一、简介
Calico 是一种容器之间互通的网络方案。在虚拟化平台中,比如 OpenStack、Docker 等都需要实现 workloads 之间互连,但同时也需要对容器做隔离控制。而在多数的虚拟化平台实现中,通常都使用二层隔离技术来实现容器的网络,这些二层的技术有一些弊端,比如需要依赖 VLAN、bridge 和隧道等技术,其中 bridge 带来了复杂性,vlan 隔离和 tunnel 隧道则消耗更多的资源并对物理环境有要求,随着网络规模的增大,整体会变得越加复杂。我们尝试把 Host 当作 Internet 中的路由器,同样使用 BGP 同步路由,并使用 iptables 来做安全访问策略,最终设计出了 Calico 方案。Calico支持多种网络架构,其中IPIP和BGP两种网络架构较为常用。
-
设计思路
Calico 不使用隧道或 NAT 来实现转发,而是巧妙的把所有二三层流量转换成三层流量,并通过 host 上路由配置完成跨 Host 转发。
-
优势
-
优化资源利用
二层网络通讯需要依赖广播消息机制,广播消息的开销与 host 的数量呈指数级增长,Calico 使用的三层路由方法,则完全抑制了二层广播,减少了资源开销。
-
可扩展性
Calico 使用与 Internet 类似的方案,Internet 的网络比任何数据中心都大,Calico 同样天然具有可扩展性。
-
依赖少
Calico 仅依赖三层路由可达。
-
可适配性
Calico 较少的依赖性使它能适配所有 VM、Container、白盒或者混合环境场景。
-
二、calico架构
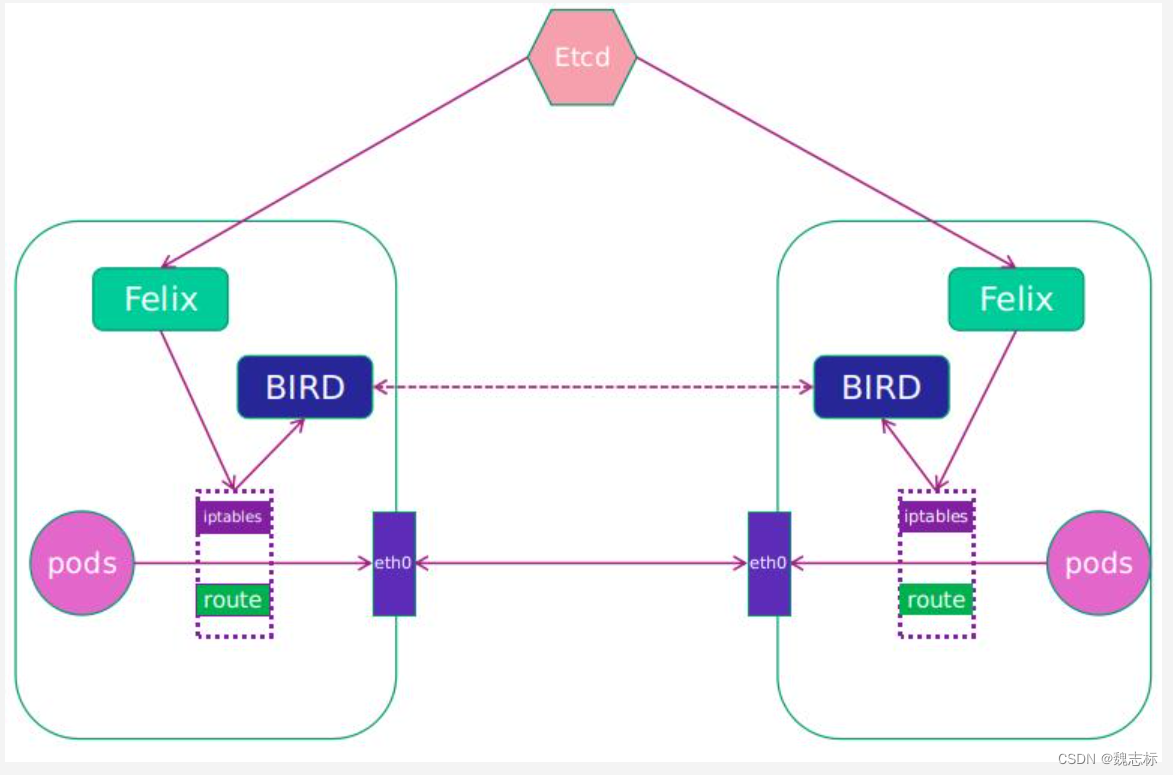
-
Felix
Calico Agent,运行在每一台 Host 的 agent 进程,主要负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等,保证跨主机容器的网络互通。Felix会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是创建了一个容器等。用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离。
-
etcd
Calico的后端存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
-
BGP Client(BIRD)
Calico 为每一台 Host 部署一个 BGP Client,使用 BIRD 实现,BIRD 是一个单独的持续发展的项目,实现了众多动态路由协议比如 BGP、OSPF、RIP 等。负责将Felix 在各Node上的设置通过BGP协议广播到Calico网络,从而实现网络互通。BIRD是一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,你们路由的时候得到这里来。
-
BGP Route Reflector
