文章目录
- 环境的配置
- 神经网络CNN的介绍
- 卷积
- 前馈神经网络
- 卷积神经网络
- 应用邻域
- 数据集准备
- 数据预处理
- 构建基准模型
- 总结
- 什么是过拟合(overfit)?
- 什么是数据增强?
- 单独制作数据增强,精确率提高了多少? 然后再添加的dropout层,是什么实际效果?
- 参考资料
环境的配置
详细配置参考
1、安装Anaconda
2、配置TensorFlow、Keras
①创建虚拟环境
输入下面命令
conda create -n tf1 python=3.6
#tf1是自己为创建虚拟环境取的名字,后面python的版本可以根据自己需求进行选择
②安装tensorflow和keras
pip install 包名
#直接这样安装可以由于网络的原因,安装失败或者安装很慢
#解决方式:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
#此次安装命令如下:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow==1.14.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple keras==2.2.5
神经网络CNN的介绍
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习算法,常用于计算机视觉任务,如图像分类、物体检测和语义分割等。
卷积
简单定义:设f(x),g(x)是R1上的两个可积函数,作积分: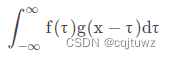
称为函数f(x)与g(x)的卷积,记为:f ( x ) ∗ g ( x ) = h ( x )
-
卷积与傅里叶变换有着密切的关系:两函数的傅里叶变换的乘积 = 它们卷积后的傅里叶变换(能简化傅里叶分析)
-
h(x)要比f(x)、g(x)更光滑:特别当g(x)为具有紧致集的光滑函数,f(x)为局部可积时,它们的卷积h(x)也是光滑函数;利用这一性质,对于任意的可积函数f(x),都可以简单地构造出一列逼近于f(x)的光滑函数列fs,这种方法称为函数的光滑化或正则化
前馈神经网络
-
前馈神经网络是一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层.各层间没有反馈。
-
其中每一层包含若干个神经元,各神经元可以接收前一层神经元的信号,并产生输出到下一层。第0层叫输入层,最后一层叫输出层,其他中间层叫做隐含层(或隐藏层、隐层),隐层可以是一层。也可以是多层。
一个典型的多层前馈神经网络如下图所示:
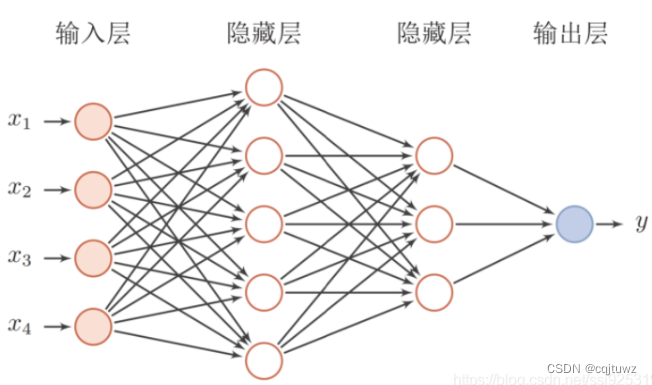
卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习算法,常用于计算机视觉任务,如图像分类、物体检测和语义分割等。
CNN的核心思想是模仿人类的视觉系统,通过多个卷积层和池化层的组合,自动地从原始输入数据中提取特征。以下是CNN的主要组成部分:
-
卷积层(Convolutional Layer): 卷积层是CNN的核心组件。它通过将输入数据与一组可学习的卷积核进行卷积操作,提取局部区域的特征。卷积操作是指使用卷积核在输入数据上进行滑动操作,计算卷积核与输入的点积,并生成特征图作为输出。每个卷积核可以捕捉不同的特征,如边缘、纹理和形状等。
3×3核的卷积核(卷积核一般采用3×3或2×2),卷积过程如下图:
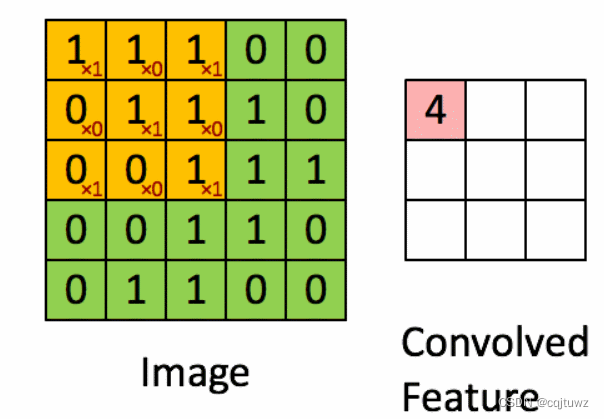
-
激活函数(Activation Function): 在卷积层之后,通常会应用一种非线性激活函数,如ReLU(Rectified Linear Unit),用于引入非线性特征。激活函数将每个卷积操作的输出进行非线性变换,增强网络的表达能力。
