B站上面那个翻译我有点看不懂,打算自己啃英文翻译了(有自己意译的部分),然后懒得做字幕,就丢在博客上面了,2.2之前的章节结合那个机翻字幕能看懂
2.4无监督学习-part-1
After supervised learning, the most widely used form of machine learning is unsupervised learning. Let’s take a look at what that means, we’ve talked about supervised learning and this video is about unsupervised learning.
除了监督学习,最广泛的机器学习模式就是无监督学习了。让我们看看无监督学习是什么意思,我们已经讨论过监督学习,这个视频将要讨论无监督学习。
When we’re looking at supervised learning in the last video recalled, it looks something like this in the case of a classification problem. Each example, was associated with an output label y such as benign or malignant, designated by the poles and crosses in unsupervised learning. Were given data that isn’t associated with any output labels y, say you’re given data on patients and their tumor size and the patient’s age.
在上一个视频里,我们回顾了监督学习。分类问题是这样的,每个样本都与一个输出标签y相关联,比如良性或恶性,用O和X来表示。而在无监督学习中,给定的数据没有任何与之相关的输出标签y。比如,你获得了关于患者、肿瘤大小和患者年龄等数据。
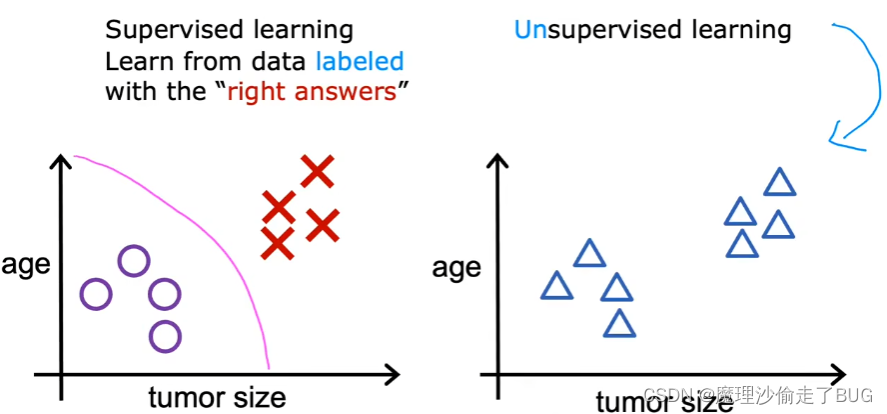
But not whether the tumor was benign or malignant, so the dataset looks like this on the right. We’re not asked to diagnose whether the tumor is benign or malignant, because we’re not given any labels. Why in the dataset, instead, our job is to find some structure or some pattern or just find something interesting in the data.
