深入理解计算机系统系列文章目录
第一章 计算机的基本组成
1. 内容概述
2. 计算机基本组成
第二章 计算机的指令和运算
3. 计算机指令
4. 程序的机器级表示
5. 计算机运算
6. 信息表示与处理
第三章 处理器设计
7. CPU
8. 其他处理器
第四章 存储器和IO系统
9. 存储器的层次结构
10. 存储器和I/O系统
文章目录
- 深入理解计算机系统系列文章目录
- 前言
- 参考资料
- 一、机器码与计算机指令
- 1. 基本概念
- 1.1 纸带编程
- 1.2 CPU功能
- 1.3 编译与汇编
- 1.4 解析指令和机器码
- 2. 指令跳转
- 2.1 指令跳转
- 2.2 指令循环
- 3. 函数调用
- 3.1 程序栈
- 3.2 构造一个 stack overflow
- 3.3 利用函数内联进行性能优化
- 二、程序执行
- 1. 静态编译
- 1.1 ELF
- 1.2 程序装载
- 1.3 内存分段/分页
- 2. 动态链接
- 2.1 PLT/GOT
- 总结
前言
参考资料
《深入理解计算机系统》
《深入浅出计算机组成原理》
一、机器码与计算机指令
1. 基本概念
1.1 纸带编程
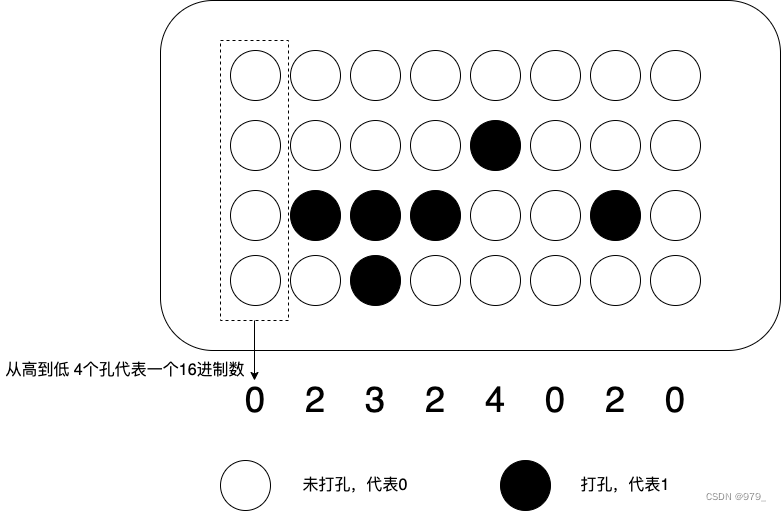
以前写程序都是用一种古老的物理设备,叫作“打孔卡(Punched Card)”。
用这种设备写程序,要先在脑海里或者在纸上写出程序,然后在纸带或者卡片上打洞。
这样,要写的程序、要处理的数据,就变成一条条纸带或者一张张卡片,之后再交给当时的计算机去处理。
那个时候,人们在特定的位置上打洞或者不打洞,来代表“0”或者“1”。
为什么早期的计算机程序要使用打孔卡,而不能像我们现在一样,用 C 或者 Python 这样的高级语言来写呢?
原因很简单,因为计算机或者说 CPU 本身,并没有能力理解这些高级语言。
即使在今天,我们使用的现代个人计算机,仍然只能处理所谓的“机器码”,也就是一连串的“0”和“1”这样的数字。

1.2 CPU功能
CPU 的全称是 Central Processing Unit,中文是中央处理器。
从硬件的角度来看,CPU 就是一个超大规模集成电路,通过电路实现了加法、乘法乃至各种各样的处理逻辑。
从软件工程师的角度来讲,CPU 就是一个执行各种计算机指令(Instruction Code)的逻辑机器。
这里的计算机指令,就好比一门 CPU 能够听得懂的语言,我们也可以把它叫作机器语言(Machine Language)。
两种 CPU 各自支持的语言,就是两组不同的计算机指令集,英文叫 Instruction Set。
这里面的“Set”,其实就是数学上的集合,代表不同的单词、语法。
一个计算机程序,不可能只有一条指令,而是由成千上万条指令组成的。
但是 CPU 里不能一直放着所有指令,所以计算机程序平时是存储在存储器中的。
这种程序指令存储在存储器里面的计算机,我们就叫作存储程序型计算机(Stored-program Computer)。
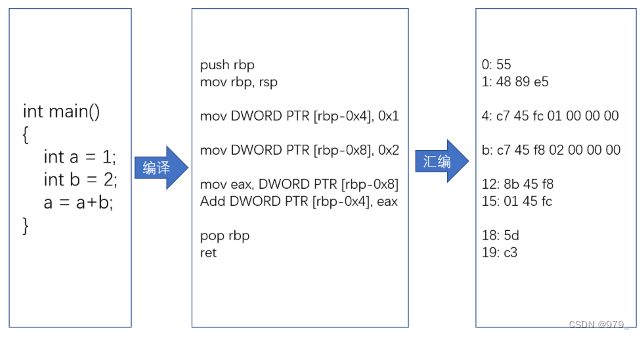
1.3 编译与汇编
要让一段程序在一个 Linux 操作系统上跑起来,我们需要把整个程序翻译成一个汇编语言(ASM,Assembly Language)的程序,
这个过程我们一般叫编译(Compile)成汇编代码。
针对汇编代码,我们可以再用汇编器(Assembler)翻译成机器码(Machine Code)。
这些机器码由“0”和“1”组成的机器语言表示。这一条条机器码,就是一条条的计算机指令。
这样一串串的 16 进制数字,就是我们 CPU 能够真正认识的计算机指令。
在一个 Linux 操作系统上,我们可以简单地使用 gcc 和 objdump 这样两条命令,把对应的汇编代码和机器码都打印出来。
$ gcc -g-c test.c
$ objdump -d -M intel -S test.o
汇编代码其实就是“给程序员看的机器码”,也正因为这样,机器码和汇编代码是一一对应的。
我们人类很容易记住 add、mov 这些用英文表示的指令,而 8b 45 f8 这样的指令,由于很难一下子看明白是在干什么,所以会非常难以记忆。
1.4 解析指令和机器码
常见的指令可以分成五大类。
第一类是算术类指令。我们的加减乘除,在 CPU 层面,都会变成一条条算术类指令。
