文章目录
- 前言
- 一、基本知识介绍
- 二、举例实操以及重要知识再现(列表、元组、集合、字典)
前言
一、基本知识介绍
python基础
标准库与扩展库中的对象的导入与使用:
import 模块名(as别名)
import numpy as np
from 模块名 import 对象名(as别名)
from math import sin as f
__name__属性可以控制python程序运行方式
第二章:运算符、表达式、与内置对象
python中定义变量时:
1.变量名必须以字母或者下划线为开头(但是以下划线开头有特殊意义)
2.变量名中不能有空格或者标点符号
3.不能使用关键字为变量名
4.变量名对大小写敏感
python支持复数类型的运算
python支持分数的运算:
x=Fraction(3,7) #创建分数对象
对str类型的字符串调用其encoad()方法进行编码得到bytes字节串,对bytes字节串调用其decoad()方法并指定正确的编码格式得到str字符串
‘Hello world’.encoad(‘gbk’)
_.decoad)(‘gbk’) #解码 _表示最后一次正确输出结果
python运算符与表达式:
python中一切都是对象 圆括号是明确和改变表达式运算顺序的利器
from random import randint #导入
a=[randint(1,100) for i in range(10)] #包含10个1到100的随机数的列表
x=list(range(10))
import random
random.shuffle(x) #打乱顺序
sorted(x) #排序
enumerate()函数用来枚举可迭代对象中的元素,返回可迭代的enumerate对象其中每个元素都是包含索引和值的元组
map()函数:
map()把一个函数依次映射到序列或迭代器对象的每个元素上,并返回一个可迭代的map对象作为结果,map对象中每个元素是原序列中元素经过函数处理过的结果,map()函数不对原序列或迭代器对象做任何修改
def myMap (lst,value):
return map(lambda item: item+value,lst)
list(myMap(range(5),8)) #相当于给列表中的每个数都加8
reduce()函数: #可以将一个接收两个参数的函数以迭代累计的方式从左到右依次作用到一个序列或迭代器对象的所有元素上,并且允许指定一个初始值
from functools import reduce
seq=list(range(1,10))
reduce(lambda x,y: x+y,seq)
reduce(operator.add,map(str,seq)) #转换成字符串再累加,结果就是字符串的拼接
range()函数: #这个函数我们经常会用到
for i in range(100,0,-1):
if i % 17 == 0:
print(i)
break
zip()函数: 就是用来把多个可迭代对象中的元素都压缩在一起,返回一个可迭代的zip对象
eval()函数: 用来计算字符串的值,有的时候也能用来实现类型转换的功能
python序列结构
几种分类方式:
1、有序序列和无序序列
2、可变序列和不可变序列
可以用负数作为索引,比如下标为-1就指最后一个元素,以此类推
列表: list
除非必要,否则都应该从列表的尾部进行追加和删除操作,列表中的元素的类型可以不相同;;列表的功能虽然强大,但是负担比较重,所有尽量避免过多的使用列表
list()函数可以把其他类型转换为列表,但是对于将字典的转换,默认是将字典的键转换为列表,若想把元素转换就要使用items()方法明确说明,或者values()来说明
sort() #排序 reverse()将列表中所有元素逆序或者翻转
copy()函数; 返回列表的浅复制,也就是生成一个新的列表,并且把原列表吧中的所有元素的引用都复制到新列表中,如果这个列表中有可变类型的数 据,那么改变一个,另一个也会改变,而不可变类型数据就不会存在这样的问题
所对应的就是深复制,也就是队员列表中的元素进行递归,把所有的值都复制到新列表中,对嵌套的子列表不再是复制引用。相互独立
import copy
x=[1,2,[3,4]]
y=copy.deepcopy(x)
y.append(6)
不会对x中的值有所影响
列表对象支持的运算符:
+ * 都可以实现列表增加元素或者元素的重复,但是都会返回新的列表,效率很低;所以我们一般会使用+= *=来进行前面的操作,这样就属于原地操作,和append()一样都很高效
成员测试符in for i in range[2] i in [1,2,3]
内置函数对列表的操作:
切片操作: [start: end:step]
切片得到的是列表的浅复制
元组:轻量级列表 tuple
列表的功能很强大,但是负担很重,有的时候并不需要那么多功能,所以我们可以使用元组,如果元组中只有一个元素,一定要在最后增添一个逗号
元组是不可变的,支持双向索引,python对元组的访问速度比列表快很多,元组可哈希
字典:反应对应关系的映射类型 dict
字典是包含若干键、值元素的无序可变序列,所有元素放在大括号中
字典中元素的键可以是python中任意不可变数据,键不允许重复,值可以重复;字典在内部维护的哈希表使得检索速度非常快
字典中元素的访问通过键作为下标来访问对应的值,一般情况下,我们都会配合条件判断来访问字典元素,以防止异常出现
字典对象提供get()方法来返回指定键对应的值
aDict.get(‘address’,‘Not Exists.’) 当我们访问不存在的键address时就会返回Not Exists.