-
池化层(Pooling Layer): 池化层用于降低特征图的空间维度,减少参数数量,并增强特征的平移不变性。常用的池化操作包括最大池化和平均池化,它们分别提取输入数据的最大值和平均值作为特征图的输出。
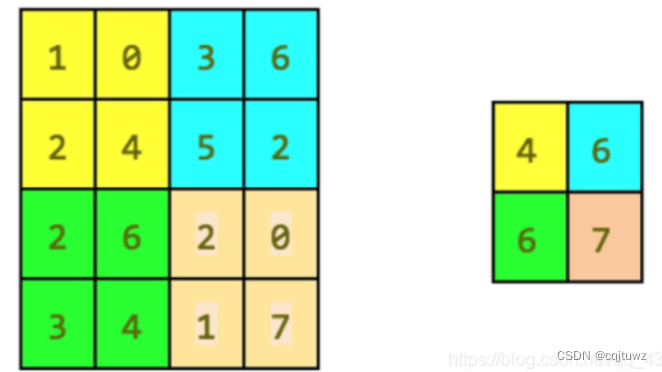
-
全连接层(Fully Connected Layer): 在经过多个卷积层和池化层后,通过对特征图进行展平操作,将其作为输入传递给全连接层。全连接层是一个经典的神经网络结构,每个神经元都与上一层的所有神经元相连,用于对提取到的特征进行分类或回归等任务。
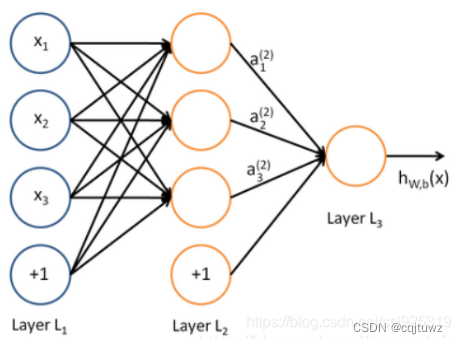
除了上述常见的组件,CNN还可以通过增加多个卷积层、池化层和全连接层来构建更深的网络结构。深层次的CNN可以学习到更高级别的抽象特征,提高模型的性能。
应用邻域
-
图像分类(Image Classification): CNN在图像分类任务中表现出色。通过训练,CNN可以学习到从输入图像中提取特征,并将其分为不同的类别,比如识别猫和狗的图像。
-
物体检测(Object Detection): CNN在物体检测中也取得了很大的成功。通过在图像中滑动卷积窗口进行特征提取,结合目标检测算法(如候选区域和边界框回归),CNN可以实现定位和识别图像中的多个物体。
-
人脸识别(Face Recognition): CNN在人脸识别领域广泛应用。训练一个CNN模型以识别人脸特征,可以用于人脸验证(例如解锁手机)和人脸识别(例如安全监控)等任务。
-
语义分割(Semantic Segmentation): CNN可以将图像中的每个像素分类为不同的语义类别,实现图像的精确分割。这在医学图像分析、自动驾驶和图像编辑等领域具有重要应用。
-
视频分析(Video Analysis): CNN也可以应用于视频分析任务,如动作识别、行为识别和视频标注等。通过对视频帧进行卷积和池化操作,CNN能够提取时间和空间信息。
卷积神经网络不仅仅局限于上述应用领域,在许多其他领域,如自然语言处理(NLP)、药物发现和声音处理等,也可以使用CNN进行特征提取和分类任务。
数据集准备
猫狗图片数据集下载:——提取码:ruyn
数据集下载完毕后,解压缩,注意存放路径不能存在中文,如图所示:
数据预处理
对猫狗图像进行分类,代码如下:
import os, shutil
# 原始目录所在的路径
original_dataset_dir = 'E:\\Cat_And_Dog\\train\\'
# 数据集分类后的目录
base_dir = 'E:\\Cat_And_Dog\\train1'
os.mkdir(base_dir)
# # 训练、验证、测试数据集的目录
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# 猫训练图片所在目录
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
# 狗训练图片所在目录
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
# 猫验证图片所在目录
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
# 狗验证数据集所在目录
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
# 猫测试数据集所在目录
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
# 狗测试数据集所在目录
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