第二类是数据传输类指令。给变量赋值、在内存里读写数据,用的都是数据传输类指令。
第三类是逻辑类指令。逻辑上的与或非,都是这一类指令。
第四类是条件分支类指令。日常我们写的“if/else”,其实都是条件分支类指令。
最后一类是无条件跳转指令。写一些大一点的程序,我们常常需要写一些函数或者方法。
在调用函数的时候,其实就是发起了一个无条件跳转指令。

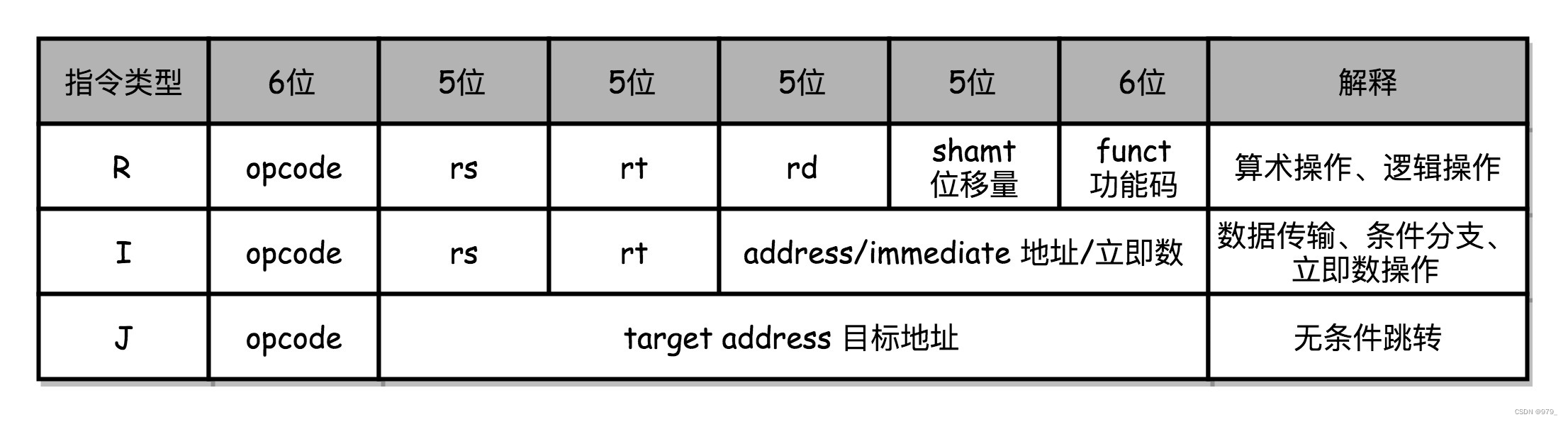
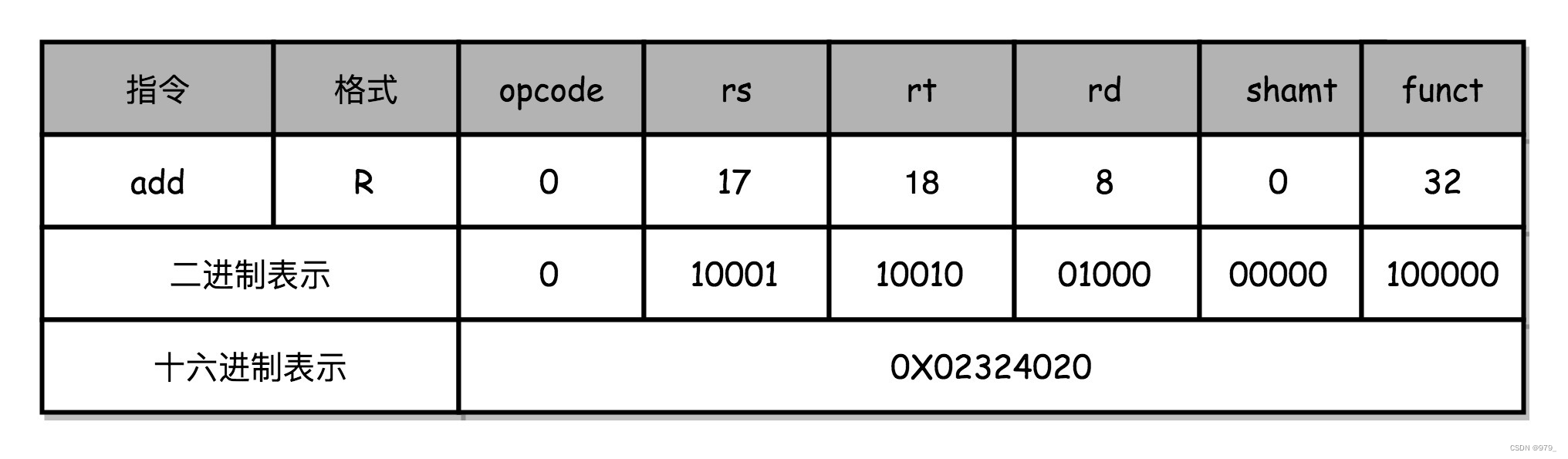
MIPS 的指令是一个 32 位的整数,
高 6 位叫操作码(Opcode),也就是代表这条指令具体是一条什么样的指令,
剩下的 26 位有三种格式,分别是 R、I 和 J。
- R 指令
一般用来做算术和逻辑操作,里面有读取和写入数据的寄存器的地址。
如果是逻辑位移操作,后面还有位移操作的位移量,
而最后的功能码,则是在前面的操作码不够的时候,扩展操作码表示对应的具体指令的。 - I 指令
通常是用在数据传输、条件分支,以及在运算的时候使用的并非变量还是常数的时候。
这个时候,没有了位移量和操作码,也没有了第三个寄存器,
而是把这三部分直接合并成了一个地址值或者一个常数。 - J 指令
一个跳转指令,高 6 位之外的 26 位都是一个跳转后的地址。
例子如下:
add $t0,$s2,$s1
对应的 MIPS 指令里
- opcode 是 0
- rs 代表第一个寄存器 s1 的地址是 17,rt 代表第二个寄存器 s2 的地址是 18,rd 代表目标的临时寄存器 t0 的地址,是 8。
- 因为不是位移操作,所以位移量是 0。
把这些数字拼在一起,就变成了一个 MIPS 的加法指令。
2. 指令跳转
2.1 指令跳转
-
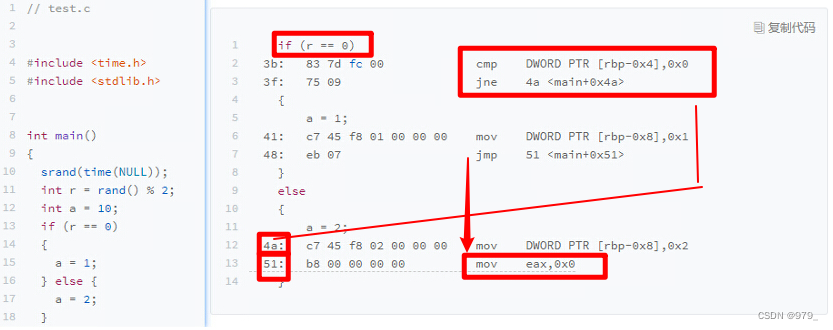
r == 0
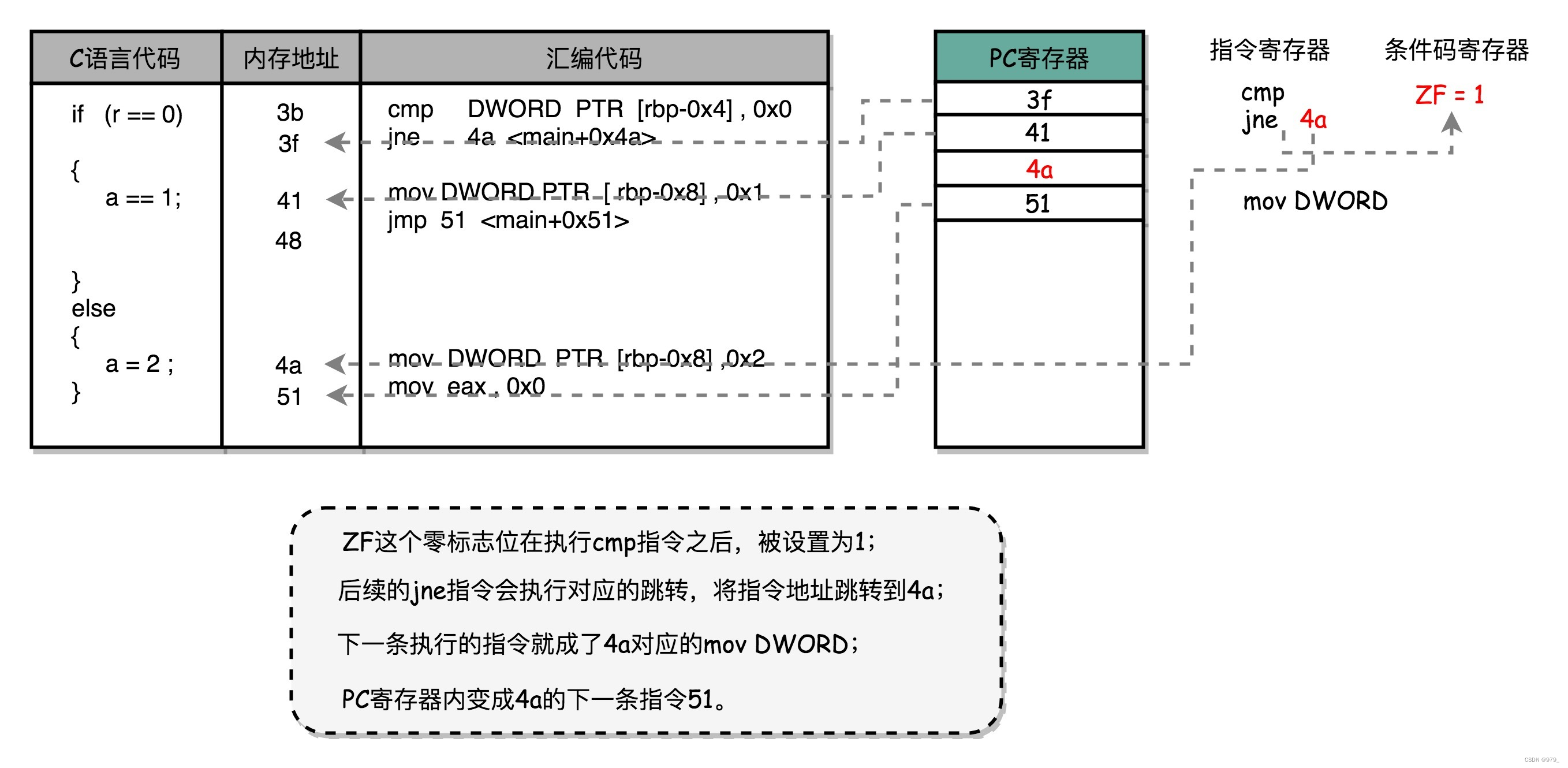
可以看到,这里对于 r == 0 的条件判断,被编译成了 cmp 和 jne 这两条指令。cmp 指令比较了前后两个操作数的值,
这里的 DWORD PTR 代表操作的数据类型是 32 位的整数,而[rbp-0x4]则是变量 r 的内存地址。
所以,第一个操作数就是从内存里拿到的变量 r 的值。第二个操作数 0x0 就是我们设定的常量 0 的 16 进制表示。
cmp 指令的比较结果,会存入到 条件码寄存器 当中去。
–> 在这里,如果比较的结果是 True,也就是 r == 0,就把零标志条件码(对应的条件码是 ZF,Zero Flag)设置为 1。
–> Intel 的 CPU 下还有进位标志(CF,Carry Flag)、符号标志(SF,Sign Flag)以及溢出标志(OF,Overflow Flag)cmp 指令执行完成之后,PC 寄存器会自动自增,开始执行下一条 jne 的指令。
跟着的 jne 指令,是 jump if not equal 的意思,它会查看对应的零标志位。
–> 如果 ZF 为 1,说明上面的比较结果是 TRUE
–> 如果是 ZF 是 0,也就是上面的比较结果是 False,会跳转到后面跟着的操作数 4a 的位置。这个 4a,对应这里汇编代码的行号,也就是上面设置的 else 条件里的第一条指令。
当跳转发生的时候,PC 寄存器就不再是自增变成下一条指令的地址,而是被直接设置成这里的 4a 这个地址。
这个时候,CPU 再把 4a 地址里的指令加载到 指令寄存器 中来执行。 -
mov DWORD PTR [rbp-0x8],0x2
跳转到执行地址为 4a 的指令,实际是一条 mov 指令,
第一个操作数和前面的 cmp 指令一样,是另一个 32 位整型的内存地址,以及 2 的对应的 16 进制值 0x2。
mov 指令把 2 设置到对应的内存里去,相当于一个赋值操作。
然后,PC 寄存器里的值继续自增,执行下一条 mov 指令。 -
mov eax,0x0
这条 mov 指令的第一个操作数 eax,代表 累加寄存器 ,第二个操作数 0x0 则是 16 进制的 0 的表示。
这条指令其实没有实际的作用,它的作用是一个占位符。
回过头去看 if 条件,如果满足的话,在赋值的 mov 指令执行完成之后,有一个 jmp 的无条件跳转指令。
跳转的地址就是这一行的地址 51。