在大型网络规模中,如果仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,因为所有节点之间俩俩互联,需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。
三、ipip模式分析
就是把一个IP数据包又套在一个IP包里,即把 IP 层封装到 IP 层的一个 tunnel。它的作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,不需要 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。
基础网络:

通信原理
calico中用环境变量CALICO_IPV4POOL_IPIP来标识是否开启IPinIP Mode. 如果该变量的值为Always那么就是开启IPIP,如果关闭需要设置为Never
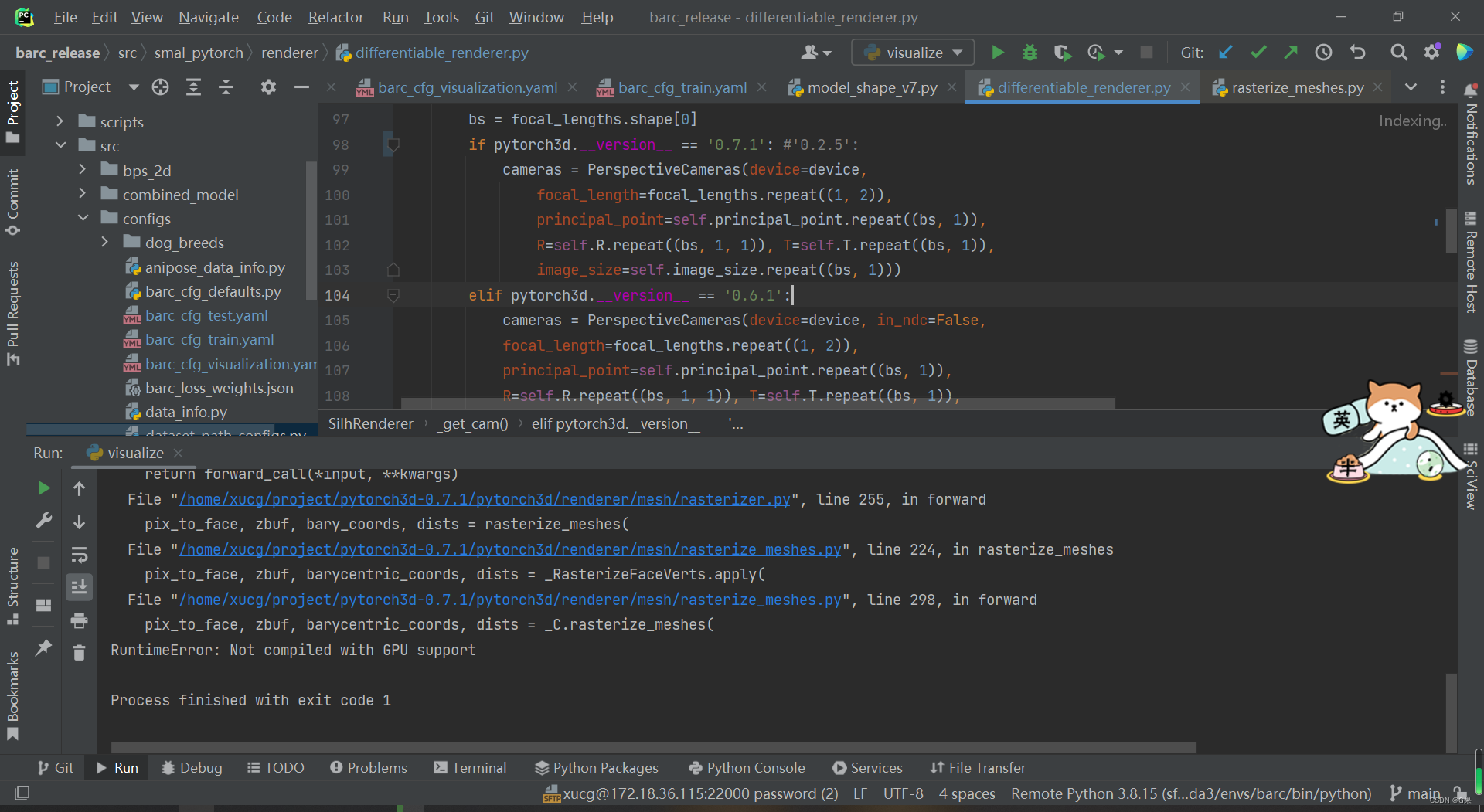
[root@node1 ~]# calicoctl get ippool -o wide
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED DISABLEBGPEXPORT SELECTOR
default-ipv4-ippool 10.233.64.0/18 true Always Never false false all()
IPIP的calico-node启动后会拉起一个linux系统的tunnel虚拟网卡tunl0, 并由二进制文件allocateip给它分配一个calico IPPool中的地址,如下:
6: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 10.233.90.0/32 scope global tunl0
valid_lft forever preferred_lft forever
log记录在本机的/var/log/calico/cni目录下。tunl0是linux支持的隧道设备接口,当有这个接口时,出这个主机的IP包就会本封装成IPIP报文。同样的,当有数据进来时也会通过该接口解封IPIP报文。然后IPIP模式的网络通信模型如下图所示。
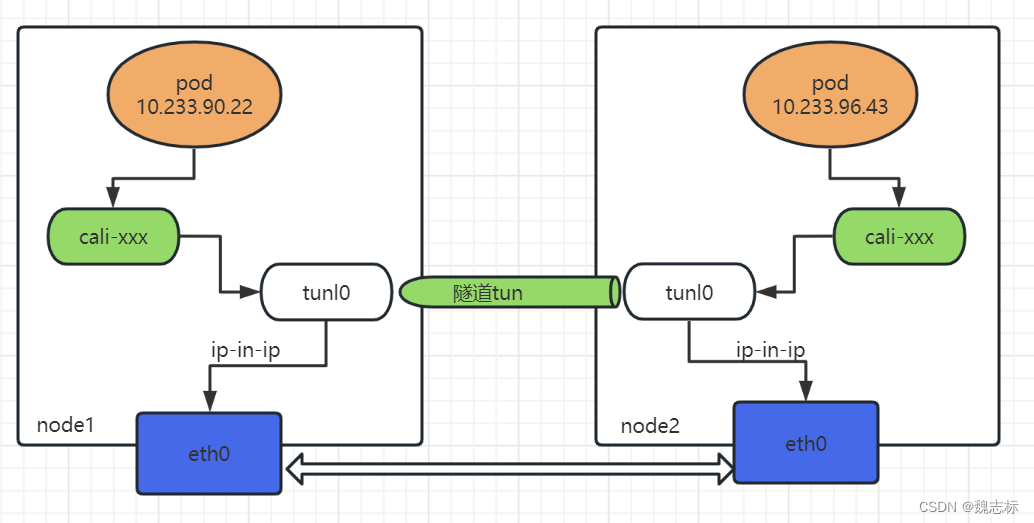
按照上述模型,网络通信流程如下:
-
Pod-1 -> calixxx -> tunl0 -> eth0 <----> eth0 -> calixxx -> tunl0 -> Pod-2
-
根据node1宿主机中的路由规则中的下一跳,使用tunl0设备将ip包发送到node2的宿主机
查看node1的路由如下:
[root@node1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.5.1 0.0.0.0 UG 0 0 0 eth0
10.233.90.0 0.0.0.0 255.255.255.0 U 0 0 0 *
