点击下方链接获取全部内容文档题目及其答案:
10W+前端面试题&面试资料&八股文题目及其答案
https://m.tb.cn/h.5a7v237?tk=QeVPdsoKwr4 CZ3457
部分题目如下:
1. call丶apply丶bind区别及源码实现(手写)
不同点:
- call丶apply 是直接调用;bind 是你返回某个函数,等待某个状态触发再执行
- call 第二个参数开始是以参数列表的形式,apply 的第二个参数是以数组的方式
相同点:
- 都是用来改变函数的 this 对象的指向
- 第一个参数都是 this 要指向的参数
- 都可以利用后续参数传参
应用场景:
-
call丶apply 将伪数组转化为数组(含有 length 属性的对象丶dom节点,函数的参数 arguments)
// 测试 var div = document.getElementsByTagName('div'); console.log(div); console.log([].slice.call(div)); console.log([].slice.apply(div)); -
call 用来判断数据类型
var arr = [1, 2, 3]; console.log(Object.prototype.toString.call(arr)); -
利用 call 和 apply 做继承
function Father(name) { this.name = name; this.showName = function() { console.log(this.name); } } function Son(name) { // Father.call(this, arguments); Father.call(this, name); } var son = new Son('haha'); son.showName(); -
利用 apply 进行数组拼接丶添加
var arr1 = [1, 2, 3]; var arr2 = [4, 5, 6]; [].push.apply(arr1, arr2); console.log(arr1); -
bind 配合 setTimeout 使用
<ul> <li>1</li> <li>2</li> <li>3</li> </ul> <script> var lis = document.getElementsByTagName('li'); for (var i = 0; i < lis.length; i++) { lis[i].onclick = fn; } function fn() { setInterval(function () { console.log(this.innerText) }.bind(this), 1000) //this指向事件源lis[i] } </script> -
bind 在偏函数中的应用
// 偏函数: 固定函数的某一个或几个参数,返回一个新的函数来接收剩下的变量参数 function mul(a, b) { return a * b; } let double= mul.bind(null, 2); alert(double(3)); alert(double(4)); alert(double(5));
call 源码实现
Function.prototype.myCall = function(context) {
if(typeof this != 'function') { // 容错处理 防止调用这个方法的对象不是函数
throw new TypeError('Error');
}
context = context || window;
context.fn = this; // this指向 谁调用这个函数this就指向谁
const args = [...arguments].slice(1); // 参数
const result = context.fn(...args);
delete context.fn;
return result; // 返回一个对象
}
// 测试
function Father(name, price) {
this.name = name;
this.price = price;
}
function Son(name, price) {
Father.myCall(this, name, price);
this.age = 18;
}
var son = new Son('banana', 5)
console.log(son.name);
apply 源码实现
Function.prototype.myApply = function(context) {
console.log(arguments);
if(typeof this != 'function') { // 容错处理 防止调用的这个对象不是函数
throw TypeError('error');
}
context = context || window;
context.fn = this;
var result;
if(arguments[1]) {
result = context.fn(...arguments[1]);
}else {
result = context.fn();
}
delete context.fn;
return result;
}
// 测试用例
function Father(name, price) {
this.name = name;
this.price = price;
}
function Son(name, price) {
Father.myApply(this, [name, price]);
this.age = 18;
}
var son = new Son('banana', 5);
console.log(son.name);
bind 源码实现
// 1. 函数A调用bind方法 需要传递的参数o, x, y, z...
// 2. 返回新的函数B
// 3. 函数B在执行的时候 具体的功能实现实际上还是使用的A 只不过this指向变成了o 不传是window
// 4. 函数B在执行的时候 你传递参数 会拼接到x, y, z的后面 一并在内部传递给A执行
// 5. 当你以new B() 构造函数依旧是A 而且obj这个参数不会起到任何操作
Function.prototype.myBind = function(target) {
var self = this;
var args = [].slice.call(arguments, 1);
var temp = function() {};
var f = function() {
var _args = [].slice.call(arguments, 0);
return self.apply(this instanceof temp ? this : (target || window), args.concat(_args));
}
temp.prototype = self.prototype;
f.prototype = new temp();
return f;
}
// 测试
function get() {
return this.x;
}
var module = {
x: 18
}
var getX = get.myBind(module);
getX();
2. 函数式编程之柯里化
就是把接受多个参数的函数变成接受一个单一函数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术
源码实现
function fixedParamsCurry(fn) { var _args = [].slice.call(arguments, 1); return function() { var newArg = _args.concat([].slice.call(arguments, 0)); return fn.apply(this, newArg); }}function Curry(fn, length) { // 你当前传入的函数需要几个参数 var length = length || fn.length; return function() { if(arguments.length < length) { var combined = [fn].concat([].slice.call(arguments, 0)); return Curry(fixedParamsCurry.apply(this, combined), length - arguments.length); }else { return fn.apply(this, arguments); } }}
优点:
-
参数复用
-
正则校验
-
发送请求
function ajax(method, url, data) { console.log(method, url, data); } var ajaxCurry = Curry(ajax); var postAjax = ajaxCurry('POST'); postAjax('www.test1.com', 'name=hehe&code=111'); postAjax('www.test1.com', 'name=hehe&code=222'); var postTest1Ajax = postAjax('www.test.com'); postTest1Ajax('name=hehe&code=11'); postTest1Ajax('key');
-
-
延迟执行
- 我们 JS 中经常使用的 bind,实现机制就是 Currying
缺点:
- 存取
arguments对象通常比存取命名参数要慢一些 - 一些老版本的浏览器在
arguments.length的实现上是相当慢的 - 使用
fn.apply(...)和apply.call(...)通常比直接调用fn(...)稍微慢 - 创建大量嵌套作用域和闭包函数会带来开销,无论是内存还是速度上
附一道经典面试题
// 实现一个add方法,
add(1)(2)(3) = 6;
add(1, 2, 3)(4) = 10;
add(1)(2)(3)(4)(5) = 15;
// (1)
function add() {
var _args = Array.prototype.slice.call(arguments);
var _add = function() {
_args.push(...arguments);
return _add;
}
_add.toString = function() {
return _args.reduce(function(a, b) {
return a + b;
})
}
return _add;
}
// (2)
function add(a, b, c, d) {
return a + b + c + d;
}
function fixedParamsCurry(fn) {
var _args = [].slice.call(arguments, 1);
return function() {
var newArg = _args.concat([].slice.call(arguments, 0));
return fn.apply(this, newArg);
}
}
function Curry(fn, length) {
// 你当前传入的函数需要几个参数
var length = length || fn.length;
return function() {
if(arguments.length < length) {
var combined = [fn].concat([].slice.call(arguments, 0));
return Curry(fixedParamsCurry.apply(this, combined), length - arguments.length);
}else {
return fn.apply(this, arguments);
}
}
}
var newAdd = Curry(add);
newAdd(1)(2)(3)(4)
3. 防抖 和 节流(手写)
对 DOM 进行操作或者发送 Ajax 请求进行资源的加载,这样是操作很消耗性能的,要知道我们的 JS 是主线程的 这个主线程是单线程的,里面有这个的机制叫事件轮训机制,DOM 操作会触发页面的重排。
防抖
函数防抖就是在函数需要频繁触发情况时,只有足够空闲的时间,才执行一次,好像公交车司机等人都上车才出站一样,等一小段时间没有人再上车才走。
函数防抖源码实现:
function debounce(handler, delay) { var timer = null; return function() { var _self = this, _args = arguments; if(timer) { clearTimeout(timer); } timer = setTimout(function() { handler.apply(_self, _args); }, delay); }}
应用场景:
-
实时搜索
var oInput = document.getElementById('inp');function ajax(e) { console.log(e, this.value);}oInput.oninput = dobounce(ajax, 1000); -
拖拽
节流
函数节流就是预定一个函数只有在大于等于执行周期才执行,周期内不执行,好像水滴攒到一定重量才会落下一样
函数节流源码实现:
function throttle(method, delay) { var last = 0; return function() { var now = + new Date(); if(now - last > delay) { method.apply(this, arguments); last = now; } }}
应用场景:
-
窗口调整 (scroll 滚动事件)
-
页面滚动 (瀑布流的布局或者进行动态页面的加载)
-
抢购疯狂点击 (脚本式的触发事件进行疯狂点击,向服务器发送疯狂的请求,服务器会崩溃)
var oDiv = document.getElementById('show');var oBtn = document.getElementById('btn');function buy(e) { console.log(this, e); oDiv.innerText = parseInt(oDiv.innerText) + 1;}oBtn.onclick = throttle(buy, 1000); -
频繁提交操作
4. 数据处理之扁平化
定义:
数组扁平化,一般用在数组和对象,数组扁平化是指深度很深的对象变成一层,也就是深度为1的对象,数组扁平化是降维过程,是多维数组经过扁平化变成一维的数组
数组拍平也称为数组扁平化,就是将数组里面的数据打开,最后合并为一个数组。
源码实现
- for循环
Array.prototype.flattern = function () { var arr = this || [], resArr = [], len = arr.length; for(var i = 0; i < len; i++) { Object.prototype.toString.call(arr[i]) === '[object Array]' ? resArr = resArr.concat(arr[i].flattern()) : resArr.push(arr[i]); } return resArr;}// 测试var arr = [1, 2, [3, [4, 5], {}, null], [[[6]], 'hehe']]console.log(arr.flattern());
- reduce
Array.prototype.flattern = function(arr) { var arr = this || []; return arr.reduce(function(prev, next) { return Object.prototype.toString.call(next) === '[object Array]' ? prev.concat(next.flattern()) : prev.concat(next); }, [])}
- flat
Array.prototype.flattern = function(arr) { var arr = this || []; return arr.flat(Infinity); }
性能测试用 console.time() 和 console.timeEnd()
总结:
性能最好的是 es6 的 flat 最差是reduce
适用场景:
原数据层级嵌套很深的情况,2层以上有很大的便利,且你所要操作的数据不仅在第一层,更多的增删改查发生在更深的层级
5. JS数据类型以及判断方法
JavaScript 有 七 种数据类型:Number丶String丶Boolean丶undefined丶null丶Object丶Symbol,其中对象类型包括Array丶Function丶RegExp丶Date
按存储类型分类
- 基本类型
- number
- string
- boolean
- null
- undefined
- symbol
- 引用类型
- object
按是否可变分类
- 可变类型
- object
- 不可变类型
- number
- boolean
- string
- null
- undefined
- symbol
按是否可以拥有方法类型
- 可拥有方法类型
- number
- string
- boolean
- object
- symbol
- 不可拥有方法类型
- null
- undefiend
Symbol应用场景
-
作为对象属性,当一个复杂对象中含有多个属性的时候,很容易将某个属性名覆盖掉,利用 Symbol 值作为属性名可以很好的避免这一现象
const name = Symbol('name');const obj = { [name]: 'haha'} -
模拟类的私有方法
const speak = Symbol();class person { [speak]() { }}
判断数据类型的方法
- typeof
typeof 返回的结果为 number丶string丶boolean丶object丶undefined丶function丶symbol
typeof null === ‘object’
缺点:typeof 可以准确地判断出基本类型,但是对于引用类型除了 function 之外返回的都是 object,不能进一步判断它们的类型
- instanceof
A instanceof B:A 的原型链上有没有B 的原型
缺点:从结果看 instanceof 不能区别 undefined 和 null,而且对于基本类型如果不是用 new 声明的则也测试不出来,对于是使用 new 声明的类型,它还可以检测出多层继承关系
- constructor
function F() {}F.prototype = {a: 'xxx'}var f = new F();console.log(f.constructor === F);
缺点:constructor 不能判断 undefiend 和 null,并且使用它是不安全,因为 constructor 的指向是可以改变的
- Object.prototype.toString.call()
JS 怎么判断是一个空对象?
- 最常见的思路,for…in… 遍历属性
function checkNullObj(obj) { for(var prop in obj) { return false; } return true;}
- 通过 JSON 自带的 stringify() 方法来判断
JSON.stringify() 方法用于将 JavaScript 值转换为 JSON 字符串
function checkNullObj(obj) { if(JSON.stringify(obj) === '{}') { return true; } return false; }
- ES6 新增的方法 Object.keys()
object.keys() 方法会返回一个由一个给定对象的自身可枚举属性组成的数组
如果我们的对象为空,它会返回一个空数组,如下:
function checkNullObj(obj) { return Object.keys(obj).length === 0;}
null 和 undeifined 区别?
- undefined 表示一个变量自然的丶最原始的状态值,而 null 则表示一个变量被人为的设置为空对象,而不是原始状态
- 在实际使用过程中,为了保证变量所代表的语义,不要对一个变量显示的赋值 undefined,当需要释放一个对象时,直接赋值为 null 即可
6. JS 原型链和继承(手写)
原型是 function 对象的一个属性,它定义了构造函数构造出来的对象的公共祖先。通过该构造函数产生的对象,可以继承该原型的属性和方法。原型也是对象。
有了原型,原型还是对象,那么这个名为原型的对象自然还有自己的原型,这样的原型上还有原型的结构就构成了原型链。
对象有属性 __proto__,指向该对象的构造函数的原型对象
方法(函数)除了有属性 __proto__,还有属性 prototype,prototype 指向该方法的原型对象
传统形式(原型链继承)
**缺点:**过多继承没用的属性
Grand.prototype.lastName = 'JC';function Grand() {};var grand = new Grand();Father.prototype = grand;function Father() { this.name = 'hehe';}var father = new Father();Son.prototype = father;function Son() {};var son = new Son();
借用构造函数继承(类似继承)
**优点:**可以传参
缺点:
- 不能继承借用构造函数的原型
- 每次构造函数都要多走一个函数
function Person(name, age, sex) { this.name = name; this.age = age; this.sex = sex;}function Student(name, age, sex, grade) { Person.call(this, name, age, sex); this.grade = grade;}var student = new Student('dg', 40, 'male', 18);
组合式继承
(通俗来说就是用原型链实现对原型属性和方法的继承,用借用构造函数继承对实例属性的继承)
**优点:**避免了原型链和构造函数的缺陷,融合他们的优点,成为 JavaScript 中最常用的继承模式
**缺点:**实例和原型链上存在两份相同的属性
Father.prototype.getfaName = function() { console.log(this.faName);}function Father(name) { this.faName = 'father';}Child.prototype = new Father(); Child.prototype.constructor = Child;function Child(args) { this.chName = 'child'; Father.apply(this, []);}var child = new Child();
共享原型
**缺点:**不能随便改动自己的原型
Father.prototype.lastName = 'Deng';function Father() {};function Son() {};Son.prototype = Father.prototype;var son = new Son();var father = new Father();
圣杯模式(寄生组合继承)
// 第一种写法function inherit(Target, Origin) { function F() {}; F.prototype = Origin.prototype; Target.prototype = new F(); Target.prototype.constructor = Target; Target.prototype.uber = Origin.prototype;}// 第一种写法var inherit = (function() { function F() {}; return function(Target, Origin) { F.prototype = Origin.prototype; Target.prototype = new F(); Target.prototype.constructor = Target; Target.prototype.uber = Origin.prototype; }})();
7. JS 精度丢失不准确的问题,如何解决
- 计算机编程语言里浮点数计算会存在精度丢失问题(或称舍入误差),其根本原因是二进制和实现位数限制有些数无法有限表示。
- 计算机里每种数据类型的存储是一个有限宽度,比如 JavaScript 使用 64 位存储数字类型,因此超出的会舍去。舍去的部分就是精度丢失的部分。
- 小数进行算术运算时,实质上就是把十进制的浮点数转化为二进制,这样的结果是无穷的,JS最多有2的53次方有效数字,并不是精准的,所以
解决方案
-
toFixed,指要保留的小位数,这个方法是四舍五入,也不是很精确,对于计算金额的话,不推荐使用,而且不同浏览器对于toFixed的计算结果也存在差异
(0.1 + 0.2).toFixed(1); -
把需要计算的数字升级(乘以10的n次幂)成计算机能够精确识别的整数,等计算完毕再降级(除以10的n次幂),这是大部分变成语言处理精度丢失的通用方法
(0.1 * 10 + 0.2 * 10) / 10 === 0.3;
8. 异步编程的四种方案
为什么会有异步?
JS的执行的环境 为 单线程,这种模式比较简单,执行环境相对单纯,坏处是一个任务耗时很长,后面的任务都必须排队等着,会拖延整个程序的执行。
常见的浏览器无响应(假死),往往就是因为某段 JavaScript 代码长时间执行(比如死循环),导致整个页面卡在这个地方,其他任务无法执行。
所以JavaScript语言将 任务执行模式 分为两种 同步 和 异步。
异步执行模式的应用场景有哪些?
在浏览器端,耗时很长的操作应该异步执行,避免浏览器失去响应,最好的例子是 ajax 请求。
在服务端,异步模式 甚至是唯一的模式,因为执行环境是单线程,如果允许同步执行所有的 http 请求,服务端性能会急剧下降,很快就会失去响应。
回调函数(callback)
function loadingDo(callback) { console.log(111); // 同步代码 setTimeout(() => { callback(); }, 2000)}function printMe() { console.log('回调函数来了......');}loadingDo(printMe);
优点:
-
解决了同步的问题(只要有一个任务耗时过长,后面的任务都必须排队等着,会拖延整个程序的执行)
-
简单丶容易理解和实现
缺点:
- 回调地狱,不能用 try catch 捕获错误,不能 return
回调地狱的根本问题在于:
- 缺乏顺序性:回调地狱导致的调试困难,和大脑的思维方式不符
- 不利于代码的阅读和维护,各个部分之间高度耦合,流程会很混乱(多个回调函数嵌套的情况),一旦有所改动,就会牵一发而动全身
- 而且每个任务只能指定一个回调函数
$.ajax(url1, () => { // 处理逻辑 $.ajax(url2, () => { // 处理逻辑 $.ajax(url3, () => { // 处理逻辑 }) })})
事件监听
采用事件驱动模式,任务的执行不取决于代码的顺序,而取决于某个事件是否发生
f1.on('done', f2);fucntion f1() { setTimeout(function() { // f1的任务代码 f1.trigger('done'); }, 1000)}
优点:
-
比较容易理解,可以绑定多个事件,每个事件指定多个回调函数,而且可以 去耦合
-
有利于实现模块化
缺点:
-
整个程序都要变成事件驱动型,运行流程会变得很不清晰
-
通过代码不能很明确的判断出主流程
发布/订阅
我们假定存在一个“信号中心”,当某个任务执行完毕就向信号中心发出一个信号(事件),然后信号中心收到这个信号之后将会进行广播。如果有其他任务订阅了该信号,那么这些任务就会收到一个通知,然后执行任务相关的逻辑。
function Event() {
// 存储不同的事件类型对应处理不同的处理函数 保证后续的emmit可以执行
this.cache = {};
}
Event.prototype.on = function(type, handle) {
if(!this.cache[type]) {
this.cache[type] = [handle];
}else {
this.cache[type].push(handle);
}
}
Event.prototype.emmit = function() {
// 没有保证参数是多少个 就用arguments
var type = arguments[0];
var arg = [].slice.call(arguments, 1);
for(var i = 0; i < this.cache[type].length; i++) {
this.cache[type][i].apply(this, arg);
}
}
Event.prototype.empty = function(type) {
this.cache[type] = [];
}
Event.prototype.once = function(type, handle) {
var _this = this;
function on() {
_this.off(type, on);
handle.apply(_this, arguments);
}
on.handle = handle;
_this.on(type, on);
}
Event.prototype.off = function (type, handle) {
let handles = this.cache[type];
// 如果缓存列表中没有响应的handles,返回false
if(!handles) {
return false;
}
if(!handle) {
// 如果没有传handle的话,就会将type值对应缓存列表中的handle都清空
handles && (handles.length = 0);
}else {
// 若有fn,遍历缓存列表,看看传入的fn与哪个函数相同,如果相同就直接从缓存列表中删除即可
let cb;
for(let i = 0, cbLen = handles.length; i < cbLen; i++) {
cb = handles[i];
if(cb === handle || cb.handle === handle) {
handles.splice(i, 1);
break;
}
}
}
}
// 测试
function deal1(time) {
console.log('overtime1 ' + time);
}
function deal2(time) {
console.log('overtime2 ' + time);
}
function deal3(time) {
console.log('overtime3 ' + time);
}
function deal4(time) {
console.log('overtime4 ' + time);
}
// 测试
var oE = new Event();
oE.on('over', deal1);
oE.on('over', deal2);
oE.on('over', deal3);
oE.once('over2', deal4);
oE.off('over', deal1);
oE.emmit('over', 'first-2020-9-6');
oE.emmit('over2', 'second-2020-9-7');
console.log('---------');
oE.emmit('over', 'first-2020-9-6');
oE.emmit('over2', 'second-2020-9-7');
优点:
-
这个方法的性质与 事件监听 类似,但是明显优于后者。因为可以通过查看 消息中心,了解存在多少信号丶每个信号有多少订阅者,从而监控程序的运行。
-
对象之间的解耦,异步编程中,可以更松耦的代码编写
缺点:
-
创建订阅者本身要消耗一定的 时间和内存
-
虽然可以弱化对象之间的联系,多个发布者和订阅者嵌套在一起的时候,程序难以跟踪维护
Promise原理
Promise出现的原因
为了获取异步结果,获取大量函数。当需要发送多个请求,且每个请求之间需要相互依赖时,我们只能嵌套的形式来解决
当处理多个异步逻辑时,就需要多层的回调函数嵌套,也就是我们常说的回调地狱
let url1 = 'http://haha1.com';
let url2 = 'http://haha2.com';
let url3 = 'http://haha3.com';
$.ajax({
url: url1,
error: function(err) {},
success: function(data1) {
console.log(data1);
$.ajax({
url: url2,
data: data1
error: function(err) {},
success: function(data2) {
console.log(data2);
$.ajax({
url: url3,
data: data2
error: function(err) {},
success: function(data3) {
console.log(data3);
}
})
}
})
}
})
回调地狱这种编码模式的主要问题是:
-
代码臃肿
-
可读性差
-
耦合度高,可维护性差
-
代码复用性差
-
容易滋生bug
-
只能在回调里面处理异常
定义: Promise 是异步编程的一种解决方案,所谓的 Promise 简单来说就是一个容器,里面保存着未来才会结束的事件的结果。比传统的异步解决方案【回调函数】和【事件】更合理丶更强大。
特点:
-
Promise 对象接受一个回调函数作为参数,该回调参数接受两个参数,分别是成功时的回调 resolve 和失败时的回调 reject;另外 resolve 的参数除了正常值以外,还可能是一个 Promise 对象的实例; reject 的参数通常是一个 Error 对象的实例
-
then 方法返回一个新的 Promise实例 ,并接收两个参数 onResolved(fulfilled状态的回调);onRejected(rejected状态的回调,该参数可选)
-
catch 方法返回一个新的 Promise 实例
-
finally 方法不管 Promise 状态如何都会执行,该方法的回调函数不接受任何参数
-
promise.all 方法将多个 Promise 实例,包装成一个新的 Promise 实例,该方法接受一个由 Promise 对象组成的数组作为参数(Promise.all()方法的参数可以不是数组,但必须有 iterator 接口,且返回的每个成员都是 Promise 实例),注意参数中主要有一个实例触发catch方法,都会触发。Promise.all()方法返回的新的实例的catch方法,如果参数的某个实例本身调用了catch方法,将不会触发Promise.all()方法返回的新实例的catch方法
-
Promise.race() 方法的参数与 Promise.all() 方法一样,参数中的实例只要有一个率先改变状态就会将该实例的状态传给 Promise.race() 方法,并将返回值作为 Promise.race() 方法产生的 Promise 实例的返回值
-
Promise.resolve() 将现有对象转化为 Promise 对象,如果该方法的参数为一个 Promise对象,Promise.resolve() 将不再做任何处理;如果参数 thenable 对象(即具有then方法),
Promise.resolve()将该对象转为Promise对象并立即执行then方法;如果参数是一个原始值,或者是一个不具有then方法,则Promise.resolve方法返回一个新的Promise对象,状态为fulfilled,其参数将会作为then方法中onResolved回调函数的参数,如果Promise.resolve方法不带参数,会直接返回一个fulfilled状态的Promise对象。
需要注意的是,立即 resolve()的Promise对象,是在本轮 事件循环 的结束的时执行,而不是在下一轮 事件循环 的开始时
-
Promise.reject() 方法同样返回一个新的 Promise 对象,状态为 rejected,无论传入任何参数都将作为 reject() 的参数
-
对象的状态不受外界影响,Promsie 对象代表一种异步操作,有三种状态: pending(进行中) 丶fulfilled(已成功)丶
rejected(已失败),其中pending为初始状态,只有异步操作的结果可以改变状态,其它的任何操作都不能改变状态。 -
一旦状态改变了,就不会再变了,任何时间都可以得到这个结果。Promsied 对象的状态只有两种可能: pending->fulfilled 或 pending->rejected,只要这两种情况发生,并且一直保持这个结果。
如果改变发生了,你再对 Promise 对象添加回调函数,也会立即得到这个结果。这与事件监听不同,事件监听的特点是你错过再去监听的话,是得不到结果的。
优点:
-
统一异步API
Promise 的一个重点优点是它逐渐被用作浏览器的异步 API,统一现在各种各样的 API,以及不兼容的模式和手法
-
Promise与事件对比
和事件相比,Promise 更适合处理一次性的结果。在结果计算出来之前或之后注册回调函数都是可以的,都可以拿到正确的值。Promise 的这个优点很自然,但是不能使用 Promise 处理多次触发的事件。链式处理是 Promise 的又一优点,但是事件不能这样链式处理
-
Promise 与回调对比
解决了回调地狱的问题,将异步操作以同步操作的流程表达出来
-
Promise 带来的额外好处是包含了更好的错误处理方式(包含了异常处理),并且写起来很轻松(因为可以重用一些同步的工具),比如Array.prototype.map()
缺点:
-
首先不能取消 Promise,一旦创建它就会立即执行,中途无法取消
-
其次,如果还不设置回调函数,Promise 内部抛出的错误,不会反映到外部
-
最后,当处于 Pending 状态,无法得知目前进展到哪一个阶段了
-
Promise 真正执行回调的时候,定义 Promise 那部分实际上已经走完了,所以Promise的报错堆栈上下文不太友好
Promise构造函数是同步还是异步执行,then呢?
Promise 如何实现 then 处理,动手实现 then?
Promise.resolve(obj),obj 有几种可能?
Promise.resolve(value)方法返回一个以给定值解析后的Promise对象。
- promise对象:如果这个值是一个
promise,你们将返回这个promise - thenable: 如果这个值是
thenable(即带有then这个方法) 返回的Promise会跟随这个thenable的对象,采用它的最终状态 - 正常值:否则返回的Promise将以此值完成,此函数将类Promise对象的多层嵌套展平
const promise1 = Promise.resolve(123);
promise1.then((value) => {
console.log(value)
})
Promsie源码实现
// 同步
// 异步
// then链式操作
// 处理返回普通值
// 处理返回Promise值
// then异步操作
// then捕获操作
// 空then
// 同步
// 异步:以前是先去执行状态直接变 然后再去注册的时候 在注册中直接判断完直接执行这个回调就可以了
// 现在不一样了 你要去想注册 然后再改变这个状态 此时再用这种方式就不能感知这种状态的变化
// 可以用一个数组想存起来 你去注册一个函数的时候 我先不去执行 我先去存储
// 真正用到你的时候再去执行
function MyPromise(executor) {
var self = this;
self.status = 'pending';
// Promise.then这种方式就拿不到了你传的形参,让形参变成Promsie对象自己的值
// 这样在其他地方就可以用到它了
self.resolveValue = null;
self.rejectReason = null;
// 回调数组 你先去注册一个函数我不执行 然后等你真正res/rej的时候我再执行
self.resolveCallBackList = []; // 存储注册成功的函数
self.rejectCallBackList = []; // 存储注册失败的函数
function resolve(value) {
if(self.status === 'pending') { // 只有处于等待的状态你才能去改变你这样的状态 如果你是Fulfilled或Reject状态是不能再进行状态切换的
self.status = 'Fulfilled';
self.resolveValue = value; // 赋值 方便后续传递获取到
self.resolveCallBackList.forEach(function(ele) { // 真正触发的时候把数组里面的东西拿出来
ele();
});
}
}
function reject(reason) {
if(self.status === 'pending') {
self.status = 'Reject';
self.rejectReason = reason;
self.rejectCallBackList.forEach((ele) => {
ele();
})
}
}
// 捕获同步代码是否出现异常 如果出现异常的话 可以通过try catch的方式捕获到
// 捕获到的话reject来执行 把捕获到的信息往外一传
// 首先它同步执行的时候你会感知到它是否抛出的错误了 如果真的抛出错误的话
// 相应的去执行这个reject
try{
executor(resolve, reject); // 立即执行函数
}catch(e) {
reject(e);
}
}
// 现在的返回值不单单是普通的返回值 只是做一个普通的处理
// 返回值有普通值和Promsie对象 这个函数做一个统一处理
function ResolutionReturnPromsie(nextPromise, returnValue, res, rej) {
if(returnValue instanceof MyPromise) { // 返回对象是Promise
returnValue.then(function() { // 在这块给你注册成功和失败的回调的话 外部使用的话一定会触发到你
// 你就注册成功和失败的回调我去通过.then载下面注册成功和失败的回调,相应的执行
res(val);
}, function() {
rej(reason);
})
}else { // 普通值
res(returnValue);
}
}
MyPromise.prototype.then = function(onFulfilled, onRejected) { // 成功的回调函数,失败的回调函数
// 如果没有传参数 空then处理
// 透视的本质不是忽视 而是你交给我的东西 我完全不去修改 原封不动的传递给下一位 这就是你填一个空then它内部是这么做的
if(!onFulfilled) {
onFulfilled = function(val) {
return val;
}
}
if(!onRejected) {
onRejected = function(reason) {
throw new Error(reason); // 你这个错误抛到我这里来我再给你下一个去 这个透视的本质并不是忽视 而是你交给我的东西我不去修改原封不动的传递给下面 这是你添加一个空then内部是这样来做的
}
}
var self = this;
var nextPromise = new MyPromise(function(res, rej) {
if(self.status === 'Fulfilled') {
setTimeout(function() { // 注册这个回调函数执行的时候是异步的方式来执行的
try { // then中抛出错误
var nextResolveValue = onFulfilled(self.resolveValue);
ResolutionReturnPromsie(nextPromise, nextResolveValue, res, rej);
}catch(e) {
rej(e);
}
}, 0)
}
if(self.status === 'Rejected') {
setTimeout(function() {
try{
var nextResolveValue = onRejected(self.rejectReason);
ResolutionReturnPromsie(nextPromise, nextResolveValue, res, rej);
}catch(e) {
rej(e);
}
}, 0)
}
// 异步判断 无论是同步的事情和异步的事情它都能解决 新注册函数
if(self.status === 'pending') {
self.resolveCallBackList.push(function() {
setTimeout(function() {
try{
var nextResolveValue = onFulfilled(self.resolveValue);
ResolutionReturnPromsie(nextPromise, nextResolveValue, res, rej);
}catch(e) {
rej(e);
}
}, 0)
})
self.rejectCallBackList.push(function() {
setTimeout(function() {
try {
var nextRejectValue = onRejected(self.rejectReason);
ResolutionReturnPromsie(nextPromise, nextResolveValue, res, rej);
}catch(e) {
rej(e);
}
}, 0)
})
}
})
return nextPromise; // 每次都返回一个promise对象
}
MyPromise.race = function(promiseArr) {
return new MyPromise(function(resolve, reject) {
promiseArr.forEach(function(promise, index) { // 循环每个Promise对象 给他注册一个成功和失败的回调函数 成功和失败的回调执行的是"new MyPromise"里面的resolve和reject 只要它状态改变了 再去触发状态不会变了
promise.then(resolve, reject);
})
})
}
// Promise.all();
// 1. 接收一个Promsie实例的数组或具有Iterator接口的对象作为参数
// 2. 这个方法返回一个新的promise对象
// 3. 遍历传入的参数,用Promsie.resolve()将参数“包一层”,使其变成一个promise对象
// 4. 参数所有回调成功才是成功,返回值数组与参数顺序一致
// 5. 参数数组其中一个失败,则触发失败状态,第一个触发失败的Promsie错误信息作为Promsie.all的错误信息
// 应用场景:
// 1. 一个页面,有多个请求,我们需求所有的请求都返回数据后再一起处理渲染
// 测试
let p1 = new MyPromise(function(resolve, reject) {
setTimeout(function() {
resolve(1);
}, 1000)
})
let p2 = new MyPromise(function(resolve, reject) {
setTimeout(function() {
resolve(2);
}, 2000)
})
let p3 = new MyPromise(function(resolve, reject) {
setTimeout(function() {
resolve(3);
}, 3000)
})
MyPromise.all([p1, p2, p3]).then(res => {
console.log(res);
})
用 Promise 封装一个 ajax?
const promiseAjax = function() {
function formatParams(param) {
var arr = [];
for(var name in param) {
arr.push(encodeURIComponent(name) + '=' + encodeURIComponent(param[name]));
}
arr.push(('v=' + Math.random()).replace(".", ""));
return arr.join('&');
}
if(!data) {
data = {};
}
data.params = data.params || {};
return new Promise((resolve, reject) => {
data.params = formatParams(data.params);
if(data.type === 'get') {
data.params = formatParams(data.params);
xhr.open("GET", data.url + "?" + data.params, true);
xhr.send(null);
}else if(options.type === 'post') {
xhr.open('POST', data.url, true);
xhr.setRequestHeader('Content-type', 'application/json');
xhr.send(data.params);
}
xhr.onreadystatechange = function() {
if(xhr.readyState === 4) {
if(xhr.status === 200) {
resolve(xhr.response);
}else {
reject(xhr.responseText);
}
}
}
})
}
Promise 链式调用如何实现的?
链式调用流程
- promise1 = new Promise((excutor = (resolve, reject) => {…}))中的 executor 是立即执行的,但最后执行resolve 可能是在异步操作中
- promise1.then 会给 promise1 添加回调,然后返回一个新的 promise2,这个新的 promise2 的决议依靠之前回调中的 resolvePromise 方法
- promise1 决议后执行回调,首先执行 then 中传入的 onFulfilled(promise1.value ),赋值给变量x,再执行resolvePromise(promise 2.x, promise2Resolve, promise2Reject)
- 如果 x 是个已决议的 Promise 或者普通的数据类型,那么就可以 promise2Resolve(x) 决议 promise2
- 如果 x 是个 pending 状态的 promise 或者 thenable 对象,那么执行 x.then,将 resolvePromise 放入 x 的成功回调队列,等到 x 决议 后将 x.value 成功赋值,然后执行 resolvePromise(promise2, x.value, promise2Resolve, promise2Reject)
- 在此期间如果执行了 promise2.then,就新建一个 promise3 并返回,将传入的 onFulfilled(promise2.value)和针对 promise3 的 resolvePromise 传入 promise2 的成功回调队列中,等待 promise2 的决议
- promise3.then 同上,就此实现了链式调用
链式调用顺序
- promise1 => promise2 => promise3,因为 promise2 的要在 promise1 的成功回调里执行
链式调用透传
- 如果 promise1.then 传入的 onFulfilled 不是一个函数,此时 onFulfilled 会被改写成 value => value
Generator/yeild
ES6 新引入的 Generator 函数,可以通过 yeild 关键字,把函数的执行挂起,通过 next() 方法可以切换到下一个状态,为了执行流程提供了可能,从而为异步编程提供了解决方案。
function *fetch() {
yeild $.ajax('www.xxx1.com', () => {});
yeild $.ajax('www.xxx2.com', () => {});
yeild $.ajax('www.xxx3.com', () => {});
}
let it = fetch();
let result1 = it.next();
let result2 = it.next();
let result3 = it.next();
特点
-
控制控制函数的执行,可以配合 CO 函数库使对象
-
Generator 需要手动调用 next() 就能执行下一步
-
Generator 返回的是生成器对象
-
Generator 不能够返回 Promise 的 resolve/reject 的值
实现原理
async await 原理
在多个回调依赖的场景中,尽管 Promsie 通过链式调用取代了回调嵌套,但过多的链式调用可读性仍然不佳,流程控制也不方便,ES7 提出的 async 函数,终于让JS 对于异步操作有了终极解决方案,简洁优美地解决了以上问题
设想一个这样的场景,异步任务a -> b -> c之间存在关系,如果我们通过 then 链式调用处理这些关系,可读性并不是很好,如果我们想控制其中某个过程,比如在某些条件下,b 不往下执行到 c,那么也不是很方便控制
Promise.resolve(a)
.then(b => {
// do something
})
.then(c => {
// do something
})
但是如果通过 async/await 来实现这个场景,可读性和控制流程都会方便不少
async() => {
const a = await $.ajax({
'url': 'www.xxx1.com'
})
cosnt b = await ({
'url': 'www.xxx1.com',
'params': a
});
const c = await.resolve({
'url': 'www.xxx1.com',
'params': b
});
}
**优点:**代码清晰,不用像 Promise 写一堆 then 链,处理了回调地狱的问题
**缺点:**await 将异步代码改造成同步代码,如果多个异步操作没有依赖性而使用 await 会导致性能上的降低
async function test() {
// 以下代码没有依赖性的话,完全可以使用Promise.all的方式
// 如果有依赖性,其实就是解决回调地狱的例子了
await fetch('www.xxx1.com');
await fetch('www.xxx2.com');
await fetch('www.xxx3.com');
}
Promise 和 async/await,和 Callback 有什么区别?
Async 里面有多个 await 请求,可以怎么优化?
// 串行请求
const showColumnInfo = async (id) => {
console.time('showColumnInfo');
const Promise1 = await getColumn('awaitPromise1');
const Promise2 = await getColumn('awaitPromise2');
console.log(`name${Promise1.name}`);
console.log(`descript:${Promise1.description}`);
console.log(`name:${Promise2.name}`);
console.log(`description:${Promise2.description}`);
console.timeEnd('showColumnInfo');
}
showColumnInfo();
1. 可以使两个请求并行处理
const showColumnInfo = async(id) => {
console.time('showColumnInfo');
const Promise1 = getColumn('awaitPromise1');
const Promise2 = getColumn('awaitPromise2');
const awaitPromise1 = await Promise1;
const awaitPromise2 = await Promise2;
console.log(`name: ${awaitPromise1.name}`);
console.log(`descript:${awaitPromise1.description}`);
console.log(`name: ${awaitPromise2.name}`);
console.log(`descript:${awaitPromise2.description}`);
}
2. 使用 Promise.all() 可以让多个 await 操作并行
const showColumnInfo = async(id) {
console.time('showColumnInfo');
const [Promise1, Promise1] = await Promise.all([
getZhihuColumn('Promise1'),
getZhihuColumn('Promise2')
])
console.log(`name: ${Promise1.name}`);
console.log(`description: ${Promise1.description}`);
console.log(`name: ${Promise2.name}`);
console.log(`description: ${Promise2.description}`);
console.timeEnd('showColumnInfo');
}
showColumnInfo();
对 async丶await 的理解,内部实现原理是怎么样?
async/await 是 Generator 函数的语法糖,并对 Generator 函数进行了改进
async:声明了一个异步函数,自动将常规转换成 promise,返回值也是一个 promise 对象,只有 async 函数内部的异步操作执行完,才会执行 then 方法指定的回调函数,内部可以使用 await
await:暂停异步的功能执行,放在 promise 调用之前,await 强制其他代码等待,直到 promise 完成并返回结果,只能与 promise 一起使用,不适用与回调,只能在 async 函数内部使用
Async 函数对 Generator 函数的改进,体现在以下四点:
- **async 内置执行器:**Generator 函数的执行必须依靠执行器,而 async 函数自带 执行器,无需手动执行 next 方法
- **更好的语义:**async 和 await,比起 星号 和 yeild,语义更清楚了。async 表示函数里面异步操作,await 表示紧跟在后面的表达式需要等待结果
- **更广的适应性:**co 模块约定,yeild 命令后面只能是 Thunk 函数或 Promise对象,而 async函数的 await 命令后面,可以是 Promise 对象和原始类型的值(数值丶字符串和布尔值,但这时会自动转成立即 resolved 的 Promise 对象)
- **返回值是 Promise:**await 返回值是 Promsie对象,比 Generator 函数返回的 Iterator 对象方便,可以直接使用 then() 方法进行调用。
