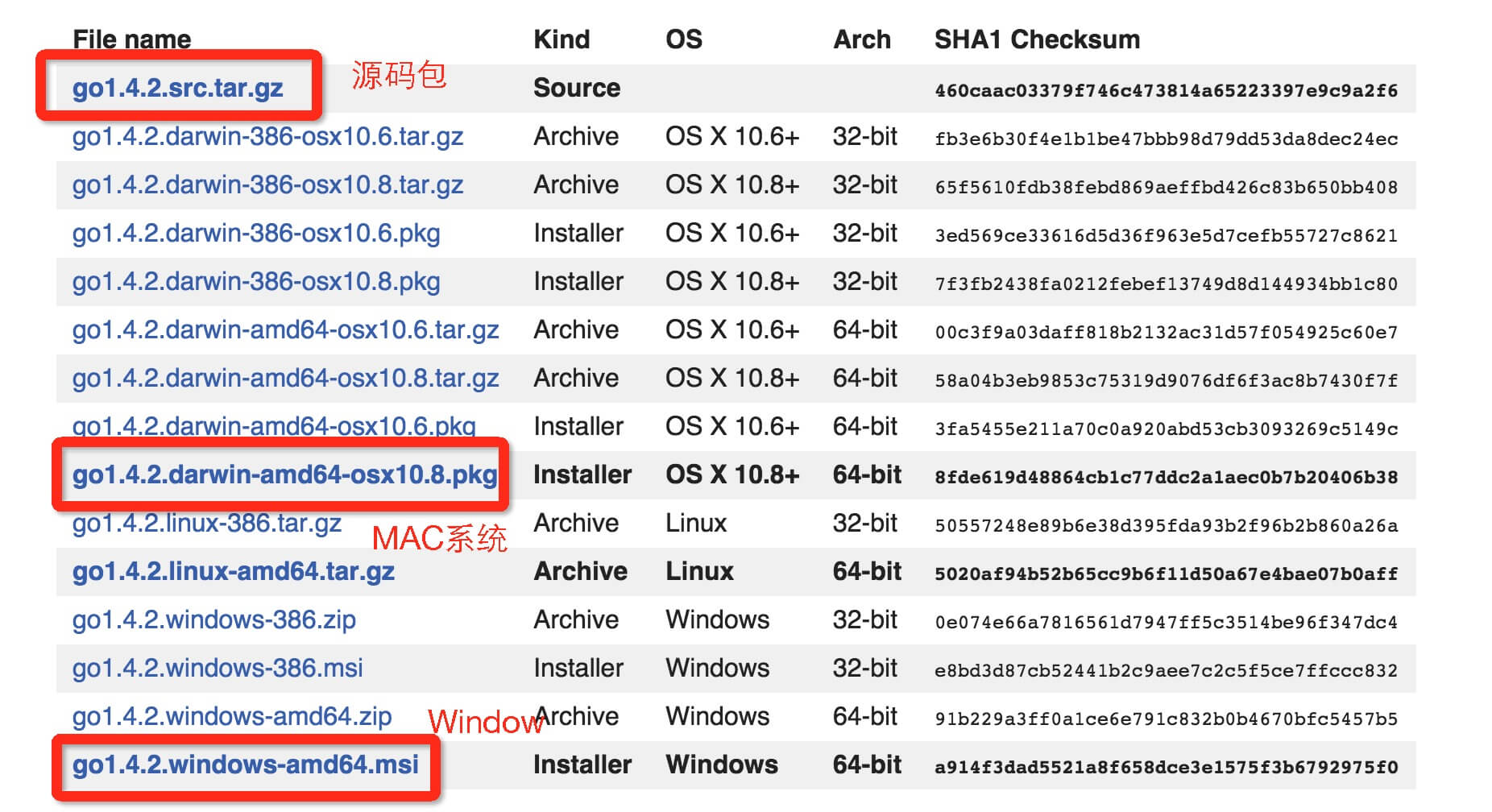
1.自定义函数
1.1 自定义函数类型
根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function)
一进一出。
(2)UDAF(User-Defined Aggregation Function)
用户自定义聚合函数,多进一出。
类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
用户自定义表生成函数,一进多出。
如lateral view explode()
1.2 代码实现udf函数
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
/**
* initialize 初始化,参数校验个数校验。
* evaluate方法就是核心的处理逻辑,,每处理一行数据就会调用一次evaluate方法。关注一行数据。会被循环的调用。hive会循环的调用。
*
*/
public class MyLength extends GenericUDF {
/**
* 判断传进来的参数的类型和长度
* 约定返回的数据类型
* ObjectInspector,对象检查器。上一个的元信息。
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length !=1) {
throw new UDFArgumentLengthException("please give me only one arg");
}
//数据类型arguments[0].getCategory(),PRIMITIVE基本数据类型。
if (!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(1, "i need primitive type arg");
}
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 解决具体逻辑的,
*/
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
Object o = arguments[0].get();
if(o==null){
return 0;
}
return o.toString().length();
}
@Override
// 用于获取解释的字符串
public String getDisplayString(String[] children) {
return "";
}
}
1.3 创建临时函数
(1)打成jar包上传到服器/opt/module/hive/datas/myudf.jar
(2)将jar包添加到hive的classpath,临时生效
add jar /opt/module/hive/datas/myudf.jar;
(3)创建临时函数与开发好的java class关联
create temporary function my_len
as "com.atguigu.hive.udf.MyUDF";
(4)即可在hql中使用自定义的临时函数
select
ename,
my_len(ename) ename_len
from emp;
删除临时函数
drop temporary function my_len;
注意:临时函数只跟会话有关系,跟库没有关系。只要创建临时函数的会话不断,在当前会话下,任意一个库都可以使用,其他会话全都不能使用。