10.233.90.1 0.0.0.0 255.255.255.255 UH 0 0 0 cali41f400bfcca
10.233.90.22 0.0.0.0 255.255.255.255 UH 0 0 0 cali128d86428f3
10.233.92.0 192.168.5.27 255.255.255.0 UG 0 0 0 tunl0 ###去往pod网络的下一跳是node2的物理机地址,网卡是tunl0
10.233.96.0 192.168.5.126 255.255.255.0 UG 0 0 0 tunl0
169.254.169.254 192.168.5.2 255.255.255.255 UGH 0 0 0 eth0
192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
-
tunl0是一种ip隧道设备,当ip包进入该设备后,会被Linux中的ipip驱动将该ip包直接封装在宿主机网络的ip包中,然后发送到node2的宿主机
-
进入node2的宿主机后,该ip包会由ipip驱动解封装,获取原始的ip包,然后根据node2宿主机中路由规则发送到calixxx。
网络结构实战分析
环境信息:一台master、三台worker节点,网络模式为ipip
- 首先启动三台pod,如下
[root@node1 ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-5977dc5756-7rr4k 1/1 Running 0 21h 10.233.96.43 node2 <none> <none>
nginx-5977dc5756-tnj57 1/1 Running 0 21h 10.233.92.39 node3 <none> <none>
nginx-5977dc5756-xr6hj 1/1 Running 0 21h 10.233.90.22 node1 <none> <none>
- 查看pod网络信息
[root@node1 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if28: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group default
link/ether 32:18:c3:ca:b9:fa brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.233.90.22/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::3018:c3ff:feca:b9fa/64 scope link
valid_lft forever preferred_lft forever
[root@node1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