特点
- async await 与 Promise 一样,是非阻塞的。
- async await 是基于 Promise 实现的,可以说是改良版的 Promise,它不能用于普通的回调函数
- async await 使得异步代码看起来像同步代码,这正是它的魔力所在
使用
let fs = require('fs');
function read(file) {
return new Promise(function(resolve, reject) {
fs.readFile(file, 'utf8', function(err, data) {
if(err) reject(err);
resolve(data);
})
})
}
function readAll() {
read1();
read2();
}
async function read1() {
let r = await read('1.txt', 'utf8');
console.log(r);
}
async function read2() {
let r = await read('2.txt', 'utf8');
console.log(r);
}
readAll();
// 写在index.js文件下 命令运行: node index.js
async await 源码实现
async函数的实现原理就是将 Generator 函数和自动执行器包装在一个函数里
const myAsync = (gen) => {
return new Promise((resolve, reject) => {
let g = gen();
function step(val) {
try {
var res = g.next(val);
}catch(e) {
return reject(e);
}
if(res.done) {
return res.value;
}
Promise.resolve(res.value).then(val => {
step(val);
}, err => {
g.throw(err);
})
}
step();
})
}
function* myGenerator() {
try {
console.log(yield Promise.resolve(1));
console.log(yield 2);
console.log(yield Promise.reject('error'));
}catch(error) {
console.log(error);
}
}
const result = myAsync(myGenerator);
// 通过递归调用生成器对象next函数
function _asyncToGenerator(fn) {
return function() {
var self = this,
args = arguments;
return new Promise(function(resolve, reject) {
var gen = fn.apply(self, args);
function _next(value) {
asyncGeneratorStep(gen, resolve, reject, _next, _throw, 'next', value);
}
// 抛出异常
function _throw(err) {
asyncGeneratorStep(gen, resolve, reject, _next, _throw, 'throw', err);
}
// 第一次触发
_next(undefined);
})
}
}
// 上次Promsie这些完成后,立即执行下一步,迭代器状态done=true时结束
function asyncGeneratorStep(gen, resolve, reject, _next, _throw, key, arg) {
// console.log(gen, resolve, reject, _next, _throw, key, arg);
try {
var info = gen[key](arg);
var value = info.value;
}catch(e) {
reject(error);
return;
}
if(info.done) {
resolve(value);
}else {
Promise.resolve(value).then(_next, _throw);
}
}
// 测试
// const asyncFunc = _asyncToGenerator(function* () {
// console.log(1);
// yield new Promise(resolve => {
// setTimeout(() => {
// resolve();
// console.log('sleep 1s');
// }, 1000)
// })
// console.log(2);
// const a = yield Promise.resolve('a');
// console.log(3);
// const b = yield Promise.resolve('b');
// const c = yield Promise .resolve('c');
// return [a, b, c];
// })
// asyncFunc().then(res => {
// console.log(res);
// })
// 对比
// const func = async () => {
// console.log(1);
// await new Promise((resolve) => {
// setTimeout(() => {
// resolve ();
// console.log('sleep 1s');
// }, 1000)
// })
// console.log(2);
// const a = await Promise.resolve('a');
// console.log(3);
// const b = await Promise.resolve('b');
// const c = await Promise.resolve('c');
// return [a, b, c];
// }
// func().then(res => {
// console.log(res);
// })
JavaScript 异步解决方案的发展历程以及优缺点?
-
callback
- 优点:逻辑简单
- 缺点:深层次产生回调地狱
-
Promise
- 优点:一旦改变状态,就不会再变,任何时候都可以得到这个结果;可以将异步的操作以同步操作的流程表达出来,避免了层层嵌套的回调函数
- 缺点:无法取消;当处理 pending 状态时,无法得知目前进展到哪一个阶段
-
Generator
- 优点:执行可控;每一步可以传递数据,也可以传递异常
- 缺点:控制流程复杂,插本较高
-
async/await
- 优点:代码清晰,不需链式调用就可以处理回调地狱的问题;错误可以被 try catch
- 缺点:控制流程复杂,成本较高
9. JS 执行机制/事件循环机制
JavaScript 单线程的目的
JavaScript 是一门单线程解释型语言,这意味着在同一个时间下,我们只能执行一条命令,之所以它是一门单线程语言,和它的用途有关。
JavaScript 设计出来的目的初衷是为了增强浏览器和用户的交互,因为 JavaScript 是一门解释型的语言,而解释器内嵌于浏览器,这个 解释器 是 单线程 的。
之所以不设计成多线程是因为 渲染页面 的时候 多线程 容易 引起死锁或资源冲突等问题。例如,假定 JavaScript 同时有两个线程,一个线程在某个 DOM 节点上添加内容,而在另一个线程上删除了这个节点,这时候浏览器应该以哪个线程为准呢?但是浏览器本身是多线程的,比如解释运行 JavaScript 的同时还在加载网络资源。
为什么会有 Event Loop ?
JavaScript 的任务分为 同步 和 异步,它们的处理方式也各自不同,同步任务是直接放在 主线程 排队依次执行,异步任务会放在 任务队列 中,若有多个异步任务则需要在任务队列中排队等候,任务队列类似于 缓冲区,任务的下一步会被移到 调用栈,然后主线程执行 调用栈 的任务
JavaScript 是单线程的,单线程是 JS 引擎中解析和执行 JS 代码的线程只有一个(主线程),每次只能做一件事情,然而 ajax 请求中,主线程在等待响应的过程中回去做其他事情,浏览器会先在事件表注册 ajax 的回调函数,响应回来后回调函数被添加到任务队列中等待执行,不会造成线程阻塞,所以说 JS 处理 ajax 请求是异步的
综上所诉,检查调用栈是否为空以及讲某个任务添加到调用栈中的过程就是 event loop,这就是 JavaScript 实现异步的的核心
回调函数和任务队列的区别?
回调函数
回调函数是作为参数传给另一个函数的函数,这个函数会在另一个函数执行完成后执行
任务队列
任务队列是一个事件的队列,IO 设备完成一项任务后,就在队列中添加一个事件,表示相关的异步任务可以进入执行栈了。
**同步任务:**主线程上排队执行的任务,前一个任务完成后才能执行下一个任务
**异步任务:**不进入主线程,进入任务队列的任务。只有当主线程的同步任务执行完成后,主线程会读取任务队列中的任务,开始异步执行。
任务队列中的事件包括 IO 设备的事件丶用户产生的事件。只要指定过回调函数,这些事件发生时就会进入任务队列,等待主线程读取。
异步任务必须指定回调函数,当主线程开始这些异步任务,就是这些对应的回调函数
微任务和宏任务的区别?
微任务和宏任务是异步任务的两个种类。
宏任务:当前调用栈中执行的代码称为宏任务(主代码块丶定时器等)
微任务:当前(此次事件循环中)宏任务执行完,在下一个宏任务开始之前需要执行的任务,可以理解为回调事件。(promise.then丶process.nextTick等等)
宏任务的事件放在 callback queue 中,由 事件触发线程 维护;微任务的事件放在 微任务队列 中,由 JS引擎线程 维护
在挂起任务时,JS 引擎会将所有任务按照类别分到这两个队伍中,首先在宏任务的队列中取出第一个任务,执行完成后取出微任务的队列中的所有任务顺序执行;之后再执行宏任务任务,周而复始,直到两个队列的任务都取完
JavaScript为什么要区分微任务和宏任务?
区分 微任务 和 宏任务 是为了将 异步队列任务 划分为 优先级,通俗的理解就是为了 插队。
一个 Event Loop,微任务 是在 宏任务 之后调用,微任务 会在下一个 Event Loop 之前执行调用完毕,并且其中会将 微任务 执行当中新注册的微任务一并调用执行完,然后才开始下一次 Event Loo ,所以如果有新的宏任务就需要一直等待,等到上一个 Event Loop 当中微任务被清空为止。由此可见,我们可以在下一个 Event Loop 之前进行插队。
如果不区分 微任务 和 宏任务 ,那就无法在下一次 Event Loop 之前进行插队,其中新注册的任务等到下一个宏任务完成之前进行,这中间可能你需要的状态就无法在一个宏任务中等到同步。
介绍宏任务和微任务?
任务机制
介绍 宏任务 和 微任务 之前需要先了解 任务执行机制
JavaScript 是 单线程语言。JavaScript 任务需要排队顺序执行,如果一个任务耗时过长,后边一个任务也得等着,但是,假如我们需要浏览新闻,但新闻包含的超清图片加载很慢,总不能网页一直卡着直到图片完全出来,所以将任务设计成了两类:同步任务 和 异步任务。
同步任务 和 异步任务 分别进入不同的执行“场所”,同步任务 进入 主线程,异步任务 进入 Event Table 并 注册函数。当指定的事情完成时,Event Table 会将这个函数移入 Event Queue。主线程 内的任务执行完毕,会去Event Queue 读取对应的函数,进入主线程。
上述过程不断重复,也就是常说的Event Loop(事件循环)
异步任务中的宏任务和微任务
事件循环
- 宏任务执行结束
- 看看有可行的微任务
- 有的话执行所有的微任务,然后开始新的宏任务
- 没有的话,开始新的宏任务
微任务(microtask)
当前(此次事件循环中)宏任务执行完,在下一个宏任务开始之前需要执行的任务,可以理解为回调事件
宏任务中的事件放在 callback queue 中,由 事件触发线程 维护;微任务的事件放在微任务队列中,由 JS引擎线程 维护。
- Promise
- Object.observe(已经废弃)
- MutationObserve
- process.nextTick(nodejs)
宏任务(macrotask)
当前调用栈中执行的代码称为宏任务
- 主代码块
- setTimeout
- setInterval
- I/O(ajax)
- UI 渲染
- setImmediate (nodejs)
- 可以看到,事件队列中的每个事件都是一个宏任务,现在称为宏任务队列
Promise 和 setTimout 的区别?
promise 里面的和 then 里面执行有什么区别?
- Promise构造函数里面是同步执行的,无法取消
- then里面属于异步,且属于微任务
new Promsie (function(resolve, reject) {
// 同步任务
console.log('macrotask');
resolve('result');
}).then(function(value) {
// 异步任务 微任务
console.log('microtask');
console.log(value === 'result');
})
JavaScript 事件循环和消息队列(浏览器环境)
因为 JavaScript 是单线程的,而浏览器是多线程,所以为了执行 不同的同步异步的代码,JavaScript 运行的环境采用 事件循环 和 消息队列 来达到目的。
-
每个线程的任务执行顺序都是FIFO(先进先出)
-
在 JavaScript 运行的环境中,有一个负责程序本身的运行,作为 主线程;另一个负责主线程与其他线程的通信,被称为 Event Loop 线程,是为了判断 何时执行微任务?何时执行宏任务?,每次完成一个宏任务或微任务都会去检查有没有宏任务和微任务要不要处理,这个操作就称为 Event Loop。
-
每当主线程遇到 异步任务,把它们移入 Event Loop线程,然后主线程继续执行,等到主线程运行完之后,再去 Event Loop 线程拿结果
执行任务分类:
- 同步任务
- 异步任务
- 宏任务
- 微任务
Event Loop 线程中包含任务队列(用来对不同优先级的异步事件进行排序),而任务队列又分为 macro-task(宏任务) 与 micro-task(微任务)
-
宏任务 大概包括:script(整体代码)丶setTimeout丶setInterval丶 I/O(与程序交互的都可以成为IO)丶UI渲染等
-
微任务 大概包括:process.nextTick丶Promise.then catch finally丶Object.observe(已废弃)丶MutationObserve(html5新特性)
-
setTimeout
/Promise等我们称之为任务源。而进入任务队列的是它们指定的具体执行任务
Event Loop过程
来自不同的任务源的任务会进入到不同的任务队列中,而不同的任务队列过程如下:
- JavaScript 引擎首先从 宏任务 中取出第一个任务
- 执行完毕后,将 微任务 中的所有任务取出,按顺序全部执行
- 然后再从 宏任务 中取出下一个
- 执行完毕后,再次将 微任务 中的全部取出
- 循环往复,知道任务队列中的任务都取完
PS:补充
- 同步任务 和 异步任务 会发到不同的线程去执行
- 所有会进入到的 异步 都是指的是事件回调中的那部分代码,也就是说 new Promise 在实例化的过程中所执行的代码都是同步进行的,而 then 中注册的回调才是异步执行的
- 在 同步代码 执行完成才会去检查是否有 异步任务 执行,并执行相应的回调,而微任务又会在宏任务之前执行
- async/await 本质上还是基于 Promise 的一些封装,而 Promise 是属于微任务的一种,所以 await 关键字与Promise.then 效果类似。async 函数在 await 之前的代码都是同步执行的,可以理解成 await 之前的代码属于 new Promsie 时传入的代码,await 之后的所有代码都是在 Promise.then 中的回调
Promise 有没有解决异步的问题?
Promise 对象是 JavaScript 的异步操作解决方案,为异步操作提供统一接口。它起到代理作用(proxy),充当异步操作与回调函数之间的中介,使得异步操作具备同步操作的接口。Promise 可以让异步操作写起来,就像在写同步操作的流程,而不必一层层地嵌套回调函数
Promise 解决了 callback 回调函数的问题,async await是异步的终极解决方案。
JavaScript 事件循环 和 消息队列(Node环境)
Node中 的 Event Loop 和浏览器中的 Event Loop是完全不相同的东西。Node.js 采用 V8 作为 JS 的解析引擎,而I/O 处理方面使用了自己的 libuv ,libu 是一个基于 事件驱动的跨平台抽象层,封装了不同操作系统的一些底层特性,对外提供统一的API,事件循环机制也是它里面的实现
Node的运行机制如下
-
V8 引擎解析JavaScript脚本
-
解析后的代码,调用 Node API
-
libuv 库负责调用 Node API 的执行,它将不同的任务分配给不同的线程,形成一个 Event Loop(事件循环),以异步的方式将任务的执行结果返回给 V8 引擎
-
V8 引擎再将结果返回给用户
其中 libuv 引擎中的事件循环分为 6 个阶段,它们会按照顺序反复运行。每当进入某一个阶段的时候,都会从对应的回调队列中取出函数去执行。当队列为空或者执行的回调函数数量到达系统设定的阀值,就会进入下一个阶段
根据Node.js官方文档介绍,每次事件循环都包含6个阶段
-
timer阶段:这个阶段执行setTimeout(callback)丶setInterval(callback)预定的callback,并且是由poll阶段控制的 -
I/O callbacks阶段:执行一些系统调用错误,比如网络通信的错误回调,或者处理一些上一轮循环中的少数未执行的I/O回调 -
idle,prepare阶段:仅node内部使用 -
poll阶段:获取新的I/O事件,例如操作读取文件等,适当的条件下node将阻塞在这里 -
check阶段:执行setImmediate()的callback回调 -
close callbacks阶段:执行socket.on('close', callback)的callback会在这个阶段执行
NodeJs中宏任务队列主要有4个
- Timer Queue
- IO Callbacks Queue
- Check Queue
- Close Callbacks Queue
NodeJs中微任务队列主要有2个
- Next Tick Queue: 是放置process.nextTick(callback)的回调任务的
- Other Micro Queue: 放置其他microtask,比如Promise等
在浏览器中,也可以认为只有一个微队列,所有的mircrotask都会被添加到一个微队列中,但是在NodeJS中,不同的microtask会被放置在不同的微队列中
NodeJs中的EventLoop过程
-
执行全局的 Script 的同步代码
-
执行 microtask 微任务,先执行所有的Next Tick Queue中的所有任务,再执行Other Microtask Queue中的所有任务
-
开始执行macrotask宏任务,共六个阶段,从第一个阶段开始执行相应每一个阶段 macrotask 中的所有任务
注意:这里是所有每个阶段宏任务队列中的第一个任务出来执行,每一个阶段的macrotask任务执行完毕后,开始执行微任务,也就是步骤2
Timers Queue->步骤2->I/O Queue->步骤2->Check Queue->步骤2->Close Callback Queue->步骤2->Timer Queue…
Node 11.x新变化
现在Node 11.x在timer阶段的setTimout丶setInterval…和在check阶段的setimmediate都在Node 11.x里面都修改为一旦执行一个阶段里的一个任务就立即执行微任务队列,是为了和浏览器更加趋同。
10. 作用域 与 作用域链
作用域定义:变量(变量作用于又称上下文)和函数生效(能被访问)的区域
**[[scope]]:**每个 JavaScript 函数都是一个对象,对象有些属性我们可以访问,但有些不可以,这些属性仅供 JavaScript 引擎存取,[[scope]] 就是其中一个,[[scope]] 指得就是我们的作用域,其中存储了运行期上下文的集合
作用域链:[[scope]] 中所存储的执行期上下文对象的集合,这个集合呈链式链接,我们把这种链式链接叫做 作用域链
PS:
- **运行期上下文:**当函数执行时,会创建一个称为 执行期上下文 的内部对象,一个执行期上下文定义了一个函数执行时环境,函数每次执行时对应的执行上下文都是 独一无二 的,所以多次调用一个函数会导致创建多个执行上下文,当函数执行完毕,执行上下文被销毁
- **查找变量:**从作用域链的顶端依次向下查找
- **执行期上下文:**每次代码执行和函数调用都会产生一个执行环境,称为 执行期上下文
- **执行上下文栈:**多个 执行期上下文 会形成执行上下文栈
作用域分类
- **全局作用域:**变量在函数外定义为全局变量,全局变量有局部作用域:网页中的所有脚本和函数均可使用
- 最外层函数和在最外层函数定义的变量拥有全局作用域
- 所有未定义直接赋值的变量自动声明为拥有全局作用域
- 所有 window 对象的属性都拥有全局作用域
- **局部作用域:**变量在函数内声明为局部作用域
- 块级作用域
- 块级作用域的函数在预编译阶段将函数声明提升到全局作用域,并且会在全局函数声明一个变量,值为undefined,同时也会被提升到对应的块级作用域顶层
- 块级作用域函数只有定义声明函数的那行代码执行过后,才会被映射到全局作用域
- 块级作用域函数只有执行函数声明语句的时候,才会重写对应的全局作用域上的同名变量
为什么需要块级作用域?
- 变量提升导致内层变量可能覆盖外层变量
- 用来计数的循环变量泄漏为全局变量
JS 运行三部曲
- 语法编译
- 预编译
- 解释执行
预编译前奏
- imply global(暗示全局变量):即任何变量未经声明就赋值,此变量为全局对象所有
- 一切声明的全局变量,全是 window 的属性
预编译四部曲
- 创建 AO 对象
- 找形参和变量声明,将变量和形参名作为 AO 属性名,值为 undefined
- 将实参值和形参统一
- 在函数体里面找函数声明,值赋予函数体
this绑定情况
- 函数预编译过程 this 是指向 window
- 全局作用域 this 指向 window
- call/apply 可以改变函数运行时 this 指向
- obj.func(); func里面的 this 指向 obj
- 箭头函数里面的 this 和内部 arguments,由定义时外围最接近一层的非箭头函数的 arguments 和 this决定其值
11. ES6新特性
解决原有语法的缺陷和不足
var丶let 和 var 区别
- var 声明是全局作用域或函数作用域,而 let 和 const 是块级作用域
- var 变量可以在其范围内更新和重新声明;let 变量可以被更新但不能重新声明;const 变量既不能更新也不能重新声明
- 它们都被提升到其作用域的顶端。但是,虽然使用变量 undefined 初始化了 var 变量,但为初始化 let 和 const 变量
- 尽管可以在不初始化的情况下声明 var 和 let,但是在声明期间必须初始化 const
对原有语法的增强
解构赋值
数组的解构:根据数组对应的位置提取对应的值赋给对应的变量
let arr = [1, 2, 3];
let [x, y, z] = arr;
如果未取到对应的值,赋值 undefined
可以用 … 运算符
var [x, ...other] = arr;
可以设置默认值
var [x = '0', y, z] = arr;
用途:字符串截取
const str = 'http://www.baidu.com?titile=article';
var [, strParam] = str.split('?');
对象的解构:根据属性名提取
const obj = {name: 'zdd', age: 18};
const { name, age } = obj;
如果想换一个变量名&添加默认值
const {name: objName='www', age} = obj;
应用场景:代码简化
const { log } = console;
log('hh');
模板字符串
字符串增强:
- 可换行
- 可使用插值表达式添加变量,变量也可以替换成可执行的 JS 语句
let str = `生成一个随机数:${ Math.random() }`;
标签模板字符串,标签相当于一个自定义函数,自定义函数的第一个参数是被差值表达式截取的数组
// 标签模板字符串
const name = 'www';
const isMan = true
const tagFn = function (strings, name, isMan) {
let sex = isMan ? 'man' : 'woman';
return strings[0] + name + strings[1] + sex + strings[2]
}
const result = tagFn`hey, ${name} is a ${isMan}.`
字符串的拓展方法
- includes
- startWith
- endsWith
函数参数增强:参数默认值
只有当参数不传或传入 undefined 时使用默认值
const fn = function (x=1, y) {
console.log(x)
console.log(y)
}
fn()
… 操作符:收起剩余数据丶展开数组
收取剩余参数,取代 arguments,arguments 是一个类数组,… 操作符是一个数组类型,可以使用数组方法
- 仅使用一次
- 放在参数最后
const fn = function (x, ...y) {
console.log(y)
}
fn(1,2,3,4,5)
展开数组
const spredArr = [1,2,3,4]
console.log(...spredArr)
console.log.apply(this, spredArr) //es5代替方案
箭头函数
箭头函数和普通函数的区别
-
语法更加简洁丶清晰
-
箭头函数不会创建自己的 this
-
箭头函数继承而来的 this 指向永远不变
-
call丶apply丶bind 无法改变箭头函数中 this 的指向
var id = 'Global'; // 箭头函数定义在全局作用域 let fun1 = () => { console.log(this.id) }; fun1(); // 'Global' // this的指向不会改变,永远指向Window对象 fun1.call({id: 'Obj'}); // 'Global' fun1.apply({id: 'Obj'}); // 'Global' fun1.bind({id: 'Obj'})(); // 'Global' -
箭头函数不能作为构造函数使用
let Fun = (name, age) => { this.name = name; this.age = age; }; // 报错 let p = new Fun('cao', 24); -
箭头函数没有自己的 arguments
// 例子一 let fun = (val) => { console.log(val); // 111 // 下面一行会报错 // Uncaught ReferenceError: arguments is not defined // 因为外层全局环境没有arguments对象 console.log(arguments); }; fun(111); // 例子二 function outer(val1, val2) { let argOut = arguments; console.log(argOut); // ① let fun = () => { let argIn = arguments; console.log(argIn); // ② console.log(argOut === argIn); // true }; fun(); } outer(111, 222); -
箭头函数没有自己的原型
let sayHi = () => { console.log('Hello World !') }; console.log(sayHi.prototype); // undefined -
箭头函数不能用作 Generator 函数,不能使用 yeild 关键字
-
不可以使用 arguments 对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替
var add = (...values) => { console.log(values); let sum = 0; for(var val of values) { sum += val; } return sum; } add(2, 5, 3);
对象字面量的增强
- 如果 key 和 value 变量名相同,省略 value
- 省略函数:function
- 计算属性:[Math.random()]
const bar = 'bar'
const obj = {
bar,
fn() {
console.log('1111')
},
[Math.random()]: '123'
}
console.log(obj)
新增对象丶全新的方法丶全新的功能
Object.assign()
合并多个对象,第一个参数就是最终的返回值,如果对象的属性名相同,后面的覆盖前面
用途:复制对象,给 options 属性赋默认值
深拷贝
let objA = {
a: 'aa',
b: 'bb'
}
let objB = {
b: 'dd',
c: 'ee'
}
let result = Object.assign({}, objA, objB)
result.a = 'cc'
console.log(objA, result) //{a: "aa", b: "bb"} {a: "cc", b: "dd", c: "ee"}
Object.is()
判断两个值是否相等,返回布尔值
用途:在 ES5 中,对于 0 的判断不区分正负,-0 == +0 返回 true,NaN == NaN 返回 false;Object.is() 规避了这些问题
Object.is(+0, -0)//false
Object.is(NaN, NaN) //true
Proxy:代理对象
const person = {
name: 'www',
age: '20'
}
const personProxy = new Proxy(person, {
get(target, key) {
return target[key] ? target[key] : 'default'
},
set(target, key, value) {
target[key] = value % 2 ? value : 99
}
})
console.log(person.xxx) // undefined
console.log(personProxy.xxx) // default
console.log(personProxy.age) //20
personProxy.age = 100
console.log(personProxy) //{name: "www", age: 99}
这里注意的一点是,这里被拦截的是 personProxy,而不是 person
与 Object.definedProperty 的比较
-
相比与 Object,definedProperty 只能监听 get 和 set 行为,proxy 监听的行为更多一些,has丶deleteProperty … 等很多
-
对于数组的 push丶pop 等操作,proxy 是监听的整个对象的行为,所以通过 set 方法能够监听到;而 definedProperty 需要指定该对象的属性名,对于数组来说,就是指定数组的下标,是监听不到数组的 push丶pop 等操作的
let arr = [] let arrProperty = new Proxy(arr, { set(target, key, value) { console.log(target, key, value) //[1] "length" 1 target[key] = value return true } }) arrProperty.push(1) console.log(arrProperty) //[1] -
proxy 以非侵入的方式,监听了对象的读写;definedProperty 需要指定具体需要监听对象的属性名,与上面的数组类似,如果想要监听一个包含多个属性的对象的读写行为,defiendProperty 需要便利这个对象所有的属性
Reflect:封装操作对象的统一 API
在之前的 ES5 中,操作对象有很多方式
const obj = {
name: '111',
age: '22'
}
// 判断对象某个属性是否存在
console.log('name' in obj)
// 删除某个属性
console.log(delete obj['name'])
// 获取对象key
console.log(Object.keys(obj))
对于不同的操作方式,使用的方法却不同,Reflect 的目的是使用同一套方式去操作对象
const obj = {
name: '111',
age: '22'
}
// 判断对象某个属性是否存在
console.log(Reflect.has(obj,'name'))
// 删除某个属性
console.log(Reflect.deleteProperty(obj, 'name'))
// 获取对象key
console.log(Reflect.ownKeys(obj))
全新的数据结构和数据类型
class
// ES5 写法
function People(name) {
this.name = name;
}
People.prototype.sayHi = function() {
console.log(this.name);
}
let p = new People('tom');
p.sayHi();
// 使用 class
class People {
constructor (name) {
this.name = name;
},
say () {
console.log(this.name);
}
}
const p = new People('tony');
p.say();
类的继承
class People {
constructor (name) {
this.name = name;
},
say () {
console.log(this.name);
}
}
class Worker extends People {
constructor(name, age) {
super(name);
this.name = name;
}
sayAge () {
super.say();
console.log(this);
console.log(this.age);
}
}
const p = new Worker('tom', 18);
p.sayAge();
ES6 中 class 语法不是新的对象继承模型它只是原型链的语法糖表现形式
- extends 允许一个子类继承父类,需要注意得是,子类的 constructor 函数中需要执行 super() 函数。当然,你也可以在子类方法中调用父类的方法,
- 类的声明不会提升,如果你要使用某个 class,那么你必须在使用之前定义它,否则会抛出一个ReferenceError的错误。
- 在类中定义函数不需要使用 function 关键字
es5 和 es6 继承的区别
-
class 声明会提升,但不会初始化赋值。Foo 进入暂时性死区,类似于 let、const 声明变量
const bar = new Bar(); // it's ok function Bar() { this.bar = 42; } const foo = new Foo(); // ReferenceError: Foo is not defined class Foo { constructor() { this.foo = 42; } } -
Class 声明内部会启用严格模式
// 引用一个未声明的变量 function Bar() { baz = 42; // it's ok } const bar = new Bar(); class Foo { constructor() { fol = 42; // ReferenceError: fol is not defined } } const foo = new Foo(); -
Class 的所有方法(包括静态方法和实例方法)都是不可枚举的
// 引用一个未声明的变量 function Bar() { this.bar = 42; } Bar.answer = function() { return 42; }; Bar.prototype.print = function() { console.log(this.bar); }; const barKeys = Object.keys(Bar); // ['answer'] const barProtoKeys = Object.keys(Bar.prototype); // ['print'] class Foo { constructor() { this.foo = 42; } static answer() { return 42; } print() { console.log(this.foo); } } const fooKeys = Object.keys(Foo); // [] const fooProtoKeys = Object.keys(Foo.prototype); // [] -
必须使用 new 调用 new
function Bar() { this.bar = 42; } const bar = Bar(); // it's ok class Foo { constructor() { this.foo = 42; } } const foo = Foo(); // TypeError: Class constructor Foo cannot be invoked without 'new' -
class 内部无法重写类名
function Bar() { Bar = 'Baz'; // it's ok this.bar = 42; } const bar = new Bar(); // Bar: 'Baz' // bar: Bar {bar: 42} class Foo { constructor() { this.foo = 42; Foo = 'Fol'; // TypeError: Assignment to constant variable } } const foo = new Foo(); Foo = 'Fol'; // it's ok
Set 和 Map WeakSet weakMap 区别
简述:
- Set 和 Map 的主要应用场景在于 数组重组 和 数据存储
- Set 是一种叫做集合的数据结构,Map 是一种叫字典的数据结构
集合 和 字典 的区别:
- 共同点:集合丶字典 可以存储不同的值
- 不同点:集合是以【value, value】的形式存储元素,字典是以【key, value】
集合(Set)
ES6 新增的一种新的数据结构,类似于数组,成员唯一(内部没有重复的值)。且键值对数据排序即顺序存储
Set 本身就是一种构造函数,用来生成 Set 数据结构
Set 对象允许你存储任何类型的唯一值,无论是原始值或者是对象引用
const s = new Set();
[1, 2, 3, 4, 3, 2, 1].forEach(x => s.add(x));
for(let i of s) {
console.log(i);
}
// 去重数组的重复对象
let arr = [1, 2, 3, 2, 1, 1];
[...new Set(arr)];
注意:向 Set 加入值的时候,不会发生类型转换,所以 5 和 “5” 是不同的值。Set 内部判断两个值是否不同,使用的算法叫做 “Same-value-zero equality”,它类似于精确相等运算符(===),主要的区别是 NaN 等于自身,而精确相等运算符认为 NaN 不等于自身。
let set = new Set();
let a = NaN;
let b = NaN;
set.add(a);
set.add(b);
console.log(set);
let set1 = new Set();
set1.add(5);
set1.add('5');
console.log([...set1]);
操作方法:
- add(value):新增,相当于 array 里的 push
- delete(value):存在即删除集合中 value
- hash(value):判断集合中是否存在 value
- clear():清空集合
遍历方法:
- keys():返回一个包含集合中所有键的迭代器
- values():返回一个包含集合中所有值得迭代器
- entries():返回一个包含 Set 对象中所有元素的键值对迭代器
- forEach(callbackFn, thisArg):用于对集合成员执行 callbackFn 操作,如果提供了 thisArg 参数,回调中的 this 会是这个参数,没有返回值
WeakSet
WeakSet 对象允许你将 弱引用对象 存储在一个集合中
WeakSet 和 Set 的区别:
- WeakSet 只能存储对象引用,不能存放值,而 Set 对象都可以
- WeakSet 对象中存储的对象都是被弱引用的,即垃圾回收机制不考虑 WeakSet 对该对象的应用,如果没有其它的变量或属性引用这个对象值,则这个对象将会被垃圾回收掉(不考虑该对象还存在于 WeakSet 中),所以 WeakSet 对象里有多少个成员元素,取决于垃圾回收机制有没有运行,运行前后成员个数可能不一致,遍历结束之后,有的成员可能取不到(被垃圾回收),WeakSet 对象是无法被遍历(ES6 规定 WeakSet 不可遍历),也没有办法拿到它包含的所有元素
方法:
- add(value):在 WeakSet 对象中添加一个元素 value
- has(value):判断 WeakSet 对象中是否包含 value
- delete(value):删除元素 value
字典(Map)
是一组键值对的结构,具有极快的查找速度
const m = new Map();
const o = {p: 'haha'};
m.set(o, 'content');
m.get(o);
m.has(o);
m.delete(o);
m.has(o);
操作方法:
- set(key, value):向字典中添加新元素
- get(key):通过键查找特定的数值并返回
- has(key):判断字典中是否存在键 key
- delete(key):通过键 key 从字典中移除对应得数据
- clear():将这个字典中得所有元素删除
遍历方法:
- Keys():将字典中包含得所有键名以迭代器形式返回
- values():将字典中包含的所有数值以迭代器形式返回
- entries():返回所有成员的迭代器
- forEach():遍历字典的所有成员
WeakMap
WeakMap 对象是一组键值对的集合,其中的键是弱引用对象,而值可以是任意
注意:WeakMap 弱引用的只是键名,而不是键值。键值依然是正常引用
WeakMap中,每个键对自己所引用对象的引用都是弱引用,在没有其它引用和改键引用同一对象,这个对象将会被垃圾回收(相应的 Key 则变成无效的),所以 WeakMap 的 key 是不可枚举的
方法:
- has(key):判断是否有 key 关联对象
- get(key):返回 key 关联对象(没有则返回 undefined)
- set(key):设置一组 key 关联对象
- delete(key):移除 key 的关联对象
总结
Set:
- 成员唯一丶无序且不重复
- [value, value],键值与键名是一致的(或者说只有键值,没有键名)
- 可以遍历,方法有 add丶delete丶has
WeakSet:
- 成员都是对象
- 成员都是弱引用,可以被垃圾机制回收,可以用来保存 DOM 节点,不容易造成内存泄漏
- 不能遍历,方法有add丶delete丶has
Map:
- 本质上是键值对的集合,类似集合
- 可以遍历,方法很多可以跟各种数据格式转换
WeakMap:
- 只接受对象为键名(null),不接受其它类型的值作为键名
- 键名是弱引用,键值可以是任意,键名所指向的对象可以被垃圾回收,此时键名是无效的
- 不能遍历,方法有get丶set丶has丶delete
Symbol
用途:
- 防止全局对象中,某个属性名重名,产生冲突
- 定义私有属性,外部访问不到,且遍历不到
const s = Symbol('描述')
console.log(s)
const obj = {
[Symbol('私有属性')]: '11'
}
console.log(obj) //obj对象Symbol('私有属性')这个属性外部访问不到
console.log(Object.keys(obj)) //[]
console.log(Object.getOwnPropertySymbols(obj)) //[Symbol(私有属性)]
const s1 = Symbol.for('111')
const s2 = Symbol.for('111')
console.log(s1 === s2) //true
for …of 遍历
es5 中,使用 for … in 遍历键值对结构数据,使用 forEach 遍历数组
ES6 中新增了 set丶map 数据结构,for … of 是用来统一遍历某一种特性的数据结构(可迭代)
const arr = [1, 2, 3]
for (const item of arr) {
// 遍历数组
console.log(item)
}
const s = new Set()
s.add(1).add(2).add(3)
for (const item of s) {
// 遍历set结构
console.log(item)
}
const m = new Map([
['name', '昵称'],
['title', '标题']
])
for (const [key, value] of m) {
// 遍历map结构
console.log(key)
console.log(value)
console.log(m.get(key))
}
const newSet = new Set([
['name', '昵称'],
['title', '标题']
])
const newMap = new Map(newSet)
for (const [key, val] of newMap) {
// 遍历set初始化后的map结构
console.log(key)
console.log(val)
}
const obj = {
name: 'ttt',
age: '19'
}
for (const [key, val] of obj) {
// 遍历对象报错 Uncaught TypeError: obj is not iterable
console.log(key, val)
}
上面代码中,for … of 可以遍历数组丶set 和 map,但是却不能遍历对象,是因为对象没有可迭代的接口
可迭代接口
在浏览器中打印一个数组,在数组的原型对象上有一个 Symbol 内置属性 Symbol.iterator 方法,该方法会返回一个 iterator 对象,该对象包含一个 next 方法,调用 iterator.next() 会返回一个迭代器结果对象 iterationResult,iterationResult 对象包含两个值,value 为遍历的 item,done 为当前数据是否遍历完成
var arr = [1, 2]
const iterator = arr[Symbol.iterator]()
console.log(iterator) // Array Iterator {}
const ite = iterator.next()
console.log(ite) //{value: 1, done: false} value为迭代器的值,done标识是否遍历完
const ite2 = iterator.next()
console.log(ite2) //{value: 2, done: false} value为迭代器的值,done标识是否遍历完
const ite3 = iterator.next()
console.log(ite3) //{value: 3, done: true} value为迭代器的值,done标识是否遍历完
由于上面代码中 obj 对象没有 Symbol.iterator 的内置方法,所以它不是一个可迭代对象,当使用 for … 遍历时就报错,下面手动实现 obj 可迭代
let iteratorObj = {
name: 'ttww',
age: '18',
[Symbol.iterator]() {
let index = 0;
let arr = [];
for(const key in iteratorObj) {
arr.push([key, iteratorObj[key]]);
}
return {
next () {
return {
value: arr[index],
done: index ++ >= arr.length
}
}
}
}
}
for(const [key, val] of iteratorObj) {
console.log(key, val);
}
上面的代码中:
- iteratorObj 有了可迭代接口,认为是可迭代对象 iterable;
- Symbol.iterator 方法返回的对象是迭代器对象 iterator
- 迭代器对象 next 方法返回的对象可迭代器结果对象 iterationResult
生成器 generator
用途:处理异步调用回调嵌套的结果
function *getFn() {
console.log(111);
yield 100;
console.log('222');
yield 200;
console.log('3333');
yield 300;
}
let generator = getFn();
console.log(generator.next());
console.log(generator.next());
console.log(generator.next());
console.log(generator.next());
- 在函数名前面加一个 *,函数就变成生成器函数,执行该函数时,里面的函数不会立即执行,而是会返回一个生成器对象,调用生成器对象的 .next 方法函数开始执行,当遇到 yeild 关键字,函数就会停止执行,并把 yeild 的值当作 next 方法返回对象的 value;
- 当下次调用 next 方法时,函数从当前位置开始继续执行,生成器函数被执行返回的生成器对象 generator,内部也是实现了迭代器接口,所以可以使用 for …of 来遍历
function* geFn() {
console.log('111')
yield 100
console.log('222')
yield 200
console.log('333')
yield 300
}
let generator = geFn()
for (const item of generator) {
console.log(item)
}
可以使用生成器函数改写上面对象的迭代器方法
let iteratorObj = {
name: 'ttww',
age: '18',
[Symbol.iterator]: function* () {
let index = 0;
let arr = []
for (const key in iteratorObj) {
arr.push([key, iteratorObj[key]])
}
for (const item of arr) {
yield item
}
}
}
for (const [key, val] of iteratorObj) {
console.log(key, val)
}
这里有一个注意的点就是在循环 arr 数组时,不能是有 forEach 遍历,是因为 forEach 里需要传一个回调函数,这个函数不是生成器函数,在非生成器函数里使用 yield 关键字会报错
12. 闭包引发的内存泄漏及垃圾回收机制
闭包
闭包就是能够读取其它函数内部遍历的函数
由于在 JavaScript 语言中,只有函数内部的子函数才能读取局部变量,因此可以把闭包简单理解成 “定义在一个函数内部的函数”
所以,在本质上,闭包将函数内部和外部连接起来的一座桥梁
闭包的用途
- 读取内部的变量
- 让这些变量的值始终保持在内存中
使用闭包的注意点
- 由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在 IE 中可能导致内存泄漏。解决方法是,在退出函数之前,将不使用的局部变量全部删除
- 闭包会在父函数外部,改变父函数内部变量的值。所以如果你把父函数当作对象使用,把闭包当作它的公用方法,把内部变量当作它的私有属性,这时一定要小心,不能随便改变父函数内部变量的值
常见的四种内存泄漏:
-
全局变量
在非严格模式下当应用未声明的变量时,会在全局对象中创建一个新变量。在浏览器中,全局对象将是 window,这意味着
function foo(arg){ bar =“some text”; // bar将泄漏到全局. }为什么不能泄漏到全局呢?我们平时都会定义全局变量呢
**原因:**全局变量是根据定义无法被垃圾回收机制回收,需要特别注意用于临时存储和处理大量信息的全局变量。如果必须使用全局模式来存储数据,请确保将其指定为 null 或在完成后重新分配它
**解决方法:**严格模式
-
被遗忘的定时器和回调函数
var someResource = getData(); setInterval(function() { var node = document.getElementById('Node'); if(node) { node.innerHTML = JSON.stringify(someResource)); // 定时器也没有清除 } // node、someResource 存储了大量数据 无法回收 }, 1000);**原因:**与节点或数据关联的计时器不再需要,node 对象可以删除,整个回调函数也不需要了。可是,计时器回调函数仍然没被回收(计时器停止)。同时,someResource 如果存储了大量的数据,也是无法被回收的
**解决方法:**在定时器完成工作的时候,手动清除定时器
-
DOM 引用
var refA = document.getElementById('refA'); document.body.removeChild(refA); // dom删除了 console.log(refA, "refA"); // 但是还存在引用 // 能 console 出整个div 没有被回收**原因:**保留了 DOM 节点的引用,导致 GC 没有回收
**解决方法:**refA = null
注意:此外还要考虑 DOM 树内部或子节点的引用问题。加入你的 JavaScript 代码中保存了表格某一个 的引用。将来决定删除整个表格的时候,直觉认为 GC 会回收除了已经保存的 以外的其它节点。实际情况并非如此:此 是表格的子节点,子元素和父元素是引用关系。由于代码保留了 的引用,导致整个表格仍待在内存中。保存 DOM 元素引用的时候,要小心谨慎
-
闭包
注意:闭包本身没有错误,不会引起内存泄漏,而是使用错误导致
var theThing = null; var replaceThing = function () { var originalThing = theThing; var unused = function () { if (originalThing) console.log("hi"); }; theThing = { longStr: new Array(1000000).join('*'), someMethod: function () { console.log(someMessage); } }; }; setInterval(replaceThing, 1000);这是一段糟糕的代码,每次调用 replaceThing,theThing 得到一个包含大数组和一个新闭包(someMethod)的对象。同时,变量 unused 是一个引用 originalThing 的闭包(先前的 replaceThing 又调用了 theThing)。思绪乱了吗?最重要的事情是,闭包的作用域一旦创建,它们有同样的父级作用域,作用域是共享的。someMethod 可以通过 theThing 使用,someMethod 与 unused 分享闭包作用域,尽管 unused 从未使用,它引用的 originThing 迫使它保留在内存中(防止被回收)。当这段代码反复运行,就会看到内存占用不断上升,垃圾回收器(GC)并无法降低内存占用。本质上闭包的链表已经创建,每一个闭包携带一个指向大数组的间接的引用,造成严重的内存泄漏
解决:去除 unuserd 函数或者在 replaceThing 函数最后一行加上 originThing = null
垃圾回收机制
垃圾回收机制
JS 会在创建变量时自动分配内存,在不使用的时候会自动周期性的释放内存,释放的过程就叫“垃圾回收机制”。这个机制有好的一面,当然也有不好的一面。一方面自动分配内存减轻了开发者的负担,开发者不用过多的去关注内存使用,但是另一方面,正是因为是自动回收,所以如果不清楚回收的机制,会很容易造成混乱,而混乱就很容易造成内存泄漏,由于是自动回收,所以就存在了一个内存是否需要被回收的问题,但是这个问题的判定在程序中意味着无法通过某个算法去准确完整的解决,后面探讨的回收机制只能有限的去解决一般的问题
回收算法
垃圾回收对是否需要回收的问题主要依赖于对变量的判定是否可访问,由此衍生出两种主要的回收算法
- 标记清理
- 引用计数
标记清除
标记清除是 JS 最常用的回收策略,2012 年后所有浏览器都使用了这种策略,此后的对回收策略的改进也是基于这个策略的该井。其策略是:
- 变量进入上下文,也可以理解为作用域,会加上标记,证明其存在于该上下文
- 将所有在上下文的变量以及上下文中被访问引用的变量标记去掉,表明这些变量活跃有用
- 在此之后再被加上标记的变量标记为准备删除的变量,因为上下文的变量已经无法访问它们
- 执行内存清理,销毁带标记的所有非法活跃值并回收之前被占用的内存
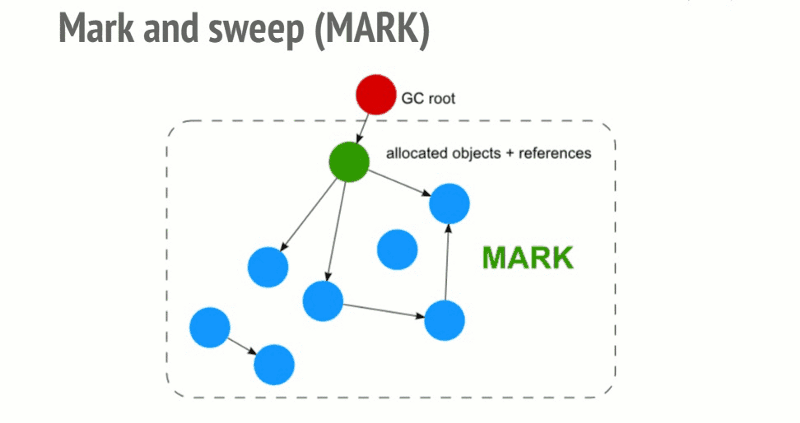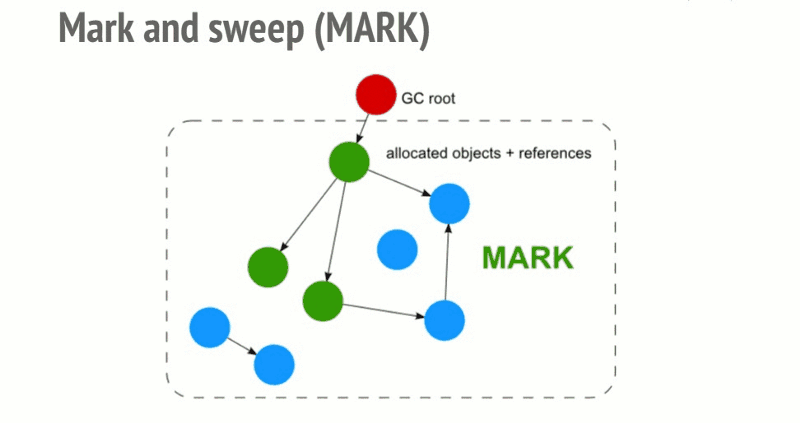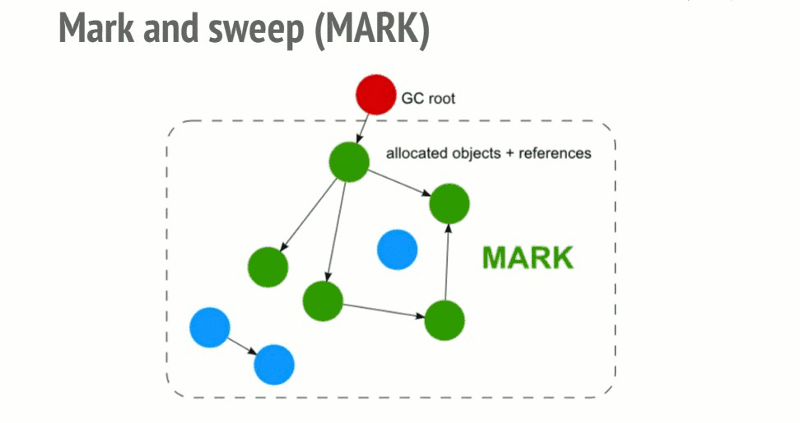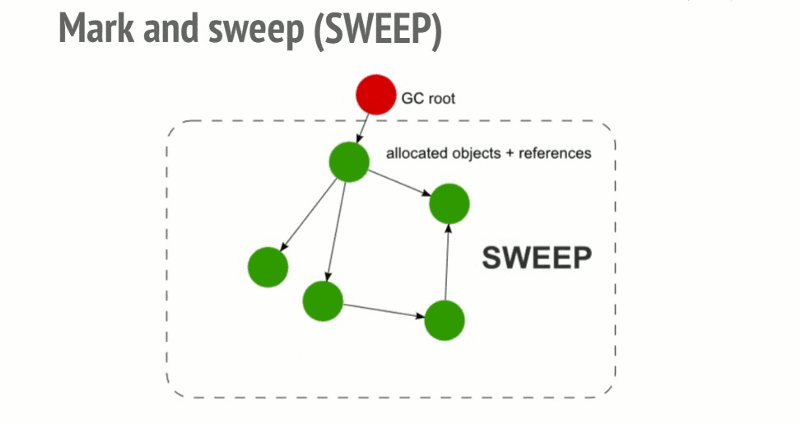
局限:
- 由于是从根对象(全局对象)开始查找,对于那些无法从根对象查询到的对象都将被清除
- 回收后会形成内存碎片,影响后面申请大的连续内存空间
引用计数
引用计数策略相对而言不常用,因为弊端较多。其思路是对每个值记录它被引用的次数,通过最后对次数的判断(引用次数为 0)来决定是否保留,具体的规则有:
- 声明一个变量,赋予它一个引用值,计数 + 1
- 同一个值被赋予另外一个变量时,引用 + 1
- 保存对该值引用的变量被其它值覆盖,引用 - 1
- 引用为 0,回收内存
局限
最重要的问题就是,循环引用的问题
function refProblem () {
let a = new Object();
let b = new Object();
a.c = b;
b.c = a; //互相引用
}
根据之前提到的规则,两个都互相引用了,引用计数不为 0,所以两个变量都无法回收。如果频繁的调用改函数,则会造成很严重的内存泄漏
Nodejs V8 回收机制
V8 的回收机制基于 分代回收机制,将内存分为新生代(young generation)和老生代(tenured generation),新生代为存活时间较短的对象,老生代为存活时间较长或者常驻内存的变量

