【MATLAB第49期】基于MATLAB的深度学习ResNet-18网络不平衡图像数据分类识别模型
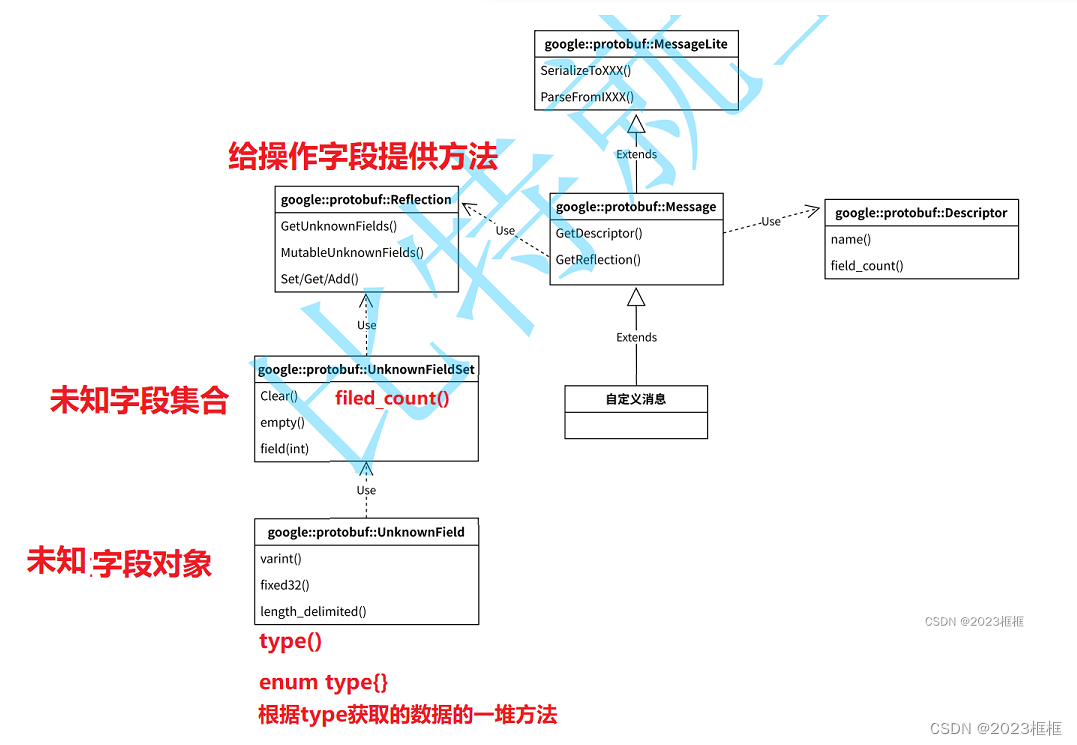
一、基本介绍
这篇文章展示了如何使用不平衡训练数据集对图像进行分类,其中每个类的图像数量在类之间不同。两种最流行的解决方案是down-sampling降采样和over-sampling过采样。
在降采样中,每个类别的图像数量减少到所有类别中的最小图像数量。降采样的实现很容易:只需使用splitEachLabel函数并指定类的最小数量,
另一方面,当执行过采样时,每个类别的图像数量增加。这两种策略对于不平衡的数据集都是有效的。然而,过采样需要更复杂的过程。
本篇文章采用过采样平衡数据 。
Label Count
_____________ _____
caesar_salad 13
caprese_salad 8
french_fries 91
greek_salad 12
hamburger 119
hot_dog 16
pizza 150
sashimi 20
sushi 62
过采样结果:
Label Count
_____________ _____
caesar_salad 150
caprese_salad 150
french_fries 150
greek_salad 150
hamburger 150
hot_dog 150
pizza 150
sashimi 150
sushi 150
二、数据情况
食品图像数据集包含九类食物的978张照片(ceaser_salad、caprese_salad,french_fries、greek_saland、汉堡包、hot_dog、披萨、生鱼片和寿司)。
数据集可在下列地址下载
https://www.mathworks.com/supportfiles/nnet/data/ExampleFoodImageDataset.zip
本文为了提高运行速度 ,选择80%训练, 10%验证,10%测试。


三、代码展示
1.导入数据
imds = imageDatastore('ExampleFoodImageDataset');
2.图像数据展示
numExample=16;
idx = randperm(numel(imds.Files),numExample);
for i=1:numExample
I=readimage(imds,idx(i));
I_tile{i}=insertText(I,[1,1],string(imds.Labels(idx(i))),'FontSize',20);
end
% use imtile function to tile out the example images
I_tile = imtile(I_tile);
figure()
imshow(I_tile);title('examples of the dataset')
3.数据集划分 (训练80%,验证10%,测试10%)
[imdsTrain, imdsValid,imdsTest]=splitEachLabel(imds,0.8,0.1,0.1);
4.选取最大样本数
PerClass是所有类中的最大样本数。
PerClass = max(numObservations);
5.平衡数据
