论文标题:
SPEECH: Structured Prediction with Energy-Based Event-Centric Hyperspheres
收录会议:
ACL 2023 Main Conference
论文链接:
https://arxiv.org/abs/2305.13617
开源链接:
https://github.com/zjunlp/SPEECH

总述
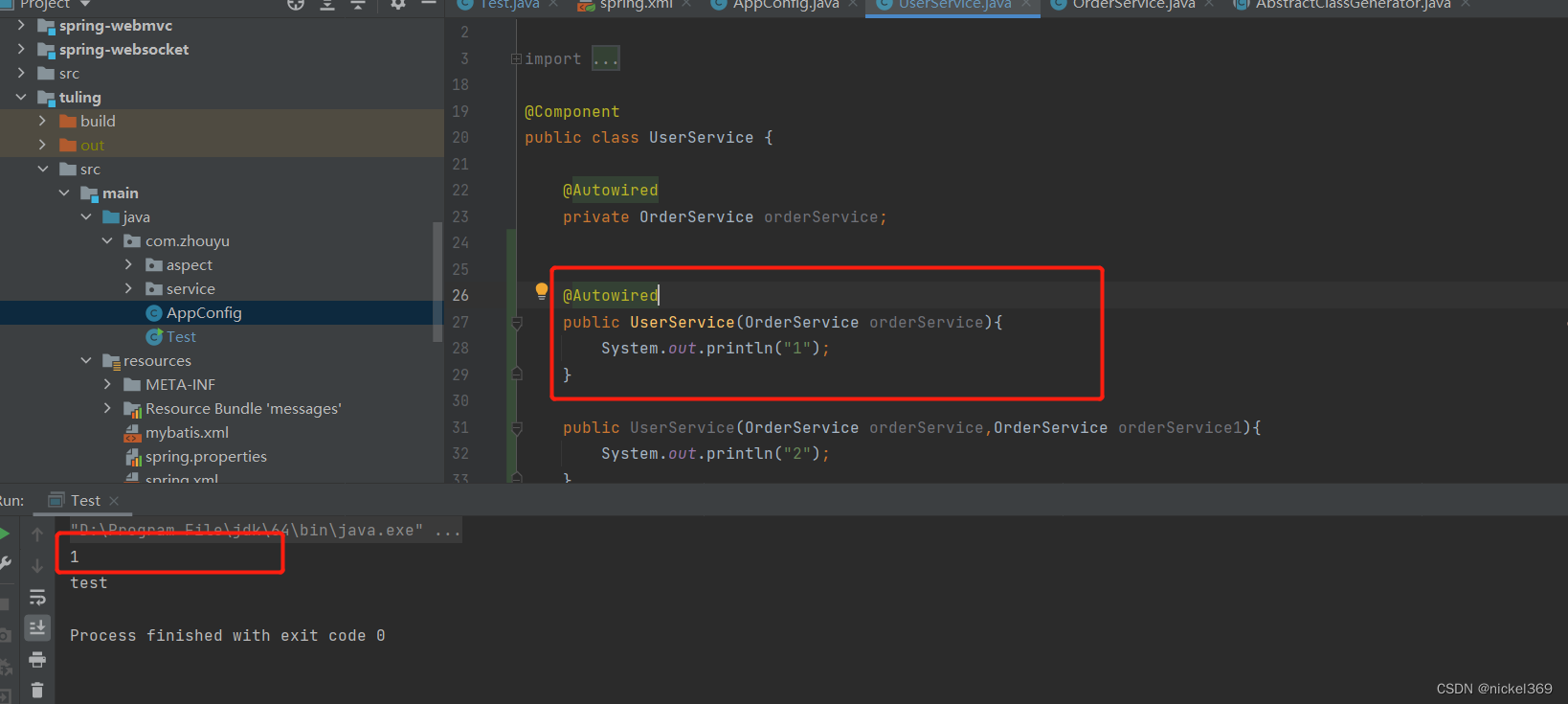
以事件为中心的结构化预测旨在输出事件的结构化组件。事件结构往往比较复杂,而且结构间存在多种依赖,比如 Token 之间的长距离依赖、触发词和事件类别之间的关联、以及事件类别和事件关系之间的依赖。