我们的 main 函数没有设定返回值,而 mov eax, 0x0 其实就是给 main 函数生成了一个默认的为 0 的返回值到累加器里面。
if 条件里面的内容执行完成之后也会跳转到这里,和 else 里的内容结束之后的位置是一样的。
2.2 指令循环
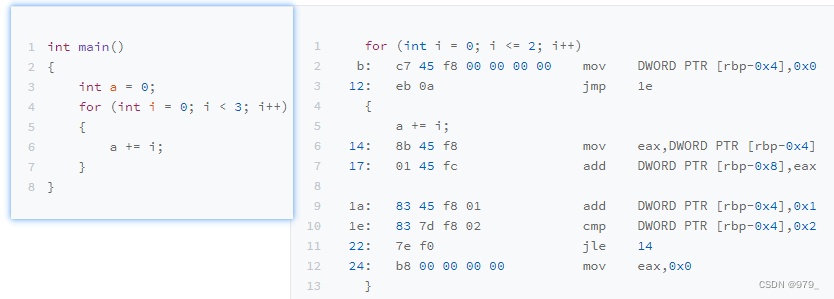
可以看到,对应的循环也是用 1e 这个地址上的 cmp 比较指令,和紧接着的 jle 条件跳转指令来实现的。
主要的差别在于,这里的 jle 跳转的地址,在这条指令之前的地址 14,而非 if…else 编译出来的跳转指令之后。
往前跳转使得条件满足的时候,PC 寄存器会把指令地址设置到之前执行过的指令位置,重新执行之前执行过的指令,
直到条件不满足,顺序往下执行 jle 之后的指令,整个循环才结束。
如果你看一长条打孔卡的话,就会看到卡片往后移动一段,执行了之后,又反向移动,去重新执行前面的指令。
其实,你有没有觉得,jle 和 jmp 指令,有点像程序语言里面的 goto 命令,直接指定了一个特定条件下的跳转位置。
虽然我们在用高级语言开发程序的时候反对使用 goto,
但是实际在机器指令层面,无论是 if…else…也好,还是 for/while 也好,都是用和 goto 相同的跳转到特定指令位置的方式来实现的。
想要在硬件层面实现这个 goto 语句,除了本身需要用来保存下一条指令地址,以及当前正要执行指令的 PC 寄存器、指令寄存器外,
我们只需要再增加一个条件码寄存器,来保留条件判断的状态。
这样简简单单的三个寄存器,就可以实现条件判断和循环重复执行代码的功能。
3. 函数调用
3.1 程序栈
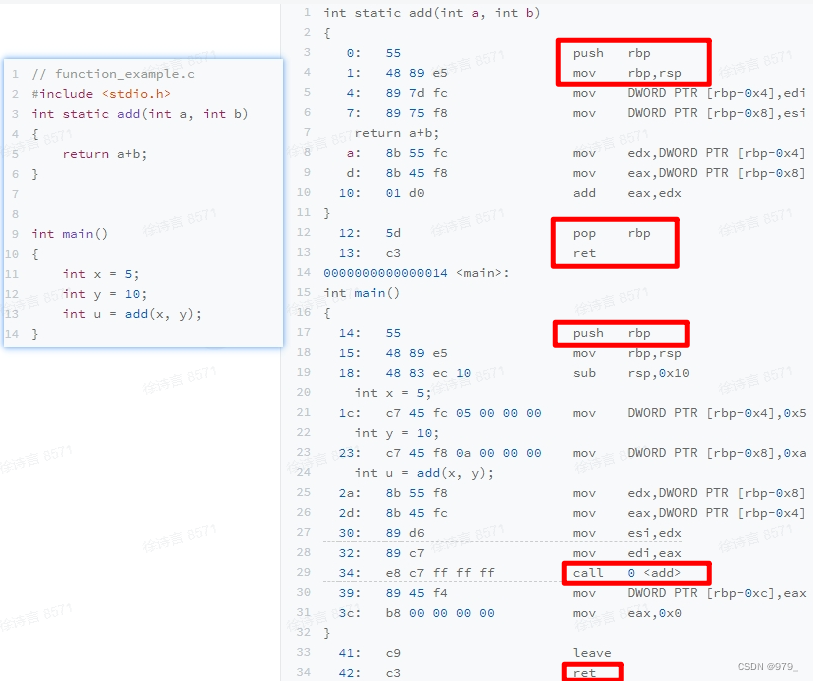
add 函数编译之后,代码先执行了一条 push 指令和一条 mov 指令;
在函数执行结束的时候,又执行了一条 pop 和一条 ret 指令。
这四条指令的执行,其实就是在进行我们接下来要讲**压栈(Push)和出栈(Pop)**操作。
函数调用和上一节我们讲的 if…else 和 for/while 循环有点像。
它们两个都是在原来顺序执行的指令过程里,执行了一个内存地址的跳转指令,
让指令从原来顺序执行的过程里跳开,从新的跳转后的位置开始执行。
但是,这两个跳转有个区别,if…else 和 for/while 的跳转,是跳转走了就不再回来了,就在跳转后的新地址开始顺序地执行指令。
而函数调用的跳转,在对应函数的指令执行完了之后,还要再回到函数调用的地方,继续执行 call 之后的指令。
有没有一个可以不跳转回到原来开始的地方,来实现函数的调用呢?直觉上似乎有这么一个解决办法。
能不能把后面要跳回来执行的指令地址给记录下来呢?
就像前面讲 PC 寄存器一样,我们可以专门设立一个“程序调用寄存器”,来存储接下来要跳转回来执行的指令地址。
等到函数调用结束,从这个寄存器里取出地址,再跳转到这个记录的地址,继续执行就好了。
但是在多层函数调用里,简单只记录一个地址也是不够的。
我们在调用函数 A 之后,A 还可以调用函数 B,B 还能调用函数 C。这一层又一层的调用并没有数量上的限制。
在所有函数调用返回之前,每一次调用的返回地址都要记录下来,但是我们 CPU 里的寄存器数量并不多。
像我们一般使用的 Intel i7 CPU 只有 16 个 64 位寄存器,调用的层数一多就存不下了。
我们在内存里面开辟一段空间,用栈这个后进先出(LIFO,Last In First Out)的数据结构。
栈就像一个乒乓球桶,每次程序调用函数之前,我们都把调用返回后的地址写在一个乒乓球上,然后塞进这个球桶。
这个操作其实就是我们常说的压栈。
如果函数执行完了,我们就从球桶里取出最上面的那个乒乓球,很显然,这就是出栈。
拿到出栈的乒乓球,找到上面的地址,把程序跳转过去,就返回到了函数调用后的下一条指令了。
如果函数 A 在执行完成之前又调用了函数 B,那么在取出乒乓球之前,我们需要往球桶里塞一个乒乓球。
而我们从球桶最上面拿乒乓球的时候,拿的也一定是最近一次的,也就是最下面一层的函数调用完成后的地址。
乒乓球桶的底部,就是栈底,最上面的乒乓球所在的位置,就是栈顶。
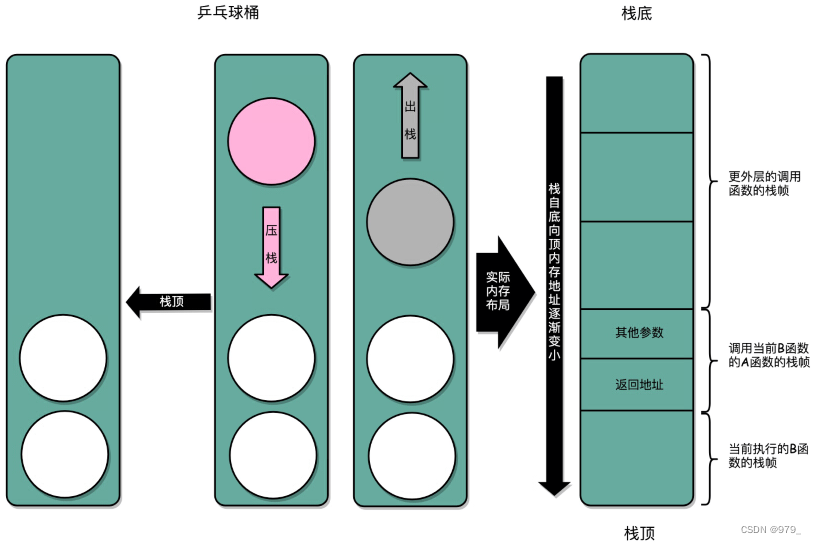
在真实的程序里,压栈的不只有函数调用完成后的返回地址。
比如函数 A 在调用 B 的时候,需要传输一些参数数据,这些参数数据在寄存器不够用的时候也会被压入栈中。
