目录
1.起因
2.sql改进
3.改造pagehelper
4.新的问题
方案一
方案二
方案三(终极)
5.附上pagehelper官方使用指南
1.起因
项目中有个查询非常慢,查询第一页都很慢,
sql为一张大表A left join了许多张基础数据表(小表),
select * from A
left join b on xxx
left join c on xxx
left join d on xxx
left join e on xxx
left join f on xxx
left join g on xxx
left join h on xxx
left join i on xxx
left join g on xxx
where xxx此时的sql被pagehelper包装在最后加了limit x,x查询比较慢
2.sql改进
其实翻页一页就10条数据,靠前的页码应该是很快的(项目中限制了只能查前10页),select * from A limit 10,10很快
于是想着改进sql,先单独查出大表分页数据后在left join其它基础数据表
select * from (
select * from A where xxx order by xxx limit x,x
) A1
left join b on xxx
left join c on xxx
left join d on xxx
left join e on xxx
left join f on xxx
left join g on xxx
left join h on xxx
left join i on xxx
left join g on xxx3.改造pagehelper
由于pagehelper的分页是包在整个执行sql的最外层,想要limit加在指定位置需要,我操作的数据源是mysql就需要去重写pagehelper的MySqlDialect里面的getPageSql方法,具体造作如下
编写MySqlDialectUdf类继承MySqlDialect重写getPageSql方法
package com.hsf.framework.datasource;
import com.github.pagehelper.Page;
import com.github.pagehelper.dialect.helper.MySqlDialect;
import org.apache.ibatis.cache.CacheKey;
import java.util.regex.Pattern;
/**
* ClassName: MySqlDialectUdf
* Description:
* date: 2023/6/30 14:58
*
* @author yanglp
* @since JDK 1.8
*/
public class MySqlDialectUdf extends MySqlDialect {
@Override
public String getPageSql(String sql, Page page, CacheKey pageKey) {
Pattern compileFixed = Pattern.compile("/\\*fixed\\*/");
String compileLimit = "/\\*limit\\*/";
if (compileFixed.matcher(sql).find()) {//自定义分页逻辑
if (page.getStartRow() == 0) {//第一页
sql = sql.replaceFirst(compileLimit, " LIMIT ? ");
} else {
sql = sql.replaceFirst(compileLimit, " LIMIT ?, ? ");
}
return sql;
}
return super.getPageSql(sql, page, pageKey);//正常分页逻辑
}
}
代码里面有两个重要的字符串
/*fixed*/ 代表此sql将自定义按指定位置插入limit
/*limit*/ 代表要插入limit的具体位置
匹配到自定定义分页指令则走自定义拼接,未匹配到则走正常的分页逻辑
接下来改造sql,改造完的mapper.xml查询语句为
<select id="selectMesProcessChangeList" parameterType="MesProcessChange" resultMap="MesProcessChangeResult">
/*fixed*/
select * (
select * from A
<where>
<if test="barcode != null and barcode != ''"> and barcode = #{barcode}</if>
<if test="docNo != null and docNo != ''"> and doc_no = #{docNo}</if>
<if test="companyId != null "> and company_id = #{companyId}</if>
</where>
order by id desc /*limit*/ ) pc
left join b on xxx
left join c on xxx
left join d on xxx
left join e on xxx
left join f on xxx
left join g on xxx
left join h on xxx
left join i on xxx
left join g on xxx