但是我们不知道图(右侧无监督学习的图中)中这些点的肿瘤到底是良性还是恶性的。我们不必去诊断肿瘤到底是良性还是恶性的,因为我们没有获得任何标签(就是说,我们不知道这个图里面的三角形到底代表是良性肿瘤还是恶性肿瘤,而且也没有提前给机器学习系统提供示例,即带有患者年龄 肿瘤大小对应的是否为恶性肿瘤的数据集,所以我们无法直接判断出图中的三角形所代表的肿瘤到底是恶性还是良性),所以在这个什么信息也不知道的数据集中,我们的工作是去找到一些结构或一些模式或者只是寻找数据中有趣的点(即我们要发掘数据中潜在的关联关系)
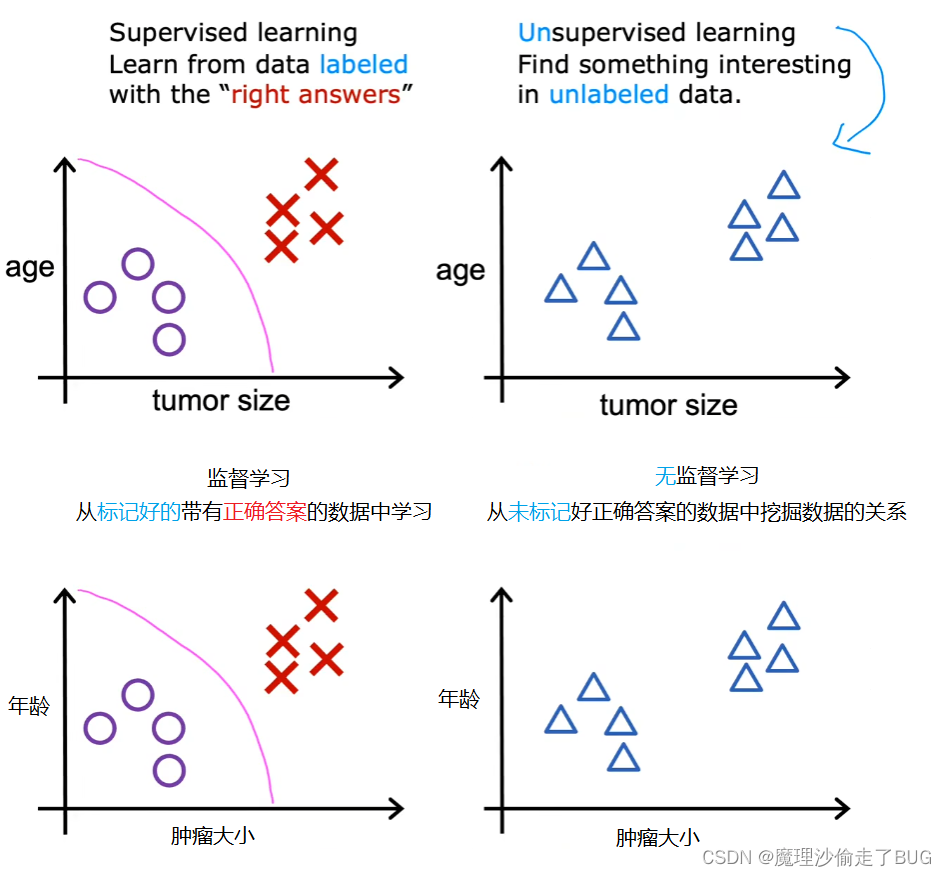
This is unsupervised learning, we call it unsupervised because we’re not trying to supervise the algorithm. To give some quote right answer for every input, instead, we asked the our room to figure out all by yourself what’s interesting. Or what patterns or structures that might be in this data, with this particular data set.
这就是无监督学习,我们之所以叫它无监督学习是因为我们不会去监督算法,我们不会给每个输入都提供一些正确答案,恰恰相反的是,我们让算法自己发现一些有趣的东西(让算法自己发掘数据之间的关系),或者,通过特定的数据集让算法自己挖掘出隐藏在数据中的模式或者结构。
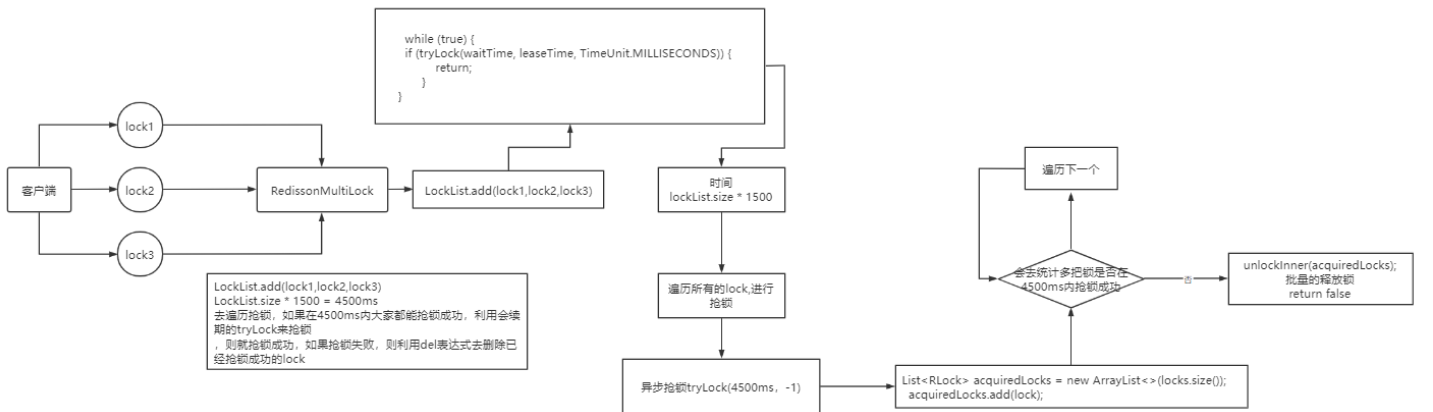
An unsupervised learning algorithm, might decide that the data can be assigned to two different groups or two different clusters. And so it might decide, that there’s one cluster what group over here, and there’s another cluster or group over here. This is a particular type of unsupervised learning, called a clustering algorithm. Because it places the unlabeled data, into different clusters and this turns out to be used in many applications.
