文章目录
- 引言
- GB2312
- GBK
- unicode 和 ISO10646
- ISO10646的编码结构
- 结论
- 参考文献
引言
由于物理实现比较容易等原因计算机等数字系统内部使用二进制字符的记录、存贮、传递和交换通过编码来实现。字符的机内编码其实就是该字符在字符图库中的序号。拼音文字一般仅有几十个字母组成。而汉字集形、音、义等多种信息于一体数量繁多1994年的《中华字海》收录的汉字数竟达87019个之多。显然定义汉字编码字符集比拼音文字要困难,一要从大量汉字(包括简体字、繁体字、日本汉字、韩国汉字)中选取必需的汉字而又不致使字符集空间过大;二要对选定的汉字以某种方式(拼音、部首、笔画等等)排列字符次序。
本文对汉字编码的历程和几个编码标准作一简单介绍。
GB2312
GB2312即《信息交换用汉字编码字符集---基本集》由国家标准总局发布1981年5月1日实施。它对促进汉字信息技术的发展和计算机的应用发挥了重要作用有人称它是汉字编码的“秦始皇”。几乎所有的中文系统和国际化的软件都支持 GB2312。GB2312收录图形字符7445个包括阿拉伯和罗马数字拉丁字母日文假名希腊字母俄文字母汉语拼音符号和注音字母其中简体汉字6763个以频度的高低、构词能力的强弱、实际用处的大小为原则进行选字分成两级:一级汉字3755个按拼音排序;二级汉字3008个按部首、笔画排序。一、二级汉字约 占近代文献汉字累计使用频度99。75%以上。GB2312是二字节编码。它将代码表分为94个区。区号对应第一字节;每个区94个位‚位号对应第二 字节。为了兼容 ASCII 码将区号和位号组成的两个字节的值分别加0x20(0x20以下为控制符)再将最高位分别置1以示区别。GB2312的编码范围为0xA1A1-0xFEFE。例:“啊”字是 GB2312之中的第一个汉字排在16区1位它的编码为0xB0A1。
GBK
GBK 全称《汉字内码扩展规范》1.0版于1995年12月15日确定为技术规范指导性文件发布和实施.它解决了 GB 2312收录汉字数量不足的缺点.GBK 与 GB2312兼容并支持 ISO10646.1国际标准. ISO10646是国际标准化组织 ISO 公布的一个编码标准称为《通用多八位编码字符集》英文名为 Universal Multilpe-Octet Coded Character Set(简称 UCS).该标准中的汉字部份称为“CJK 统一汉字”(C 指中国J 指日本K 指朝鲜).GBK 也采用双字节表示编码范围为0x8140-0xFEFE首字节在0x81-0xFE 之间尾字节 在0x40-0xFE 之间剔除0xxx7F 一条线.总计23940个码位‚共收入汉字(包括部首和构件)21003个图形符号883个.全部编码分为三大部分:1、汉字区包括 GBK/2:0xBOA1-0x F7FE收录 GB2312汉字6763个 按原序排列; GBK/3:0x8140-0x AOFE收录 CJK 汉字6080个; GBK/4:0xAA40-0xFEAO 收录 CJK 汉字和增补的汉字8160个.CJK 汉字在前按 UCS 代码大小排列; 增补的汉字(包括部首和构件)在后按《康熙字典》的页码/字位排列. 2、图形符号区包括 GBK/1:0x A1A1-0x A9FE,除 GB2312的符号外,还增补了其它符号计符号717个.GBK/5:0x A840-0x A9AO,扩充非汉字区.计符号166个.3、用户自定义区即 GBK 区域中的空白区用户可以自己定义字符.空白区分三个小区:0xAAA1-0xAFFE码位564个; 0xF8A1-0xFEFE 码位658个;0x A140-0x A7A0码位672个.
unicode 和 ISO10646
国际标准化组织(ISO)和多语言软件制造商组成的协会组织(The Unicode Consortium)致力于制定集世界所有语言于一体的一种编码标准.1991年前后它们开始合并双方的工作成果并为创立一个单一编码表而协同工作.此前的各种编码系统存在明显的缺陷一没有包含足够的字符;二相互间存在冲突:同一编码值代表不同的字符或用不同的编码值代表相同的字符.以至在 Windows 等环境下不得不使用“代码页”(Codepage)来描述编码系统以确定编码值与字形的关联.Unicode 编码也可以看作是 ISO10646国际标准的一种实现方法.