randReplicateFiles是一个仅对文件进行混洗的支持功能。
要选择的图像数量由PerClass定义。从数据库中找到不同类别的图像目录,然后随机复制对应的图像至对应的数量,以平衡类中的图像数量。
files = splitapply(@(x){randReplicateFiles(x,desiredNumObservationsPerClass)},imdsTrain.Files,G);
6.构建网络
加载预先训练的模型,ResNet-18
net = resnet18;
inputSize = net.Layers(1).InputSize;
lgraph = layerGraph(net);
learnableLayer='fc1000';
classLayer='ClassificationLayer_predictions';
7.图像增强
定义图像增强器
pixelRange = [-30 30];
RotationRange = [-30 30];
scaleRange = [0.8 1.2];
imageAugmenter = imageDataAugmenter( ...
'RandXReflection',true, ...
'RandXTranslation',pixelRange, ...
'RandYTranslation',pixelRange, ...
'RandXScale',scaleRange, ...
'RandYScale',scaleRange, ...
'RandRotation',RotationRange ...
);

8.设置网络参数
miniBatchSize = 64;
valFrequency = max(floor(numel(augimdsTest.Files)/miniBatchSize)*10,1);
options = trainingOptions('sgdm', ...
'MiniBatchSize',miniBatchSize, ...
'MaxEpochs',5, ...%30
'InitialLearnRate',1e-2, ...%3e-4
'Shuffle','every-epoch', ...
'ValidationData',augimdsValid, ...
'ValidationFrequency',valFrequency, ...
'Verbose',false, ...
'Plots','training-progress');
9.训练网络
net = trainNetwork(augimdsTrain,lgraph,options);
10.分类评估
[YPred,probs] = classify(net,augimdsTest);
accuracy = mean(YPred == imdsTest.Labels)
YValidation = imdsTest.Labels;
YTrue=imdsTest.Labels;
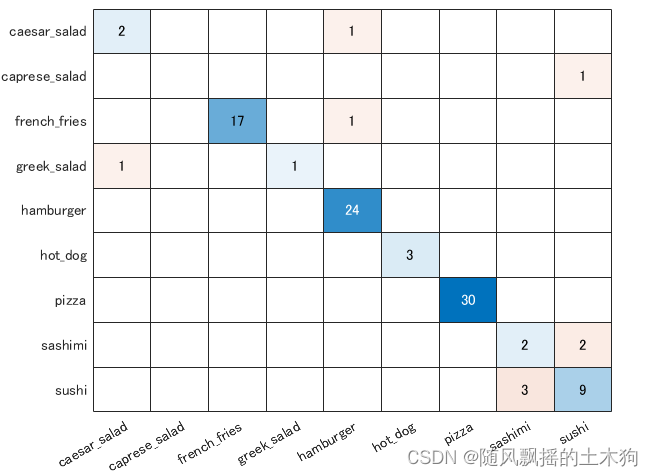
figure;cm=confusionchart(YTrue,YPred);
%当我运行这个代码时,主要的错误分类是生鱼片和寿司,
%它们看起来很相似。请尝试使用此代码进行过度采样,并希望它对您的工作有所帮助。
四、运行效果
五、代码获取
后台私信回复“49期”,即可获取下载链接。