</select>那么怎么生效走MySqlDialect呢,在yml文件中配置pagehelper.helperDialect
pagehelper:
helperDialect: com.hsf.framework.datasource.MySqlDialectUdf本来pagehelper.helperDialect是配置pagehelper的指定方言的,配置为mysql,那么解析拼接分页的时候就是走的MySqlDialect,但是我们重写了MySqlDialect,需要走我们自定义的方法,那么helperDialect就需要指定为MySqlDialectUdf的全路径名
4.新的问题
到这里如果你的项目是单一数据源且为mysql,那么如上操作就够了,如果你的项目配置了多数据源且是不同数据库类型的,那么如上配置问题就来了
我的项目是有两个数据源一个mysql一个sqlserver,如上配置之后导致sqlserver的分页语句也走的mysql的limit做分页显然不对
多数据源配置autoRuntimeDialect为true之后pagehelper允许在运行时根据多数据源自动识别对应方言的分页,做成如下配置
pagehelper:
helperDialect: com.hsf.framework.datasource.MySqlDialectUdf
autoRuntimeDialect: true发现自定义的MySqlDialect并未生效,看源码发现如果设置自动选择方言autoRuntimeDialect: true之后,helperDialect属性的设置是不会生效的
public void setProperties(Properties properties) {
this.initAutoDialectClass(properties);
String useSqlserver2012 = properties.getProperty("useSqlserver2012");
if (StringUtil.isNotEmpty(useSqlserver2012) && Boolean.parseBoolean(useSqlserver2012)) {
registerDialectAlias("sqlserver", SqlServer2012Dialect.class);
registerDialectAlias("sqlserver2008", SqlServerDialect.class);
}
this.initDialectAlias(properties);
String dialect = properties.getProperty("helperDialect");
String runtimeDialect = properties.getProperty("autoRuntimeDialect");
if (StringUtil.isNotEmpty(runtimeDialect) && "TRUE".equalsIgnoreCase(runtimeDialect)) {
this.autoDialect = false;
this.properties = properties;
} else if (StringUtil.isEmpty(dialect)) {
this.autoDialect = true;
this.properties = properties;
} else {
this.autoDialect = false;
this.delegate = instanceDialect(dialect, properties);
}
}问题又来了,既要mysql能走自定义方言又要不同类型数据源能自动切换方言该怎么办,
方案一
前面写过一篇自定义pagehelper的拦截器的
Mybatis PageHelper分页语句执行前做sql拦截并变更
用这个方案可以拦截sql做截取变换改造sql,但现在我们要使用自定义方言,放弃这个方案
方案二
下载pagehelper的源码修改原生MySqlDialect的getPageSql再打包成jar引入到我们的项目可以参考这篇文章
PageHelper-Spring-Boot-Starter 新增SUNDB数据库支持
方案三(终极)
我项目引入的是pagehelper-spring-boot-starter
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.5</version>
</dependency>继续翻看GitHub - pagehelper/pagehelper-spring-boot: pagehelper-spring-boot
看到版本更新日志
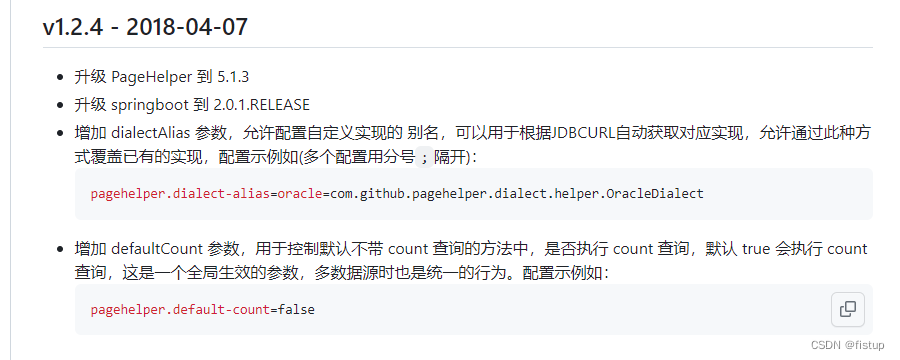
1.2.4版本就已经支持各种类型的数据库的自定义方言实现了
pagehelper:
dialectAlias: mysql=com.hsf.framework.datasource.MySqlDialectUdf
autoRuntimeDialect: true
reasonable: true
supportMethodsArguments: true
params: count=countSql如上配置,既可以实现不同数据库切换方言,又可以自定义对应数据库的自定义分页实现,完美解决
5.附上pagehelper官方使用指南
https://github.com/pagehelper/Mybatis-PageHelper/blob/master/wikis/zh/HowToUse.md