具体分析
calico所管理的容器内部联通主机外部网络的方法都是一样的,用linux支持的veth-pair。
1:首先在pod内部看到的eth0@if28为容器的网卡,这个28表示的是主机网络命名空间下的28号ip link.另一端是主机网络空间下的cali128d86428f3,这个128d86428f3是VethNameForWorkload函数利用容器属性计算的加密字符的前11个字符,可以在主机上看到,如下:
#################################
28: cali128d86428f3@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
#################################
2:查看pod内部的默认路由
[root@node1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
可以看到,不光是当前pod的calixxx的MAC地址,其他的pod的calixxx的MAC地址也都是ee:ee:ee:ee:ee:ee,这样的配置简化了操作,使得容器会把报文交给169.254.1.1来处理,但是这个地址是本地保留的地址也可以说是个无效地址,但是通过veth-pair会传递到对端calixxx上,因为calixxx网卡开启了arpproxy,所以它会代答所有的ARP请求,让容器的报文都发到calixxx上,也就是发送到主机网络栈,再有主机网络栈的路由来送到下一站. 可以通过cat /proc/sys/net/ipv4/conf/calixxx/proxy_arp/来查看,输出都是1。
物理机上确认如下:
[root@node1 ~]# cat /proc/sys/net/ipv4/conf/cali128d86428f3/proxy_arp
1
[root@node1 ~]#
这里注意,calico要响应arp请求还需要具备三个条件,否则容器内的ARP显示异常:
1:宿主机的arp代理得打开
2:宿主机需要有访问目的地址的明确路由,这里我理解为宿主机要有默认路由
3:发送arp request的接口与接收arp request的接口不能相同,即容器中的默认网关不能是calico的虚拟网关
- 不同node之间ip包路径
pod1地址: 10.233.90.22 节点:node1
pod2地址:10.233.96.43 节点:node2
从pod1 ping pod2
####查看pod1路由如下:
[root@node1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
####可以看到默认路由是169.254.1.1,所有的包都从eth0出去
[root@node1 ~]# ping 10.233.96.43
PING 10.233.96.43 (10.233.96.43) 56(84) bytes of data.
