目录
性能优化问题
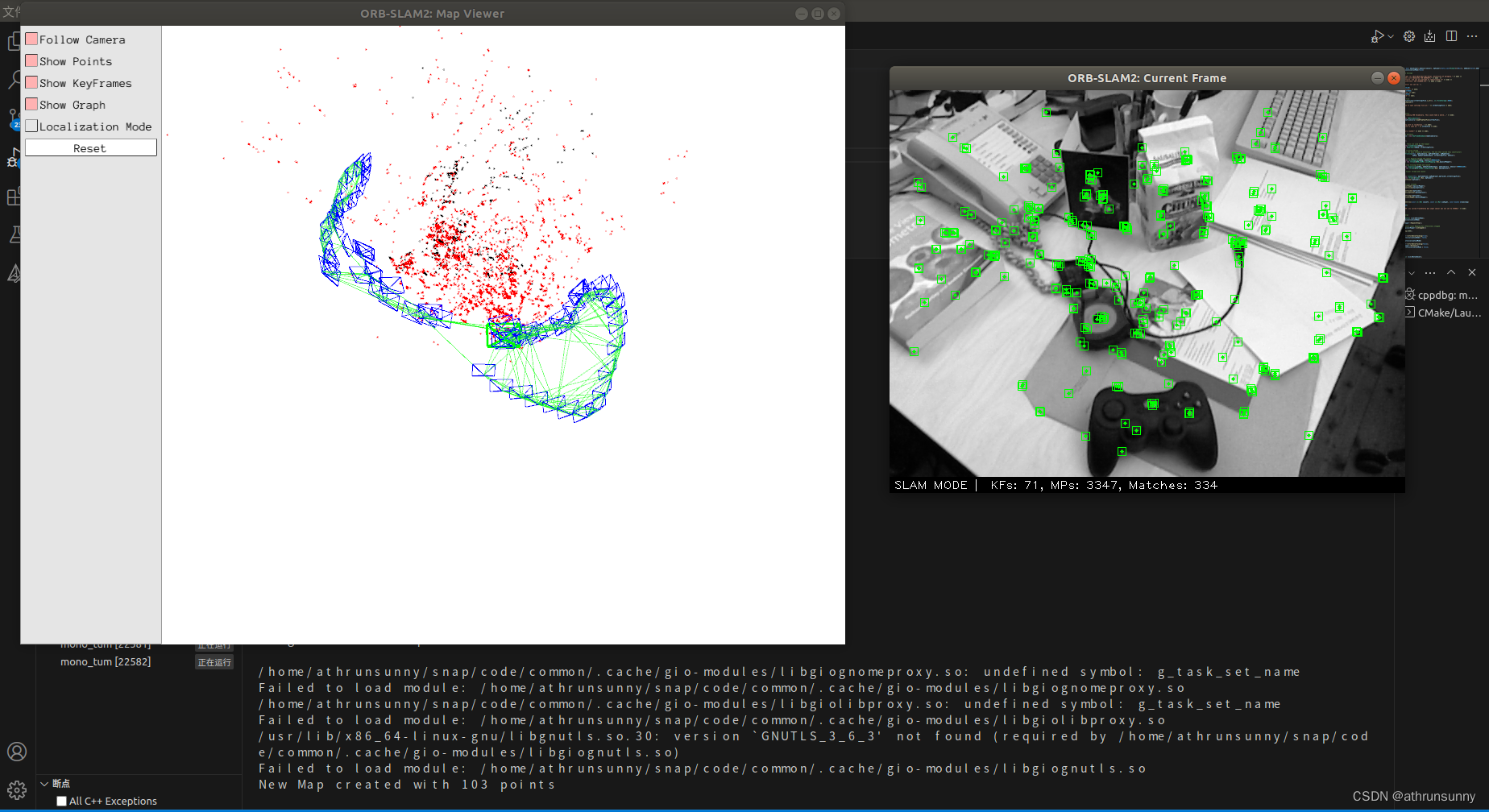
为什么重启 Milvus 服务端之后,第一次搜索时间非常长?
为什么搜索的速度非常慢?
如何进行性能调优?
应如何设置 IVF 索引的 nlist 和 nprobe 参数?
性能优化问题
为什么重启 Milvus 服务端之后,第一次搜索时间非常长?
重启后第一次搜索时,会将数据从磁盘加载到内存,所以这个时间会比较长。可以在 server_config.yaml 中开启 preload_collection,在内存允许的情况下尽可能多地加载集合。这样在每次重启服务端之后,数据都会先载入到内存中,可以解决第一次搜索耗时很长的问题。或者在查询前,调用方法 load_collection() 将该集合加载到内存。
为什么搜索的速度非常慢?
请首先检查 server_config.yaml 的 cache.cache_size 参数是否大于集合中的数据量。
如何进行性能调优?