整个函数 A 所占用的所有内存空间,就是函数 A 的栈帧(Stack Frame)。
而实际的程序栈布局,顶和底与我们的乒乓球桶相比是倒过来的。
底在最上面,顶在最下面,这样的布局是因为栈底的内存地址是在一开始就固定的。
而一层层压栈之后,栈顶的内存地址是在逐渐变小而不是变大。
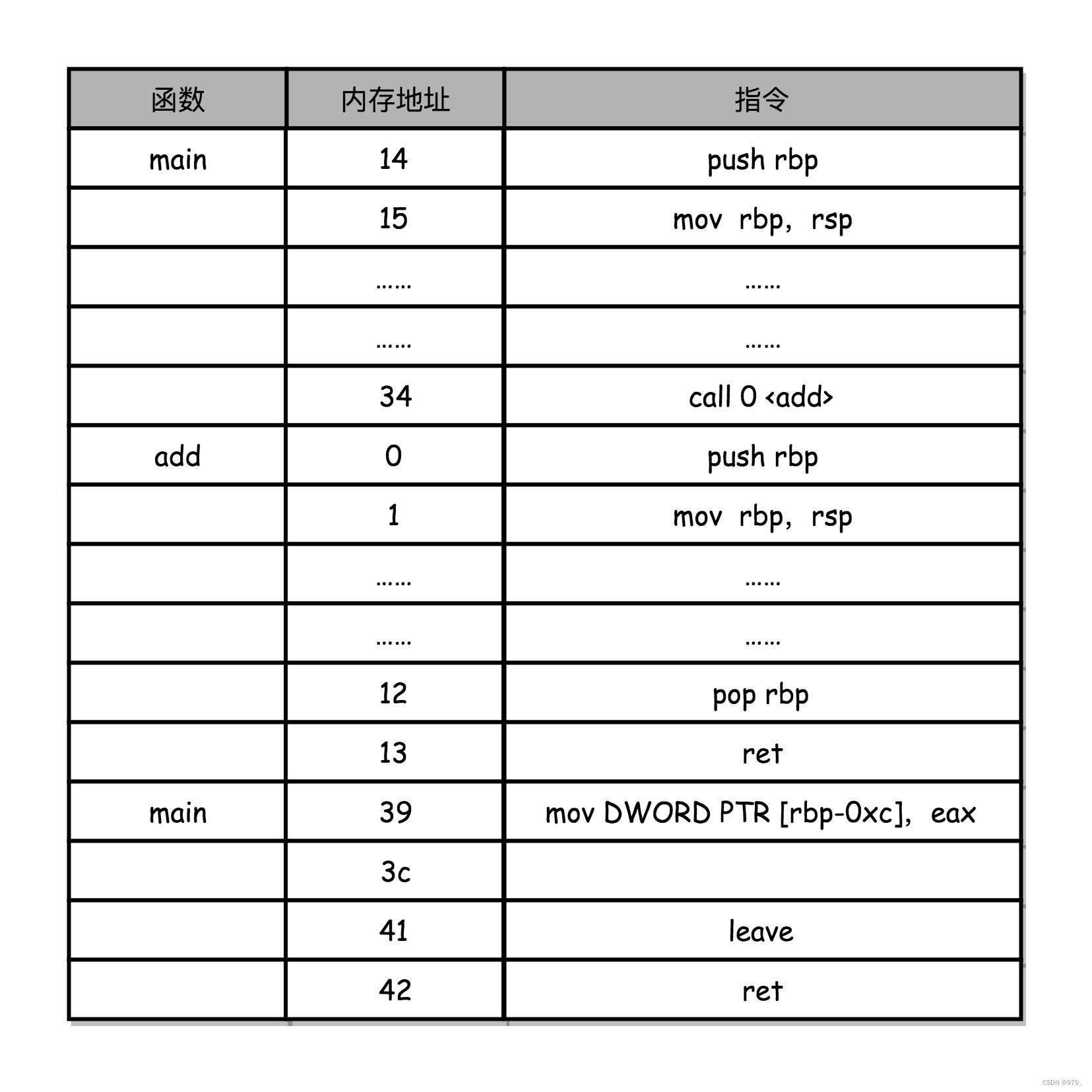
图中,rbp 是 register base pointer 栈基址寄存器(栈帧指针),指向当前栈帧的栈底地址。
rsp 是 register stack pointer 栈顶寄存器(栈指针),指向栈顶元素。
我们在调用第 34 行的 call 指令时,会把当前的 PC 寄存器里的下一条指令的地址压栈,保留函数调用结束后要执行的指令地址。
而 add 函数的第 0 行,push rbp 这个指令,就是在进行压栈。
这里的 rbp 又叫栈帧指针(Frame Pointer),是一个存放了当前栈帧位置的寄存器。
push rbp 就把之前调用函数,也就是 main 函数的栈帧的栈底地址,压到栈顶。
接着,第 1 行的一条命令 mov rbp, rsp 里,则是把 rsp 这个栈指针(Stack Pointer)的值复制到 rbp 里,而 rsp 始终会指向栈顶。
这个命令意味着,rbp 这个栈帧指针指向的地址,变成当前最新的栈顶,也就是 add 函数的栈帧的栈底地址了。
而在函数 add 执行完成之后,又会分别调用第 12 行的 pop rbp 来将当前的栈顶出栈,这部分操作维护好了我们整个栈帧。
然后,我们可以调用第 13 行的 ret 指令,这时候同时要把 call 调用的时候压入的 PC 寄存器里的下一条指令出栈,更新到 PC 寄存器中,将程序的控制权返回到出栈后的栈顶。
3.2 构造一个 stack overflow
通过引入栈,我们可以看到,无论有多少层的函数调用,或者在函数 A 里调用函数 B,再在函数 B 里调用 A,
这样的递归调用,我们都只需要通过维持 rbp 和 rsp,这两个维护栈顶所在地址的寄存器,就能管理好不同函数之间的跳转。
不过,栈的大小也是有限的。
如果函数调用层数太多,我们往栈里压入它存不下的内容,程序在执行的过程中就会遇到栈溢出的错误,
这就是大名鼎鼎的“stack overflow”。
要构造一个栈溢出的错误并不困难,最简单的办法,就是我们上面说的 Infiinite Mirror Effect 的方式,
让函数 A 调用自己,并且不设任何终止条件。
这样一个无限递归的程序,在不断地压栈过程中,将整个栈空间填满,并最终遇上 stack overflow。

除了无限递归,递归层数过深,在栈空间里面创建非常占内存的变量(比如一个巨大的数组)
3.3 利用函数内联进行性能优化
把一个实际调用的函数产生的指令,直接插入到的位置,来替换对应的函数调用指令。
但是如果被调用的函数里,没有调用其他函数,这个方法还是可以行得通的。
事实上,这就是一个常见的编译器进行自动优化的场景,我们通常叫函数内联(Inline)。

除了依靠编译器的自动优化,你还可以在定义函数的地方,加上 inline 的关键字,来提示编译器对函数进行内联。
内联带来的优化是,CPU 需要执行的指令数变少了,根据地址跳转的过程不需要了,压栈和出栈的过程也不用了。
不过内联并不是没有代价,内联意味着,我们把可以复用的程序指令在调用它的地方完全展开了。
如果一个函数在很多地方都被调用了,那么就会展开很多次,整个程序占用的空间就会变大了。
二、程序执行
1. 静态编译
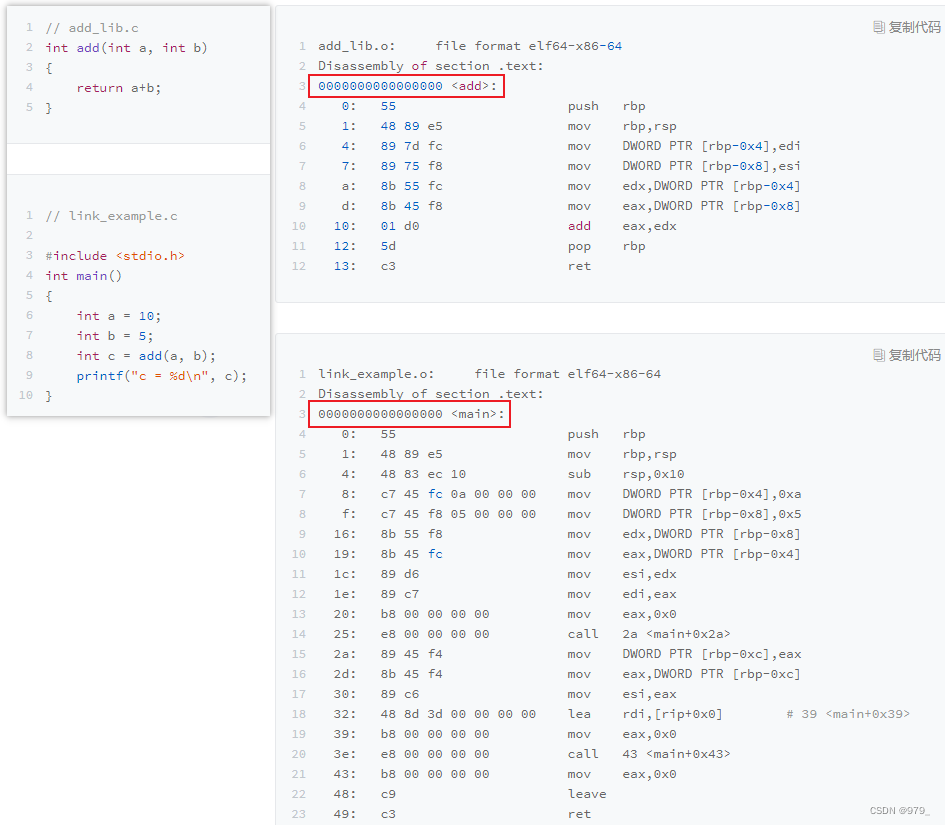
$ gcc -g -c add_lib.c link_example.c
$ objdump -d -M intel -S add_lib.o
$ objdump -d -M intel -S link_example.o
即使通过 chmod 命令赋予 link_example.o 文件可执行的权限,
运行./link_example.o 仍然只会得到一条 cannot execute binary file: Exec format error 的错误。
发现两个程序的地址都是从 0 开始的。
如果地址是一样的,程序如果需要通过 call 指令调用函数的话,它怎么知道应该跳转到哪一个文件里呢?
