CMU 15-445 -- 关系型数据库重点概念回顾 - 01
- 引言
- Relational Data Model
- DBMS
- 数据模型
- Relational Model
- Relation & Tuple
- Primary Keys
- Foreign Keys
- Data Manipulation Languages (DML)
- Relational Algebra
- Advanced SQL
- SQL 的历史
- SQL
- Aggregates
- Group By
- Having
- Output Redirection
- Output Control
- Order By
- Limit
- Nested Queries
- Common Table Expressions
- String Operations
- String Matching
- String Operations
- Date/Time Operations
- Window Functions
引言
本系列为 CMU 15-445 Fall 2022 Database Systems 数据库系统 [卡内基梅隆] 课程重点知识点摘录,附加个人拙见,同样借助CMU 15-445课程内容来完成MIT 6.830 lab内容。
CMU 15-445实验如果有空,后期会在本专栏补充上。
Relational Data Model
DBMS
所有系统都会产生数据,因此数据库几乎是所有系统都不可或缺的模块。在早期,各个项目各自造轮子,因为每个轮子都是为应用量身打造,这些系统的逻辑层(logical)和物理层(physical)普遍耦合度很高。
Ted Codd 发现这个问题后,提出 DBMS 的抽象(Abstraction):
- 用简单的、统一的数据结构存储数据
- 通过高级语言操作数据
- 逻辑层和物理层分离,系统开发者只关心逻辑层,而 DBMS 开发者才关心物理层。
数据模型
在逻辑层中,我们通常需要对所需存储的数据进行建模。如今,市面上有的数据模型包括:
- Relational => 大部分 DBMS 属于关系型,也是本课讨论的重点
- Key/Value
- Graph
- Document
- Column-family
- Array/Matrix
Relational Model
Relation & Tuple
每个 Relation 都是一个无序集合(unordered set),集合中的元素称为 tuple,每个 tuple 由一组属性构成,这些属性在逻辑上通常有内在联系。
Primary Keys
primary key 在一个 Relation 中唯一确定一个 tuple,如果你不指定,有些 DBMSs 会自动帮你生成 primary key。
Foreign Keys
foreign key 唯一确定另一个 relation 中的一个 tuple
Data Manipulation Languages (DML)
在 Relational Model 中从数据库中查询数据通常有两种方式:Procedural 与 NonProcedural:
- Procedural:查询命令需要指定 DBMS 执行时的具体查询策略,如 Relational Algebra
- Non-Procedural:查询命令只需要指定想要查询哪些数据,无需关心幕后的故事,如 SQL
使用哪种方式是具体的实现问题,与 Relational Model 本身无关。
Relational Algebra
relational algebra 是基于 set algebra 提出的,从 relation 中查询和修改 tuples 的一些基本操作,它们包括:

将这些操作串联起来,我们就能构建更复杂的操作
注意:
- 使用 Relation Algebra 时,我们实际上指定了执行策略,如:

- 它们所做的事情都是 ”返回 R 和 S Join 后的结果中,b_id 等于 102 的 tuples“。
虽然 Relational Algebra 只是 Relational Model 的具体实现方式,但在之后的课程将会看到它对查询优化、执行的帮助。
本部分参考课程链接
Advanced SQL
在 Relational Model 下构建查询语句的方式分为两种:
- Procedural 和 Non-Procedural。
第一节课中已经介绍了 Relational Algebra,它属于 Procedural 类型,而本节将介绍的 SQL 属于 Non-Procedural 类型。使用 SQL 构建查询时,用户只需要指定它们想要的数据,而不需要关心数据获取的方式,DBMS 负责理解用户的查询语义,选择最优的方式构建查询计划。
SQL 的历史
- ”SEQUAL" from IBM’s System R prototype
- Structured English Query Language
- Adopted by Oracle in the 1970s
- IBM releases DB2 in 1983
- ANSI Standard in 1986. ISO in 1987
- Structured Query Language
当前 SQL 的标准是 SQL 2016,而目前大部分 DBMSs 至少支持 SQL-92 标准,具体的系统对比信息可以到这里查询。
SQL
SQL 基于:
- Aggregations + Group By
- String / Date / Time Operations
- Output Control + Redirection
- Nested Queries
- Common Table Expressions
- Window Functions
本节使用的示例数据库如下所示:
student(sid, name, login, gpa)
| sid | name | login | age | gpa |