为了解决这些问题,本文提出了基于能量的超球体(SPEECH)以解决以事件为中心的结构化预测任务。SPEECH 使用基于能量的建模对事件结构化组件之间的复杂依赖进行建模,并使用简单但有效的超球体来表示事件类别。在 MAVEN-ERE 和 OntoEvent-Doc 两个事件数据集上进行的实验表明,SPEECH 模型在事件检测和事件关系抽取任务上表现不俗。

▲ 以事件为中心的结构化预测任务示例

方法
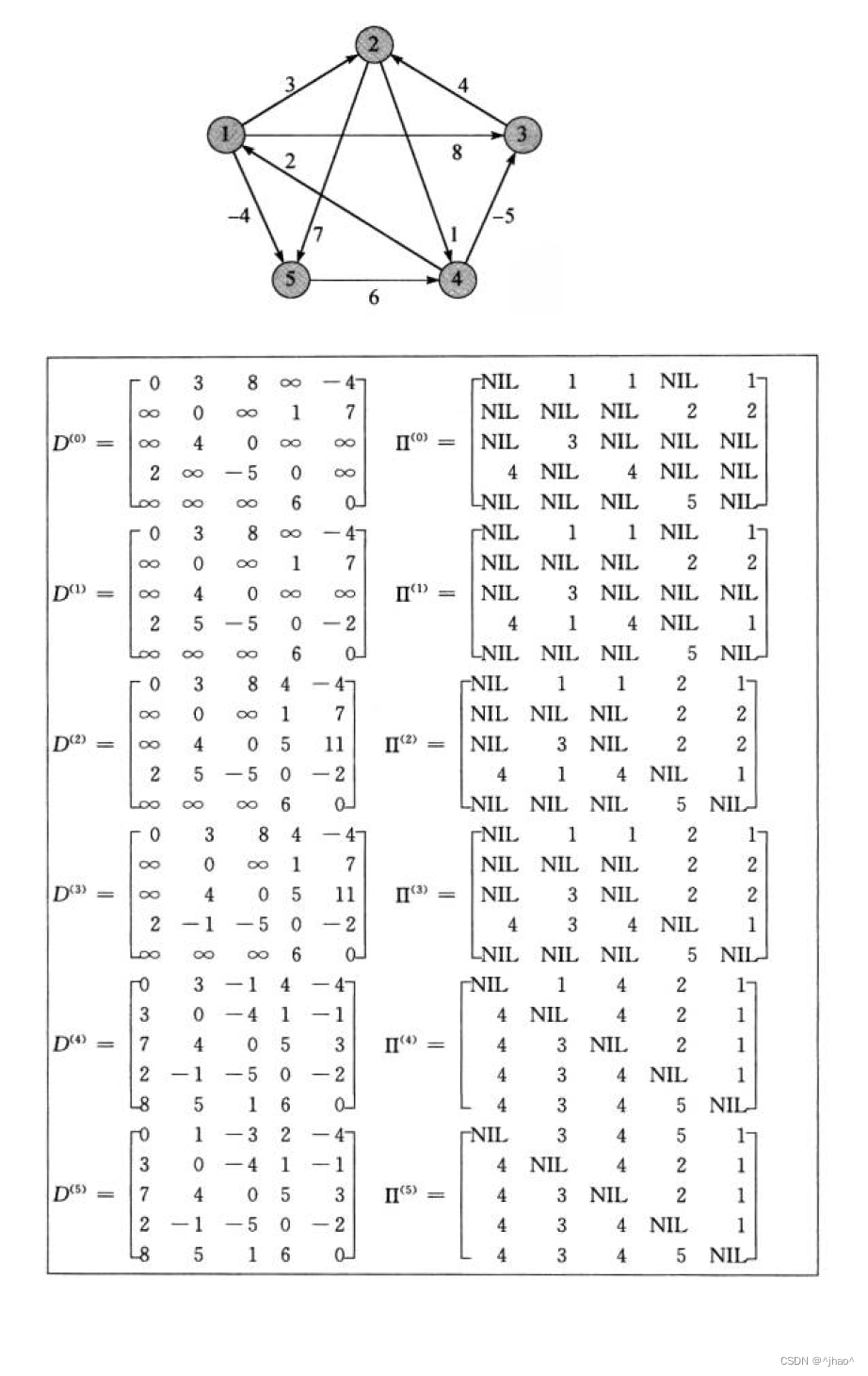
SPEECH 模型的设计灵感主要来源于万有引力定律和能量函数。如果把抽象的事件类别看成电子核/恒星,其对应的样本就可看成核外电子/行星。因此本文提出利用基于能量的超球体来建模事件类别及其样本。模型主要与 token、sentence、document 三种维度的能量相关联。
