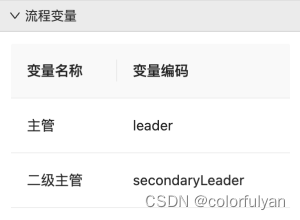
文章目录
- 一、网络结构
- 1、总体网络结构(backbone)
- 2、主干网络介绍(backbone)
- 2.1 多分支模块堆叠
- 2.2 下采样网络结构
- 2.3 整个backbone代码
- 3、FPN特征金字塔
- 二、预测结果的解码
一、网络结构
1、总体网络结构(backbone)
主干网络示意图如下,其实采用的和YoloV3、YoloV4、YoloV5类似的网络结构
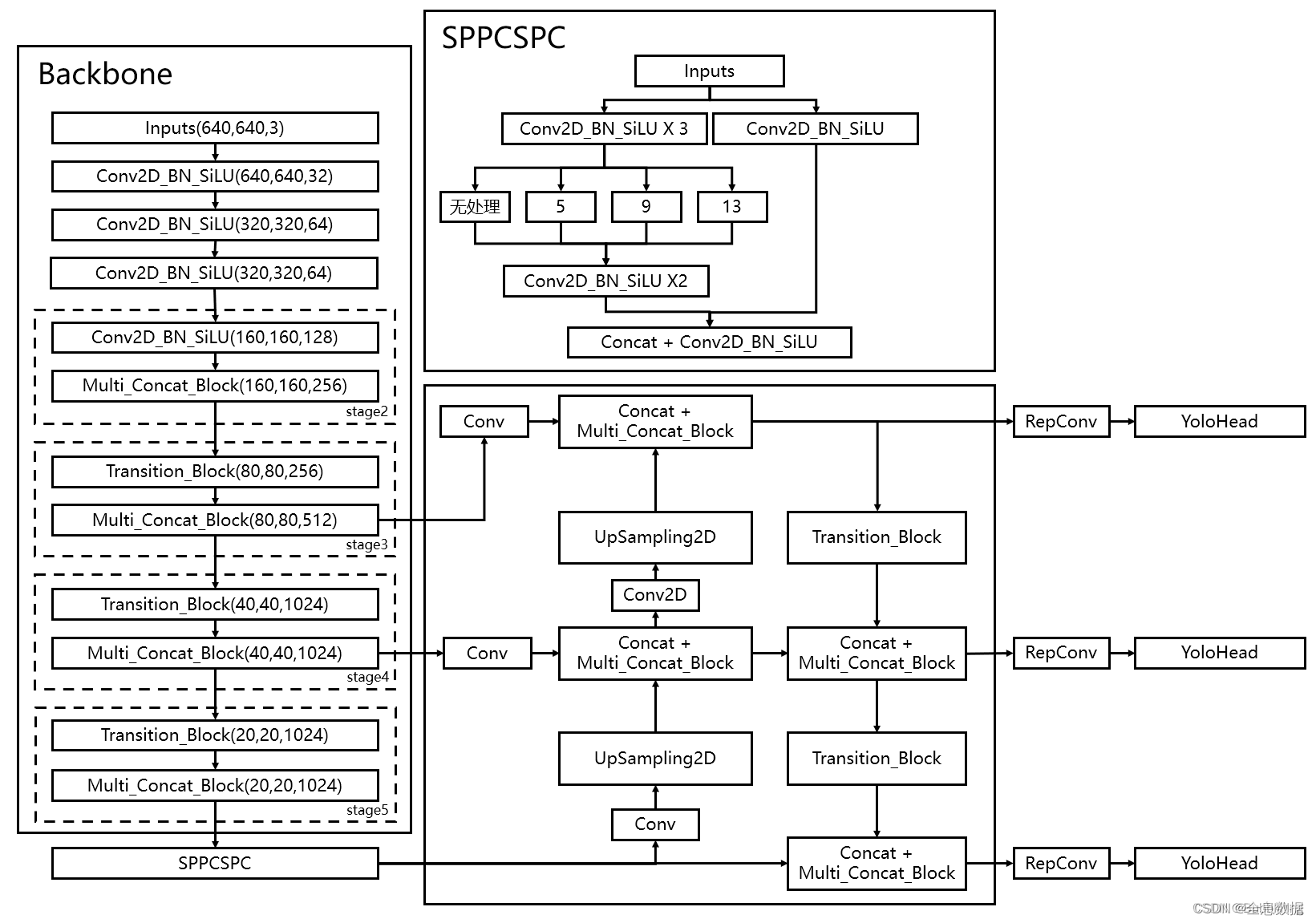
2、主干网络介绍(backbone)
2.1 多分支模块堆叠
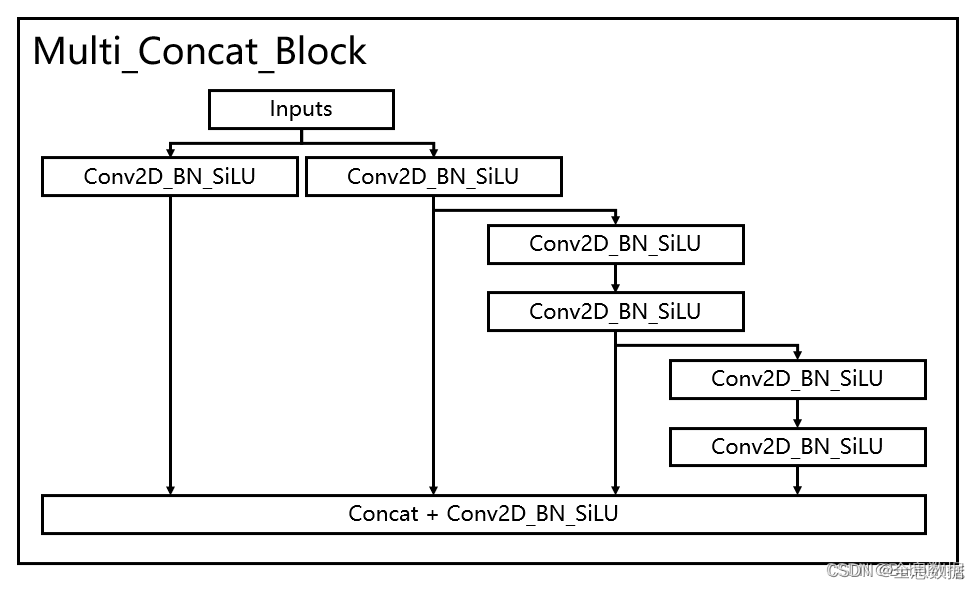
代码如下,多分支模块堆叠的类名为:Multi_Concat_Block
import torch
import torch.nn as nn
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=SiLU()): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
# 走SiLU
self.act = nn.LeakyReLU(0.1, inplace=True) if act is True else (
act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Multi_Concat_Block(nn.Module):
def __init__(self, c1, c2, c3, n=4, e=1, ids=[0]):
super(Multi_Concat_Block, self).__init__()
c_ = int(c2 * e)
self.ids = ids
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = nn.ModuleList(
[Conv(c_ if i == 0 else c2, c2, 3, 1) for i in range(n)]
)
self.cv4 = Conv(c_ * 2 + c2 * (len(ids) - 2), c3, 1, 1)
def forward(self, x):
x_1 = self.cv1(x)
x_2 = self.cv2(x)
x_all = [x_1, x_2]
for i in range(len(self.cv3)):
x_2 = self.cv3[i](x_2)
x_all.append(x_2)
out = self.cv4(torch.cat([x_all[id] for id in self.ids], 1)) # 1:在1维拼接, 0:在0维拼接
return out
if __name__ == '__main__':
ids = {
'l': [-1, -3, -5, -6],
'x': [-1, -3, -5, -7, -8],
}['l']
x = torch.randn(2, 3, 5, 5)
print(x.shape)
out = Multi_Concat_Block(3, 3, 5, n=4, ids=ids)(x)
print(out.shape)
输出:
torch.Size([2, 3, 5, 5])
torch.Size([2, 5, 5, 5])
2.2 下采样网络结构
结合了maxpooling和2
×
\times
× 2步长的卷积
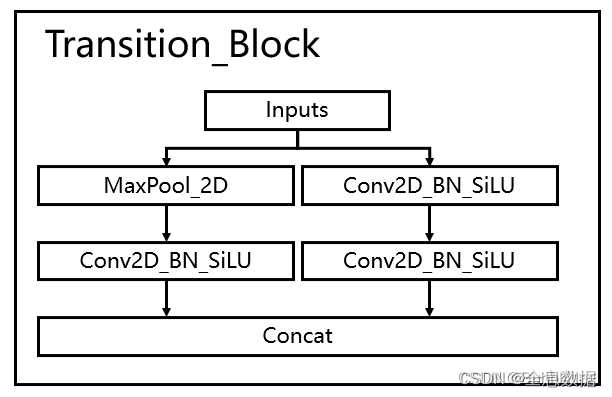
代码如下,下采样结构类名为Transition_Block,
import torch
import torch.nn as nn
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=SiLU()): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
# 走SiLU
self.act = nn.LeakyReLU(0.1, inplace=True) if act is True else (
act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class MP(nn.Module):
def __init__(self, k=3, t=2):
super(MP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=t, padding=1)
def forward(self, x):
return self.m(x)
class Transition_Block(nn.Module):
def __init__(self, c1, c2):
super(Transition_Block, self).__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c1, c2, 1, 1)
self.cv3 = Conv(c2, c2, 3, 2)
self.mp = MP()
def forward(self, x):
x_1 = self.mp(x)
x_1 = self.cv1(x_1)
x_2 = self.cv2(x)
x_2 = self.cv3(x_2)
return torch.cat([x_2, x_1], 1)
if __name__ == '__main__':
x = torch.randn(2, 3, 9, 9)
print(x.shape)
out = Transition_Block(3, 5)(x)
print(out.shape)
输出:
torch.Size([2, 3, 9, 9])
torch.Size([2, 10, 5, 5])
2.3 整个backbone代码
整个主干网络实现代码为:
import torch
import torch.nn as nn