64 bytes from 10.233.96.43: icmp_seq=1 ttl=62 time=1.67 ms
64 bytes from 10.233.96.43: icmp_seq=2 ttl=62 time=0.983 ms
64 bytes from 10.233.96.43: icmp_seq=3 ttl=62 time=1.64 ms
64 bytes from 10.233.96.43: icmp_seq=4 ttl=62 time=0.649 ms
在node1的cali128d86428f3网卡抓包,如下:
####pod中的eth0与Cali128d86428f3是一对veth pair,因此,Cali128d86428f3接收到的ip流向一定与pod中的eth0相同,为 10.233.90.22->10.233.96.43
[root@node1 ~]# tcpdump -eni cali128d86428f3 -nnvv | grep 10.233.90.22
tcpdump: listening on cali128d86428f3, link-type EN10MB (Ethernet), capture size 262144 bytes
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46034, seq 74, length 64
10.233.96.43 > 10.233.90.22: ICMP echo reply, id 46034, seq 74, length 64
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46034, seq 75, length 64
10.233.96.43 > 10.233.90.22: ICMP echo reply, id 46034, seq 75, length 64
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46034, seq 76, length 64
10.233.96.43 > 10.233.90.22: ICMP echo reply, id 46034, seq 76, length 64
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46034, seq 77, length 64
10.233.96.43 > 10.233.90.22: ICMP echo reply, id 46034, seq 77, length 64
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46682, seq 1, length 64
在node1的tunl0网卡抓包
####查看主机路由
[root@node1 ~]# route -n
10.233.96.0 192.168.5.126 255.255.255.0 UG 0 0 0 tunl0
####如上可以看到往10.233.96.0的数据包,下一跳地址是192.168.5.126,为node2的物理地址,并且所有的数据包都从tunl0出去
[root@node1 ~]# tcpdump -eni tunl0 -nnvv | grep 10.233.90.22
tcpdump: listening on tunl0, link-type RAW (Raw IP), capture size 262144 bytes
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46682, seq 162, length 64
10.233.96.43 > 10.233.90.22: ICMP echo reply, id 46682, seq 162, length 64
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46682, seq 163, length 64
10.233.96.43 > 10.233.90.22: ICMP echo reply, id 46682, seq 163, length 64
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46682, seq 164, length 64
10.233.96.43 > 10.233.90.22: ICMP echo reply, id 46682, seq 164, length 64
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46682, seq 165, length 64
10.233.96.43 > 10.233.90.22: ICMP echo reply, id 46682, seq 165, length 64
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46682, seq 166, length 64
10.233.96.43 > 10.233.90.22: ICMP echo reply, id 46682, seq 166, length 64
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46682, seq 167, length 64
10.233.96.43 > 10.233.90.22: ICMP echo reply, id 46682, seq 167, length 64
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46682, seq 168, length 64
10.233.96.43 > 10.233.90.22: ICMP echo reply, id 46682, seq 168, length 64
10.233.90.22 > 10.233.96.43: ICMP echo request, id 46682, seq 169, length 64
