本文以在SWM34S(M33内核,150Mhz,编译器Keil MDK 5.36)上优化为例,说明优化方法和需要注意的地方,其他MCU可以参考。
在编写模拟SPI通信驱动LCD的例子的时候,会用到一个发送字节的核心函数,其基本实现方式如下:
static void Spi4_WriteByte(uint8_t d)
{
uint8_t i,spidat;
spidat = d;
for(i=0; i<8; i++)
{
if( (spidat&0x80)!=0 )
LCD0_SPI4_MOSI_HIGH();
else
LCD0_SPI4_MOSI_LOW();
spidat <<= 1;
LCD0_SPI4_CLK_LOW();
LCD0_SPI4_CLK_HIGH();
}
}

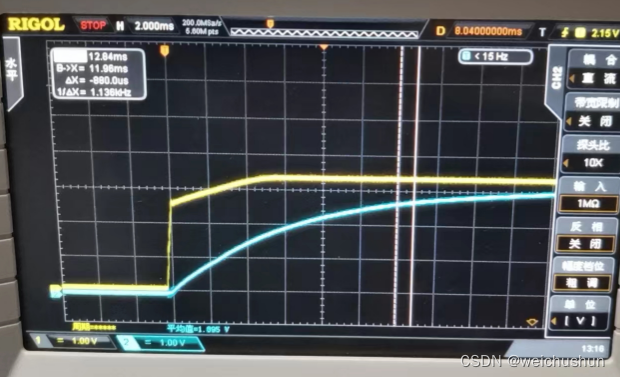
如上图,我们可以看到时钟的低电平时间非常的短,高电平时间很长。从如上代码我们也能看出来,是因为时钟高低电平只有一条指令,基本已经是最短的了,高电平持续期间还有其他代码运行。
参考一下ST7735的spi时序图:
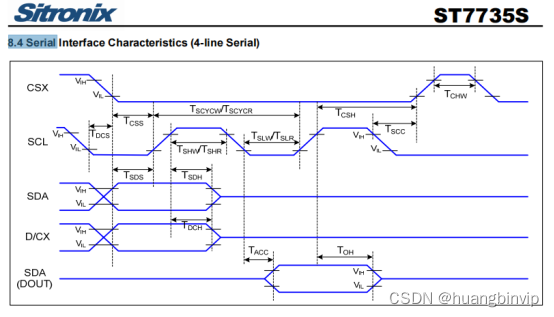
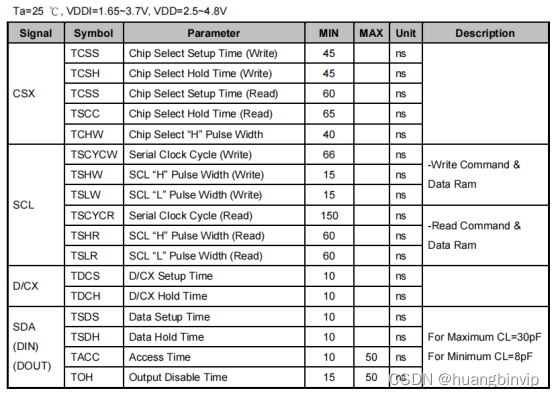
重点看写参数:时钟低电平最低宽度Tshw(15ns),时钟高电平最低宽度Tslw(15ns),时钟最小周期Tscycw(66ns)。我们在实现模拟spi驱动的时候要严格遵循这个时序要求,很明显上面测试到的时序,低电平6ns太短了,需要处理。
简单的方法,在时钟低电平后插入延时,但是会导致整个速度变慢
LCD0_SPI4_CLK_LOW();
__NOP();
LCD0_SPI4_CLK_HIGH();
优化第一步:
把时钟拉低的时间移动到前面来,整个执行时间和代码并没有增加:
static void Spi4_WriteByte(uint8_t d)
{
uint8_t i,spidat;
spidat = d;
for(i=0; i<8; i++)
{
LCD0_SPI4_CLK_LOW();
if( (spidat&0x80)!=0 )
LCD0_SPI4_MOSI_HIGH();
else
LCD0_SPI4_MOSI_LOW();
spidat <<= 1;
LCD0_SPI4_CLK_HIGH();
}
}
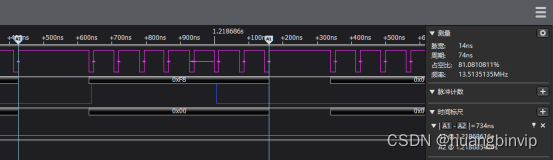
由于编译器的优化(而且一定要开优化(O1以上),速度才会快,开与不开大约相差3倍),从低电平到高电平之间的时间似乎并没有完全和代码一致,但是宽度已经变成14ns了,已经能基本满足我们的需求了。
好了,到这里,我们把基本时序调整完成,发送一个字节大约需要714ns,此时发送一帧数据(320x240 16bit)大约需要110ms。
感觉速度还是不够,如何来进一步优化?
乍一看,貌似也没有多少优化空间了(那几个宏定义的操作已经是最优实现,可以不考虑)?那还能咋整?
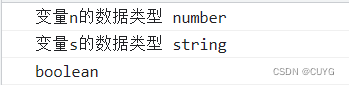
细节决定成败,请记住我们用的是32bit mcu,代码中的i,spidat两个变量是采用8bit定义的,习惯了单片机的内存紧张,尽量用最小单位来定义了。
优化第二步,将变量i定义为32bit,看看发生了什么变化:
uint32_t i;
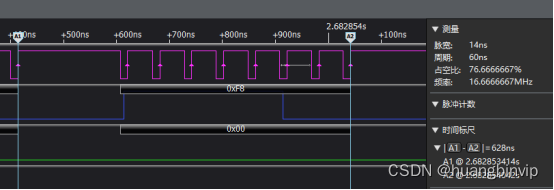
看看效果,一个字节的发送时间从714ns降低到628ns,一帧的数据时间降低到94.16ms。是不是很惊奇,说明在32bit的mcu上,效率最高的内存访问还是32bit的方式,在需要极度时间优化的时候请正确使用。
优化第三步,将变量spidat也定义为32bit:
最终全部代码如下:
static void Spi4_WriteByte(uint8_t d)
{
uint32_t i,spidat;
spidat = d;
for(i=0; i<8; i++)
{
LCD0_SPI4_CLK_LOW();
if( (spidat&0x80)!=0 )
LCD0_SPI4_MOSI_HIGH();
else sudu
LCD0_SPI4_MOSI_LOW();
spidat <<= 1;
LCD0_SPI4_CLK_HIGH();
}
}
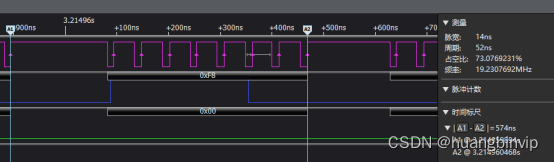
这个优化我们很容易忽略,因为spi传输8bit数据的时候,我们是msb在前,要先判断最高位,惯性的就用了8bit来表示数据,其实我们是需要判断第8bit,而不是一定需要8bit数据长度,在代码中,用32bit也是一样的效果
从图中实际测试数据来看,我们的字节传输时间再次下降到574ns,一帧数据86.09ms,提升还是比较明显。
综合来看,仅仅通过优化两个变量类型的定义,一帧数据的传输时间从110ms->94.16ms->86.09ms,提速约30%,并没有为cpu带来任何影响,也不会多ram开销,效果非常明显。
**************文章为原创,倾注了大量心血,欢迎转载,请注明出处**************