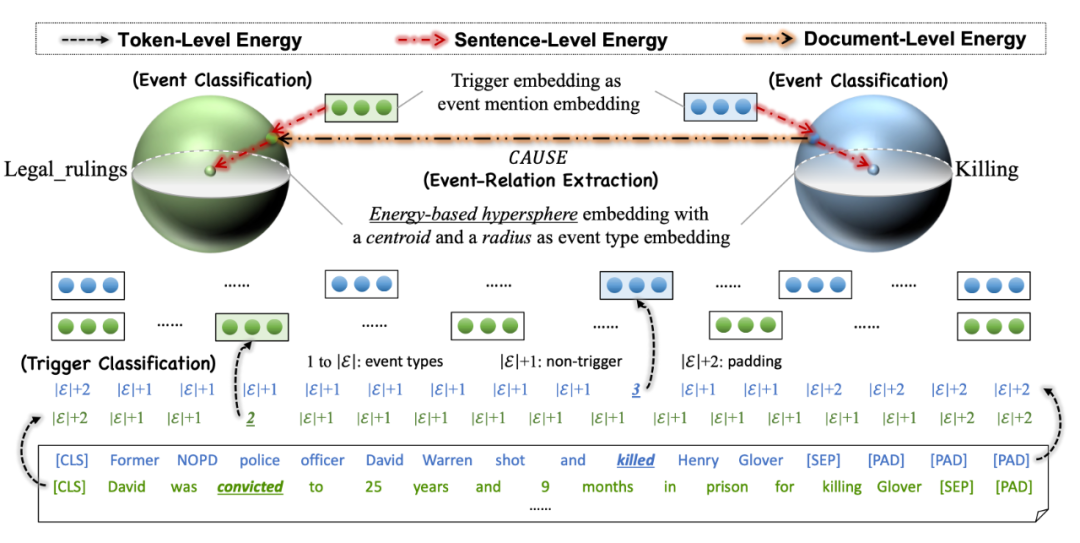
▲ SPEECH模型概览
(1)Token 级别的能量
能量函数:
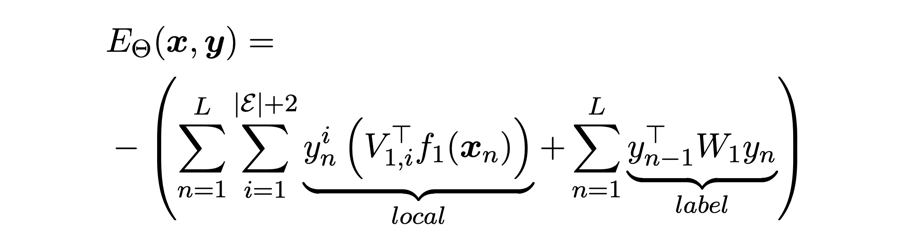
损失函数:
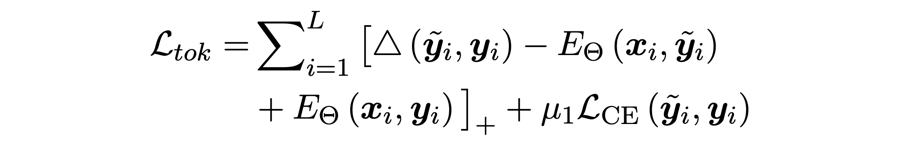
这里主要考虑了 token 之间(local)和 token 类别之间(label)的能量。
(2)Sentence 级别的能量
本文用一个基于能量的超球体来表示每个事件,事件类别表示成球体质心,事件样本被尽可能约束在球体表面,超球体的度量公式表示为:
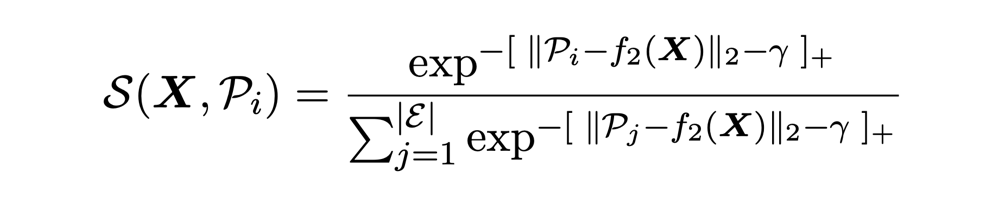
能量函数:
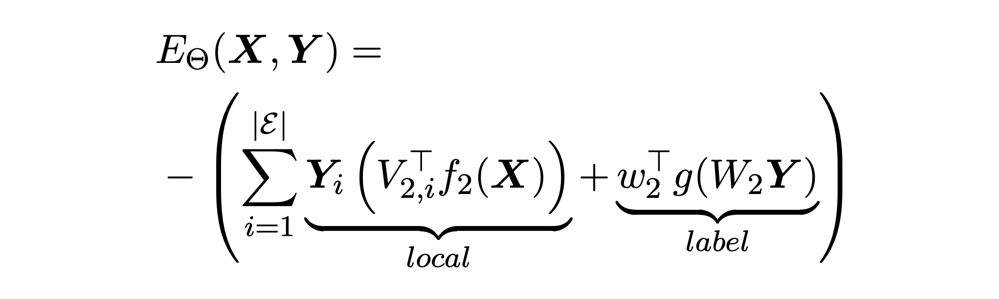
损失函数:
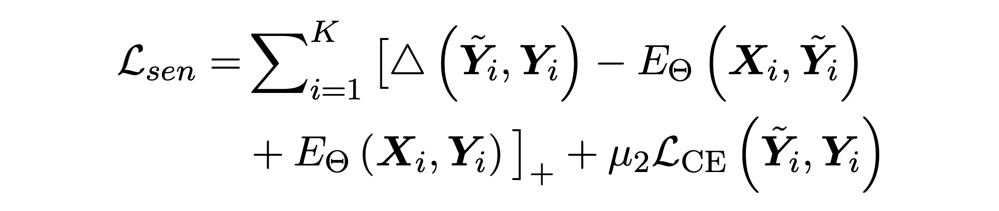
这里主要考虑了事件之间(local)和事件类别之间(label)的能量。
(3)Document级别的能量
能量函数:
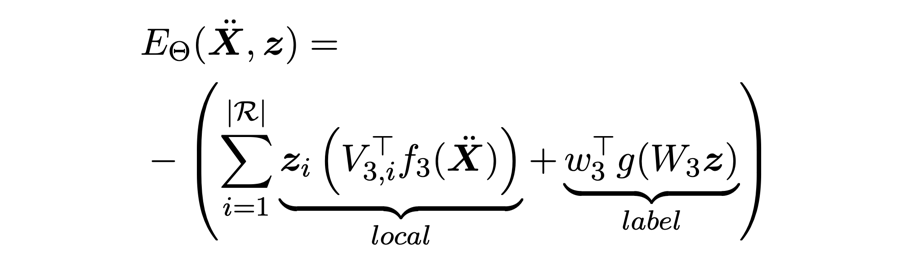
损失函数:
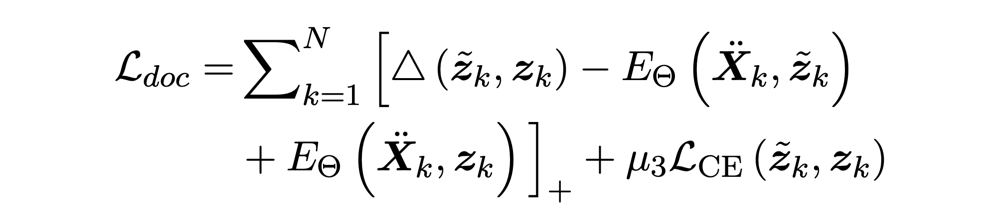
这里主要考虑了事件对之间(local)和事件关系类别之间(label)的能量。

实验