无监督学习算法可能会将数据分配到两个不同的组或者两个不同的聚类簇中。无监督学习算法会决定这儿有一个聚类簇,那儿有一个聚类簇或者组(见下图右图画圈的地方),这是一种特定类型的无监督学习,称为聚类算法。因为它将未标记的数据放入不同的聚类簇中,所以它就称为聚类算法。聚类算法得到了广泛的应用。
For example, clustering is used in google news, what google news does is every day it goes. And looks at hundreds of thousands of news articles on the internet, and groups related stories together.
例如,谷歌新闻就使用了聚类算法,谷歌新闻每天要做的是浏览互联网上的成百上千的新闻文章中并将相同类别的新闻合并到一个组中。
For example, here is a sample from Google News, where the headline of the top article, is giant panda gives birth to rear twin cubs at Japan’s oldest zoo. This article has actually caught my eye, because my daughter loves pandas and so there are a lot of stuff panda toys. And watching panda videos in my house, and looking at this, you might notice that below this are other related articles.
例如,这是一个来自谷歌新闻的样本,顶部文章的标题是“巨型熊猫在日本最古老的动物园产下双胞胎幼崽”。这篇文章真的引起了我的注意,因为我的女儿很喜欢熊猫。所以我们家里有很多熊猫玩具,并且会观看熊猫视频。通过查看这个样本,你可能会注意到在下方有其他相关的文章。
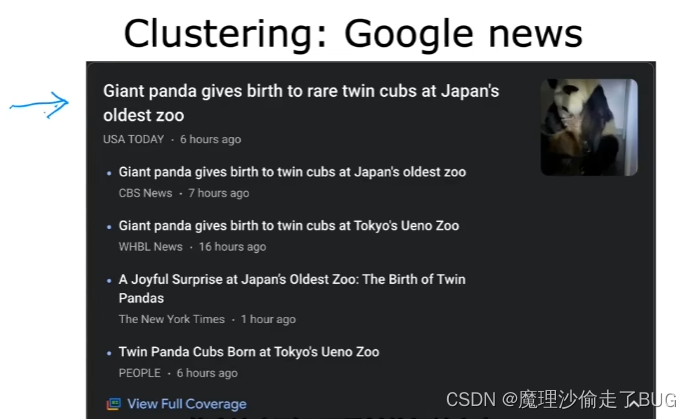
Maybe from the headlines alone, you can start to guess what clustering might be doing. Notice that the word panda appears here here, here, here and here and notice that the word twin also appears in all five articles. And the word Zoo also appears in all of these articles, so the clustering algorithm is finding articles. All of all the hundreds of thousands of news articles on the internet that day, finding the articles that mention similar words and grouping them into clusters.
单从标题上看,你可能已经开始猜测聚类算法的作用了。请注意,熊猫这个词在这里、这里、这里和这里(下图中画蓝色的圈的地方)出现,而双胞胎这个词也出现在这五篇文章中。此外,动物园这个词也出现在所有这些文章中,因此聚类算法正是依靠这些关键词搜寻着相关的文章。在那一天的互联网上的成千上万篇新闻文章中,聚类算法将相似关键词的文章聚合到一个聚类簇中。
Now, what’s cool is that this clustering algorithm figures out on his own which words suggest, that certain articles are in the same group. What I mean is there isn’t an employee at google news who’s telling the algorithm to find articles that the word panda. And twins and zoo to put them into the same cluster, the news topics change every day. And there are so many news stories, it just isn’t feasible to people doing this every single day for all the topics that use covers.
现在,有意思的是,这个聚类算法能够自行判断带有哪些关键词的文章属于同一组。我的意思是,谷歌新闻没有员工告诉算法要找到包含“熊猫”、“双胞胎”和“动物园”这些词的文章,算法自动将它们放在同一个聚类中。每天都有许多新闻,让人动手去把每天的新闻按主题分类是不可行的。
Instead the algorithm has to figure out on his own without supervision, what are the clusters of news articles today. So that’s why this clustering algorithm, is a type of unsupervised learning algorithm. Let’s look at the second example of unsupervised learning applied to clustering genetic or DNA data.
相反,聚类算法必须在没有监督的情况下自行判断今天的新闻文章属于哪一类文章。这就是为什么聚类算法是一种无监督学习算法的原因。现在,让我们来看一下无监督学习应用于聚类遗传或DNA数据的第二个例子。
This image shows a picture of DNA micro array data, these look like tiny grids of a spreadsheet. And each tiny column represents the genetic or DNA activity of one person, So for example, this entire Column here is from one person’s DNA. And this other column is of another person, each row represents a particular gene.
