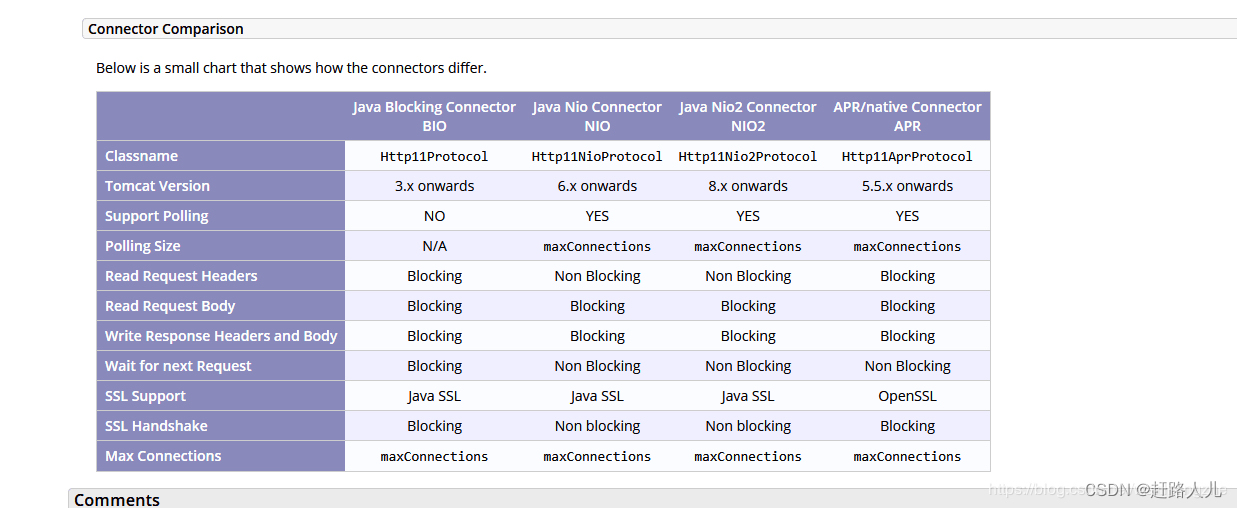
Tomcat支持一下几种IO模型:
| 支持的IO模型 | 特点 |
| BIO | 同步阻塞式IO,每一个请求都会创建一个线程,对性能开销大,不适合高并发场景。 |
| NIO | 同步非阻塞式IO,基于多路复用Selector监测连接状态通知线程处理,达到非阻塞的目的,比传统的BIO效率高。Tomcat8.0的默认方式。 |
| AIO | 异步IO,基于各种回调处理。 |
| APR | Apache Http服务器的支持库,通过JNI技术调用本地库实现非阻塞IO。 |
主流模式还是NIO。官方对这三种的区别的详细说明:
Tomcat启动的时候,可以通过log看到Connector使用的是哪一种运行模式:
Starting ProtocolHandler [“http-bio-8080”]
Starting ProtocolHandler [“http-nio-8080”]
Starting ProtocolHandler [“http-apr-8080”]1、BIO:
基于java BIO实现。Tomcat7(包含)以下默认使用这种方式。它的处理流程如下:
- tomcat负责创建监听,accept socket连接
- 将socket连接放到tomcat线程池中处理,等待http的请求,并将请求分配给对应的servlet处理业务
- 处理完请求之后,通过servletResponse写会数据
上面这三步都是在一个线程里面完成的,也就是同步进行。
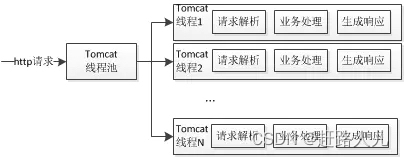
缺点:一个链接一个线程(面向连接的),即客户端有连接时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情(比如后续的请求并没有到来,或者请求完毕连接还没有释放)会造成不必要的线程开销,非常消耗资源。BIO的connector在最新tomcat8.5及其之后的版本已经移除支持了。
1.1)BIO的Connector实现原理:
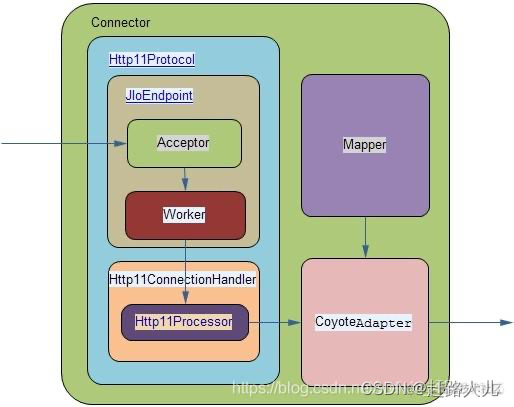
BIO的connector实现中,主要采用org.apache.coyote.http11.Http11Protocol处理请求,Http11Protocol包含了JIoEndpoint对象及Http11ConnectionHandler对象。
1)JIoEndpoint:
JIoEndpoint维护了两个线程池,Acceptor及Worker。Acceptor是接收socket连接,当有连接进来,就会从Worker线程池中(Exector)找出空闲的线程处理socket,如果worker线程池没有空闲线程,则Acceptor将阻塞。
Worker线程拿到socket后,就从Http11Processor对象池中获取Http11Processor对象,进一步处理。 Worker线程池是默认线程池,也可以自己配置Executor标签并引用为工作线程池!