V8 堆的构成
V8 将堆分成了几个不同的区域

- **新生代(New Space/Young Generation):**大多数新生对象被分配到这,分为两块空间,整体占据小块空间,垃圾回收的频率较高,采用的回收算法为 Scavenge 算法
- **老生代(Old Space/Old Generation):**大多数在新生区存活一段时间后的对象会转移至此,采用的回收算法为 标记清除 & 整理(Mark-Sweep & Mark-Compact,Major GC)算法,内部再细分为两个空间
- **指针空间(Old pointer space):**存储的对象含有指向其它对象的指针
- **数据空间(Old data space):**存储的对象仅包含数据,无指向其它对象的指针
- **大对象空间(Large Object Space):**存放超过其它空间(Space)限制的大对象,垃圾回收器从不移动此空间中的对象
- **代码空间(Code Space):**代码对象,用于存放代码段,是唯一拥有执行权限的内存空间,需要注意的是如果代码对象太大而被移入大对象空间,这个代码对象在大对象空间内也是拥有执行权限的,但不能因此说大对象空间也有执行权限
- **Cell 空间丶属性空间丶Map 空间(Cell丶Property丶Map Space):**这些区域存放Cell丶属性 Cell 和 Map,每个空间因为都是存放相同大小的元素,因此内存结构很简单
Scavenge 算法
Scavenge 算法是新生代空间中的主要算法,该算法由 C.J.Cheney 在 1970 年在论文 A nonrecursive list compacting algorithm 提出
Scavenge 主要采用了 Cheney 算法,Cheney 算法新生代空间的堆内存分为 2 块同样大小的空间,称为 Semi Space,处于使用状态的成为 From 空间,闲置的称为 To 空间。垃圾回收过程如下:
- 检查 From 空间,如果 From 空间被分配满了,则执行 Scavenge 算法进行垃圾回收
- 如果未分配满,则检查 From 空间的是否由存活对象,如果无存活对象,则直接释放未存活对象的空间
- 如果存活,将检查对象是否符合晋升条件,如果符号晋升条件,则移入老生代空间,否则将对象赋值进 To 空间
- 完成复制后将 From 和 To 空间角色互换,然后再从第一步开始执行
晋升条件
- 经历过一次 Scavenge 算法筛选
- To 空间内存使用超过 25%

标记清除 & 整理(Mark-Sweep & Mark-Compact,Major GC)算法
之前说过,标记清除策略会产生内存碎片,从而影响内存的使用,这里标记整理算法(Mark-Compact)的出现就能很好的解决这个问题。标记整理算法是在标记清除(Mark-Sweep)的基础上演而来的,整理算法会将活跃的对象往边界移动,完成移动后,再清除不活跃的对象

由于需要移动对象,所以在处理速度上,会慢于 Mark-Sweep
全停顿(Stop The World)
为了避免应用逻辑与垃圾回收器看到的逻辑不一样,垃圾回收器在执行回收时会停止应用逻辑,执行完回收任务后,再继续执行应用逻辑。这种行为就是 全停顿。停顿的时间取决于不同引擎执行一次垃圾回收的时间。这种停顿对新生代空间的影响较小,但对老生空间可能会造成停顿的现象
增量标记(Incremental Marking)
为了解决全停顿的现象,2011 年 V8 推出了增量标记。V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JS 应用逻辑交替进行,直至标记完成

13. 前端性能优化
1. 减少 HTTP 请求
一个完整的HTTP请求需要经历 DNS 查找,TCP 握手,浏览器发出 HTTP 请求,服务器接收请求,服务器处理请求并发回响应,浏览器接收响应等过程。
这是一个HTTP请求,请求的文件大小为18.4KB

名词解释:
- Queueing: 在请求队列中的时间
- Stalled: 从TCP连接建立完成,到真正可以传输数据之间的时间差,此时间包括代理协商时间。
- Proxy negotiation: 与代理服务器连接进行协商所花费的时间
- DNS Lookup: 执行 DNS 查找所花费的时间,页面上的每个不同的域都需要进行 DNS 查找
- Intial Connect / Connecting: 建立连接所花费的时间,包括TCP握手/重试和协商SSL
- SSL: 完成SSL握手所花费的时间
- Request sent: 发出网络请求花费的时间,通常为一毫秒的时间。
- Waiting(FEEB): TFFP 是发出页面请求到接受应答数据第一个字节的时间。
- Content Download: 接受响应数据所花费的时间。
从这个例子可以看出,真正下载数据的时间占比为 13.05/204.16 = 6.39%,文件越小,这个比例越小,比例就越高。这就是为什么建议将多个小文件合并为越高大文件,从而减少 HTTP 请求次数的原因。
2. 使用 HTTP2
HTTP2 相比 HTTP 1.1 有如下几个优点
解析速度快
解析器解析 HTTP1.1 的请求时,必须不断地写入字节,直到遇到分隔符 CRLF 为止。而解析 HTTP2 的请求就不用这么麻烦,因为 HTTP 是基于帧的协议,每个帧都有表示帧的字段。
多路复用
HTTP1.1 如果要同时发起多个请求,就得建立多个 TCP 连接,因为一个 TCP 连接同时只能处理一个 HTTP1.1 的请求。
在 HTTP2 上,多个请求可以共用一个 TCP 连接,这称为多路复用。同一个请求和响应用一个流来表示,并有唯一的流ID来标识。
多个请求请求和响应在 TCP 连接中可以乱序发送,到达目的后再通过流 ID 重新组建。
首部压缩
HTTP2提供了首部压缩的功能
例如下面两个请求:
:authority: unpkg.zhimg.com:method: GET:path: /za-js-sdk@2.16.0/dist/zap.js:schema: httpsaccept: */*accept-encoding: gzip, deflate, braccept-language: zh-CN, zh; q= 0.9cache-control:no-cachepragma: no-cacheredferer: https://www.zhihu.com/sec-fetch-dest: scriptsec-fetch-mode: no-corssec-fetch-site: cross-siteuser-agent: Mozilla/5.0(Window NT 6.1; Window64; x64) AppleWebkit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari.53736
:authority: zz.bdstatic.com:method: GET:path: /linksubmit/push.js:scheme: httpsaccept: */*accept-encoding: gzip, deflate, braccept-language: zh-CN,zh;q=0.9cache-control: no-cachepragma: no-cachereferer: https://www.zhihu.com/sec-fetch-dest: scriptsec-fetch-mode: no-corssec-fetch-site: cross-siteuser-agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36
从上面两个请求可以看出来,有很多数据都是重复的。如果可以把相同的首部存储起来,仅发送它们之间不同的部分,就可以节省不少的流量,加快请求的时间。
HTTP/2 在客户端和服务端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送。
下面再来看个简化的例子,假设客户端按照顺序发送如下的请求首部:
Header1: fooHeader2: barHeader3: bat
当客户端发送请求的时,它会根据首部只值创建一张表:
| 索引 | 首部名称 | 值 |
|---|---|---|
| 62 | Header1 | foo |
| 63 | Header2 | bar |
| 64 | header3 | bat |
当服务器收到请求,它会照样创建一张表。
当客户端发送下一个请求的时候,如果首部相同,它可以直接发送照样的首部块
62 63 64
服务器会查找先前创建的表格,并把这些数字还原成对应的完整的首部块。
优先级
HTTP2 可以对比较紧急的请求设置一个较高的优先级,服务器在收到这样的请求后,可以优先处理。
流量控制
由于一个TCP 连接流量宽带(根据客户端到服务器的网络宽度而定)是固定的,当有多个请求并发时,一个请求占的流量多,另一个请求占的流量就会少,流量控制可以对不同的流的流量进行精确控制。
服务器推送
HTTP2 新增的一个强大的新功能,就是服务器可以对一个客户端请求发送多个响应。换句话说,除了对最初请求的响应外,服务器还可以额外向客户端推送资源,而无需客户端明确的请求。
例如当浏览器请求一个网站时,除了返回 HTML 页面外,服务器还可以根据 HTML 页面中的资源的 URL,来提前推送资源。
3. 使用服务端渲染
客户端渲染过程
- 访问客户端渲染的网站
- 服务器返回一个包含了引入资源语句和<div id="app>的HTML语句
- 客户端通过 HTTP 向服务器请求资源,当必要的资源都加载完毕后,执行 new Vue() 开始实例化并渲染页面。
服务端渲染过程
- 访问服务端渲染的网站
- 服务器会查看当前路由组件需要哪些资源文件,然后将这些文件的内容填充到 HTML 文件。如果有 ajax 请求,就会执行它进行数据预取并填充到 HTML 文件,最后返回到这个 HTML 页面。
- 当客户端接收到这个 HTML 页面时,可以马上就开始渲染页面。与此同时,页面也会加载资源,当必要的资源都加载完毕后,开始执行 new Vue()开始实例化并接管页面。
从上述两个过程可以看出,区别在于第二步。客户端渲染的网站会直接返回 HTML 文件,而服务端渲染的网站会渲染完页面再返回这个 HTML 文件。
这样做的好处是什么》是更快的到达时间
假设你的网站需要加载完 abcd 四个文件才能渲染完毕,并且每个文件大小为 1M。
这样一算:客户端渲染的网站需要加载 4 个文件和HTML 文件才能完成首屏渲染,总计为 4M(忽略 HTML 文件大小)。服务端渲染的网站只需要加载一个渲染完毕的 HTML 文件就能完成首页渲染,总计大小为已经渲染完毕的 HTML 文件(这种文件不会太大,一般为几百K,我的个人网站博客(SSR)加载的 HTML 文件为400K )。这就是服务端文件渲染更快的原因。
4. 静态资源使用 CDN
当用户访问一个网站时,如果没有 CDN,过程是这样的:
- 浏览器要将域名解析为 IP 地址,所以需要向本地 DNS 发出请求。
- 本地 DNS 依次向根服务器丶顶级域名服务器丶权限服务器发出请求,得到网站服务器的 IP 地址。
- 本地 DNS 将 IP 地址发回给浏览器,浏览器向网站服务器 IP 地址发出请求并得到资源。

如果用户访问的网站部署了 CDN,过程是这样的:
- 浏览器要将域名解析为 IP地址,所以需要向本地 DNS 发出请求。
- 本地 DNS 依次向根服务器丶顶级域名服务器丶权限服务器发出请求,得到全局负载均衡系统(GSLB)的IP地址。
- 本地 DNS 再向 GSLB 发出请求,GLSB 的主要功能是根据本地 DNS 的 IP 地址判断用户的位置,筛选出距离用户较近的本地负载均衡系统(SLB),并将该 SLB 的 IP地址作为结果返回给本地 DNS。
- 本地 DNS 将 SLB 的 IP 地址发回给浏览器,浏览器向 SLB 发出请求。
- SLB 根据浏览器请求的资源和地址,选出最优的缓存服务器发回给浏览器。
- 浏览器再根据 SLB 返回的地址重定向到缓存服务器。
- 如果缓存服务器有浏览器需要的资源,就将资源发回给浏览器。如果没有,就向服务器请求资源,再发给浏览器缓存在本地。

5. 将 CSS 放在文件头部,JavaScript 文件放在底部。
所有放在 head 标签里的 CSS 和 JS 都会堵塞渲染。如果这些 CSS 和 JS 需要加载和解析很久的话,那么页面就空白了。所以JS 文件要放在底部,等 HTML 解析完了再加载 JS 文件。
那为什么 CSS 文件还要放在头部呢?
因为先要加载 HTML 再加载 CSS,会让太湖第一时间看到的页面是没有样式的丶“丑陋”的,为了避免这种情况发生,就要将 CSS 文件放在头部了。
另外,JS 文件也不是不可以放在头部,只要给 script 标签加上 defere 属性就可以了,异步下载,延迟执行。
6. 使用字体图标 iconfont 代替图片图标
字体图标就是将图标制作成一个字体,使用时就跟字体一样,可以设置属性,例如 font-size丶color等等,非常方便。并且字体图标是矢量图,不会失真。还有一个优点是生成的文件特别小。
压缩字体文件
使用 fontmin-webapck 插件机对字体文件进行压缩
7. 善用缓存,不重复加载相同资源
为了避免用户每次网站都得请求文件,我们可以通过添加 Expires 或 max-age 来控制这一行为。Expires 设置了一个时间,只要在这个时间之前,浏览器都不会请求文件,而是直接使用缓存。而 max-age 是一个相对时间,建议使用 max-age 代替 Expires。
不过会产生一个问题,当文件更新怎么办?怎么通知浏览器重新请求文件?
可以通过更新页面中引用的资源连接地址,让浏览器主动放弃缓存,加载新资源。
具体做法是把资源地址 URL 的修改与文件内容关联起来,也就是说,只有文件内容变化,才会导致相应 URL 的变更,从而实现文件级别的精确缓存控制。什么东西与文件内容相关呢?我们会很自然的联想到利用书籍摘要算法对文件求摘要信息,摘要信息与文件内容一一对应,就有了一种可以精确到单个文件粒度的缓存控制依据了。
8. 压缩文件
压缩文件可以减少下载时间,让用户体验更好。
得益于webpack 和 node 的发展,现在压缩文件已经非常方便了。
在 webapck 可以使用如下插件
- JavaScript:UglifyPlugin
- CSS:MiniCssExtractPlugin
- HTML:HtmlWebpackPlugin
其实,我们还可以做得更好。那就是使用 gzip 压缩。可以通过向 HTTP 请求头中的 Acccpt-Encoding 头添加 gzip 标识来开启这一功能。当然服务器也支持这个功能。
gzip 是目前最流行和最有效的压缩功能。举个例子,我用 Vue 开发的项目构建后生成的 app.js 文件大小为 1.4MB,使用 gzip 压缩后只有 573KB,体积减少了渐近 60%。
附上webpack 和 node 配置 gzip 的使用方法
下载插件
npm install compress-webpack-plugin --save-devnpm install compression
webapck配置
const CompressionPlugin = require("cmpression-webpack-plugin");moduel.exports = { plugins: [new CompressionPlugin()],}
node 配置
const compression = require("compression");// 在球体中间件使用app.use(compression())
9. 图片优化
9-1. 图片延迟加载
在页面中,先不给图片设置路径,只有那个图片出现在浏览器的可视区域时,才去加载真正的图片,这就是延迟加载。对于图片很多的网站来说,一次性加载全部图片,会对用户体验造成很大的影响,所以需要使用图片延迟加载。
首先可以将图片这样设置,在页面不可见时图片不会加载:
<img data-src>
等图片可见时,使用JS 加载图片
const img = document.querySelector("img");img.src = img.dataset.src;
9.2 响应式图片
响应式图片的优点是浏览器能够根据屏幕大小自动加载合适的图片
通过picture 实现
<picture> <source srcset="" media="(min-width: 801px)"> <source srcset="" media="(max-width: 800px)"> <img src=""></picture>
9.3 调整图片大小
例如,你有个 1920 * 1080 大小的图片,用缩略图的方式展示给用户,并且当用户鼠标停在上面时才能展示全图。如果用户从未真正将鼠标悬停在缩略图上,则浪费了下载图片的时间。
所以,我们可以用两张图片来实行优化。一开始,只加载缩略图,当用户悬停在图片上时,才加载大图。还有一种方法,即对大图进行延迟加载,在所有元素都加载完成后手动更改大图的 src 进行下载。
9.4 降低图片质量
例如 JPG 格式的图片,100% 的质量和 90% 质量的通常看不出区别,尤其是用来当背景图片。我们经常用 PS 切背景图时,将图片切成 JPG 格式,并且将它压缩到60% 的质量,基本上看不出区别。
压缩方法有两种,一种是通过 webpack 提供的 插件 image-webpack-loader,二是通过在线网站进行压缩。
以下附上 webpack 插件 image-webpack-loader 的用法
npm i -D image-webpack-loader
webpack配置
{
test: /\.(png|jge?g|gif|svg)(\?.*)?$/,
use: [{
loader: "url-loader",
options: [
limit: 10000, /* 图片大小小于1000字节限制时自动转成 base64 码引用 */
name: util.assetsPath("img/[name].[hash:7].[ext]")]
}, // 对图片进行压缩
{
loader: "image-webpack-loader",
options: {
bypassOnDebug: true
}
}
]
}
9-5. 尽可能利用 CSS3 效果代替图片
有很多图片使用CSS 效果(渐变丶阴影等)就能画出来,这种选择 CSS3 效果更好。因为代码大小通常是图片大小的几分之一甚至几十分之一
9-6. 使用 webp 格式的图片
Webp 的优势体现在它具有更优的图像数据压缩算法,能够带来更小的图片体积,而且拥有肉眼识别无差异的图像质量;同时具备了无损和有损的压缩模式,Alpha 透明以及动画的特性。在 JEPG 和 PNG 上的转化效果都相当优秀丶稳定和统一。
10. 通过 webpack 按需加载代码,提取第三库代码,减少 ES6 转成 ES5 的冗余代码。
懒加载或者按需加载,是一种很好的优化网页或应用的方式。这种方式实际上先把你的代码在一些逻辑断点处分离开,然后在一些代码块中完成某些操作后,立即引用或即将引用另外一些新的代码块。这样加快了应用的初始速度,减少了它的总体体积,因为某些代码可能永远不会被加载。
根据文件内容生成文件名,结合 import 动态引入组件实现按需加载
通过配置 output 的 filename 属性可以实现这个属性。filename 属性的值选项中有一个 [contenthash] 也会发生变化。
output: {
filename: '[name].[contenthash].js',
chunkFilename: '[name].[contenthash].js',
path: path.resolve(__dirname, "../dist")
}
提取第三方库
由于引入的第三方库一般都比较稳定,不会经常改变。所以将它们单独提取出来,作为长期缓存是一个更好的选择。
这里需要使用的是 webpack4 的 splitChunk 插件的 cacheGroups 选项。
optimization: {
runtimeChunk: {
name: "manifest" // 将 webpack 的tuntime 代码拆分为一个单独的 chunk },
splitChunks: {
cacheGroups: {
vendor: {
name: "chunk-vendors",
test: /[\\/]nodule_modules[\\/]/,
priority: -10,
chunks: "initial"
},
comon: {
name: "chunk-common",
minChunks: 2,
priority: -20,
chunks: "initial",
reuseExistingChunk: true
}
}
}
}
}
- test: 用于控制哪些模块被这个缓存组匹配到。原封不动传递出去的话,它默认会选择所有的模块。可以传递的类型: RegExp丶String和Function;
- priority: 表示抽取权重,数字越大表示优先级越高。因为一个 module 可能会满足多个 cacheGroups 的条件,那么抽取到哪个就由权重最高的说了算。
- reuseExistingChunk: 表示是否使用已有的 chunk,如果为true 则表示如果当前的 chunk 包含的模块已经被抽离出去了,那么将不会生成新的。
- minChunks(默认是1): 在分割之前,这个代码最小应该被引用的次数(译注:保证代码块复用性,默认配置的策略是不需要多次引用也可以被分割的)
- chunks(默认是async): initial丶async和all
- name(打包的chunks的名字): 字符串或者函数(函数可以根据推荐自定义名字)
减少 ES6 转为 ES5 的冗余代码
Babel 转化后的代码想要实现和原来代码一样的功能需要借助一些帮助函数,比如:
class Person() {}
会转换成:
"use strict"
function _classCallCheck(insatnce, Constructor) {
if(!(instance instanceof Constructor)) {
throw new TypeError("Cannot calll a class ss a funciton");
}
}
var Person = funtion Person() {
_classCallCheck();
}
这里的_classCallCheck 就是 helper 函数,如果在很多文件里都声明了类,那么就会产生很多个这样的 helper 函数。
这里的 @babel/runtime 包就声明了所有需要用到的帮助函数,而 @babel/plugin-transfrom-runtime 的作用就是将所有需要 helper 函数的文件,从 @babel/runtime 包引进来:
"use strict";
var _classCallCheck2 = require("@babel/runtime/helpers/callCallCheck");
var _classCallCheck3 = _interopRequireDefault(_classCallCheck2);
function _interopRequireDefault(obj) {
return obj && obj._esModule ? obj : {default: obj};
}
var Person = function Person() {
(0, _classCallCheck3.default)(this, Person);
}
这里就没有再编译出 helper 函数 classCallCheck 了,而是直接引用了 @babel.runtime 中的 helpers/classCallCheck.
安装
npm i -D @babel/plugin-transform @babel/runtime
使用
在.babelrc文件中
"plugin": {
"@babel/plugin-transform-runtime"
}
11. 减少重排重绘
浏览器渲染过程
- 解析 HTML 生成 DOM 树
- 解析 CSS 生成 CSSDOM 规则树
- 将 DOM 树 与 CSSDOM 规则树合并在一起生成渲染树
- 遍历渲染树开始布局,计算每个节点的位置大小信息
- 将渲染树每个节点绘制到屏幕

重排: 当改变 DOM 元素位置或大小时,会导致浏览器重新渲染生成渲染树,这个过程叫重排。
重绘: 当重新生成渲染树后,就要将渲染树每个节点绘制到屏幕,这个过程叫重绘。不是所有的动作都会导致重排,例如改变字体颜色,只会导致重绘。记住,重排会导致重绘,重绘不会导致重排。
重排和重绘这两个操作都是非常昂贵的,因为 JavaScript 引擎线程和 GUI 渲染线程是互斥,它们同时只能一个在工作。
什么操作会导致重排?
- 添加或删除可见的 DOM 元素
- 元素位置改变
- 元素尺寸改变
- 内容改变
- 浏览器窗口尺寸改变
如何减少重排重绘?
- 用 JavaScript 修改样式时,最好不要直接写样式,而是替换 class 来修改样式
- 如果要对 DOM 元素进行一系列操作,可以将 DOM 元素脱离文档流,修改完成后,再将它带回文档。推荐使用隐藏元素(display:none)或者文档碎片(DocumentFragement),都能很好的实现这个方案。
12. 使用事件委托
事件委托利用了事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件。所有用到按钮的事件(多数鼠标事件和键盘事件)都适合采用事件委托技术,使用事件委托可以节省内存。
<ul>
<li>苹果</li>
<li>香蕉</li>
<li>凤梨</li>
</ul>
//
gooddocument.querySelector("ul").onclick = (event) => {
const target = event.target;
if(target.nodeName === "LI") {
console.log(target.innerHTML);
}
}
//
baddocument.querySelectorAll("li").forEach((e) =>{
e.onclick = function() {
console.log(this.innerHTML)
}
})
13. 注意程序的局部性
一个编写良好的计算机程序常常具有良好的局部性,它们倾向于引用最近引用过的数据项附近的数据项,或者最近引用过的数据项本身,这种倾向性,被称为局部性原理。有良好局部性的程序比局部性差的程序运行得更快。
局部性通常有两种不同的形式:
- 时间局部性:在一个具有良好时间局部性的程序中,被引用过一次的内存位置很可能在不远的未来被多次引用
- 空间局部性:在一个具有良好空间局部性的程序中,如果一个内存位置被引用了一次,那么程序很可能在不远的将来引用附近的一个内存位置。
时间局部性实例
function sum(array) {
let i,
sum = 0;
for(i = 0; i < len; i++) {
sum += arr[i];
}
return sum;
}
在这个实例中,变量 sum 在每次循环迭代中被引用一次,因此,对于 sum 来说,具有良好的时间局部性
空间局部性示例
function sum1(array, rows, cols) {
let i,
j,
sum = 0;
for(i = 0; i < rows; i++) {
for(j = 0; j < cols; j++) {
sum += array[i][j];
}
}
return sum;
}
空间局部性差的程序
function sum2(array, rows, cols) {
let i,
j,
sum = 0;
for(j = 0; j < cols; j++) {
for(i = 0; i < rows; i ++) {
sum += array[i][j];
}
}
}
看一下上面的两个空间局部性示例,像示例中每行开始按顺序访问数组每个元素的方式,称为具有步长为1的引用模式。
如果在数组中,每隔K个元素进行访问,就称为步长为K的引用模式。
一般而言,随着步长的增加,空间局部性下降。
这两个例子有什么区别?区别在于第一个示例是按行扫描数组,每扫描完一行再去扫下一行;第二个示例是按列来扫码数组,扫完一行中的一个元素,马上就去扫下一行中的同一行元素。
数组在内存中是按照行顺序来存放的,结果就是逐行扫描数组的示例得到了步长为1引用模式,具有良好的空间局部性;而另一个示例步长为 rows,空间局部性极差。
性能测试:
运行环境:
- cpu: i5-7400
- 浏览器:chrome 70.0
对于一个长度为9000的二维码数组(子数组也为9000)进行10次空间局部性测试,时间(毫秒)取平均值,结果如下:
所用示例为上述两个空间局部性示例
| 步长为1 | 步长为9000 |
|---|---|
| 124 | 2316 |
从以上测试结果来看,步长为1的数组执行时间比步长为9000的数组快了一个数量级
总结:
- 重复引用相同变量的程序具有良好的时间局部性
- 对于具有步长为 K 的引用模式的程序,步长越小,空间局部性越好;而在内存中以大步长跳来跳去的程序空间局部性会很差
14. if-else 对比 switch
当判断条件数量越来越多时,越倾向于使用 switch 而不是 if-else
if(color === "blue") {
} else if(color === "yellow") {
} else if(color === "white") {
} else if(color === "black") {
} else if(color === "green") {
} else if(color === "orange") {
} else if(color === "pink") {
}
swtich(color) {
case "blue":
break;
case "yellow":
break;
case "white":
break;
case "black":
break;
case "green":
break;
case "orange":
break;
case "pink":
break;
}
像以上这种情况,使用 swtich 是最好的。假设 color 的值为 pink,则 if-else 语句要进行 7 次判断,switch 只需要进行一次判断。从可读性来讲,switch 语句也更好。
从使用时机来说,当条件值大于两个的时候,使用 switch 更好。不过 if-else 也有 switch 无法做到的事情,例如由于多个判断条件的情况下,无法使用 switch。
15. 查找表
当条件语句特别多时,使用switch 和 if-else 不是最佳的选择,这时不妨试一下查找表。查找表可以使用数组和对象来构建。
switch (index) {
case: "0"
return result0;
case: "1"
return result1;
case: "2"
return result2;
case: "3"
return result3;
case: "4"
return result4;
case: "5"
return result5;
case: "6"
return result6;
case: "7"
return result7;
case: "8"
return result8;
case: "10
return result10;
case: "11"
return result11;
}
// 可以将这个 switch 语句转换为查找表const results = [result0, result1, result2, result3, result4, result5, result6, result7, result8, result9, result10, result11];return results[index];
// 如果条件语句不是数值而是字符串,可以用对象来建立查找表const map = { red: result0, green: result1}return map[color];
16. 避免页面卡顿
60fps 与设备刷新率
目前大多数设备的屏幕刷新率为 60次/秒。因此,如果在页面中有一个动画或者渐变效果,或者用户正在滚动页面,那么浏览器渲染动画或者页面的每一帧的速率也需要跟设备屏幕的刷新率保持一致。
其中每一帧的预算时间仅比 16 毫秒多一点(1秒/60 = 16.66毫秒)。但实际上,浏览器有整理工作要做,因此你的所有工作需要在 10 毫秒内完成。如果无法符合此预算,帧率将下降,并且内容会在屏幕上抖动。此现象通常称为卡顿,会对用户体验产生负面影响。

假如你用 JavaScript 修改了 DOM,并触发样式修改,经历重排重绘最后画到屏幕上。如果这其中任意一项的执行时间过长,都会导致渲染这一帧的时间过长,平均帧率就会下降。假设这一帧花了 50 ms,那么此时的帧率1s / 50ms = 20fps,页面看起来就像卡顿了一样。
对于一些长时间运行的 JavaScript,我们可以使用定时器进行切分,延迟执行。
for (let i = 0, len = array.length; i < len; i++) {
process(array[i]);
}
假设上面的循环结构由于 process() 复杂度过高或者数组元素太多,甚至两者都有,可以尝试一下切分。
const todo = array.concat();
setTimeout(function() {
process(todo.shift());
if(todo.length) {
setTimout(arguments.callee, 24);
}else {
callback(array);
}
})
17. 使用 requestAnimationFrame 来实现视觉变化
从第 16 点我们可以知道,大多数设备屏幕刷新率为 60 次/秒,也就是说每一帧的平均时间为 16.66 毫秒。在使用 JavaScript 实现动画效果的时候,最好的情况就是每次代码都是在帧的开头开始执行。从而保证 JavaScript 在帧开始时运行的唯一方式是使用 requestAnimationframe
function upateScreen(time) {
}
requestAnimationFrame(upateScreen);
如果采用 setTimout 或者 setInterval 来实现动画的话,回调函数将在帧中的某个时间点运行,可能刚好在末尾,而这可能经常会使我们丢失帧,导致卡帧。
18. 使用 Web Workers
Web Worker 使用其它工作线程从而独立于主线程之外,它可以执行任务而不干扰用户界面。一个 worker 可以将消息发到创建它的 JavaScript 代码,通过将消息发送到该代码指定的事件处理程序。
Web Worker 适用于那些处理纯数据,或者与浏览器 UI 无关的长时间运行脚本。
创建一个新的 Worker 很简单,指定一个脚本的 URL 来执行 worker 线程(main.js)
var myWorker = new Worker("worker.js");
first.onchange = function() {
myWorker.postMessage([first.value, second.value]);
console.log("Message posted to worker");
}
second.onchange = function() {
myWorker.postMessage([first.value, second.value]);
console.log("Message posted to worker");
}
在 worker 中接收到消息后,我们可以写一个事件处理函数代码作为响应(worker.js)
onmessage = function() {
console.log("Message received from main script");
var workerResult = "Result:" + (e.deta[0] * e.deta[1]);
console.log("Posting message back to main script");
postMessage(workerResult);
}
onmessage 处理函数在接收到消息后马上执行,代码消息本身作为事件的deta属性进行使用。这里我们简单的对这2个数字做乘法处理并再次使用postMessage()方法,将结果传回给主线程。
回到主线程,我们再次使用onmessage 以响应 worker 回传的消息:
myWorker.onmessage = function(e) {
result.textContent = e.deta;
console.log("Messag received from worker");
}
在这里我们获取消息事件的data,并且将它设置为 result 的 textContent,所以用户可以直接看到运算的结果。
不过在 Worker 中,不能直接操作 DOM 节点,也不能使用 window 对象的默认方法和属性。然而你可以使用大量 window 对象之下的东西。包括 WebSocketys,IndexedDB以及FireFox 专用的 Data Store API等数据存储机制。
19. 使用位运算
JavaScript 中的数字都使用 IEEE-754 标准以 64 位格式存储。但是在位操作中,数字被转换成有符号的 32 位格式。即使需要转换,位操作也比其它数字运算和布尔操作快得多。
取模
由于偶数的最低位为 0, 奇数为 1,所以取模运算可以用位操作来代替。
if(value % 2) {
}
else {
}// 位操作if(value & 1) { }else { }
取整
~~ 10.12~~ 10~~ "1.5"~~ undefined~~ null
位掩码
const a = 1;const b = 2;const c = 3;const options = a | b | c;if(b & options) { }
20. 不要覆盖原生方法
无论你的 JavaScript 代码如何优化,都比不上原生方法。因为原生方法是用低级语言写的(C/C++),并且被编译成机械码,称为浏览器的一部分。当原生方法可用时,尽量使用它们,特别是数字运算和 DOM 操作。、
21. 降低 CSS 选择器的复杂性
浏览器读取选择器,遵循的原则是从选择器的右边到左边读取
#block .text p { color; red;}
- 查找所有的 P 元素
- 查找结果 1 中的元素是否有类名位 text 的父元素
- 查找结果中 2 中的元素是否有 id 为 block 的父元素
CSS 选择器优先级
内联 > ID选择器 > 类选择器 > 标签选择器
结论:
- 选择器越短越好
- 尽量使用高优先级的选择器,例如 ID 和 类选择器。
- 避免使用通配符选择器
CSS 选择器没有优化的必要,因为最快和最慢的选择器性能差别非常小
22. 使用 flexbox 而不是较早的布局模型
在早期的 CSS 布局方式中我们能对元素实行绝对定位丶相对定位或者浮动定位。而现在,我们有了新的布局方式flexbox,它比早期的布局方式来说有个优势,那就是性能比较好。
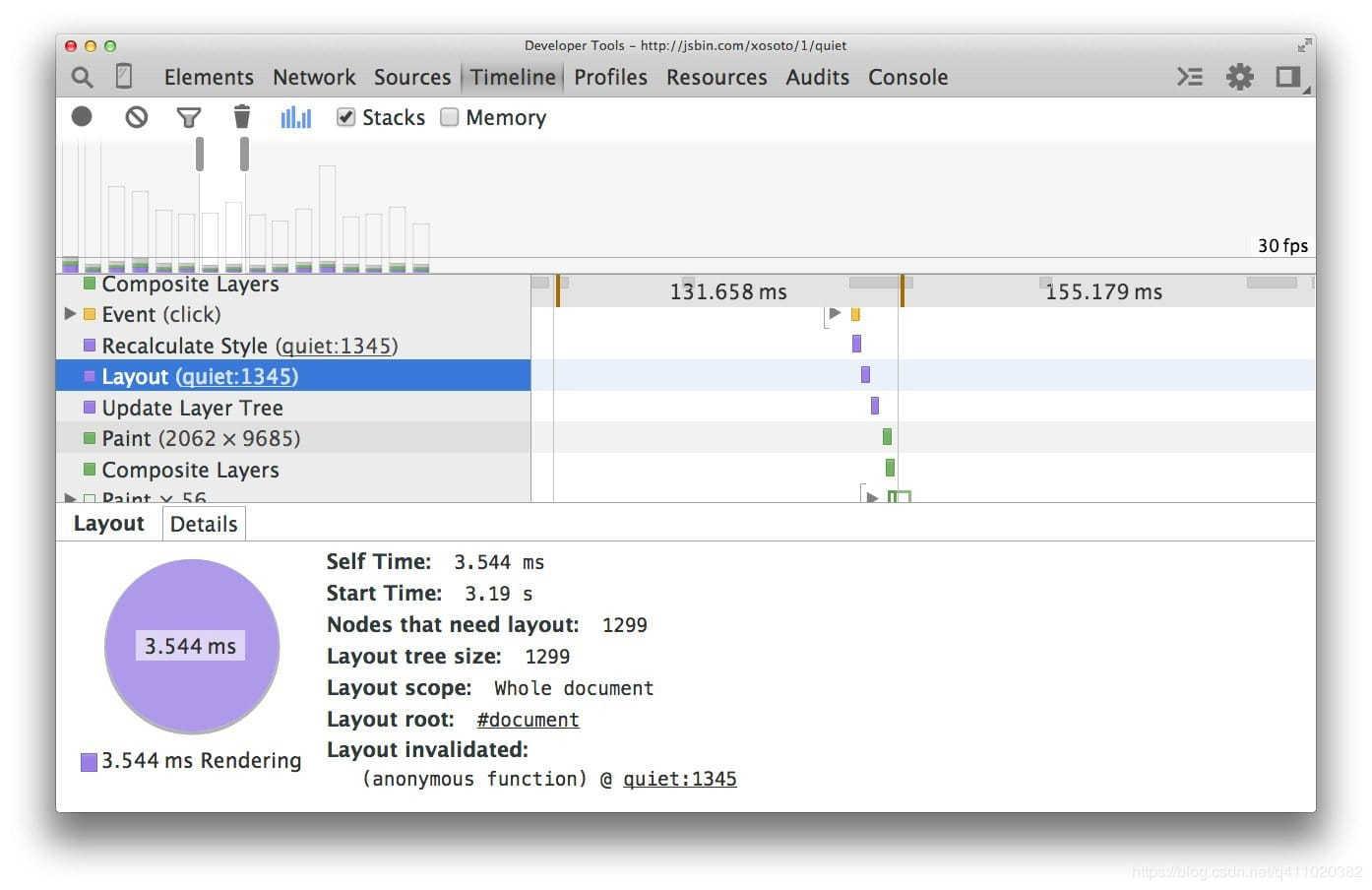
现在,对于相同数量的元素和相同的视觉外观,布局的时间要少得多
不过 flexbox 的兼容性还是有点问题,不是所有浏览器都支持它,所以要谨慎使用。
23. 使用 transform 和 opcacity 属性更改实现动画
在 CSS 中,transform 和 opacity 这两个属性更改不会重复重排和重绘,它们是可以由生成器(composite)单独处理的属性。

