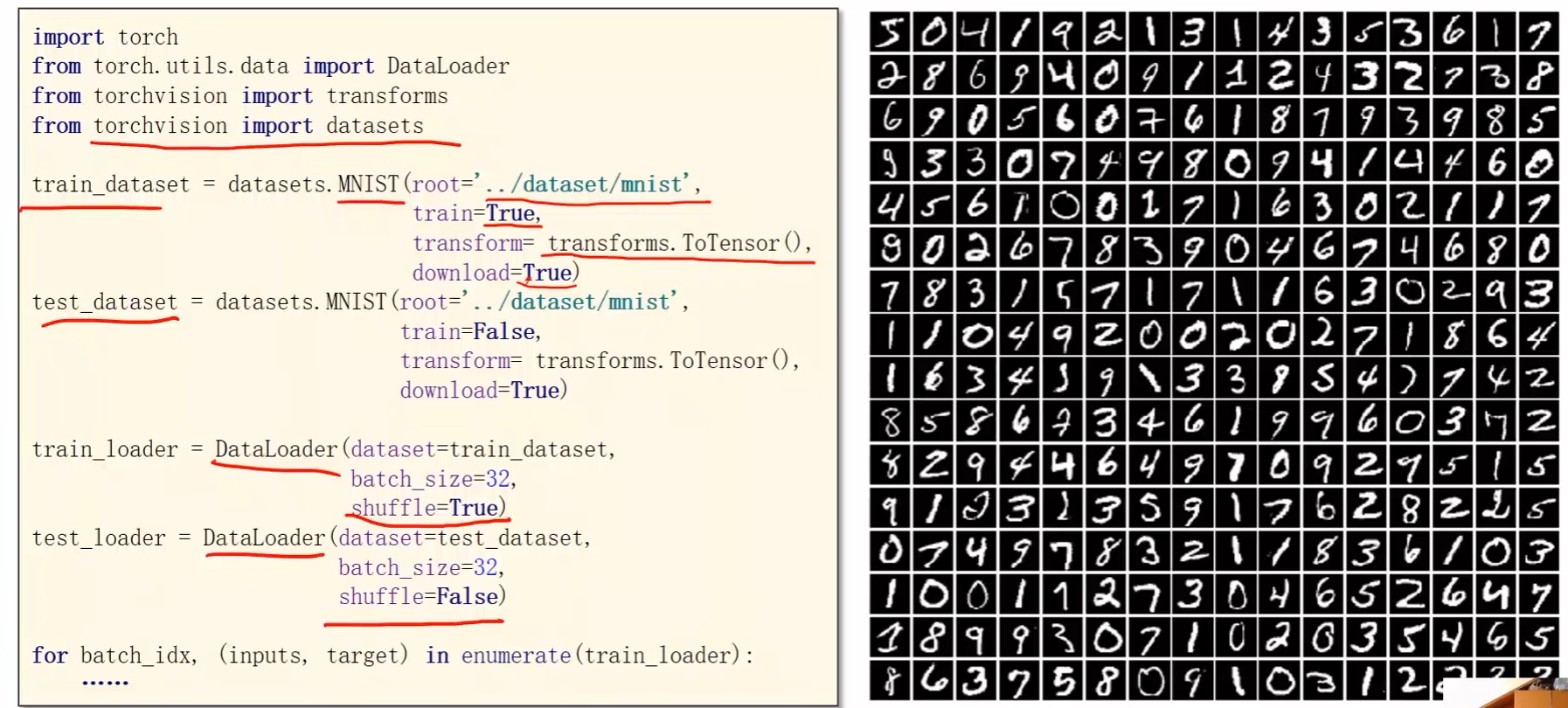
b站刘二大人《PyTorch深度学习实践》课程第八讲加载数据集笔记与代码:https://www.bilibili.com/video/BV1Y7411d7Ys?p=8&vd_source=b17f113d28933824d753a0915d5e3a90
Dataset用于构造数据集,该数据集能够支持索引
DataLoader用于从数据集中拿出一个mini-batch来用于训练
术语:
- epoch:训练轮数
- 所有的训练样本都进行了前向和反向传播的一个过程
- 所有训练样本都进行了训练
- Batch-Size:每轮训练进行mini-batch的次数
- 每次训练的时候所用的样本数量
- Iterations:batch分了多少个
- 内层的batch一共执行了多少次

外层表示训练周期,内层是对batch进行迭代
例如有1万个样本,batch是1千个,即batch-size = 1000,iterations=10
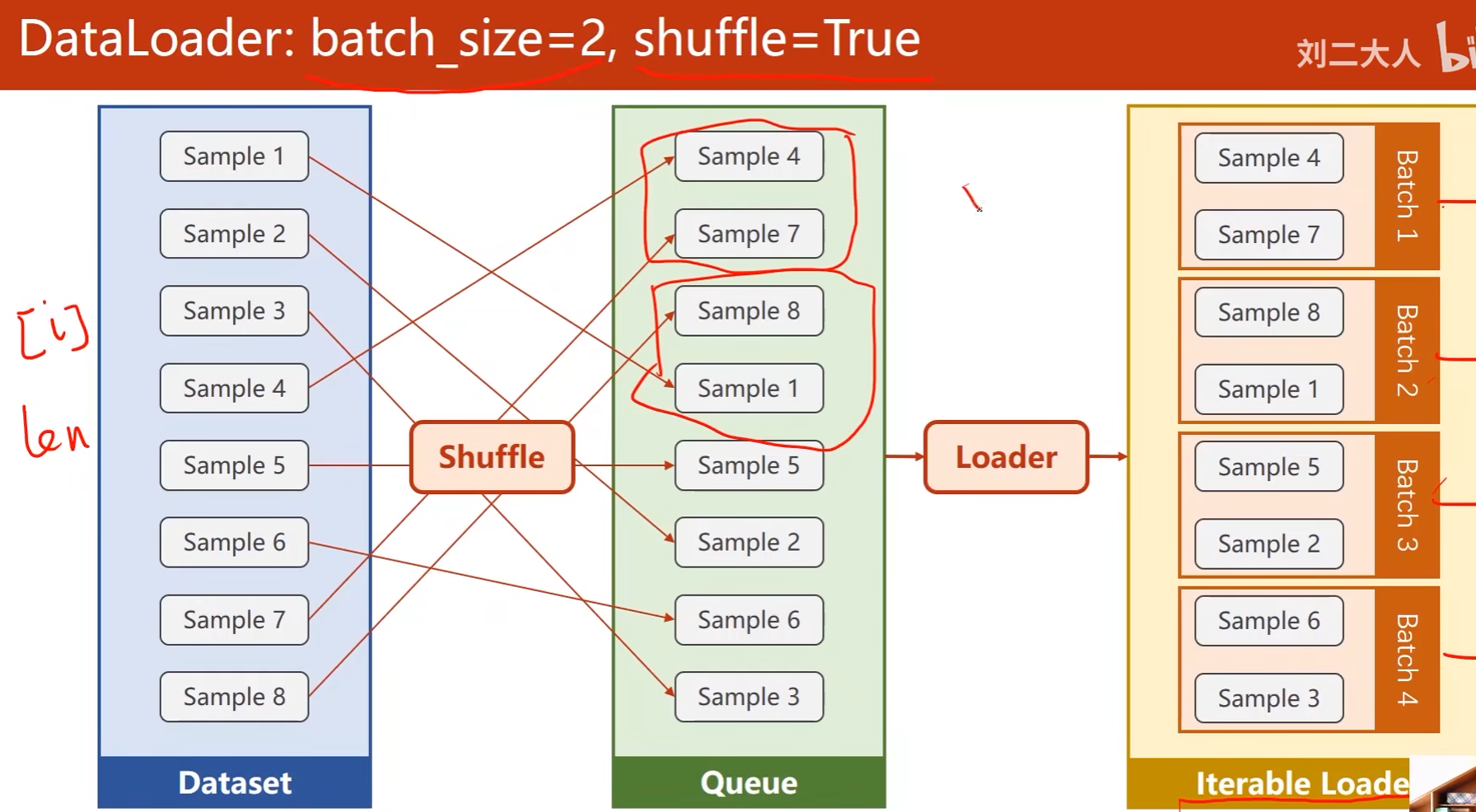
DataLoader:
- batch_size:指定batch大小
- shuffle:打乱数据,增强随机性
数据集要能够支持索引,即DataLoader要能够访问到里面的每一个元素,同时要能够提供长度信息,以便于DataLoader对Dataset自动进行小批量的数据集省出
首先是随机打乱数据(Shuffle),接下去Loader会对打乱后的数据进行分组,做成可迭代的Loader
代码实现Dataset和DataLoader:
- Dataset是一个抽象类,不能实例化对象,只能继承