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=SiLU()): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
# 走SiLU
self.act = nn.LeakyReLU(0.1, inplace=True) if act is True else (
act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Multi_Concat_Block(nn.Module):
def __init__(self, c1, c2, c3, n=4, e=1, ids=[0]):
super(Multi_Concat_Block, self).__init__()
c_ = int(c2 * e)
self.ids = ids
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = nn.ModuleList(
[Conv(c_ if i == 0 else c2, c2, 3, 1) for i in range(n)]
)
self.cv4 = Conv(c_ * 2 + c2 * (len(ids) - 2), c3, 1, 1)
def forward(self, x):
x_1 = self.cv1(x)
x_2 = self.cv2(x)
x_all = [x_1, x_2]
for i in range(len(self.cv3)):
x_2 = self.cv3[i](x_2)
x_all.append(x_2)
out = self.cv4(torch.cat([x_all[id] for id in self.ids], 1)) # 1:在1维拼接, 0:在0维拼接
return out
class MP(nn.Module):
def __init__(self, k=2):
super(MP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=k)
def forward(self, x):
return self.m(x)
class Transition_Block(nn.Module):
def __init__(self, c1, c2):
super(Transition_Block, self).__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c1, c2, 1, 1)
self.cv3 = Conv(c2, c2, 3, 2)
self.mp = MP()
def forward(self, x):
x_1 = self.mp(x)
x_1 = self.cv1(x_1)
x_2 = self.cv2(x)
x_2 = self.cv3(x_2)
return torch.cat([x_2, x_1], 1)
class Backbone(nn.Module):
def __init__(self, transition_channels, block_channels, n, phi, pretrained=False):
super().__init__()
# -----------------------------------------------#
# 输入图片是640, 640, 3
# -----------------------------------------------#
ids = {
'l': [-1, -3, -5, -6],
'x': [-1, -3, -5, -7, -8],
}[phi]
self.stem = nn.Sequential(
Conv(3, transition_channels, 3, 1),
Conv(transition_channels, transition_channels * 2, 3, 2),
Conv(transition_channels * 2, transition_channels * 2, 3, 1),
)
self.dark2 = nn.Sequential(
Conv(transition_channels * 2, transition_channels * 4, 3, 2),
Multi_Concat_Block(transition_channels * 4, block_channels * 2, transition_channels * 8, n=n, ids=ids),
)
self.dark3 = nn.Sequential(
Transition_Block(transition_channels * 8, transition_channels * 4),
Multi_Concat_Block(transition_channels * 8, block_channels * 4, transition_channels * 16, n=n, ids=ids),
)
self.dark4 = nn.Sequential(
Transition_Block(transition_channels * 16, transition_channels * 8),
Multi_Concat_Block(transition_channels * 16, block_channels * 8, transition_channels * 32, n=n, ids=ids),
)
self.dark5 = nn.Sequential(
Transition_Block(transition_channels * 32, transition_channels * 16),
Multi_Concat_Block(transition_channels * 32, block_channels * 8, transition_channels * 32, n=n, ids=ids),
)
if pretrained:
url = {
"l": 'https://github.com/bubbliiiing/yolov7-pytorch/releases/download/v1.0/yolov7_backbone_weights.pth',