24. 合理使用规则,避免过度优化
性能优化主要分为两类:
-
加载时优化(1-10)
-
运行时优化(11-23)
14. 性能优化指标
FP & FCP
首次绘制,FP(First Paint),这个指标用于记录页面第一次绘制像素的时间。
首次内容绘制,FCP(First Contentful Paint),这个指标用于记录页面首次绘制文本丶图片丶非空白 Canvas 或 SVG 的时间
这两个指标看起来大同小异,但是 FP 发生的时间小于等于 FCP。
FP 指的是绘制像素,比如说页面的背景色是灰色的,那么在显示灰色背景时就记录下了 FP 指标。但是此时 DOM 内容还没开始绘制,可能需要文件下载丶解析等过程,只有当 DOM 内容发生变化才会触发,比如说渲染出一段文字,此时就会记录下 FCP 指标。因此说我们可以把这两个指标认为是和白屏时间相关的指标,所以是最快越好。
上图是官方推荐的时间区间,也就是说如果 FP 和 FCP 两指标在 2 秒内完成的话我们的页面就算体验优秀。
LCP
最大内容绘制,LCP(Largest Contentful Paint),用于记录视窗内最大的元素绘制的时间,该时间会随着页面渲染变化而变化,因为页面中的最大元素在渲染过程中可能会发生变化,另外该指标会在用户第一次交互后停止记录。指标变化如下图:
LCP 其实能比以前两个指标更能体现一个页面的性能好坏程序,因为这个指标会持续更新。举个例子:当页面出现骨架屏或者 Loading 动画时 FCP 其实被记录下来了,但是此时用户希望看到的内容其实并未呈现,我们更想知道的是页面主要的内容是何时呈现出来的。
在2.5秒内表示体验优秀
TTI
首次可交互的时间,TTI(Time to Interactive)。这个指标计算过程略微复杂,它需要满足以下几个条件
- 从 FCP 指标后开始计算
- 持续 5 秒内无长任务(执行时间超过 50 ms)且无两个以上正在进行中的 GET 请求
- 往前回溯至 5 秒前的最后一个长任务结束的时间
这里你可能会疑问为什么长任务需要定义为 50ms 以外 ?
Google 提出了一个 RAIL 模型:
对于用户交互(比如交互事件),推荐的响应时间是 100ms 以内。那么为了达成这个目标,推荐在空闲时间里执行任务不超过 50ms(W3C 也有这样的规定),这样能在用户无感知的情况下响应用户的交互,否则会造成延迟感。
长任务也会在 FID 以及 TBT 指标中使用到
因此这是一个很重要的用户体验指标,代表着页面何时真正进入可用的状态。毕竟光内容渲染的快也不够,还要能迅速响应用户的交互。相比大家应该体验过某些网站,虽然网站渲染出来了,但是响应交互很卡顿,只能过一会儿才能流程交互的情况。
FID
首次输入延迟,FID(First Input Delay),记录在 FCP 和 TTI 之间用户首次与页面交互时响应的延迟。
这个指标其实挺好理解,就是看用户交互事件触发到页面响应中间耗时多少,如果其中有长任务的话那么势必会造成响应时间变长。
其实在上文我们就讲过 Google 推荐响应用户交互在 100ms 以内
TBT
阻塞总时间,TBT(Total Blocking Time),记录在 FCP 到 TTI 之间所有长任务的阻塞时间总和。
假如说在 FCP 和 TTI 之间页面总共执行了以下长任务(执行时间大于 50ms)以及端任务(执行时间低于 50ms)
那么每个长任务的阻塞时间就等于它所执行的总时间减去 50ms.
所以对于上图的情况来说,TBT 总共等于 345ms
这个指标的高低其实也影响了 TTI 的高低,或者说和长任务相关的几个指标都有关联性。
CLS
累计位移偏移,CLS(Cumulative Layout Shit),记录了页面上非预期的位移波动。
大家想必遇到这类情况:页面渲染过程中突然插入一张巨大的图片或者说点击了某个按钮突然动态插入了一块内容等等相当影响用户体验的网站。这个指标就是为这种情况而生的,计算方式为:位移影响的面积*位移距离。
以上图为例,本文移动了 25% 的屏幕高度距离(位移距离),位移前后影响了 75% 的屏幕高度面积(位移影响的面积),那么 CLS 为 0.25 * 0.75 = 0.1875。
CLS 推荐值为低于 0.1,越低说明页面跳来跳去的情况就越少,用户体验越好。毕竟很少有人喜欢阅读或者交互过程中网页突然动态插入 DOM 的情况,比如说插入广告~
介绍完了所有的指标,接下来我们来了解下哪些是用户体验的三大核心指标丶如何获取相应的指标数据及如何优化。
三大核心指标
Google 在今年五月提出了网站用户体验的三大核心指标,分别是:
- LCP
- FID
- CLS
LCP 代表了页面的速度指标,虽然还存在其它的一些体现速度的指标,但是上文也说过 LCP 能体现的东西更多一些。一是指标实时更新,数据更精确,二是代表着页面最大元素的渲染时间,通常来说页面最大元素的快速载入能让用户感觉性能还挺好的。
FID 代表了页面的交互体验指标,毕竟没有一个用户希望触发交互以后页面的反馈很迟缓,交互响应的快会让用户觉得网页挺流畅。
CLS 代表了页面的稳定指标,尤其在手机上这个指标更为重要。因为手机屏幕越小,CLS 值一大的话会让用户觉得页面体验做的很差。
如何获得指标
lighthouse
你可以提高安装 lighthouse 插件来获得如下指标
web-vitals-extension
官方出品,你可以通过安装 web-vitals-extension 插件来获取三大核心指标
web-vitals 库
官方出品,你可以通过安装 web-vitals 包来获取如下指标
代码使用方式也挺简单:
import {getCLS, getFID, getLCP} from 'web-vitals';getCLS(console.log);getFID(console.log);getLCP(console.log);
Chrome DevTools
这个工具不多做介绍了,打开 Perfomance 即可快速获取如下指标
如何优化指标
资源优化
改项措施可以帮助我们优化 FP 丶FCP丶LCP 指标。
-
压缩文件丶使用 Tree-shaking 删除无用代码
-
服务端配置 Gzip 进一步再压缩文件体积
-
资源按需加载
-
通过 Chrome DevTools 分析首屏不需要使用的 CSS 文件,以此来精简 CSS
-
内联关键的 CSS 代码
-
使用 CDN 加载资源及 dns-prefetch 预解析 DNS 的 IP 地址
<link rel="dns-prefetch" href="//delai.me"> -
对资源使用 preconnect,以便预先进行 IP 解析丶TCP 握手丶TLS 握手
<link rel="preconnect" href="http://xxxxxx" > -
缓存文件,对首屏数据做离线缓存
-
图片优化,包括:用 CSS 代替图片丶裁剪适配屏幕的图片大小丶小图使用 base64 或者 PNG 格式丶支持 WebP 就尽量使用 WebP丶渐进式加载图片
网络优化
该项措施可以帮助我们优化 FP丶FCP丶LCP 指标。
这块内容大多数可以让后端或者运维帮你去配置,升级至最新的网络协议通常让你网站加载的更快。
比如说使用 HTTP2.0 协议丶TLS 1.3 协议或者直接拥抱 QUIC 协议
优化耗时任务
该项措施可以帮助我们优化 TTI 丶FID丶TBT 指标。
- 使用 Web Worker 将耗时任务丢到子线程中,这样能让主线程再不卡顿的情况下处理 JS 任务。
- 调度任务 + 时间切片,这块技术在 React 16 中有使用到。简答来讲就是给不同的任务分配优先级,然后将一段长任务切片,这样能保证任务只能在浏览器的空闲时间中执行而不卡顿主线程
不要动态插入内容
该项措施可以帮助我们优化 CLS 指标
- 使用骨架屏给用户一个预期的内容框架,突兀的显示内容体验不会很好
- 图片切勿不设置长宽,而是使用占位图给用户一个图片位置的预期
- 不要在现有的内容中间插入内容,起码给出一个预留位置
15. 一个网页从请求到呈现花了很长时间,如何排查?
查看面板

响应比较慢可以从两个层面去考虑
- 连接初始化阶段耗时
- 请求和响应耗时
查看关键指标:
-
排队
- 达到浏览器最大并发数量限制
- 有更高优先级的请求插队,低优先级的任务被延后
- 系统内存空间不足,浏览器使用磁盘空间
-
拥堵原因和排队中类似
-
DNS查询 花在 DNS 查询上的时间
-
Proxy negotiation 代理协商
-
Request sent 请求被发送
-
Request to ServiceWorker 请求被发送到 ServiceWorker
-
Waiting (TTFB) 等待收到响应的第一个字节
-
Context Download 内容下载
-
Receiving Push 浏览器通过HTTP/2 Server Push 接受数据
-
Reading Push 浏览器读取之前收到的数据
常见问题现象及解决方法
出现长时间的排队或者拥堵

原因:浏览器对同一个域名最大的 TCP 链接数有限制,超过限制的请求会被排队。
为什么会达到最大并发数?
- 一次性获取到资源数量太多
- 资源体积太大,很多都在下载中
- 有些请求响应太慢或者无响应。例如一分钟之内,每隔10秒钟发送一个无响应的请求,随着可用的请求慢慢被沾满,正常的请求排队数量会越来越多。
解决方法:
- **减少请求数量:**可以移除不必要的请求,或者将多个请求合并成一个。例如雪碧图
- **使用域名分片:**例如使用不同的域名指向相同的资源,从而突破域名的限制。例如 img1.tt.cc/1.jpg 和 img2.tt.cc/1.jpg
- **前端给每个 Ajax 请求设置超时:**防止过多的无响应请求占据着连接资源,可以在超时之后释放连接。有些 Ajax 库,例如 jQuery 的 Ajax,默认是没有设置超时时长的,当你使用这些库时,最好明确的设置。
- **后端设置请求处理超时:**后端接口应设置最长超时时长
长时间的 TTFB

出现这种问题从两个方面排查:
- 客户端到服务端之间的网络通信比较慢
- 服务端的响应比较慢,可能是服务端压力太大,达到宽带上限,内存溢出,高CPU,IOwait高,Recv-Q高,或者 sql 查询慢等各种原因
注意:对于同一个源的请求,如果有些请求很快,有些请求很慢。那么问题一般是服务端的问题。因为如果是网络通信比较慢,那么则所有的请求都会变慢的。
16. 首屏加载如何优化
白屏加载和首屏加载时间的区别?
-
白屏时间是指浏览器从响应用户输入网址,到浏览器开始显示内容的时间
-
首屏时间是指浏览器从响应用户输入网址地址到首屏内容渲染完成的时间吗,此时整个网页不一定要全部渲染完成,但在当时视窗的内容需要。
-
白屏时间是首屏时间的一个子集。
如何优化首屏加载时间?
-
**CDN 分发(减少传输时间):**通过多台服务器部署相同的副本,当用户访问的时,服务器根据用户跟哪台服务器距离距离近,来决定哪台服务器去响应这个请求。
-
**后端在业务层的缓存:**数据库查询缓存是可以设置缓存的,这个对于处于高频率的请求很有用。浏览器一般不会对于
content-type:application/json的接口进行缓存;所以有时需要我们手动地为接口设置缓存。比如一个用户的签到状态,它的缓存时间可以设置到明天之前。 -
静态的资源
-
前端的资源动态加载:
- 路由动态加载,最常用的做法,以页面为单位,进行动态加载
- 组件动态加载,对于不在当前视窗的组件,先不加载
- 图片懒加载,越来越多的浏览器支持原生的懒加载,通过给 img 标签加上 loading=“lazy” 来开启懒加载模式
-
减少请求的数量:这点在 http1.1的优势很明显,因为 http1.1 的请求是串行的(尽管多个 tcp 通道),每个请求都需要往返后才能请求下一个请求。此时合并请求可以减少在路途上浪费的时间,此外还会带来重复的请求头部信息(比如 cookie)。在 http2.0 中这个问题会弱化很多,但也有做的必要。
-
**页面使用骨架屏:**意思是在首屏加载完成之前,通过渲染一些简单的元素占位。骨架屏的好处在于可以减少用户等待时的急躁情绪。这点很有效,在很多成熟的(京东丶淘宝丶YouTube)都有大量应用。没有骨架屏的话,一个 loading 的菊花图也是可以的。
-
使用 SSR 渲染
-
**引入 HTTP2.0:**HTTP2.0 对比 HTTP1.1,最重要的提升是传输性能,在接口小而多的时候更加明显。
-
**利用好 HTTP压缩:**即使是最普通的 gzip,也能把 boostrap.mini.css 压缩到原来的17%。可见,压缩的效果非常明显,特别是对于文本类的静态资源。另外,接口也是能压缩的。接口不大的话不用压缩,因为性价比低(考虑压缩和解压的时间)。
-
**利用好 script 标签的 async 和 defere 这两个属性:**功能独立且不要求马上执行的 JS 文件,可以加上 async 属性。如果是优先级低且没有依赖的 JS,可以加上 defere 属性。
-
**(少用)选择先进的图片格式:**使用 WebP 的图片格式来代替现有的 jpeg 和 peg,当页面图片较多时,这点作用非常明显。把部分大容量的图片从 B
-
**目前(少用)渲染的优先级:**浏览器有一套资源的加载优先级策略,也可以通过 JS 来自己控制请求的顺序和渲染的顺序。一般我们不需要这么细粒度的控制,而且控制的代码也不好写。
-
**(少用)前端做一些接口缓存:**前端也可以做接口缓存,缓存的位置有两个,一个是内存,即赋值给运行时的变量,另一个是 localStorage。比如用户的签到日历(展示用户是否签到),我们可以缓存这样的接口到 localStorage,有效期是当天。或者有个列表页,我们总是缓存上次的列表内容到本地,下次加载时,我们先从本地读取缓存,并同时发起请求到服务器获取最新列表。
-
对于第三方 JS 库的优化,分离打包
生产环境是内网的话,就把资源放内网,通过静态文件引入,会比 node_module 和外网 CDN 的打包加载快很多。如果有外网的话,可以通过 CDN 的方式引入,因为不用占用外网的宽带,不仅可以为您节省流量,还可以通过 CDN 加速,获得更快的访问速度。但是要注意的是,如果你引用的 CDN 资源在于第三方服务器,在安全性上并不完全可控的。
目前采用引入依赖包生产环境的 JS 文件方式加载,直接通过 window 可以访问暴露出的全局变量,不必通过 import 引入,Vue.use去注册。
在 webpack 的 dev 开发配置文件中,加入如下参数,可以分离打包第三方资源包,key 为依赖包名称,value 是源码抛出来的全局变量。如下图所示,可以看到打包后的 Vue 相关资源排除在外了。对于一些其他的工具库,尽量按需引入的方式。
externals: { vue: "Vue", vuex: "Vuex", "vue-router": "vueRouter", axios: "axios", "element-ui": "ELEMENT" } -
Vue-router 使用懒加载
在访问当前页面才会加载相关的资源,异步方式分模块加载文件,默认的文件是随机的 id。如果在 output 或者配置了 chunkFilename,可以在 component 中添加了 webpackChunkName,是为方便调试,在页面加载时候,在页面加载时候,会显示加载的对应文件名 + hash值,如下图:
{ path: "/Login", name: "Login", component: () => import(/* webpackChunkName: "Login" */ "@/view/Login") } -
开启 gzip 压缩
gzip 压缩是一种 http 请求优化方式,通过减少文件体积来提高加载速度。HTML丶JS丶CSS 文件甚至 JSON 数据都可以用它压缩,可以减少 60% 以上的体积。前端配置 gzip 压缩,并且服务端使用 nginx 开启 gzip,用来减少网络传输的流量带下。
npm i compression-webpack-plugin -D // 在 webpack 的 dev 开发配置文件加入以下代码 const CompressionWebpackPlugin = require("compression-webpack-plugin"); plugins: [ new CompressionWebpackPlugin() ]启动 gzip 配置打包之后,会变成下面这样,自动生成 gz 包。目前大部分主流的浏览器客户端都是支持 gzip 的,就算小部分非主流浏览器也不支持也不用担心,不支持 gzip 格式文件的会默认访问源文件的,所以不要配置清楚源文件。
配置好后,打开浏览器访问线上,F12 查看控制台,如果该文件资源的响应头里显示有 Content-Encoding: gzip,表示浏览器支持并且启用了 gzip 压缩的资源。
-
前端页面代码层面的优化
- 合理使用 v-if 和 v-show
- 合理使用 watch 和 computed
- 使用 v-for 必须添加 key,最好为唯一 id,避免使用 index,且在同一个标签上,v-for 不要和 v-if 同时使用
- 定时器的销毁。可以在 beforeDestroy() 声明周期内执行销毁事件;也可以使用 $once 这个事件监听器,在定义定时器事件的位置来清除定时器。
-
图片资源的压缩,icon 资源使用雪碧图
17. 前端模块化发展史
模块化的开发方式可以提高代码复用率,方便进行代码的管理。通常一个文件就是一个模块,有自己的作用域,只能向外暴露特定的变量和函数。目前流行的 JS 模块化规范有 CommonJS 丶 AMD丶CMD 以及 ES6的模块化系统。
CommonJS
Node.js 是 commonJS 规范的主要实践者,它有四个重要的环境变量为模块化的实现提供支持:module丶exports丶require丶global,用 module.exports 定义当前模块对外输出的接口(不推荐直接使用 exports),用 require 加载模块。
// 定义模块
math.jsvar basicNum = 0;
function add (a, b) {
return a + b;
}
module.exports = { // 在这里写上向外暴露的函数丶变量
add: add,
basicNum: basicNum
}
// 引用自定义模块,参数包含路径,可省略.js
var math = require("./math");math.add(2, 5);// 引用核心模块,不需要带路径
var http = require("http");
http.createService(...).listen(3000);
CommonJS 用同步的方式加载模块,在服务端,模块文件都存在本地磁盘,读取非常快,所以这样做不会有问题。但是在浏览器端,限于网络原因,更合理的方案是使用异步加载。
AMD 和 require.js
AMD 规范使用异步方式加载模块,模块的加载不影响它后面语句的执行。所有依赖这个模块的语句,都定义在一个回调函数中,等到加载完成之后,这个回调函数才会执行。这里介绍用 require.js 实现 AMD 规定的模块化;用 require.config() 指定引用路径等,用 define() 定义模块,用 require() 加载模块。
首先我们需要引入 require.js 文件和一个入口文件 main.js。main.js 中配置 require.config() 并规定项目中用到的基础模块。
// 网页中引入 require.js 及 main.js
<script src="js/require.js" data-main="js/main"></script>
// 在 main.js 入口文件/模块
require.config({
baseUrl: "js/lib",
path: {
"jquery":
"jquery.min" // 实际路径为 js/lib/juqery.min.js
"underscore": "underscore.min"
}
})
// 执行基本操作
require(["jquery", "underscore"], function($, _) { // some code here
})
引用模块的时候,我们将模块名放在 [] 中作为 require 的第一个参数;如果我们定义了模块本身也依赖其它模块,那就需要将它们放在 [] 中作为 define() 的第一个参数
defined(function() {
var basicNum = 0;
var add = function(x, y) {
return x + y;
};
return {
add: add,
basicNum: basicNum
}
})
// 定义一个依赖 underscore.js 的模块
define(["underscore"], function(_) {
var classify = function(list) {
_.countBy(list, function(num) {
return num > 30 ? "old" : "young"
})
}
return {
classify: classify
}
})
// 引用模块 将模块放在 [] 内
require(["jquery", "math"], function($, math) {
var sum = math.add(10, 20);
$("#sum").html(sum);
})
CMD 和 sea.js
require.js 在申明依赖的模块时会在第一时间加载并执行模块内的代码
define(["a", "b", "c", "d", "e", "f"], function(a, b, c, d, e, f) { // 等于在最前面声明并初始化了要用到的所有模块 if(false) { // 即便没有用到某个模块 b,但 b 还是提前执行了 b.foo(); }})
CDM 是另一种 JS 模块化方案,它与 AMD 很类似,不同点在于:AMD 推崇依赖前置丶提前执行,CMD 推崇依赖就近丶延迟执行。此规范其实是在 sea.js 推广过程中产生的。
// AMD 写法define(["a", "b", "c", "d", "e", "f"], function(a, b, c, d, e, f) { // 对于在最前面声明并初始化了要用到的所有模块 a.doSomething(); if(false) { // 即使没有用到某个模块 b 但 b 还是提取执行了 b.doSomething(); }})// CMD 写法define(function(require, exports, module) { var a = require("jquery.js"); a.doSomething(); if(false) { var b = require("./b"); b.doSomething(); }});// sea.js// 定义模块 math.jsdefine(function(require, exports, module) { var $ = require("jquery.js"); var add = function(a, b) { return a + b; } exports.add = add;})// 加载模块seajs.use(["math.js"], function(math) { var sum = math.add(1 + 2);})
ES6 Module
ES6 在语言标准的层面上,实现了模块化,而且实现得相当简单,旨在成为浏览器和服务器通用的模块化解决方案。其模块功能主要由两个命令构成:export 和 import。 export命令用于规定模块化的对外接口,import 命令用于输入其它模块提供的功能。
// 定义模块 math.jsvar basicNum = 0;var add = function(a, b) { return a + b;};exports { basicNum, add };// 引用模块import { basicNum, add } from './math';function test(ele) { ele.textContext = add(99 + basicNum);}
如上例所示,使用 import 命令的时候,用户需要知道要加载的变量名或者函数名。其实 ES6 还提供了 export default 命令,为模块指定默认输出,对应的 import 语句不需要使用大括号。这也更趋势近于 AMD 的引用写法。
// export default 定义输出export default { basicNum, add }// 引入import math from "./math";function test(ele) { ele.textContent = math.add(99 + math.basicNum);}
ES6 的模块不是对象,import 命令会被 JavaScript 引擎静态分析,在编译时就引入模块代码,而不是在代码运行时加载,所以无法实现条件加载。也正因为这个,使得静态分析成为可能。
ES6 模块于 CommonJS 模块的差异
- CommonJS 模块输出的是一个值的拷贝,ES6 模块输出是值的引用。
- CommonJs 模块输出的是值的拷贝,也就是说,一旦输出一个值,模块内部的变化就影响不到这个值
- ES6 模块的运行机制与 CommonJS 不一样,JS 引擎对脚本静态分析的时候,遇到模块加载命令 import,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。换句话说,ES6 的 import 有点像 Unix 系统的”符号连接“,原始值变了,import 加载的值也会跟着变。因此,ES6 模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。
- CommonJS 模块运行时加载, ES6 模块是编译时输出接口
- 运行时加载:CommonJS 模块就是对象:即在输入时是先加载整个模块,生成一个对象,然后再从这个对象上面读取方法,这种加载称为”运行时加载“
- 编译时加载:ES6 模块不是对象。而是通过 export 命令显示指定输出的代码,import 时采用静态命令的形式。即在 import 时可以指定加载某个输出值,而不是加载整个模块,这种加载称为”编译时加载“。
CommonJS 加载的是一个对象(即 module.exports属性),该对象只有在脚本完成时才会生成。而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码编译解析阶段就会生成。
18. 拷贝(手写)
18-1. 浅拷贝
创建一个新的对象,把原有的对象属性值,完整的拷贝过来。其中包括了原始类型的值,还有引用对象的内存地址。
Object.assign() Array.prototype.slice() 和 Array.prototype.concat() 还有 ES6 的拓展运算符 都属于浅拷贝
18-2. 深拷贝
拷贝所有的属性值,以及属性地址指向的值的内存空间。
function deepClone(obj) { if(!obj && typeof obj != "object") { return; } var newObj = toString.call(obj) === '[object Array]' ? [] : {}; for(var key in obj) { if(obj[key] && typeof obj[key] === "object") { newObj[key] = deepClone(obj[key]); }else { newObj[key] = obj[key]; } } return newObj;}// 测试let arr = [{a: 1, b: 2}, {a: 3, b: 4}];let newArr = deepClone(arr);newArr.length = 1;console.log(newArr);console.log(arr);newArr[0].a = 123;console.log(arr[0]);newArr[0].a = 123;console.log(arr[0]);// 但是这个方法会存在 引用失效 的问题var b = {};var a = {a1: b, a2: b};console.log(a.a1 === a.a2);var c = deepClone(a);console.log(c.a1 === c.c2);
一行代码的深拷贝:JSON.parse(JSON.stringify)
let arr = [{a: 1, b: 2}, {a: 3, b: 4}];let newArr2 = JSON.parse(JSON.stringify(arr));console.log(arr[0]);newArr2[0].a = 123;console.log(arr[0])
但是,JSON内部采用递归的方式。数据一旦多,就会有递归爆栈的风险
解决爆栈: cloneForce
- 如果保持引用不是你想要的,就不能用 cloneForce
- 在对象数量较多的时候会出现很大的问题,如果数据量很大不适用 cloneForce
// 保持引用关系function cloneForce(x) { // ============= const uniqueList = []; // 用来去重 // ============= let root = {}; // 循环数组 const loopList = [ { parent: root, key: undefined, data: x, } ]; while(loopList.length) { // 深度优先 const node = loopList.pop(); const parent = node.parent; const key = node.key; const data = node.data; // 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素 let res = parent; if (typeof key !== 'undefined') { res = parent[key] = {}; } // ============= // 数据已经存在 let uniqueData = find(uniqueList, data); if (uniqueData) { parent[key] = uniqueData.target; continue; // 中断本次循环 } // 数据不存在 // 保存源数据,在拷贝数据中对应的引用 uniqueList.push({ source: data, target: res, }); // ============= for(let k in data) { if (data.hasOwnProperty(k)) { if (typeof data[k] === 'object') { // 下一次循环 loopList.push({ parent: res, key: k, data: data[k], }); } else { res[k] = data[k]; } } } } return root;}function find(arr, item) { for(let i = 0; i < arr.length; i++) { if (arr[i].source === item) { return arr[i]; } } return null;} var b = {};var a = {a1: b, a2: b};console.log(a.a1 === a.a2) // truevar c = cloneForce(a);console.log(c.a1 === c.a2) // true
总结:cloneForce:保持引用关系??
19. 数组去重丶数组乱序(手写)
数组去重
利用 API
Set 方法
但是无法去除对象
var arr = [2, 1, 3, 4, 1, 1];console.log([...new Set(arr)]);
数组的 indexOf 方法
function unique(arr) { var len = arr.length newArr = []; for(var i = 0; i < len; i++) { if(newArr.indexOf(arr[i]) === -1) { newArr.push(arr[i]) } } return newArr;}// 测试var arr = [2, 1, 3, 4, 1, 1, {}, {}];console.log(unique(arr));
利用对象的属性不能相同的特点进行去重
无法去重对象 可以去重空对象
function unique(arr) { if(!Array.isArray(arr)) { console.log("type error!"); return; } var newArr = [], obj = {}, len = arr.length; for(var i = 0; i < len; i++) { if(!obj[arr[i]]) { newArr.push(arr[i]); obj[arr[i]] = 1; }else { obj[arr[i]] ++; } } return newArr;}// 测试var arr = [2, 1, 3, 4, 1, 1, {}, {}];console.log(unique(arr));
数组乱序
利用 sort 进行排序
直接利用 sort 进行排序,有漏洞,大部分元素位置没有移动
var arr = [1, 2, 3, 4, 5];var newArr = arr.sort((a, b) => (Math.random() > 0.5 ? -1 : 1));console.log(newArr);
经典洗牌算法实现
function shuffle(arr) { let len = arr.length, randomIndex, // 随机数 tempItem; // 存储临时数据 for(let i = len - 1; i >= 0; i--) { randomIndex = Math.floor(Math.random() * (i + 1)); // 交换位置 // tempItem = arr[randomIndex]; // arr[randomIndex] = arr[i]; // arr[i] = tempItem; [arr[i], arr[randomIndex]] = [arr[randomIndex], arr[i]]; } return arr;}// 测试var arr = [1, 2, 3, 4, 5];console.log(shuffle(arr));
20. ajax丶axios丶fetch 之间优缺点对比
Ajax
定义:
-
Ajax 即
Asynchronous Javascript And XML(异步 JavaScript 和 XML),是指一种创建交互式网页应用的网页开发技术。 -
对于 IE7+ 和其他浏览器,可以直接使用
XMLHttpRequest对象,对于 IE6 以及以前的浏览器,使用ActiveXObject对象
优点:
-
**提高了性能和速度:**减少了客户端和服务端之间的流量传输,同时减少了双方响应的时间,响应更快,因此提高了性能和速度
-
**交互性好:**使用 AJAX,可以开发更快,更具交互性的 Web 应用程序
-
**异步调用:**Ajax 对 Web 服务器进行异步调用。这意味着客户端浏览器在开始渲染之前避免等待所有数据到达
-
**节省宽带:**基于 Ajax 的应用程序使用较少的服务器宽带,因为无需重新加载完整的页面
-
底层使用 XMLHttpRequest
-
**拥有开源 JavaScript 库:**jQuery
-
Ajax 通过 HTTP 协议进行通信