|---|---|---|---|---|
| 53666 | Kanye | kayne@cs | 39 | 4.0 |
| 53668 | Bieber | jbieber@cs | 22 | 3.9 |
enrolled(sid, cid, grade)
| sid | cid | grade |
|---|---|---|
| 53666 | 15-445 | C |
| 53688 | 15-721 | A |
course(cid, name)
| cid | name |
|---|---|
| 15-445 | Database Systems |
| 15-721 | Advanced Database Systems |
Aggregates
Aggregates 通常返回一个值,它们包括:
- AVG(col)
- MIN(col)
- MAX(col)
- SUM(col)
- COUNT(col)
举例如下:
- count.sql
SELECT COUNT(login) AS cnt FROM student WHERE login LIKE '%@cs';
SELECT COUNT(*) AS cnt FROM student WHERE login LIKE '%@cs';
SELECT COUNT(1) AS cnt FROM student WHERE login LIKE '%@cs';
- multiple.sql
SELECT AVG(gpa), COUNT(sid) FROM student WHERE login LIKE '%@cs';
- distinct.sql
SELECT COUNT(DISTINCT login) FROM student WHERE login LIKE '%@cs';
aggregate 与其它通常的查询列不可以混用,比如:
- mix.sql
SELECT AVG(s.gpa), e.cid FROM enrolled AS e, student AS s WHERE e.sid = s.sid;
不同 DBMSs 的输出结果不一样,严格模式下,DBMS 应该抛错。
Group By
group by 就是把记录按某种方式分成多组,对每组记录分别做 aggregates 操作,如求每门课所有学生的 GPA 平均值:
SELECT AVG(s.gpa), e.cid FROM enrolled AS e, student AS s WHERE e.sid = s.sid GROUP BY e.cid;
所有非 aggregates 操作的字段,都必须出现在 group by 语句,如下面示例中的 e.cid 和 s.name:
SELECT AVG(s.gpa), e.cid, s.name FROM enrolled AS e, student AS s WHERE e.sid = s.sid GROUP BY e.cid, s.name;
Having
基于 aggregation 结果的过滤条件不能写在 WHERE 中,而应放在 HAVING 中,如:
SELECT AVG(s.gpa) AS avg_gpa, e.cid FROM enrolled AS e, student AS s WHERE e.sid = s.sid GROUP BY e.cid HAVING avg_gpa > 3.9;
Output Redirection
将查询结果储存到另一张表上:
- 该表必须是已经存在的表
- 该表的列数,以及每列的数据类型必须相同
SQL-92.sql:
SELECT DISTINCT cid INTO CourseIds FROM enrolled;
INSERT INTO CourseIds ( SELECT DISTINCT cid FROM enrolled );
MySQL.sql:
CREATE TABLE CourseIds ( SELECT DISTINCT cid FROM enrolled );
Output Control
Order By
语法: ORDER BY <column*> [ASC|DESC]
SELECT sid, grade FROM enrolled WHERE cid = '15-721' ORDER BY grade;
按多个字段分别排序:
SELECT sid FROM enrolled WHERE cid = '15-721' ORDER BY grade DESC, sid ASC;
Limit
语法:LIMIT <count> [offset]
SELECT sid, name FROM student WHERE login LIKE '%@cs' LIMIT 10;
SELECT sid, name FROM student WHERE login LIKE '%@cs' LIMIT 20 OFFSET 10;
Nested Queries
nested queries 包含 inner queries 和 outer queries,前者可以出现在 query 的任何位置,且 inner queries 可以引用 outer queries 中的表信息。
例 1:获取所有参与 ‘15-445’ 这门课所有学生的姓名:
SELECT name FROM student WHERE sid IN ( SELECT sid FROM enrolled WHERE cid = '15-445' );
SELECT (SELECT S.name FROM student AS S WHERE S.sid = E.sid) AS sname FROM enrolled AS E WHERE cid = '15-445';
语法中支持的谓词包括:
- ALL: 所有 inner queries 返回的记录都必须满足条件
- ANY:任意 inner queries 返回的记录满足条件即可
- IN:与 ANY 等价