# 将前1000张猫图像复制到train_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
# 将下500张猫图像复制到validation_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
# 将下500张猫图像复制到test_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
# 将前1000张狗图像复制到train_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# 将下500张狗图像复制到validation_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# 将下500张狗图像复制到test_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
分类后如下图所示:
 查看分类后,对应目录下的图片数量:
查看分类后,对应目录下的图片数量:
#输出数据集对应目录下图片数量
print('total training cat images:', len(os.listdir(train_cats_dir)))
print('total training dog images:', len(os.listdir(train_dogs_dir)))
print('total validation cat images:', len(os.listdir(validation_cats_dir)))
print('total validation dog images:', len(os.listdir(validation_dogs_dir)))
print('total test cat images:', len(os.listdir(test_cats_dir)))
print('total test dog images:', len(os.listdir(test_dogs_dir)))

猫狗训练图片各 1000 张,验证图片各 500 张,测试图片各 500 张。
构建基准模型
第①步:构建网络模型:
#网络模型构建
from keras import layers
from keras import models
#keras的序贯模型
model = models.Sequential()
#卷积层,卷积核是3*3,激活函数relu
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
#最大池化层
model.add(layers.MaxPooling2D((2, 2)))
#卷积层,卷积核2*2,激活函数relu
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
#最大池化层
model.add(layers.MaxPooling2D((2, 2)))
#卷积层,卷积核是3*3,激活函数relu
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
#最大池化层
model.add(layers.MaxPooling2D((2, 2)))
#卷积层,卷积核是3*3,激活函数relu
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
#最大池化层
model.add(layers.MaxPooling2D((2, 2)))
#flatten层,用于将多维的输入一维化,用于卷积层和全连接层的过渡
model.add(layers.Flatten())
#全连接,激活函数relu
model.add(layers.Dense(512, activation='relu'))
#全连接,激活函数sigmoid
model.add(layers.Dense(1, activation='sigmoid'))