这么说吧,无论是这里的运行报错,还是 objdump 出来的汇编代码里面的重复地址,
都是因为 add_lib.o 以及 link_example.o 并不是一个可执行文件(Executable Program),而是目标文件(Object File)。
只有通过链接器(Linker)把多个目标文件以及调用的各种函数库链接起来,我们才能得到一个可执行文件。
我们通过 gcc 的 -o 参数,可以生成对应的可执行文件,对应执行之后,就可以得到这个简单的加法调用函数的结果。
实际上,“C 语言代码 - 汇编代码 - 机器码” 这个过程,在我们的计算机上进行的时候是由两部分组成的。
- 第一个部分由编译(Compile)、汇编(Assemble)以及链接(Link)三个阶段组成。
在这三个阶段完成之后,我们就生成了一个可执行文件。 - 第二部分,我们通过装载器(Loader)把可执行文件装载(Load)到内存中。
CPU 从内存中读取指令和数据,来开始真正执行程序。
1.1 ELF
程序最终是通过装载器变成指令和数据的,所以其实我们生成的可执行代码也并不仅仅是一条条的指令。
我们还是通过 objdump 指令,把可执行文件的内容拿出来看看。
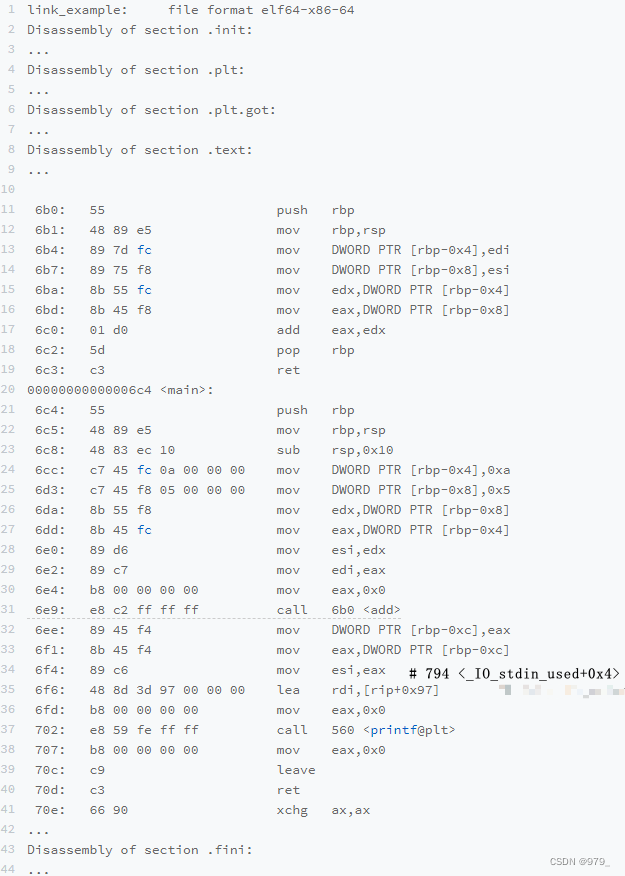
可执行代码 dump 出来内容,和之前的目标代码长得差不多,但是长了很多。
因为在 Linux 下,可执行文件和目标文件所使用的都是一种叫 ELF(Execuatable and Linkable File Format)的文件格式,
中文名字叫可执行与可链接文件格式,
这里面不仅存放了编译成的汇编指令,还保留了很多别的数据。
比如我们过去所有 objdump 出来的代码里,你都可以看到对应的函数名称,
像 add、main 等等,乃至你自己定义的全局可以访问的变量名称,都存放在这个 ELF 格式文件里。
这些名字和它们对应的地址,在 ELF 文件里面,存储在一个叫作符号表(Symbols Table)的位置里。
符号表相当于一个地址簿,把名字和地址关联了起来。
我们先只关注和我们的 add 以及 main 函数相关的部分。
你会发现,这里面,main 函数里调用 add 的跳转地址,不再是下一条指令的地址了,而是 add 函数的入口地址了,
这就是 EFL 格式和链接器的功劳。
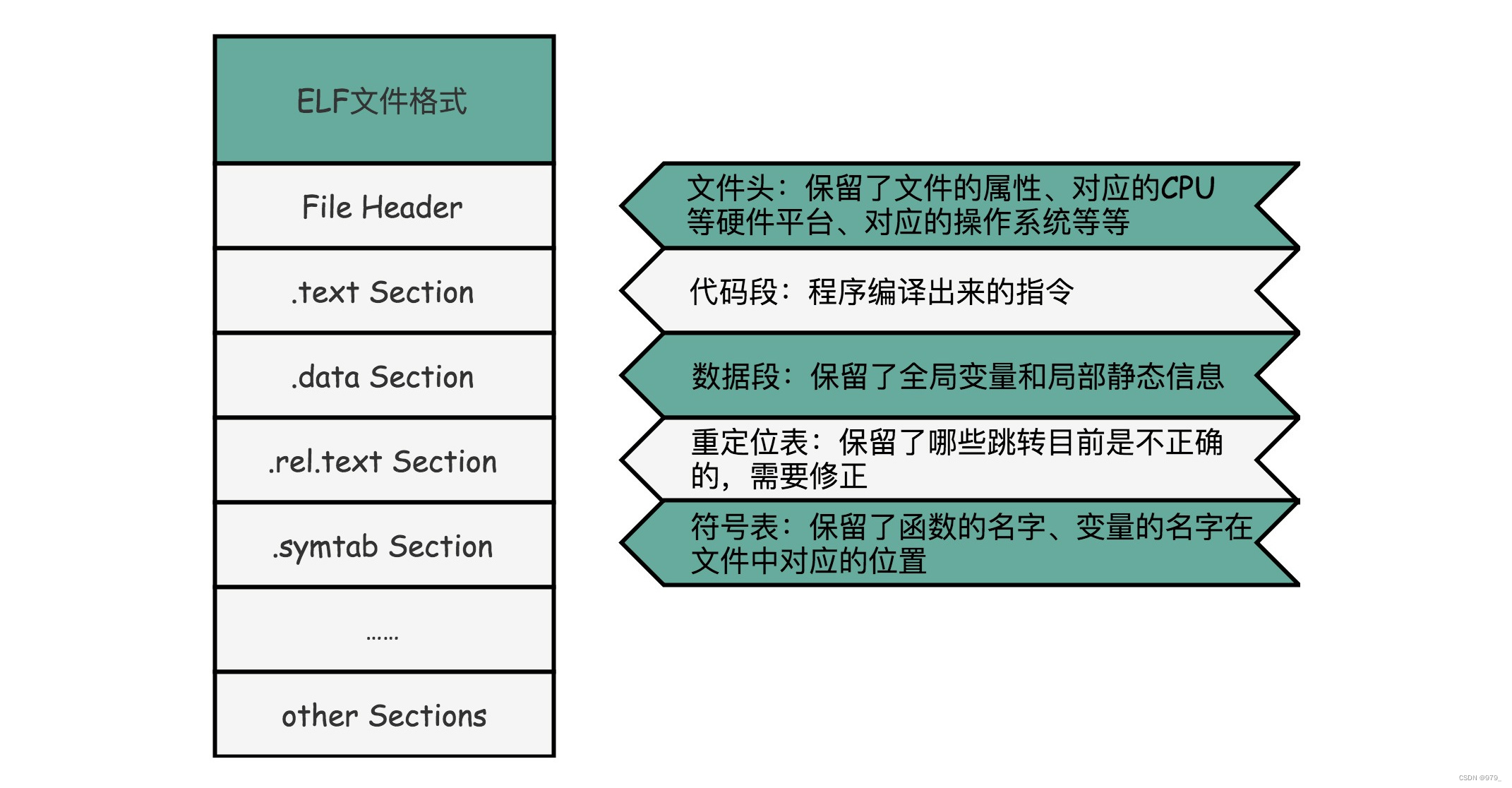
ELF 文件格式把各种信息,分成一个一个的 Section 保存起来。
ELF 有一个 基本的文件头(File Header) ,用来表示这个文件的基本属性,比如是否是可执行文件,对应的 CPU、操作系统等等。
除了这些基本属性之外,大部分程序还有这么一些 Section:
- 首先是 .text Section ,也叫作代码段或者指令段(Code Section),
用来保存程序的代码和指令; - 接着是 .data Section ,也叫作数据段(Data Section),
用来保存程序里面设置好的初始化数据信息; - 然后就是 .rel.text Secion ,叫作重定位表(Relocation Table)。
重定位表里,保留的是当前的文件里面,哪些跳转地址其实是我们不知道的。
比如上面的 link_example.o 里面,我们在 main 函数里面调用了 add 和 printf 这两个函数,
但是在链接发生之前,我们并不知道该跳转到哪里,这些信息就会存储在重定位表里; - 最后是 .symtab Section ,叫作符号表(Symbol Table)。
符号表保留了我们所说的当前文件里面定义的函数名称和对应地址的地址簿。
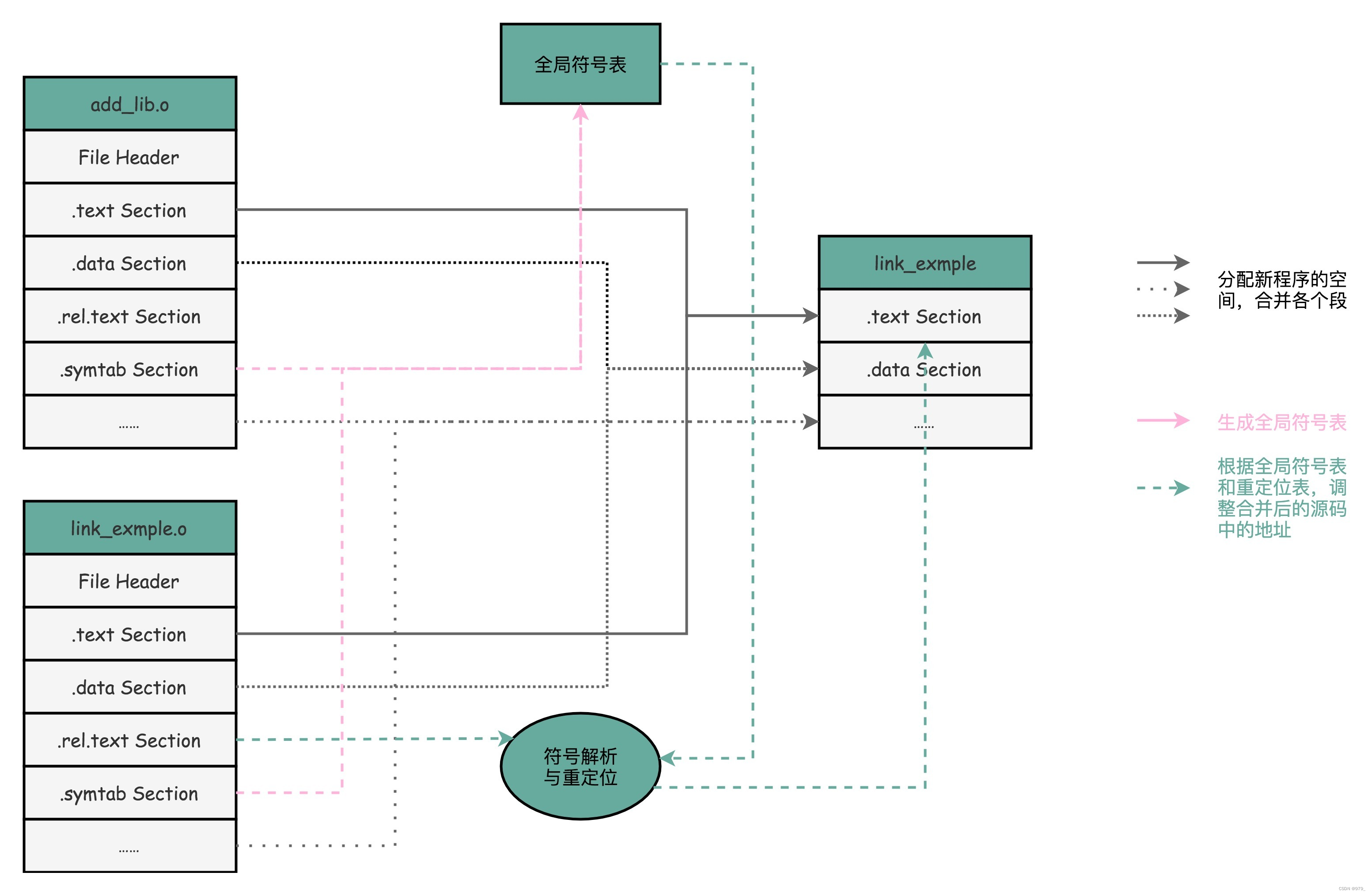
链接器会扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。
然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正。
最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。
这也是为什么,可执行文件里面的函数调用的地址都是正确的。
在链接器把程序变成可执行文件之后,要装载器去执行程序就容易多了。
装载器不再需要考虑地址跳转的问题,只需要解析 ELF 文件,把对应的指令和数据,加载到内存里面供 CPU 执行就可以了。
为什么同样一个程序,在 Linux 下可以执行而在 Windows 下不能执行了。
其中一个非常重要的原因就是,两个操作系统下可执行文件的格式不一样。
我们今天讲的是 Linux 下的 ELF 文件格式,而 Windows 的可执行文件格式是一种叫作 PE(Portable Executable Format)的文件格式。
Linux 下的装载器只能解析 ELF 格式而不能解析 PE 格式。
如果我们有一个可以能够解析 PE 格式的装载器,我们就有可能在 Linux 下运行 Windows 程序了。这样的程序真的存在吗?