2)Http11ConnectionHandler:
- Http11ConnectionHandler对象维护了一个Http11Processor对象池,Http11Processor对象会解析socket中的http request并封装到Request对象中(这个Request是临时使用的一个类,它的全类名是org.apache.coyote.Request),并创建org.apache.coyote.Request。
- 随后调用org.apache.catalina.connector.CoyoteAdapter继续完成解析,构造org.apache.catalina.connector.Request和Response对象,并且通过connector.getService().getContainer().getPipeline().getFirst().invoke(request, response)将请求转发发给对应的Container(Engine,也就是Servlet容器)。
- 然后就是另一个流程了,即Engine->Host->Context->Wrapper的处理流程,即Engine找到对应的Web应用并且调用对应的Servlet方法,然后将response通过socket发回client。注意这些操作也都是在Worker线程中完成的。
2、NIO:
2.1)配置
Tomcat6、7已经支持了NIO,但必须修改Connector配置来启动,修改tomcat安装目录下(conf/server.xml):

修改成:

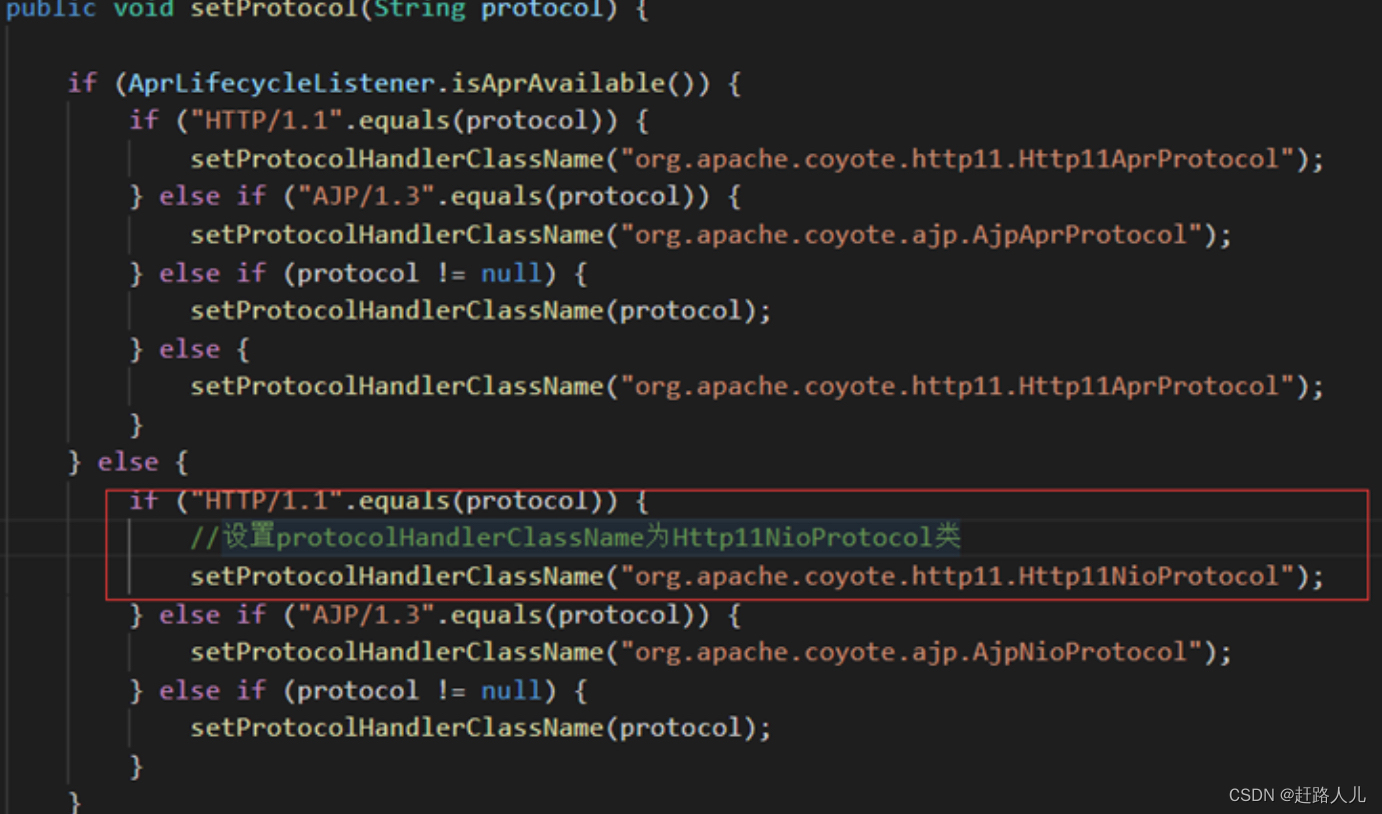
Tomcat8默认使用这种方式(HTTP/1.1在Tomcat8.0中使用的是Http11NioProtocol),源码如下:
2.2)NIO组件:
tomcat的org.apache.coyote.http11.Http11NioProtocol Connector 从 tomcat 6.x 开始支持, Tomcat里面NIO的实现是交给Endpoint组件完成的,NioEndpoint是基于JDK的NIO实现的多路复用的IO模型,并且Tomcat的网络模型是主从Reactor多线程模型。
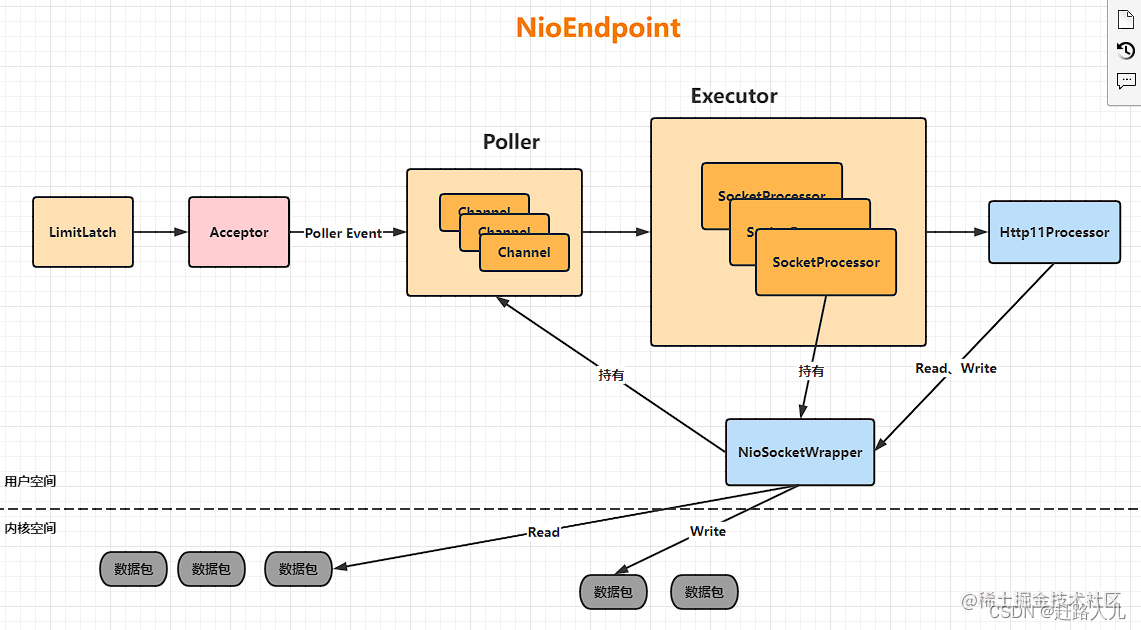
- LimitLatch:连接控制器,负责控制最大连接数,NIO模式下默认是10000个,当连接数达到最大限制时阻塞线程,直到后续处理完连接后,连接数-1才继续执行。
- Acceptor:负责接收连接,默认由1个单独的线程通过while(true)循环调用#accept( )方法来接收新的连接,一旦有新的连接到达,就会返回一个Channel对象,将Channel对象交给Poller组件处理。