运行以上代码出现以下错误
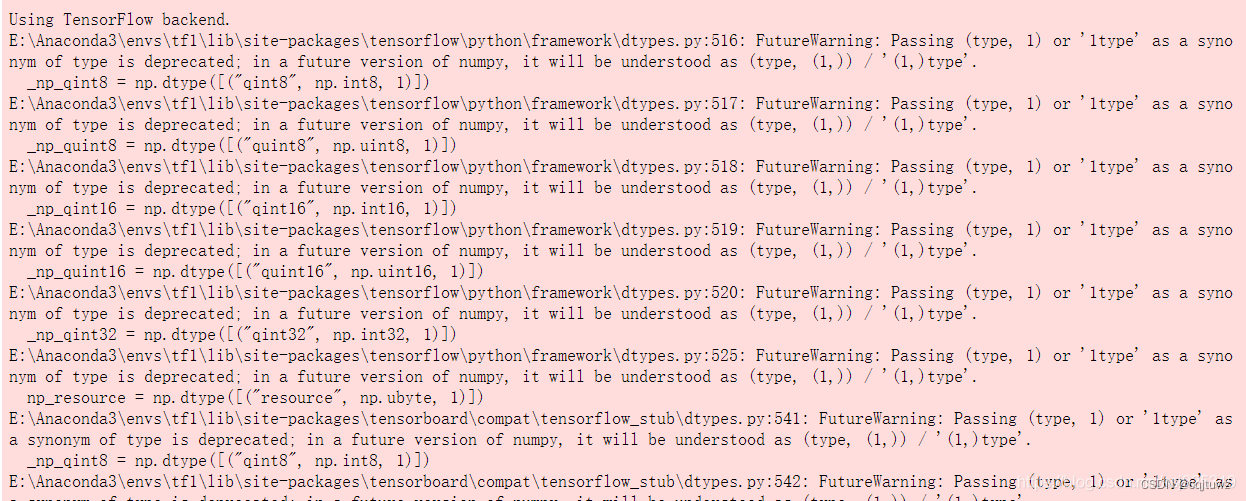
- 错误原因:这是由于 numpy 版本与 tensorflow 版本不匹配的问题,安装 1.16.4 版本的 numpy 即可,命令如下:
pip install numpy==1.16.4 -i "https://pypi.doubanio.com/simple/"
- 安装完成后,会自动卸载已有的 numpy 版本。
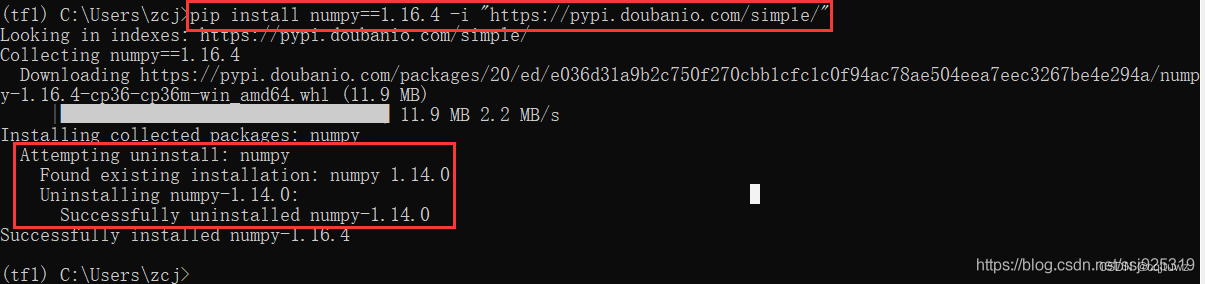
最后重新运行即可
查看模型各层参数:
#输出模型各层的参数状况
model.summary()
结果如下图所示

2、配置优化器
- loss:计算损失,这里用的是交叉熵损失
- metrics:列表,包含评估模型在训练和测试时的性能的指标
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
3、文件中图像转换成所需格式
将训练和验证的图片,调整为150*150
from keras.preprocessing.image import ImageDataGenerator
# 所有图像将按1/255重新缩放
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 这是目标目录
train_dir,
# 所有图像将调整为150x150
target_size=(150, 150),
batch_size=20,
# 因为我们使用二元交叉熵损失,我们需要二元标签
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
处理结果
#查看上面对于图片预处理的处理结果
for data_batch, labels_batch in train_generator:
print('data batch shape:', data_batch.shape)
print('labels batch shape:', labels_batch.shape)
break
- 如果出现错误:ImportError: Could not import PIL.Image. The use of
load_imgrequires PIL,是因为没有安装 pillow 库导致的,使用如下命令在 tf1 虚拟环境中安装: pip install pillow -i “https://pypi.doubanio.com/simple/”
结果:
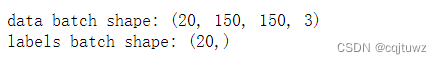
4、开始训练模型
#模型训练过程
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
此步骤电脑性能越好,训练就越快

5、保存模型
#保存训练得到的的模型
model.save('G:\\Cat_And_Dog\\kaggle\\cats_and_dogs_small_1.h5')
6、结果可视化(需要在 tf1 虚拟环境中安装 matplotlib 库,命令:pip install matplotlib -i “https://pypi.doubanio.com/simple/”)。
#对于模型进行评估,查看预测的准确性
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
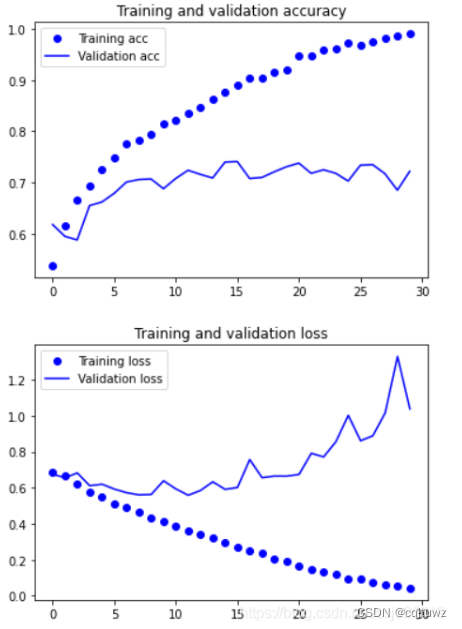
训练结果如上图所示,很明显模型上来就过拟合了,主要原因是数据不够,或者说相对于数据量,模型过复杂(训练损失在第30个epoch就降为0了),训练精度随着时间线性增长,直到接近100%,而我们的验证精度停留在70-72%。我们的验证损失在5个epoch后达到最小,然后停止,而训练损失继续线性下降,直到接近0。
总结
什么是过拟合(overfit)?
