上一章对值对象以及实体进行了一些简单的讲解:
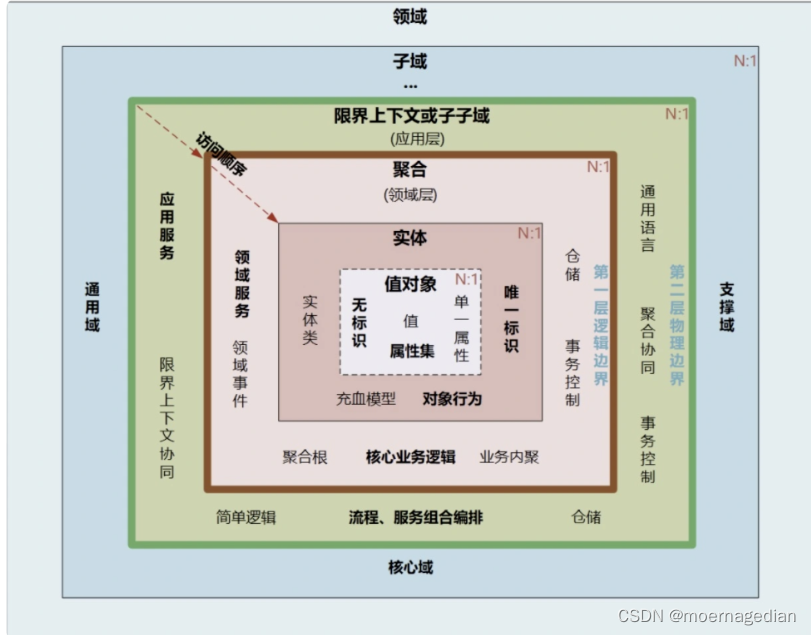
聚合
聚合:我们把一些关联性极强、生命周期一致的实体、值对象放到一个聚合里。
聚合有一个聚合根和上下文边界,这个边界根据业务单一职责和高内聚原则,定义了聚合内部应该包含哪些实体和值对象,而聚合之间的边界是松耦合的。
同一个聚合的 A 和 B 两个实体来共同完成,我们就可以将这段业务逻辑用领域服务来实现;
聚合 C 和聚合 D 中的两个服务共同完成,这时你就可以用应用服务来组合这两个服务。
聚合根
聚合根也称为根实体,它不仅是实体,还是聚合的管理者。
- 首先它作为实体本身,拥有实体的属性和业务行为,实现自身的业务逻辑。
- 其次它作为聚合的管理者,在聚合内部负责协调实体和值对象按照固定的业务规则协同完成共同的业务逻辑。
- 最后在聚合之间,它还是聚合对外的接口人,以聚合根 ID 关联的方式接受外部任务和请求,在上下文内实现聚合之间的业务协同。也就是说,聚合之间通过聚合根 ID 关联引用,如果需要访问其它聚合的实体,就要先访问聚合根,再导航到聚合内部实体,外部对象不能直接访问聚合内实体。
在订单聚合中,Order类作为聚合根,负责管理订单的整体状态和操作。它包含了订单的基本信息(订单ID、订单日期、订单金额、配送地址),以及订单项(OrderItem)列表。
领域服务
当一些逻辑不属于某个实体时,可以把这些逻辑单独拿出来放到领域服务中,理想的情况是没有领域服务。
应用服务
应用层作为展现层与领域层的桥梁,是用来表达用例和用户故事的主要手段。
领域事件
领域事件是历史的记录,捕捉重要时刻的意图和任何相关上下文,通俗地来讲业务中由于某个领域对象的动作被触发会引发与之关联的另外的领域对象也受到影响。(提前了解领域命令是指的是动作还未发生,只能有一个命令的接收者)
仓储(基础服务层)
仓储介于领域模型和数据模型之间,主要用于聚合的持久化和检索。它隔离了领域模型和数据模型,以便我们关注于领域模型而不需要考虑如何进行持久化。
repository
- converter (可以简单理解为数据格式的转换)
- enums
- mapper
- po
- RootConig.java (配置相关,比如mybatis可以指定扫描的包)
// 不局限于mysql,可以是redis、es等
public interface OrderRepository {
void save(Order order);
Order findById(String orderId);
void delete(Order order);
// 其他查询方法根据具体需求添加
}