一级缓存
概述
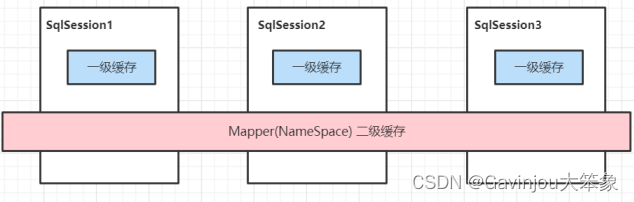
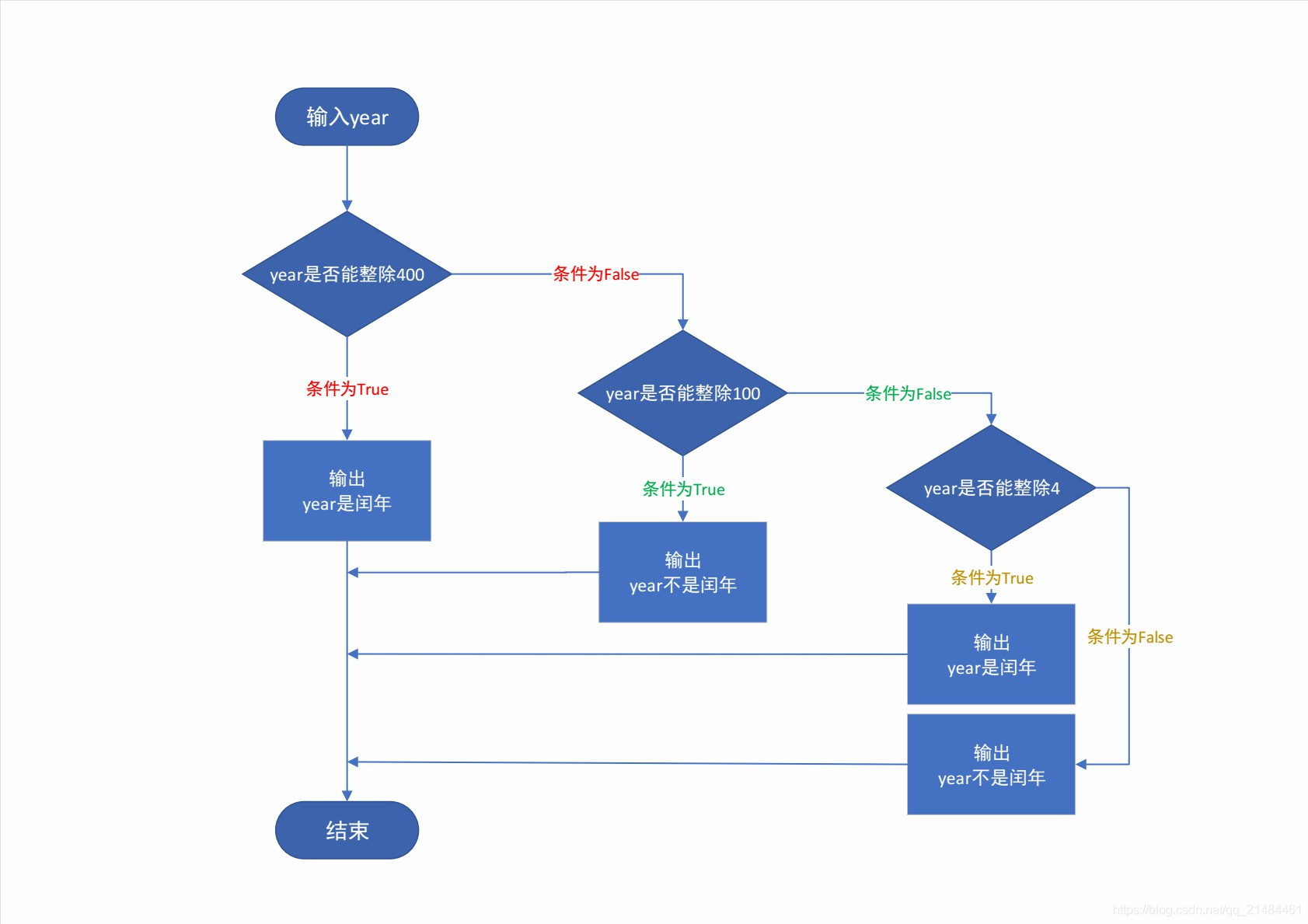
- 一级缓存是 SqlSession 级别的缓存。在操作数据库时需要构造 SqlSession 对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的 SqlSession 之间的缓存数据区域(HashMap)是互相不影响的
- 二级缓存是 Mapper 级别的缓存,多个 SqlSession 去操作同一个 Mapper 的sql语句,多个 SqlSession 可以共用二级缓存,二级缓存是跨 SqlSession 的
- 首先新增测试用例 firstLevelCacheTest,然后同时会发现如果使用(增删改)操作,不管是否已经 commit(),都会清理一级缓存
public class CacheTest {
@Test
public void firstLevelCacheTest() throws IOException {
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
User user1 = sqlSession.selectOne("com.itheima.mapper.UserMapper.findByCondition", 1);
User user = new User();
user.setId(1L);
user.setName("tom");
sqlSession.update("com.itheima.mapper.UserMapper.updateUser",user);
sqlSession.commit();
User user2 = sqlSession.selectOne("com.itheima.mapper.UserMapper.findByCondition", 1);
System.out.println(user1 == user2);
System.out.println(user1);
System.out.println(user2);
sqlSession.close();
}
}
源码分析
- 首先我们主要关注下面的的流程,看看一级缓存的行为,首先执行一次 sqlSession.selectOne() 查询,然后执行一次更新语句,再次执行一次查询
public class CacheTest {
@Test
public void firstLevelCacheTest() throws IOException {
...
