文章目录
- 前言
- 一、二叉树剪枝
- 题目分析
- 思路分析
- 代码
- 二、序列化与反序列化二叉树
- 题目分析
- 思路分析
- 代码
- 三、从根节点到叶节点的路径数字之和
- 题目分析
- 思路分析
- 代码
- 四、 向下的路径节点之和
- 题目分析
- 思路分析
- 思路①代码
- 思路②代码
- 五、节点之和最大的路径
- 题目分析
- 思路分析
- 代码
- 六、展平二叉搜索树
- 题目分析
- 思路分析
- 迭代代码
- 七、二叉搜索树中的中序后继
- 题目分析
- 思路分析
- 思路①代码
- 思路②代码
- 八、所有大于等于节点的值之和
- 题目分析
- 思路分析
- 代码
- 九、二叉搜索树迭代器
- 题目分析
- 思路分析
- 思路①代码
- 思路②代码
- 十、二叉搜索树中两个节点之和
- 题目分析
- 思路分析
- 思路①代码
- 思路②代码
- 思路③代码
- 十一、 值和下标之差都在给定的范围内
- 题目分析
- 思路分析
- 思路①代码
- 思路②代码
- 十二、日程表
- 题目分析
- 思路分析
- 思路①代码
- 思路②代码
- 总结
前言
剑指offer专项突破版(力扣官网)——> 点击进入
本文所属专栏——>点击进入
多插几句:
考虑到有些小伙伴可能对二叉树的了解尚浅,我在这里就把二叉树的基础知识放在这里了,需要的可以点击进去 回顾或者预习一下。
二叉树经典习题
二叉树——理论篇
二叉树——顺序结构
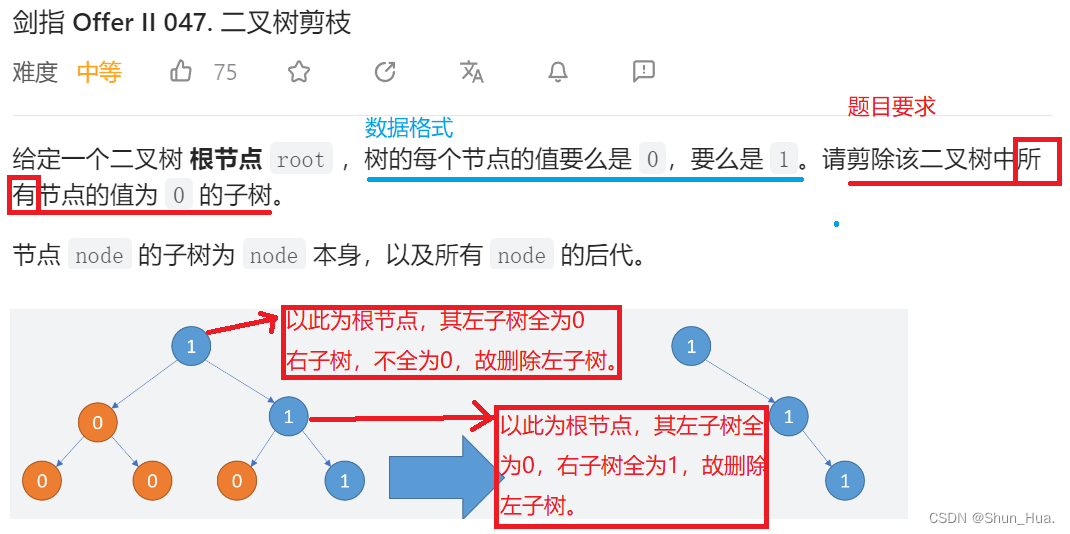
一、二叉树剪枝
题目分析
思路分析
此题的关键在于如何判断一个二叉树全为0?,我们可以采用递归的角度观察,如果左右子树为0,并且根节点为0——后序遍历,那么这颗树就必然全为0。那大方向确定了,还有一个小问题:如何剪枝呢?,从叶子结点往上剪,我们只需要将剪完之后的结果返回,用结果修改根结点的左右结点,然后再用剪完之后的结果结合根节点判断当前二叉树的情况是否全为0即可。
代码
typedef struct TreeNode TNode;
TNode* pruneTree(TNode* root)
{
if(root == NULL)
{
return NULL;
}
else
{
root->left = pruneTree(root->left);
root->right = pruneTree(root->right);
if((root->val == 0)&&(root->left)==NULL&&(root->right) == NULL)
{
return NULL;
}
}
return root;
}
二、序列化与反序列化二叉树
题目分析

思路分析
我们要解决的第一个大问题是:如何还原一颗树?,一个结点可以分为左结点,根和右结点。先有根节点才能指向其左右结点,因此我们可以采用前序遍历。那如何转换呢?比如:[1,2,3,null,null,4,5],那按照前序遍历,结果应该是这样:[12##34##5##],说明这里'#’就代指空指针,转换成这样我们也无从下手再转换为二叉树,因此我们需要在数据间加上标记,这里我的标记是,。
因此最终结果就是:[1,2,#,#,3,4,#,#,5,#,#,],这样就方便我们切割取数据了!
