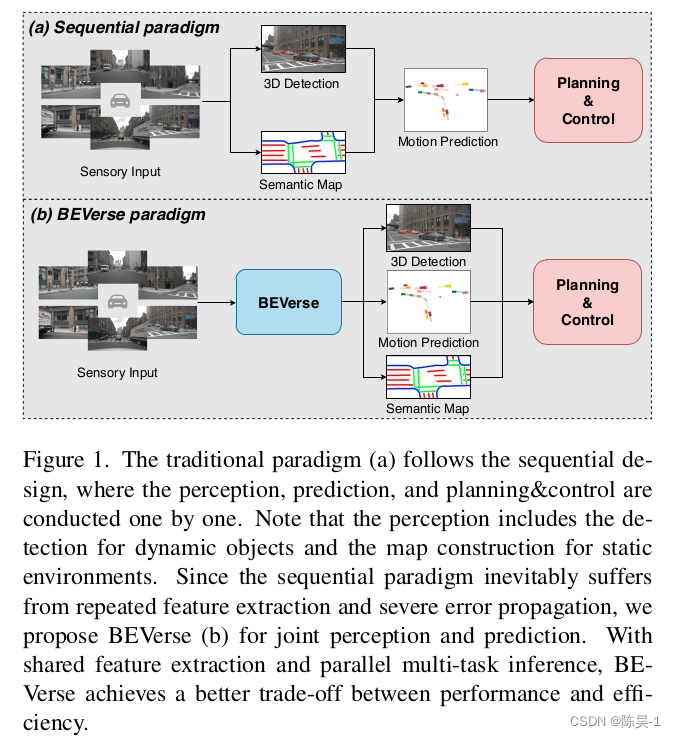
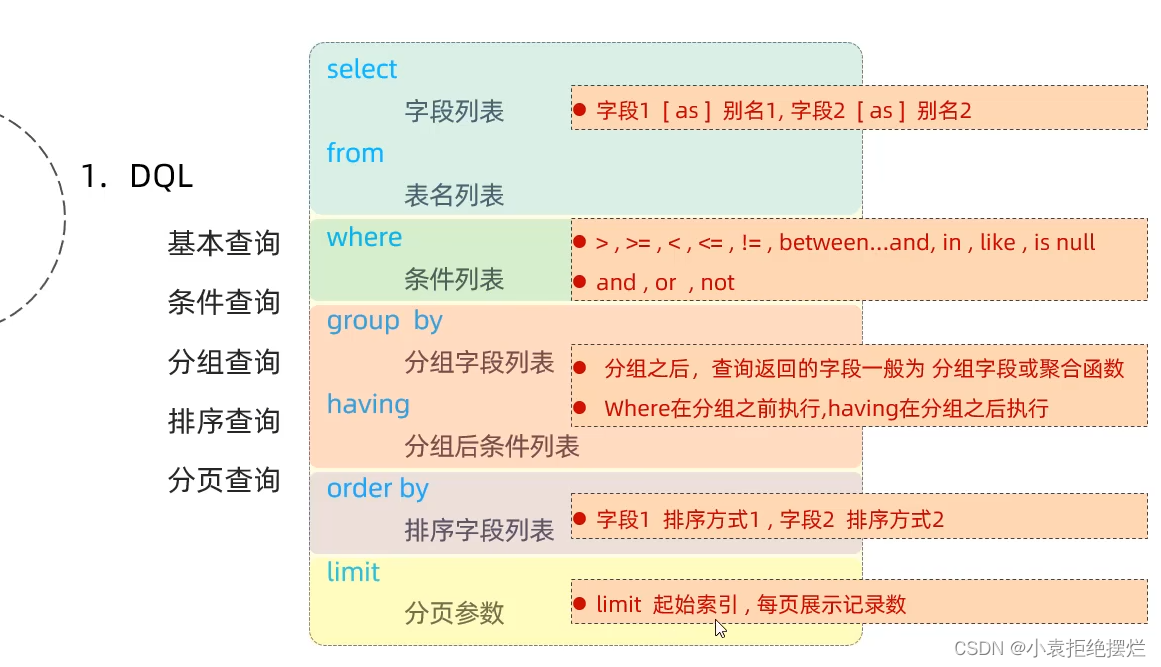
注意:这张图还包含了对于的顺序,先分组再排序,再分页,顺序不能乱
基本查询

# 1.基本查询
# 查询全部行
select * from tb_emp;
select id, user_name, password, name, gender, image, job, entry_date, create_time, update_time from tb_emp;
# 查询全部行的对应列,推荐用第二种,直观(先输入查询的select from 表,再输入第一个元素就能全部生成对应的列)
select name,entry_date from tb_emp;
# 加个起别名的操作(AS),其实也可以不加as,效果一样的
select name as 姓名, entry_date as 入职日期 from tb_emp;
select name 姓名, entry_date 入职日期 from tb_emp;
# 去除重复distinct(会去除查询列都相同的行)
select distinct job from tb_emp;
# 2.条件查询(查询指定行)-where,这就解释查询大于50分人的全部信息
select * from tb_emp where gender=2;