这张图片展示了DNA微阵列数据的图像,它们看起来像是一个电子表格的微小网格。每一个微小的列代表一个人的遗传活性或DNA活性。例如,这整列(下图中标记处)是来自一个人的DNA数据,而另一列则是另一个人的数据,每一行代表一个特定的基因。

So just as an example, perhaps this role here might represent a gene that affects eye color, or this role here is a gene that affects how tall someone is. Researchers have even found a genetic link to whether someone dislikes certain vegetables, such as broccoli, or brussels sprouts, or asparagus. So next time someone asks you why didn’t you finish your salad, you can tell them, maybe it’s genetic for DNA micro race.
举个例子,或许这一行代表着一个影响眼睛颜色的基因,而这一行则是一个影响身高的基因。研究人员甚至发现了与一个人是否讨厌某些蔬菜(如西兰花、甘蓝或芦笋)之间存在遗传联系。 所以,下次有人问你为什么没有吃完沙拉,你可以告诉他们,也许这是由DNA微阵列的遗传因素所决定的。
【向ChatGPT提问】请用通俗的语言解释一下什么是DNA微阵列?
【ChatGPT回答】DNA微阵列是一种用于研究基因活动的技术。它可以帮助科学家了解在特定条件下,组织或细胞中的哪些基因处于活跃状态。DNA微阵列使用微小的玻璃片或芯片上的许多微小孔洞来捕捉和分析DNA片段。这些孔洞中含有用于检测基因活动的特定DNA探针。当基因活跃时,相应的DNA片段会结合到探针上并发出信号。通过分析这些信号,科学家可以了解基因在不同人群或条件下的表达情况,从而揭示基因对特定特征或疾病的影响。DNA微阵列技术对于研究遗传学、生物学和医学等领域具有重要作用。
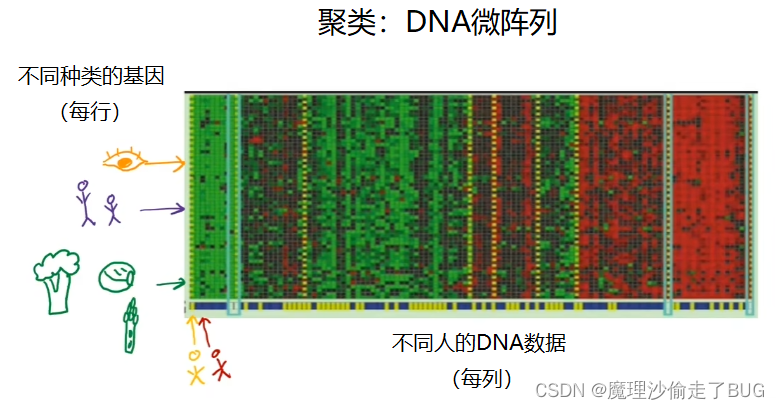
The idea is to measure how much certain genes, are expressed for each individual person. So these colors red, green, gray, and so on, show the degree to which different individuals do, or do not have a specific gene active. And what you can do is then run a clustering algorithm to group individuals into different categories. Or different types of people like maybe these individuals that group together, and let’s just call this type one. And these people are grouped into type two, and these people are groups as type three.
我们的想法是通过这个DNA微阵列测量每个人特定基因的表达程度。所以图中的这些红色、绿色、灰色等颜色展示了不同人的特定基因的表达程度。通过运行聚类算法,你可以将不同的人按基因的不同分成不同的类别。比如,让我们将这些人归为第一类;这些人归为第二类;而这些人则被归为第三类(如下图所示)。

This is unsupervised learning, because we’re not telling the algorithm in advance, that there is a type one person with certain characteristics. Or a type two person with certain characteristics, instead what we’re saying is here’s a bunch of data. I don’t know what the different types of people are but can you automatically find structure into data.
这就是无监督学习算法,因为我们没有事先告诉算法这三类人有什么特定的特征,恰恰相反的是,我们所做的只是给算法提供了一堆数据。我们并不知道不同的人会被归为哪一类,但是你可以通过算法自动地发现数据中的结构(或关系)。
And automatically figure out whether the major types of individuals, since we’re not giving the algorithm the right answer for the examples in advance. This is unsupervised learning, here’s the third example, many companies have huge databases of customer information given this data. Can you automatically group your customers, into different market segments so that you can more efficiently serve your customers.
