b站刘二大人《PyTorch深度学习实践》课程第六讲逻辑斯蒂回归笔记与代码:https://www.bilibili.com/video/BV1Y7411d7Ys?p=6&vd_source=b17f113d28933824d753a0915d5e3a90
分类问题:
- MNIST数据集:手写数字数据集;6万个训练样本,1万个测试样本,10个分类(0 ~ 9)
- PyTorch框架中有一个配套的工具包torchvision,里面提供了一些流行的数据集,但是安装的时候并不会包含数据集,需要额外下载
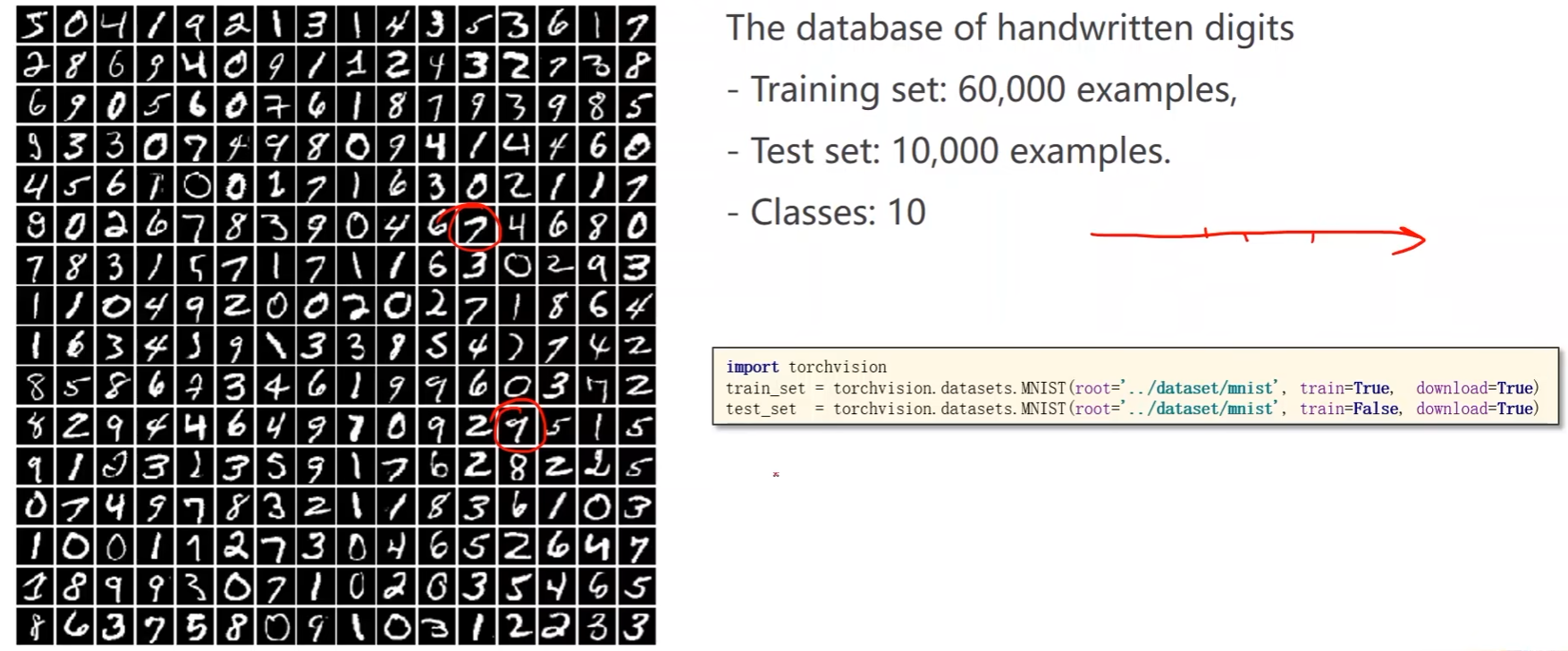
import torchvision
# root是数据集的保存位置,train表示是不是训练集,download表示是否要下载数据集
train_set = torchvision.datasets.MNIST(root='D:/pycharm_workspace/Liuer_lecturer/dataset/mnist', train=True, download=True)
test_set = torchvision.datasets.MNIST(root='D:/pycharm_workspace/Liuer_lecturer/dataset/mnist', train=False, download=True)
- CIFAR-10数据集:5万个训练样本,1万个测试样本,10个分类

import torchvision
train_set = torchvision.datasets.CIFAR10(...)
test_set = torchvision.datasets.CIFAR10(...)