具体操作涉及三个库函数,如果手搓有点费时间,所以这里我就把这几个函数的用法列举下来方便大家参考。
①:数字转字符串。
sprintf(要存放的字符串的位置,要存放数据的格式,要存放的数据);
char buffer[20];
int n = 10;
sprintf(buffer,"%d",n);
意思为:将n以整形的形式格式化,再将格式化的数据放在buffer中。
②:字符串转数字
int ret = atoi(要转换的字符串);
ret = atoi("-100");
③:切割字符串
strtok(要切割的字符串,切割字符串的标记);
说明:在第一次需要传要切割的字符串,之后就无需再传要切割的字符串了,直接传空指针即可。
char mark[2] = ",";
char str[10] = "1,2,3,4,5";
for(char* stok = strtok(str,mark);stok != NULL;stok = strtok(NULL,mark));
{
printf("%s",stok);
}
另外为了将树转换为字符串,我们还需要顺序表,以便于及时的增容。
代码
typedef struct TreeNode TNode;
typedef struct SeqList
{
char* arr;
int size;
int capacity;
}SeqList;
void Init(SeqList* seq)
{
seq->arr = NULL;
seq->size = 0;
seq->capacity = 0;
}
void CheckCapacity(SeqList* seq)
{
if(seq->capacity == seq->size)
{
int capacity = seq->capacity == 0 ? 4 : (seq->capacity)*2;
seq->arr = (char*)realloc(seq->arr,sizeof(char)*capacity);
seq->capacity = capacity;
}
}
void PushBack(SeqList* seq,char* nums)
{
char* str = nums;
while((*str)!='\0')
{
CheckCapacity(seq);
(seq->arr)[(seq->size)++] = *str;
str++;
}
CheckCapacity(seq);
(seq->arr)[(seq->size)] = 0;
}
void PreOrder(SeqList* seq,TNode* root,char* buffer)
{
if(root == NULL)
{
PushBack(seq,"#,");
}
else
{
sprintf(buffer,"%d",root->val);
PushBack(seq,buffer);
PushBack(seq,",");
PreOrder(seq,root->left,buffer);
PreOrder(seq,root->right,buffer);
}
}
char* serialize(struct TreeNode* root)
{
char buffer[20];
SeqList seq;
Init(&seq);
PreOrder(&seq,root,buffer);
return seq.arr;
}
/** Decodes your encoded data to tree. */
TNode* BuyNode(int val)
{
TNode* NewNode = (TNode*)malloc(sizeof(TNode));
NewNode->left = NULL;
NewNode->right = NULL;
NewNode->val = val;
return NewNode;
}
TNode* deser (char* data,char* mark,char* str)
{
if(str == NULL)
{
return NULL;
}
else
{
TNode* root = NULL;
if(*str != '#')
{
int num = atoi(str);
root = BuyNode(num);
str = strtok(NULL,mark);
root->left = deser(data,mark,str);
str = strtok(NULL,mark);
root->right = deser(data,mark,str);
}
return root;
}
}
struct TreeNode* deserialize(char* data)
{
printf("%s",data);
char mark[2] = ",";
char* str = strtok(data,mark);
TNode *root = deser(data,mark,str);
return root;
}
三、从根节点到叶节点的路径数字之和
题目分析

思路分析
此题是计算从根结点到叶子结点所有数字之和,我们只需在遍历到根节点时对当前数字×10 + 当前节点的值,然后判断是否是叶子结点,是,就对和加上目前所求的和即可,否则就继续往下遍历。很显然我们是先算根节点,因此我们采用的是前序遍历。
代码
typedef struct TreeNode TNode;
void PreOrder(TNode* root,int count,int* sum)
{
if(root == NULL)
{
return;
}
count = count*10 + root->val;
if(root->left == NULL && root->right == NULL)
{
(*sum)+=count;
return;
}
PreOrder(root->left,count,sum);
PreOrder(root->right,count,sum);
}
int sumNumbers(TNode* root)
{
int sum = 0;
PreOrder(root,0,&sum);
return sum;
}
四、 向下的路径节点之和
题目分析

思路分析
①:直接遍历,以所有的结点为起点,当做根节点,分别进行向下遍历所有路径,如果与目标值相等就将总路径数加1。
②:前缀和——我们之前在数组篇——和为K的子数组用过前缀和的知识,主要采用了哈希的数据结构,本题与那道题的用法几乎一样,这样我们不用将所有的情况都要遍历一遍,我们求和等于sum,只需要求当前的和与sum相减,在哈希表是否存在即可。
特殊的情况,比如对于根节点来说,如果路径和等于sum,则当前和与sum相减等于0,因此我们要在哈希表中放上一个0结点,还有在进行路径遍历时,为了防止路径复用的情况,因此当遍历当前路径之后,我们需要将哈希表的此路径的值进行删除。
关于C语言哈希表的知识我就放在这了:
哈希表——C语言
点击即可进入
思路①代码
//要想存在此路径,必须以每一个结点为起点进行走
typedef struct TreeNode TNode;
void Check(TNode* root,long long count, int targetSum,int* sum)
{
if(root == NULL)
{
return;
}
else
{
count+=(root->val);
if(count == targetSum)
{
(*sum)++;
}
Check(root->left,count,targetSum,sum);
Check(root->right,count,targetSum,sum);
}
}
void PreOrder(TNode* root,int* sum, int targetSum)
{
if(root == NULL)
{
return;
}
else
{
Check(root,0,targetSum,sum);
PreOrder(root->left,sum,targetSum);
PreOrder(root->right,sum,targetSum);
}
}
int pathSum(struct TreeNode* root, int targetSum)
{
int sum = 0;
PreOrder(root,&sum,targetSum);
return sum;
}
思路②代码
typedef struct Hash
{
long long key;
int val;
UT_hash_handle hh;
}Hash;
int find(Hash** head, long long key)
{
Hash* ret = NULL;
printf("%lld ",key);
HASH_FIND(hh,*head,&key,sizeof(key),ret);
if(ret != NULL)
{
return ret->val;
}
return 0;
}
void put(Hash **head,long long key)
{
Hash* ret = NULL;
HASH_FIND(hh,*head,&key,sizeof(key),ret);
if(ret == NULL)
{
ret = (Hash*)malloc(sizeof(Hash));
ret->key = key;
ret->val = 1;
HASH_ADD(hh,*head,key,sizeof(key),ret);
}
else
{
(ret->val)++;
}
}
void Del(Hash** head,long long key)
{
Hash* ret = NULL;
HASH_FIND(hh,*head,&key,sizeof(key),ret);
if(ret != NULL)
{
(ret->val)--;
}
}
typedef struct TreeNode TNode;
int PreOrder(Hash** head,TNode* root,long long sum, int targetSum)
{
//说明:这里的sum的和可能会超过int的最大值或者最小值,因此需要long long
//与此同时key作为键值也得是long long类型的。
if(root == NULL)
{
return 0;
}
else
{
sum+=(root->val);
int count = find(head,sum-targetSum);
put(head,sum);
count+=(PreOrder(head,root->left,sum,targetSum));
count+=(PreOrder(head,root->right,sum,targetSum));
//返回根节点,以防别的路径重复使用此路径我们需要将此删除一下
Del(head,sum);
return count;
}
}
int pathSum(struct TreeNode* root, int targetSum)
{
Hash* head = NULL;
put(&head,0);
//根节点的路径和等于targetSum,那根节点的路径和-targetSum等于0
//因此这里需要放一个0.
