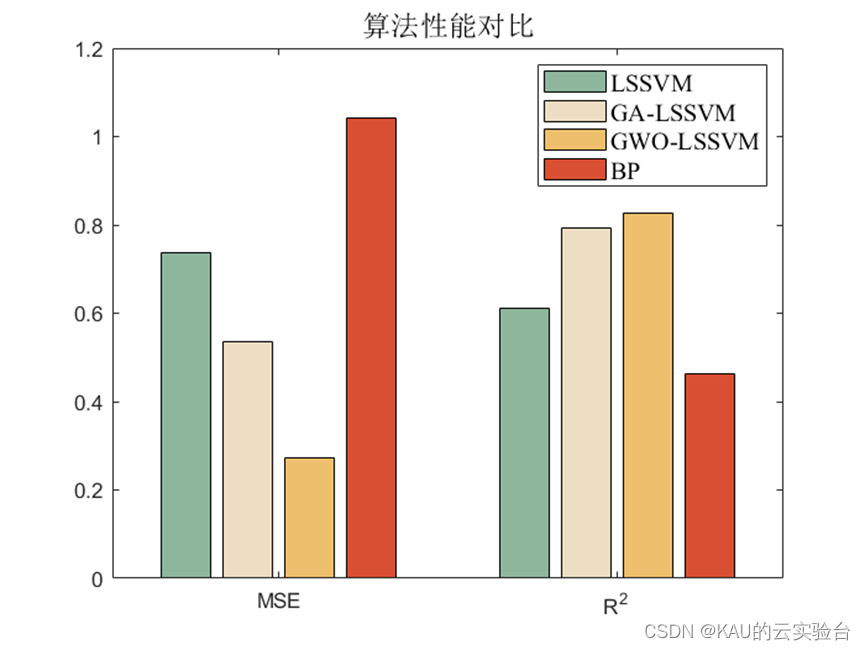
DevOps 体系是从原始运维一步步走过来的,原始运维好比是本,有了本进而想继续提升效率、减少出错、优化流程,就发展到了 DevOps,AIOps……各种Ops
首先,运维的业务职能规范后形成章程、纲领,在互联网快速发展的特点下,形成了一套应对”快”和”变”的体系,并不停的迭代升级,工作这些年,体会到千象背后是有恒道的,运维工作一直围绕高 SLA 和低成本的业务目标运转着,只是工具在围绕着体系变来变去。从开发的角度理解,运维体系就像是算法,实现算法的语言就像是工具,DevOps 就是工具的升级。
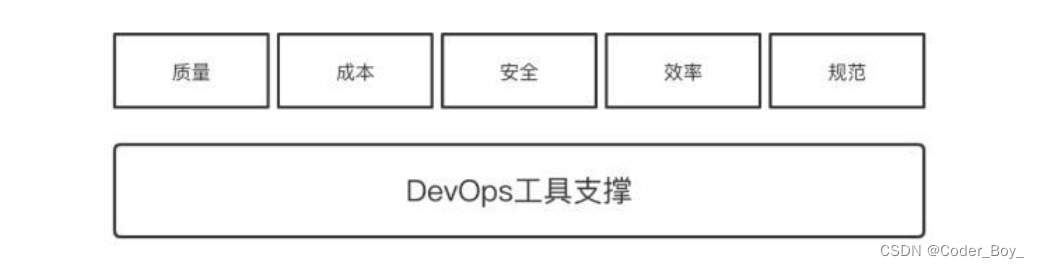
工具的本质其实是一个基础支撑,有了这个支撑,一系列目标的实现才更科学、高效,简单示意如下。
原始阶段,运维工程师与各部门无数的磨合、探索下,慢慢形成了最初的体系,其无形的规范着运维的工作和注意事项,工程师通过这个纲领开展日常工作并保障业务的健康发展,这个阶段可以说是制度为王、制度规范,没有系统的运维平台,有的只是零散的一些大小工具,各种事物基本靠人工、靠制度、靠约束,虽是原始阶段,但也是运维最真实的样子,忙碌而又忙碌,效率总跟不上需求,制度总跟不上执行,与开发的协作总难同一频道,需要大量的运维人力。
再向后发展,为了提高效率的同时解决与开发间的沟通协作问题,提出了 DevOps,大家开始做自动化、做 DevOps 文化,这个自动化其本质是把运维体系落在一个到多个系统上,通过自动化系统来提高工作效率,同时用系统来实现制度,开发和运维都在一个系统上协作,遵守同样的规则,协作上也高效多了,这个阶段到了技术为王、平台规范,市场上出现了运维开发,出现了 SRE,各种问题得到了有效的解决,当然解决的程度取决 DevOps 系统做的优劣,这个就参差不齐了,但出现了这个发展方向。
再向后发展,行业领头羊提出要进一步减少人工参与,用机器自动化替换人工自动化,进而出现了 AIOps。
细心观察,从原始运维向 DevOps 的演进过程,就是越来越注重技术解决问题的过程,人员需要越来越少,能用技术替代的岗位慢慢被替代,随着自动化平台的成熟稳定,理论上理想的终极状态可能只留”运维平台+业务运维“,其他运维转岗业务运维,业务运维转岗技术运营。