1.4 创建永久函数
注意:因为add jar本身也是临时生效,所以在创建永久函数的时候,需要制定路径(并且因为元数据的原因,这个路径还得是HDFS上的路径)。
create function my_len2
as "com.atguigu.hive.udf.MyUDF"
using jar "hdfs://hadoop102:8020/udf/myudf.jar";
(2)即可在hql中使用自定义的永久函数
select
ename,
my_len2(ename) ename_len
from emp;
(3)删除永久函数
drop function my_len2;
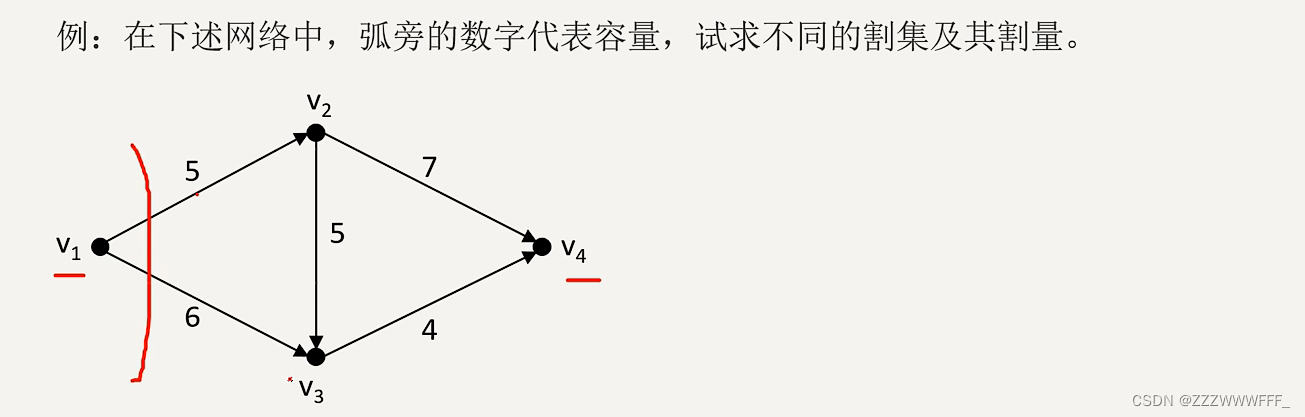
2.分区表和分桶表
2.1 分区表
Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。分区就是为方便过滤条件。
创建分区表:
create table dept_partition
(
deptno int, --部门编号
dname string, --部门名称
loc string --部门位置
)partitioned by (day string)
row format delimited fields terminated by '\t';
2.2 分区表读写数据
load数据集
vim dept_20220401.log
10 行政部 1700
20 财务部 1800
load data local inpath '/opt/module/hive/datas/dept_20220401.log'
into table dept_partition
partition(day='20220401');
insert数据集
将day='20220401'分区的数据插入到day='20220402'分区,可执行如下装载语句
insert overwrite table dept_partition partition (day = '20220402')
select deptno, dname, loc
from dept_partition
where day = '2020-04-01';
读数据
select deptno, dname, loc ,day
from dept_partition
where day = '2020-04-01';
分区表基本操作
查看所有分区信息
show partitions dept_partition;
增加分区
alter table dept_partition add partition(day='20220403');
--同时创建多个分区
alter table dept_partition add partition(day='20220404') partition(day='20220405');
删除分区
alter table dept_partition drop partition (day='20220403');
alter table dept_partition drop partition (day='20220404'), partition(day='20220405');
修复分区
Hive将分区表的所有分区信息都保存在了元数据中,只有元数据与HDFS上的分区路径一致时,分区表才能正常读写数据。若分区表为外部表,用户执行drop partition命令后,分区元数据会被删除,而HDFS的分区路径不会被删除,同样会导致Hive的元数据和HDFS的分区路径不一致。