return PreOrder(&head,root,0,targetSum);
}
五、节点之和最大的路径
题目分析

思路分析
问题的关键在于求根节点的路径和,问题接着就转换为求左右的最大路径,同时还得求左右的最大路径和,那要怎么办呢?返回当前的最大路径(得大于0才能求当前节点的最大路径和),同时用指针做参数,求出左右的最大路径和。
代码
#define MIN -1001
typedef struct TreeNode TNode;
int PostOrder(TNode* root,int *max)
{
if(root == NULL)
{
return 0;
}
else
{
//首先返回值为当前一边路径的最大值。
int lmax = MIN;
int lpath = PostOrder(root->left,&lmax);
//返回值如果小于0,则直接当做0即可,因为我们求的是最大的路径和。
lpath = lpath < 0 ? 0 : lpath;
int rmax = MIN;
int rpath = PostOrder(root->right,&rmax);
rpath = rpath < 0 ? 0 : rpath;
//求出根节点的路径和,即左右路径相加,再加上根节点的值
int sum_path = lpath + rpath + root->val;
//求出左右路径的较大值
int bigger_path = lpath > rpath ? lpath : rpath;
//求出左右路径和的较大值
int bigger_sum_path = lmax > rmax ? lmax : rmax;
//求出最终的最大路径
sum_path = bigger_sum_path > sum_path ? bigger_sum_path : sum_path;
//看是否要进行修改
*max = *max > sum_path ? *max : sum_path;
//返回左右路径的较大值加上根节点的值
return bigger_path + root->val;
}
}
int maxPathSum(struct TreeNode* root)
{
int max = MIN;
PostOrder(root,&max);
return max;
}
六、展平二叉搜索树
题目分析

补充:二叉树搜索数的定义——左子树的结点小于根节点,右子树的结点大于根节点。
思路分析
很明显是中序遍历,那问题就出现了,是递归还是迭代?如果是递归,我们得保存一下结点的值,也就是说,得开辟一个顺序表存放这些结点,然后对这些结点进行修改,即不断地让左结点指向NULL,右结点指向顺序表的下一个结点。如果是迭代,那就得用栈的数据结构,不断地进行存储,然后取出栈顶的元素,上一次栈顶的元素如果保存其不为空,就将上一次保存的结点指向当前元素的结点,同时修改当前的结点——左节点置为空,再更新上一次保存的结点为当前节点,进行下一次循环,当栈为空同时当前节点为空时停止循环。
迭代代码
typedef struct TreeNode TNode;
typedef struct Stack
{
TNode** arr;
int size;
int capacity;
}Stack;
void Init(Stack* stack)
{
stack->arr = NULL;
stack->size = 0;
stack->capacity = 0;
}
void Push(Stack* stack, TNode* val)
{
if(stack->size == stack->capacity)
{
int capacity = stack->capacity == 0 ? 4 : \
(stack->capacity)*2;
stack->arr = (TNode**)realloc\
(stack->arr,sizeof(TNode*)*capacity);
stack->capacity = capacity;
}
(stack->arr)[(stack->size)++] = val;
}
TNode* Pop(Stack* stack)
{
if(stack->size > 0)
{
return (stack->arr)[--(stack->size)];
}
else
{
return NULL;
}
}
bool is_empty(Stack* stack)
{
if(stack->size == 0)
{
return true;
}
return false;
}
struct TreeNode* increasingBST(struct TreeNode* root)
{
Stack stack;
Init(&stack);
TNode* cur = root;
TNode* prev = NULL;
TNode* first = NULL;
while(cur != NULL || !is_empty(&stack))
{
//将左边的元素都入栈
while(cur != NULL)
{
Push(&stack,cur);
cur = cur->left;
}
//获取最左边的元素
cur = Pop(&stack);
if(prev == NULL)
{
//说明是cur是最左边的元素
first = cur;
}
else
{
prev->right = cur;
}
prev = cur;
//左边入完,入右边
cur->left = NULL;
cur = cur->right;
}
return first;
}
七、二叉搜索树中的中序后继
题目分析

思路分析
很明显跟上一题的思路一样,这里使用迭代,如果等于指定节点我们保存一下,当下一次循环此节点等于指定节点,我们就返回当前的栈顶节点即可,如果没有我们就返回空节点。
还有一种思路,就是指定节点的下一个结点是大于指定结点的所有节点中最小的结点。利用这一点我们即可利用二叉搜索树的性质进行查找。
思路①代码
typedef struct TreeNode TNode;
typedef struct Stack
{
TNode** arr;
int size;
int capacity;
}Stack;
void Init(Stack* stack)
{
stack->arr = NULL;
stack->size = 0;
stack->capacity = 0;
}
void Push(Stack* stack, TNode* val)
{
if(stack->size == stack->capacity)
{
int capacity = stack->capacity == 0 ? 4 : \
(stack->capacity)*2;
stack->arr = (TNode**)realloc\
(stack->arr,sizeof(TNode*)*capacity);
stack->capacity = capacity;
}
(stack->arr)[(stack->size)++] = val;
}
TNode* Pop(Stack* stack)
{