# where后面可以跟很多条件语句
# 比较运算符 > < <= != =... between and(范围)[是左闭右闭]
# in(set)(指定书集) like和not like(模糊查询) is null(判断是否为null)
# 逻辑运算符 and or not
# 注意:=null是等于字符串null,而想要查询是否为null 需要用 is null
select * from student where math between 80 and 100 and english in(88,98) and name is not null
and not(id is null);
条件查询

# 2.条件查询(查询指定行)-where,这就解释查询大于50分人的全部信息
select * from tb_emp where gender=2;
# where后面可以跟很多条件语句
# 比较运算符 > < <= != =... between and(范围)[是左闭右闭]
# in(set)(指定书集) like和not like(模糊查询) is null(判断是否为null)
# 逻辑运算符 and or not
# 注意:=null是等于字符串null,而想要查询是否为null 需要用 is null
select * from student where math between 80 and 100 and english in(88,98) and name is not null
and not(id is null);
# 模糊匹配
# like (_匹配单个字符,%匹配任意个字符)
# 查询名字两个字符的员工
select * from tb_emp where name like '___';
# 查询姓张的员工
select * from tb_emp where name like '张%';
聚合函数

-- 聚合函数
-- 1. 统计该企业员工数量 -- count
-- A. count(字段)
select count(id) from emp; # 29
select count(job) from emp;# 28(job里面有一个null) -- null值不参与聚合函数运算
-- B. count(*) -- 就直接查询有几行数据
select count(*) from emp;
-- C. count(值) -- 也是直接查询几行数据不过建议用上面那个
select count(1) from emp;
-- 2. 统计该企业员工 ID 的平均值
select avg(id) from emp;
-- 3. 统计该企业最早入职的员工的入职日期
select min(entrydate) from emp;
-- 4. 统计该企业最近入职的员工的入职日期
select max(entrydate) from emp;
-- 5. 统计该企业员工的 ID 之和
select sum(id) from emp;
分组查询
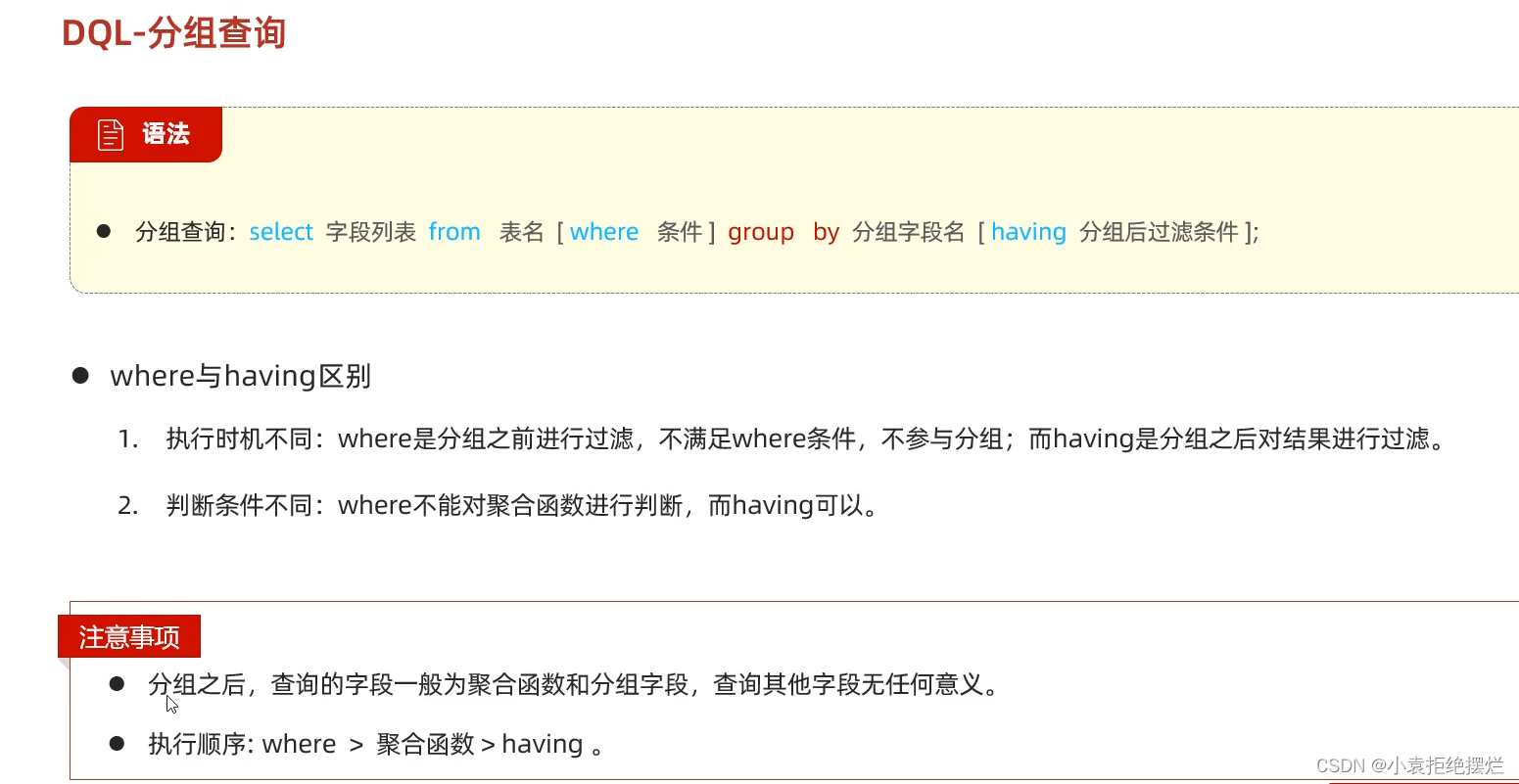
尤其是这个注意1,查询其他字段一般是会报错的
# 4.分组查询
-- 分组
-- 1. 根据性别分组 , 统计男性和女性员工的数量 -- count
select gender,count(*) from tb_emp group by gender;
-- 2. 先查询入职时间在 '2015-01-01' (包含) 以前的员工 , 并对结果根据职位分组 , 获取员工数量大于等于2的职位 -- count