ISO10646的编码结构
ISO10646采用四个字节编码(可简称为 UCS-4) 这四个字节依次称为组、平面、行和列,其中组的范围从0x00到0x7F 平面、行、列都是从0x00到0xFF,ISO10646规定每个平面的最后二个编码位置(0xFFFE 和0xFFFF)保留不用可算出共有2,147,418,112个编码位置.
0组0平面称为基本多语言平面 (Basic Multilingual Plane)简称 BMP.收录 CJK 和 CJK 扩展 A 汉字 27487个及其它文字;0组1平面称为增补多语言平面(Supplementary Multilingual Plane) 简称 SMP.收录汉字以外的文字,绝大部分为拼音文字;0组2平面称为增补表意字符平面(Supplementary Ideographic Plane)简称 SIP.收录中日韩(CJK)扩展 B 等汉字42700余个.到目前为止仅这三个平面收入字符.当只使用0组0平面称为基本多语言平面 (Basic Multilingual Plane)简称 BMP.收录 CJK 和 CJK 扩展 A 汉字 27487个及其它文字;0组1平面称为增补多语言平面(Supplementary Multilingual Plane)简称 SMP.收录汉字以外的文字绝大部分为拼音文字;0组2平面称为增补表意字符平面(Supplementary Ideographic Plane)简称 SIP.收录中日韩(CJK)扩展 B 等汉字42700余个.到目前为止仅这三个平面收入字符.当只使用BMP 时可省略组和平面,将32位编码缩短成16位(简称 UCS-2)因此倍受青睐.BMP 中收录的字符结合图简述如下:
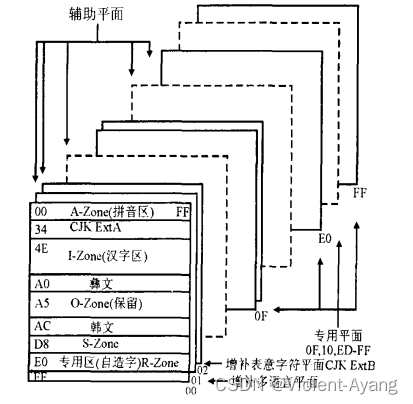
(1)0x0000~0x00A0:基本拉丁字母区 包括控制符.如0x007F 为控制符 DEL.事实上 该区前128个 字符 只要去除前八位就是通常的八位 ASCII 码.
(2)0x00A1~0x1FFF:拼音文字区.收录除基本拉丁字母以外的各种拼音文字‚包括欧洲各国语言、 斯拉夫语、希伯来文、阿拉伯文、印度各地方言、马来文、泰文、满文、藏文等等.
(3)0x2000~0x28FF:符号区.包括标点、上下、钱币、箭头、表格、数学工程、地理图示等等.
(4)0x2E80~0x33FF:中日韩符号区.收录康熙字典部首、中日韩辅助部首、注音符号、日本假名、韩文 、音符、年号、月份、日期、时间等.
(5)0x3400~0x4DFF:中日韩(CJK)扩展 A 区收6582个中日韩汉字.
(6)0x4E00~0x9FFF:中日韩文字区收20902个 CJK 汉字.
(7)0x A000~0x A4FF:彝族文字区.
(8)0x AC00~0x D7FF:韩文拼音组合字区.
(9)0x D800~0x DFFF:代理区专用于 UTF-16.
(10)0x E000~0x F8FF:专用字区保留供用户使用.
(11)0x F900~0x FAFF:收中日韩汉字302个.
(12)0x FB00~0x FFFD:收录拉丁文字、希伯来文、阿拉伯文、中日韩直式标点、半形全形符号等. 3.2 UFT-16、UTF-32和 UFT-8
ISO10646的四字节编码空间足可容纳中外古今所有人类使用的文字和符号‚事实上,常用的均已编入 BMP 中,二字节编码已可满足一般信息处理的需要.显然,处理 unicode 式的二个字节编码要比处理四个字节节省得多.问题是SMP 和 SIP 及其它平面上的字符怎么办?unicode 提出一种编码处理方式叫做 UTF- 16.UTF 是 a UCS(or Unicode)Transformation Format 的缩写‚UTF-16是把 BMP 外的字符编码也转换成 BMP 中二个16位编码单元来表示的意思.