if(stack->size > 0)
{
return (stack->arr)[--(stack->size)];
}
else
{
return NULL;
}
}
bool is_empty(Stack* stack)
{
if(stack->size == 0)
{
return true;
}
return false;
}
void Stack_free(Stack* stack)
{
free(stack->arr);
}
struct TreeNode* inorderSuccessor(struct TreeNode* root\
, struct TreeNode* p)
{
Stack stack;
Init(&stack);
TNode* cur = root;
TNode* prev = NULL;
while(cur || !is_empty(&stack))
{
while(cur)
{
Push(&stack,cur);
cur = cur->left;
}
cur = Pop(&stack);
if(cur == p)
{
prev = cur;
}
else if(prev != NULL)
{
Stack_free(&stack);
return cur;
}
cur = cur->right;
}
return NULL;
}
思路②代码
//当前节点的值比目标值大时,我们需要保存一下当前节点的值,同时让当前节点变小,
//看是否存在下一个可能的节点
//当前节点的值比目标值小时,我们需要让其变大,看是否有可能的结点比目标值大。
//循环结束的条件为当找不到比目标值大的结点或者找不到结点,即结点值为空
typedef struct TreeNode TNode;
struct TreeNode* inorderSuccessor(TNode* root, TNode* p)
{
TNode* cur = root;
TNode* ret = NULL;//当找不到时,即为空
while(cur)
{
if(cur->val > p->val)
{
ret = cur;//保存可能是要找的结点
cur = cur->left;
}
else
{
cur = cur->right;
}
}
return ret;
}
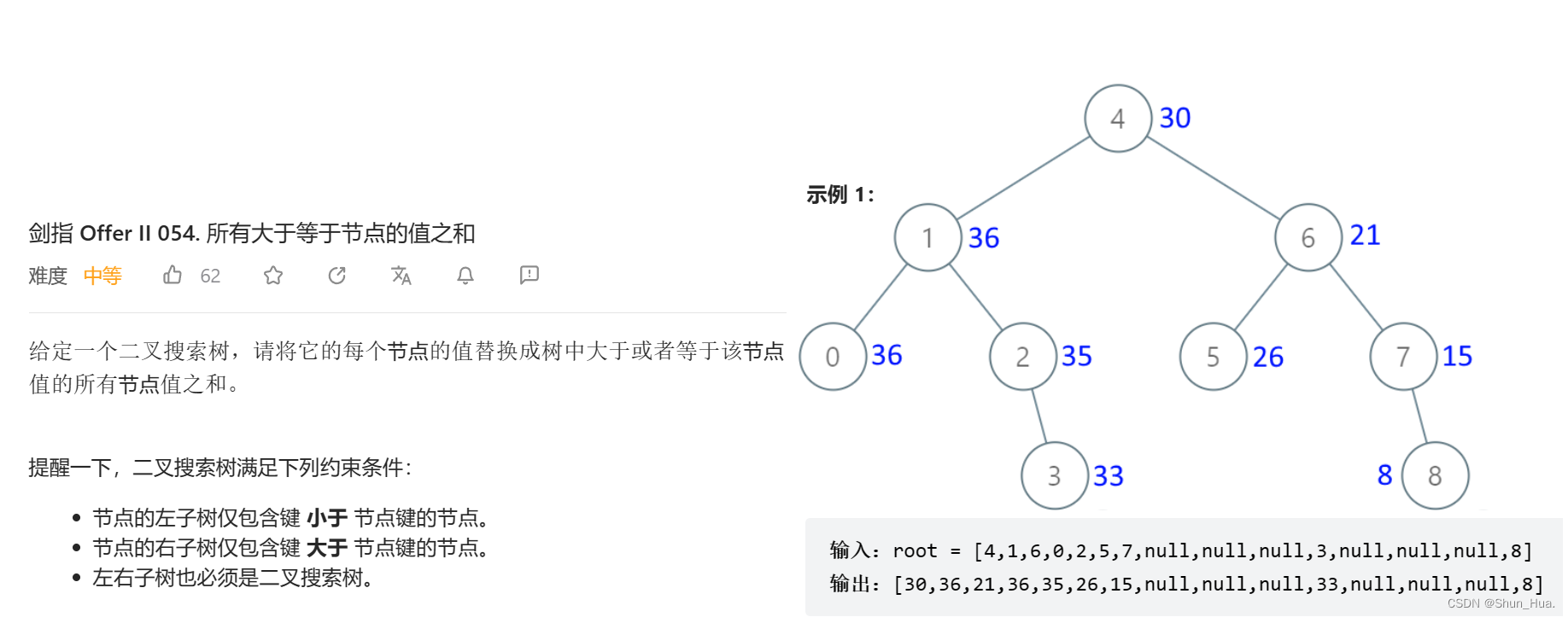
八、所有大于等于节点的值之和
题目分析
思路分析
跟前两道题的迭代思路一样,不过这里是中序遍历的灵活变通,先遍历右子树再遍历根再遍历左子树,同时记录目前结点累加的和,并赋值给当前的结点即可。
代码
//题目分析
//先遍历右子树,再遍历根,再遍历左子树
//在遍历的同时,计算sum,再更新此节点的值即可
typedef struct TreeNode TNode;
typedef struct Stack
{
TNode** arr;
int size;
int capacity;
}Stack;
void Init(Stack* stack)
{
stack->arr = NULL;
stack->size = 0;
stack->capacity = 0;
}
void Push(Stack* stack, TNode* val)
{
if(stack->size == stack->capacity)
{
int capacity = stack->capacity == 0 ? 4 : \
(stack->capacity)*2;
stack->arr = (TNode**)realloc\
(stack->arr,sizeof(TNode*)*capacity);
stack->capacity = capacity;
}
(stack->arr)[(stack->size)++] = val;
}
TNode* Pop(Stack* stack)
{
if(stack->size > 0)
{
return (stack->arr)[--(stack->size)];
}
else
{
return NULL;
}
}
bool is_empty(Stack* stack)
{
if(stack->size == 0)
{
return true;
}
return false;
}
void Stack_free(Stack* stack)
{
free(stack->arr);
}
struct TreeNode* convertBST(struct TreeNode* root)
{
Stack stack;
Init(&stack);
TNode* cur = root;
int sum = 0;
while(cur || !is_empty(&stack))
{
while(cur)
{
Push(&stack,cur);
cur = cur->right;
}
cur = Pop(&stack);
sum+=(cur->val);
cur->val = sum;
cur = cur->left;
}
return root;
}
九、二叉搜索树迭代器
题目分析
思路分析
既然是中序遍历,既可以采用迭代,进行遍历时,将节点存放在顺序表中,当调用下一个结点时,根据下标一个一个访问即可,也可以采用迭代,利用栈的数据结构,节点初始化为根节点,不断将左节点入栈,直到当前节点为空再出栈,同时保存一下当前节点的右节点,最后返回当前节点即可,之后的不断的调用保存的节点,重复此过程即可。
思路①代码
typedef struct TreeNode TNode;
typedef struct Stack
{
TNode** arr;
int size;
int capacity;
}Stack;
void Init(Stack* stack)
{
stack->arr = NULL;
stack->size = 0;
stack->capacity = 0;
}
void Push(Stack* stack, TNode* val)
{
if(stack->size == stack->capacity)
{
int capacity = stack->capacity == 0 ? 4 : \
(stack->capacity)*2;
stack->arr = (TNode**)realloc\
(stack->arr,sizeof(TNode*)*capacity);
stack->capacity = capacity;
}
(stack->arr)[(stack->size)++] = val;
}
TNode* Pop(Stack* stack)
{
if(stack->size > 0)
{
return (stack->arr)[--(stack->size)];
}
else
{
return NULL;
}
}
bool is_empty(Stack* stack)
{
if(stack->size == 0)
{
return true;
}
return false;
}
void Stack_free(Stack* stack)
{
free(stack->arr);
}
typedef struct