"x": 'https://github.com/bubbliiiing/yolov7-pytorch/releases/download/v1.0/yolov7_x_backbone_weights.pth',
}[phi]
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", model_dir="./model_data")
self.load_state_dict(checkpoint, strict=False)
print("Load weights from " + url.split('/')[-1])
def forward(self, x):
x = self.stem(x)
x = self.dark2(x)
# -----------------------------------------------#
# dark3的输出为80, 80, 512,是一个有效特征层
# -----------------------------------------------#
x = self.dark3(x)
feat1 = x
# -----------------------------------------------#
# dark4的输出为40, 40, 1024,是一个有效特征层
# -----------------------------------------------#
x = self.dark4(x)
feat2 = x
# -----------------------------------------------#
# dark5的输出为20, 20, 1024,是一个有效特征层
# -----------------------------------------------#
x = self.dark5(x)
feat3 = x
return feat1, feat2, feat3
if __name__ == '__main__':
x = torch.randn(16, 3, 640, 640)
print("x.shape:", x.shape)
out1, out2, out3 = Backbone(3, 5, n=4, phi='l')(x)
print("out1.shape:", out1.shape, '\n', "out2.shape:", out2.shape, '\n', "out3.shape:", out3.shape)
输出:
x.shape: torch.Size([16, 3, 640, 640])
out1.shape: torch.Size([16, 48, 80, 80])
out2.shape: torch.Size([16, 96, 40, 40])
out3.shape: torch.Size([16, 96, 20, 20])
3、FPN特征金字塔
backbone与FPN以及head代码:
import os
import sys
import numpy as np
import torch
import torch.nn as nn
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from nets.backbone import Backbone, Multi_Concat_Block, Conv, SiLU, Transition_Block, autopad
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))
class RepConv(nn.Module):
# Represented convolution
# https://arxiv.org/abs/2101.03697
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, act=SiLU(), deploy=False):
super(RepConv, self).__init__()
self.deploy = deploy
self.groups = g
self.in_channels = c1
self.out_channels = c2
assert k == 3
assert autopad(k, p) == 1
padding_11 = autopad(k, p) - k // 2
self.act = nn.LeakyReLU(0.1, inplace=True) if act is True else (
act if isinstance(act, nn.Module) else nn.Identity())
if deploy:
self.rbr_reparam = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=True)
else:
self.rbr_identity = (
nn.BatchNorm2d(num_features=c1, eps=0.001, momentum=0.03) if c2 == c1 and s == 1 else None)
self.rbr_dense = nn.Sequential(
nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False),
nn.BatchNorm2d(num_features=c2, eps=0.001, momentum=0.03),
)
self.rbr_1x1 = nn.Sequential(
nn.Conv2d(c1, c2, 1, s, padding_11, groups=g, bias=False),
nn.BatchNorm2d(num_features=c2, eps=0.001, momentum=0.03),
)
def forward(self, inputs):
if hasattr(self, "rbr_reparam"):