没错,Linux 下著名的开源项目 Wine,就是通过兼容 PE 格式的装载器,使得我们能直接在 Linux 下运行 Windows 程序的。
而现在微软的 Windows 里面也提供了 WSL,也就是 Windows Subsystem for Linux,可以解析和加载 ELF 格式的文件。
我们去写可以用的程序,也不仅仅是把所有代码放在一个文件里来编译执行,而是可以拆分成不同的函数库,
最后通过一个静态链接的机制,使得不同的文件之间既有分工,又能通过静态链接来“合作”,变成一个可执行的程序。
对于 ELF 格式的文件,为了能够实现这样一个静态链接的机制,里面不只是简单罗列了程序所需要执行的指令,
还会包括链接所需要的重定位表和符号表。
1.2 程序装载
通过链接器,把多个文件合并成一个最终可执行文件。
在运行这些可执行文件的时候,我们其实是通过一个装载器,解析 ELF 或者 PE 格式的可执行文件。
装载器会把对应的指令和数据加载到内存里面来,让 CPU 去执行。
说起来只是装载到内存里面这一句话的事儿,实际上装载器需要满足两个要求。
-
可执行程序加载后占用的内存空间应该是连续的。
执行指令的时候,程序计数器是顺序地一条一条指令执行下去。
这也就意味着,这一条条指令需要连续地存储在一起。 -
我们需要同时加载很多个程序,并且不能让程序自己规定在内存中加载的位置。
虽然编译出来的指令里已经有了对应的各种各样的内存地址,
但是实际加载的时候,我们其实没有办法确保,这个程序一定加载在哪一段内存地址上。
因为我们现在的计算机通常会同时运行很多个程序,可能你想要的内存地址已经被其他加载了的程序占用了。
可以在内存里面,找到一段连续的内存空间,然后分配给装载的程序,
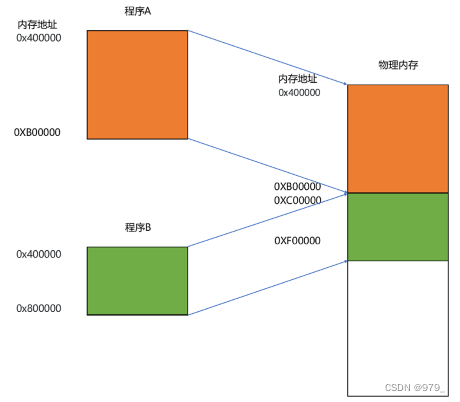
然后把这段连续的内存空间地址,和整个程序指令里指定的内存地址做一个映射。
把指令里用到的内存地址叫作虚拟内存地址(Virtual Memory Address),
实际在内存硬件里面的空间地址,我们叫物理内存地址(Physical Memory Address)。
程序里有指令和各种内存地址,我们只需要关心虚拟内存地址就行了。
对于任何一个程序来说,它看到的都是同样的内存地址。
我们维护一个虚拟内存到物理内存的映射表,这样实际程序指令执行的时候,会通过虚拟内存地址,找到对应的物理内存地址,然后执行。
因为是连续的内存地址空间,所以我们只需要维护映射关系的起始地址和对应的空间大小就可以了。
1.3 内存分段/分页
这种找出一段连续的物理内存和虚拟内存地址进行映射的方法,我们叫分段(Segmentation)。
这里的段,就是指系统分配出来的那个连续的内存空间。
-
优点
分段的办法很好,解决了程序本身不需要关心具体的物理内存地址的问题 -
缺点
-
内存碎片
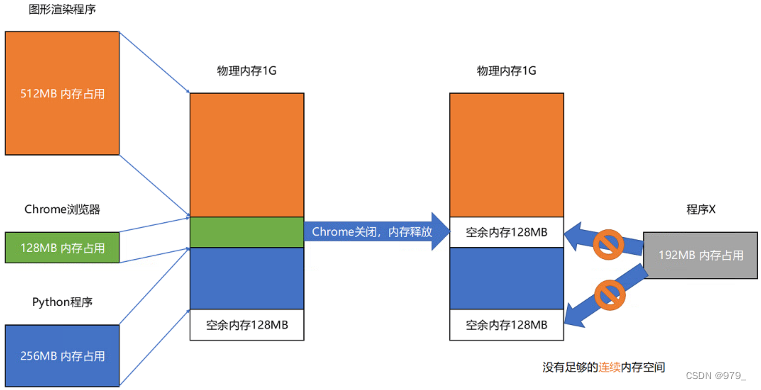
解决的办法叫内存交换(Memory Swapping)
把 Python 程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里面。
不过读回来的时候,我们不再把它加载到原来的位置,而是紧紧跟在那已经被占用了的 512MB 内存后面。
这样,我们就有了连续的 256MB 内存空间,就可以去加载一个新的 200MB 的程序。
如果你自己安装过 Linux 操作系统,你应该遇到过分配一个 swap 硬盘分区的问题。
这块分出来的磁盘空间,其实就是专门给 Linux 操作系统进行内存交换用的。 -
性能瓶颈
硬盘的访问速度要比内存慢很多,而每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。
所以,如果内存交换的时候,交换的是一个很占内存空间的程序,这样整个机器都会显得卡顿。
当需要进行内存交换的时候,让需要交换写入或者从磁盘装载的数据更少一点,这样就可以解决这个问题。
这个办法,在现在计算机的内存管理里面,就叫作内存分页(Paging)。和分段这样分配一整段连续的空间给到程序相比,分页是把整个物理内存空间切成一段段固定尺寸的大小。
而对应的程序所需要占用的虚拟内存空间,也会同样切成一段段固定尺寸的大小。