缺点:
- 增加了设计和开发的时间
- 比构建经典 Web 应用程序更复杂
- Ajax 应用程序中的安全性较低(容易受到 CSRF 和 XSS 攻击),因为所有文件都是在客户端下载的
- 可能会出现网络延迟的问题
- 禁用 JavaScript 的浏览器无法使用该应用程序
- 由于安全限制,只能使用它访问服务于初始页面的主机的信息。如果需要显示来自其它服务器的信息,则无法在 AJax 中显示。
原理实现:
function ajax(method, url, data, success, boolean) { var xhr = null; if(window.XMLHttpRequest) { xhr = new XMLHttpRequest(); }else { xhr = new ActiveXObject('Microsoft.XMLHTTP'); } if(method === 'get' && data) { url += '?' + data; } xhr.open(method, url, boolean); if(method == 'get') { xhr.send(); }else { xhr.setRequestHeader('Content-Type', 'application/x-www-urlencoded'); xhr.send(data); } xhr.onreadystatechange = function() { if(xhr.readyState == 4) { if(xhr.status == 200) { success(xhr.responseText); }else { alert('出错了;Err ' + xhr.status); } } }}
Axios
其实 Axios 也是对原生 XMLHttpRequest 的一种封装,不过是 Promise 实现版本。它是一个用于浏览器和 nodejs 的 HTTP 客户端。
axios有一下特征:
- 从浏览器中创建 XMLHttpRequest
- 从 node.js 创建 http 请求
- 支持 Promise API
- 拦截请求和响应
- 转换请求数据和响应数据
- 取消请求
- 自动转换 JSON 数据
- 客户端支持防御 XSRF
fetch
定义:
fetch 是 Ajax 的替代品,是在 ES6 出现的,使用了 ES6 中的 Promise 对象。Fetch 是基于 Promise 设计的。Fetch 的代码结构比起 Ajax 简单多了,参数有点像 jQuery Ajax。但是,一定记住 Fetch 不是 Ajax 的进一步封装,而是原生 JS,没有使用 XMLHttpRequest。
优点:
- 符合关注分离,没有将输入丶输出和用事件来跟踪的状态混杂在一个对象里
- 更好更方便的写法
- 更加底层,提供的 API 丰富
- 脱离了 XHR,是 ES 规范里新的实现方式
- fetch 中可以设置 mode 为
no-cors(不跨域)
缺点:
- 不支持同步请求
- 只对网络请求报错,对400丶500都当成成功的请求,需要封装去处理
- 默认不会带 cookie,需要添加配置项
- 不支持 abort,不支持超时控制,使用 setTimeout 及 Promise.reject 的实现的超时控制并不能阻止请求过程继续在后台运行,造成了流量的浪费。
- fetch 没有办法原生监测请求的进度,而 XHR 可以
21. 跨域
什么是跨域?
跨域是指一个域下的文档或脚本试图去请求另一个域下的资源,这里的跨域是广义的。
广义的跨域:
- 资源跳转:A链接丶重定向丶表单提交
- 资源嵌入:丶
其实我们通常说的跨域是狭义的,是由浏览器同源策略限制的一类请求场景。
什么是同源策略?
同源策略/SOP(Same origin policy)是一种约定,由 Netscape 公司 1995 年引入浏览器,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,浏览器是很容易收到 XSS丶SDRF等攻击。所谓同源策略,浏览器是很容易受到 XSS 丶CSRF 等攻击。所谓同源策略是指“协议 + 域名 + 端口‘三者相同,即便两个不同的域名指向同一个 IP 地址,也非同源。
同源策略限制以下几种行为:
- Cookie 丶LocalStorage 和 IndexDB 无法读取
- DOM 和 JS 对象无法获得
- AJAX 请求不能发送
跨域解决方案
- 通过 JSONP 跨域
- document.domain + iframe 跨域
- location.hash + iframe
- window.name + iframe 跨域
- postMessage 跨域
- 跨域资源共享(CORS)
- Nginx 代理
- NodeJs 中间件代理跨域
- WebSocket 协议跨域
通过 JSONP 跨域
通常为了减轻 Web 服务器的负载,我们把 JS丶CSS丶Img 等静态资源分离到另一台独立域名的服务器上,在 HTML 页面中通过相应的标签从不同域名下加载静态资源,而被浏览器允许,基于此原理,我们可以通过动态创建 script,再请求一个带网址实现跨域通信。
原生实现
<script> var script = document.createElement("script"); script.type = "text/javascript"; // 传参一个回调函数名给后端,方便后端返回时执行这个在前端定义的回调函数 script.src = "http://www.domain2.com:8080/login?user=admin&callback=handleCallback"; document.head.appendChild(script); // 回调执行函数 function handleCallback(res) { alert(JSON.stringify(res)); }</script>
服务端返回如下(返回时即执行全局函数)
handleCallback({ "status": true, "user": "admin" })
jQuery Ajax
$.ajax({ url: "http://www.domain2.com:8080/login", type: "get", dataType: "jsonp", 请求方式为 json jsonCallback: "handleCallback" // 自定义回调函数名, data: {}})
Vue.js
this.$http.jsonp("http://www.domain2.com:8080/login", { params: {}, jsonp: "handleCallback"}).then((res) => { console.log(res)})
后端 Node.js 代码示例
var querystring = require("querystring");var http = require("http");var server = http.createServer();server.on("request", function(req, res) { var params = qs.parse(req.url.split("?")[1]); var fn = http.createServer(); // JSONP 返回设置 res.writeHead("Content-Type", "text/javascript"); res.write(fn + '(' + JSON.stringify(params) + ')' ); res.end();})server.listen("8080");console.log('Server is running at port 8080...');
JSONP缺点:只能实现 Get 一种请求
document.domain + iframe 跨域
此方案仅限主域相同,子域不同的跨域应用场景
实现原理:两个页面都通过 JS 强制设置 document.domain 为基础主域,就实现了同域。
父窗口:http://www.domain.com/a.htlm
<iframe id="iframe" src="http://child.domain.com/b.html"></iframe><script> document.domain = "domain.com"; var user = "domain";</script>
子窗口:http://.child.domain.com/b.html
<script> document.domain = "domain.com"; // 获取父窗口中变量 alert("get is data from parent --> " + window.parent.user);</script>
location.hash + iframe 跨域
实现原理:A 欲与 B 跨域相互通信,通过中间页 C 来实现。三个页面,不同域之间利用 iframe 的 location.hash 传值,相同域之间直接 JS 访问来通信。
具体实现:A域:a.html -> B 域:b.html -> A域:c.html,a 和 b 不同域只能通过 hash 值单向通信,b 与 c 也不同域只能单向通信,但 c 与 a 同域,所以 c 可通过 parent.parent 访问 a 页面访问所有对象。
a.htlm:(http://www.domain1.com/a.html)
<iframe id="iframe" src="http://www.domain2.com/b.html" style="display: none"></iframe><script> var iframe = document.getElement("iframe"); // 向 b.html 传 hash 值 setTimeout(function () { iframe.src = iframe.src + "#user=admin"; }, 1000); // 开发给同域 c.html 的回调方法 function onCallback(res) { alert("data from c.html --> " + res) }</script>
b.html:(http://www.domain1.com/a.html)
<iframe id="iframe" src="http://domain1.com/c.html" style="display: none;"></iframe><script> var iframe = document.getElement("iframe"); // 监听 a.html 传来的 hash 值,再传给c.html window.onhashchange = function() { iframe.src = iframe.src + location.hash; }</script>
c.html:(http://www.domain1.com/c.html)
<script> // 监听 b.html 传来的 hash 值 window.onhashchange = function() { // 再通过操作同域 a.html 的 JS 回调,将结果传来 window.parent.parent.onCallback("hello: " + location.hash.replace("#user", '')); }</script>
window.name + iframe 跨域
window.name 属性的独特之处:name 值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值。(2MB)
a.html:(http://www.domain1.com/a.html)
var proxy = function(url, callback) { var state = 0; var iframe = document.createElement("iframe"); // 加载跨域页面 iframe.src = url; // onload 事件会触发 2 次,第 1 次加载跨域页,并留存数据于 window.name iframe.onload = function() { if(state === 1) { // 第 2 次 onload(同域 proxy 页)成功后,读取同域 window.name 中数据 callback(iframe.contentWindow.name); destoryFrame(); }else if(state === 0) { // 第 1 次 onload(跨域页)成功后,切换到同域代理页面 iframe.contentWindow.location = "http://domain1.com/proxy.html" state = 1; } } document.body.appendChild(iframe); // 获取数据以后销毁这个 iframe,释放内存;这也保证了(不被其它域 frame js 访问) function destoryFrame() { iframe.contentWindow.document.write(""); iframe.contentWindow.close(); document.body.removeChild(iframe); }}// 请求跨域 b 页面数据proxy("http://www.domain2.com/b.html", function(data) { alert(data);})
proxy.html:(http://www.domain1.com/proxy.html)
中间代理页,与 a.html 同域,内容为空即可。
b.html:(http://www.domain2.com/b.html)
<script> window.name = "This is domain2 data!";</script>
总结:通过 iframe 的 src 属性由外域转向本地域,跨域数据即由 iframe 的 window.name 从外域传递到本地域。这个就巧妙绕过了浏览器的跨域访问限制,但同时它又是安全操作。
postMessage 跨域
postMessage 是 HTML5 XMLHttpRequest Level 2 中的 API ,且是为数不多可以跨域操作的 window 属性之一,它可用于解决以下方面的问题。
- 页面和其打开的新窗口的数据传递
- 多窗口之间消息传递
- 页面与嵌套的 iframe 消息传递
- 上面三个场景的跨域数据传递
用法:postMessage(data, origin) 方法接受两个参数
data: html5 规范支持任意基本类型或可复制的对象,但部分浏览器只支持字符串,所以传参时最好用 JSON.string() 序列化。
origin:协议 + 主机 + 端口号,也可以设置为 “*”,表示可以传递给任意窗口,如果要指定和当前窗口同源的话设置为“/”
a.html:(http://www.domain1.com/a.html)
<iframe id="iframe" src="http://www.domain2.com/b.html" style="display: none;"></iframe><script> var iframe = document.getElementById("iframe"); iframe.onload = function() { var data = { name: "aym" } // 向 domain2 传递跨域数据 iframe.contentWindow.postMessage(JSON.stringfy(data), "http://www.domain2.com"); } // 接受 domain2 返回数据 window.addEventListener("message", function(e) { alert("data from domain2 ---> ", e.data); })</script>
b.html:(http://www.domain2.com/b.html)
<script> // 接收 domain1 的数据 window.addEventListener("message", function() { alert('data from domain1 --> ', e.data); var data = JSON.parse(e.data); if(data) { data.number = 16; // 处理后再发回 domain1 window.parent.postMessage(JSON.stringify(data), "http://www.domain1.com"); } }, false)</script>
跨域资源共享(CORS)
普通跨域请求:只要服务端设置 Access-Control-Origin 即可,前端无须设置,若要带 Cookie 请求:前后端都需要设置。
需注意的是:由于同源策略的限制,所读取的 Cookie 为跨域请求接口所在域的 Cookie,而非当前页。如果要想实现当前页 Cookie 的写入, 可参考下文:七丶Nginx 反向代理中设置 proxy_cookie_domain 和 八丶NodeJs 中间件代理中 cookieDomainRewrite 参数的设置。
目前,所有浏览器都支持该功能(IE8+:IE8/9 需要使用 XDomainRequest 对象来支持 CORS),CORS 也已经成为主流的跨域解决方案。
前端设置:
-
原生 Ajax
// 前端设置是否携带xhr.withCredentials = true实例代码:
var xhr = new XMLHttpRequest(); // IE8/IE9 需用 window.XDomainRequest 兼容// 前端设置是否带 cookiexhr.withCredentiasls = true;xhr.open("post", "http://www.domain2.com:8080/login", true);xhr.setRequestHeader("Content-Type", "application/x-www-urlencoded");xhr.send("user=admin");xhr.onreadystatechange = function() { if(xhr.readyState === 4 && xhr.status === 200) { alert(xhr.responseText); }} -
jQuery Ajax
$.ajax({ ... xhrFields: { withCredentials: true // 前端设置是否带 cookie }, crossDomain: true // 会让请求头中包括跨域得额外信息,但不会包含 cookie}) -
axios 设置
axios.defaults.withCredentials = true; -
vue-resource 设置:
Vue.http.options.credentials = true;
服务端设置
若后端设置成功,前端浏览器控制台则不会出现跨域报错信息,反之说明没有设置成功
-
Java 后台
/** 导入包:import javax.servlet.http.HttpServletResponse;* 接口参数中定义:HttpServletResponse response*/// 运行跨域访问的域名;若有端口需写全(协议+域名+端口),若没有端口末尾不用加'/'reponse.setHeader("Access-Control-Allow--credentials", "true");// 提示 OPTIONS 预检时,后端需要设置的两个常用自定义reponse.setHeader("Access-Control-Allow-Headers", "Content-Type, X-Requested-With"); -
NodeJs 后台示例
var http = require("http");var server = http.createServer();var qs = require("querystring");server.on("request", function(req, res) { var postData = ''; // 数据块接收中 req.addListener("data", function(chunk) { postData += chunk; }) // 数据接收完毕 req.addListener("end", function() { postData += qs.parse(postData); // 跨域后台限制 res.writeHead(200, { "Access-Control-Allow-Credentials": "true", // 后端允许发送 Cookie "Access-Controls-Allow-Origin": "http://www.domain1.com", // 允许访问的域(协议+域名+端口) /* * 此处设置的 Cookie 还是 domain2 的而非 domain1,因为后端也不能跨域写 cookie(nginx 反向代理可以实现), * 但只需 domain2 中写入一次 cookie 认证,后面的跨域接口都能从 domain2 中获取 cookie,从而实现所有的接口都能跨域访问 */ "Set-Cookie": "l=a123456;Path=/;Domain=www.domain2.com;HttpOnly" // HttpOnly 的作用是让 JS 无法读取 cookie }); res.write(JSON.stringify(postData)); res.sed(); })});server.listen('8080');console.log("Server is running ar port 8080....");
Nginx 代理跨域
nginx 配置解决 iconfont 跨域
浏览器跨域访问 JS 丶CSS丶Img 等常规静态资源被同源策略许可,但 iconfont 字体文件(eot | otf | ttf | woff | svg)例外,此时可在 nginx 的静态服务器中加入以下配置。
location / { add_header Access-Control-Allow-Origin *; }
nginx 反向代理接口跨域
跨域原理:同源策略是浏览器的安全策略,不是 HTTP 协议的一部分。服务器端调用 HTTP 接口只是使用 HTTP 协议,不会执行 JS 脚本,不需要同源策略,也就不存在跨域问题。
实现思路:通过 nginx 配置一个代理服务器(域名和 domain1 相同,端口不同)做跳板机,反向代理访问 domain2 接口,并且可以顺便修改 cookie 中 domain 信息,方便当前域 cookie 写入,实现跨域登录。
# proxy 服务器server { listen 81, server www.domain1.com; location / { proxy_pass http://www.domain2:8080; # 反向代理 proxy_cookie_domain www.domain2.com www.domain1.com; # 修改 cookie 里域名 index index.html index.html; # 当用 webpack-dev-server 等中间件代理接口访问 nignx 时,此时浏览器参与,故没有同源策略限制,下面的跨域配置可不启用 add_header Access-Control-Allow-Origin http://www.domain1.com; # 当前浏览器跨域不带 cookie 时,可为 * add_header Access-Control-Allow-Credentials true; }}
前端代码示例:
var xhr = new XMLHttpRequest();// 前端开发,浏览器是否读写 cookie‘xhr.withCredentials = true;// 访问 nginx 中的代理服务器xhr.open("get", "http://www.domain1.com:81?user=admin", true);xhr.send();
NodeJs 后台示例:
var http = require("http");var server = http.createServer();var qs = require("querystring");server.on("request", function(req, res) { var params = qs.parse(req.url.substring(2)); // 向前台写 cookie res.writeHead(200, { "Set-Cookie": "l=a123456;Path=/;Domain=www.domain2.com;HttpOnly" // HttpOnly: 脚本无法读取 }) res.write(JSON.stringify(params)); res.end();});server.listen("8080");console.log("Server is running at port 8080...");
NodeJs 中间件代理跨域
node 中间件实现跨域代理,原理大致与 nginx 相同,都是通过一个代理服务器,实现数据的转发,也可以通过设置 cookieDomainRewrite 出事故修改响应头中 cookie 中域名,实现当前域的 cookie 写入,方便接口登录验证。
非 Vue 框架的跨域(2次跨域)
利用 Node + Express + http-proxy-middleleware 搭建一个 proxy 服务器
前端代码示例:
var xhr = new XMLHttpRequest();// 前端开关:浏览器是否读写 cookiexhr.withCredentials = true;// 访问 http-proxy-middleware 代理服务器xhr.open("get", "http://www.domain1.com:3000/login?user=admin", true);xhr.send();
中间件服务器:
var express = require("express");var proxy = require("http-proxy-middleware");var app = express();app.use('/', proxy({ // 地理跨域目标接口 target: "http://domain2.com:8080", changeOrigin: true, // 修改响应头信息,实现跨域并允许带 cookie onProxyRes: function(proxyRes, req, res) { res.header("Access-Control-Allow-Origin", "http://www.domain1.com"); res.header("Access-Control-Allow-Credentials", "true"); }, // 修改响应信息中的 cookie 域名 cookieDomainRewrite: "www.domain1.com" // 可以为 false,表示不修改}))app.listen(3000);console.log('Proxy server is listen at port 3000...');
Nodejs 后台同(六:Nginx)
Vue 框架的跨域(1次跨域)
利用 node + webpack + webpack-dev-server 代理接口跨域。在开发环境下,由于 Vue 渲染服务和接口代理服务都是 webpack-dev-serve 同一个,所以页面与代理接口之间不再跨域,无须设置 headers 跨域信息了。
webpack.congfig.js 部分配置:、
module.exports = { entry: {}, module: {}, ... devServer: { historyApiFallback: true, proxy: [{ content: "/login", target: "http://www.domain2.com:8080", // 代理跨域目标接口 changeOrigin: true, secure: false, // 当代理某些 http 服务报错时用 cookieDomainRewrite: "www.domain1.com" // 可以为 false,表示不修改 }], noInfo: true }}
WebSocket 协议跨域
WebnSocket protocol 是 HTML5 一种新的协议,它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是 server push 技术的一种很好的实现。
原生 WebSocket API 使用起来不方便,我们使用 Socket.io,它很好地封装了 webSocket 接口,提供了更简单丶灵活的接口,也对不支持 webSocket 的浏览器提供了向下兼容。
前端代码:
<div>user input: <input type="text"></div><script src="https://cdn.bootcss.com/socket.io/2.2.0/socket.io.js"></script><script> var socket = io("http://www.domain2.com:8080"); // 连接成功处理 socket.on("connect", funtion() { // 监听服务端消息 socket.on("message", function(msg) { console.log("data from server:---> " + msg); }) // 监听服务端关闭 socket.on("disconnect", function() { console.log("Server socket has closed"); }) }) document.getElementsByTagName("input")[0].onblur = function() { socket.send(this.value); }</script>
Nodejs socket 后台:
var socket = require("socket.io");// 启用 http 服务var server = http.createServer(function(req, res) { res.writeHead(200, { res.writeEnd(200, { "Content-type": "text/html" }); res.end(); }) server.listen("8080"); console.log("Server is running at port 8080...");})// 监听 socket 连接socket.listen(server).on("connection", function(client) { // 接收信息 client.send("message", function(msg) { client.send("hello: " + msg); console.log("data from client: ---> " + msg); }) // 断开处理 client.on("disconnect", function() { console.log("Client socket has closed"); })})
22. 前端 SEO
搜索引擎工作原理
在搜索引擎网站的后台会有一个庞大的数据库,里面存储了海量的关键词,而每个关键词又对应着很多网址,这些网址是被称之为“搜索引擎蜘蛛”或“网络爬虫”程序从茫茫的互联网上一点一点下载收集而来的。随着各种各样网站的出现,这些勤劳的“蜘蛛”每天在互联网上爬行,从一个链接到另一个链接,下载其中的内容,进行分析提炼丶知道其中的关键词,如果“蜘蛛”认为是垃圾信息或重复信息,就舍弃不要,继续爬行,寻找最新丶有用的信息保存起来提供用户搜索。当用户搜索时,就能检索出与关键字相关的网址显示给访客。
一个关键字对应多个网址,因此就出现了排序的问题,相应的当与关键字最吻合的网址就会排在前面了。在“蜘蛛”抓取网页内容,提炼关键字的这个过程中,就存在一个问题:“蜘蛛”能否看懂。如果网站内容是 flash 和 JS 等,那么它是看不懂的,会犯迷糊,即使关键字再贴切也没用。相应的,如果网站内容可以被搜索引擎能识别,那么搜索引擎就会提高该网站的权重,增加对该网站的友好度。这个过程我们称之为 SEO。
SEO 简介
SEO(Search Engine Optimization),即搜索引擎优化。SEO 是随着搜索引擎的出现而来的,两者是相互促进丶相互共生的关系。SEO 的存在就是为了提升网页在搜索引擎结果中的收录数量以及排序位置而做的优化行为。而优化的目的就是为了提升网站在搜索引擎中的权重,增加对搜索引擎的友好度,使得用户在访问网站时能排在前面。
分类:白帽 SEO 和 黑帽 SEO,起到了改良和规范网站设计的作用,使网站对搜索引擎和用户更加友好,并且网站也能从搜索引擎中获取合理的流量,这是搜索鼓励和支持的。黑帽 SEO 利用和放大搜索引擎政策缺陷来获取更多用户的访问量,这类行为大多是欺骗搜索引擎,一般搜索引擎公司是不支持和鼓励的。本文针对白帽 SEO,那么白帽 SEO 能做什么呢?
- 对网站的标题丶关键字丶描述精心设置,反映网站的定位,让搜索引擎明白网站是做什么的
- 网站内容优化:内容于关键字的对应,增加关键字的密度
- 在网站上合理设置 Robots.txt 文件
- 生成针对搜索引擎友好的网站地图
- 增加外部链接,到各个网站上宣传
为什么做 SEO?
提高网站的权重,增强搜索引擎友好度,以达到提高排名,增加流量,改善(潜在)用户体验,促进销售的作用。
前端 SEO 规范
前端是构建网站中很重要的一个环节,前端的工作主要是负责页面的 HTML + CSS + JS,优化好这几个方面会为 SEO 打好一个坚实的基础。通过网站的结构布局设计和网页代码优化,使前端页面既让浏览器用户能够看懂(提升用户体验),也能让“蜘蛛”看懂(提高搜索引擎友好度)。
前端 SEO 注意事项:
网站结构布局优化:尽量简单丶开门见山丶提倡扁平化结构
一般而言,建立的网站结构层次越少,越容易被“蜘蛛”抓取,也就容易被收录。一般中小型网站目录结构超过三级,“蜘蛛”便不愿意往下爬了。并且根据相关数据调查:如果访客经过 3 次还没有知道需要的信息,很可能离开。因此,三层目录结构也是体验的需要,为此我们需要做到:
-
控制首页链接数量
网站首页是权重最高的地方,如果首页链接太少,没有“桥”,“蜘蛛”不能继续往下爬到网页,直接影响网站收录数量。但是首页链接也不能太多,一旦太多,没有实质性的链接,也容易影响用户体验,也会降低网站网页的权重,收录效果也不好。
-
扁平化的目录层次
尽量让“蜘蛛”只要跳转 3 次,就能到达网站内的任何一个地方
-
导航优化
导航应该尽量采用文字方式,也可以搭配图片导航,但是图片代码一定要进行优化,标签必须添加“alt” 和 “title” 属性,告诉搜索引擎导航的定位,做到即使图片未能正常显示时,用户也能看到提示文字。
其实,在每一个网页上应该加上面包屑导航,好处是:从用户体验方面来说,可以让用户了解当前所处的位置以及当前网页在整个网站中的位置,帮助用户很快了解网站组织方式,从而形成更好的位置感,同时提供了返回各个页面的接口,方便用户操作;对“蜘蛛”而言,能够清楚的了解网站结构,同时增加了大量的内部链接,方便抓取,降低跳出率。
-
网站的结构布局 – 不可忽略的细节
页面头部: logo 及 主导航,以及用户的信息。
页面主体:左边正文,包括面包屑导航及正文;右边放热门文章及相关文章,好处:留住访客,让访客多停留,对”蜘蛛“而言,这些文章属于相关链接,增强了页面相关性,也能增强页面的权重。
页面底部:版本信息和友情链接。
特别注意:分页导航写法,推荐写法:“首页 1 2 3 4 5 6 7 8 9 下拉框”,这样"蜘蛛"能够根据相应页码直接跳转,下拉狂直接选择页面跳转。而下面的写法是不推荐,”首页 下一页 尾页“,特别是分页数量较多时,”蜘蛛“需要经过很多次往下爬,才能抓取,会很累丶会容易放弃。
-
利用布局,把重要内容 HTML 代码放在最前
搜索引擎抓取 HTML 内容是从上到下,利用这一特点,可以让主要代码优先读取广告等不重要代码放在下边。例如,在左栏和右栏的代码不变的情况下,只需改一下样式,利用 float: left 和 float: right 就可以随意让两栏在展现上位置互换,这样就可以保证重要代码在最前,让爬虫最先抓取。同样适用于多栏的情况。
-
控制页面的大小,减少 HTTP 请求,提高网站的加载速度
一个页面最好不要超过 100 K,太大页面加载速度慢。当速度很慢时,用户体验不好,留不住访客,并且一旦超时,”蜘蛛“也会离开。
网页代码优化
-
突出重要内容 – 合理的设计 title丶description 和 keywords
标题:只强调重点即可,尽量把重要的关键词放在前面,关键词不要重复出现,尽量做到每个页面的
标题中不要设置相同的内容。标签:关键词,列举出几个页面的重要关键字即可,切记过分堆砌。 标签:网页描述,需要高度概括网页内容,切记不能太长,过分堆砌关键词,每个页面也要有所不同。
-
语义化书写 HTML 代码,符合 W3C 标准
尽量让代码语义化,在适当的位置使用适当的标签,用正确的标签做正确的事。让阅读源码者和”蜘蛛“一目了然。比如 h1~h6是用于标题类的。
标签是用来设置页面主导航,列表形式的代码使用 ul 或 ol,重要的文字使用 strong 等。
-
标签:页面链接,要加”title“属性加以说明,让访客和”蜘蛛”知道。而外部链接,链接到其它网站的,则需要加上“el=nofollow”属性,告诉“蜘蛛”不要爬,因为一旦“蜘蛛”爬了外部链接之外,就不会再回来了
<a href="https://www.360.cn" title="360安全中心" class="logo"></a> -
正文标题要用 h 标签
h1 标签自带权重“蜘蛛”认为它最重要,一个页面有且最多只能有一个 H1 标签,放在该页面最重要的标题上面,如首页的 logo 上可以加 H1 标签。副标题用标签,而其它地方不应该随便乱用 h 标题标签。
-
应使用“alt”属性加以说明
<img src="cat.jpg" width="300" height="200" alt="猫" />当网络速度很慢,或者图片地址失效的时候,就可以体现出 alt 属性的作用,它可以让用户在图片没有显示的时候知道这个图片的作用。同时为图片设置高度和宽度,可提高页面的加载速度。
-
表格应该使用表格标题标签
caption 元素定义表格标题,caption 标签必须紧随 table 标签之后,你只能对每个表格定义一下
<table border='1'> <caption>表格标题</caption> <tbody> <tr> <td>apple</td> <td>100</td> </tr> <tr> <td>banana</td> <td>200</td> </tr> </tbody></table> -
br标签:只用于文本内容的换行,比如:
<p> 第一行文字内容<br/> 第二行文字内容<br/> 第三行文字内容</p> -
重要的内容不要用 JS 输出,因为“蜘蛛”不会读取 JS 里的内容,所以只要内容必须放在 HTML 里
-
尽量少使用 iframe 框架,因为“蜘蛛”一般不会读取其中的内容
-
谨慎使用 display: none
对于不想显示的文字内容,应当设置 z-index 或缩进设置成足够大的负数偏离出浏览器之外。因为搜索引擎会过滤掉 display: none 其中的内容
前端网站性能优化
-
减少 HTTP 请求数量
在浏览器于服务器进行通信时,主要是通过 HTTP 进行通信。浏览器和服务器需要经过三次握手,每次握手需要花费大量时间。而且不同浏览器对资源文件并发请求数量有限(不同浏览器允许并发数),一旦 HTTP 请求数量达到一定数量,资源请求就存在等待状态,这是致命的,因此减少 HTTP 的请求数量可以很大程度对网站性能进行优化
-
CSS Sprites
国内俗称 CSS 精灵,这是将多张图片合并成一张图片达到减少 HTTP 请求的一种解决方案,可以通过 CSS 的 background 属性来访问图片内容,这种方案同时还可以减少图片总字节数。
-
合并 CSS 和 JS 文件
现在前端有很多前端工程化打包工具,如:grunt丶gulp丶webpack 等。为了减少 HTTP 请求数量,可以通过这些工具再发布将多个 CSS 或者多个 JS 合并成一个文件。
-
采用 lazyload
俗称懒加载,可以控制网页上的内容在一开始无需加载,不需要发请求,等到用户操作真正需要的时候立即加载出内容。这样就控制了网页资源一次性请求数量。
-
控制资源文件加载优先级
浏览器在加载 HTML 内容时,是将 HTML 内容从上至下解析,解析到 link 或者 script 标签就会加载 href 或者 src 对应链接内容,为了第一时间展示页面给用户,就需要将 CSS 提前加载,不要受 JS 加载影响。、
一般情况下 CSS 在投头部,JS 在底部
-
尽量外链 CSS 和 JS(结构丶表现和行为的分离),保证网页代码的整洁,也有利于日后维护
<link rel="stylesheet" href="asstes/css/style.css" /><script src="assets/js/main.js"></script> -
利用浏览器缓存
浏览器缓存是将网站资源存储到本地,等待下次请求该资源时,如果资源已经存在就不需要到服务器重新请求该资源,直接在本地读取该资源。
-
减少重排(Reflow)
基本原理:重排是 DOM 的变化影响到了元素的几何属性(宽和高),浏览器会重新计算元素的几何属性,会使渲染树受到影响的部分失效,浏览器会验证 DOM 树上的所有其它结点的 visibility 属性,这也是 reflow 低效的原因。如果 reflow 的过于频繁,CPU 使用率就会急剧上升。
减少重排,如果需要在 DOM 操作时添加样式,尽量使用增加 class 属性,而不是通过 style 操作样式。
-
减少 DOM 操作
-
图标使用 IconFont 替换
-
不使用 CSS 表达式,会影响效率
-
使用 CDN 网络缓存,加快用户访问速度,减轻服务器压力
-
启用 GZIP 压缩,浏览器速度加快,搜索引擎的蜘蛛抓取信息量也会增大
-
伪静态设置
如果是动态网页,如果开启伪静态功能,让蜘蛛“误以为”这是静态网页,以为静态网页比较适合蜘蛛的胃口,如果 url 中带有关键字更好。
23. Service Worker有哪些作用
什么是 Service Worker ?
Servcie Worker 是一项比较新的 Web 技术,是 Chromium 团队在吸收了 ChromePackaged App 的 Eevent Page 机制,同时吸取了 HTML5 AppCache 标准失败的教训之后,推出一套新的 W3C 规范,旨在提高 WebApp 的离线缓存能力,缩小 WebApp 与 NativeApp 之间差距。
Service Worker 从英文翻译过来就是服务工人,服务于前端页面的后台线程,基于 Web Worker 实现。有着独立的 JS 允许环境,分担丶协助前端页面完成前端开发者分配的需要在后台悄悄执行的任务。基于它可以实现拦截和处理网络请求丶消息推送丶精默更新丶事件同步等服务。
一个简单的示例:
// index.html<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> <script> function register() { navigator.serviceWorker .register("serviceworker.js") .then(function(serviceWorker) {}) } </script></head><body οnlοad="register()"> <h1>serviceWorker Test!</h1> <image src=""></image> </body></html>
// serviceworker.jsconst OFFLINE_CACHE = 'V1';this.addEventListener("install", function (event) { event.waitUntil( caches.open(OFFLINE_CACHE).then(function (cache) { return cache.addAll([ '/sw/sw/index.html', '/sw/sw/showTroopers.jpg' ]) }) )})this.addEventListener("activate", function (event) { })this.addEventListener("fetch", function (event) { event.respndWith( cache.open(OFFLINE_CACHE).then(function (cache) { return cache.match(event.request.url); }) )})
该实例展示了 Service Worker 最基本的离线缓存应用,前端是原来的 web 应用中使用 Service Worker 只需三大步
- 切入到 HTTPS;由于 Service Worker 可以劫持连接,伪造和过滤响应,所以保证其在传输过程中不被篡改非常重要
- 在页面加载的恰当时机注册 Service Worker;示例中在 index 页面的 body onload 事件中注册了同 path 下的 serviceworker.js 作为 index 页面的线程服务
- 编写 serviceworker 脚本逻辑;serviceworker 是事件驱动型服务线程,所以 serviceworker 脚本逻辑中基本都是以事件监听作为逻辑入口,示例中在 serviceworker 脚本被安装的 install 事件中缓存 index 域名主资源及子资源,在 fetch 事件中,拦截前端页面发起的资源请求并到之前缓存的 cache 中匹配
该实例部署到服务器上,用户第一次打开 index 页面,仍然会从服务器上拉取,之后便去安装 Service Worker,执行 Servcie Worker 中 install 事件,浏览器会再次拉取需要缓存的资源,这一次的缓存是否从网络拉取取决于资源设置的过期时间。当 install 事件中的资源均拉取成功,Service Worker 算是安装成功。如果有一个资源拉取失败,此次 Service Worker 安装失败,若用户下次再打开该页面,浏览器仍然会重复之前的安装流程尝试安装。
24. 位运算符在 JS 中的妙用
-
所有 JavaScript 数字存储为根为 10 的 64(8 比特)浮点数。JavaScript 不是类型语言。与许多其它编程语言不同,JavaScript 不定义不同类型的数字,比如 整数丶短丶长丶丶浮点等等
-
整数精度(不使用小数点或指数计数法)最多为 15 位。小数精度的最大位数是 17,但是浮点运算并不总是 100% 准确
-
位运算直接对二进制位进行计算,位运算直接处理每一个比特位,是非常底层的运算,好处是速度极快,缺点是很不直观,很多场景不能够使用
-
位运算只对整数起作用,如果一个位运算以 64 位浮点数的形式存储,但是做位运算的时候,是以 32 位带符号的整数进行运算的,并且返回值也是一个 32 位带符号的整数
JS 中常用的 7 个位运算符
1. 按位与(AND)
& 以特定的方式组合操作二进制数中对应的位,如果对应的位都为 1,那么结果就是 1,如果任意一个位是 0,则结果就是0
// 1的二进制表示为: 00000000 00000000 00000000 00000001
// 3的二进制表示为: 00000000 00000000 00000000 00000011
// -----------------------------
// 1的二进制表示为: 00000000 00000000 00000000 00000001
console.log(1 & 3) // 1
2. 按位或(OR)
| 运算符跟 & 的区别在于如果对应的位中任一个操作数为 1,那么结果就是 1
// 1的二进制表示为: 00000000 00000000 00000000 00000001
// 3的二进制表示为: 00000000 00000000 00000000 00000011
// -----------------------------
// 3的二进制表示为: 00000000 00000000 00000000 00000011
console.log(1 | 3) // 3
3. 按位异或(XOR)
^ 如果对应两个操作位有且有一个 1 时结果为 1,其它都是 0
// 1的二进制表示为: 00000000 00000000 00000000 00000001
// 3的二进制表示为: 00000000 00000000 00000000 00000011
// -----------------------------
// 3的二进制表示为: 00000000 00000000 00000000 00000011
console.log(1 | 3) // 3
-
4. 按位非(NOT)
- 运算符是对位求反,1 变 0,0 变 1,也就是求二进制的反码
// 1的二进制表示为: 00000000 00000000 00000000 00000001
// 3的二进制表示为: 00000000 00000000 00000000 00000011
// -----------------------------
// 1反码二进制表示: 11111111 11111111 11111111 11111110
// 由于第一位(符号位)是1,所以这个数是一个负数。JavaScript 内部采用补码形式表示负数,即需要将这个数减去1,再取一次反,然后加上负号,才能得到这个负数对应的10进制值。
// -----------------------------
// 1的反码减1: 11111111 11111111 11111111 11111101
// 反码取反: 00000000 00000000 00000000 00000010
// 表示为10进制加负号:-2
console.log(~ 1) // -2
简单记忆:一个数与自身的取反值相加等于 -1
5. 左移(Left shift)
<< 该操作符会将指定操作数的二进制向右移动指定的位数,则移动规则;舍丢高位,低位补 0 即按二进制形式把所有的数字向左移动对应的位数,高位移出(舍弃),低位的空位补零
// 1的二进制表示为: 00000000 00000000 00000000 00000001
// -----------------------------
// 2的二进制表示为: 00000000 00000000 00000000 00000010
console.log(1 << 1) // 2
有符号右移 >>
>> 该操作符会将指定操作数的二进制位向右指定的位数。向右被移出的位被丢弃,拷贝最左侧的位以填充左侧。由于新的最左侧的位总是和以前相同,符号位没有被改变。所以被称作“符号传播”
// 1的二进制表示为: 00000000 00000000 00000000 00000001
// -----------------------------
// 0的二进制表示为: 00000000 00000000 00000000 00000000
console.log(1 >> 1) // 0
25. PWA技术
随着互联网技术的发展,web 应用已经越来越流行,技术的发展越来越迅速,尤其是互联网的到来使得 HTML5 技术,Hybrid 混合发展,更加火爆起来,但是 web 应用没能摆脱 PC 时代的一些根本性的问题,所需的资源依赖网络下载,用户体验始终要依赖浏览器,这让 web 应用和 Native 应用相比于尤其在移动手机端的体验,总让人感觉 不正规,而 PWA 技术的到来,让下一代 web 应用终于步入正轨
基于此,本文主要内容有以下几部分内容:
- PWA 基本概念讲解
- Service Worker 原理讲解
- Web Push 协议讲解
- 将一个 SPA 项目改造为 PWA
- mainfest.json 配置解析
- Service Worker 资源缓存
- 添加保存到桌面
- 接收消息推送
- 总结
什么是 PWA?
PWA(progressing web app),渐进式网页应用程序,是 Google 在 2016 年 Google/O 大会上提出的下一代 web 应用模型,并在随后的日子里迅速发展。一个 PWA 应用首先是一个网页,可以通过 Web 技术编写出一个网页应用,随后借助于 App Mainfest 和 Service Worker 来实现 PWA 的安装和离线等功能
PWA 的特点
- **渐进式:**适用于选用任何浏览器的所有用户,因为它是以渐进式增强作为核心宗旨来开发的
- **自适应:**适合任何机型:桌面设备丶移动设备丶平板电脑或任何未来设备
- **连接无关性:**能够借助于服务工作线程在离线或低质量网络状况下工作
- **离线推送:**使用推送消息通知,能够让我们的应用像 Native App 一样,提升用户体验
- **及时更新:**在服务工作线程更新进程的作用下时刻保持最新状态
- **安全性:**通过 HTTPS 提供,以防止窥探和确保内容不被篡改
对于我们移动端来讲,用简单的一句话来概括一个 PWA 应用就是,我们开发的 H5 页面增加可以添加到屏幕的功能,点击主屏幕图标可以实现启动动画以及隐藏地址栏实现离线缓存功能,即使用户手机没有网络,依然可以使用一些离线功能。这些特点和功能不正是我们目前针对移动 web 的优化方向,有了这些特性将使得 Web 应用渐进式接近原生 App,真正实现秒开优化
Service Worker 是什么?
Servcie Worker 是一个基于 HTML5 API,也是 PWA 技术栈中最重要的特性,它在 Web Worker 的基础上加上了持久离线缓存和网络代理能力,结合 Cache API 面向提供了 JavaScript 来操作浏览器缓存的能力,这使得 Service Worker 和 PWA 密不可分
Servcie Worker 概述
- 一个独立的线程,单独的作用域范围,单独的运行环境,有自己独立的 context 上下文
- 一旦被 Install,就永远存在,除非被手动 unregister。即使 Chrome(浏览器)关闭也会在后台运行。利用这个特性可以实现离线消息推送功能
- 处于安全性考虑,必须在 HTTPS 环境下才能工作。当然在本地调试时,使用 localhost 则不受 HTTPS 限制
- 提供拦截浏览器请求的接口,可以控制打开的作用域范围下所有的页面请求。需要注意的是一旦请求被 Service Worker 接管,意味着任何请求都由你来控制,一定要做好容错机制,保证页面的正常运行
- 由于是独立线程,Service Worker 不能直接操作页面 DOM。但可以通过事件机制来处理。例如使用 postMessageS
Service Worker 生命周期
- **注册(register):**这里一般指在浏览器解析到 JavaScript 有注册 Service Worker 时的逻辑,即调用 navigator.serviceWorker.register() 时所处理的事情
- **安装中(installing):**这个状态发生在 Service Worker 注册之后,表示开始安装
- **安装后(intstalled/waiting):**Service Worker 已经完成了安装,这时会触发 install 事件,在这里一般会做一些静态资源的离线缓存。如果还有旧的 Service Worker 正在运行,会进入 waiting 状态,如果你关闭浏览器,或者调用 self.skipWaiting() 方法表示强制处于 waiting 状态的 Service Worker 进入 activate 状态
- **激活(activating):**表示正在进入 activate 状态,调用 self.clients.claim() 会来强制控制未受控制的客户端,例如你的浏览器开了多个含有 Service Worker 的窗口,会在不切的情况下,替换旧的 Service Worker 脚本不再控制着这些页面,之后会被停止。此时会触发 activate 事件
- **激活后(activated):**在这个状态表示 Service Worker 激活成功,在 activate 事件回调中,一般会清除上一个版本的静态资源缓存,或者其它更新缓存的策略,这代表着 Servcie Worker 已经可以处理功能性的事件 fetch(请求)丶aync(后台同步)push(推送)丶message(操作 dom)
- **废弃状态(redundant):**这个状态表示一个 Service Worker 的生命周期结束
整个流程可以用下图解释:
Service Worker 支持的事件:

Service Worker 浏览器兼容性:
Service Worker 作为一个新的技术,那么就必然会有浏览器兼容性问题。从图上可以看到对于大部分的 Android 来说支持性还是很不错的,尤其是 Chrome for Android,但是对于 IOS 系统而言 11.3 之前不支持 Service Worker 的,这可能也是 Service Worker 没能普及开来的一个原因,但是好消息是苹果宣布后续会持续更新对 Service Worker 的支持,那么前景还是值得期待的
消息推送
消息推送,顾名思义就是你在手机上收到的某个 APP 的消息推送,相较于移动端 Native 应用,web 应用是缺少这一项常用的功能。而借助 PWA 的 Push 特性,就是用户在打开浏览器时,不需要进入特定的网站,就能收到该网站推送而来的消息,例如:新评论,新特性等等,而借助于 Android 的 Chrome,我们可以实现在用户不打开任何浏览器应用的情况下,收到我们项目的推送,就像一个真实的手机推送
什么是 Web Push
Web Push 是一个基于客户端,服务端和推送服务器三者组成的一种流程规范,可以分为三个步骤:
- 客户端完成请求订阅一个用户的逻辑
- 服务端调用遵从 web push 协议的接口,传送消息推送(push message)到推送服务器(该服务器由浏览器决定,开发者所能做的只有控制发送的数据)
- 推送服务器将该消息推送至对应的浏览器,用户收到该推送
下图展示了一个用户订阅的过程:

所谓用户订阅,就是说我想要收到你的网站或者你的 APP 的推送通知,我就需要告诉你是谁,我要把我的标识传给你,否则你怎么知道要给我推送
下图展示了服务端收到用户订阅请求后如何推送:
- 首先,在你的项目的后台(Your Server)要存储一下用户订阅时传给你的标识
- 在后台需要给你推送的时候,找到这个标识,然后联系推送服务器(Push Service)将内容和标识传给推送服务,然后让推送服务将消息推送给用户端(IOS 和 Android 各自由自己的推送服务器,这个和操作系统相关)
- 这里就有一个约定,用户的标识,就和推送服务达成一致,例如使用 Chrome 浏览器,那么推送服务就是谷歌的推送服务(FCM)
开始改造现有的 SPA 应用
添加 mainfest.json 配置页面参数
添加到桌面快捷功能本省是 PWA 应用的一部分,它让我们的应用看起来更像是一个 Web App,我们在前端项目的 public 文件夹下新建 mainfest.json 文件:
{
"name": "WECIRCLE",
"short_name": "WECIRCLE",
"icons": [
{
"src": "./img/icons/android-chrome-192x192.png",
"sizes": "192x192",
"type": "image/png"
},
{
"src": "./img/icons/android-chrome-512x512.png",
"sizes": "512x512",
"type": "image/png"
}
],
"start_url": "./index.html",
"display": "standalone",
"background_color": "#000000",
"theme_color": "#181818"
}
其中:
-
name:指定Web App 的名称,也就是保存在桌面图标的名称
-
short_name:当 name 名称过长时,将会使用 short_name 来代替 name 显示,也就是 Web App 的简称
-
short_url:指定了用户打开该 Web App 时加载的URL。相对于 URL 会相对于 mainfest.json。这里我们指定了 index.html 作为 Web App 的启动页
-
display:指定了应用的显示模式,它有四个值可以选择:
- fullscreen:全屏展示,会尽可能将所有的显示区域都占满
- standalone:浏览器相关 UI(如导航栏丶工具栏等)将会被隐藏,因此看起来更像一个 Native App
- minimal-ui:显示形式与 standalone 类似,浏览器相关 UI 最小化为一个按钮,不同浏览器在实现上略有不同
- broswer:一般来说,会和正常使用浏览器打开样式一致。这里需要说明一下的是一些系统的浏览器不支持 fullscreen 时将会显示成 standalone 的效果,当不支持 standalone 属性时,将会希纳是成 minimal-ui 的效果,以此类推
-
icons:指定了应用的桌面图标和启动页图像,用数组表示:
- sizes:图标的大小。通过指定大小,系统会选取最适合的图标展示在相应位置上
- src:图标的文件路径。相对路径是相对于 mainfest.json 文件,也可以使用绝对路径例如 xxx.png
- type:图标的图片类型。浏览器会从 icons 中选择最接近 128dp(px = dp * (dpi / 160)) 的图片作为启动画面图像
-
background_color:指定了启动画面的背景颜色,采用相同的颜色可以实现从启动画面到首页的平稳过渡,也可以用来改善页面资源正在加载时的用户体验,结合 icons 属性,可以定义背景颜色 + 图片 icon 的启动页效果,类似于 Native App 的 spalash screen 效果
-
theme_color:指定了 Web App 的主题颜色。可以通过该属性来控制浏览器 UI 的颜色。例如状态栏丶内容页中状态栏丶地址栏的颜色
配置 IOS 系统的页面参数:
理想很丰满,现实却很骨感,mainfest.json 那么强大但是也逃不过浏览器兼容性问题,正如下图 mainfest.json 的兼容性:
由于 IOS 系统对 mainfest.json 是属于部分支持,所以我们需要在 head 里给配置而外的 meta 属性才能让 IOS 系统更加完善:
<meta name="apple-mobile-web-app-capable" content="yes">
<meta name="apple-mobile-web-app-title" content="WECIRCLE">
<link rel="apple-touch-icon" sizes="76x76" href="./img/icons/apple-touch-icon-76x76-1.png" />
<link rel="apple-touch-icon" sizes="152x152" href="./img/icons/apple-touch-icon-152x152.png-1" />
<link rel="apple-touch-icon" sizes="180x180" href="./img/icons/apple-touch-icon-180x180.png-1" />
- apple-touch-icon:指定了应用的图标,类似于 mainfest.json 文件的 icons 配置,也是支持 sizes 属性,来供不同场景的选择
- apple-mobile-web-app-capable:类似于 mainfest.json 中的 display 的功能,通过设置为 yes 可以进入 standalone 模式,目前来说 IOS 系统还支持这个模式
- apple-mobile-web-app-title:指定了应用的名称
- apple-mobile-web-app-status-bar-style:指定了 IOS 移动设备的状态栏(status bar)的样式,有 Default丶Black丶Black-translucent 可以设置
采用 IOS12.0 测试下来看,apple-touch-icon丶apple-mobile-web-app-status-bar-style 是真实生效的,而 mainfast.json 的 icons 则不会被 IOS 系统识别,下面是 IOS 系统 safari 保存到桌面操作的截图
在 Android 的 Chrome 中:
最后,别忘了将 mainfest.json 文件在 html 中进行引入
<link rel="manifest" href="manifest.json">
注册和属于 Service Worker 的缓存功能
1. 要将 Service Worker 进行注册
在前端项目 public 文件夹下的 index.html 中添加如下代码:
if('serviceWorker' in navigator) {
window.addWEventListener('load', function() {
navigator.servicelistener.register('/sw-my.js', {scope: '/'})
.then(function(registration) {
// 注册成功
console.log('ServiceWorker registration successful with scope:', registration.scope);
})
.catch(function(err) {
// 注册失败
console.log('ServiceWorker registration failed:', err);
})
})
})
}
采用 servcieWorkerContainer.register() 来注册 Service Worker,这里要做好容错判断,保证某些机型在不支持 Service Worker 的情况下可以正常运行,而不会报错
例外需要注意的是只有在 https 下,navigator 里才会有 serviceWorker 这个对象
2. 在前端项目 public 文件夹下新建 sw-my.js,并定义需要缓存的文件路径
// 定义需要缓存的文件
var cacheFiles = [
'./lib/weui/weui.min.js',
'./lib/slider/slider.js',
'./lib/weui/weui.mini.css'
];
// 定义缓存的 key 值
var cacheName = '20190301';
3. 监听 install 事件,来进行相关文件的缓存操作:
// 监听 install 事件,安装完成后,进行文件缓存
self.addEventListener("install", function(e) {
console.log('Service Worker 状态:install');
// 找到 key 对应的缓存并且获得可以操作的 cache 对象
var cacheOpenPromise = caches.open(cacheName).then(function (cache) {
// 将需要缓存的文件加进来
return cache.addAll(cacheFiles);
})
// 将 promise 对象传给 event
e.waitUntil(cacheOpenPromise);
})
我们在 sw-my.js 里面采用的标准的 web worker 的编程方式,由于运行在另一个全局上下文中(self),这个全局上下文不同于 window,所以我们采用 self.addEventListener()
Cache API 是由 Service Worker 提供用来操作缓存的接口,这些接口基于 Promise 来实现,包括了 Cache 和 Cache Storage,Cache 直接和请求打交道,为缓存的 Request/Response 对象对提供存储机制,CacheStorage 表示 Cache 对象的存储实例,我们可以直接使用全局的 caches 属性访问 Cache API