select job,count(*) from tb_emp where entry_date<='2015-01-01' group by job having count(*)>=2;
排序查询
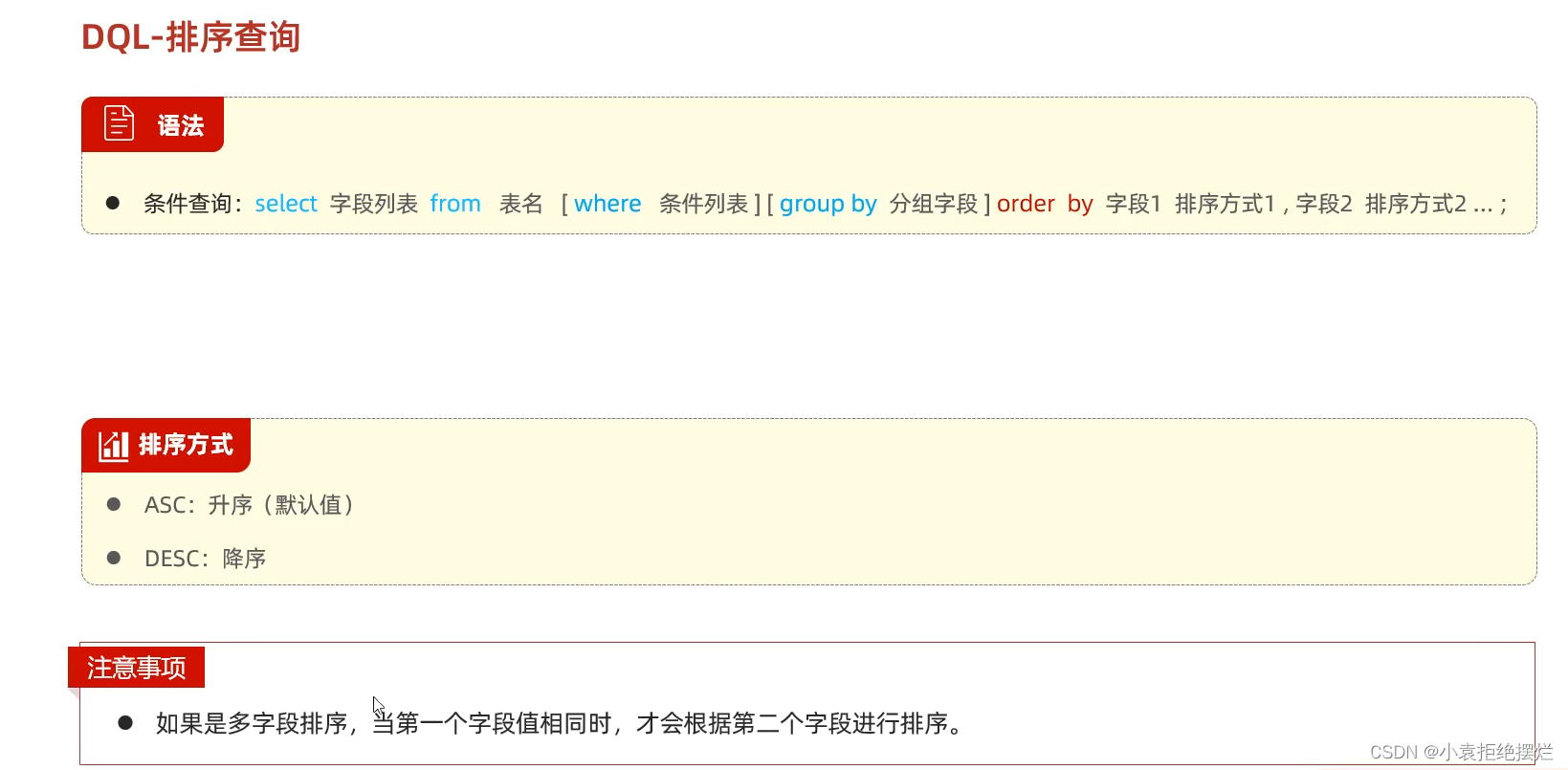
# 5.排序查询
-- 1. 根据入职时间, 对员工进行升序排序 -- 排序条件
select * from tb_emp order by entry_date asc;
select * from tb_emp order by entry_date ;# 默认升序asc可以不写
-- 2. 根据入职时间, 对员工进行降序排序
select * from tb_emp order by entry_date desc ;# desc降序
-- 3. 根据 入职时间 对公司的员工进行 升序排序 , 入职时间相同 , 再按照 ID 进行降序排序
select * from tb_emp order by entry_date asc , id desc ;
#多个字段用,隔开,越前,优先级越高(第一个字段相同,才会用第二个字段排序)
分页查询
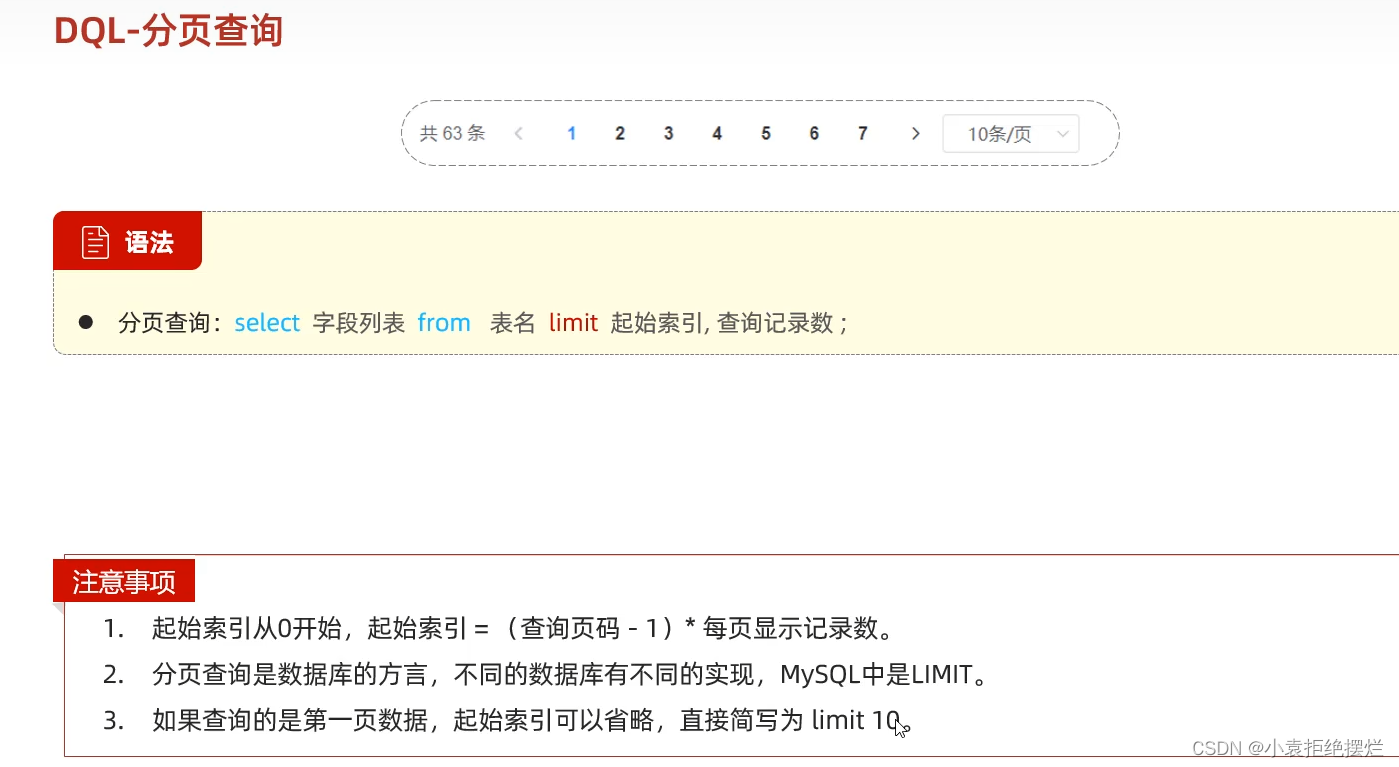
-- =================== 分页查询 ======================
limit 起始索引,查询记录数(这种语句可以实现了一个分页的效果,当然也可以不分页)
-- 1. 查询第1页员工数据, 每页展示10条记录
select * from emp limit 0,10;
select * from emp limit 10;
-- 2. 查询第2页员工数据, 每页展示10条记录
select * from emp limit 10,10;
-- 公式 : 页码 ---> 起始索引 -------> 起始索引 = (页码 - 1) * 每页记录数
案例练习(条件控制语句学习)

# 6.案例
# 1.姓 (含)张 性别 男 入职 在2000-01-01到2015-12-31之间
# 查第一页数据 每页十条,对查询的记录根据最后修改的时间进行倒序排序
select * from tb_emp where name like '%张%' and gender=1
and entry_date between '2000-01-01' and '2015-12-31'
order by update_time desc limit 10 ;
# 2.根据性别和男女划组,进行对应人数统计
select if(gender=1,'男士','女士') as '性别',count(*) as '总数' from tb_emp group by gender;
#IF(exp1,exp2,exp3),exp1为true返回exp2否则返回exp3
select case when job=1 then '班主任'
when job=2 then '讲师'
when job=3 then '学工主任'
when job=4 then '教研主管' end as '职位'
,count(*) as 总数 from tb_emp group by job;
# case when exp1 then exp2 when .. else exp_n END(注意后面有个end)
# exp1成立返回exp2 .. 如果都不成功 返回else 后面的exp_n