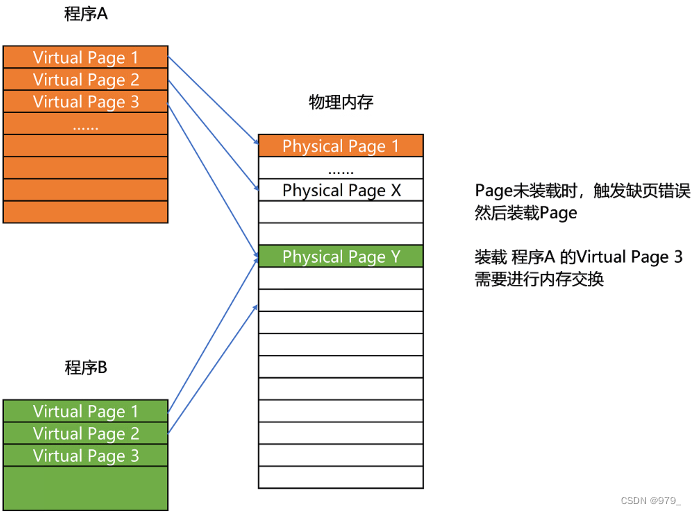
这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。
从虚拟内存到物理内存的映射,不再是拿整段连续的内存的物理地址,而是按照一个一个页来的。
页的尺寸一般远远小于整个程序的大小。在 Linux 下,我们通常只设置成 4KB。由于内存空间都是预先划分好的,也就没有了不能使用的碎片,而只有被释放出来的很多 4KB 的页。
即使内存空间不够,需要让现有的、正在运行的其他程序,通过内存交换释放出一些内存的页出来,
一次性写入磁盘的也只有少数的一个页或者几个页,
不会花太多时间,让整个机器被内存交换的过程给卡住。
更进一步地,分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。
我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,
而是只在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。实际上,我们的操作系统,的确是这么做的。
当要读取特定的页,却发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault)。
我们的操作系统会捕捉到这个错误,然后将对应的页,从存放在硬盘上的虚拟内存里读取出来,加载到物理内存里。
这种方式,使得我们可以运行那些远大于我们实际物理内存的程序。
同时,这样一来,任何程序都不需要一次性加载完所有指令和数据,只需要加载当前需要用到就行了。
-
通过虚拟内存、内存交换和内存分页这三个技术的组合,
我们最终得到了一个让程序不需要考虑实际的物理内存地址、大小和当前分配空间的解决方案。
这些技术和方法,对于我们程序的编写、编译和链接过程都是透明的。
这也是我们在计算机的软硬件开发中常用的一种方法,就是加入一个间接层。
通过引入虚拟内存、页映射和内存交换,我们的程序本身,就不再需要考虑对应的真实的内存地址、程序加载、内存管理等问题了。
任何一个程序,都只需要把内存当成是一块完整而连续的空间来直接使用。
在虚拟内存、内存交换和内存分页这三者结合之下,你会发现,其实要运行一个程序,“必需”的内存是很少的。
CPU 只需要执行当前的指令,极限情况下,内存也只需要加载一页就好了。再大的程序,也可以分成一页。
每次,只在需要用到对应的数据和指令的时候,从硬盘上交换到内存里面来就好了。
以我们现在 4K 内存一页的大小,640K 内存也能放下足足 160 页呢,
也无怪乎在比尔·盖茨会说出“640K ought to be enough for anyone”这样的话。
2. 动态链接
程序的链接,是把对应的不同文件内的代码段,合并到一起,成为最后的可执行文件。
这个链接的方式,让我们在写代码的时候做到了“复用”。
同样的功能代码只要写一次,然后提供给很多不同的程序进行链接就行了。
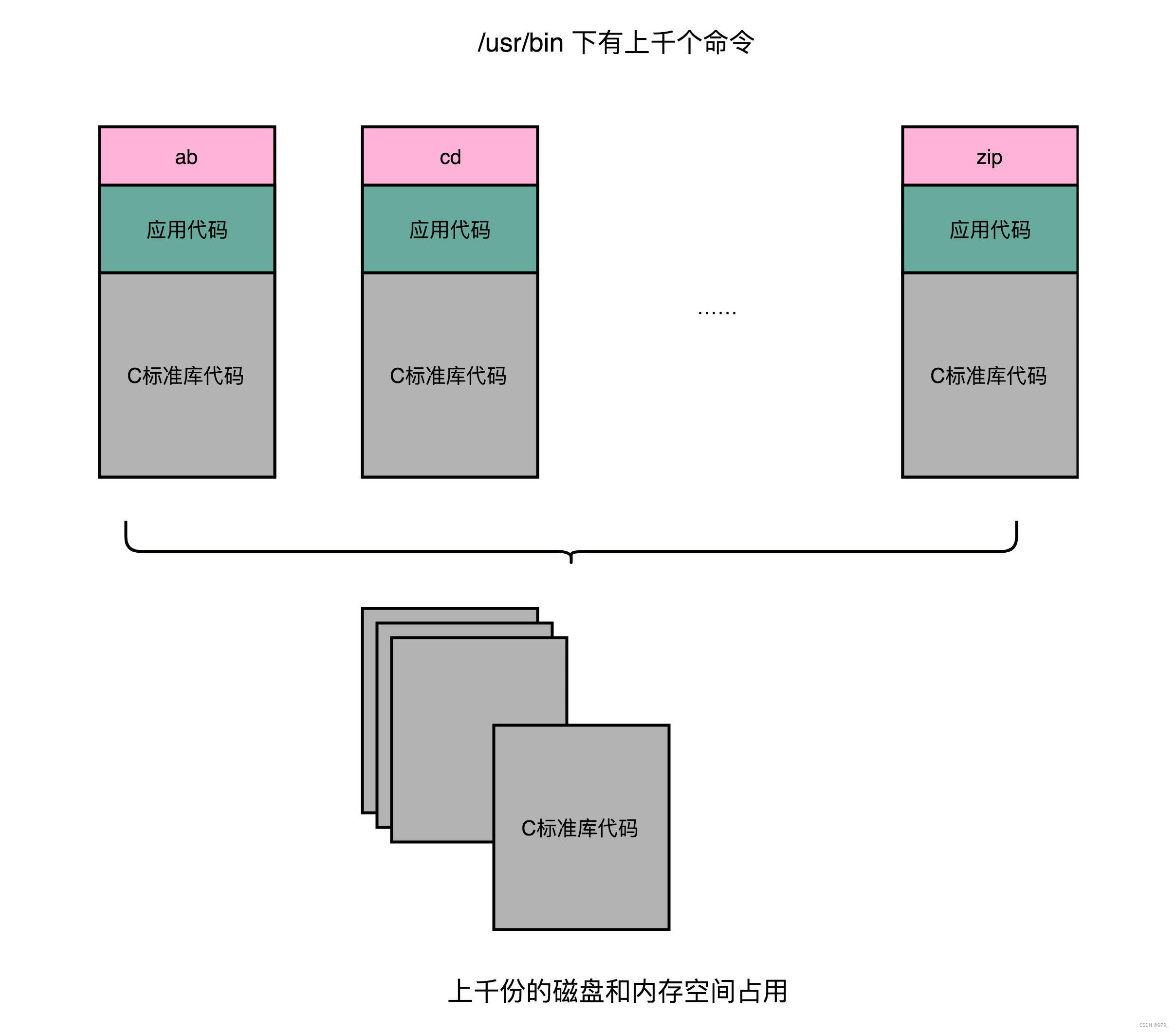
但是,如果我们有很多个程序都要通过装载器装载到内存里面,
那里面链接好的同样的功能代码,也都需要再装载一遍,再占一遍内存空间。
这就好比,假设每个人都有骑自行车的需要,那我们给每个人都生产一辆自行车带在身边,
固然大家都有自行车用了,但是马路上肯定会特别拥挤。
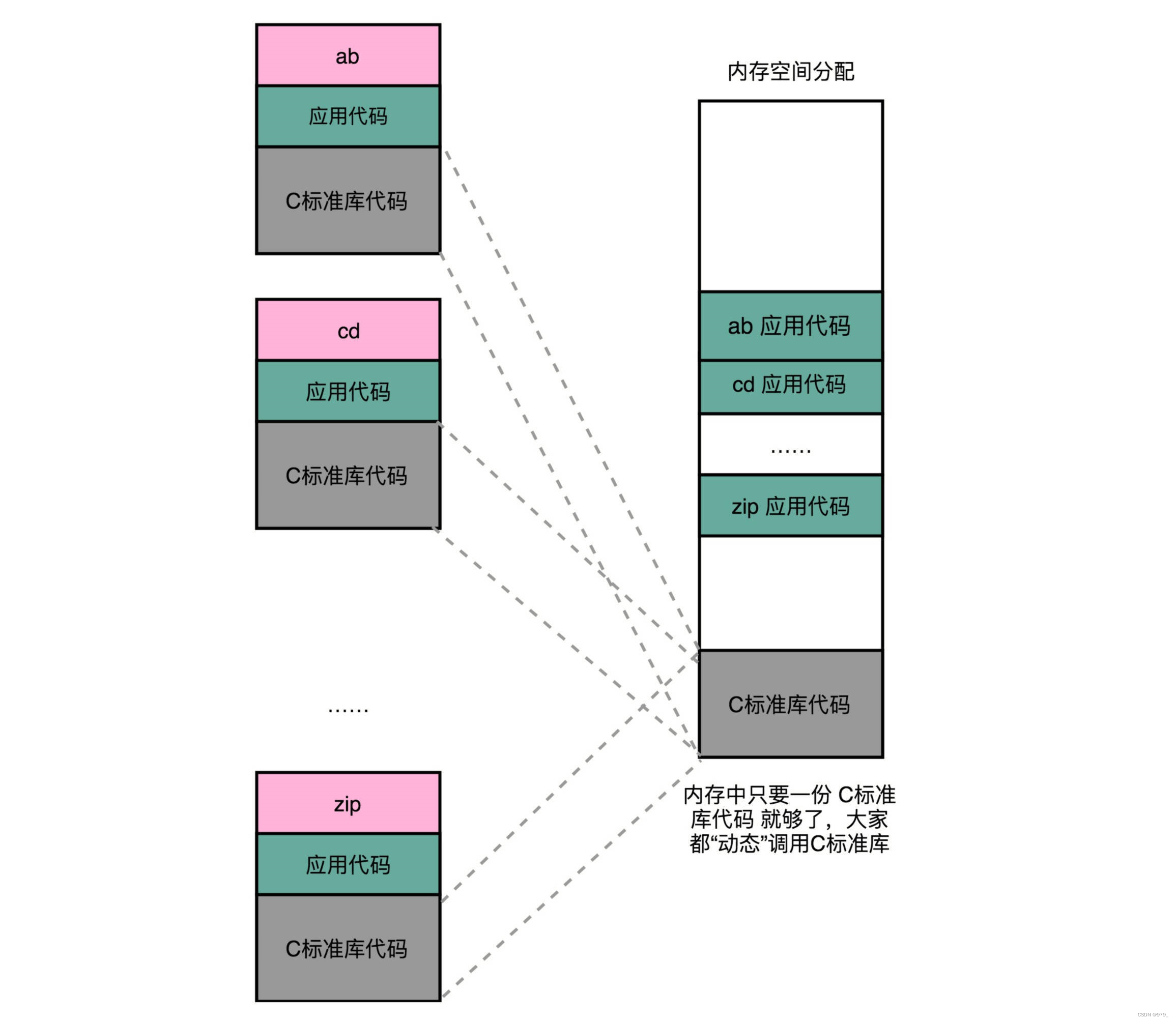
在动态链接的过程中,我们想要“链接”的,不是存储在硬盘上的目标文件代码,而是加载到内存中的共享库(Shared Libraries)。
顾名思义,这里的共享库重在“共享“这两个字。
这个加载到内存中的共享库会被很多个程序的指令调用到。
在 Windows 下,这些共享库文件就是.dll 文件,也就是 Dynamic-Link Libary(DLL,动态链接库)。
在 Linux 下,这些共享库文件就是.so 文件,也就是 Shared Object(一般我们也称之为动态链接库)。
这两大操作系统下的文件名后缀,一个用了“动态链接”的意思,另一个用了“共享”的意思,正好覆盖了两方面的含义。
不过,要想要在程序运行的时候共享代码,也有一定的要求,就是这些机器码必须是“地址无关”的。