return self.act(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.act(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return (
kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid,
bias3x3 + bias1x1 + biasid,
)
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch[0].weight
running_mean = branch[1].running_mean
running_var = branch[1].running_var
gamma = branch[1].weight
beta = branch[1].bias
eps = branch[1].eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, "id_tensor"):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros(
(self.in_channels, input_dim, 3, 3), dtype=np.float32
)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def repvgg_convert(self):
kernel, bias = self.get_equivalent_kernel_bias()
return (
kernel.detach().cpu().numpy(),
bias.detach().cpu().numpy(),
)
def fuse_conv_bn(self, conv, bn):
std = (bn.running_var + bn.eps).sqrt()
bias = bn.bias - bn.running_mean * bn.weight / std
t = (bn.weight / std).reshape(-1, 1, 1, 1)
weights = conv.weight * t
bn = nn.Identity()
conv = nn.Conv2d(in_channels=conv.in_channels,
out_channels=conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
dilation=conv.dilation,
groups=conv.groups,
bias=True,
padding_mode=conv.padding_mode)
conv.weight = torch.nn.Parameter(weights)
conv.bias = torch.nn.Parameter(bias)
return conv
def fuse_repvgg_block(self):
if self.deploy:
return
print(f"RepConv.fuse_repvgg_block")
self.rbr_dense = self.fuse_conv_bn(self.rbr_dense[0], self.rbr_dense[1])
self.rbr_1x1 = self.fuse_conv_bn(self.rbr_1x1[0], self.rbr_1x1[1])
rbr_1x1_bias = self.rbr_1x1.bias
weight_1x1_expanded = torch.nn.functional.pad(self.rbr_1x1.weight, [1, 1, 1, 1])
# Fuse self.rbr_identity
if (isinstance(self.rbr_identity, nn.BatchNorm2d) or isinstance(self.rbr_identity,
nn.modules.batchnorm.SyncBatchNorm)):
identity_conv_1x1 = nn.Conv2d(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=1,
stride=1,
padding=0,
groups=self.groups,
bias=False)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.to(self.rbr_1x1.weight.data.device)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.squeeze().squeeze()
identity_conv_1x1.weight.data.fill_(0.0)
identity_conv_1x1.weight.data.fill_diagonal_(1.0)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.unsqueeze(2).unsqueeze(3)
identity_conv_1x1 = self.fuse_conv_bn(identity_conv_1x1, self.rbr_identity)
bias_identity_expanded = identity_conv_1x1.bias
weight_identity_expanded = torch.nn.functional.pad(identity_conv_1x1.weight, [1, 1, 1, 1])
else:
bias_identity_expanded = torch.nn.Parameter(torch.zeros_like(rbr_1x1_bias))
weight_identity_expanded = torch.nn.Parameter(torch.zeros_like(weight_1x1_expanded))
self.rbr_dense.weight = torch.nn.Parameter(
self.rbr_dense.weight + weight_1x1_expanded + weight_identity_expanded)