Cache 相关的 API 说明:
Cache.match(request, options); // 返回一个 Promise 对象,resolve 的结果是跟 Cache 对象匹配的第一个已经缓存的请求
Cache.matchAll(request, options); // 返回一个 Promise 对象,resolve 的结果是跟 Cache 对象匹配的所有请求组成的数组
Cache.addAll(requests); // 接收一个 URL 数组,检索并把返回的 response 对象添加到给定的 Cache 对象
Cache.delete(request, options); // 搜索 key 值为 request 的 Cache 条目。如果找到,则删除该 Cache 条目,并且返回一个 resolve 为 true 的 Promise 对象;如果未找到,则返回一个 resolve 为 false 的 Promise 对象
Cache.keys(request, options); // 返回一个 Promise 对象,resolve 的结果是 Cache 对象 key 值组成的数组
4. 监听 fetch 事件来使用缓存数据
self.addEevntListener('fetch', function(e) {
console.log('现在正在请求:' + e.request.url);
e.respondWith(
// 判断当前请求是否需要缓存
caches.match(e.request).then(function(cache) {
// 有缓存就用缓存,没有就从新请求获取
return cache || fetch(e.request);
}).catch(function (err) {
console.log(err);
// 缓存报错还直接从新发请求获取
return fetch(e.request);
})
)
})
上一步我们将相关的资源进行了缓存,那么接下啦就要使用这些缓存,这里同样要做好容错逻辑,记住一旦请求被 Service Worker 接管,浏览器的默认请求就不再生效了,意思是请求的发与不发,出错与否全部由自己的代码控制,这里一定要做好兼容,当缓存失效或者发生内部错误时,及时调用 fecth 重新发起请求。正如上面提到的 Service Worker 的生命周期,fetch 事件的触发,必须依赖于 Service Worker 进入 activated 状态,于是到了第五步
5. 监听 activate 事件来更新缓存数据
使用缓存一个必不可少的步骤就是更新缓存,如果缓存无法更新,那么将毫无意义。我们在 sw-my.js 中添加如下代码:
// 监听 activate 事件,激活后通过 cache 的 key 来判断是否更新 cache 中的静态资源
self.addEventListener('activate', function(e) {
console.log('Service Worker 状态:', activate);
var cachePromsie = cache.keys().then(function(keys) {
// 遍历当前 scope 使用的 key 值
return Promise.all(keys.map(function(key) {
// 如果新获取到的 key 和之前缓存的 key 不一致,就删除之前版本的缓存
if(key != cacheName) {
return cache.delete(key);
}
})
})
e.waitUntil(cachePromise);
// 保证第一次加载 fetch 触发
return self.clients.claim();
})
- 每当已安装的 Service Worker 页面被打开时,便会触发 Service Worker 脚本更新
- 当上次脚本更新写入 Service Worker 数据库的时间戳与本次更新超过 24 小时,便会触发 Service Worker 脚本更新
- 当 sw-my.js 文件改变时,便会触发 Service Worker 脚本更新
更新流程与安装类似,只是在更新安装成功后不会立即进入 active 状态,更新后的 Service Worker 会和原始的 Service Worker 共同存在,并运行它的 install,一旦新的 Service Worker 安装成功,它会进入 wait 状态,需要等待版本的 Service Worker 进/线程终止。self.skipWaiting() 可以阻止等待,让新的 Service Worker 安装成功后立即激活。self.clients.claim() 方法让没被控制的 clients 受控,也就是设置本省为 activate 的 Service Worker
打开 Chrome 控制台,点击 Application,查看 Service Worker 的状态:
- status 表示当前 Service Worker 的状态
- clients 表示当前几个窗口连接这个 Service Worker
这里需要说明的是,如果你的浏览器开了多个窗口,那么如果在不调用 self.skipWaiting() 的情况下,必须将窗口关闭再打开才能使 Service Worker 更新成功
采用 offline-plugin 插件完善 Service Worker
上面我们写的 Service Worker 逻辑虽然已经完成,但是还有一些不完善的地方,比如我们每次构建完之后,每个文件的 MD5 都会改变,所以我们在每次写缓存文件列表时,都需要手动的修改:
var cacheFiles = [
'./static/js/vendor.d70d8829.js'
'./static/js/app.d70d8869.js'
]
这带来一定的复杂性,那么接下来就利用 webpack 的 office-plugin 插件来帮助我们完善这些事情,自动生成 sw-my.js
1. 安装 offline-plugin 插件
npm install offline-plugin --save
2. 在 vue.config.js 里配置
configureWebpack: {
plugins: [
new OfflinePlugin({
// 要求触发 ServiceWorker 事件回调
ServiceWorker: {
events: true
},
// 更新策略选择全部更新
updateStrategy: 'all',
// 除去一些不需要缓存的文件
excludes: ['**/.**', '**/*.map', '**/*.gz', '**/*.png', '**/*.jpg'],
// 添加 index.html 的更新
rewrites (assets) {
if(asset.idnexOf('index.html') > -1) {
return './index.html';
}
return asset;
}
})
]
}
3. 在前端项目 src 目录新建 registerServiceWorker.js 里面对 Service Worker 进行注册:
import * as OfflinePluginRuntime from 'offline-plugin/runtime';
OfflinePluginRuntime.install({
onUpdateReady: () => {
// 更新完成之后,调用 applyUpdate 即 skipwaiting() 方法
OfflinePluginRuntime.applyUpdate();
},
onUpdated: () => {
// 弹一个确认框
weui.confirm('发现新版本,是否更新?', () => {
// 刷新一下页面
window.location.reload();
}, () => {
}, {
title: ''
})
}
})
当发现 Service Worker 更新后,弹窗来确认是否更新,如下图:
这里说明一下:
- 选择了 office-plugin 插件之后,之前我们手写的注册 Service Worker 和 Service Worker 缓存相关逻辑都可以去掉了,因为 offline-plugin 会帮我们做这些事情
- offline-plugin 插件会自动扫描 webpack 构建出来的 dist 目录里的文件,对这些文件配置缓存列表,正如上面插件里面的配置
- excludes: 指定了一些不需要缓存的文件列表,例如我们不希望对图片资源进行缓存,并且支持正则表达式的方式
- updateStrategy:指定了缓存策略选择全部更新,另外一种是增量更新 changed
- event: true:指定了要触发 Service Worker 时间的回调,这个 main.js 里的配置是相对应的,只有这里设置成 true,那边的回调才会触发
- 我们在 main.js 里的配置是为了当 Service Worker 有更新时,立刻进行更新,而不让 Service Worker 进入 wait 状态,这和上面我们讲到的 Service Worker 更新流程相对应
更多的 offline-plugin 相关配置,可以去官网看文档
在执行 npm run build 命令之后,就会生成对应的 sw.js 文件,部署之后就可以替换我们之前手写的 sw-my.js 了
除此之外,我们在 PC 段的 Chrome 也可以选择使用安装到桌面的功能,这让我们的程序应用看起来更像是一个桌面应用:
添加消息推送逻辑:
消息推送逻辑,主要分为两种方案,一种的非常简单的使用 PC 的 Chrome 的开发者工具自带的 Push 功能,可以通过 Application -> Service Worker 面板 -> Push 按钮来实现,如下图:
这种方式只能是简单的推送,并且依赖于浏览器,大多数作为调试来使用,而真正的为 APP 添加消息推送,需要结合 Web Push 协议来实现,同时消息推送主要包括去掉逻辑和后端逻辑,其中:
- 前端逻辑包括:
- 用户授权订阅逻辑
- 收到推送后借助 Notification 通知逻辑
- 后端逻辑包括:
- 存储用户授权标识
- 根据标识向推送服务器发送请求
**1. 前端订阅逻辑 **
获取用户标识,要借助与 Service Worker,基于 Web Push 的推送和通知相关全部要用到 Service Worker。在之前创建的 registerServiceWorker.js 增加如下代码:
navigator.seviceWorker.ready.then((registration) => {
// publicKey 和后台的 publickey 对应保持一致
const publicKey = 'BAWz0cMW0hw4yYH-DwPrwyIVU0ee3f4oMrt6YLGPaDn3k5MNZtqjpYwUkD7nLz3AJwtgo-kZhB_1pbcmzyTVAxA';// web-push 定义的客户端的公钥,用来和后端的 web-push 对应
// 获取订阅请求(浏览器会弹出一个确认框,用户是否同意消息推送)
try {
if(window.PushManager) {
registeration.pushManager.getSubscription().then(subscription => {
// 如果用户没有订阅 并且是一个登录用户
if(subscription && window.localStorage.getItem('cuser')) {
const subscription = registration.pushManager.subscribe({
userVisibleOnly: true, // 表明该推送是否需要显示地展示给用户,即推送是否是否会有消息提醒,如果没有消息提醒就表明是进行“静默”推送。在 Chrome 中,必须要将其设置为 true,否则浏览器就会在控制台报错
applicationServerKey: urlBase64ToUnit8Array(publicKey) // web-push 定义的客户端的公钥,用来和后端的 web-push 对应
})
// 用户同意
.then(function(subscription) {
console.log(subscription);
alert(subscription);
if(subscription && subscription.endpoint) {
// 存入数据库
let resp = service.post('users/asssubscription', {
subscription: JSON.stringify(subscription);
})
}
})
// 用户不同意或者生成失败
.catch(function(err) {
console.log('No it did not. This happened: ', err);
});
}esle { // 用户已经订阅过
console.log('Your have subscribed our notification');
}
})
}
}catch (e) {
console.log(e);
}
})
26. 说说 DOM 事件流
事件流之事件冒泡与事件捕获
事件流所描述的就是从页面中接受事件的顺序
因为有两种观点,所以事件流也有两种,分别是事件冒泡和事件捕获。现在的主流是事件冒泡
事件冒泡
事件冒泡即事件开始时,由最具体的元素接受(也就是事件发生所在的节点),然后逐级传播到较为不具体的节点
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<button id="clickMe">Click Me</button>
<script>
var button = document.getElementById('clickMe');
button.onclick = function () {
console.log('1. You click Button');
};
document.body.onclick = function () {
console.log('2. You click body');
};
document.onclick = function () {
console.log('3. You click document');
};
window.onclick = function () {
console.log('4. You click window');
};
</script>
</body>
</html>
在代码所示的页面中,如果点击了 button,那么这个点击事件会按如下的顺序传播(Chrome 浏览器)
- button
- body
- document
- window
也就是说,click 事件首先字在 button 元素上发生,然后逐级向上传递,这就是事件冒泡
事件捕获
事件捕获的概念,与事件冒泡正好相反。它认为当某个事件发生时,父因素应该更早接收到事件,具体元素则接收到事件。比如说刚才的 demo,如果是事件捕获的话,事件发生顺序会是这样的
- window
- document
- body
- button
DOM 事件流
DOM 事件流包括三个阶段:
- 事件捕获阶段
- 处于目标阶段
- 事件冒泡阶段
事件捕获阶段
也就是说当事件发生时,首先发生的是事件捕获,为父元素截获事件提供了机会
例如把 window 点击事件更改为使用事件捕获模式(addEventListner 最后一个参数,为 true 则代表事件捕获模式,false 则表示事件冒泡模式)
window.addEventListener('click', function() {
console.log('4. You click window');
}, true);
处于目标与事件冒泡阶段
事件到了具体元素时,在具体元素上发生,并且被看成冒泡阶段的一部分
随后,冒泡阶段发生,事件开始冒泡
阻止事件冒泡
事件冒泡过程,是可以被阻止的阻止事件冒泡而带来不必要的错误和困扰
这个方法就是 stopPropagation()
button.addEventListener('click', function(event) {
// event为事件对象
console.log('1. You click Button');
event.stopPropagation();
console.log('Stop Propagation!');
}, false);
不难看出事件到达具体元素后,停止了冒泡,但不影响父元素的事件捕获
总结与感想
事件流:描述的就是从页面中接受事件的顺序,分有事件冒泡与事件捕获两种。
DOM 事件流的三个阶段:
- 事件捕获阶段
- 处于目标阶段
- 事件冒泡阶段
事件委托
JS event.currentTarget( ) 和 event.target( ) 的区别
这两个方法都是监听事件触发的目标。区别是:
- event.currentTarget() 会返回当前触发事件的元素
- 而 event.target() 会返回触发事件的源头对象。
用法:可以用来监听事件的元素是否事件发生的源头元素。这个源头元素指的是,当我点击子元素,虽然父元素的点击事件也会被触发(冒泡机制),但子元素才是事件的源头元素。
**event.currentTarget():**返回其监听器触发事件的节点,即当前处理事件的元素、文档或窗口。包括冒泡和捕获事件
**event.target():**target 事件属性可返回事件的目标节点(触发该事件的节点,也就是事件发生的源头,事件发生所绑定的那个节点),如生成事件的元素、文档或窗口。也就是说,监听冒泡或者捕获事件的 target,会返回事件发生的那个元素,而不是冒泡或者捕获事件触发的元素。
阻止事件冒泡
function bubbles(e) {
var ev = e || window.event;
if(ev && ev.stopPropagation) { // 非 IE 浏览器
ev.stopPropagation();
} else { // IE浏览器(IE 11以下)
ev.cancheBubble = true;
}
}
阻止默认事件
function stopDefault (e) {
if(e && e.preventDefault) { // 非 IE
e.preventDefault();
}else { // IE
window.event.returnValue = false;
}
return false;
}
27. 前端存储的方式
cookie
HTTP Cookie(也叫 Web Cookie 或浏览器 Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一个浏览器,如保持用户的登录状态。Cookie 使基于无状态 HTTP 协议记录稳定的状态信息成为了可能。
cookie 特点:
- cookie 的大小受限制,cookie 大小被限制在 4KB
- cookie 也可以设置过期的时间,默认是会话结束的时候,当时间到期自动销毁
- 一个域名下存放的 cookie 的个数是有限制的,不同的浏览器存放的个数不一样,一般为 20 个
- 用户每次请求一次服务器数据,cookie 会随着这些请求发送到服务器
- cookie 数据始终在同源的 HTTP 请求中携带(即使不需要),这也是 cookie 不能太大的重要原因
session
session 代表着服务器和客户端一次会话的过程。session 对象存储特定用户会话所需的属性及配置信息。这样,当用户在应用程序的 Web 页之间跳转时,存储在 session 对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。当客户端关闭会话,或者 session 超时失效时会话结束。
cookie 和 session 区别:
- cookie 数据存放在客户的浏览器上,session 数据放在服务器上
- cookie 不是很安全,别人可以分析存放在本地的 cookie 并进行 cookie 欺骗,考虑到安全应使用 session
- 单个 cookie 保存的数据不能超过 4 k, session 可以存储数据远高于 cookie
- cookie 只能保存 ASCII,session 可以存放任意数据类型
h5 新的存储方法(localStorage 和 sessionStorage)
这是一种持久化的存储方式,也就是说如果不手动清除,数据永远不会过期。它是采用 key-value 的方式存储数据,底层数据接口是 splite,按域名将数据分别保存到对应的数据库文件里,它能保存更大的数据。
特点:
- 保存的数据长期存在,下一次访问该网站的时候,网页可以直接读取以前保存的数据
- 大小为 5 M 左右
- 仅在客户端使用,不和服务端进行通信
- 存储的信息在同一域中是共享的
- localStorage 本质上是对象字符串的读取,如果存储的内容多的话会消耗内存空间,会导致页面变卡
indexedDB
indexedDB 就是浏览器提供的本地数据库,它可以被网页脚本创建和操作。indexedDB 允许存储大量数据,提供查找接口,还能建立索引。这些都是 localStorage 所不具备的。就数据库类型而言,indexedDB 不属于关系型数据库(不支持 SQL 查询语句),更接近 NoSQL 数据库
特点:
- **键值对存储:**indexedDB 内部采用对象仓库(object store)存放数据。所有类型的数据都可以直接存入,包括 JavaScript 对象。对象仓库中,数值以“键值对”的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复的,否则就会抛出一个错误
- **异步:**indexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 localStorage 形式对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现
- **支持事务:**indexedDB 支持事务,这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚事务发生之前的状态,不存在只改写一部分数据的情况
- **同源限制:**indexedDB 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库
- **存储空间大:**indexedDB 的存储空间比 localStorage 大得多,一般来说不少于 250 MB,甚至没有上限
- **支持二进制存储:**indexedDB 不仅可以存储字符串,还可以存储二进制数据(ArrayBuffer 对象和 Blob 对象)
28. 数组循环的方法,数组遍历 去掉某个值
29. 什么是 Native、Web App、Hybrid 、React Rative 和 Weex ?
此处 App 为应用,application 并非我们通常讲的手机 App
Navtive App
传统的原生 App 开发模式,有 IOS 和 AOS 两大系统,需要各自语言开发各自 App
优点:性能和体验都是最好的
缺点:开发和成本发布高
举个例子:网易管家 App
应用技术:Swift OC Java
WebApp
移动端的网站,常被称为 H5 应用,说白了就是特定运行在移动端浏览器上的网站应用。一般泛指 SPA(Single Page Application)模式开发出的网站,与 MPA(Muti-page Application)对应
优点:开发和发布和成本最低
缺点:性能和体验不能讲是最差的,但也受到浏览器处理能力的限制,多次限制体验会占用用户一定的流量
举个例子:网易管家 App
应用技术:ReactJS、angularJS、VueJS等等
说到 Web App 不少人会联想到 WAP
Hybrid App
混合模式移动应用,介于 Web App、Native 这两者之间的 App 开发技术,兼具“Native App 良好体验的优势” 和 “Web App跨平台开发的优势”
主要的原理是:由 native 通过 JSBridge 等方法提供统一的 API,然后用 html + css 实现界面,JS 来写逻辑调用 API,最终的页面在 Webview 中显示,这种模式下,Android 和 iOS 的 API 一般具有一致性,Hybrid App 所以有跨平台的效果
优点:开发和发布都比较方便,效率介于 Native App 和 Web App 之间
缺点:学习范围较广,需要原生配合
举个例子:我爱我家 App
应用技术:PhoneGap、AppCan
React Native App
Facebook 发现 Hybrid App,开发和发布成本低于 Native App
优点:效果体验接近 Native App,发布和开发成本低于 Native App
缺点:学习有一定成本、且文档较少、免不了踩坑
举个例子:Facebook、YouTube、QQ
Weex App
阿里巴巴团队在 RN 的成功案例上,重新设计出的一套开发模式,站在了巨人肩膀上并有淘宝团队项目做养料,广受关注,2016年4月正式开源,并在 v2.0 版本官方支持 Vue.js,与 RN 分庭抗礼
优点:单页开发模式效率极高,热更新发包体积小,并且跨平台更高
缺点:刚刚起步,文档欠缺;社区没有 RN 活跃,暂不支持完全使用 Weex 开发 App
举个例子:淘宝、天猫、天猫
Native App
Native App 是一种基于智能手机本地操作系统如 iOS、Android、WP 并使用原生编程编写的第三方应用程序,也叫本地 App。一般使用的开发语言为 Java、C++、Object-C
自 iOS 和 Android 这两个的手机操作系统发布以来,在互联网从此就多了一个新的名词:App 意为运行在智能的移动终端设备第三方应用程序
Native App 因为位于平台层上方,向下访问和兼容的能力会比较好一些,可以支持在线或离线,消息推送或本地资源访问,摄像拨号功能的获取。但是由于设备碎片化,App 的开发成本要高很多,维持多个版本的更新升级比较麻烦,用户的安装门槛也较高。但是比较乐观的是,AppStore 培养了一种比较好的用户付费模式,所以在 Apple 的生态圈里,开发者的盈利模式是一种明朗状态,其它 market 也在往这条路上靠拢
优势:
- 相比于其它模式,提供最佳的用户体验,最优质的用户界面,最华丽的交互
- 针对不同平台提供不同的用户体验
- 可节省宽带成本,打开速度更快
- 功能更为强大,特别是在与系统交互中,几乎所有功能都能实现
劣势:
- 门槛高,原生开发人才稀缺,至少比前端和后端少,开发环境昂贵
- 无非跨平台,开发的成本比较大,各个系统独立开发
- 发布成本高,需要通过 store 或 market 的审核,导致更新缓慢
- 维护多个版本、多个系统的成本比较高,而且必须做兼容
- 应用市场逐渐饱和,怎样抢占用户时间需要投入大量的时间和金钱,这也导致”僵尸“App 增多
什么情况下会阻塞DOM渲染
讲讲MVVM,说说与MVC有什么区别
文件上传的二进制具体是怎么处理的
ES6/ES7/ES8的特性
- serviceworker如何保证离线缓存资源更新
- virtual dom有哪些好处
- canvas优化绘制性能
- 算法:Promise串行
- await 可以返回变量吗
- async await 原理
- 前端 SEO
服务端预渲染框架?
回调函数一定是异步函数
浏览器API 地板不能浏览器不兼容
性能优化测试
object.defined proxy 监听数组的 a[0] = 1
event.target 和 currenttarget 区别
visibilte opcary 区别
更新 队列 大文件上传 怎么切割 如何并发请求
组件深 solt
组件库设计 竞品分析 工作进度 二次封装 边界 工程化的东西
1. Vue 生命周期
| 钩子函数 | 作用 | 应用场景 |
|---|---|---|
| beforeCreate(创建前) | 是获取不到 props 或者 data 中的数据,因为这些数据初始化都在 initState 中。 | 可以在这加一些loading 效果,在created 时进行移除 |
| created(创建后) | 可以访问到 data 中的数据,但是这个时候组件还没被挂载,所以看不到。 | 异步请求数据丶页面初始化的工作 |
| beforeMount(载入前) | 开始创建 VDOM,相关的 render 函数首次被调用,把 data 里面的数据和模板生成 html | |
| mounted(载入后) | 并将 VDOM 渲染成真实的 DOM 并且渲染数据,组件中如果有子组件的话,会递归挂载子组件,只有当子组件全部挂载完毕,才会执行根组件的挂载钩子 | 获取挂载dom元素节点 |
| beforeUpdate(更新前) | 数据更新前,发生在虚拟 DOM 重新渲染和打补丁之前,可以在此区间进一步更改状态,不会触发附加的渲染过程 | |
| update(更新后) | 数据更新后 | 当数据更新需要做一些业务处理的时候使用 |
| beforeDestory(销毁前) | 适合移除事件丶定时器等等,否则会引起内存泄漏的问题 | |
| destoryed(销毁后) | 进行一系列的销毁操作,如果有子组件的话,也会递归销毁子组件,当所有子组件都销毁完毕后才会执行根组件的 destroyed 钩子函数。 | |
| deactivated | 用 keep-alive 包裹的组件在切换时不会进行销毁,而是缓存到内存中执行这个钩子函数 | |
| activated | 命中缓存渲染后会执行这个函数 |
2. Vue 父子组件生命周期执行顺序
Vue 父子组件生命周期钩子的执行顺序遵循:从外到内丶然后从内到外。
组件加载渲染过程
父组件beforeCreate -> 父组件created -> 父组件beforeMount -> 子组件beforeCreated -> 子组件created -> 子组件beforeMount -> 子组件mounted -> 父组件mounted
子组件更新过程
父组件beforeUpdate -> 子组件beforeUpdate -> 子组件updated -> 父组件updated
父组件更新过程
父组件beforeUpdate -> 父组件updated
销毁过程
父组件beforeDestory -> 子组件beforeDestory -> 子destoryed -> 父组件destoryed
3. 组件通信
props 和 e m i t / emit/ emit/on
最基本的父组件给子组件传递数据方式,将我们自定义的属性传给子组件,子组件通过 $emit 方法,触发父组件 v-on 的事件,从而实现子组件触发父组件方法
- 父组件传值给子组件:子组件通过 props 方法接受数据
- 子组件传值给父组件:$emit 方法传递参数
优点:
- 使用最为简单,也是父子组件传递最常见的方法
- Vue 会为 props 提供了类型检查支持
- $emit 不会修改到别的组件的同名事件,因为它只能触发父级的事件,这里和 event-bus 不同
缺点:
- 单一组件层级一深需要逐层传递,会有很多不必要的代码量
- 不能解决了多组件依赖同一个状态的问题
eventBus
就是创建一个事件中心,相当于中转站,可以用它来传递事件和接受事件。项目小的时候 用这个比较合适
使用方法
// bus.js
import Vue from 'vue'
export default new Vue({})
// component-a.js
import bus from './bus.js'
export default {
created () {
created () {
bus.$on('event-name', (preload) => {
// ...
})
}
}
}
// component-b.js
import bus from './bus.js'
export default {
created () {
bus.$emit('event-name', preload);
}
}
优点:
- 解决了多层级组件之间繁琐的事件传播
- 使用原理十分简单,代码量少
缺点:
- 由于是使用一个 Vue 实例,所以容易出现重复触发的情景,例如:
- 多人开放时,A、B两个人定义了同一个事件名
- 两个页面都定义了同一个事件名,并且没有用 $off 销毁(常出现在路由切换时)
- 在 for 出来的组件里注册
- 项目一大用这种方式管理事件会十分混乱,这时候建议用 Vuex
vuex:
主要有两种数据会使用 vuex 进行管理
-
组件之间全局共享数据
-
通过后端异步请求的数据
-
优点:
- 解决了多层组件之间繁琐的事件传
- 解决了多组件依赖同一状态的问题
- 单向数据流
- 为 Vue 量身定做,学习成本不高
-
缺点
- 不能做数据持久化存储,刷新页面就要重制,要做数据持久化可以考虑使用 localstorage
- 增加额外的代码体积,简单的业务场景不建议使用
provide / inject
在父组件上通过 provide 提供给后代组件的数据/方法,在后代组件上通过 inject 来接收被注入的数据/方法
provide 选项应该是一个对象或返回一个对象的函数。该对象包含其子孙的属性。在该对象中你可以使用 ES2015 Symbol 作为 key,但是原生只支持 Symbol 和 Reflect.ownKeys 的环境下可工作
inject 选项应该是:一个字符串数组 或 一个对象,对象的 key 是本地的绑定名。
优点:
- 不用像 props 一层层传递,可以跨层级传递
缺点:
- 用这种方式传递的属性是非响应式的,所以尽可能来传递一些静态属性
- 引用官网的话是 它将你的应用以目前的组件方式耦合了起来,使重构变得更加困难,我对这句话的理解是用了provide/inject 你就要遵循它的组件组织方式,在项目的重构时如果要破坏这个组织方式会有额外的开发成本,其实 event-bus 也有这种问题
slot
你可以在组件的 html 模版里添加自定义内容,这个内容可以是任何代码模板,就像:
<navigator-link url='/profile'>
<!-- 添加一个 Font Awesome 图标 -->
<span class="fa fa-user"></span>
Your Profile
</navigator-link>
父组件模版的所有东西都会在父级作用域内编译;子组件模版的所有东西都会在子级作用域内编译
你也可以通过 slot-scope 属性来实现从子组件将一些信息传递给父组件,注意这个属性是 vue2.1.0+ 新增的
优点:
- 可以在父组件里自定义到子组件内的内容,虽然其它属性也可以,但是我觉得 slot 更倾向于自定义的条件是来自于父容器中
- 复用性好,适合做组件开发
缺点:
- 和 props 一样不支持跨层级传递
$parent 和 $children
通过 p a r e n t / parent/ parent/children 可以拿到父子组件的实例,从而调用实例里的方法,实现父子组件通信。并不推荐这种做法
使用方法
通过 this. p a r e n t 或者 t h i s . parent 或者 this. parent或者this.children 拿到父或子组件的实例
优点:
- 可以拿到父子组件的实例,从而拥有实例里的所有属性
缺点:
- 用这种方法写出的组件十分难维护,因为你并不知道数据的来源是哪里,有悖于单向数据流的原则
- this.$children 拿到的是一个数组,你并不能很准确的找到你要找的子组件的位置,尤其是子组件多的时候
4. extend 能做什么
作用是拓展组件生成一个构造器,通常会与 $mount 一起使用。
使用场景:
- 组件模板都是事先定义好的,如果我要从接口动态渲染组件怎么办?
- 所有内容都是在
#app下渲染,注册组件都是在当前位置渲染。如果我要实现一个类似于window.alert()提示组件要求像调用 JS 函数一样调用它,该怎么办?
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>在Vue中注册组件</title>
</head>
<body>
<div id="todoItem"></div>
</body>
<script src="https://cdn.jsdelivr.net/npm/vue" type="text/javascript"></script>
<script>
// 局部注册组件
var todoItem = Vue.extend({
data: function () {
return {
todoData: [
{ id: 0, text: '蔬菜' },
{ id: 1, text: '奶酪' },
{ id: 2, text: '随便其它什么人吃的东西' }
]
}
},
template: `
<ul>
<li v-for='(d, i) in todoData' :key="i">
{{ d.text }}
</li>
</ul>
`
});
// 请注意,在实例化extends组件构造器时,传入属性必须是 propsData、而不是 props 哦
new todoItem({
propsData: {
todoData: [
{ id: 0, text: '蔬菜' },
{ id: 1, text: '奶酪' },
{ id: 2, text: '随便其它什么人吃的东西' }
]
}
}).$mount('#todoItem')
</script>
</html>
5. mixin 和 mixins 区别
类似小程序的 behaviors,用于组件间代码共享的特性
mixin
- 用于全局混入,会影响到每个组件实例,通常插件都是这样做初始化的。
- 虽然文档不建议我们在应用中直接使用 mixin,但是如果不滥用的话也是很有帮助的,比如可以全局混入封装好的 ajax 或者一些工具函数等等。
mixins
- 应用场景:应该是我们最常使用的拓展组件的方式了。如果多个组件中有相同的业务逻辑,就可以将这些逻辑剥离出来,通过 mixins 混入代码,比如 上拉下拉加载数据 这种逻辑等等。
- 另外需要注意的是同名钩子函数(craeted, mounted…)将混为一个数组,mixins 混入的钩子函数会先于 组件内的钩子函数 执行,并且在遇到同名选项的时候也会有选择性的进行合并,
- 对象数据(data)在内部会进行递归合并,并在发生冲突时以组件数据优先。
- 值为对象的选项(method丶component和directives)将混合为同一个对象,两个对象键名冲突时,取组件对象的键值对
6. computed 和 watch 区别
computed
- 是计算属性,依赖其他属性计算值,并且 computed 的值有缓存,只有当计算机值变化才会返回内容。
- 一般需要依赖别的属性来动态获得值的时候可以使用 computed
- 应用场景:
- 适用于一些重复使用数据或复杂及废时的运算。我们可以把它放入 computed 中进行计算,然后会在 computed 中缓存起来,下次直接获取了
- 如果我们需要的数据依赖于其它的数据的话,完美可以把该数据设计为 computed 中
- 购物车结算商品的时候
<template>
<div class="hello">
{{fullName}}
</div>
</template>
<script>
export default {
data() {
return {
firstName: "飞",
lastName: "旋"
}
},
props: {
msg: String
},
computed: {
fullName() {
return this.firstName + ' ' + this.lastName;
}
}
}
</script>
computed 设计的初衷是:为了使模版中的逻辑运算更简单。它有两大优势:
- 使模版中的逻辑更清晰,方便代码管理
- 计算之后的值会被缓存,依赖的 data 值改变后会重新计算
因为我们要理解 computed 的话,我们只需要理解如下如下问题:
- computed 是如何初始化的,初始化之后做了哪些事情?
- 为什么我们改变了 data 中的属性值后,computed 会重新计算,它是如何实现的?
- computed 它是如何缓存值的,当我们下次访问该属性的时候,是怎样读取缓存数据的?
methods
区别是:
- computed 是基于响应式依赖来进行缓存的。只有在响应式依赖发生改变它们才会重新求值,也就是说,当 msg 属性值没有发生改变时,多次访问 reverseMsg 计算属性会立即返回之前缓存的计算结果,而不会再次执行 computed 中的函数。但是 methods 方法中是每次调用,都会执行函数,methods 它不是响应式的。
- computed 中的成员可以只定义一个函数作为只读属性,也可以定义成 get/set 变成可读写属性,但是 methods 中的成员没有这样的
watch
watch 它是一个对 data 的数据监听回调,当依赖的 data 的数据变化时,会执行回调。在回调中会传入 newVal 和 oldVal 两个参数。
Vue 实例将会在实例化时调用 $watch(),它会遍历 watch 对象的每一个属性
**watch 的使用场景是:**当在 data 的某个数据发生变化时,我们需要做一些操作,或者当需要在数据变化时执行异步或开销较大的操作时,我们就可以使用 watch 来进行监听
- 监听到值的变化就会执行回调,在回调中可以执行一些逻辑操作。
- 对于监听到值的变化需要做一些复杂逻辑的情况下可以使用
watch - 使用场景:当一条数据影响到多条数据的时候就需要用到
watch,例如搜索数据
理解 handler 方法及 immediate 属性
如上 watch 有一个特点是:第一次初始化页面的时候,是不会去执行 age 这个属性监听的,只有当 age 值发生改变的时候才会执行监听计算。因此我们上面第一次初始化页面的时候,basicMsg 属性值默认为空字符串。那么我们现在想要第一次初始化页面的时候也希望它能够进行 age 进行监听,最后能把结果返回给 basicMsg 值来。因此我们需要修改下我们的 watch 的方法,需要引入 handler 方法和 immediate 属性
<!DOCTYPE html>
<html>
<head>
<title>vue</title>
<meta charset="utf-8">
<script type="text/javascript" src="https://cn.vuejs.org/js/vue.js"></script>
</head>
<body>
<div id="app">
<p>空智个人信息情况: {{ basicMsg }}</p>
<p>空智今年的年龄: <input type="text" v-model="age" /></p>
</div>
<script type="text/javascript">
var vm = new Vue({
el: '#app',
data: {
basicMsg: '',
age: 31,
single: '单身'
},
watch: {
age: {
handler(newVal, oldVal) {
this.basicMsg = '今年' + newVal + '岁' + ' ' + this.single;
},
immediate: true
}
}
});
</script>
</body>
</html>
如上代码,我们给我们的代码的 age 属性绑定了一个 handler 方法。其实我们之前的 watch 当中的方法默认就是这个 handler 方法。但是在这里我们使用了 immediate: true 属性,含义是:如果在 watch 里面声明了 age 的话,就会立即执行里面的 handler 方法。如果 immediate 值为 false 的话,那么效果就和之前的一样,就不会执行 handler 这个方法的。因此设置了 immediate: true 的话,第一次页面加载的时候也会执行该 handler 函数的,即第一次 basicMsg 有值
理解 deep 属性
watch 里面有一个属性为 deep,含义是:是否深度监听某个对象的值,该值默认为 false
<!DOCTYPE html>
<html>
<head>
<title>vue</title>
<meta charset="utf-8">
<script type="text/javascript" src="https://cn.vuejs.org/js/vue.js"></script>
</head>
<body>
<div id="app">
<p>空智个人信息情况: {{ basicMsg }}</p>
<p>空智今年的年龄: <input type="text" v-model="obj.age" /></p>
</div>
<script type="text/javascript">
var vm = new Vue({
el: '#app',
data: {
obj: {
basicMsg: '',
age: 31,
single: '单身'
}
},
watch: {
'obj': {
handler(newVal, oldVal) {
this.basicMsg = '今年' + newVal.age + '岁' + ' ' + this.obj.single;
},
immediate: true,
deep: true // 需要添加deep为true即可对obj进行深度监听
}
}
});
</script>
</body>
</html>
如上测试代码,如果我们不把 deep: true 添加的话,当我们在输入框中输入值的时候,改变 obj.age 值后,obj 对象中的 handler 函数是不会被执行到的。受 JS 的限制,Vue 不能检测到对象属性的添加或删除的。它只能监听到 obj 这个对象的变化,比如说对 obj 赋值操作会被监听到。比如在 mouted 事件钩子函数中对我们的 obj 进行重新赋值操作
mounted() {
this.obj = {
age: 22,
basicMsg: '',
single: '单身'
};
}
以后我们的页面会被渲染到 age 为 22,因此这样我们的 handler 函数才会被执行到。如果我们需要监听对象中的某个属性值的话,外面可以使用 deep 设置为 true 即可生效。deep 实现机制是:监听器会一层层的往下遍历,给对象的所有属性都加上这个监听器。当然性能开销会非常大
当然我们可以直接对对象中的某个属性进行监听,比如就对 'obj.age’来进行监听,如下的代码也是可以生效的
<!DOCTYPE html>
<html>
<head>
<title>vue</title>
<meta charset="utf-8">
<script type="text/javascript" src="https://cn.vuejs.org/js/vue.js"></script>
</head>
<body>
<div id="app">
<p>空智个人信息情况: {{ basicMsg }}</p>
<p>空智今年的年龄: <input type="text" v-model="obj.age" /></p>
</div>
<script type="text/javascript">
var vm = new Vue({
el: '#app',
data: {
obj: {
basicMsg: '',
age: 31,
single: '单身'
}
},
watch: {
'obj.age': {
handler(newVal, oldVal) {
this.basicMsg = '今年' + newVal + '岁' + ' ' + this.obj.single;
},
immediate: true,
// deep: true // 需要添加deep为true即可对obj进行深度监听
}
}
});
</script>
</body>
</html>
watch 和 computed 的区别是:
相同点:它们两者都是观察页面数据变化的
不同点:computed 只有当依赖的数据变化时才会计算,当数据没有变化时,它会读取缓存数据。watch 每次都需要执行函数。watch 更适合数据变化时的异步操作
共同点:都支持对象的写法
6. keep-alive 组件有什么用
- 如果你需要在组件切换的时候,保存一些组件的状态防止多次渲染,就可以使用 keep-alive 组件包裹需要保存的组件。
- 对于 keep-alive 组件来说,它拥有两个独立的生命周期钩子函数,分别为
activated和deactivated。用 keep-alive 包裹的组件在切换时不会进行销毁,而是缓存到内存中并执行 deactivated 钩子函数,命中缓存渲染后会执行 activated 钩子函数。 - 使用场景:有时候需要将整个路由页面一切缓存,也就是将
<router-view>进行缓存- 商品列表页点击商品跳转商品详情,返回后任显示原有信息
- 订单列表跳转到的订单详情,然后返回
keep-alive的生命周期
当引入 keep-alive 的时候,页面第一次进入,钩子的触发顺序为 created > mounted > activated,退出后触发 deactived。再次进入(前进或后退)时,只会触发 activated。
事件挂载的方法等,只执行一次的放在 mounted,组件每次进去执行的方法放在 activated
vue 缓存页面keep-alive 的坑(数据不刷新,只缓存第一次进入的页面数据),强制刷新缓存的页面的方法
需求:A 进入 B,根据不同 ID 刷新 B 页面数据,B 进入 C,如果 C 有操作数据,则返回 B 后刷新 B 数据,否则 B 页面不刷新。

解决方案一
A 页面
beforRoutLeave(to, from, next) {
to.meta.isrefer = true; // 刷新 B 的数据
to.meta.type = false;
next();
}
B 页面
beforeRouteEnter(to, from, next) {
to.meta.keeplive = true;
if(vm.$route.meta.isrefer) {
next(vm => {
// 这里把页面初始值重新赋值,以刷新页面
vm.dataList = [];
vm.$route.meta.isrefer = false; // 恢复初始值
vm.seatList = [];
vm.query = {
activatedId: vm.$route.query.activityId,
meetplaceId: vm.$route.query.meetplaceId
}
vm.getSeatImgList(); // 请求数据
})
}
beforeRouteLeave(to, from, next) {
from.meta.keeplive = true; // 每次进入页面都缓存 B
next();
}
}
C 页面与上面不变
App.vue
<keep-alive>
<router-riew v-if="$route.meta.keeplive"><router-view>
</keep-alive>
<router-view v-if="!$route.meta.keeplive"></router-view>
解决方案二(利用 provide 和 inject)推荐使用
app.vue
<keep-alive v-if="isRouterAlive">
<router-view v-if="$route.meta.keeplive"></router-riew>
<keep-alive>
<router-view v-if="!$route.meta.keeplive"></router-view>
Data 里面加个初始值
data () {
return {
isRouterAlive: true
}
}
与 data 同级加个 provide
provide () {
return {
reload: this.reload
};
}
Method 加 reload 方法
reload () {
this.isRouterAlive = false;
this.$nextTick(() => {
this.isRouteAlive = true;
})
}
要缓存的页面
// 与 data 同级加个
inject: ["reload"]
修改 beforeRouterEnter
beforeRouteEnter(to, from, next) {
to.meta.keeplive = true;
next(vm => {
vm.reload(); // 调用 app.vue 的方法
})
}
7. v-show 与 v-if 区别
共同点:都能控制元素的显示和隐藏
不同点:
- 实现方式
v-if是直接从 DOM 树上删除和重建元素节点v-show只是修改 CSS 样式,也就是 display 的属性值,元素始终在 DOM 树上
- 编译过程
v-if切换有一个局部编译/卸载的过程,切换过程中合适地销毁和重建内部的事件监听和子组件v-show只是简单的基于 CSS 切换
- 编译条件
v-if是惰性的,如果初始条件为假,则什么都不做,只有在条件第一次为真的时候才开始编译v-show是在任何条件都被编译,然后被缓存,而且 DOM 元素始终被保留
- 性能消耗
v-if有更高的切换消耗,不适合做频繁的切换v-show有更高的初始渲染消耗,适合做频繁的切换
- 使用场景
- 如果需要频繁的切换,则使用
v-show比较好 - 如果在运行时条件很少改变,则使用
v-if较好
- 如果需要频繁的切换,则使用
8. 组件中 data 什么时候可以使用对象
- 组件复用时所有组件实例都会共享
data,如果data是对象的话,就会造成一个组件修改data以后会影响到其他所有组件,所以需要将data写成函数,每次用到就调用一次函数获得新的数据。 - 当我们使用
new Vue()的方式的时候,无论我们将 data 设置为对象还是函数都是可以的,因为new Vue()的方式是生成一个根组件,该组件不会复用,也就不会共享 data 的情况了。
9. v-for 与 v-if 的优先级
- 当 Vue 处理指令时,
v-for比v-if具更高的优先级 - 永远不要把
v-if和v-for同时用在同一个元素上,如果实在需要,则在外套层template,在这一层进行v-if判断,然后再内部进行v-for循环,避免每次只有v-if只渲染很少一部分元素,也要遍历同级的所有元素
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.jsdelivr.net/npm/vue"></script>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.js"></script>
</head>
<body>
<div id="app">
<ul >
<li v-for="item in user" v-if="item.isActive">{{item.name}}</li>
</ul>
</div>
</body>
<script>
new Vue({
el: '#app',
data: {
user: [
{name: 'hehe1', isActive: true},
{name: 'hehe2', isActive: false},
{name: 'hehe3', isActive: true},
{name: 'hehe4', isActive: true},
]
},
});
// 将会进行如下运算
// this.users.map(function(user) {
// if(user.isActive) {
// return user.name;
// }
// })
</script>
</html>
- 如果条件出现在循环内部,可通过计算属性
computed提前过滤掉那些不需要显示的项
computed: {
items: function() {
return this.list.filter(function (item) {
return item.isShow
})
}
}
10. Vue 子组件调用父组件方法总结
this.$emit(‘fn’)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>
</head>
<body>
<div id="app">
<div>
<child @fatherMethod="fatherMethod"></child>
</div>
</div>
<script>
Vue.component('child', {
template: `<div @click="activeBtn">点击我</div>`,
methods: {
activeBtn() {
console.log(11);
this.$emit('fatherMethod');
}
}
})
var app = new Vue({
el: "#app",
methods: {
fatherMethod() {
console.log('父组件');
}
}
})
</script>
</body>
</html>
this.$parent.fn()
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>
</head>
<body>
<div id="app">
<div>
<child></child>
</div>
</div>
<script>
Vue.component('child', {
template: `<div @click="activeBtn">点击我</div>`,
methods: {
activeBtn() {
this.$parent.fatherMethod();
}
}
})
var app = new Vue({
el: "#app",
methods: {
fatherMethod() {
console.log('父组件');
}
}
})
</script>
</body>
</html>
父组件把方法通过props传入子组件中,在子组件里面调用这个方法
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>
</head>
<body>
<div id="app">
<div>
<child :acson="fatherMethod"></child>
</div>
</div>
<script>
Vue.component('child', {
template: `<div @click="activeBtn">点击我</div>`,
props: {
acson: {
type: Function,
default: null
}
},
methods: {
activeBtn() {
this.acson();
}
}
})
var app = new Vue({
el: "#app",
methods: {
fatherMethod() {
console.log('父组件');
}
}
})
</script>
</body>
</html>
11. 自己封装的组件如何使用 v-model
<!-- parent -->
<template>
<div class="parent">
<p>我是父亲, 对儿子说: {{sthGiveChild}}</p>
<Child v-model="sthGiveChild"></Child>
</div>
</template>
<script>
import Child from './Child.vue';
export default {
data() {
return {
sthGiveChild: '给你100块'
};
},
components: {
Child
}
}
</script>
<!-- child -->
<template>
<div class="child">
<p>我是儿子,父亲对我说: {{give}}</p>
<a href="javascript:;" @click="returnBackFn">回应</a>
</div>
</template>
<script>
export default {
props: {
give: String
},
model: {
prop: 'give',
event: 'returnBack'
},
methods: {
returnBackFn() {
this.$emit('returnBack', '还你200块');
}
}
}
</script>
12. Vue 响应式原理