- DataLoader用于帮助我们加载数据,可以实例化
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# DiabetesDataset类继承自Dataset
class DiabetesDataset(Dataset):
def __init__(self):
pass
def __getitem__(self, index): # 为了实例化之后能够支持下标操作
pass
def __len__(self): # 获取数据条数
pass
# 实例化DiabetesDataset类对象
dataset = DiabetesDataset()
# 初始化loader,传入数据集dataset,设置batch_size,是否需要打乱数据,num_worker用于读取的时候是否要用多线程(进程数)
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
在windows系统下使用num_worker直接去训练会有一些问题:


使用DataLoader
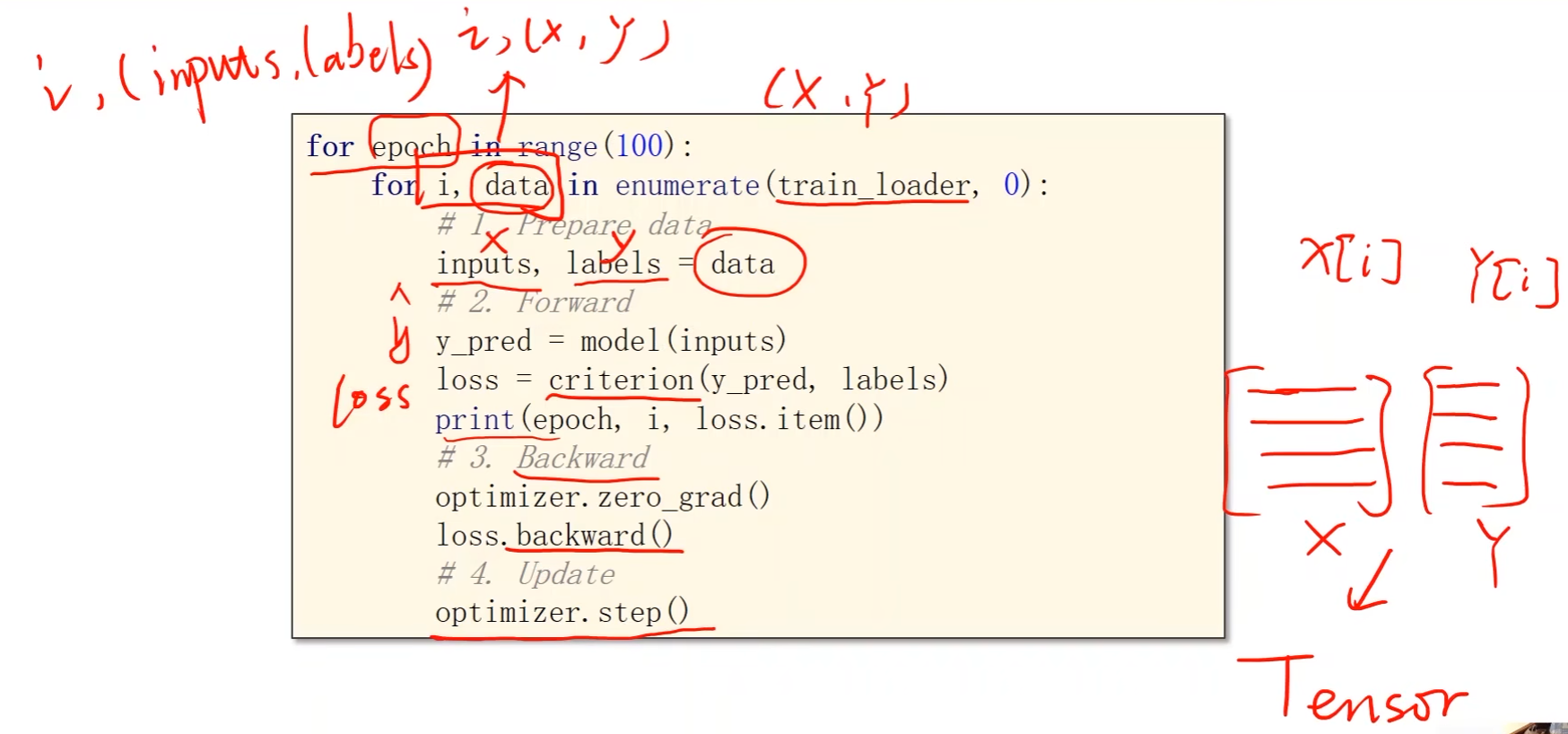
# 训练过程
# 外层表示训练周期,例如epoch取50表示所有的数据要跑50次
for epoch in range(100):
# 内层直接对train_loader进行迭代
# 用enumerate是为了获取当前迭代次数i,data存储train_loader的数据x和标签y,元组形式
for i, data in enumerate(train_loader, 0):
# 1. prepare data
inputs, labels = data # inputs(x)和labels(y)都是张量