也就是说,我们编译出来的共享库文件的指令代码,是地址无关码(Position-Independent Code)。
换句话说就是,这段代码,无论加载在哪个内存地址,都能够正常执行。如果不是这样的代码,就是地址相关的代码。
而常见的地址相关的代码,比如绝对地址代码(Absolute Code)、利用重定位表的代码等等,都是地址相关的代码。
重定位表,在程序链接的时候,我们就把函数调用后要跳转访问的地址确定下来了,
这意味着,如果这个函数加载到一个不同的内存地址,跳转就会失败。
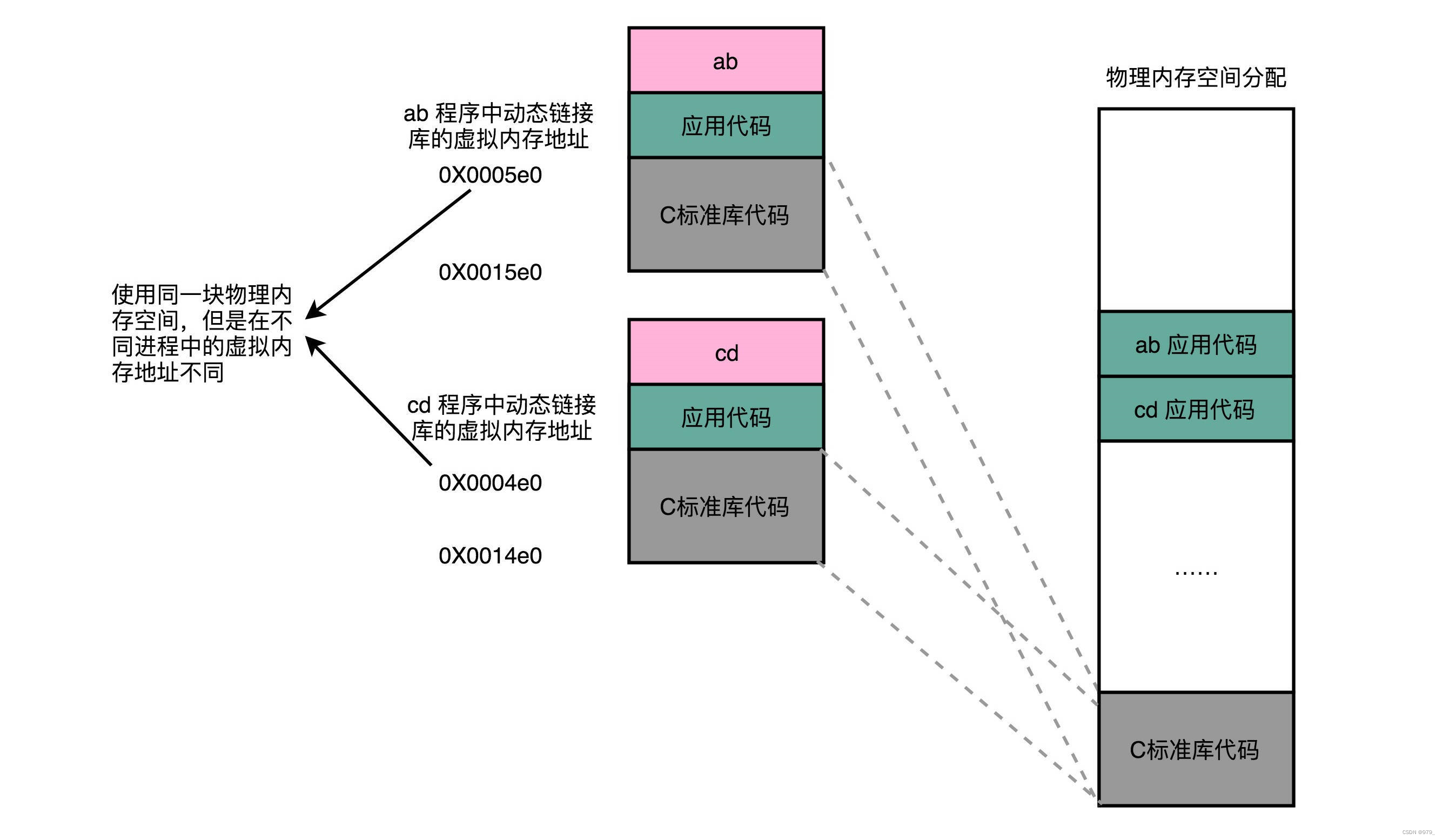
对于所有动态链接共享库的程序来讲,虽然我们的共享库用的都是同一段物理内存地址,
但是在不同的应用程序里,它所在的虚拟内存地址是不同的。
我们没办法、也不应该要求动态链接同一个共享库的不同程序,必须把这个共享库所使用的虚拟内存地址变成一致。
如果这样的话,我们写的程序就必须明确地知道内部的内存地址分配。
动态代码库内部的变量和函数调用都很容易解决,我们只需要使用**相对地址(Relative Address)**就好了。
各种指令中使用到的内存地址,给出的不是一个绝对的地址空间,而是一个相对于当前指令偏移量的内存地址。
因为整个共享库是放在一段连续的虚拟内存地址中的,无论装载到哪一段地址,不同指令之间的相对地址都是不变的。
2.1 PLT/GOT
首先,lib.h 定义了动态链接库的一个函数 show_me_the_money。
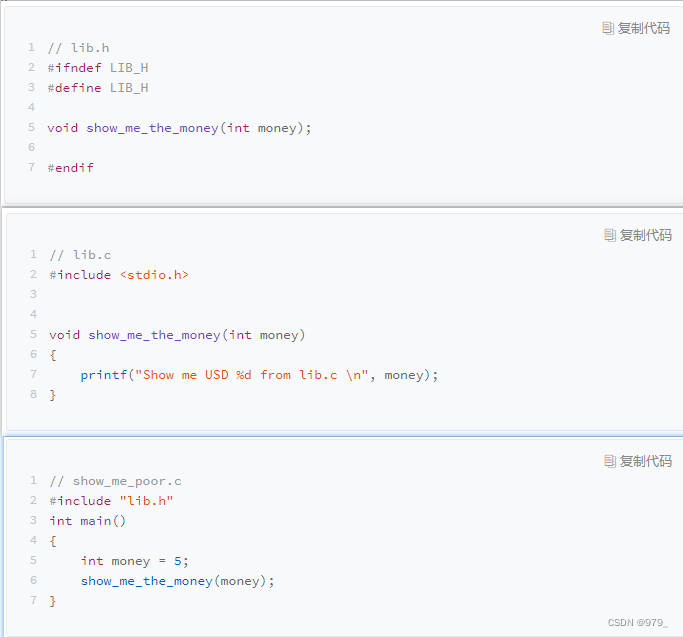
最后,我们把 lib.c 编译成了一个动态链接库,也就是 .so 文件。
$ gcc lib.c -fPIC -shared -o lib.so
$ gcc -o show_me_poor show_me_poor.c ./lib.so
你可以看到,在编译的过程中,我们指定了一个 -fPIC 的参数。
这个参数其实就是 Position Independent Code 的意思,也就是我们要把这个编译成一个地址无关代码。
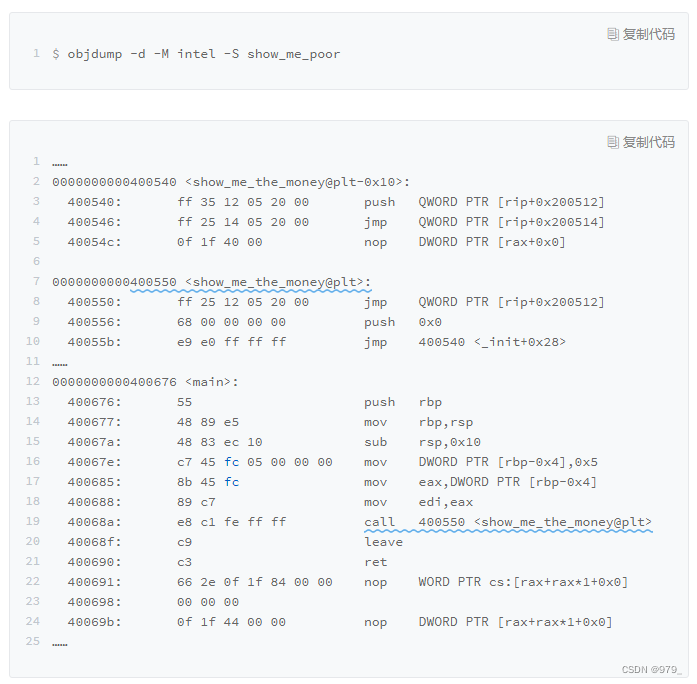
这里后面有一个 @plt 的关键字,代表了我们需要从 PLT,也就是 程序链接表(Procedure Link Table) 里面找要调用的函数。
对应的地址呢,则是 400550 这个地址。
那当我们把目光挪到上面的 400550 这个地址,你又会看到里面进行了一次跳转,
这个跳转指定的跳转地址,你可以在后面的注释里面可以看到,GLOBAL_OFFSET_TABLE+0x18。
这里的 GLOBAL_OFFSET_TABLE,就是我接下来要说的全局偏移表。
在动态链接对应的共享库,我们在共享库的 data section 里面,保存了一张 全局偏移表(GOT,Global Offset Table)。
虽然共享库的代码部分的物理内存是共享的,但是数据部分是各个动态链接它的应用程序里面各加载一份的。
所有需要引用当前共享库外部的地址的指令,都会查询 GOT,来找到当前运行程序的虚拟内存里的对应位置。
而 GOT 表里的数据,则是在我们加载一个个共享库的时候写进去的。
不同的进程,调用同样的 lib.so,各自 GOT 里面指向最终加载的动态链接库里面的虚拟内存地址是不同的。
这样,虽然不同的程序调用的同样的动态库,各自的内存地址是独立的,调用的又都是同一个动态库,
但是不需要去修改动态库里面的代码所使用的地址,而是各个程序各自维护好自己的 GOT,能够找到对应的动态库就好了。
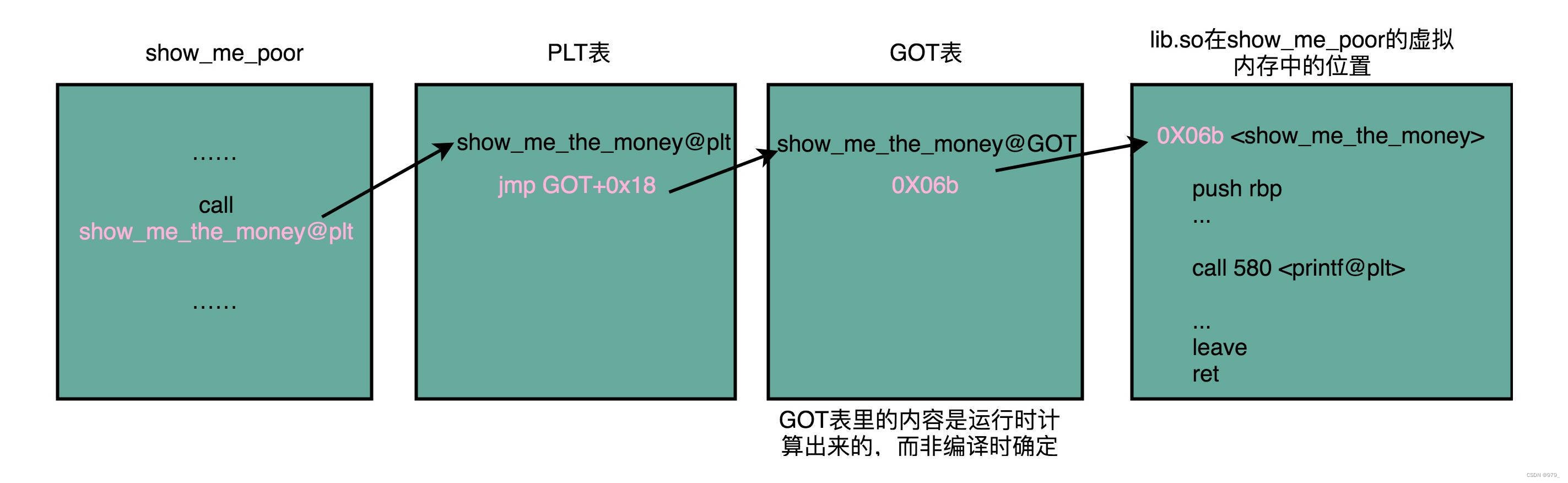
GOT 表位于共享库自己的数据段里。GOT 表在内存里和对应的代码段位置之间的偏移量,始终是确定的。
这样,我们的共享库就是地址无关的代码,对应的各个程序只需要在物理内存里面加载同一份代码。
而我们又要通过各个可执行程序在加载时,生成的各不相同的 GOT 表,来找到它需要调用到的外部变量和函数的地址。
这是一个典型的、不修改代码,而是通过修改“地址数据”来进行关联的办法。
它有点像我们在 C 语言里面用函数指针来调用对应的函数,并不是通过预先已经确定好的函数名称来调用,
而是利用当时它在内存里面的动态地址来调用。