总结一下:
- 任何一个
Vue Component都有一个与之对应的Watcher实例 Vue的data上的属性会被添加getter和setter属性- 当
Vue Componnetrender函数被执行的时候,data上会被触碰(touch),即被读,getter方法会被调用,此时 Vue 会去记录此Vue Componnent所依赖的所有data。(这一过程被称为依赖收集) data被改动时候(主要是用户操作),即被写,setter方法会被调用,此时 Vue 会去通知所有依赖于此data的 组件去调用
Vue 不支持 IE8 以下版本的浏览器,因为浏览器是基于 Object.defineProperty 来实现数据响应的,而Object.defienProperty 是 ES5 中无法 shim 的特性,这也是为什么 Vue 不支持 IE8 以及更低版本浏览器的原因;Vue 通过 Object.defineProperty 的 getter/setter 对收集的依赖进行监听,在监听被访问和修改时通知变化,进而更新视图数据。
Vue数据响应式变化涉及Observer丶Watcher丶Dep
1. 首选进行Vue的init初始化操作
- initData这里面做了两件事,一是将_data上面的数据代理到vm上,二是通过执行observe(data, true/asRootData)将所有data变成可观察的,即对data定义的每个属性进行getter/setter操作,这里就是Vue实现响应式的基础
- 这里new Observer(value) 就是实现响应式的核心方法之一了,通过它将data转变可以变成观察的,而这里正是我们开头说的,用了Object.definedProperty实现了data的getter/setter操作,通过Watcher来观察数据的变化,进行更新到视图中。
2. Observer
- Observer类是将每个目标对象(即data)的键值对转换成getter/setter形式,用于进行依赖收集以及调度更新
https://juejin.cn/post/6844903561327820808
????
13. Vue 中的 key 和 React 中的key
Vue 中的 key
作用:
-
Vue 中的 key 是为了 Vue 中的 vNode 标记的唯一标识,通过这个标识,我们的 diff 操作可以更准确丶更快速。
-
为了虚拟 dom 能够快速找准对应的节点,进行对比,极大的提升虚拟 dom 对比速度,也减少了不必要的遍历。
特点:
-
准确: 如果不加 key,那么 Vue 会选择复用节点(Vue的就地更新策略),导致之前节点的状态被保留下来,会产生一系列的 bug
-
快速: key 的唯一性可以被 Map 数据结构充分利用,相比于遍历查找的时间复杂度O(n),Map的时间复杂度仅仅为O(1)。
function createKeyOldIdx(children, beginIndex, endIndex) { let i, key; const map = {}; for(i = beginIndex, i <= endIndex, ++i) { key = children[i].key; if(isDef(key)) { map[key] = i; } } return map; }
应用场景:
-
列表组件
<div v-for="item in items" :key="item.id"> <!-- 内容 --> </div> -
允许用户在不同的登录方式之间切换
<template v-if="loginType === 'username'"> <label>Username</label> <input placeholder="Enter you name" key="username-input"> </template> <template v-else> <label>Email</label> <input placeholder="Enter your email address" key="email-input"> </template>
React 中的 key
定义:
属性,它是一种特殊的属性,它的出现不适给开发者用的,而是给 React 自己使用的,有了 key 属性后,就可以与组件建立了一种对应关系,简单来说,react 利用 key 来识别组件,它是一种身份识别,就像每个人有一个身份证来辨识一样。每个key对应一个组件,相同的key,React认为是同一个组件,这样后续相同的 key 对应组件都不会被创建。
作用:
react 的 diff 算法是把 key 当成唯一 id 然后比对组件的 value 来确定是否需要更新的,所以如果没有 key,react 将不会知道该如何更新组件。
- key 值相同的,如果两个元素是相同的 key,且满足第一点元素类型相同,若元素属性有所变化,则 React 值更新组件对应的属性,这样的情况下,性能开销相对较小
- key 值不同,在 render 函数执行的时候,新旧两个虚拟 DOM 会进行对比,如果两个元素有不同的 key,那么前后两次渲染中就会被认为是不同的元素,这时候旧的那个元素会被不挂载,新的元素会被挂载
14. $nextTick 的使用和作用
原理:
在下一次 DOM 更新循环之后执行延迟回调,在修改数据之后立即使用这个方法,获取更新后的 DOM。
$nextTick原理: 为什么要使用$nextTick?这是由于 Vue 是异步执行 dom 更新的,一旦观察到数据变化,Vue 就会开启一个队列,然后把在同一个事件循环(event loop)当中观察到数据变化的 watcher 推送进这个队列。如果这个 watcher 被触发多次,只会被推送到队列一次。这种缓冲行为可以有效的去掉重复数据造成的不必要的计算和 dom 操作。而下一个事件循环开始时,Vue 会进行必要的 dom 更新,并清空队列($nextTick方法就相当于在 dom 更新 和 清空队列后 额外插入的执行步骤)
应用场景:需要在视图更新之后,基于新的视图进行操作。
需要注意得是,在 created 和 mouted 阶段,如果操作渲染后的视图,也要使用$nextTick方法
-
点击按钮显示原本以v-show = false隐藏起来的输入框,并获得焦点
<div id="app"> <input type="text" v-show = "showit" id="keywords"> <button @click="click">click</button> </div> <script src="https://cdn.jsdelivr.net/npm/vue"></ <script> new Vue({ el: '#app', data: { showit: false }, methods: { showsou() { this.showit = true; // document.getElementById('keywords').focus(); this.$nextTick(function() { document.getElementById('keywords').focus(); }) }, click() { this.showsou(); } } }); </script> -
点击获取元素的宽度
<div id="app"> <p ref="myWidth" v-if="showMe">{{message}}</p> <button @click="getMyWidth">click</button> </div> <script src="https://cdn.jsdelivr.net/npm/vue"></script> <script> new Vue({ el: '#app', data: { showMe: false, message: "" }, methods: { getMyWidth() { this.showMe = true; // this.message = this.$refs.myWidth.offsetWidth; this.$nextTick(() => { this.message = this.$refs.myWidth.offsetWidth; }) } } }); </script> -
使用 swiper 插件通过 ajax 请求图片后的滑动问题
源码分析
let timerFunc;
let callbacks = []; // 回调函数队列
let pending = false; // 异步锁
// 执行回调函数
function flushCallbacks() {
// 重置异步锁
pending = false;
// 防止出现nextTick包含nextTick时出现的问题,在执行回调函数队列时,提前复制备份,清空回调函数队列
const copies = callbacks.slice(0);
callbacks.length = 0;
// 执行回调函数队列
for(let i = 0; i < copies.length; i++) {
copies[i]();
}
}
// 判断1:是否支持原生Promise
if (typeof Promise !== 'undefiend' && isNative(Promise)) {
const p = Promise.resolve();
timerFunc = () => {
p.then(flushCallbacks);
if(isIOS) setTimeout(noop);
}
isUsingMicroTask = true;
// 判断2:是否原生支持MutationObserver
}else if(!isIE && MutationObserver !== 'undefiend' && (
isNative(MutationObserver) ||
MutationObserver.toString() === '[object MutationObserverConstructor]'
)) {
let counter = 1;
const observer = new MutationObserve(flushCallbacks);
const textNode = document.createTextNode(String(counter));
observer.observe(textNode, {
characterData: true
})
timerFunc = () => {
counter = (counter + 1) % 2;
textNode.data = String(counetr);
}
isUsingMicroTask = true;
// 判断3:是否原生支持setImmediate
}else if(typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
timerFunc = () => {
setImmediate(flushCallbacks);
}
// 判断4:上面都不行,直接使用setTimeout
}else {
timerFunc = () => {
setTimeout(flushCallbacks, 0);
}
}
// 微任务 Promise MutationObserver
// 宏任务 setImmediate setImmediate
// 我们调用的nextTick函数
export function nextTick(cb?: Function, ctx?: Object) {
let _resolve;
// 将回调函数推入异步队列
callback.push(() => {
if(cb) {
try {
cb.call(ctx);
} catch(e) {
handleError(e, ctx, 'nextTick');
}
}else if(_resolve) {
_resolve(ctx);
}
})
// 如果异步锁未锁上,锁上异步锁,调用异步函数;
// 准备等同步函数执行完后,就开始执行回调队列
if(!pending) {
pending = true;
timerFunc();
}
// 如果没有提供回调,并且支持Promise,返回一个Promise
if(!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve;
})
}
}
- 把回调函数放在callbacks等待执行
- 将执行函数放到微任务或者宏任务中
- 事件循环到了微任务或者宏任务,执行函数依次执行callbacks中的回调
this.$nextTick是微任务
实现一个简易版本的nextTick
// 通过nextTick接收回调函数,通过setTimeout来异步执行回调函数
// 通过这种方式,可以在下一个tick中 执行回调函数,即在UI重新渲染后执行回调函数
let callbacks = [];
let pending = false;
function nextTick(cb) {
callbacks.push(cb);
if(!pending) {
pending = true;
setTimeout(flushCallback, 0);
}
}
function flushCallbacks() {
pending = false;
let copies = callbacks.slice();
callbacks.length = 0;
copies.forEach(copy => {
copy();
})
}
// 测试
nextTick(function() {
console.log(1);
})
console.log(2);
// 2
// 1
15. Vue 的组件为什么要用 export defalut?
Vue 的模块机制是通过 webpack 实现的模块化,因此可以使用 import 来引入模块,,例如:
import Vue from 'vue'
import App from './App'
import router from './router'
你还可以在 build/webpack.base.conf.js 文件中修改相关配置:
resolve: {
extensions: ['.js', '.vue', '.json'],
alias: {
'vue$': 'vue/dist/vue.esm.js',
'@': resolve('src'),
}
}
意思是,你的模块可以省略.js丶.vue丶json 后缀,webpack 会在之后自动加上
export 用来导出模块,Vue 的单文件组件通常需要导出一个对象,这个对象是 Vue 实例的选项对象,以便在其它地方可以使用import引入。而 new Vue() 相当于一个构造函数,在入口文件 main.js 构造根组件的同时,如果根组件还包含其它子组件,那么 Vue 会通过引入的选项对象构造其对应的 Vue 实例,最终形成一棵组件树。
export 和 export defalut 的区别在于:
export可以导出多个命名模块,例如:
// demo1.js
export const str = 'hello word';
export function f(a) {
return a + 1;
}
对应的引入格式:
// demo2.js
import { str, f } from 'demo1'
export default只能导出一个默认模块,这个模块可以匿名,例如:
// demo1.js
export default {
a: 'hello',
b: 'world'
}
对应的引入方式
import obj from 'demo1'
引入的方式可以给这个模块取任意名字,例如’obj’,且不需要用大括号括起来
总结:
export命令对外接口是有名称的且import命令从模块导入的变量名与被导入模块对外接口的名称相同,而export default命令对外输出的变量名可以是任意的,这时import命令后面,不使用大括号export default命令用于指定的默认输出。显然,一个模块只能有一个默认输出,因此export default命令只能使用一次。所以,import命令后面才不用加大括号,因为只可能唯一对应export default命令。
16. Vuex原理
Vuex是什么?怎么使用? 那种功能场景下使用它 ?
Vuex 是专门为 VueJs 应用程序设计的状态管理工具。它是集中式存储管理应用的所有组件的状态,并以相应的规则保证以一种可预测的方式发生变化。
- Vuex 框架中状态管理。
- 在 main.js 引入 store.js, 新建一个目录 store.js
- 场景:单页面应用中 组件之间的状态 音乐播放 登录状态 加入购物车
Vuex 有哪种属性
State丶Getter丶Mutation丶Action丶Module
1)State
state 是存储的单一状态,是存储的基本数据。
2)Getters
getter 是 store 的计算属性,对 state 的加工,是派生出来的数据。就像 computed 计算属性一样,getter 返回的值会根据它的依赖被缓存起来,且只有当它的依赖值发生变化才被重新计算。
3)Mutation
mutation 提交更改数据,使用 store.commit 方法更改 state 存储的状态。(mutation是同步函数)
4)Action
action像一个装饰器,提交 mutation,而不是直接变更状态(action可以包含任何异步操作)
5)Modules
Module是 store 分割的模块,每个模块拥有自己的state丶getter丶mutations丶actions
6)辅助函数
Vuex提供了 mapState丶MapGetter丶MapActions丶mapMutation等辅助函数给开发vm中处理store
Vuex 会有一定的门槛和复杂性,它的主要使用场景是大型单页面应用场景,如果你的项目不是很复杂,用一个bus也可以实现数据的共享,但是它在数据管理,维护,还只是一个简单的组件,而 Vuex 可以更优雅高效的完成状态管理,所以,是否属于 Vuex 取决于你的团队和技术储备
Vuex 的特点
- 遵循单向数据流
- Vuex 中的数据是响应式的
Vuex 数据传输过程
- 通过 new Vue.Store() 创建一个仓库,state 是公共的状态,state -> components 渲染页面
- 当组件内部通过 this.$store.state 属性来调用公共状态中的 state,进行页面的渲染
- 当组件需要修改数据的时候,必须遵循单向数据流。组件里在 methods 中拓展 mapActions,调用 store 里的 actions 里的方法
- actions 中的每个方法都会接收一个对象,这个对象里面有个 commit 方法,用来触发 mutation 里面的方法
- mutation 里面的方法用来修改 state 中的数据,mutation 里面的方法都会接收2个参数
疑问:
Vuex 的 store 是如何挂载注入到组件中呢?
-
利用 Vue 的插件机制,使用 Vue.use(vuex) 时,会调用 Vuex 的 install 方法,挂载 Vuex
-
里面的 applyMixin 方法使用 Vue 混入机制,Vue 的生命周期 beforeCreate 钩子函数前混入 vuelint 方法
分析源码知道 vuex 是利用 vue 的 mixin 混入机制,在 beforeCraete 钩子前混入 vuexlnit 方法,vuexlint 方法实现了 store 注入 vue 组件实例,并注册了 vuex store 的引用属性
$store
store注入过程
Vuex 的 state 和 getter 是如何映射到各个组件实例中响应式更新状态呢?
- store 实现的源码在 src/store.js
- 找到 resetStoreVM 核心方法
- 可以看出 Vuex 的 state 状态是响应式,是借助 Vue 的 data 是响应式,将 state 存入 Vue 实例组件的 data中;Vuex 的 getters 是借助 Vue 的计算属性 computed 实现数据实时监听
- computed 计算属性监听 data 数据变更主要经历几个过程
Vuex 页面刷新数据丢失的解决办法
解决思路:将 state 的数据保存在 localstorage、sessionstorage 或 cookie 中(三者的区别),这样即可保证页面刷新数据不丢失且易于读取。
由于 Vue 是单页面应用,操作都是在一个页面跳转路由,因此 sessionStorage 较为合适,原因如下
- sessionStorage 可以保证打开页面时 sessionStorage 的数据为空;
- 每次打开页面 localStorage 存储着上一次打开页面的数据,因此需要清空之前的数据。
Vuex 的数据在每次页面刷新时丢失,是否可以在页面刷新前再将数据存储到 sessionstorage 中呢,是可以的。beforeunload 事件可以在页面刷新前触发,但是在每个页面中监听 beforeunload 事件感觉也不太合适,那么最好的监听该事件的地方就在 app.vue 中。
-
在 app.vue 的 created 方法中读取 sessionstorage 中的数据存储在 store 中,此时用vuex.store的replaceState 方法,替换 store 的根状态
-
在 beforeunload 方法中将 store.state 存储到 sessionstorage 中。
代码如下
export default {
name: 'App',
created () {
//在页面加载时读取sessionStorage里的状态信息
if (sessionStorage.getItem("store") ) {
this.$store.replaceState(Object.assign({}, this.$store.state,JSON.parse(sessionStorage.getItem("store"))))
}
//在页面刷新时将vuex里的信息保存到sessionStorage里
window.addEventListener("beforeunload",()=>{
sessionStorage.setItem("store",JSON.stringify(this.$store.state))
})
}
}
17. 路由原理
路由这个概念最先是后端出现的。在以前用模板引擎开发页面时,经常会看到这样
http://www.xxx.com/login
大致流程可以看成这样:
- 浏览器发出请求
- 浏览器监听到80端口(或443)有请求过来,并解析路径
- 根据服务器的路由配置,返回相应信息(可以是html字符串,也可以是json数据和图片等)
- 浏览器根据数据包的 Content-Type 来决定如何解析数据
简单来说路由就是用来跟后端进行交互的一种方式,通过不同的路径,来请求不同的资源,请求不同的页面是路由的其中一种功能。
hash模式
随着 ajax 的流行,异步数据请求交互在不刷新浏览器的情况下进行。而异步交互体验的跟高级版本就是SPA — 单页应用。单页应用不仅仅是在页面交互无刷新的,连页面跳转都是无刷新的,为了实现单页应用,所以就有了前端路由。
类似服务器路由,前端路由实现起来其实也很简单,就是匹配不同的 URL 路径,进行解析,然后动态的渲染区域html 内容。但是这样存在一个问题,就是 url 每次变化的时候,都会造成页面的刷新。那解决问题的思路在改变 url 的情况下,保证页面的不刷新。在 2014 年之前,大家是通过 hash 来实现路由的, url hash就是类似于:
http://www.xxx.com/#.login
这种#。后面 hash 值的变化,并不会导致浏览器向服务器发出请求,浏览器不发出请求,也就不会刷新页面。另外每次 hash 值的变化,还会触发 hashchange 这个事情,通过这个事情我们就可以知道 hash 值发生了哪些变化。然后我们便可以监听 hashchange 来实现更新页面部分内容的操作:
function matchAndUpdate() {
}
window.addEventListener("hashchange", matchAndUpdate)
history模式
14年之后,因为 HTML5 标准发布。多了两个API pushState 和 replaceState,通过这两个 API 可以改变 url 地址且不会发送请求。同时还有 popstate事件。通过这些就能用另一种方式来实现前端路由,但原理都是跟 hash 实现相同的。用了 HTML5 的实现,单页路由的 url 就不会多出一个 #,变得更加美观。但因为没有 # 号,所以当用户刷新页面之类的操作时,浏览器还是会想浏览器服务器发送请求。为了避免出现这种情况,所以这个实现需要服务器的支持,需要把路由都重定向到根页面。
funtion matchAndUpdate() {
// todo 匹配路径做 dom 更新操作
}
window.addEventListener("popstate", matchAndUpdate)
vue-router 是什么?它有哪些组件?
vue 用来写路由的一个插件。router-link丶router-view
active-class 是哪些组件的属性?
vue-router模块的router-link组件 children数组定义子路由
怎么定义vue-router的动态路由?怎么获取传过来的值?
在router目录下的index.js文件 对path属性加上/:id
使用router对象的params.id
vue-router有哪些导航钩子?
三种
第一种:是全局导航钩子:router.beforeEach(to, from, next) 作用:跳转之前进行判断拦截
第二种:组件内的钩子
第三种:单独路由独享组件
$route和$router的区别
$router是VueRouter的实例,在script标签中想要导航到不同的URL,使用
r
o
u
t
e
r
.
p
u
s
h
方法。返回上一个历史
h
i
s
t
o
r
y
用
router.push方法。返回上一个历史history用
router.push方法。返回上一个历史history用router.to(-1)
$route为当前router跳转对象 里面可以获取当前路由的name丶path丶query丶params等
vue-router的两种模式
前端路由实现本质就是监听URL的变化,然后匹配路由规则,显示相应的页面,并且无须刷新页面
Hash模式
www.test.com/#/,就是Hash URL,当#后面的哈希值发生变化时,可以通过hashchange事件来监听URL的变化,从而进行跳转页面,并且无论哈希值如何变化,服务端收到的URL请求永远是www.test.com
window.addEventListener('hashchange', () => {
// ...具体逻辑
})
Hash模式相对于说更简单,并且兼容性也更好
History模式
History模式是HTML5新推出的功能,主要使用history.pushState和history.replace改变URL
通过History模式改变URL同样不会引起页面的刷新,只会更新浏览器的历史记录
// 新增历史记录
history.pushState(stateObject, title, URL)
// 替换当前历史记录
history.replaceState(stateObject, title, URL)
当用户做出浏览器动作时,比如点击后退按钮时会触发popState事件
window.addEventListener('popState', e => {
console.log(e.state);
})
两种模式对比
- Hash模式只可以更改
#后面的内容,History模式可以通过API设置任意的同源URL - History模式可以通过API添加任意类型的数据到历史记录中,Hash模式只能更改哈希值,也就是字符串
- Hash模式无须后端配置,并且兼容性好。History模式在用户手动输入地址或者刷新页面的时候会发起URL请求,后端需要配置
index.html页面用于匹配不到静态资源的时候
vue-router实现路由懒加载(动态加载路由)
三种方式
-
第一种:vue异步组件技术 === 异步加载,vue-router配置路由,使用vue的异步组件技术,可以实现按需加载,但是这种情况下一个组件生成一个JS文件
-
路由懒加载(使用import)
-
webpack提供的require(), vue-router配置路由,使用webpack的require.ensure技术,也可以按需加载。这种情况下,多个路由指定相同的chunkName,会合并打包成一个JS文件
路由守卫
-
分类
-
全局守卫:是指路由实例上直接操作的钩子函数,特点是所有路由配置的组件都会触发,直白点就是触发路由就会触发这些钩子函数
- router.beforeEach(to, from, next) (全局前置守卫)
- router.beforeResolve(to, from, next) (全局解析守卫)
- router.afterEach(to, from) (全局后置守卫)
- 注:beforeEach 和 afterEach 都是 vue-router 实例对象的属性,每次跳转前 beforeEach 和 afterEach 都会执行的
-
路由独享守卫:是指在单个路由配置的时候也可以设置的钩子函数
-
beforeEnter(to, from, next)
{ path: '/', name: 'Login', component: Login, beforeEnter: (to, from, next) => { console.log('即将进入 Login'); next(); } }
-
-
组件内守卫: 是指在组件内执行的钩子函数,类似于组件内的生命周期,相当于为配置路由的组件添加的生命周期钩子函数
- beforeRouterEnter(to, from, next)
- beforeRouterUpfate(to, from, next)
- beforeRouterLeave(to, from, next)
-
-
应用场景
- 只有当用户已经登录并拥有某些权限时才能进入某些路由
- 一个由多个表单组成的向导,例如注册流程,用户只有在当前路由的组件中填写了满足的信息才可以导航到下一个路由
- 当用户未执行保存操作而试图离开导航时提醒用户
- 应用场景:在用户离开当前界面时询问
- 应用场景:验证用户登录过期
vue路由传参的形式
-
页面刷新数据不会丢失
<div class="exmaine" @click="insurance(2)">查看详情</div> methods: { insurance(id): { this.$router.push({ path: "/particulars/${id}" }) } } // 对应的路由配置 { path: "/particulars/:id", name: "particulars", component: particulars } // 另外页面获取参数如下 this.$route.params.id -
页面刷新数据会丢失(可以在路由的path里加参数,加上参数以后刷新页面数据就不会丢了)
// 通过路由属性中的name来确定匹配的路由 通过params来传递参数 methods: { insurance(id) { this.$router.push({ name: "particulars", params: { id: id } }) } } // 对应路由配置:注意这里不能使用:/id来传递参数了 因为组件中已经使用params来携带参数了 { path: "/particulars", name: "particulars", component: particulars } // 子组件中主要获取参数 this.$route.params.id -
使用path来匹配路由,然后通过query来传递参数
methods: { insurance(id) { this.$router.push({ path: "/particulars", qury: { id: id } }) } } { path: "/particulars", name: "particulars", components: "particulars" } this.$route.query.id -
应用场景
- 点击父组件
18. Vue SSR
SSR:服务端将 Vue 组件渲染为HTML字符串,并将 html 字符串直接发送到浏览器,最后将这些静态资源标记“激活”为客户端上完全可以可交互的应用程序。
优点:
- 更好的 SEO,由于搜索引擎爬虫工具可以直接查看完全渲染的页面
- 更快的内容到达时间,提高首屏渲染速度
缺点:
- 开发条件受限(服务端只执行 beforeCreated 和 created 生命周期函数,并且没有window丶DOM和BOM等)
- 涉及构建设置和部署的更多要求,需要处于 node server 的运行环境
- 更多的服务端负载
优点:(SPA缺点)
- 首屏渲染速度慢 来回次数多 内容到达时间长
- SEO不友好 搜索引擎爬虫不友好
VUe模板 解析html 查库等异步操作
- 开发条件受限 不执行Mounted生命周期的钩子函数 第三方库不能使用
- 构建部署要求多 nodejs渲染
- 服务端负载变大
预渲染 几个广告页面 没有动态页面 非常在于SEO 静态 应用程序
传统的web渲染技术 asp.net php jsp
cli3
渲染器 vue-server-render
nodejs 服务器 express
ssr>npm i vue-server-render express -D
入口:app.js
服务端入口:entry-server.js
客户端入口:entry-client.js
打包脚本 跨平台
19. MVVM
什么是 MVVM?
- MVVM 是 Model-View-ViewModel 的缩写,MVVM是一种设计思想。Model 层代表数据模型,也可以在Model 中定义数据修改和操作的业务逻辑;View 代表 UI 组件,它负责将数据模型转化成 UI 展示出来,ViewModel 是一个同步View和Model的对象。
- 在 MVVM 架构下,View 和 Model 之间并没有直接的联系,而是通过 ViewModel 进行交互,Model和ViewModel 之间的交互是双向的,因此View数据的变化会同步到 Model 中,而 Model 数据的变化也会立即反应到 View 上。
- ViewModel 通过双向数据绑定把 View 层和 Model 层连接了起来,而 View 和 Model 之间的同步工作完全是自动的,无需人为干涉,因此开发者只需要关注业务逻辑,不需要手动操作 DOM,不需要关注数据状态的同步问题,复杂的数据状态维护完全有 MVVM 来统一管理。
MVVM 和 MVC 区别?
- MVC和MVVM其实区别不大。都是一种设计思想。主要是 MVC 中的 Controller 演变成 MVVM 中的viewModel。
- MVVM 主要是解决了 MVC 中大量的 DOM 操作使页面性能降低,加载速度变慢,影响用户体验。和当 Model 频繁发生变化,开发者需要主动更新到 View。
20. Vue 优点
Vue两大特点:响应式编程丶组件化
- 轻量级框架: 只关注视图层,是一个构建数据的视图集合,大小只有几十 KB
- 简单易学: 国人开发,中文文档,不存在语言障碍,易于理解和学习
- 双向数据绑定: 保留了 angular 的特点,在数据操作方面更加简单
- 组件化:
- 保留了 react 的优点,实现了 html 的封装和重用,在构建单页面应用方面有着独特的优势。
- 优点是:提高开发效率丶方便重复使用丶简化调试步骤丶提高整个项目的可维护性丶便于协同开发。
- 视图丶数据丶结构分离: 使数据的更改更为简单,不需要进行逻辑代码的修改,只需要操作数据就能完成相关操作
- 虚拟DOM: dom 操作是非常耗费性能的,不再使用原生的 dom 操作结点,极大解放 dom 操作,更具体操作还是dom,只不过换了一种方式
- 运行速度赶快:
- 相比较与 react 而言,同样是操作虚拟 DOM,就性能而言,Vue 存在很大的优势
- Vue 是单页面应用,使页面局部刷新,不用每次跳转页面都要请求所有数据 和 dom,这样大大加快了访问速度和提高用户体验。而且它第三方 UI 库很多,节省开发时间。
21. Vue 常用修饰符
.prevent: 提交事件不再重载页面.stop: 阻止单击冒泡事件.capture: 事件监听 事件发生的时候会调用.self: 当事情发生在该元素本身而不是子元素的时候会触发.number: 将用户的输入转为成数值类型.once: 只会触发一次
v-on可以监听多个方法吗????
可以???
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<input type="text" @input = "onInput" @focus ="onFucus" @blur ="onBlur">
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>
<script>
new Vue({
el: "input",
methods: {
onInput: function () {
console.log(1);
},
onBlur: function () {
console.log(2);
},
onFucus: function() {
console.log(3);
}
},
})
</script>
</body>
</html>
22. Vue 事件中如何使用 event 对象?
-
如果是函数的形式的,直接给个形参
<div id="app"> <button v-on:click="click">click me</button> </div> ... var app = new Vue({ el: '#app', methods: { click(event) { console.log(typeof event); // object } } }); -
如果是函数执行的形式,需要传入一个参数
$event<div id="app"> <button v-on:click="click($event, 233)">click me</button> </div> ... var app = new Vue({ el: '#app', methods: { click(event, val) { console.log(typeof event); // object } } });
23. Vue 中如何编写可复用的组件?
- 高内聚,低耦合
- 单一职责
- 组件分类
- 通用组件(可复用组件)
- 业务组件 (一次性组件)
- 可复用组件尽量减少对外部条件的依赖,所有与 Vuex 相关的操作都不应该在可复用组件中出现
- 组件应当避免对父组件的依赖,不要通过 this. p a r e n t 来操作父组件的示例,父组件也不要通过 t h i s . parent 来操作父组件的示例,父组件也不要通过 this. parent来操作父组件的示例,父组件也不要通过this.children 来引用子组件的示例,而是通过子组件的接口与之交互
???
https://www.jianshu.com/p/79a37137e45d
24. Vue 插槽
使用场景:
- 父组件向子组件传递 DOM 节点
- “固定部分+动态部分”的组件的使用场景
单个插槽 | 默认插槽 | 匿名插槽
-
特点:不用设置 name 属性
-
源码实现
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> </head> <body> <div id="app"> <h1>我是父组件的标题</h1> <my-home> <p>这是一些初始内容</p> <p>这是更多的初始内容</p> </my-home> </div> <script> Vue.component('my-home', { data: function() { return { count: 0 } }, template: `<div><h2>我是子组件的标题</h2><slot>只有在没有要分发的内容时才会显示。</slot></div>` }) new Vue({ el: "#app" }) </script> </body> </html>
具名插槽
- 特点:有 name 属性,具名属性可以在一个组件
中出现多次,出现在不同的位置 - 源码实现
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>
</head>
<body>
<div id="app">
<app-layout>
<h1 slot="header">这里可能是一个页面标题</h1>
<p>主要内容的一个段落</p>
<p>另一个主要段落</p>
<p slot="footer">这里有一些联系信息</p>
</app-layout>
</div>
<script>
// 具名插槽
Vue.component('app-layout', {
template: `<div class="container">
<header>
<slot name="header">头</slot>
</header>
<main>
<slot></slot>
</main>
<footer>
<slot name="footer">尾巴</slot>
</footer>
</div>`
})
new Vue({
el: "#app"
})
</script>
</body>
</html>
作用域插槽
- 特点:在 slot 上绑定数据,可从子组件获取数据的可复用的插槽
- 应用场景:封装一个列表组件(或者类似列表的组件)因为在真正使用场景下,子组件的数据都是来自父组件的,作为组件内部应该保持纯净,就像 element-ui 里的 table 组件,肯定不会定义一些数据在组件内部,然后传递给你,table 组件的数据都是来自调用者,然后 table 会把每一行的 row,在开发者需要时,传递出去
- 源码实现:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>
</head>
<body>
<div id="app">
<child>
<template slot-scope="user">
<div class="tmp">
<span v-for="item in user.data">{{ item }}</span>
</div>
</template>
</child>
</div>
<script>
Vue.component('child', {
data: function() {
return {
data: ['haha', 'hihi', 'hehe']
}
},
template: `<div class="child">
<slot :data="data"></slot>
</div>`
})
new Vue({
el: "#app"
})
</script>
</body>
</html>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>
</head>
<body>
<div id="app">
<todo-list :todos="todos">
<template slot-scope="slotProps">
<span v-if="slotProps.todo.isComplete">✓</span>
<span>{{ slotProps.todo.text }}</span>
</template>
</todo-list>
</div>
<script>
Vue.component('todoList', {
props: {
todos: {
type: Array
}
},
template: `<ul>
<li v-for="todo in todos" :key="todo.id">
<slot :todo="todo"></slot>
</li>
</ul>`
})
new Vue({
el: "#app",
data() {
return {
todos: [
{
id: 0,
text: 'haha0',
isComplete: false
},
{
text: 'haha1',
id: 1,
isComplete: true
},
{
text: 'haha2',
id: 2,
isComplete: false
},
{
text: 'haha3',
id: 3,
isComplete: false
}
]
}
}
})
</script>
</body>
</html>
动态插槽名
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>
</head>
<body>
<div id="app">
<base-layout>
<template v-slot:[dyname]>
This is Me.
</template>
</base-layout>
</div>
<script>
Vue.component('base-layout', {
template: `<div>
<header style="font-size: 20rpx">
<slot name="header"></slot>
</header>
</div>`
})
new Vue({
el: "#app",
data: {
dyname: 'header'
}
})
</script>
</body>
</html>
25. 说说你对 SPA 单页面的理解,它的优缺点是什么?
SPA(single-page application)单页面仅在Web页面初始化时加载相应的 HTML丶JavaScript 和 CSS。一旦页面加载完成,单页面不会因为用户的操作而进行页面的重新加载或跳转;取而代之的是利用路由机制实现 HTML 内容的变换,UI 和 用户的交互,避免页面的重新加载。
优点:
- 用户体验好丶快,内容的改变不需要加载整个页面,避免了不必要的跳转和重新渲染
- 基于上面一点,SPA 相对于服务器的压力较小
- 前后端分离,架构清晰,前后端进行交互逻辑,后端负责数据处理
缺点:
- 初始加载耗时多: 为实现单页面Web应用功能及显示效果。需要在加载页面的时候将JavaScript丶CSS统一加,部分页面按需加载
- 前进后退路由管理: 由于单页面应用在一个页面中显示所有的内容,所以不能使用浏览器的前进后退功能,所有的页面切换需要自己建立堆栈管理
- SEO难度较大: 由于所有的内容都在一个页面中动态替换显示,所以在SEO上其有天然的弱势
26. Vue.js 中的 ajax 请求代码应该写在组件的 methods 中还是 vuex 的 action 中
如果请求来的数据不是被其他组件公用,仅仅在请求的组件内使用,就不要放入vuex的state里面
如果被其他地方复用,这个很大概率上是需要的,如果是需要的请将放入action里面,方便使用
27. Vue 单元测试
单元测试是什么?
- 为检测特定的目标是否符合标准而采用专用的工具或者方法进行验证,并最终得出特定结果
- 需要访问数据库的测试不是单元测试
- 需要访问网络的测试不是单元测试
- 需要访问文件系统的测试不是单元测试
为什么需要单元测试?
- 准确性:测试可以验证代码的正确性,在上线前做到心里有底
- 自动化:当然手工也可以测试,通过 console 可以打印出内部信息,但是这是一次性的事情,下次测试还需要从头来过,效率不能得到保证。通过编写测试用例,可以做到一次编写,多次运行。
- 解释性:测试用例用于测试接口丶模块的重要性,那么在测试用例中就会涉及如何使用这些 API。其它开发人员如果要使用这些 API,那阅读测试用例是一种很好的途径,有时比文档说明更清晰。
- 驱动开发丶指导设计:代码被测试的前提是代码本身的可测试性,那么要保证代码的可测试性,就需要在开发中注意 API 的设计,TDD 将测试前移就是起到这么一个作用。
- 保证重构:互联网行业产品迭代速度很快,迭代必然存在代码重构的过程,那怎么才能保证重构后代码的的质量呢?有测试用例做后盾,就可以大胆的进行重构。
测试分类:
- 单元测试:关注应用中每个零件的正常运转,防止后续修改影响之前的组件
- 功能测试:确保其整体表现符合预期,关注能否让用户正常使用
- 整合测试:确保单独运行正常的零部件整合到一起之后依然能正常运行
单元测试的原则:
- 测试代码时,只考虑测试,不考虑内部实现
- 数据尽量模拟现实,越靠进现实越好
- 充分考虑数据的边界条件
- 对重点丶复杂丶核心代码,重点测试
- 利用AOP,减少测试代码数量,避免无用功能
- 测试丶功能开发相结合,有利于设计和代码重构
常用的测试工具:
-
Mocha:JavaScript的测试框架,类似于 Java 中 Junit
-
Chai:单元测试的验证框架
28. 如何设计一个通用组件?
- 要易用(至少让使用者能够简单方便的引入到程序当中)
- 要稳定(需要增加关键的测试)
- 要灵活(关键参数可配置)
- 要全面(日志丶拦截器丶监听器)
- 要谨慎(要考虑多种情况)
- 要易读(写的东西要能给别人讲清楚)
如何做?
- 如何做到易用,所谓中口难调,你觉得好用,其他人未必这样觉得。
29. Vue 如何防止引入外部 CSS 导致的全局污染
在它的 style 上加入 scope 属性
值得注意的是, Vue 的 scope 属性会导致该 style 不能覆盖 import 进来的 CSS 样式文件
30. 单页面和多页面的区别?
| 单页面应用(SPA) | 多页面应用(MPA) | |
|---|---|---|
| 结构 | 一个主页面 + 许多模块的组件 | 许多完整的页面 |
| 资源文件(CSS丶JS) | 组件公用的资源只需要加载一次 | 每个页面都要加载公用的资源 |
| 刷新方式 | 页面局部刷新 | 整页刷新 |
| url 模式 | a.com/#/page1 a.com/#/page2 hash和history都可使用 | a.com/page1.html a.com/page2.html |
| 用户体验 | 页面切换快丶体验佳;当初次加载文件过多时,需要做相关的调优 | 页面切换慢,网速慢得时候,体验尤其不好 |
| 转场动画 | 容易实现 | 无法实现 |
| 数据传递 | 容易 | 依赖 url 传参丶或者 cookie丶localStorage等 |
| 搜索引擎优化(SEO) | 需要单独方案丶实现较为困难丶不利于SEO检索 可用服务器渲染(SSR)优化 | 实现方法简易 |
| 适用范围 | 高要求的体验度丶追求界面流畅的应用 | 适用于追求高度支持搜索引擎的应用 |
| 开发成本 | 较高,常需要借助专业的框架 | 较低,但页面重复代码多 |
| 维护成本 | 相对容易 | 相对复杂 |
31. Vue 中的 computed 实现原理
-
每个 computed 属性都会生成对应的观察者(Watcher 实例),观察者存在 value 属性和 get 方法。computed 属性的 getter 函数会在 get 方法中调用,并将返回值赋值给 value。初始时设置 dirty 和 lazy 的值为 true。lazy 为 true 不会立即执行 get 方法,而是会在读取 computed 值时执行。
function initComputed(vm, computed) { var watchers = vm._computedWatchers = Object.create(null); // 存放 computed 的观察者 var isSSR = isServerRendering(); for(var key in computed) { var userDef = computed[key]; var getter = typeof userDef === "function" ? userDef : userDef.get; // ... watchers[key] = new Watcher( // 生成观察者(Watcher 实例) vm, getter || noop, // getter 将在观察者 get 方法中执行 noop, computedWatcherOptions // { lazy: true } 懒加载,暂不执行 get 方法,当读取 computed 属性值执行 ) // ... defineComputed(vm, key, userDef); } } -
将 compted 属性添加到组件实例上,并通过 get丶set 方法获取或者设置属性值,并且重定义 getter 函数、
function defineCompted(target, key, userDef) { var shouldCache != isServerRendering(); // ... sharedPropertyDefinition.shouldCache ? createComputedGetter(key) : createGetterInvoker(userDef); // ... Object.defineProperty(target, key, sharedPropertyDefinition); // 将 computed 属性添加到组件实例上 }// 重定义的 getter 函数 function createComputedGetter(key) { return function computedGetter() { var watcher = this._computedWatchers && this.computedWatchers[key]; if(watcher) { // true 懒加载 watcher.evaluate(); // 执行 watcher 方法后设置 dirty 为 false } if(Dep.target) { watcher.depend(); } return watch.value; // 返回观察者的 value 值 } } -
页面初始渲染时,读取 computed 属性值,触发定义后的 getter 属性。由于观察者的 dirty 值为 true,将会调用 get 方法,执行原始 getter 函数。getter 函数中读取 data (响应式)数据,读取数据时会触发 data 的 getter 方法,会将 computed 属性对应的观察者添加到 data 的依赖收集器中(用于 data 变更时通知更新)。观察者的 get 方法执行完成后,更新观察者的 value 值,并将 dirty 设置为 false,表示 value 值已更新,之后在执行观察者的 depend 方法,将上层观察者(该观察者含页面更新的方法,方法中读取了 computed 属性值)也添加到 getter 函数中 data 的依赖收集器中(getter 中的 data 的依赖收集器包含 computed 对应的观察者,以及包含页面更新方法(调用了 computed 属性)的观察者),最后返回 computed 观察者的 value 值。
-
当更改了 computed 属性的 getter 函数依赖的 data 值时,将会根据之前依赖收集的观察者,依次调用观察者的 update 方法,先调用 computed 观察者的 update 方法,由于设置观察者的 dirty 为 true,表示 computed 属性 getter 函数依赖的 data 值发生变化,但不调用观察者的 get 方法更新 value 值。再调用包含页面更新方法的观察者的 update 方法,在更新页面时读取 computed 属性值,触发重定义的 getter 函数,此时由于 computed 属性的观察者 dirty 为 true,调用该观察者的 get 方法,更新 value 值,并返回,完成页面的渲染。
-
dirty 值初始为 true,即首次读取 computed 属性值时,根据 setter 计算属性值,并保存在观察者 value 上,然后设置 dirty 值为 false。之后读取 computed 属性值时,dirty 值为 false,不调用 setter 重新计算值,而是直接返回观察者的 value,也就是上一次计算值。只有当 computed 属性 setter 函数依赖的 data 发生变化时,才设置 dirty 为 true,即下一次读取 computed 函数值调用 setter 重新计算。也就是说,computed 属性依赖的 data 不发生变化时,不会调用 setter 函数重新计算值,而是读取上一次计算值。


总结:
- 当组件初始化的时候,computed 和 data 会分别建立各自的响应系统,Observe 遍历 data 中每个属性设置 get/set 数据拦截
- 初始化 computed 会调用 initComputed 函数
- 注册一个 watcher 实例,并在内实例化一个 Dep 消息订阅器用作后续收集依赖(比如渲染函数的 watcher 或者其它观察该计算属性的 watcher)
- 调用计算属性时会触发器 Object.defineProperty 的 get 访问器函数
- 调用 watch.depend() 方法向自身的消息订阅器 dep 的 subs 中添加其它属性的 watcher
- 调用 watcher 的 evaluate 方法(进而调用 watcher 的 get 方法)让自身成为其它 watcher 的消息订阅器的订阅者,首先把 watcher 赋给 Dep.target,然后执行 getter 求值函数,当访问求值函数里面的属性(比如来自 data丶props 或 其它 computed)时,会同样触发它们的 get 访问器函数从而把该计算属性的 watcher 添加到求值函数中的属性 watcher 的消息订阅器 dep 中,当这些操作完成,最后关闭 Dep.target 赋为 null 并返回求值函数结果
- 当某个属性发生变化,触发 set 拦截函数,然后调用自身消息订阅器 dep 的 notify 方法,遍历当前 dep 中保存所有订阅者 watcher 的 subs 数组,并逐个调用 watcher 的 update 方法,完成响应更新
computed 计算值为什么还可以依赖另外一个 computed 计算值
其中的原理是,加入计算属性 A 依赖计算属性 B,而计算属性 B 又依赖响应式数据 C,那么最一开始先把计算属性 AB 都转化为 watcher,然后再把计算属性 AB 挂载到 vm 上面的时候,插入了一段 getter,而计算属性 B 的这个 getter 在这个计算属性 B 被读取的时候会把计算属性 A 的 watcher 添加到响应式数据 C 的依赖里面,所以响应式数据 C 在改变的时候会先后导致计算属性 B 和 A 执行 update,从而发生改变。
而其中关键的那段代码就是这段:
function createComputedGetter(key) {
return function computedGetter() {
const watcher = vm.computedWatchers[key];
if(watcher) {
if(watch.dirty) {
watcher.evaluate();
}
// 这里非常关键
if(Dep.target) {
watcher.depend();
}
return watcher.value;
}
}
}
为什么在计算属性 B 的 getter 函数里面会添加计算属性 A 的 watcher呢?这是因为计算属性 B 在求值成功完成后,会自动把 Dep.target 出栈,从而暴露出计算属性 A 的 watcher。代码如下:
class Watcher {
get() {
// 这里把自己的 watcher 入栈
pushTarget(this);
const value = this.getter();
// 这里把自己的 watcher 出栈
popTarget(this);
this.deps = [...this.newDeps];
this.newDeps = [];
return value;
}
}
这就是 pushTarget 和 popTarget 调度 watchers 的魅力之处
需要注意的点:
- 在计算属性生成 getter 的时候,不能直接使用 Object.defineProperty,而是使用闭包把 key 值存储了起来
- 为什么不直接使用 defineReative 把计算属性变成响应式的。因为当把计算属性用setter 挂载到 vm 上面的时候,计算属性这里确实变成了一个具体的值,但是如果使用 defineReative 把计算属性变成响应式的话,计算属性会执行自己的依赖,从而和响应式数据的依赖重复了。其实这也是把非数据变成响应式的的一种方法。
32. Vue 中的 watch 实现原理