- EXISTS: inner queries 返回的表不为空
SELECT name FROM student WHERE sid ANY ( SELECT sid FROM enrolled WHERE cid = '15-445')
例 2:找到至少参与一门课程的所有学生中,id 最大的
SELECT sid, name FROM student WHERE sid >= ALL (SELECT sid FROM enrolled);
SELECT sid, name FROM student WHERE sid IN (SELECT MAX(sid) FROM enrolled);
SELECT sid, name FROM student WHERE sid IN (SELECT sid FROM enrolled ORDER BY sid DESC LIMIT 1);
例 3:找到所有没有学生参与的课程
SELECT * FROM course WHERE NOT EXISTS (SELECT * FROM enrolled WHERE course.cid = enrolled.cid);
nested queries 比较难被优化。
Common Table Expressions
在一些复杂查询中,创建一些中间表能够使得这些查询逻辑更加清晰:
WITH cteName AS (SELECT 1) SELECT * FROM cteName
WITH cteName (col1, col2) AS (SELECT 1, 2) SELECT col1 + col2 FROM cteName
WITH cteName1(col) AS (SELECT 1),cteName2(col) AS (SELECT 2) SELECT C1.col + C2.col FROM cteName1 AS C1, cteName2 AS C2;
例 1:找到所有参与课程的学生中 id 最大的
WITH cteSource(maxId) AS (
SELECT MAX(sid) FROM enrolled
)
SELECT name FROM student, cteSource
WHERE student.sid = cteSource.maxId
例 2:打印 1-10
WITH RECURSIVE cteSource (counter) AS (
(SELECT 1)
UNION ALL
(SELECT counter + 1 FROM cteSource
WHERE counter < 10)
)
SELECT * FROM cteSource;
String Operations
| DBMS | String Case | String Quotes |
|---|---|---|
| SQL-92 | Sensitive | Single Only |
| Postgres | Sensitive | Single Only |
| MySQL | InSensitive | Single/Double |
| SQLite | Sensitive | Single/Double |
| Oracle | Sensitive | Single Only |
如在 condition 中判断两个字符串忽略大小写后是否相等:
/* SQL-92 */
WHERE UPPER(name) = UPPER('KaNyE')
/* MySQL */
WHERE name = "KaNyE"
String Matching
SELECT * FROM enrolled AS e
WHERE e.cid LIKE '15-%';
SELECT * FROM student AS s
WHERE s.login LIKE '%@c_';
String Operations
SQL-92 定义了一些 string 函数,如
SELECT SUBSTRING(name, 0, 5) AS abbrv_name
FROM student WHERE sid = 53688;
SELECT * FROM student AS s
WHERE UPPER(e.name) LIKE 'KAN%';
不同 DBMS 有不同的 string 函数(没有完全遵从 SQL-92 标准),如连接两个 strings
/* SQL-92 */
SELECT name FROM student
WHERE login = LOWER(name) || '@cs';
/* MySQL */
SELECT name FROM student
WHERE login = LOWER(name) + '@cs';
SELECT name FROM student
WHERE login = CONCAT(LOWER(name), '@cs')
Date/Time Operations
不同的 DBMS 中的定义和用法不一样,具体见各 DBMS 的文档。
Window Functions
主要用于在一组记录中,对每一条记录进行一些计算,如:
例 1:
SELECT *, ROW_NUMBER() OVER () AS row_num FROM enrolled;
会得到类似下表:

例 2:
SELECT cid, sid,
ROW_NUMBER() OVER (PARTITION BY cid)
FROM enrolled
ORDER BY cid;
可是得到类似下表:
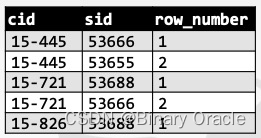
例 3:找到每门课获得最高分的学生
SELECT * FROM (
SELECT *,
RANK() OVER (PARTITION BY cid ORDER BY grade ASC) AS rank
FROM enrolled
) AS ranking
WHERE ranking.rank = 1
通俗易懂的学会:SQL窗口函数
本部分参考课程链接