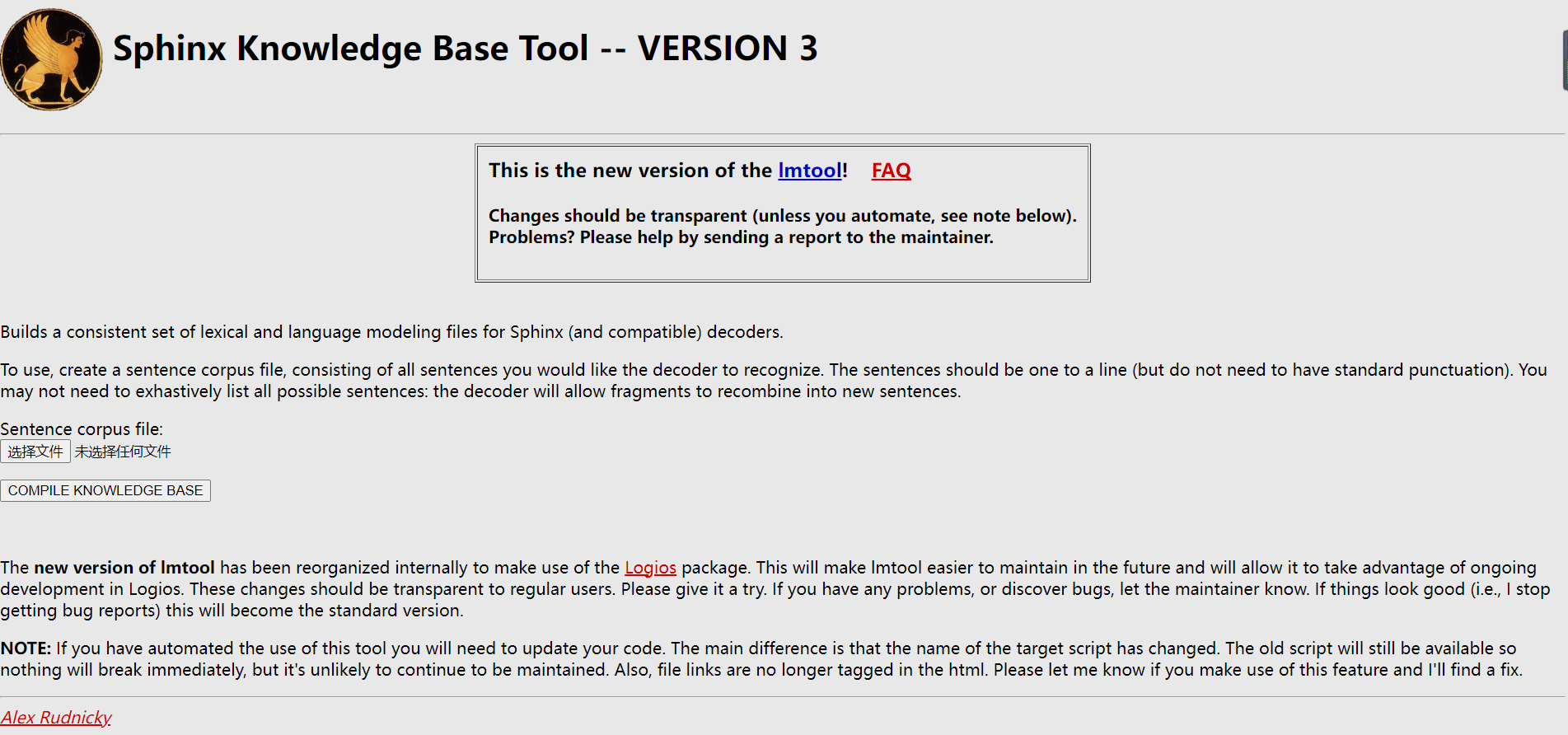
上传制作文件即可。然后点击
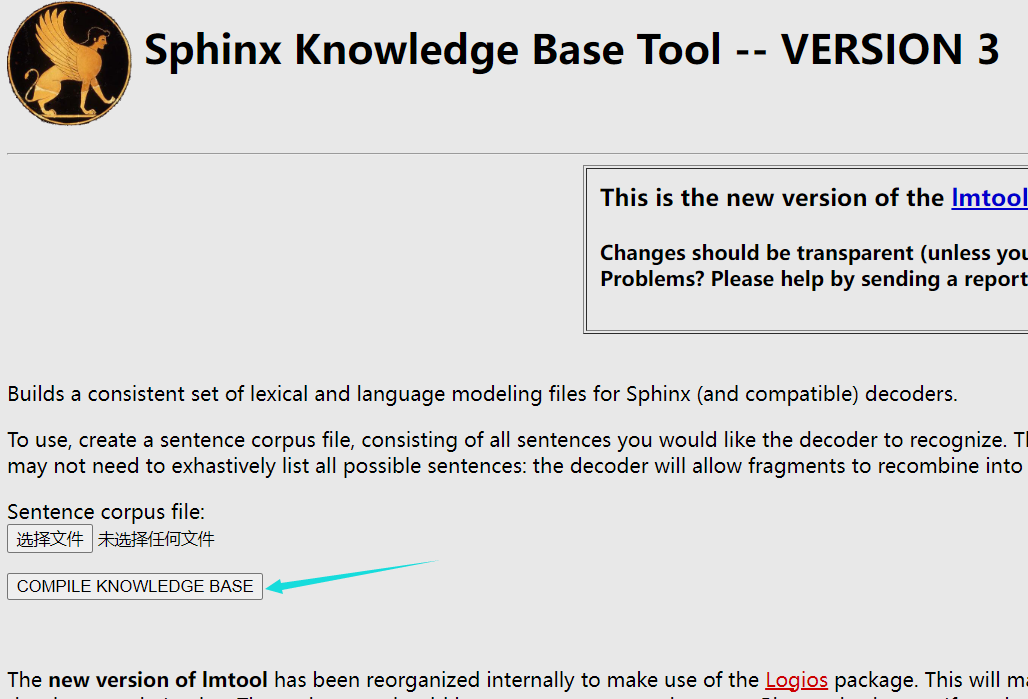
就会进入下载页面。得到压缩包,你需要进行解压。
这是我下载解压后的文件:
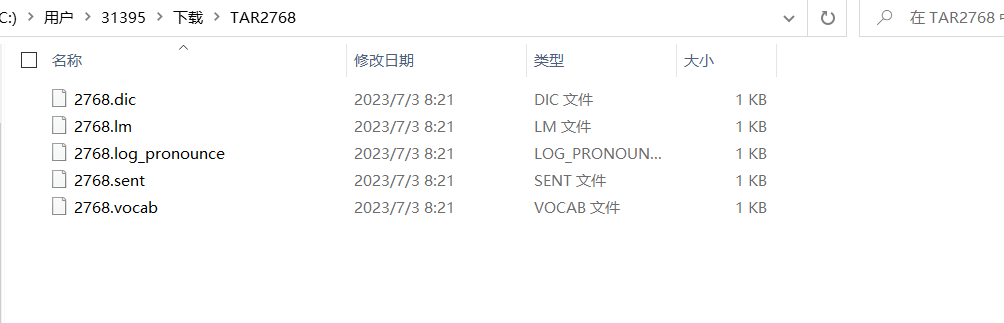
然后在此进入到我们的zh-CN目录。
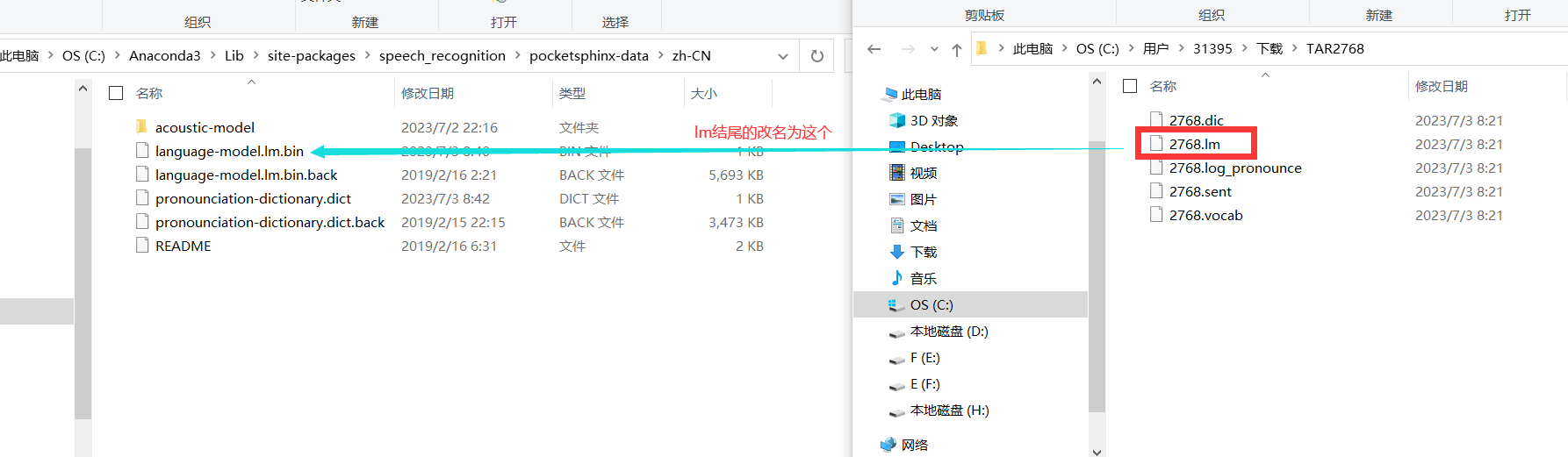
然后的话,重新制作我们的词典:
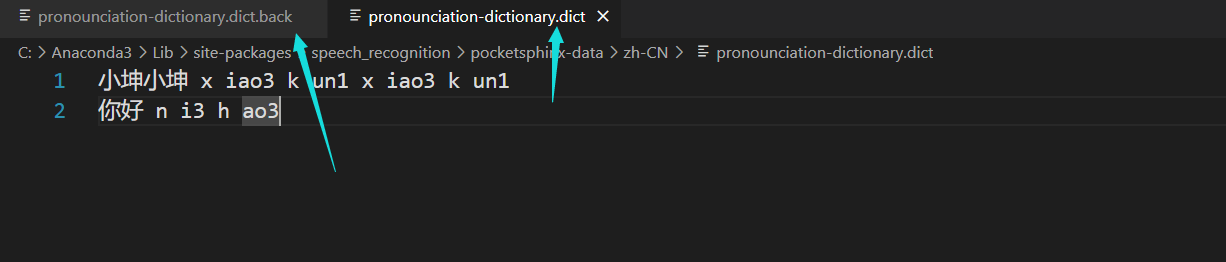
这个词典怎么制作的呢,其实就是,把文字和对应的声调在一开始的大的那个词典文件里面去找到,然后手动复制上去,一个字一个字找,就好了。
然后这里准备工作完成。
编码实现唤醒
之后的话,我们就可以愉快编码了。
import sys
import os
sys.path.append(os.path.abspath(os.path.dirname(os.getcwd())))
import pyttsx3
import speech_recognition as sr
from pydub import AudioSegment
from pydub.playback import play
class VocabularyKey:
# 风扇的声音比较容易识别到坤坤
KUN_KUN = "小坤小坤"
HELLO = "你好"
class ActionChain:
def __init__(self,language=0,rate=150,volume=0.9):
self.engine = pyttsx3.init()
self.engine.setProperty('rate', rate)
# 速度调试结果:50戏剧化的慢,200正常,350用心听小说,500敷衍了事
self.engine.setProperty('volume', volume)
self.voices = self.engine.getProperty('voices')
if int(language) == 0:
self.engine.setProperty('voice', 'zh')
# self.engine.setProperty('voice', self.voices[1].id)
self.shutDown = False
self.going = False
def __base(self):
pass
def process(self,key):
if(self.going):
return self.shutDown
self.going = True
# key = key.replace(" ", "")
#执行基础的指令,暂不定义
#执行非基础指令
#这个识别率比较低
if (VocabularyKey.HELLO in key or key in VocabularyKey.HELLO):
print("正在说话")
self.speak("你好,我是全民偶像练习生,喜欢,唱跳,rap,篮球")
self.going = False
return self.shutDown
if(VocabularyKey.KUN_KUN in key or key in VocabularyKey.KUN_KUN):
print("正在播放坤哥")
try:
self.sound("aiyou.mp3")
self.sound("aiyou.mp3")
self.sound("aiyou.mp3")
except Exception as e:
print(e)
#这里再转圈圈
# self.shut_down()
self.going = False
return self.shutDown
return self.shutDown
def sound(self,path):
# 设置音频文件路径
audio_file = path
# 使用 pydub 加载音频文件
audio = AudioSegment.from_file(audio_file, format="mp3")
# 播放音频
play(audio)
def go_forward(self):
pass
def speak(self,text):
self.engine.say(text) # pyttsx3->将结果念出来
self.engine.runAndWait()
self.engine.stop()
def go_backward(self):
pass
def go_turn_left(self):
pass
def go_turn_right(self):
pass
def shut_down(self):
self.shutDown = True
"""
实现语音识别
"""
class Recognition:
def __init__(self,timeout = 0.3):
self.timeout = timeout
self.setChainFlag = False
self.setMicFlag = False
self.recognition = sr.Recognizer()
self.showDown = False
def setMic(self,device_index=2, sample_rate=16000):
self.mic = sr.Microphone(device_index, sample_rate)
self.setMicFlag = True
def recognition_from_media(self,source_path):
test = sr.AudioFile(source_path)
with test as source:
audio = self.recognition.record(source)
c = self.recognition.recognize_sphinx(audio, language='zh-CN')
return c
def setChain(self,actionChain):
"""
处理逻辑的动作逻辑
:param actionChain:
:return:
"""
self.chain = actionChain
def process_command(self,text):
if(not self.setMicFlag):
raise Exception("处理逻辑初始化异常")
#actionChain 对象
return self.chain.process(text)
def recognition_real_time(self,device_index=2, sample_rate=16000):
if(not self.setMicFlag):
try:
self.setMic(device_index,sample_rate)
print("已开启麦克风")
except Exception as e:
raise Exception("麦克风开启失败")
with self.mic as source:
self.recognition.adjust_for_ambient_noise(source)
while not self.showDown:
audio = self.recognition.listen(source)
try:
# 使用PocketSphinx进行语音识别
text = self.recognition.recognize_sphinx(audio, language='zh-CN')
if text:
print("当前识别到:" + text)
self.showDown = self.process_command(text)
except sr.UnknownValueError:
print("无法识别语音")
except sr.RequestError as e:
print("语音识别异常: {0}".format(e))
if __name__ == '__main__':
recognition = Recognition()
chain = ActionChain()
recognition.setChain(chain)
recognition.recognition_real_time()
# chain.speak("你好,我是全民偶像练习生,喜欢,唱跳,rap,篮球")
# chain.sound("./aiyou.mp3")
可以看到的是,在代码当中的话,主要还是使用到这个speed,他会做个监听。那么这个时候简单的 这个就做好了,后面也可以整合到ros里面去。
至于效果的话,我就不演示了。