若分区元数据和HDFS的分区路径不一致,还可使用msck命令进行修复,以下是该命令的用法说明。
msck repair table table_name [add/drop/sync partitions];
msck repair table table_name add partitions:该命令会增加HDFS路径存在但元数据缺失的分区信息。
msck repair table table_name drop partitions:该命令会删除HDFS路径已经删除但元数据仍然存在的分区信息。
msck repair table table_name sync partitions:该命令会同步HDFS路径和元数据分区信息,相当于同时执行上述的两个命令。
二级分区表
create table dept_partition2(
deptno int, -- 部门编号
dname string, -- 部门名称
loc string -- 部门位置
)
partitioned by (day string, hour string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/hive/datas/dept_20220401.log'
into table dept_partition2
partition(day='20220401', hour='12');
select
*
from dept_partition2
where day='20220401' and hour='12';
动态分区
动态分区相关参数
1.动态分区功能总开关(默认true,开启)
set hive.exec.dynamic.partition=true
2.严格模式和非严格模式
动态分区的模式,默认strict(严格模式),要求必须指定至少一个分区为静态分区,nonstrict(非严格模式)允许所有的分区字段都使用动态分区。
set hive.exec.dynamic.partition.mode=nonstrict
3.一条insert语句可同时创建的最大的分区个数,默认为1000。
set hive.exec.max.dynamic.partitions=1000
4.单个Mapper或者Reducer可同时创建的最大的分区个数,默认为100。
set hive.exec.max.dynamic.partitions.pernode=100
5.一条insert语句可以创建的最大的文件个数,默认100000。
hive.exec.max.created.files=100000
6.当查询结果为空时且进行动态分区时,是否抛出异常,默认false。
hive.error.on.empty.partition=false
2.2 分桶表
分区针对的是数据的存储路径,分桶针对的是数据文件。
分桶表的基本原理是,首先为每行数据计算一个指定字段的数据的hash值,然后模以一个指定的分桶数,最后将取模运算结果相同的行,写入同一个文件中,这个文件就称为一个分桶(bucket)。
1.建表
create table stu_buck(
id int,
name string
)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';
1001 student1
1002 student2
1003 student3