那么我们如何思考设计一套 DevOps 运维服务体系呢?总结下来,一个最小的模型为定业务规范、建工作制度、搭 DevOps 系统,以此为最小单元循环往复、迭代升级。
一、定业务规范
先讲个美国人与中国人种地的事儿,美国人建立农场,把种地标准化流程化后,引入工具,几个人种几百亩地收成高、成本低反而不累,中国人每个人几亩地各自作业,收成低、成本高反而都很累。
做运维我感觉也是这个道理,想要批量化、高效率的作业就要规范化,制定各种标准形成规范,如果每个服务各自为战,就会出现乌泱泱一群人确实忙的脚不离地儿,但就是不出活儿。
那么我们通过 DevOps 要批量管理哪些东西呢,集中一下大概就是资源、服务、规范三类,资源包括像服务器、网络设备、负载均衡、证书、域名、代码、容器等,服务包括像围绕运维提供的服务监控告警、CI/CD、日志分析、服务预案、配置管理等,规范包括像流程、资源、服务的各种标准化等,简单示意如下。
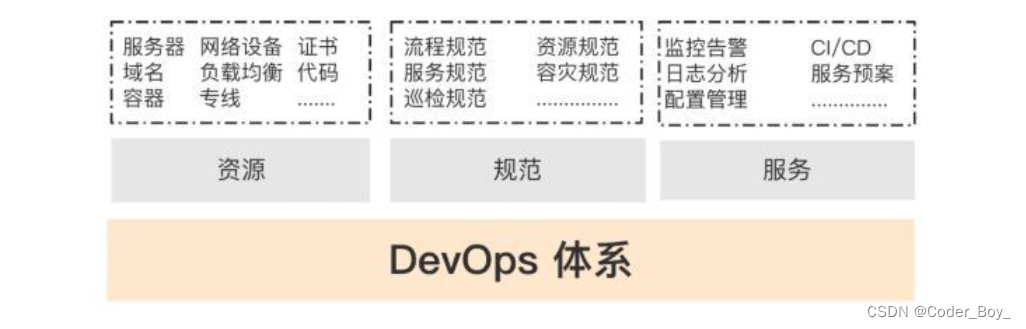
所以规范是整个 DevOps 体系建设里非常重要的一环,每个规范也对应了一些最佳实践原则,整理了一些运维中的规范如下:
1、变更规范
- 上线变更:代码上线、回滚、扩缩容;
- 配置变更:系统配置、应用配置;
- 网络变更:网络割接、设备更换;
- 其它变更:流量调度、服务切换、服务下线…
原则:
- 制定变更审核流程;
- 制定变更相关方通知(群、邮件);
- 制定变更回滚策略;
- 遵循测试、灰度、全量上线的规则;
下线变更要将服务器依赖处理干净,比如说挂着vip、有域名解析。
2、容灾规范
- 服务灾备:多机器、多机房;
- 数据灾备:多备份、异地备份;
- 网络灾备:多线路、多设备;
原则:
- 自动切换 好于 手动切换;
- 无状态 好于 有状态;
- 热备 好于 冷备;
- 多机房 好于 单机房。
3、容量规范
- 系统容量:木桶原理计算系统的全链路容量、用量、余量;
- 模块容量:模块的容量、用量、余量;
- 机房容量:分机房的容量、用量、余量;
- 单机容量:用于反向计算机房、模块容量;
原则:
- 制定模块单机容量指标(比如QPS、连接数、在线用户数等);
- 容量要考虑下行(读)、上行(写),考虑存储增量;
- 计算当前模块总容量,收集当前的用量,并对比容量计算余量;
- 系统总容量可以根据木桶原理,找到短板模块后,反向计算出来。
4、巡检规范