在node1的eth0网卡抓包
####可以看到在抓的包中,经过tunl0的ip报会被再封上一层ip,通过node1 的route规则,会发往eth0,因此在eth0处的抓包结果为 192.168.5.79 > 192.168.5.126: 10.233.90.22 > 10.233.96.43
####node1上查看路由如下:
192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
[root@node1 ~]# tcpdump -eni eth0 | grep -i icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
17:53:45.298248 fa:16:3e:50:2c:c0 > fa:16:3e:ee:78:0e, ethertype IPv4 (0x0800), length 118: 192.168.5.79 > 192.168.5.126: 10.233.90.22 > 10.233.96.43: ICMP echo request, id 3893, seq 177, length 64 (ipip-proto-4)
17:53:45.298995 fa:16:3e:ee:78:0e > fa:16:3e:50:2c:c0, ethertype IPv4 (0x0800), length 118: 192.168.5.126 > 192.168.5.79: 10.233.96.43 > 10.233.90.22: ICMP echo reply, id 3893, seq 177, length 64 (ipip-proto-4)
17:53:46.299032 fa:16:3e:50:2c:c0 > fa:16:3e:ee:78:0e, ethertype IPv4 (0x0800), length 118: 192.168.5.79 > 192.168.5.126: 10.233.90.22 > 10.233.96.43: ICMP echo request, id 3893, seq 178, length 64 (ipip-proto-4)
17:53:46.299585 fa:16:3e:ee:78:0e > fa:16:3e:50:2c:c0, ethertype IPv4 (0x0800), length 118: 192.168.5.126 > 192.168.5.79: 10.233.96.43 > 10.233.90.22: ICMP echo reply, id 3893, seq 178, length 64 (ipip-proto-4)
17:53:47.300329 fa:16:3e:50:2c:c0 > fa:16:3e:ee:78:0e, ethertype IPv4 (0x0800), length 118: 192.168.5.79 > 192.168.5.126: 10.233.90.22 > 10.233.96.43: ICMP echo request, id 3893, seq 179, length 64 (ipip-proto-4)
17:53:47.300924 fa:16:3e:ee:78:0e > fa:16:3e:50:2c:c0, ethertype IPv4 (0x0800), length 118: 192.168.5.126 > 192.168.5.79: 10.233.96.43 > 10.233.90.22: ICMP echo reply, id 3893, seq 179, length 64 (ipip-proto-4)
17:53:48.301563 fa:16:3e:50:2c:c0 > fa:16:3e:ee:78:0e, ethertype IPv4 (0x0800), length 118: 192.168.5.79 > 192.168.5.126: 10.233.90.22 > 10.233.96.43: ICMP echo request, id 3893, seq 180, length 64 (ipip-proto-4)
17:53:48.302016 fa:16:3e:ee:78:0e > fa:16:3e:50:2c:c0, ethertype IPv4 (0x0800), length 118: 192.168.5.126 > 192.168.5.79: 10.233.96.43 > 10.233.90.22: ICMP echo reply, id 3893, seq 180, length 64 (ipip-proto-4)
当流量到达node2时,etho0将ipip拆封后,将流量发给tunl0,tunl0再转发给cali.xxx
- 同node之间pod通信
Calico会为每一个node分配一小段网络,同时会为每个pod创建一个“入”的ip route规则。
10.233.90.1 0.0.0.0 255.255.255.255 UH 0 0 0 cali41f400bfcca
10.233.90.22 0.0.0.0 255.255.255.255 UH 0 0 0 cali128d86428f3
当从pod 10.233.90.1访问pod 10.233.90.22时,cali41f400bfcca是直接发出10.233.90.1-> 10.233.90.22流量的,在node1的route中,发往10.233.90.22的ip报直接会被转发到cali128d86428f3,不会用到tunl0,只有在node间访问的时候才会使用tunl0进行ipip封装!
此处涉及一个算法
1:当目的地址不在本地网络时,报文会被转发到默认网关。节点的出口网关或者默认网关,通常位于节点与网络连接的物理网口eth0上。
2:此时不会发生arp解析,因为源ip和目的ip不在同一个网络内。
3:网段的检查是使用按位运算完成的。
总结
-
IPIP模式下,node间的Pod访问会使用IPIP技术对出node的ip报进行隧道封装
-
node内的Pod访问不会用到ipip隧道封装。
-
Pod的ip都是由calico-node设置的IP地址池进行分配的,Calico会为每一个node分配一小段网络。