1004 student4
1005 student5
1006 student6
1007 student7
1008 student8
1009 student9
1010 student10
1011 student11
1012 student12
1013 student13
1014 student14
1015 student15
1016 student16
load data local inpath '/opt/module/hive/datas/student.txt'
into table stu_buck;
2.分桶排序表
create table stu_buck_sort(
id int,
name string
)
clustered by(id) sorted by(id)
into 4 buckets
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/hive/datas/student.txt'
into table stu_buck_sort;
3. Hive文件格式
3.1 Text File
文本文件是Hive默认使用的文件格式,文本文件中的一行内容,就对应Hive表中的一行记录。
create table textfile_table
(column_specs)
stored as textfile;
orc
每个Orc文件由Header、Body和Tail三部分组成。
Index Data:一个轻量级的index,默认是为各列每隔1W行做一个索引。每个索引会记录第n万行的位置,和最近一万行的最大值和最小值等信息。
Row Data:存的是具体的数据,按列进行存储,并对每个列进行编码,分成多个Stream来存储。
Stripe Footer:存放的是各个Stream的位置以及各column的编码信息。
create table orc_table
(column_specs)
stored as orc
tblproperties (property_name=property_value, ...);
Parquet
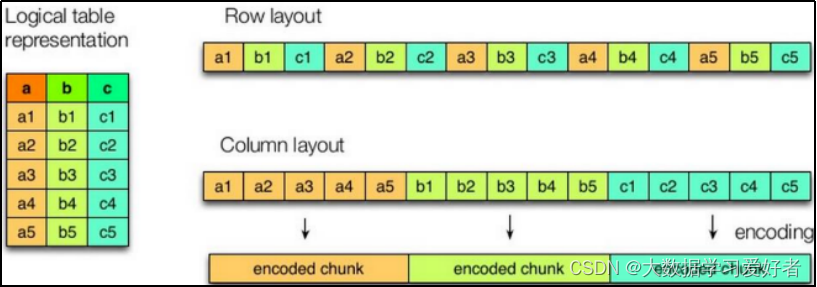
Parquet文件是Hadoop生态中的一个通用的文件格式,它也是一个列式存储的文件格式。
Parquet文件的格式如下图所示:
行组(Row Group):一个行组对应逻辑表中的若干行。
列块(Column Chunk):一个行组中的一列保存在一个列块中。
页(Page):一个列块的数据会划分为若干个页。
Create table parquet_table
(column_specs)
stored as parquet
tblproperties (property_name=property_value, ...);
4.企业级调优
1.1 Yarn资源配置
1.1.1 Yarn配置说明
yarn.nodemanager.resource.memory-mb
一个NodeManager节点分配给Container分配的总内存。
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>65536</value>
</property>
yarn.nodemanager.resource.cpu-vcores
一个NodeManager节点分配给Container使用的CPU核数。
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>16</value>
