一、使用本地知识库构建问答应用
上篇文章基于 LangChain 的Prompts 提示管理构建特定领域模型,如果看过应该可以感觉出来 ChatGPT 还是非常强大的,但是对于一些特有领域的内容让 GPT 回答的话还是有些吃力的,比如让 ChatGPT 介绍下什么是 LangChain:
from langchain.llms import OpenAI
import os
openai_api_key=os.environ["OPENAI_API_KEY"]
llm = OpenAI(model_name="gpt-3.5-turbo", openai_api_key=openai_api_key)
my_text = "介绍下 langChain "
print(llm(my_text))

可以看出回答的貌似不是我们想要的内容,还有在一些特定的场景下的问答,比如学校学生问答系统中,学生提问周一课程是什么?,这种直接让 GPT 回答的话也是有些吃力,那这种情况下怎么解决呢?
现在有了 LangChain 那实现起来就非常简答了:
例如:现有知识内容放在了 data 目录下,有如下内容:
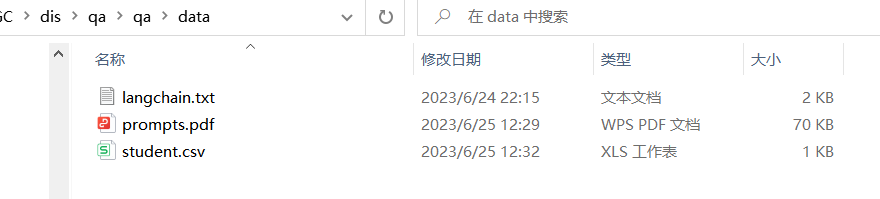
其中 txt 文件记录了 LangChain 的介绍:

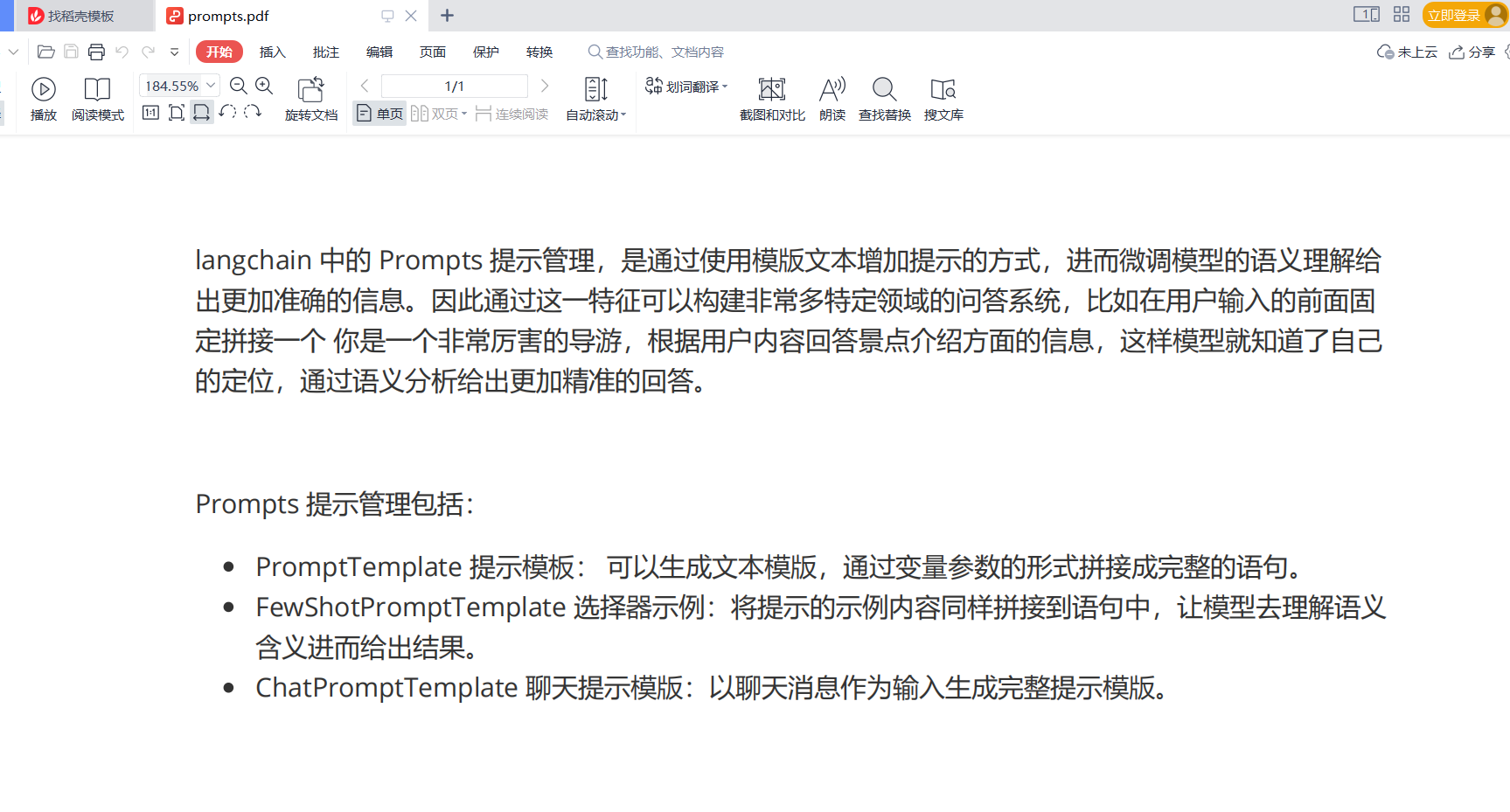
pdf 介绍了下 langchain 中的 Prompts :
csv 记录的学生课程信息:
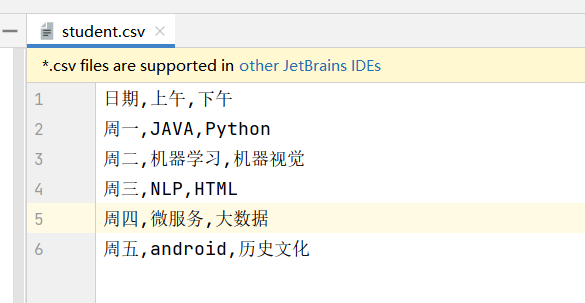
下面首先对知识内容进行载入和向量化。
3.1 文本载入及 Embedding 向量持久化
import os
# 向量数据库
from langchain.vectorstores import Chroma
# 文档加载器
from langchain.document_loaders import TextLoader, CSVLoader, PyPDFLoader
# 文本转换为向量的嵌入引擎
from langchain.embeddings.openai import OpenAIEmbeddings
# 文本拆分
from langchain.text_splitter import RecursiveCharacterTextSplitter
openai_api_key = os.environ["OPENAI_API_KEY"]
knowledge_base_dir = "./data"
doc = []
for item in os.listdir(knowledge_base_dir):
if item.endswith("txt"):
loader = TextLoader(file_path=os.path.join(knowledge_base_dir, item), encoding="utf-8")
doc.append(loader.load())
elif item.endswith("csv"):
loader = CSVLoader(file_path=os.path.join(knowledge_base_dir, item), encoding="utf-8")
doc.append(loader.load())
elif item.endswith("pdf"):
loader = PyPDFLoader(file_path=os.path.join(knowledge_base_dir, item))
doc.append(loader.load())
print("提取文本量:", len(doc))
# 拆分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=400)
docs = []
for d in doc:
docs.append(text_splitter.split_documents(d))
print("拆分文档数:", len(docs))
# 准备嵌入引擎
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# 向量化
# 会对 OpenAI 进行 API 调用
vectordb = Chroma(embedding_function=embeddings, persist_directory="./cut")
for d in docs:
vectordb.add_documents(d)
# 持久化
vectordb.persist()
运行后可以在 ./cut 看到持久化的向量内容:
3.2 构建问答
from langchain import OpenAI
# 向量数据库
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
# 文本转换为向量嵌入引擎
from langchain.embeddings.openai import OpenAIEmbeddings
import os
openai_api_key = os.environ["OPENAI_API_KEY"]
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)
# 准备好你的嵌入引擎
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectordb = Chroma(embedding_function=embeddings, persist_directory="./cut")
# 创建您的检索引擎
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectordb.as_retriever())
query = "介绍下什么是 langchain?"
res = qa.run(query)
print('问题:', query, 'LLM回答:', res)
query = "介绍下 langchain 中的 prompts ?"
res = qa.run(query)
print('问题:', query, 'LLM回答:', res)
query = "周一需要上什么课?"
res = qa.run(query)
print('问题:', query, 'LLM回答:', res)
query = "周三上午需要上什么课?"
res = qa.run(query)
print('问题:', query, 'LLM回答:', res)

可以看出已经精准的做出回答。
正常我们使用 ChatGPT 的时候都是以流的形式进行返回,同样这里我们也可以修改为流的形式:
from langchain import OpenAI
# 向量数据库
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
# 文本转换为向量的嵌入引擎
from langchain.embeddings.openai import OpenAIEmbeddings
# 流式回调
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
import os
openai_api_key = os.environ["OPENAI_API_KEY"]
llm = OpenAI(temperature=0, openai_api_key=openai_api_key, streaming=True, callbacks=[StreamingStdOutCallbackHandler()])
# 嵌入引擎
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectordb = Chroma(embedding_function=embeddings, persist_directory="./cut")
# 创建您的检索引擎
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectordb.as_retriever())
query = "介绍下什么是 langchain?"
qa.run(query)