{
Stack stack;
int size;
}BSTIterator;
void MidOreder(TNode* root,BSTIterator* obj)
{
if(root == NULL)
{
return;
}
else
{
MidOreder(root->left,obj);
Push(&(obj->stack),root);
MidOreder(root->right,obj);
}
}
BSTIterator* bSTIteratorCreate(struct TreeNode* root)
{
BSTIterator* init = (BSTIterator*)malloc\
(sizeof(BSTIterator));
Init(&(init->stack));
init->size = 0;
TNode* cur = root;
MidOreder(root,init);
return init;
}
int bSTIteratorNext(BSTIterator* obj)
{
Stack* st = &(obj->stack);
return ((st->arr)[(obj->size)++])->val;
}
bool bSTIteratorHasNext(BSTIterator* obj)
{
Stack* st = &(obj->stack);
if(st->size == obj->size)
{
return false;
}
else
{
return true;
}
}
void bSTIteratorFree(BSTIterator* obj)
{
Stack_free(&(obj->stack));
free(obj);
}
思路②代码
typedef struct TreeNode TNode;
typedef struct Stack
{
TNode** arr;
int size;
int capacity;
}Stack;
void Init(Stack* stack)
{
stack->arr = NULL;
stack->size = 0;
stack->capacity = 0;
}
void Push(Stack* stack, TNode* val)
{
if(stack->size == stack->capacity)
{
int capacity = stack->capacity == 0 ? 4 : \
(stack->capacity)*2;
stack->arr = (TNode**)realloc\
(stack->arr,sizeof(TNode*)*capacity);
stack->capacity = capacity;
}
(stack->arr)[(stack->size)++] = val;
}
TNode* Pop(Stack* stack)
{
if(stack->size > 0)
{
return (stack->arr)[--(stack->size)];
}
else
{
return NULL;
}
}
bool is_empty(Stack* stack)
{
if(stack->size == 0)
{
return true;
}
return false;
}
void Stack_free(Stack* stack)
{
free(stack->arr);
}
typedef struct
{
TNode* cur;//这是需要保存的结点
Stack stack;
}BSTIterator;
BSTIterator* bSTIteratorCreate(struct TreeNode* root)
{
BSTIterator* init = (BSTIterator*)malloc(sizeof(BSTIterator));
Init(&(init->stack));
init->cur= root;//最开始cur被初始化根节点
return init;
}
int bSTIteratorNext(BSTIterator* obj)
{
while(obj->cur)
{
Push(&(obj->stack),obj->cur);
obj->cur = (obj->cur)->left;
}
TNode* next = Pop(&(obj->stack));
obj->cur = next->right;//更新保存的结点
return next->val;
}
bool bSTIteratorHasNext(BSTIterator* obj)
{
return (!is_empty(&(obj->stack))) || ((obj->cur) != NULL);
}
void bSTIteratorFree(BSTIterator* obj)
{
Stack_free(&(obj->stack));
free(obj);
}
十、二叉搜索树中两个节点之和
题目分析
思路分析
很显然二叉树的中序遍历是升序,因此我们可以中序遍历保存结点的值,然后利用遍历后的数组再结合我们之前数组篇——排序数组中两个数字的和,就有两种思路(二分和双指针)。
我们也可以这样用双指针,利用第九题的二叉搜索迭代器(写两份),一份是从左子树的中序遍历,一份是右子树的中序遍历,这样小的话迭代左子树,大的话迭代右子树,直到有和为k或遍历的值相等为止。
思路①代码
typedef struct TreeNode TNode;
typedef struct Stack
{
int* arr;
int size;
int capacity;
}Stack;
void Init(Stack* stack)
{
stack->arr = NULL;
stack->size = 0;
stack->capacity = 0;
}
void Push(Stack* stack, int val)
{
if(stack->size == stack->capacity)
{
int capacity = stack->capacity == 0 ? 4 : \
(stack->capacity)*2;
stack->arr = (int*)realloc(stack->arr,sizeof(int)*capacity);
stack->capacity = capacity;
}
(stack->arr)[(stack->size)++] = val;
}
TNode* Pop(Stack* stack)
{
if(stack->size > 0)
{
return (stack->arr)[--(stack->size)];
}
else
{
return NULL;
}
}
bool is_empty(Stack* stack)
{
if(stack->size == 0)
{
return true;
}
return false;
}
void Stack_free(Stack* stack)
{
free(stack->arr);
}
void MidOreder(TNode* root,Stack* obj)
{
if(root == NULL)