- 确保配置文件中的参数 cache.cache_size 值大于集合中的数据量。
- 确保所有数据文件都建立了索引。
- 检查服务器上是否有其他进程在占用 CPU 资源。
- 调整参数 index_file_size 和 nlist 的值。
- 如果检索性能不稳定,可在启动 Milvus 时添加参数 -e OMP_NUM_THREADS=NUM,其中 NUM 为 CPU 逻辑核数的 2/3。
详见 性能调优。
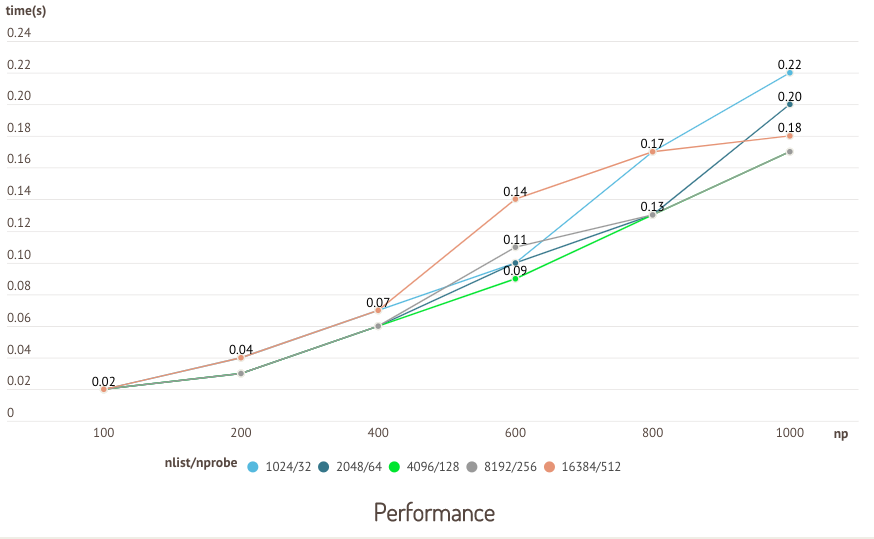
应如何设置 IVF 索引的 nlist 和 nprobe 参数?
IVF 索引的 nlist 值需要根据具体的使用情况去设置。一般来说,推荐值为 4 × sqrt(n),其中 n 为 segment 内的 entity 总量。

nprobe 的选取需要根据数据总量和实际场景在速度性能和准确率之间进行取舍。建议通过多次实验确定一个合理的值。
以下是使用公开测试数据集 sift50m 针对 nlist 和 nprobe 的一个测试。以索引类型 IVF_SQ8 为例,针对不同 nlist/nprobe 组合的搜索时间和召回率分别进行对比。
因 CPU 版 Milvus 和 GPU 版 Milvus 测试结果类似,此处仅展示基于 GPU 版 Milvus 测试的结果。

在本次测试中,nlist 和 nprobe 的值成比例增长,召回率随 nlist/nprobe 组合增长呈现上升的趋势。