self.rbr_dense.bias = torch.nn.Parameter(self.rbr_dense.bias + rbr_1x1_bias + bias_identity_expanded)
self.rbr_reparam = self.rbr_dense
self.deploy = True
if self.rbr_identity is not None:
del self.rbr_identity
self.rbr_identity = None
if self.rbr_1x1 is not None:
del self.rbr_1x1
self.rbr_1x1 = None
if self.rbr_dense is not None:
del self.rbr_dense
self.rbr_dense = None
def fuse_conv_and_bn(conv, bn):
fusedconv = nn.Conv2d(conv.in_channels,
conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
groups=conv.groups,
bias=True).requires_grad_(False).to(conv.weight.device)
w_conv = conv.weight.clone().view(conv.out_channels, -1)
w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
return fusedconv
# ---------------------------------------------------#
# yolo_body
# ---------------------------------------------------#
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, phi, pretrained=False):
super(YoloBody, self).__init__()
# -----------------------------------------------#
# 定义了不同yolov7版本的参数
# -----------------------------------------------#
transition_channels = {'l': 32, 'x': 40}[phi]
block_channels = 32
panet_channels = {'l': 32, 'x': 64}[phi]
e = {'l': 2, 'x': 1}[phi]
n = {'l': 4, 'x': 6}[phi]
ids = {'l': [-1, -2, -3, -4, -5, -6], 'x': [-1, -3, -5, -7, -8]}[phi]
conv = {'l': RepConv, 'x': Conv}[phi]
# -----------------------------------------------#
# 输入图片是640, 640, 3
# -----------------------------------------------#
# ---------------------------------------------------#
# 生成主干模型
# 获得三个有效特征层,他们的shape分别是:
# 80, 80, 512
# 40, 40, 1024
# 20, 20, 1024
# ---------------------------------------------------#
self.backbone = Backbone(transition_channels, block_channels, n, phi, pretrained=pretrained)
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
self.sppcspc = SPPCSPC(transition_channels * 32, transition_channels * 16)
self.conv_for_P5 = Conv(transition_channels * 16, transition_channels * 8)
self.conv_for_feat2 = Conv(transition_channels * 32, transition_channels * 8)
self.conv3_for_upsample1 = Multi_Concat_Block(transition_channels * 16, panet_channels * 4,
transition_channels * 8, e=e, n=n, ids=ids)
self.conv_for_P4 = Conv(transition_channels * 8, transition_channels * 4)
self.conv_for_feat1 = Conv(transition_channels * 16, transition_channels * 4)
self.conv3_for_upsample2 = Multi_Concat_Block(transition_channels * 8, panet_channels * 2,
transition_channels * 4, e=e, n=n, ids=ids)
self.down_sample1 = Transition_Block(transition_channels * 4, transition_channels * 4)
self.conv3_for_downsample1 = Multi_Concat_Block(transition_channels * 16, panet_channels * 4,
transition_channels * 8, e=e, n=n, ids=ids)