</property>
yarn.scheduler.maximum-allocation-mb
单个Container能够使用的最大内存。
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
yarn.scheduler.minimum-allocation-mb
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
修改$HADOOP_HOME/etc/hadoop/yarn-site.xml文件
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>65536</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>16</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
1个核4g
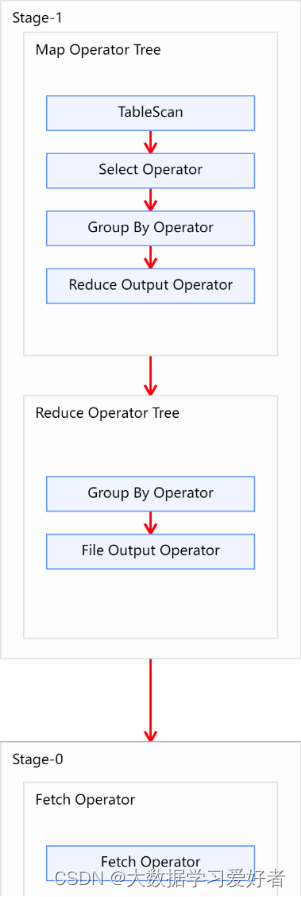
1.2 Explain查看执行计划
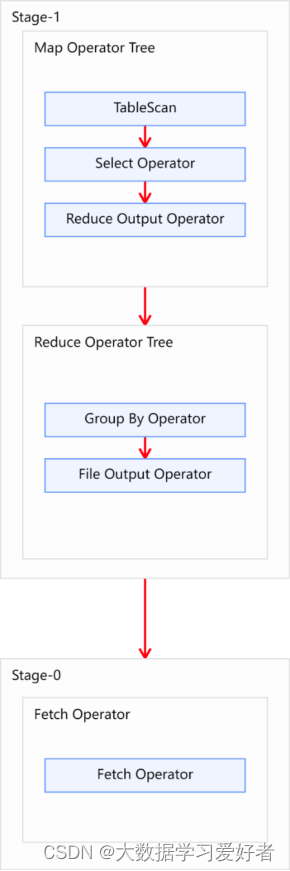
Explain呈现的执行计划,由一系列Stage组成,这一系列Stage具有依赖关系,每个Stage对应一个MapReduce Job,或者一个文件系统操作等。
若某个Stage对应的一个MapReduce Job,其Map端和Reduce端的计算逻辑分别由Map Operator Tree和Reduce Operator Tree进行描述,Operator Tree由一系列的Operator组成,一个Operator代表在Map或Reduce阶段的一个单一的逻辑操作,例如TableScan Operator,Select Operator,Join Operator等。

常见的Operator及其作用如下:
TableScan:表扫描操作,通常map端第一个操作肯定是表扫描操作
Select Operator:选取操作
Group By Operator:分组聚合操作
Reduce Output Operator:输出到 reduce 操作
Filter Operator:过滤操作
Join Operator:join 操作
File Output Operator:文件输出操作
Fetch Operator 客户端获取数据操作
EXPLAIN [FORMATTED | EXTENDED | DEPENDENCY] query-sql
1.2.1HQL语法优化之分组聚合优化
Hive对分组聚合的优化主要围绕着减少Shuffle数据量进行,所谓map-side聚合,就是在map端维护一个hash table,利用其完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,发送至reduce端,完成最终的聚合。
map-side 聚合相关的参数如下:
--启用map-side聚合
set hive.map.aggr=true;
--用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
--map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
优化前:
优化后
--启用map-side聚合,默认是true
set hive.map.aggr=true;