- Poller:Acceptor和Poller是通过SynchronizedQueue同步队列来进行生产-消费模式进行 通信,Poller的本质就是一个Selector,默认由1个单独的线程while(true)监测Channel的就绪状态,一旦有Channel可读,就会生成一个SocketProcessor任务对象给Executor线程池处理。
- SocketProcessor:也称worker,从socket中读取数据,解析成HttpServletRequest对象,并分派到对应的servlet完成逻辑处理,最后将response通过socket返回给client。
2.3)特点:
由于NIO采用了selector方式(多路复用),所以不需要为每个链接建立一个线程,而是一个请求一个work线程(面向请求的)。但是这里要注意一点:上图中read request body 以及 write response body 仍然是同步阻塞的,不会在读到部分请求内容, 或者只写了部分相应内容就给用户返回结果。
此外,tomcat还实现了特有的线程池和使用了对象池技术:
1)线程池:
tomcat并没有使用JDK原生提供的线程池,而是实现了StandardThreadExecutor,它和原生JDK的线程池ThreadPoolExecutor的区别:
- 自定义了拒绝策略,Tomcat在线程总数达到最大数时,不是立即执行拒绝策略,而是再尝试向任务队列里尝试添加任务,如果添加失败则执行拒绝策略。
- 它的任务队列TaskQueue重写了LinkedBlockingQueue的offer方法,只有当前线程数>核心线程数且小于最大线程数且提交的任务书>当前线程数,会创建新线程。目的是让队列长度无限制时,让线程池有机会创建新的线程。
2)对象池:
Java对象如果遇到高频高并发场景下,它的创建、初始化、GC等都比较耗费资源,为了减少开销,Tomcat使用了对象池技术。对象池技术的目的就是对象的缓存和复用,以空间换时间。SynchronizedStack是一个栈结构的对象池,里面缓存着PollerEvent对象,提高程序整体的性能,避免频繁的new对象和回收。
2.4)NIO的Connector实现原理:
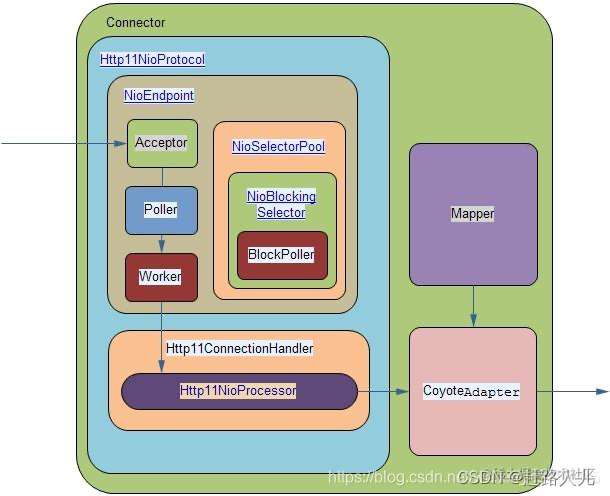
在NIO的connector实现中,主要采用org.apache.coyote.http11.Http11NioProtocol处理请求,Http11NioProtocol包含了NioEndpoint对象及Http11ConnectionHandler对象。NioEndpoint主要包括Acceptor、Poller、Worker组件。
1)流程:
- Acceptor线程用于从Accept队列中接收socket连接(使用serverSocket.accept()阻塞方式),可以设置多个Accepter线程,这一点和BIO一致。当有连接进入,acceptor不再直接使用Worker中的线程处理该连接,而是先将socketChannel封装成tomcat的NioChannel对象,然后通过队列发送给Poller(典型的生产者-消费者模式),而Poller是实现tomcat的NIO关键。
- 在Poller中,维护了一个Selector对象,也可以设置多个Poller线程。当Poller从队列中取出socketChannel后,将OP_READ事件注册到该Selector中;然后执行select方法遍历Selector,找出可读的socketChannel,并使用Worker中的线程进行处理。
- Worker在获取到从Poller传过来的socketChannel后,将socketChannel封装在SocketProcessor对象中。然后从Http11ConnectionHandler中取出Http11NioProcessor对象,从Http11NioProcessor中调用CoyoteAdapter的逻辑,随后的实现跟BIO的实现一样都是阻塞式的并且是Worker线程来做的。
注:与BIO类似,Worker也可以被自定义的线程池代替。
2)辅Selector:
在架构中,NioEndpoint对象中还维护了一个NioSelectPool对象,这个NioSelectorPool中又维护了一个BlockPoller线程,这个线程就是基于辅Selector进行NIO的逻辑,主要处理阻塞的读写操作,比如用于读取socket请求体的数据和通过response往socket中写数据。(相对于Poller中的Selector,是主selector)
当数据(请求体)不可读的时候的时候(客户端数据未发送完毕),会注册封装的 OPEN_READ 事件到 BlockPoller 线程中,然后阻塞当前线程(一般为tomcat io线程),如果OPEN_READ 事件触发,那么将会唤醒阻塞的线程。
对于响应数据(响应头和响应体)的写入由 tomcat io 线程进行,当数据不可写的时候(原始 socket 发送缓冲区满),会注册封装的 OPEN_WRITE 事件对象到 BlockPoller 线程中,然后阻塞当前线程,如果OPEN_WRITE事件触发,那么将会唤醒阻塞的线程。这里的当前线程一般就是Worker线程。BlockPoller主要用于减少Poller的压力!
2.5)tomcat的BIO和NIO区别:
根据上面的内容我们知道,tomcat的NIO connector并非完全是非阻塞的,Acceptor接收socket,从socket中读、写数据等,无论是BIO还是NIO都是阻塞模式实现的。