下面配合 tornado 高性能异步非阻塞web框架,实现接口调用问答。
二、部署 WEB 服务
安装 tornado 框架:
pip install tornado -i https://pypi.tuna.tsinghua.edu.cn/simple
创建问答服务接口 server.py :
from tornado.concurrent import run_on_executor
from tornado.web import RequestHandler
import tornado.gen
import utils_response
from langchain import OpenAI
# 向量数据库
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
# 文本转换为向量的嵌入引擎
from langchain.embeddings.openai import OpenAIEmbeddings
import os
class QA(RequestHandler):
# 准备模型
openai_api_key = os.environ["OPENAI_API_KEY"]
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)
# 准备好你的嵌入引擎
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectordb = Chroma(embedding_function=embeddings, persist_directory="./cut")
# 检索引擎
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectordb.as_retriever())
print("检索引擎已加载!")
def prepare(self):
self.executor = self.application.pool
@tornado.gen.coroutine
def get(self):
questions = self.get_query_argument('questions')
if not questions or questions == '':
return utils_response.fail(message='问题为空')
result = yield self.detection(questions)
self.write(result)
@run_on_executor
def detection(self, questions):
# 开始检测
res = self.qa.run(questions)
return utils_response.ok(res)
路由配置,并启动服务 app.py :
import tornado.web
import tornado.ioloop
import tornado.httpserver
import os
from concurrent.futures.thread import ThreadPoolExecutor
from server import QA
## 配置
class Config():
port = 8081
base_path = os.path.dirname(__file__)
settings = {
# "debug":True,
# "autore load":True,
"static_path": os.path.join(base_path, "resources/static"),
"template_path": os.path.join(base_path, "resources/templates"),
"autoescape": None
}
# 路由
class Application(tornado.web.Application):
def __init__(self):
handlers = [
("/qa", QA),
("/(.*)$", tornado.web.StaticFileHandler, {
"path": os.path.join(Config.base_path, "resources/static"),
"default_filename": "index.html"
})
]
super(Application, self).__init__(handlers, **Config.settings)
self.pool = ThreadPoolExecutor(10)
if __name__ == '__main__':
app = Application()
httpserver = tornado.httpserver.HTTPServer(app)
httpserver.listen(Config.port)
print("start success", "prot = ", Config.port)
print("http://localhost:" + str(Config.port) + "/")
tornado.ioloop.IOLoop.current().start()

下面使用 PostMan 进行测试:
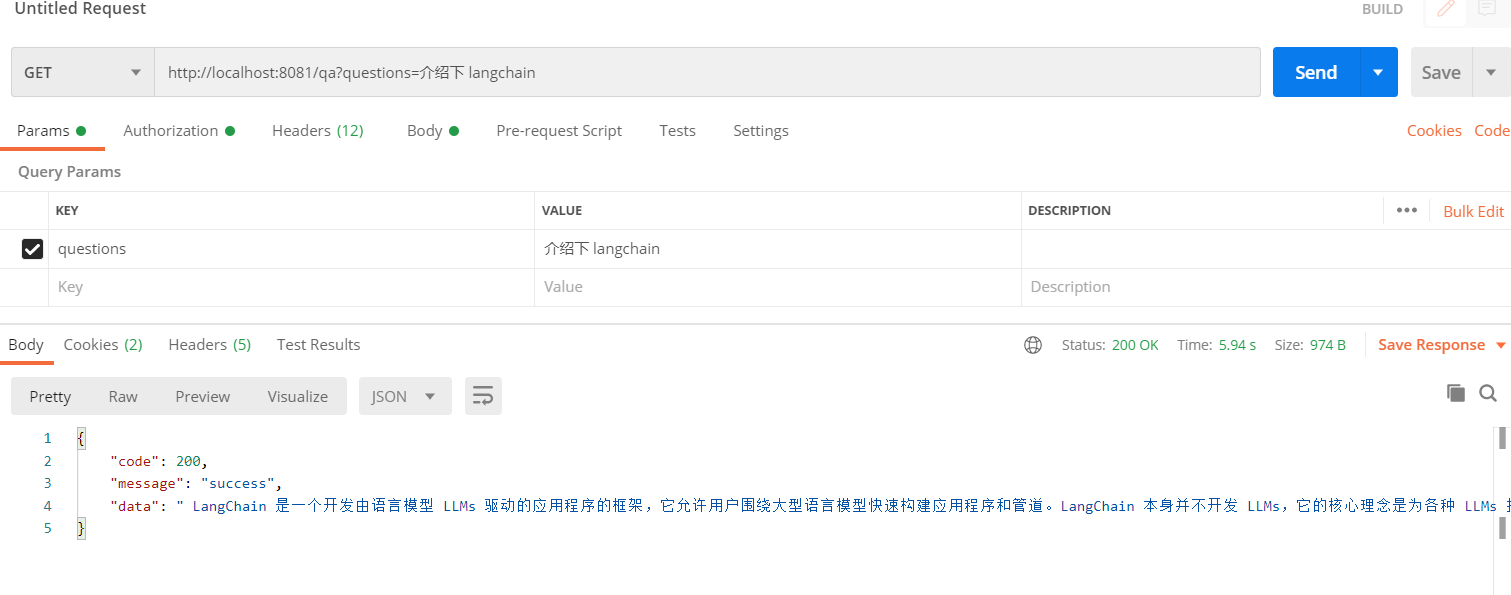
已经成功获取到答案。








![[SpringBoot]单点登录](https://img-blog.csdnimg.cn/eff781f4a934462b8ed68c0f270fb820.png)