- 用户核心指标;
- 服务核心指标;
- 基础资源指标:服务器;
- 依赖资源指标:依赖db、依赖接口;
- 自动化巡检报告;
- 值班oncall安排;
原则:
- DashBoard核心在于收敛、舍得;
- 自动化巡检的必要性在于异常侦测,预防故障。
5、告警规范
- 基础监控:CPU、内存、网络、IO;
- 应用监控:进程、端口;
- 业务监控:日志、业务埋点;
- 依赖监控:数据库、依赖接口……
原则:
- 核心监控收敛成告警,并对告警进行分级,备注告警影响;
- 核心监控形成可排查问题的DashBoard;
- 告警的价值在于实时发现故障。
6、预案规范
- 线路切换:移动、电信、联通线路切换;
- 机房切换:不同机房切换;
- 机器切换:机器故障时进行摘除;
- 服务降级:无法切换时,降低标准继续服务;
- 数据库切换:主从切换、读写切换;
- 网络切换:主备线路切换、链路切换;
原则:
- 域名切换 好于 更换IP;
- 自动摘除 好于 手动操作;
- 自动切换 好于 手动切换;
- 考虑好雪崩事宜。
7、故障管理规范
- 服务分级:确定各服务用户角度的影响;
- 故障定级:制定故障定级标准;
- 制定故障通知、处理规范;
- 制定故障复盘,改进措施按时保量完成的规范;
原则:
拥抱故障,同类故障不能重复发生。
8、权限安全规范
- 开发、运维、临时权限;
- 安全上符合安全审计标准。
9、文档、工具规范
- 统一共享知识文档;
- 统一共享各种脚本工具;
原则:
理想的情况是“一站式运维平台”,一个平台涵盖所有工具操作。
10、标准化规范:
- 主机名标准化;
- 日志存储标准化;
- 日志格式标准化;
- 域名使用标准化;
- 软件安装目录结构标准化;
原则:
- 主机名尽量能看出更多信息,比如服务、模块、机房等;
- 日志是排查问题的重要信息,一定要标准化,方便手工排查,更是为了以后用工具处理打下基础。
11、资源管理规范
- 服务器
- vip
- 域名
- 证书
- 代码
原则:
- 资源之间是有关系的,要建立有关系的资源管理。
- 这里只列了一些常见的业务规范,还有很多规范是要在业务实际问题中去制定的,规范代表了运维的最佳实践,在DevOps建设中非常重要。
二、建工作制度
制度对应着工作的做事流程方法,会影响到文化,制度的建设情况,也反映了解决问题的层次,好的制度是应该能够系统化、工具化、可执行、可量化的,这样在后期才好用DevOps实现,把制度友好的落到运维平台上。