回归任务和分类任务的区别
- 之前的学习时间和分数的例子是回归任务,其中的 y y y是一个具体的数值
- 分类任务的
y
y
y不再是具体分数,而是能否通过,fail / pass两个类别
- 二分类: P ( y ^ = 1 ) + P ( y ^ = 0 ) = 1 P(\hat{y} = 1) + P(\hat{y} = 0) = 1 P(y^=1)+P(y^=0)=1,某一个类别的概率

- 分类问题中,模型的输出是输入属于某个类别的概率
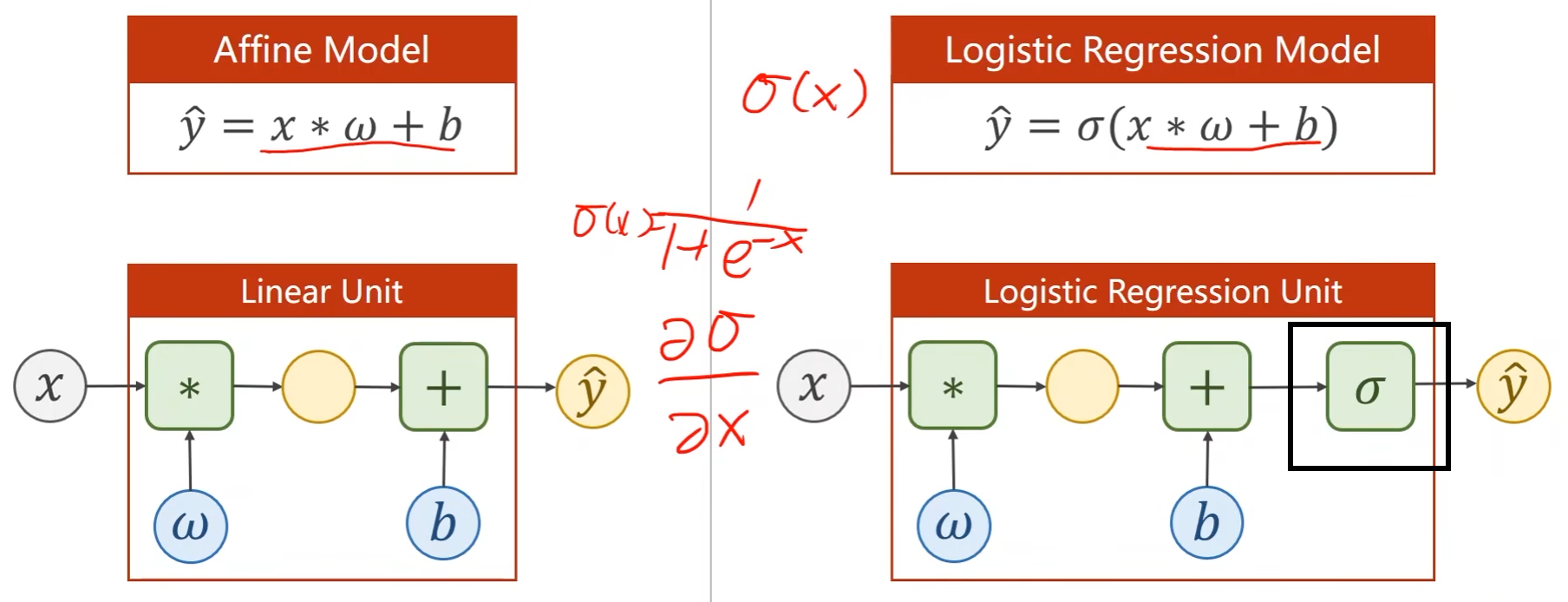