--用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
--map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
HQL语法优化之Join优化
1)Common Join
map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
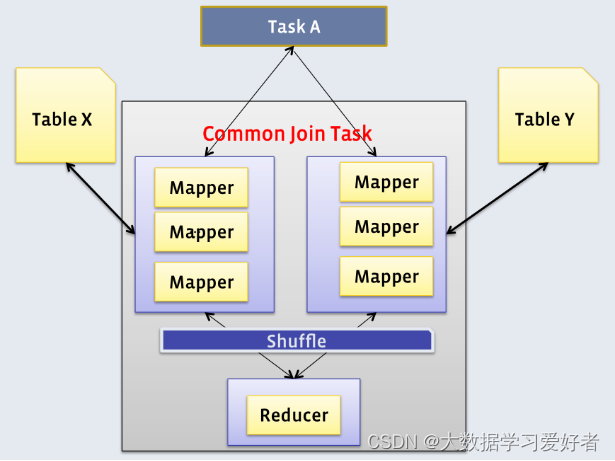
sql语句中的join操作和执行计划中的Common Join任务并非一对一的关系,一个sql语句中的相邻的且关联字段相同的多个join操作可以合并为一个Common Join任务。
select
a.val,
b.val,
c.val
from a
join b on (a.key = b.key1)
join c on (c.key = b.key1)
--
select
a.val,
b.val,
c.val
from a
join b on (a.key = b.key1)
join c on (c.key = b.key2)
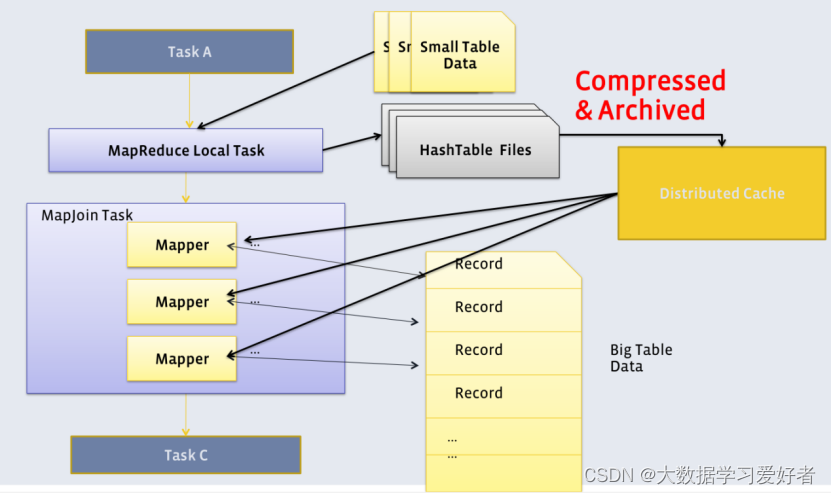
2.Map Join
大表join小表。若某join操作满足要求,则第一个Job会读取小表数据,将其制作为hash table,并上传至Hadoop分布式缓存(本质上是上传至HDFS)。第二个Job会先从分布式缓存中读取小表数据,并缓存在Map Task的内存中,然后扫描大表数据,这样在map端即可完成关联操作。
3.Bucket Map Join
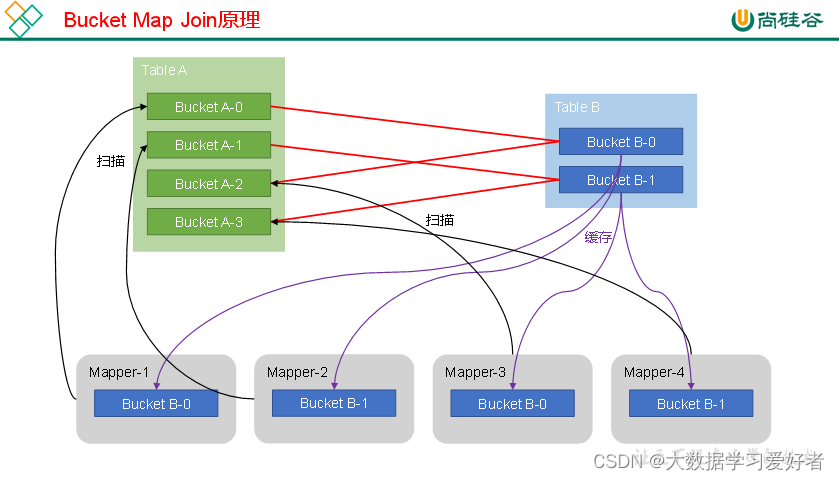
Bucket Map Join是对Map Join算法的改进,其打破了Map Join只适用于大表join小表的限制,可用于大表join大表的场景。
Bucket Map Join的核心思想是:若能保证参与join的表均为分桶表,且关联字段为分桶字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍,就能保证参与join的两张表的分桶之间具有明确的关联关系,所以就可以在两表的分桶间进行Map Join操作了。
Sort Merge Bucket Map Join
Sort Merge Bucket Map Join(简称SMB Map Join)基于Bucket Map Join。SMB Map Join要求,参与join的表均为分桶表,且需保证分桶内的数据是有序的,且分桶字段、排序字段和关联字段为相同字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍。
两个分桶之间的join实现原理为Hash Join算法;而SMB Map Join,两个分桶之间的join实现原理为Sort Merge Join算法。
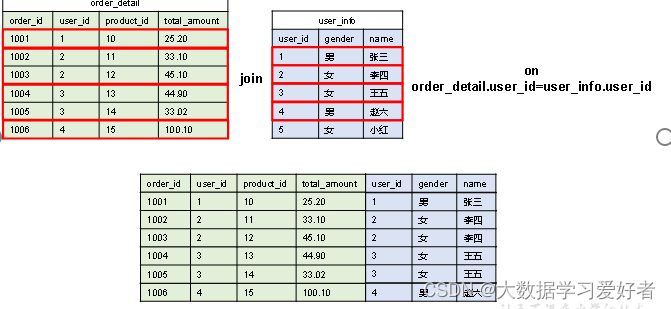
Map端是无需对整个Bucket构建hash table,也无需在Map端缓存整个Bucket数据的,每个Mapper只需按顺序逐个key读取两个分桶的数据进行join即可。
Map Join
实战:
select
*
from order_detail od
join product_info product on od.product_id = product.id