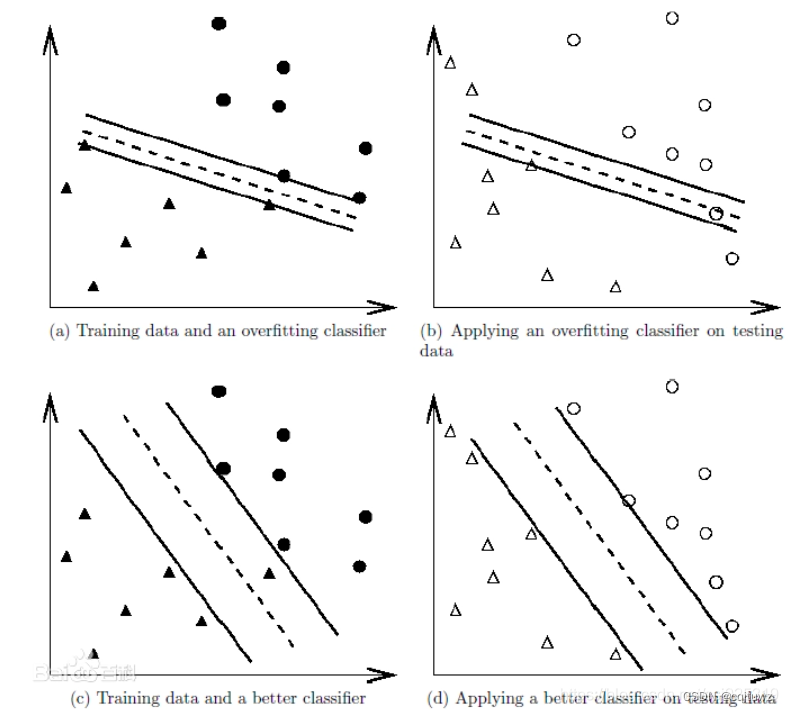
- 定义:过拟合的定义:给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比h小,但在整个实例分布上h’比h的错误率小,那么就说假设h过度拟合训练数据。
举个简单的例子,( a )( b )过拟合,( c )( d )不过拟合,如下图所示:
- 过拟合常见解决方法:
(1)在神经网络模型中,可使用权值衰减的方法,即每次迭代过程中以某个小因子降低每个权值。
(2)选取合适的停止训练标准,使对机器的训练在合适的程度;
(3)保留验证数据集,对训练成果进行验证;
(4)获取额外数据进行交叉验证;
(5)正则化,即在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。
什么是数据增强?
数据集增强主要是为了减少网络的过拟合现象,通过对训练图片进行变换可以得到泛化能力更强的网络,更好的适应应用场景。
常用的数据增强方法有:

单独制作数据增强,精确率提高了多少? 然后再添加的dropout层,是什么实际效果?
1、图像增强
利用图像生成器定义一些常见的图像变换,图像增强就是通过对于图像进行变换,从而,增强图像中的有用信息。
#该部分代码及以后的代码,用于替代基准模型中分类后面的代码(执行代码前,需要先将之前分类的目录删掉,重写生成分类,否则,会发生错误)
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
①rotation_range
一个角度值(0-180),在这个范围内可以随机旋转图片
②width_shift和height_shift
范围(作为总宽度或高度的一部分),在其中可以随机地垂直或水平地转换图片
③shear_range
用于随机应用剪切转换
④zoom_range
用于在图片内部随机缩放
⑤horizontal_flip
用于水平随机翻转一半的图像——当没有假设水平不对称时(例如真实世界的图片)
⑥fill_mode
用于填充新创建像素的策略,它可以在旋转或宽度/高度移动之后出现
2、查看增强后的图像
import matplotlib.pyplot as plt
# This is module with image preprocessing utilities
from keras.preprocessing import image
fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)]
# We pick one image to "augment"
img_path = fnames[3]
# Read the image and resize it
img = image.load_img(img_path, target_size=(150, 150))
# Convert it to a Numpy array with shape (150, 150, 3)
x = image.img_to_array(img)
# Reshape it to (1, 150, 150, 3)
x = x.reshape((1,) + x.shape)