对字典进行遍历指的是对字典的键进行遍历,想要遍历整个元素或者遍历值需要指定
update()方法可以将另一个字典的键值全部添加到当前字典对象,若存在相同的键,则以另一个字典为准进行更新
集合:元素之间不允许重复 set
集合中只能包括不可变数据类型
s={1,2,3}
s.add{4} 元素的添加
s.update(3,4)
s={1,2,3,4} 会自动删除重复的元素
二、举例实操以及重要知识再现(列表、元组、集合、字典)
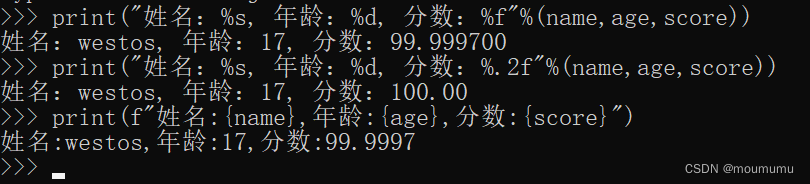
给姓名、年龄、分数赋值之后进行输出,除了最简单的方式进行输出不之外,我们也可以使用一下两种方式进行输出;一种是使用占位符,另一种比较直观,但是不能对浮点类型的数值进行控制输出小数点后的位数,所以根据需求我们可以选择更合适的输出方式,一般情况下我们会采用第二个方式,因为简单直观
几种常见函数:
abs求绝对值
divmod返回商和余数
pow求次方
round保留小数点后几位
几种常用的模块:
math数学模块
randow随机数
三元运算符:
我们可以通过最简单的print进行输出也可以用三元运算符直接进行输出
**range()**包前不包后,如果有三个数字,就依次是start、end、step

如果元组里只有一个元素,那么要在这个元素后边加逗号
\t 水平制表符
\n换行符
字符串的数据清洗:
strip:删除字符串开头和末尾的空格
lstrip:删除字符串开头的空格
rstrip:删除字符串末尾的空格
replace:字符串替换
字符串的分割和拼接:
split:分割
join:拼接
列表的常用方法:
追加:li.append()
在指定位置添加:li.insert()
一次追加多个元素:li.extend()
修改:我们通过重新赋值 的方式来进行修改
删除:
可以根据索引删除:li.pop()
根据值删除:li.remove()
全部删除:li.clear()
反转li.reverse()
排序:li.sort() 想要由大到小排序:li.sort(reverse=True)
拷贝:li.copy()
元组的常用方法:
元组不能修改
is与==的区别
==只会判断类型和值
is不但会判断类型和值,也会判断内存地址
深拷贝和浅拷贝:
浅拷贝;
ni=[1,2,3]
n2=ni.copy()
这就是浅拷贝,对原来进行修改,不会对拷贝的有影响
深拷贝:
如果有列表嵌套或者列表中有可变数据类型的时候,一定要选择深拷贝
浅拷贝只会对地址进行拷贝,深拷贝会对地址以及对应的值一起进行拷贝
集合:
集合的元素必须是不可变数据类型
空集合不能使用{},而要使用set()
集合是无序不重复的,只支持成员操作符
add:添加单个元素
update:添加多个元素
remove:删除元素,如果存在正常删除,不存在就会报错
discard:删除元素,不存在不会报错
pop:随机删除,集合为空就会报错
frozenset:不可变集合,不能进行增删改查
字典:
像集合一样,字典也只支持成员操作符,但是只会判断是否为key值的成员
d.get:查看key对应的value值,存在则返回,不存在则返回默认值,未自定义为None,定义为默认值
d.setdefault:key存在则不做任何修改,若不存在,则相当于添加
defaultdict:
d=defaultdict(list)
d[‘allow_users’].append(‘westos’)
d[‘deny_users’].extend([‘user1’,‘user2’])