User user1 = sqlSession.selectOne("com.itheima.mapper.UserMapper.findByCondition", 1);
User user = new User();
user.setId(1L);
user.setName("tom");
sqlSession.update("com.itheima.mapper.UserMapper.updateUser",user);
sqlSession.commit();
User user2 = sqlSession.selectOne("com.itheima.mapper.UserMapper.findByCondition", 1);
...
}
}
- 第一次调用 sqlSession.selectOne() 时,将会嵌套调用 selectList() 方法,得到 MappedStatement 后,使用 Executor 来执行查询
public class DefaultSqlSession implements SqlSession {
private final Configuration configuration;
private final Executor executor;
...
private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
}
- Executor 实际使用的是 CachingExecutor,执行前,先生成 CacheKey,然后委托 SimpleExecutor 进行查询
public class CachingExecutor implements Executor {
private final Executor delegate;
...
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
...
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
}
- SimpleExecutor 首先从一级缓存 localCache(就是 PerpetualCache,一个 Map)拿取数据,如果获取不了数据就会从数据库查询结果
public abstract class BaseExecutor implements Executor {
...
protected PerpetualCache localCache;
...
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
...
return list;
}
}
- 查询数据的时候,首先会在一级缓存 localCache 插入占位符,然后从数据库查出数据后,将查询数据存入缓存中
public abstract class BaseExecutor implements Executor {
...
protected PerpetualCache localCache;
...
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
}
- 查询到数据后,轮到执行更新语句
public class CacheTest {
@Test
public void firstLevelCacheTest() throws IOException {
...
User user = new User();
user.setId(1L);
user.setName("tom");
sqlSession.update("com.itheima.mapper.UserMapper.updateUser",user);
sqlSession.commit();
...
}
}
- 更新语句的执行同样创建好 MappedStatement 后,由 DefaultSqlSession 交由 CachingExecutor 执行更新操作
public class DefaultSqlSession implements SqlSession {
...
private final Executor executor;
...
@Override
public int update(String statement, Object parameter) {
try {
dirty = true;
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.update(ms, wrapCollection(parameter));
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
}
- CachingExecutor 再委派 SimpleExecutor 执行更新
public class CachingExecutor implements Executor {
...
private final Executor delegate;
...
@Override
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
flushCacheIfRequired(ms);
return delegate.update(ms, parameterObject);
}
}
- 在 SimpleExecutor 执行更新前,就会先去清除一级缓存,不管是否需要 commit(),然后再执行更新操作
public abstract class BaseExecutor implements Executor {
...
protected PerpetualCache localCache;
...
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}
@Override
public void clearLocalCache() {
if (!closed) {
localCache.clear();
localOutputParameterCache.clear();
}
}
}
- 从一级缓存 PerpetualCache 的清理,就完全可以看到,一级缓存就是个 Map 对象保存
public class PerpetualCache implements Cache {
private final String id;
private final Map<Object, Object> cache = new HashMap<>();
...
@Override
public void clear() {
cache.clear();
}
}
- 更新完数据后,然后执行 commit() 操作
public class CacheTest {
@Test
public void firstLevelCacheTest() throws IOException {
...
sqlSession.commit();
...
}
}
- DefaultSqlSession 再次委托 CachingExecutor 执行 commit() 方法
public class DefaultSqlSession implements SqlSession {
private final Executor executor;
...
@Override
public void commit() {
commit(false);
}
@Override
public void commit(boolean force) {
try {
executor.commit(isCommitOrRollbackRequired(force));
dirty = false;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
}
- CachingExecutor 则委派 SimpleExecutor 来执行 commit() 方法
public class CachingExecutor implements Executor {
private final Executor delegate;
...
@Override
public void commit(boolean required) throws SQLException {
delegate.commit(required);
tcm.commit();
}
}
- SimpleExecutor 又会再次清理一级缓存,最后才会执行 commit() 方法
public class CachingExecutor implements Executor {
private final Executor delegate;
...
@Override
public void commit(boolean required) throws SQLException {
if (closed) {
throw new ExecutorException("Cannot commit, transaction is already closed");
}
clearLocalCache();
flushStatements();
if (required) {
transaction.commit();
}
}
@Override
public void clearLocalCache() {
if (!closed) {
localCache.clear();
localOutputParameterCache.clear();
}
}
}
- 更新操作后,再一次执行查询 selectOne() 的流程,但由于一级缓存清空了,所以就没办法从一级缓存获取数据,又会再次从数据库中查询,然后存入一级缓存中。具体流程看回上面的查询流程
- 总结