{
return;
}
else
{
MidOreder(root->left,obj);
Push(obj,root->val);
MidOreder(root->right,obj);
}
}
//题目分析
//转换成升序数组的问题
bool findTarget(struct TreeNode* root, int k)
{
Stack stack;
Init(&stack);
MidOreder(root,&stack);
int *arr = stack.arr;
int size = stack.size;
for(int i = 0; i < size; i++)
{
int n = arr[i];
int target = k - n;
int left = i+1;
int right = size-1;
int mid = (left + right)/2;
while(left <= right)
{
if(arr[mid] < target)
{
left = mid + 1;
mid = (left+right)/2;
}
else if(arr[mid] > target)
{
right = mid - 1;
mid = (left+right)/2;
}
else
{
return true;
}
}
}
return false;
}
思路②代码
//省去的代码跟思路①的代码一样,这里就省去了。
bool findTarget(struct TreeNode* root, int k)
{
Stack stack;
Init(&stack);
MidOreder(root,&stack);
int *arr = stack.arr;
int size = stack.size;
int left = 0;
int right = size-1;
while(left < right)
{
if(arr[left]+arr[right] > k)
{
right--;
}
else if(arr[left] + arr[right] < k)
{
left++;
}
else
{
return true;
}
}
return false;
}
思路③代码
#define ERRO 10001
//说明一下根据力扣数据的范围进行取得特殊数据可以表明特殊意义
typedef struct TreeNode TNode;
typedef struct Stack
{
TNode** arr;
int size;
int capacity;
}Stack;
void Init(Stack* stack)
{
stack->arr = NULL;
stack->size = 0;
stack->capacity = 0;
}
void Push(Stack* stack, TNode* val)
{
if(stack->size == stack->capacity)
{
int capacity = stack->capacity == 0 ? 4 : \
(stack->capacity)*2;
stack->arr = (TNode**)realloc\
(stack->arr,sizeof(TNode*)*capacity);
stack->capacity = capacity;
}
(stack->arr)[(stack->size)++] = val;
}
TNode* Pop(Stack* stack)
{
if(stack->size > 0)
{
return (stack->arr)[--(stack->size)];
}
else
{
return NULL;
}
}
bool is_empty(Stack* stack)
{
if(stack->size == 0)
{
return true;
}
return false;
}
void Stack_free(Stack* stack)
{
free(stack->arr);
}
typedef struct
{
TNode* cur;
Stack stack;
}LBSTIterator;
LBSTIterator* LbSTIteratorCreate(struct TreeNode* root)
{
LBSTIterator* init = (LBSTIterator*)malloc\
(sizeof(LBSTIterator));
Init(&(init->stack));
init->cur= root;
return init;
}
int LbSTIteratorNext(LBSTIterator* obj)
{
while(obj->cur)
{
Push(&(obj->stack),obj->cur);
obj->cur = (obj->cur)->left;
}
TNode* next = Pop(&(obj->stack));
if(next != NULL)
{
obj->cur = next->right;
return next->val;
}
return ERRO;
}
bool LbSTIteratorHasNext(LBSTIterator* obj)
{
return (!is_empty(&(obj->stack))) || ((obj->cur) != NULL);
}
void LbSTIteratorFree(LBSTIterator* obj)
{
Stack_free(&(obj->stack));
free(obj);
}
typedef struct
{
TNode* cur;
Stack stack;
}RBSTIterator;
RBSTIterator* RbSTIteratorCreate(struct TreeNode* root)
{
RBSTIterator* init = (RBSTIterator*)malloc\
(sizeof(RBSTIterator));
Init(&(init->stack));
init->cur= root;
return init;
}
int RbSTIteratorNext(RBSTIterator* obj)
{
while(obj->cur)
{
Push(&(obj->stack),obj->cur);
obj->cur = (obj->cur)->right;
}
TNode* next = Pop(&(obj->stack));
if(next != NULL)
{
obj->cur = next->left;
return next->val;
}
return ERRO;
}
bool RbSTIteratorHasNext(RBSTIterator* obj)
{
return (!is_empty(&(obj->stack))) || ((obj->cur) != NULL);
}
void RbSTIteratorFree(RBSTIterator* obj)
{
Stack_free(&(obj->stack));
free(obj);
}
bool findTarget(struct TreeNode* root, int k)