self.down_sample2 = Transition_Block(transition_channels * 8, transition_channels * 8)
self.conv3_for_downsample2 = Multi_Concat_Block(transition_channels * 32, panet_channels * 8,
transition_channels * 16, e=e, n=n, ids=ids)
self.rep_conv_1 = conv(transition_channels * 4, transition_channels * 8, 3, 1)
self.rep_conv_2 = conv(transition_channels * 8, transition_channels * 16, 3, 1)
self.rep_conv_3 = conv(transition_channels * 16, transition_channels * 32, 3, 1)
self.yolo_head_P3 = nn.Conv2d(transition_channels * 8, len(anchors_mask[2]) * (5 + num_classes), 1)
self.yolo_head_P4 = nn.Conv2d(transition_channels * 16, len(anchors_mask[1]) * (5 + num_classes), 1)
self.yolo_head_P5 = nn.Conv2d(transition_channels * 32, len(anchors_mask[0]) * (5 + num_classes), 1)
def fuse(self):
print('Fusing layers... ')
for m in self.modules():
if isinstance(m, RepConv):
m.fuse_repvgg_block()
elif type(m) is Conv and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn)
delattr(m, 'bn')
m.forward = m.fuseforward
return self
def forward(self, x):
# backbone
feat1, feat2, feat3 = self.backbone.forward(x)
P5 = self.sppcspc(feat3)
P5_conv = self.conv_for_P5(P5)
P5_upsample = self.upsample(P5_conv)
P4 = torch.cat([self.conv_for_feat2(feat2), P5_upsample], 1)
P4 = self.conv3_for_upsample1(P4)
P4_conv = self.conv_for_P4(P4)
P4_upsample = self.upsample(P4_conv)
P3 = torch.cat([self.conv_for_feat1(feat1), P4_upsample], 1)
P3 = self.conv3_for_upsample2(P3)
P3_downsample = self.down_sample1(P3)
P4 = torch.cat([P3_downsample, P4], 1)
P4 = self.conv3_for_downsample1(P4)
P4_downsample = self.down_sample2(P4)
P5 = torch.cat([P4_downsample, P5], 1)
P5 = self.conv3_for_downsample2(P5)
P3 = self.rep_conv_1(P3)
P4 = self.rep_conv_2(P4)
P5 = self.rep_conv_3(P5)
# ---------------------------------------------------#
# 第三个特征层
# y3=(batch_size, 75, 80, 80)
# ---------------------------------------------------#
out2 = self.yolo_head_P3(P3)
# ---------------------------------------------------#
# 第二个特征层
# y2=(batch_size, 75, 40, 40)
# ---------------------------------------------------#
out1 = self.yolo_head_P4(P4)
# ---------------------------------------------------#
# 第一个特征层
# y1=(batch_size, 75, 20, 20)
# ---------------------------------------------------#
out0 = self.yolo_head_P5(P5)
return [out0, out1, out2]
if __name__ == '__main__':
x = torch.randn(16, 3, 640, 640)
print("x.shape:", x.shape)
anchors_mask = [[[12, 16], [19, 36], [40, 28]], [[36, 75], [76, 55], [72, 146]], [[142, 110], [192, 243], [459, 401]]]
out = YoloBody(anchors_mask, 20, 'l')(x)
for item in out:
print(item.shape)
输出:
x.shape: torch.Size([16, 3, 640, 640])
torch.Size([16, 75, 20, 20])
torch.Size([16, 75, 40, 40])
torch.Size([16, 75, 80, 80])