回顾前面对 BMP 的描述‚0x D800~0x DFFF 被安排作为代理区‚不能单独作为字符的编码.在代理区 中选取二个16位的 unicode 编码单元作为 BMP 平面外的字符四字节编码的代表‚所以 UTF-16又称为代 理法.位于前方(高半字)的限定只能选用0xD800~0xDBFF 当中之一‚位于后方(低半字)的也只能从 0xDC00~0xDFFF 中选取.高低半字各有编码位置1024=4×256‚因此 UTF-16可代表(4×256)×(4× 256)=16×65536个编码位置或16个字符平面.应用于 ISO 的0组第一到第十四个平面(第十五平面为专用平面,不予编码)‚编码的范围为0x00010000~0x000EFFFF‚对应的二进制均为20位.
如果字符编码位于 BMP编码值小于0x00010000,自然无须转换.将范围为0x00010000~0x000EFFFF 的编码值转换为 UTF-16编码规则也很简单:将20位二进制数值,从右往左取出10位加上110111 (0xDC00~0xDFFF 二进制值的前六位),构成 UTF-16编码的低半字接着往左取出6位,作为 UTF-16编 码的高半字的低6位,再往左取出4位,将其值减1,置于刚才6位的左面,最后在前面加上110110,就构成 UTF-16编码的高半字.
结论
从1991年发布 unicode1.0到2005年的 unicode4.1‚unicode 编码标准在不断完善中.Windows2000/XP 以,及微软 Office2000及其后的产品,内核都是Unicode.因此,无论何种文字,简体或繁体汉字,都可以同屏显示.举几个例子,以增加对 unicode 编码的感性认识: 在 word2003中,键入U+XXXX(16进制)‚按 Alt+X,相应字符就可以插入光标左侧;同样按 Alt+X 可 以显示光标左侧字符的 unicode 编码‚再按 Alt+X 又切换为字符. 在 winXP/2000中,利用 charmap 可以查看字符及其 unicode 编码,还可借此输入字符.金山词霸2005也对每个汉字给出 unicode 和 GBK 编码.事实上汉字编码在中文信息处理、电子出版(包括古籍数字化)、电子商务等领域均会涉及因此正确理解显得十分必要.
参考文献
[1] RFC2781UTF-16‚an encoding of ISO10646‚Copyright (C) The Internet Society (2000).
[2] RFC2279UTF-8‚a transformation format of ISO10646‚Copyright (C) The Internet Society (1998).
[3] http://www.foundertype.com/jishujl/jishujl.html.
[4] 黄伟敏‚肖春江.张轴材谈汉字交换码标准建立历程〔N〕.计算机世界‚1999-8-30. 5 张轴材.文字信息国际标准进展、问题与思考〔C〕.长沙全国语言文字信息化会议讲稿‚2003-11-05.
[5] 金永涛。显示屏幕上任意字符编码[J]。电脑,1994(08)。
[6] 魏再超。计算机字符编码问题[J]。福建电脑,2012(07)。
[7] 洪汉妮。字符编码即将统一[J]。电子测试,2000(05)。
[8] 袁春风 余子濠著,计算机系统基础 第二版=INTRODUCTION TO COMPUTER SYSTEMS,机械工业出版社,2018。07。
[9] 袁径三.浅说汉字编码[J].绍兴文理学院学报,2005(03):56-59+64.
[10] 杨康,袁海东,郭渊博.低冗余二维码汉字编码研究[J].计算机科学,2017,44(S2):565-569.
[11] 刘嘉煜.汉字编码字符集简介[J].印刷标准化,1997(05):14-16.
[12] 刘坤. 基于字符级卷积神经网络的中文文本分类研究[D].沈阳工业大学,2018.
[13] 黄小花.浅析汉字编码过程[J].电脑知识与技术,2015,11(04):181-182.DOI:10.14004/j.cnki.ckt.2015.0140.
[14] 刘娜.浅谈计算机中的字符编码[J].科技创新与应用,2017(01):107.









![[附源码]计算机毕业设计酒店客房管理信息系统Springboot程序](https://img-blog.csdnimg.cn/cb452dccce504d7fa28fabb5430afc13.png)