# 2. forward
y_pred = model(inputs) # y_hat
loss = criterion(y_pred, labels)
print(epoch, loss.item())
# 3. backward
optimizer.zero_grad() # 在反向传播开始将上一轮的梯度归零
loss.backward() # 反向传播(计算梯度)
# 4. backward
optimizer.step() # 更新权重w和偏置b
完整代码:
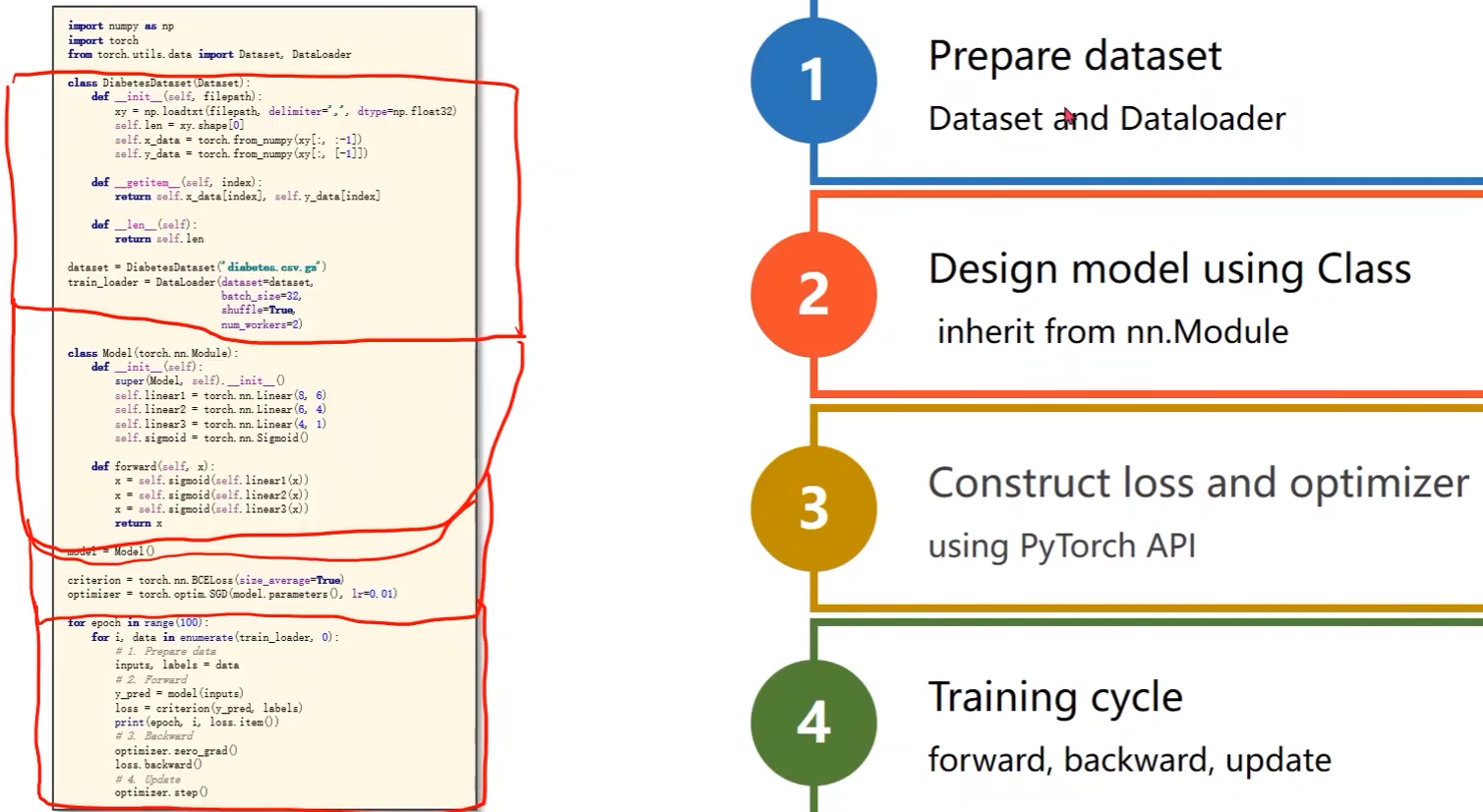
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
# DiabetesDataset类继承自Dataset
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # 取行数,获取数据集个数
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index): # 为了实例化之后能够支持下标操作
return self.x_data[index], self.y_data[index] # 返回索引
def __len__(self): # 获取数据条数
return self.len
# 实例化DiabetesDataset类对象
dataset = DiabetesDataset('dataset/diabetes.csv.gz')
# 初始化loader,传入数据集dataset,设置batch_size,是否需要打乱数据
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2) # num_worker:读取的时候是否要用多线程(进程数)
# 定义模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
# criterion = torch.nn.MSELoss(size_average=True) pytorch更新后被弃用了
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练过程
# 外层表示训练周期,例如epoch取50表示所有的数据要跑50次
for epoch in range(100):
# 内层直接对train_loader进行迭代
# 用enumerate是为了获取当前迭代次数i,data存储train_loader的数据x和标签y,元组形式
for i, data in enumerate(train_loader, 0):
# 1. prepare data
inputs, labels = data # inputs(x)和labels(y)都是张量
# 2. forward
y_pred = model(inputs) # y_hat
loss = criterion(y_pred, labels)
print(epoch, loss.item())
# 3. backward
optimizer.zero_grad() # 在反向传播开始将上一轮的梯度归零
loss.backward() # 反向传播(计算梯度)
# 4. backward
optimizer.step() # 更新权重w和偏置b