join province_info province on od.province_id = province.id;
--启用Map Join自动转换。
set hive.auto.convert.join=true;
--使用无条件转Map Join。
set hive.auto.convert.join.noconditionaltask=true;
--调整hive.auto.convert.join.noconditionaltask.size参数,使其等于product_info。
set hive.auto.convert.join.noconditionaltask.size=25285707;
当两个表很大的时候采用的是分桶表
select /*+ mapjoin(pd) */
*
from order_detail_bucketed od
join payment_detail_bucketed pd on od.id = pd.order_detail_id;
Sort Merge Bucket Map Join
--启动Sort Merge Bucket Map Join优化
set hive.optimize.bucketmapjoin.sortedmerge=true;
--使用自动转换SMB Join
set hive.auto.convert.sortmerge.join=true;
5.HQL语法优化之数据倾斜
5.1 数据倾斜
数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往同一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。
资源–充足,并行度。
5.2 分组聚合导致的数据倾斜
如果group by分组字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
1)Map-Side聚合
开启Map-Side聚合后,数据会现在Map端完成部分聚合工作。这样一来即便原始数据是倾斜的,经过Map端的初步聚合后,发往Reduce的数据也就不再倾斜了。最佳状态下,Map-端聚合能完全屏蔽数据倾斜问题。(flush,维护一个hashtable,需要内存)
--启用map-side聚合
set hive.map.aggr=true;(默认开启的)
--用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
--map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
Skew-GroupBy优化
Skew-GroupBy的原理是启动两个MR任务,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合。
相关参数如下:
--启用分组聚合数据倾斜优化
set hive.groupby.skewindata=true;
5.3 join 端数据倾斜
未经优化的join操作,默认是使用common join算法,也就是通过一个MapReduce Job完成计算。如果关联字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
5.3.1 map join
使用map join算法,join操作仅在map端就能完成,没有shuffle操作,没有reduce阶段,自然不会产生reduce端的数据倾斜。该方案适用于大表join小表时发生数据倾斜的场景。