# The .flow() command below generates batches of randomly transformed images.
# It will loop indefinitely, so we need to `break` the loop at some point!
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()

3、网络模型增加一层dropout
#网络模型构建
from keras import layers
from keras import models
#keras的序贯模型
model = models.Sequential()
#卷积层,卷积核是3*3,激活函数relu
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
#最大池化层
model.add(layers.MaxPooling2D((2, 2)))
#卷积层,卷积核2*2,激活函数relu
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
#最大池化层
model.add(layers.MaxPooling2D((2, 2)))
#卷积层,卷积核是3*3,激活函数relu
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
#最大池化层
model.add(layers.MaxPooling2D((2, 2)))
#卷积层,卷积核是3*3,激活函数relu
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
#最大池化层
model.add(layers.MaxPooling2D((2, 2)))
#flatten层,用于将多维的输入一维化,用于卷积层和全连接层的过渡
model.add(layers.Flatten())
#退出层
model.add(layers.Dropout(0.5))
#全连接,激活函数relu
model.add(layers.Dense(512, activation='relu'))
#全连接,激活函数sigmoid
model.add(layers.Dense(1, activation='sigmoid'))
#输出模型各层的参数状况
model.summary()
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
结果:
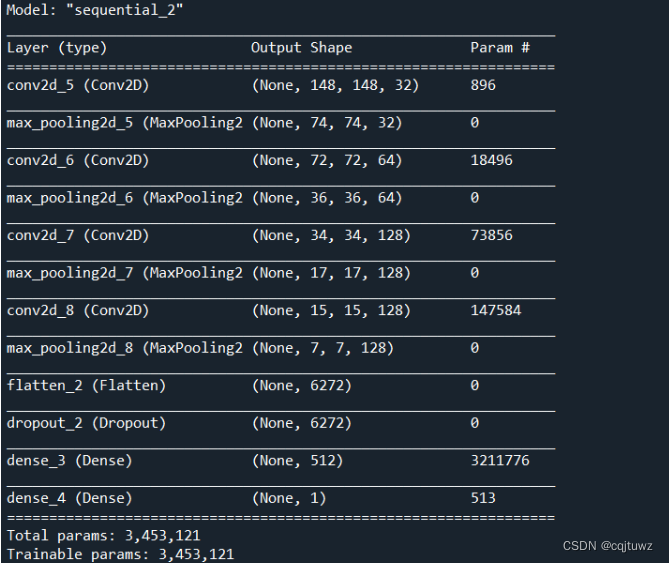
4、训练模型:
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# Note that the validation data should not be augmented!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
model.save('G:\\Cat_And_Dog\\kaggle\\cats_and_dogs_small_2.h5')
结果:
5、可视化结果
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
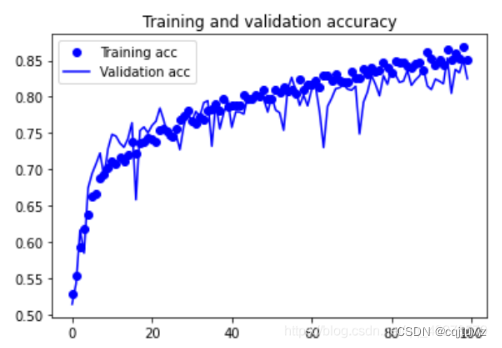
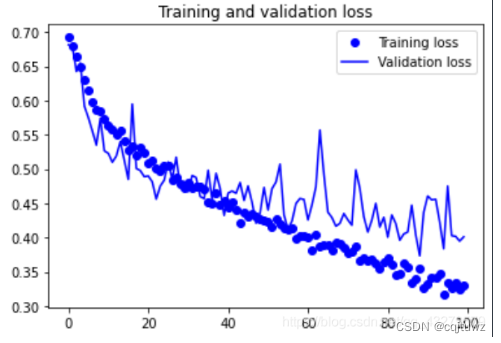
参考资料
配置参考
安装Anaconda
基于Tensorflow和Keras实现卷积神经网络CNN
基于卷积神经网络 CNN 的猫狗识别详细过程
猫狗数据集分类实验