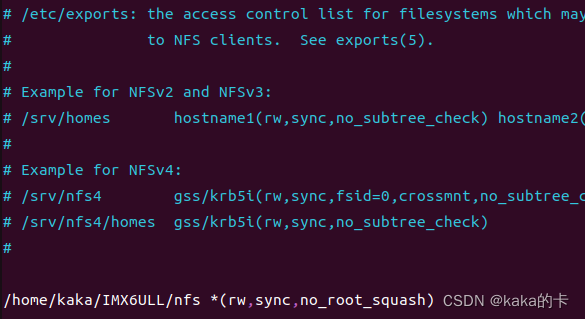
1. Hadoop序列化和反序列化及自定义bean对象实现序列化?
1) 序列化和反序列化的含义
序列化是将内存中的对象转换为字节序列,以便持久化和网络传输。
反序列化就是将字节序列或者是持久化数据转换成内存中的对象。
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息,不便于在网络中高效传输,所以hadoop开发了一套序列化机制(Writable)
2)自定义bean对象序列化传输步骤及注意事项
必须实现Writable接口
反序列化时, 需要反射调用空参构造函数,所以必须有空参构造
重写序列化方法
重写反序列化方法
注意反序列化的顺序和序列化的顺序完全一致
如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为mapreduce框中的shuffle过程一定会对key进行排序.
2. MapReduce的工作流程

MapReduce可以划分为四个阶段,分别为: Split, Map, Shuffle, Reduce。
- Split阶段: 主要负责“分”, 这个阶段MR会自动将一个大文件切分成多个block,这个split只是逻辑概念,并不是物理上的切片,仅包含每个block的起始位置,长度,所在位置等描述信息。每个block交由一个map task处理。
- Map阶段:映射阶段,处理经过split切分的数据片段,一个split对应一个map task,。每个计算节点将输入数据块作为输入,通过应用用户自定义的映射函数将其转换为一系列Key-Value。映射函数根据具体的应用逻辑来定义,可以执行过滤, 转换,提取等操作。
- Shuffle and Sort阶段:(合并与排序)(洗牌)
在映射阶段结束后,所有计算节点产生的Key-Value将被收集和排序。合并与排序阶段的目标是根据键值对进行排序,将相同键的值合并在一起。 - Reduce阶段:
归约阶段,计算节点将经过排序和合并的键值对进行处理。每个计算节点会根据用户定义的规约函数对具有相同键的值进行合并和计算。归约函数可以执行各种聚合操作,例如求和,计数, 平均值等。最终,计算节点会产生一组最终的输出键值对。
3. MR中的shuffle阶段的工作流程以及优化方式。

- 工作流程
- 分区(partition) :分区的目的是将具有相同键的键值对路由到同一个reducer,以便在reduce阶段进行处理。以便都是按照哈希算法分区。
- 排序(sort)
在每个分区内部,键值对会根据key进行排序。目的是将具有相同key的值聚在一起,以便在归约阶段进行合并操作。 - 合并(split)
在排序完成后,各分区的排序结果会被合并,生成全局有序的键值对序列。
- 优化方式
- 压缩,在shuffle阶段通过压缩中间数据可以不减少网络传输的数据量,减少网路带宽的使用。
- 增加combiner, 合并器可以在映射阶段输出键值对时执行一些局部的规约操作,减少数据传输量和磁盘IO。
4. MapReduce工作原理(Map Task 和Reduce Task 的工作机制)
MapTask:

- read: 从输入Inputsplit中解析出key/value
- map: 将解析出的key/value交给用户编写map()函数,并产生一系列的新key/value。
- collect: 调用Partitioner, 将生成的key/value分区。
- spill:溢写,当缓冲区占用达到阈值(80%)后,MR会将数据写到本地磁盘上,生成一个临时文件。注意: 将数据写入本地磁盘前,先要对数据进行一次本地排序,并在必要时对数据进行合并,压缩等操作。
- combine:当数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
ReduceTask

- copy: reduce Task从个map task上远程拷贝一片数据,如果该片数据大小超过一定阈值,写到磁盘上,否则写入内存。
- merge: 在远程copy数据的同时,reducetask启动两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
- sort: 目的是将key相同的数据聚在一起,由于各个map task已经实现对自己处理结果进行了局部排序,因此,reducetask 只需对所有数据进行一次归并排序。
- reduce: reduce()函数将计算结果写到hdfs上。
5. MapReduce有几种排序方式及排序发生的阶段
分类
- 部分排序
MapReduce根据输入记录的键对数据集排序,保证输出的每个文件内部排序。 - 全排序
首先创建一系列排好序的文件,其次,串联这些文件,最后,生成一个全局排序的文件。 - 辅助排序(GroupingComparator分组)
对键进行排序和分组以实现对值的排序。 - 二次排序
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
阶段 - 一个是在map 侧,发生在spill后partition前。
- 一个是在reduce 侧,发生在copy后 reduce前。
6. MR中的combiner的作用是什么?
- combiner的作用是对每一个maptask的输出进行局部汇总,以减小网络传输量
- combiner的输出kv要与reducer的输入kv类型对应。
- combiner和reducer的区别在于运行的位置:
- combiner是在每个map task的节点运行
- reducer是接收全局所有mapper的输出结果。
7. 如果没有定义partitioner,数据在被送达reducer前是如何被分区的
如果没有自定义的partitioning, 则默认的partition算法,根据每一条数据的key 的hashcode值模运算reducer的数量,得到分区号。(哈希取余)
8. MR不适合计算提速的场景
- 小文件
- 事务处理
- 只有一台机器
9. Hadoop的缓存机制(DistributedCache)
分布式缓存一个最重要的应用场景:map side join操作,一个表很大,另一个表很小。通过广播处理,每个计算节点上存一份小表,然后进行map端的连接操作。
广播处理运用到了分布式缓存的技术。分布式缓存机制会将需要的缓存的文件分发到各个执行任务的子节点的机器中,这样各个节点就可以自动读取本地文件系统上的数据进行处理。
10. 如何使用MR实现两个表的join?
- reduce side join : 在map 阶段, map函数同时读取两个文件file1 和 file2,为了区分两种来源的k/v数据对,对每条数据打一个标签(tag)。例:tag = 0 表示来自文件file 1, tag = 0表示来自文件file2.
- map side join: map side join针对以下场景进行的优化:两个待连接表中, 有一个表非常大,而另一个表非常小,以至于小表可以直接存入内存,并且将小表复制多份,让每个map task内存中存一份, 然后扫描大表:对于大表中的每一条记录 k/v,在内存中查找是否有相同的key的记录,如果有,则连接后输出即可。