--启动Map Join自动转换
set hive.auto.convert.join=true;
--一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。
set hive.mapjoin.smalltable.filesize=250000;
--开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;
--无条件转Map Join时的小表之和阈值,若一个Common Join operator相关的表中,存在n-1张表的大小总和<=该值,此时hive便不会再为每种n-1张表的组合均生成Map Join计划,同时也不会保留Common Join作为后备计划。而是只生成一个最优的Map Join计划。
set hive.auto.convert.join.noconditionaltask.size=10000000;
skew join (大表和大表Join,中存在数据倾斜的情况)
skew join的原理是,为倾斜的大key单独启动一个map join任务进行计算,其余key进行正常的common join。原理图如下:大表和大表。分桶也会出现的数据倾斜。
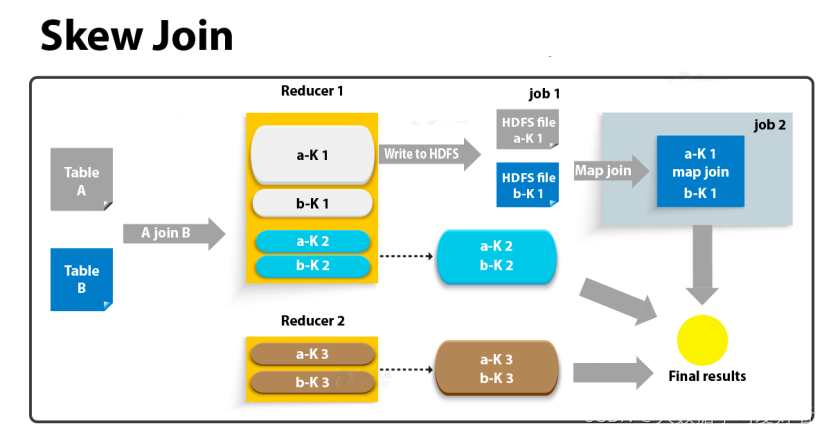
相关参数如下:
--启用skew join优化
set hive.optimize.skewjoin=true;
--触发skew join的阈值,若某个key的行数超过该参数值,则触发
set hive.skewjoin.key=100000;
若参与join的两表均为大表,其中一张表的数据是倾斜的,此时也可通过以下方式对SQL语句进行相应的调整。
select
*
from A
join B
on A.id=B.id;

select
*
from(
select --打散操作
concat(id,'_',cast(rand()*2 as int)) id,
value
from A
)ta
join(
select --扩容操作
concat(id,'_',0) id,
value
from B
union all
select
concat(id,'_',1) id,
value
from B
)tb
on ta.id=tb.id;

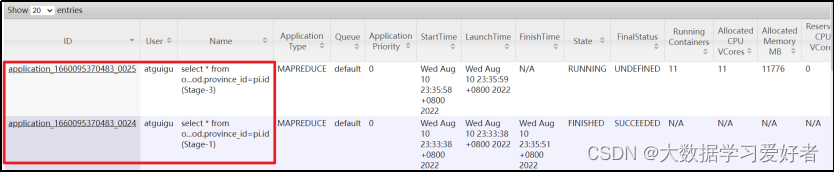
优化案例
select
*
from order_detail od
join province_info pi
on od.province_id=pi.id;
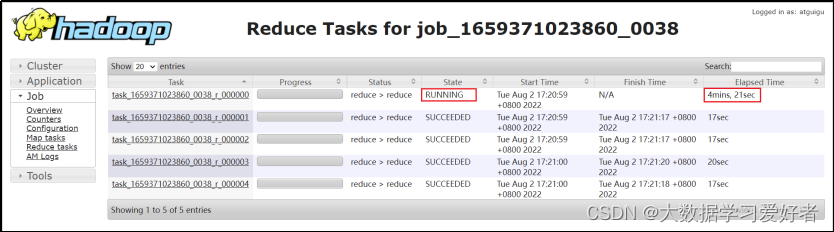
hive.auto.convert.join=false,默认开启了map join
(1)map join
设置如下参数
--启用map join
set hive.auto.convert.join=true;
--关闭skew join
set hive.optimize.skewjoin=false;

--启动skew join
set hive.optimize.skewjoin=true;
--关闭map join
set hive.auto.convert.join=false;
开启skew join后,使用explain可以很明显看到执行计划如下图所示,说明skew join生效,任务既有common join,又有部分key走了map join。