制度的产生不应该是解决一个case,而是科学的解决一类问题,制度的执行如果仅靠人的自觉自律,是靠不住的,一定要尽可能落到技术上。
- 上线审批制度
- 合规部署制度
- 日志清理制度
- 容量管理制度
- oncall管理制度
- 服务巡检制度
- 故障管理制度
- 安全管理制度
- ……
工作中最不缺的是各种制度,如何建是有技巧的,也体现了一个运维的能力,这种能力坚持下去就会变为一种文化,例如考虑问题看到本质,解决问题解决根本。
另外,制度的建立要一定要本着长远的眼光,科学的态度,DevOps的思想(工具思维)。
三、搭 DevOps 系统
搭系统就是把前面的内容用技术的手段信息化,用科学的工具实现零散的资源管理、规范制度、手工操作,最理想的目标是“一站式运维”,工程师不需要切换系统,一个平台解决所有事情。
但要管的东西实在太多了,为了专业,市面上首先出现了解决单个点的优秀方案,比如说zabbix、Jenkins…..但从用户的角度看就像“五行有了缺一个串”,解决一个业务问题,需要打开N多个系统,来回跳转,这种方式令人崩溃。好一点的大厂做个单点登陆,解决了账号混乱的问题,不过依旧是一堆系统,用户体验差、操作效率低。
实际上,这些单点的解决方案非常重要,我们在思考设计DevOps的时候,想要做到高质量、低成本,必须用好这些方案像拼积木一样做资源整合,把他们当作底层的轮子,站在巨人的肩膀上做系统,力争在应用层做到“一站式”,工作细分到这个程度,指望一个系统解决所有底层问题是不现实的,用图示意如下。
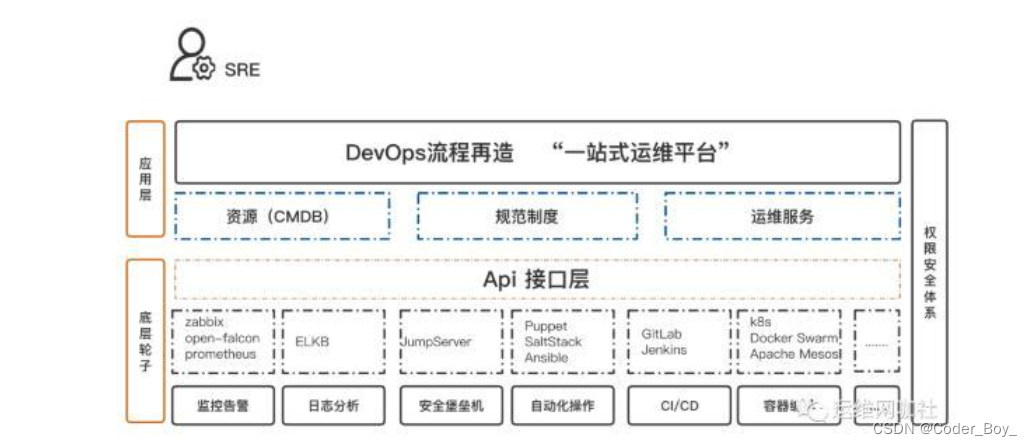
可以看到,整个工具体系分为了两层,一层是底层的轮子层,这一层面向的是单个主题的解决,讲究深度和系统的解决一类问题,上层是面向SRE的应用层,也可以说是业务层,业务层通过底层轮子封装后管理了资源、规范制度、运维服务(运维提供的服务)这三类内容,所有的轮子通过一套账号和权限体系打通。
我们要用好开源社区优秀的轮子,特别是小厂,没有必要重复建设,要通过轮子的api接口做好应用层的流程封装,通过应用层的集成,做到一站式操作,应用层作为和SRE的用户接口,体现了一个 DevOps 的用户体验,轮子可以复杂,“一站式运维平台”要做到尽可能简单、优雅。