{
LBSTIterator* prev = LbSTIteratorCreate(root);
RBSTIterator* next = RbSTIteratorCreate(root);
int left = LbSTIteratorNext(prev);
int right = RbSTIteratorNext(next);
while(left != right)
{
if(left + right == k)
{
return true;
}
if(left + right > k)
{
right = RbSTIteratorNext(next);
if(right == ERRO)
{
break;
}
}
if(left + right < k)
{
left = LbSTIteratorNext(prev);
if(left == ERRO)
{
break;
}
}
}
return false;
}
十一、 值和下标之差都在给定的范围内
题目分析
思路分析
①:暴力求解,调整k——间隔,不断地遍历数组,直到找到为止。
②:桶排序,因为两个数若满足相减的绝对值小于等于t,即相差在[0,t]——t+1个数,这样把数分为[0,t] ,[t+1,2t +2],[2t +3, 3*t + 4 ]……这些组,再对这些组进行编号,若对在其范围的数除(t+1),即为分为0,1,2,3……,若为负数,比如[- t - 1, -1]则为-1,如何算呢? 设在此范围的数为x,则编号即为(x+1)/(t+1) -1 。那还有个问题如何调整或者说固定间隔呢?当遍历到下标大于k的,我们就丢弃左边的数据,存放右边的数据。
思路①代码
bool containsNearbyAlmostDuplicate(int* nums, int numsSize, int k\
, int t)
{
long long sub = 0;
int sut = 0;
for(int i = 1; i <= k; i++)
{
int gap = i;
int cur = 0;
while(cur + gap < numsSize)
{
sub = nums[cur+gap] - (long long)nums[cur];
if(sub < 0)
{
sub = -sub;
}
if(sub <= t)
{
return true;
}
cur++;
}
}
return false;
}
思路②代码
typedef struct Hash
{
int val;
int key;
UT_hash_handle hh;
}HNode;
HNode* find(HNode* head,int key)
{
HNode* ret = NULL;
HASH_FIND_INT(head,&key,ret);
return ret;
}
int GetID(int num,long long bucketsize)
{
return num >= 0 ? num/bucketsize : (num-1ll)/bucketsize - 1;
}
bool containsNearbyAlmostDuplicate(int* nums, int numsSize, int k\
, int t)
{
HNode* head = NULL;
for(int i = 0; i < numsSize; i++)
{
int id = GetID(nums[i],t+1ll);
HNode* ret = find(head,id);
if(ret != NULL)
{
return true;
}
else
{
int key = id;
ret = (HNode*)malloc(sizeof(HNode));
ret->val = nums[i];
ret->key = key;
HASH_ADD_INT(head,key,ret);
HNode* ret = find(head,key);
}
ret = find(head,id-1);
if((ret != NULL) && (fabs((long long)ret->val - nums[i]) \
<= t))
{
return true;
}
ret = find(head,id+1);
if(ret != NULL && (fabs((long long)ret->val - nums[i])<=t))
{
return true;
}
if(i >= k)//固定间隔k
{
int del_id = GetID(nums[i-k],t+1ll);
ret = NULL;
HASH_FIND_INT(head,&del_id,ret);
HASH_DEL(head,ret);
free(ret);
}
}
return false;
}
十二、日程表
题目分析

思路分析
- 暴力解法 :遍历当前日程如果存在冲突的就返回false,否则返回true。
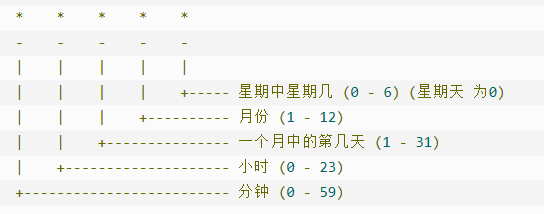
- 线段树解法:日程进行分区间,最大不超过109 (看数据格式),因此我们如果区间安排没有日程,则更新此区间有日程,若区间内有日程我们就直接返回false即可。具体的做法涉及哈希表和线段树的知识。
博主就是看这篇文章——线段树入门的。
思路①代码
typedef struct TreeNode TNode;
typedef struct Stack
{
int* start;
int* end;
int size;
int capacity;
}MyCalendar;
void Init(MyCalendar* stack)
{
stack->start = NULL;
stack->end = NULL;
stack->size = 0;
stack->capacity = 0;
}
void Push(MyCalendar* stack, int begin, int end)
{
if(stack->size == stack->capacity)
{
int capacity = stack->capacity == 0 ? 4 : \
(stack->capacity)*2;
stack->start = (int*)realloc\
(stack->start,sizeof(int)*capacity);
stack->end= (int*)realloc(stack->end,sizeof(int)*capacity);
stack->capacity = capacity;
}
(stack->start)[(stack->size)] = begin;
(stack->end)[(stack->size)] = end;
++(stack->size);
}
void Stack_free(MyCalendar* stack)
{
free(stack->start);
free(stack->end);
}
MyCalendar* myCalendarCreate()
{
MyCalendar* stack = (MyCalendar*)malloc(sizeof(MyCalendar));