即使我们没有事先给算法正确答案的示例,聚类算法也能够自动找出主要的个体类型。聚类算法就是一种无监督学习的方法。举个第三个例子,很多公司拥有庞大的客户信息数据库,当你有了客户信息数据库中的这些数据,你能否自动将你的客户划分到不同的市场区隔(市场区隔(Market Segment)是将消费者依不同的需求、特征区分成若干个不同的群体,而形成各个不同的消费群。),以便更高效地为客户提供服务。
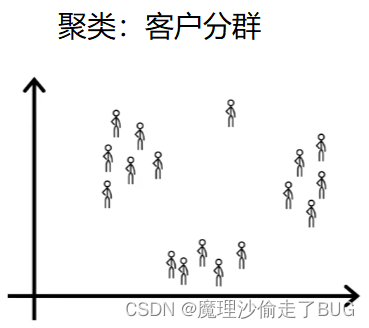
Concretely the deep learning dot AI team did some research to better understand the deep learning dot AI community. And why different individuals take these classes, subscribed to the batch weekly newsletter, or attend our AI events. Let’s visualize the deep learning dot AI community, as this collection of people running clustering.
具体来说,Deep Learning Dot AI团队进行了一些调查,该调查旨在更好地了解Deep Learning Dot AI社区。我们想了解不同的人选择学习这些课程,批量订阅每周简报或者参加我们的人工智能活动的原因。我们将Deep Learning Dot AI社区视为便于运行聚类算法的人的样本集合。
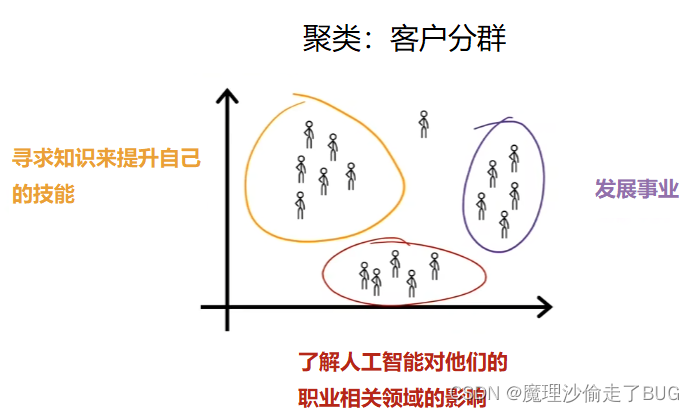
That is market segmentation found a few distinct groups of individuals, one group’s primary motivation is seeking knowledge to grow their skills. Perhaps this is you, and so that’s great, a second group’s primary motivation is looking for a way to develop their career. Maybe you want to get a promotion or a new job, or make some career progression if this describes you, that’s great too. And yet another group wants to stay updated on how AI impacts their field of work, perhaps this is you, that’s great too. This is a clustering that our team used to try to better serve our community as we’re trying to figure out. Whether the major categories of learners in the deeper and community, So if any of these is your top motivation for learning, that’s great. And I hope I’ll be able to help you on your journey. Or in case this is you, and you want something totally different than the other three categories. That’s fine too, and I want you to know, I love you all the same.
通过划分市场区隔我们发现了几类不同的人群,有一组人的学习本课程的初始动机是寻求知识来提升自己的技能。也许这就是你的情况,这非常好。第二组人的学习本课程的动机是寻找发展自己事业的途径。也许你想升职、换工作,或在职业发展中取得一些进步。如果你符合这一描述,那也非常好。还有另一组人希望随时了解人工智能对他们的职业相关领域的影响。也许这就是你的情况,那也非常好。这是我们的团队运用聚类算法试图更好地服务我们的社区,我们正努力尝试弄清楚在Deep Learning Dot AI社区中主要的学习者类别是什么。所以,如果你学习本课程的动机恰好在以上提及的三个类别之中,那太棒了。我希望我能够在你的学习旅途中帮助到你。或者,如果你的学习动机不同于以上三种类别,你希望追求与上述三种类别完全不同的东西,那也没关系。我想让你知道,我同样爱你们所有人。
So to summarize a clustering algorithm. Which is a type of unsupervised learning algorithm, takes data without labels and tries to automatically group them into clusters. And so maybe the next time you see or think of a panda, maybe you think of clustering as well. And besides clustering, there are other types of unsupervised learning as well. Let’s go on to the next video, to take a look at some other types of unsupervised learning algorithms.
所以,总结一下,聚类算法是一种无监督学习算法,它接收没有标签的数据,并试图自动将其分组成簇。也许下次当你看到或想到熊猫时,你也会想到聚类。除了聚类之外,还有其他类型的无监督学习。让我们继续下一个视频,看看其他一些无监督学习算法。