本文主要在三类以事件为中心的结构化预测任务上进行了实验,用到的数据集是最新发布的 MAVEN-ERE 以及 OntoEvent-Doc。由于 MAVEN-ERE 没有直接发布测试集标签,本文的实验是在 MAVEN-ERE 的验证集以及 OntoEvent-Doc 的测试集上进行的。
(1)触发词分类(针对token)
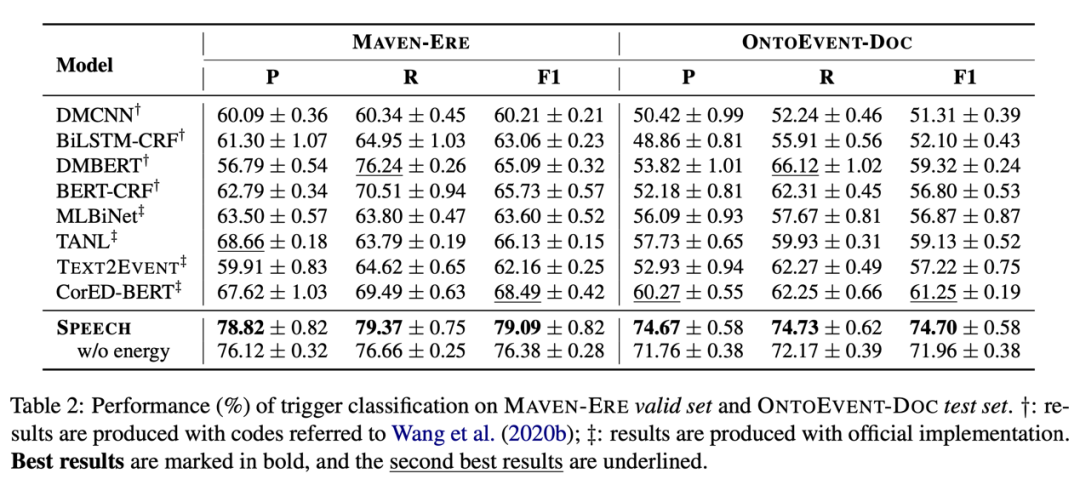
(2)事件分类(针对event mention)
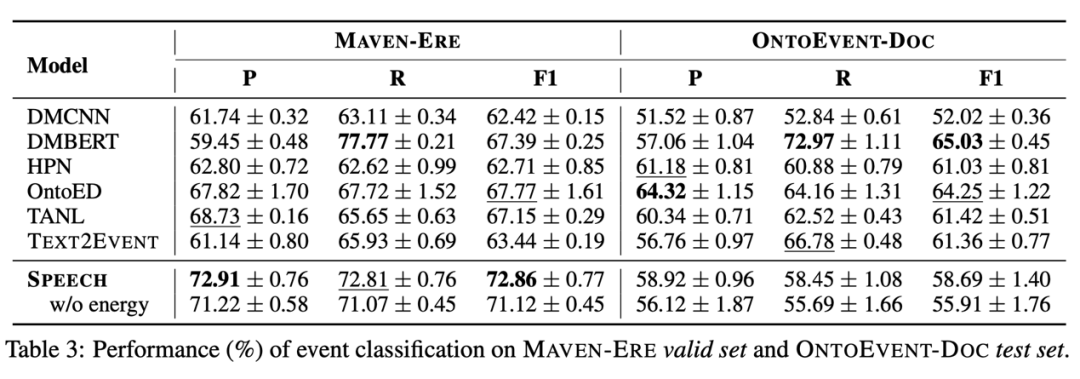
(3)事件关系抽取(针对event mention pair)
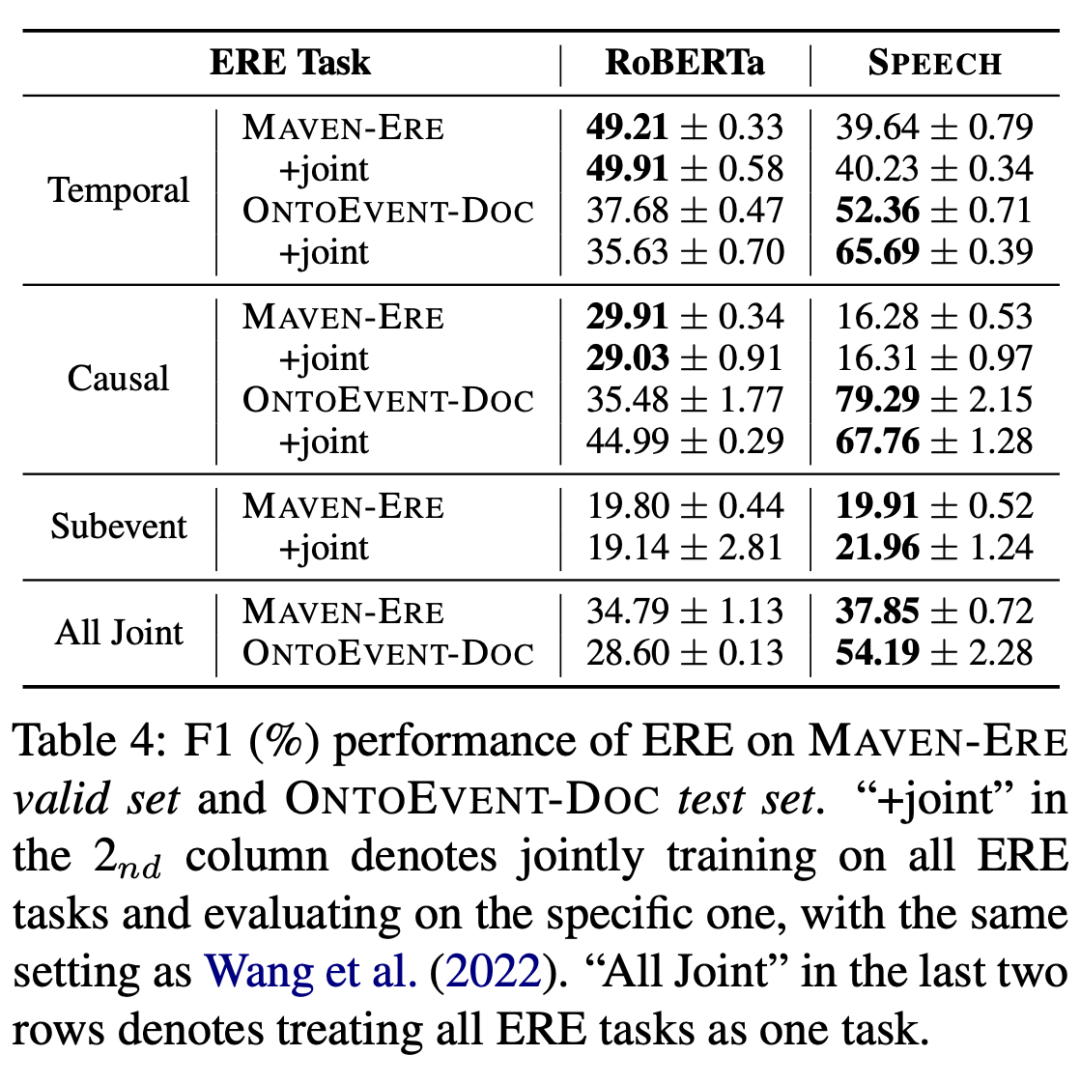
可以发现 SPEECH 模型在 MAVEN-ERE 数据集的触发词分类以及事件分类任务上表现颇佳,在 OntoEvent-Doc 数据集的触发词分类以及事件关系分类上优势明显。总体来看 SPEECH 模型表现不俗,但其效果也会受到数据集以及数据分布的影响。
如果对本文工作感兴趣,文章详细信息可以查看论文。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·







![【读书笔记】《月亮与六便士》- [英] 威廉·萨默塞特·毛姆 - 1919年出版](https://img-blog.csdnimg.cn/0d5a34e288984229a2293e7162ae5b04.png#pic_center)