在NIO中,将Acceptor获取的socket交给Worker线程的时候,采用了多路复用模型,是异步的,只有当新的请求到来时才会交给Worker线程,并且请求处理完毕立即释放线程到池子。而在BIO中,Acceptor每获取一个socket连接就必须马上要一个Worker线程来处理,否则Acceptor线程阻塞!这是NIO模式与BIO模式的最主要区别,不要小看这一点,在并发量较大的情形下可以带来Tomcat效率的显著提升:
目前大多数HTTP请求使用的是长连接,这就意味着一个TCP的socket在当前请求结束后,如果没有新的请求到来,socket不会立马释放,而是等timeout后再释放。如果使用BIO,“读取socket并交给Worker中的线程”这个过程是阻塞的,也就意味着在socket等待下一个请求或等待释放的过程中,处理这个socket的工作线程会一直被占用,无法释放;因此Tomcat可以同时处理的socket数目不能超过最大线程数,性能受到了极大限制。而使用NIO,“读取socket并交给Worker中的线程”这个过程是非阻塞的,当socket在等待下一个请求或等待释放时,并不会占用工作线程,因此Tomcat可以同时处理的socket数目远大于最大线程数,并发性能大大提高。
总结:tomcat bio是面向连接的;tomcat nio是面向请求的!
3、APR:
即Apache Portable Runtime,从操作系统层面解决io阻塞问题。在Linux系统上,需要安装了apr和native,Tomcat直接启动就支持apr。(Tomcat7或Tomcat8在Win7或以上的系统中启动默认使用这种方式)
1)安装环境:
- 安装apr:yum -y install apr apr-devel
- 安装native:cd /usr/local/tomcat/bin/ && tar -xvzf tomcat-native.tar.gz && cd tomcat-native-1.1.33-src/jni/native/ && ./configure --with-apr=/usr/bin/apr-1-config && make && make install
注:需要安装gcc环境(yum -y install gcc)
2)配置:
2.1)环境变量:
在/bin/catalina.sh中增加1行CATALINA_OPTS="-Djava.library.path=/usr/local/apr/lib"

或者在/etc/profile中加入:
export CATALINA_OPTS=-Djava.library.path=/usr/local/apr/lib
2.2)修改tomcat配置文件:
修改tomcat安装目录下(conf/server.xml):

修改成:

参考:
聊聊Tomcat的IO模型和基础调优 - 掘金
详解tomcat的连接数与线程池 - 编程迷思 - 博客园
Tomcat Connector的BIO与NIO模式的比较及区别 - 掘金