简述响应式
Vue 会把数据设置响应式,即是设置它的 get 和 set
当数据被读取,get 被触发,然后收集读取它的东西,保存到依赖收集器
当数据被更新,set 被触发,然后通知曾经读取它的东西进行更新
监听的数据改变的时候,watch 如何工作
watch 在一开始的时候,会读取一遍监听的数据的值,于是,此时那个数据就收集到 watch 的 watcher 了
然后你给 watch 设置的 handler,watch 会被放入 watcher 的更新函数中
当数据改变时,通知 watch 的 watcher 进行更新,于是你设置的 handler 就被调用了
设置 immediate,watch 如何工作
当你设置了 immediate 时,就不需要在数据改变的时候才会触发
而是在初始化 watch 时,在读取了监听的数据的值之后,便立即调用一遍你设置的监听回调,然后传入刚读取的值
设置了 deep,watch 如何工作
我们都知道 watch 有一个 deep 选项,是用来深度监听的。什么是深度监听呢?就是当你监听的属性的值是一个对象的时候,如果你没有设置深度监听,当对象内部变化时,你监听的回调是不会被触发的。
在说明这个之前,请大家先了解一下
当你使用 Object.defineProperty 给值是对象的属性设置 set 和 get 的时候
- 如果你直接改变或读取这个属性(直接赋值),可以触发这个属性的设置的 set 和 get
- 如果你改变或读取它内部的属性,get 和 set 不会被触发的
举个例子
var inner = { first: 111 };
var test = { name: inner };
Object.defineProperty(test, "name" {
get() {
console.log("name get被触发");
return inner;
},
set() {
console.log("name set被触发")
}
})
// 访问 test.name 第一次,触发 name 的 get
Object.defineProperty(test.name, "first", {
get() {
return console.log("first get被触发");
},
set() {
console.log("first set被触发");
}
})
var a = test.name;
var b = a.first;
b = a.first;
a.first = 5;
被看到除了有两次需要访问到 name,必不可少会触发到 name 的 get
之后,当我们独立访问 name 内容的 first 的时,只会触发 first 的 get 函数,而 name 设置的 get 并不会被触发
结论
看了上面的例子后,所以当你的 data 属性值是对象,比如下面的 info
data() {
return {
info: { name: 1 }
}
}
此时,Vue 在设置响应式数据的时候,遇到值是对象,会递归遍历,把对象内所有的属性都设置为响应式,就是每个属性都设置 get 和 set,于是每个属性都有自己的一个依赖收集器
首先,再次说明,watch 初始化的时候,会先读取一遍监听数据的值
没有设置 deep
因为读取了监听的 data 的属性,watch 的 watcher 会收集在这个属性的收集器中
设置了 deep
- 因为读取了监听 data 的属性,watch 的 watcher 被收集在这个属性的收集器中
- 在读取 data 属性的时候,发现设置了 deep 而且值是一个对象,回遍历递归这个值,把内部所有属性逐个读取一遍,于是属性和它的对象值内每一个属性都会收集到 watch 的 watcher
于是,无论对象嵌套多深的属性,只要改变了,会通知相应的 watch 的 watcher 会更新,于是你设置的 watch 回调就被触发了
实际证明
证明 watch 的 watcher 深度监听时是否被内部每个属性都收集
我在 Vue 内部给 watch 的 watcher 加了一个属性,标识它是 watch 的 watcher,并且去掉了多余的属性,为了截图短一点
于是我们能看到,parentName 以及 parentName 内部的属性 a 都收集了 watch 的 watcher,以此类推,就算嵌套再深,设置深度监听就可以触发回调了。
33. vue和react谈谈区别和选型考虑
相同
- 使用 Virtual DOM
- 提供了响应式和组件化的视图组件
- 将注意力集中保持在核心库,伴随于此,有配套
不同
-
性能:到目前为止,针对现实情况的测试中,Vue 的性能是优于 React的
-
选型:
- 如果你希望用(或希望能够用)模板搭建应用,请使用 Vue
- 如果你喜欢简单和能用就行的东西,请使用 Vue
- 如果你的应用需要尽可能的小和快,请使用 Vue
- 如果你计划构建一个大型应用程序,请使用 React
- 如果你想要一个同时适用于 Web 端和原生 App 的框架,请选择 React
- 如果你需要最大的生态圈,请使用 React
34. Vue 的数据为什么频繁变化但只会更新一次
Vue 在更新 DOM 时是异步执行的,只要侦听到数据变化,Vue 将开启有个队列,并缓存在同一个事件循环中发生的所有数据变更。
如果同一个 watcher 被多次触发,只会被推入到队列中一次。这种在缓冲时去除重复数据对于避免不必要的计算和 DOM 操作是非常是要的。
然后,在下一个事件循环 tick 中,Vue 刷新队列并执行实际(已去重的)工作。Vue 在内部对异步队列尝试原生的 Promise.then,MutationObserver 和 setTimmediate,如果执行环境不支持,则会采用 setTimeout(fn, 0) 代替。
35. Vue 如何实现多个路由共用一个页面组件
多个页面共用同一个组件
当多个路由共用同一个组件时,切换路由不会触发该组件页面的钩子函数。为了重新触发钩子函数,获取最新数据,有两种方式:
- 假如父组件下的两个子组件 A丶B需要共用同一个组件,在父组件中,router-view 中添加 key,并保证 key 值具有类似 ID 值得唯一性。这样就能实现,进行相应的子组件路由,会根据相应的 key 值触发相应子组件
- 通过监听路由的变化,来处理数据
在 router-veiw 里添加 key 控制
这里的弊端是如果 router-veiw 里包含其它组件,切换其它组件会让其它组件也重新渲染
这里的问题是导致切换路由会闪烁一下,因为切换路由后所有的钩子函数都会重新触发了
// app.vue
<router-view :key="key" /> // 必须加上 key 属性,让每次进入路由时重新触发钩子函数
computed: {
key() {
// 只要保证 key 唯一性就可以,保证不同页面的 key 不相同
console.log(this.$route.fullPath);
return this.$route.fullPath
}
}
// 在 index.js 文件中,让多个路由共用同一个组件,路径指向同一个组件,保证路由 path 和 name 属性具有唯一性
{
path: '/role',
name: "role", // 角色
meta: {
requireAuth: true // 表示该路由需要登录验证后才能进入,在切换路径跳转路由之前作判断
},
component: () => import("@/view/policy/policy.vue")
},
{
path: "/strategy",
name: "strategy",
meta: {
requireAuth: true // 表示该路由需要验证后才能进入 在切换路径跳转之前作判断
},
component: () => import("@/veiws/policy/policy.vue")
}
通过监听路由的方法来重新触发钩子函数
通过监听路由的变化,来重写初始数据
watch: {
$route: {
handler: "resetData"
}
}
method: {
resetData: {
if(this.$route.fullPath === '/strategy') {
// 在这里获取并处理该路由下所需要的数据
}
}
}
36. React 和 Vue 更新机制的区别
获取数据更新的手段和更新颗粒度不一样
- Vue 通过依赖收集,当数据更新时,Vue 明确地知道是哪些数据更新了,每个组件都有自己的渲染 watcher,掌管当前组件的视图更新,所以可以精确地更新对应地组件,所以更新地粒度是组件级别地
- React 会递归地把所有的子组件 re–render 一下,不管是不是更新的数据,此时都是新的。然后通过 diff 算法来决定更新哪部分的视图,所以 React 的更新粒度是预估整体
对更新数据是否需要渲染页面的处理不一样
- 只有依赖收集的数据发生更新,Vue 才回去重新渲染页面
- 只要数据有更新(setData丶useState 等手段触发更新),都会去重新渲染页面(可以使用 shouldComponentUpdate / PureComponent 改善)
37. 数据绑定与数据流
单向数据绑定 vs 双向数据绑定
所谓数据绑定,就是指 View 层和 Model 层之间的映射关系
单向数据绑定:Model 的更新会触发 View 的更新,而 View 的更新不会触发 Model 的更新,它们的作用是单向的
双向数据绑定:Model 的更新会触发 View 的更新,View 的更新也会触发 Model 的更新,它们的作用是相互的
React 采用单向数据绑定
当用户访问 View 时,通过触发 Event 进行交互,而在相应 Event Handers 中,会触发相应的 Actions,而 Actions 方法对 View 的 State 进行更新,State 更新后会触发 View 的重新渲染
可以看出,在 React 中,View 层是不能直接修改 State,必须通过相应的 Actions 来进行操作
单向数据绑定的优缺点:
优点:所有状态都可以被记录的、跟踪,状态变化通过手动调用触发,源头易追踪
缺点:会有很多类似的样板代码,代码量会相应的上升
Vue 支持单向数据绑定和双向数据绑定:
- 单向数据绑定:使用 v-bind 属性绑定、v-on 事件绑定或插值形式 {{data}}
- 双向数据绑定:使用 v-model 指令,用户对 View 的更改会直接同步到 Model
Vue 的双向数据绑定就是指使用 v-model 指令进行数据绑定,而 v-model 本质上是 v-bind 和 v-on 相组合的语法糖,是框架自动帮助我们实现了更新事件,我们完全可以采取单向数据绑定,自己实现类似的双向数据绑定
双向数据绑定的优缺点:
优点:在操作表单时使用 v-model 方便简单,可以节省繁琐或重复的 onChange 事件去处理每个表单数据的变化(减少代码量)
缺点:属于暗箱操作,无法更好的跟踪双向绑定的数据的变化
单向数据流 VS 双向数据流
所谓数据流,就是指的是组件之间的数据流动
React、Vue 以及 Angular 都是单向数据流
虽然 Vue 和 Angular 有双向数据绑定,但 Vue 和 Angular 父子组件之间数据传递,仍然遵守单向数据流,即父组件可以向子组件传递 props,但是子组件不能修改父组件传递来的 props,子组件只能通过事件通知父组件进行数据更改。如下图:
优点:由于组件数据传递只有唯一的入口和出口,使得程序更直观、更容易理解,有利于程序的维护性
所谓双向数据流,就是在子组件中可以直接更新父组件的数据(angular 支持双向数据流)
缺点:由于组件数据变化的来源入口变得可能不止一个,如果缺乏相应的“管理”手段,容易将数据流转弄得絮乱。同时也会增加了出错时 debug 的难度
数据流与数据绑定
严格来说,数据流和数据绑定是两个概念,并不是同一个东西。单向数据流也可以支持双向数据绑定,双向数据绑定也可以支持单向数据绑定
简单总结一下前端三大框架的数据流与数据绑定的区别:
38. Vue.use 源码
Vue.use() 的作用
官方文档的解释:安装 Vue.js 插件,如果插件是一个对象,必须提供 install 方法。如果插件是一个函数,他会被作为 install 方法。install 方法调用时候,会将 Vue 作为参数传入。
Vue.use() 使用场景
可以在项目中使用 vue.use() 全局注入一个插件,从而不需要在每个组件中 import 插件。例如:不使用 vue.use() 注入插件
const utils = require('./utils');
// 或者
import utils from './utils'
使用 vue.use() 注入插件,最典型的案例:
import Vue from 'vue';
import Router from 'vue-router';
Vue.use(Router);
使用了 vue.use() 注册插件之后就可以在所有的 vue 文件中使用路由:this.$route
vue.use()源码
下面切入本文的主题,我们知道了 vue.use() 怎么用还不够
import { toArray } from '../util/index'
export function initUse(Vue: GlobalAPI) {
Vue.use = function(plugin: Function | Object) {
const installedPlugins = (this._installedPlugins || (this._installedPlugins = [])) {
if(installedPlugins.indexOf(plugin) > -1) {
return this;
}
// additional parameters
const args = toArray(arguments, 1) {
if(typeof plugins.install === 'function') {
plugin.install.apply(plugin, args);
}else if(typeof plugin === 'function') {
plugin.apply(null, args);
}
installedPlugins.push(plugin);
return this;
}
}
}
}
vue.use() 源码中采用了 flow 的语法。flow 语法,官方解释是:Flow is a static type checker for your JavaScript code. It does a lot of work to make you more productive.Making you code faster.Marking you code faster, smarter, more confidently, and to a bigger scale
简单的意思就是 flow 是 JavaScript 代码的静态类型检查工具
使用 flow 的好处就是:在编译期对 JS 代码变量做类型检查,缩短调试时间,减少因类型错误引起的 bug。我们都知道 JS 是解释执行语言,运行的时候才检查变量的类型,flow 可以在编译阶段就对 JS 进行类型检查
下面将对 vue.use() 源码进行解读:
-
首先先判断插件 plugin 是否是对象或者函数
vue.use = function (plugin: Function | Object); -
判断 vue 是否已经注册过这个插件
installedPlugin.indexOf(plugin) > -1;如果已经注册过,跳出方法
-
取 vue.use 参数
const args = toArray(arguments, 1); -
toArray() 取参数
export function toArray (list: any, start ?: number): Array<any> { start = start || 0; let i = list.length - start; const res: Array<any> = new Array(i); while(i --) { ret[i] = list[i + start] } return ret; }let i = list.length - start 意思是 vue.use() 方法传入的参数,除了第一个参数外(第一个参数是插件 plugin),其它参数都存储到一个数组中,并且将 vue 对象插入到参数数组的第一位。最后参数数组就是[vue, arg1, arg2, …]
-
判断插件是否有 install 方法,如果有就执行 install() 方法。没有就直接把 plugin 当 install 执行
if(typeof plugin.install === 'function') { plugin.install.apply(plugin, args); }else if(typeof plugin === 'function') { plugin.apply(null, args); }plugin.install.apply(plugin, args) 将 install 方法绑定在 plugin 环境中执行,并且传入 args 参数数组进 install 方法。此时 install 方法内的 this 指向 plugin 对象
plugin.apply(null, args) plugin 内的 this 指向 null
最后告知 vue 该插件已经注册过 installedPlugins.psh(plugin) 保证每个插件只会注册一次
总结
使用 vue.use() 注册插件,插件可以是一个函数,可以是一个带有 install 属性的对象。不管是函数还是 install 方法,第一个参数总是 vue 对象
个人还是喜欢使用将插件的功能方法写在 install 方法里。因为 install 内的 this 指向的是 plugin 对象自身,拓展性更好
39. 数据更新了但是页面没有更新
1. Vue 无法检测实例被创建时不存在于 data 中的 property
原因:由于 Vue 会在初始化实例时对 property 执行 getter/setter 转化,所以 property 必须在 data 对象上存在才能让 Vue 将它转化为响应式的
场景:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue@2.6.14/dist/vue.js"></script>
</head>
<body>
<div id="app">
{{ message }}
</div>
<script>
var app = new Vue({
el: '#app'
})
app.message = '111!' // `vm.message` 不是响应式的
</script>
</body>
</html>
解决方法:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue@2.6.14/dist/vue.js"></script>
</head>
<body>
<div id="app">
{{ message }}
</div>
<script>
var app = new Vue({
el: '#app',
data: {
message: 222
} // 声明为空字符串
})
app.message = '111!'
</script>
</body>
</html>
2. Vue 无法检测对象 property 的添加或移除
原因:官方由于 JavaScript(ES5)的限制,Vue.js 不能检测到对象属性的添加或删除。因为 Vue.js 在初始化实例时将属性转化为 getter/setter,所以属性必须在 data 对象上才能让 Vue.js 转换它,才能让它是响应式的。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue@2.6.14/dist/vue.js"></script>
</head>
<body>
<div id="app">
{{obj.id}}
</div>
<script>
var app = new Vue({
el: '#app',
data: {
obj : {
id: 0001
}
}
})
delete app.obj.id; // 不是响应式的
</script>
</body>
</html>
解决方案:
// 动态添加 - Vue.set
Vue.set(vm.obj, propertyName, newVal);
// 动态添加 - app.$set
app.$set(app.obj, id, 222);
// 动态添加多个
// 代替 Object.assign(this.obj {a: 1, b: 2 });
app.obj = Object.assign({}, app.obj, { a: 1, b: 2 });
// 动态移除 - Vue.delete
Vue.delete(vm.obj, propertName);
// 动态移除 - app.$delete
app.$delete(app.obj, propertName);
3. Vue 不能检测通过数组索引直接修改一个数组项
原因:官方 - 由于 JavaScript 的限制,Vue 不能检测数组和对象的变化;尤雨溪 - 性能获取和获取用户体验不成正比
场景:
var vm = new Vue({
data: {
items: ['a', 'b', 'c']
}
})
vm.items[1] = 'x'; // 不能是响应式的
解决方法:
// Vue.set
Vue.set(vm.items, indexOfItem, newVal);
// vm.$set
vm.$set(vm.items, indexOfItem, newValue);
// Array.prototype.splice
vm.items.splice(indexOfItem, 1, newValue)
拓展:Object.definedProperty() 可以检测数组的变化
Object.defineProperty()可以检测数组的变化,但对数组新增一个属性(index)不会监测到数据变化,因为无法咨询到新增数组的下标(index),删除一个属性(index)也是
场景:
var arr = [1, 2, 3, 4];
arr.forEach(function(item, index) {
Object.defineProperty(arr, index, {
set: function(value) {
console.log('触发 setter');
item = value;
},
get: function() {
console.log('触发 getter');
return item;
}
})
})
arr[1] = '123'; // 触发 setter
arr[1]; // 触发 getter 返回值为 '123'
arr[5] = 5; // 不会触发
4. Vue 不能监测直接修改数组长度的变化
原因:官方-由于 JavaScript 的限制,Vue 不能检测数组和对象的变化;尤雨溪-性能代价和获得用户体验不成正比
场景:
var vm = new Vue({
data: {
items: ['a', 'b', 'c']
}
})
vm.items.length = 2; // 不是响应式
解决方法:
vm.items.splice(newLength);
5. 在异步更新执行之前操作 DOM 数据不会变化
原因:Vue 在更新 DOM 时是异步执行的。只要监听到数据变化,Vue 将开启一个队列,并缓冲在同一个事件中发生的所有数据变更。如果同一个 watcher 被多次触发,只会被推入队列中一次。这种在缓冲中去除重复数据对于避免不必要的计算和 DOM 操作是非常重要的。然后,在下一个的事件循环“tick”中,Vue 刷新队列并执行实际(已去重的)工作。Vue 在内部在异步队列尝试使用原生的 Promise.then、MutationObserver 和 setImmediate,如果执行环境不支持,则会采用 setTimeout(fn, 0) 代替
场景:
<div id="example">{{ message }}</div>
var vm = new Vue({
el: "#example",
data: {
message: '123'
}
})
vm.messgae = "new message"; // 更改数据
vm.$el.textContent = 'new message'; // false
vm.$el.style.color = 'red'; // 页面没有变化
解决方法:
var vm = new Vue({
el: "#example",
data: {
message: '123'
}
})
vm.message = 'new message'; // 更改数据
// 使用 Vue.nextTick(call) callback 将在 DOM 更新完成后被调用
Vue.nextTick(function () {
vm.$el.textContent === 'new message'; // true
vm.$el.style.color = 'red'; // 文字颜色变成红色
})
拓展:异步更新带来的数据响应的误解
<!-- 页面显示:我更新啦! -->
<div id="example">{{ message.text }}</div>
var vm = new Vue({
el: "#example",
data: {
message: {}
}
})
vm.$nextTick(function() {
this.message = {};
this.message.text = '我要更新啦!';
})
上段代码中,我们在 data 对象中声明了一个 message 空对象,然后在下次 DOM 更新循环结束之后触发的异步回到中,执行了如下两段代码:
this.message = {};
this.message.text = '我更新啦';
到这里,模版更新了,页面最后会显示 我更新啦
模版更新了,应该具有响应式特性,如果这么想那么你就已经走入了误区。
一开始我们在 data 对象中只是声明了一个 message 空对象,并不具有 text 属性,所以该 text 属性是不具有响应式特性的
但模版切切实实已经更新了,这又是怎么回事呢?
那是因为 Vue.js 的 DOM 更新是异步的,即当 setter 操作发生后,指令不会立马更新,指令的更新操作会有一个延迟,当延迟更新真正执行的时候,此时 text 属性已经赋值,所以指令更新模版时得到的是新值
模版中每个指令/数据绑定都有一个对应的 watcher 对象,在计算过程中它把属性记录为依赖。之后当依赖的 setter 被调用时,会触发 watcher 重新计算,也就会导致它的关联指令更新 DOM
具体流程如下所示:
- 执行 this.message = {}; 时,setter 被调用
- Vue.js 追踪到 message 依赖的 setter 被调用后,会触发 watcher 重新计算
- this.message.text = ‘我要更新啦!’; 对 text 属性进行赋值
- 异步回调逻辑执行结束之后,就会导致它的关联指令更新 DOM ,指令更新开始执行
所以真正的触发模版更新的操作是 this.message = {}; 这句话引起的,因为触发了 setter,所以单看上述例子,具有响应式特性的数据只有 message 这一层,它的动态添加的属性是不具备的
对应上述第二点 - Vue 无法检测对象 property 的添加或移除
6. 循环嵌套层级太深,视图不更新
看到网上有些人说数据更新的层级太深,导致数据不更新或者更新缓慢从而导致视图不更新?
由于我没有遇到这种情况,在我试图重现这种场景的情况下,发现并没有上述情况的发生,所以对于这一点不进行过多的描述
针对这种情况有人给出的方案是使用强制更新:
如果你发现你自己需要在 Vue 中做一次强制更新,99.9% 的情况,是你在某个地方做错了事
vm.$forceUpdate();
拓展:路由参数变化时,页面不更新(数据不更新)
拓展一个因为路由参数变化,而导致页面不更新的问题,页面不更新本质上就是数据没有更新
原因:路由视图组件引用了相同组件时,当路由参会变化时,会导致组件无法更新,也就是我们常说中的页面无法更新的问题
场景:
<div id="app">
<ul>
<li><router-link to="/homr/foo">Too Foo</router-link></li>
<li><router-link to="/homr/foo">Too Foo</router-link></li>
<li><router-link to="/homr/foo">Too Foo</router-link></li>
</ul>
<router-view></router-view>
</div>
const Home = {
template: `<div>{{ message}} </div>`,
data() {
return {
message: this.$route.params.name
}
}
}
const router = new VueRouter({
mode: "history",
routes: [
{
path: '/home', component: Home
},
{
path: '/home/:name',
component: Home
}
]
})
new Vue({
el: "#app",
router
})
上段代码中,我们在路由构建选项 routes 中配置了一个动态路由 ‘/home/:name’,它们公用一个路由组件 Home,这代表它们复用 RouterView
当进行路由切换时,页面只会渲染第一次路由匹配到的参数,之后再进行路由切换时,message 是没有变化的
解决方法:
-
通过 watch 监听 $route 的变化
const Home = { template: `<div>{{ message }}</div>`, data() { return { message: this.$route.params.name } }, watch: { '$route': function() { this.message = this.$route.params.name } } } new Vue({ el: '#app', router }) -
给 绑定 key 属性,这样 Vue 就会认为这是不同的
弊端:如果从 /home 跳转到 /user 等其它路由下,我们是不用担心组件更新问题,所以这个时候 key 属性是多余的
<div id="app"> <router-view :key="key"></router-view> </div>
40. Vue 常用指令
v-once
默认情况下,Vue 事件是可以重复触发的,但是在特定的情况下,我们只想事件执行一次,所以就有了 v-once
<div id="app">
<input type="text" placeholder="请输入数据" v-model="name">
<p v-once>{{ name }} <span>我会进行一次渲染</span></p>
<p>{{ name }} <span>我会进行多次渲染</span></p>
</div>
<script>
new Vue({
el: "#app",
data:({
name:"张三",
})
})
</script>
v-cloak
vue 如果渲染的时候使用的是 {{data}} 进行渲染的话,在网络不好的情况,会显示 {{data}},这样子用户体验并不好,所以有了 b-cloak 这个指令
<style>
[v-cloak] {
/* v-cloak 必须配合这个style 进行隐藏 */
display: none;
}
</style>
<div id="app">
<p v-cloak>{{ name }} <span>如果网络差,我则不会显示</span></p>
<p>{{ name }} <span>无论网络状态如何 ,我都会显示</span></p>
</div>
<script src="vue.js"></script>
<script>
new Vue({
el: "#app",
data: ({
name: "张三",
})
})
</script>
v-text and v-html
V-text 等同于 innerText
v-html 等同于 innerHtml
<div id="app">
<!-- 数据插值 : 把数据插入到指定位置 ,并且不会覆盖原有的内容 -->
<p>{{name}}</p>
<p>+++++n{{name}}+++++</p>
<!-- 数据插值 : 不会解析HMTL标签 -->
<p>{{span}}</p>
<!-- v-text 直接渲染数据, 并且会覆盖原有的数据 -->
<p v-text="name"></p>
<p v-text="name">++++++++++</p>
<!-- v-text 不会渲染 HTML 标签 -->
<p v-text="span"></p>
<!-- v-html 会覆盖原有数据, 并且可以渲染数据和html标签 -->
<p v-html="name">+++++++++</p>
<p v-html="span">+++++++++</p>
</div>
<script>
new Vue({
el: "#app",
data: ({
name: "张三",
span: "<span> 我是span标签 </span>"
})
})
</script>
v-if and v-else-if and v-else
<div id="app">
<!-- v-if 如果为假, 则压根不会创建元素 -->
<input type="text" v-model="age">
<!-- v-if 会接收数据模型中的数据 , 判断是否是真 ,为真就显示 -->
<p v-if="show">我会显示</p>
<p v-if="hidden">我不会显示</p>
<p>------</p>
<!-- v-if 可以接收行内表达式 -->
<p v-if="age >= 18">成年人</p>
<p v-if="age < 18">未成年</p>
<!-- 也可以接收直接传值 -->
<p v-if="true">我会显示</p>
<p v-if="false">我会显示</p>
<!-- v-if 也可以搭配 v-else 和 v-else-if 进行使用 -->
<!-- v-else-if如果不需要, 也是可以省略的 , 但是需要主要注意的是 ,else必须紧跟if后面 -->
<input type="text" v-model="abc">
<p v-if="abc === 'a'">a</p>
<p v-else-if="abc === 'b'">b</p>
<p v-else-if="abc === 'c'">c</p>
<p v-else>not abc</p>
</div>
<script>
new Vue({
el: "#app",
data: ({
show: true,
hidden: false,
age: 18,
abc: "a"
})
})
</script>
v-show
<div id="app">
<!-- v-show 和 v-if 特性相同, 而不同之处则是它无论条件是否成立 ,都会创建元素, 控制display,而v-if则会动态创建元素与否 -->
<p v-show="show">我会显示</p>
<p v-show="hidden">我不会显示</p>
<p v-show="true">我会显示</p>
<p v-show="false">我不会显示</p>
<input type="text" v-model="age">
<p v-show="age >= 18">我会显示</p>
<p v-show="age < 18">我不会显示</p>
</div>
<script>
new Vue({
el: "#app",
data: ({
show: true,
hidden: false,
age: 18
})
})
</script>
v-model
<div id="app">
<input placeholder="请输入数据" type="text" v-model="name">
<p>{{ name }}</p>
</div>
<script>
new Vue({
el: "#app",
data: ({
name: "张三",
})
})
</script>
v-for
<div id="app">
<!-- 单属性 -->
<!-- <li v-for="value in list">{{value}}</li> -->
<ul>
<!-- 遍历数组 -->
<li v-for="(value,index) in listArr">{{index}}---{{value}}</li>
</ul>
<ul>
<!-- 遍历对象 -->
<li v-for="(value,key) in listObj">{{key}} --- {{value}}</li>
</ul>
<ul>
<!-- 遍历字符 -->
<li v-for="(value,index) in 'abcdefghijklmn'">{{index}}---{{value}}</li>
</ul>
<ul>
<!-- 遍历数字 -->
<li v-for="(value,index) in 10">{{index}}---{{value}}</li>
</ul>
</div>
<!-- v-for 相当于 js 中的 for in 循环 -->
<!-- v-for 可以循环遍历 数组 / 对象 / 字符 / 数字 -->
<script>
new Vue({
el: "#app",
data: ({
listArr: ["张三", "李四", "王五", "赵六"],
listObj: {
name: "张三",
age: "18",
sex: "男"
}
})
})
</script>
v-bind
<div id="app">
<!-- value 绑定 -->
<input type="text" v-bind:value="name">
<input :value="name" type="text">
<input :value="age + 10 " type="text">
</div>
<!-- v-bind 可以给元素的属性动态绑定数据 -->
<!-- v-bind 取值特点: 只要是一个合法的 js 表达式即可 -->
<!-- v-bind 可以简写为 : -->
<script>
new Vue({
el: "#app",
data: ({
name: "张三",
age: 18,
})
})
</script>
41. Flux、Vuex、MobX 和 Redux各自的特点和区别
Flux
Flux 是一种架构思想,类似于 MVC、MVVM 等
Flux 的组成
-
**View:**视图层
-
**Action:**动作,即数据改变的消息对象(可通过事件触发、测试用例触发等)
- Store 的改变只能通过 Action
- 具体 Action 的处理逻辑一般放在 Store 里
- Action 对象包含 type(类型)与 payload(传递参数)
-
**Dispatcher:**派发器,接受 Actions,发给所有的 Store
-
**Store:**数据层,存放应用状态与更新状态的方法,一旦发生变动,就提醒 View 更新页面
注意:Action 仅仅是改变 Store 的一个动作,一般包含该动作的类型、传递的数据
Flux 的特点:
- **单向数据流:**视图事件或者外部测试用例发出 Action,经由 Dispatcher 派发给 Store,Store 会触发相应的方法更新数据、更新视图
- Store 可以有多个
- Store 不仅存放数据,还封装了处理数据的方法
Redux
Redux 的组成
- **Store:**存储应用 state 以及用于触发 state 更新的 dispatch 方法等,整个应用仅有单一的 Store。Store 中提供了几个 API:
- **store.getState():**获取当前的 state
- **store.dispatch(action):**用于 view 发出 action
- **store.subscribe(listener):**设置监听函数,一旦 state 变化则执行该函数(若把视图更新函数作为 listener 传入,则可触发视图自动渲染)
- **Action:**同 Flux,Action 是用于更新 state 的消息对象,由 view 发出
- 有专门生成 Action 的 Action Creator
- **Reducer:**是同一个改变 state 的纯函数(对于相同的参数返回相同的返回结果,不修改参数,不依赖外部变量),即通过应用状态与 Action 推导出新的 state:(previousState, action) => newState。Reducer 返回一个新的 state
Redux 的特点
- **单向数据流:**View 发出 Action(store.dispatch(action)),Store 调用 Reducer 计算出新的 state,若 state 发生变化,则调用监听函数重新渲染 View(store.subscrible(render)
- 单一数据源,只有一个 Store
- State 是只读,每次状态更新之后只能返回一个新的 state
- 没有 Dispatcher,而是在 Store 中集成了 dispatch 方法,store.dispatch() 是 View 发出 Action 的唯一途径
Middleware
Middleware 即中间件,在 Redux 中应用于异步数据流
Redux 的 Middleware 是对 store.dispatch() 进行了封装之后的方法,可以使 dispatch 传递 action 以外的函数或者 promise;通过 applyMiddleware 方法应用中间件。(middleware 链中的最后一个 middleware 开始 dispatch action 时,这个 action 必须是一个普通对象)
常用库:redux-action、redux-thunk、redux-promise
const store = createStore(
reducer,
// 依次执行
applyMiddleware(thunk, promise, logger)
)
Vuex
Vuex 是 vue.js 的状态管理模式
Vuex 的核心概念
- **Store:**Vuex 采用单一状态树,每个应用仅有 Store 实例,在该实例下包含了 state、actions、mutations、getter、modules
- **State:**Vuex 为单一数据源
- 可以通过 mapState 辅助函数将 state 作为计算属性访问,或者将通过 Store 将 state 注入全局之后使用 this.$store.state 访问
- State 更新视图是通过 vue 的双向绑定机制实现的
- **Getter:**Getter 的作用与 filters 有一些相似,可以将 State 进行过滤后输出
- **Mutation:**Mutation 是 vex 中改变 State 的唯一途径(严格模式下),并且只能是同步操作。Vuex 中通过 store.commit() 调用 Mutation
- Action:一些对 State 的异步操作可以放在 Action 中,并通过在 Action 提交 Mutation 变更状态
- Action 通过 store.dispatch() 方法触发
- 可以通过 mapActions 辅助函数将 vue 组件的 methods 映射成 store.dispatch 调用(需要先在根节点注入 store)
- Module:当 Store 对象过于庞大时,可根据具体的业务需求分为多个 Module,每个 Module 都具有自己的 state、mutation、action、getter
Vuex 的特点:
- 单向数据流:View 通过 store.dispatch() 调用 Action,在 Action 执行完异步操作之后通过 store.commit() 调用 Mutation 更新 State,通过 vue 的响应式机制进行视图更新
- 单一数据源:和 Redux 一样全局只有一种 Store 实例
- 可直接对 State 进行修改
MobX
MobX 背后的哲学是:任何源自应用状态的东西都应该自动地获得
意思就是,当状态改变时,所有应用到状态的地方都会自动更新
MobX 的核心概念
- State:驱动应用的数据
- Computed values:计算值,如果你想创建一个基于当前状态的值时,请使用 computed
- Reactions:反应,用于改变 State
- 依赖收集(autoRun):MobX 中的数据以来基于观察者模式,通过 autoRun 方法添加观察者

举个例子:
const obj = observable({
a: 1,
b: 2
})
autoRun((obj) => {
console.log(obj.a);
})
obj.b = 3; // 什么都没有发生
obj.a = 2; // observe 函数的回调触发了 控制台输出:2
MobX 的特点:
- 数据流流动不自然,只有用到的数据才会引发绑定,局部精确更新(细粒度控制)
- 没有时间回溯能力,因为数据只有一份引用
- 基于面向对象
- 往往是多个 Store
- 代码侵入性小
- 简单可拓展
- 大型项目使用 MobX 会使得代码难以维护
总结:
- Flux、Redux、Vuex 均为单向数据流
- Redux 和 Vuex 是基于 Flux 的,Redux 较为泛用,Vuex 只能用于 vuex
- Flux 与 MobX 适用于大型项目的状态管理,MobX 在大型项目中应用会使代码可维护性变差
- Redux 中引入了中间件,主要解决异步带来的副作用,可通过约定完成许多复杂工作
- MobX 是状态管理库中代码倾入性最小的之一,具有颗粒度控制、简单可拓展等优势,但是没有时间回溯能力,一般适用于中小型项目中
42. React、Vue 和 JQuery在什么场景下怎么选型
Vue
1. 响应式
响应式的系统可谓相当方便,也就是基于是数据可变的,通过对每一个属性建立 watcher 来监听,当属性变化的生活,响应式的更新对应的虚拟 DOM,响应式的更新对应的虚拟 DOM。
2. 模版语法
在 vue 中,我们就像在写 HTML 一样自由畅快,这就得力于 vue 的模版预防
<p>{{ message }}</p>
首先我们说的 vue 的模版其实不 html,那么既然不是 html它一定是被转换成了一个 JS 代码,就是所谓的模版编译,在 vue 中使用的就是 vue-template-compiler 这个模版编译工具,那这个工具做了什么?其实就是将 Vue 2.0 模版预编译为渲染函数(template => ast => render)
//模板代码
const compiler = require('vue-template-compiler')
const result = compiler.compile(`
<div id="test">
<div>
<p>This is my vue render test</p>
</div>
<p>my name is {{myName}}</p>
</div>`
)
console.log(result)
{
//编译结果
ast: {
type: 1,
tag: 'div',
attrsList: [ [Object] ],
attrsMap: { id: 'test' },
rawAttrsMap: {},
parent: undefined,
children: [ [Object], [Object], [Object] ],
plain: false,
attrs: [ [Object] ],
static: false,
staticRoot: false
},
render: `with(this){return _c('div',{attrs:{"id":"test"}},[
_m(0), // 上述提到的静态子树,索引为0 <div><p>This is my vue render test</p></div>
_v(" "), // 空白节点 </div> <p> 之间的换行内容
_c('p',[_v("my name is "+_s(myName))]) // <p>my name is {{myName}}</p>
])}`,
staticRenderFns: [
`with(this){return _c('div',[_c('p',[_v("This is my vue render test")])])}`
],
errors: [],
tips: []
}
然后我们执行这个 render 函数,就会返回一个 vnode,接下来就是我们熟悉的 diff 算法到更新视图
3. 实现 MVVM
实现了 MVVM 我至少认为这是一个福音,用数据去驱动视图,简化繁琐的操作 DOM,更关注与业务逻辑,这样就能节省开发时间,何写出易于维护的代码,那么什么叫 MVVM 呢?
viewmodel ,在 vue 中 viewmodel 其实就是我们的方法,我们的事件等等,都是这一层,这一层的操作帮助改变数据或者改变视图,起到承上启下的作用,也实现了 vue 非常经典的数据双向绑定
4. 使用好友,上手简单
这是 vue 最为亮眼的有点,比起 react 的 jsx,比起 angular 的 rxjs、以及各种依赖注入,vue 的语法风格和使用 api 相当友好,社区也都有一些相对固定的方案,当然还有一点比较幸福的是 vue 的性能优化做得相当到位,不用我们手动优化,不用像 react 那样父组件更新 render 子组件也要跟新。
5. 弱化性能优化,用户只需关注逻辑
相比于 react 和 angular vue 在按照模版格式开发时就没有太多限制,得益于响应式系统,也不用去做相对应的性能优化,由于 vue 内部的模版语法,能在开发环境下编译,这样就能在编译的生活去做一些性能优化比如,在这段 vue 我们明确知道第二个 name 是变量这样在内部就会有针对性的优化
<template>
<ul>
<li>0</li>
<li>{{ name }}</li>
<li>2</li>
<li>3</li>
</ul>
</template>
而在 react 中,由于 jsx 的写法灵活,不确定性多,所以在编译时就无法去做性能优化,而性能优化放到开发者身上了
<ul>{
data.map((name, i) => <li>{i !== 1 ? i : name}</li>)
}</ul>
react
1. 不可变值的设计思想,也是函数式编程的实践
我们知道,在 react 中性能优化的权利交给了开发者,所以,在默认情况下
三大框架的联系:
1. 组件化
三大框架中,都是提倡组件开发的框架,所以当你在开发 vue 的项目时,具备组件化的思想,在平常开发中能够有意识的去抽离展示型组件和容器型组件,那么在开发 react 和 angular 时,你只会得心应手,不会处处为难。
2. 都是数据驱动视图
三大框架,都是属于 MVVM 框架,数据驱动视图的思想始终贯穿,所以我们在开发时,只需要关注数据变化即可,虽然使用方式不尽相同,react 属于函数式,angular 和 vue 属于声明式编程,但是数据驱动的思想不变,比如 react 使用 setState 赋值,而 vue 和 angular 使用显示直接赋值它们最后的目的都是改值,从而触发页面更新。
3. 共同的开发套路
在三大框架中,由于都遵循组件话思想,所以都有着相同的开发套路,只是使用方式略有差别,比如都有父子组件传递、都有父子组件传递、都有数据管理框架、都有前端路由、都有插槽,只不过在 angular 中叫做投影组件,在 react 中叫做组合,都能实现一些所谓的高阶函数。
区别
1. 模版 vs JSX
React 与 Vue、angular 最大的不同是模版的编写。Vue 和 angular 鼓励你写近似常规 HTML 的模版。写起来很接近标准 HTML 元素,只是多了一些属性。而 react 则崇尚 all in js 所以独创 jsx 的编写风格,但是它们本质上都是一个语法糖,编译之后都是一个可执行的函数
2. Virtual DOM VS Incremental DOM
在底层渲染方面,vue 和 react 都使用的虚拟 DOM,而 angular 却没有使用,它使用的是 incremental DOM
3. 函数式编程 声明式编程
在 react 不可变值贯穿整个框架,如果你要改变数据,那么必须调用 api 去改,这就是函数式编程的思想,而在 vue 和 angular 中,声明式编程的思想也深入人心,即方便有快捷。这种直接赋值的方式,和用 API 赋值的方式,其实只是用法不同而已,本质还是数据驱动。
4. 社区复杂度
在 angular 和 vue 中,几乎给你想要的全部给你了,而 react 追求的更多的是自力更生,所以有选择困难症的人才会如此的纠结
5. 入门难度
angular 工程化最好的框架,也是由于拥抱了 rxjs 和 ts
react 上手很比较简单,尤其是 16 引入 hooks 之后,号称 API 终结者,但是由于社区太过于活跃各种新东西层出不穷,中文文档晦涩难懂,导致相当于 vue 上手也有难度
vue 由于是中国人写的,有着完善的中文文档和稳定的社区,并且有着亲切的模版语法,应当说是入门是最简单的
…
点击下方链接获取全部内容文档及其答案:### 10W+前端面试题&面试资料&八股文题目及其答案
https://m.tb.cn/h.5a7v237?tk=QeVPdsoKwr4 CZ3457