Init(stack);
return stack;
}
bool myCalendarBook(MyCalendar* obj, int start, int end)
{
int* begin = obj->start;
int* end1 = obj->end;
int size = obj->size;
for(int i = 0; i < size; i++)
{
int left = begin[i];
int right = end1[i];
if(end > left && start < right)
{
return false;
}
}
Push(obj,start,end);
return true;
}
void myCalendarFree(MyCalendar* obj)
{
Stack_free(obj);
}
思路②代码
typedef struct Hash
{
int key;
bool Include;
bool All_Book;
UT_hash_handle hh;
}HTNode;
typedef struct
{
HTNode * tree;
} MyCalendar;
bool Is_Reserve(MyCalendar* obj,int start, int end ,int left\
,int right,int key)
{
//这里设为闭区间
//当start与end区间和left与right区间没有交集时,为假
if(start > right || end < left)
{
return false;
}
//看当前区间是否被预定
HTNode* ret = NULL;
HASH_FIND_INT(obj->tree,&key,ret);
if(ret&&ret->All_Book)
{
return true;
}
//当start与end区间包含left与right区间
if(start <=left && end>=right)
{
//看是否区间内有预定的部分
if(ret)
{
return ret->Include;
}
else
{
return false;
}
}//当存在交集的时候
else
{
int mid = (left+right)/2;
//分析end与mid的关系
if(end <= mid)
{
//说明在left与right区间的左半段
return Is_Reserve(obj,start,end,left,mid,2*key);
}
//分析start与mid的关系
else if(start > mid)
{
//说明在left与right区间的右半段
return Is_Reserve(obj,start,end,mid+1,right,2*key+1);
}
else
{
//此时mid在start与end的中间,因此可能都要进行分析
return Is_Reserve(obj,start,end,left,mid,2*key)||\
Is_Reserve(obj,start,end,mid+1,right,2*key+1);
}
}
}
void update(MyCalendar* obj,int start, int end ,int left,int right\
,int key)
{
//如果无交集
if(start > right || end < left)
{
return;
}
//如果[start,end]包含[left,right]
if(start<=left && end>=right)
{
HTNode* ret = NULL;
HASH_FIND_INT(obj->tree,&key,ret);
//先判断是否为空
if(ret == NULL)
{
ret = (HTNode*)malloc(sizeof(HTNode));
ret->key = key;
HASH_ADD_INT(obj->tree,key,ret);
//进行初始化
}
ret->Include = true;
ret->All_Book = true;
}
else
{
//[start,end]与[left,right]出现有交集的情况
int mid = (left+right)/2;
//左边右边都要进行遍历,更新线段树
update(obj,start,end,left,mid,2*key);
update(obj,start,end,mid+1,right,2*key+1);
//到这里[left,right]包含[start,end]
HTNode* ret = NULL;
HASH_FIND_INT(obj->tree,&key,ret);
if(ret == NULL)
{
ret = (HTNode*)malloc(sizeof(HTNode));
ret->key = key;
HASH_ADD_INT(obj->tree,key,ret);
}
//进行初始化
ret->Include = true;//[left,right]包含[start,end]
ret->All_Book = false;//不一定[left,right]等于[start,end]
HTNode* lchild = NULL;
HTNode* rchild = NULL;
int lkey = 2*key;
int rkey = 2*key+1;
HASH_FIND_INT(obj->tree,&lkey,lchild);
HASH_FIND_INT(obj->tree,&rkey,rchild);
if(lchild && lchild->All_Book && rchild && rchild->All_Book)
{
ret->All_Book = true;
}
}
}
MyCalendar* myCalendarCreate()
{
MyCalendar* init = (MyCalendar*)malloc(sizeof(MyCalendar));
init->tree = NULL;
return init;
}
bool myCalendarBook(MyCalendar* obj, int start, int end)
{
if(Is_Reserve(obj,start,end-1,0,1e9,1))
{
return false;
}
update(obj,start,end-1,0,1e9,1);
return true;
}
void myCalendarFree(MyCalendar* obj)
{
HTNode* head = obj->tree;
HTNode* cur = head,*next = NULL;
HASH_ITER(hh,head,cur,next)
{
HASH_DEL(head,cur);
free(cur);
}
free(obj);
}
总结
本篇主要涉及二叉树和完全二叉树的知识,主要为二叉树的中序遍历,前序遍历,以及涉及一点点的哈希和前缀和以及线段树的知识。
今天的分享就到这里了,如果觉得文章不错,点个赞鼓励一下吧!我们下篇文章再见!