使用线性模型的时候,模型输出 y ^ = w x + b \hat{y} = wx + b y^=wx+b是实数,而现在所需要的分类输出是概率,即模型输出 y ^ ∈ [ 0 , 1 ] \hat{y} \in \left[0,1\right] y^∈[0,1]
那么就需要将线性模型的输出值由实数空间映射到0到1之间,逻辑斯蒂回归就是用于完成该映射任务
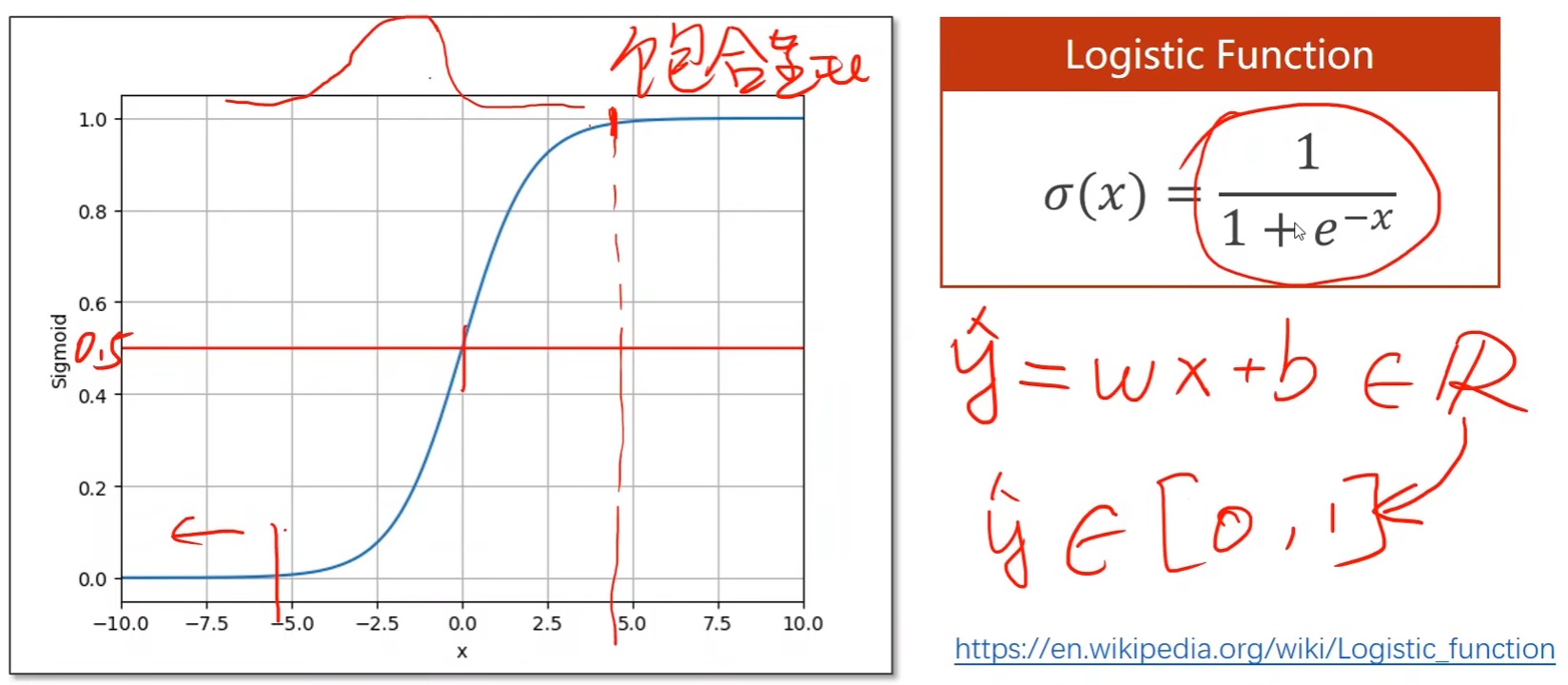
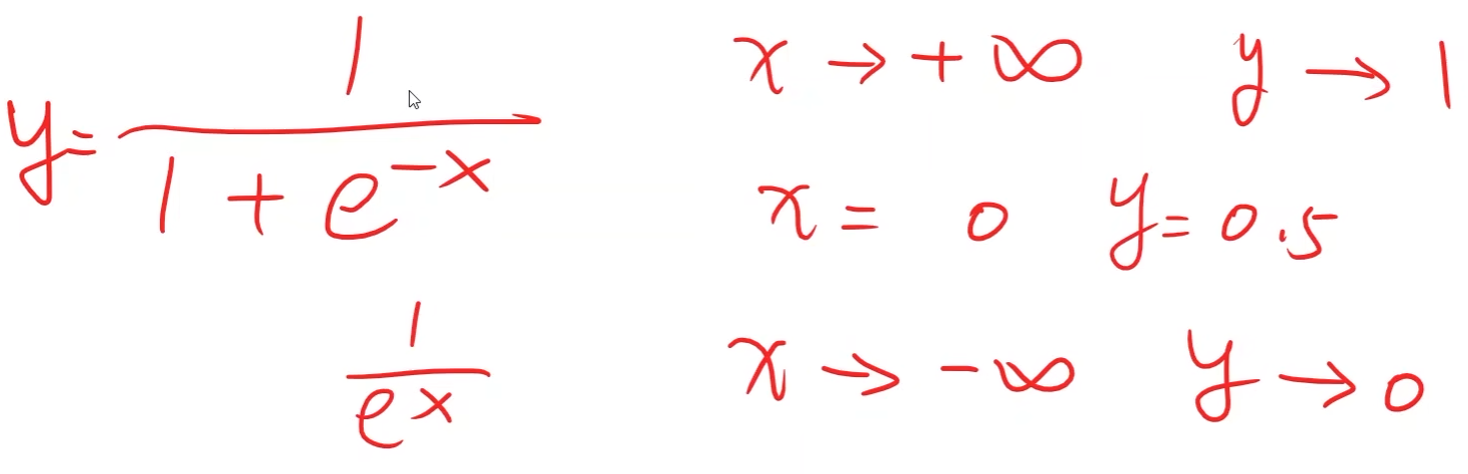
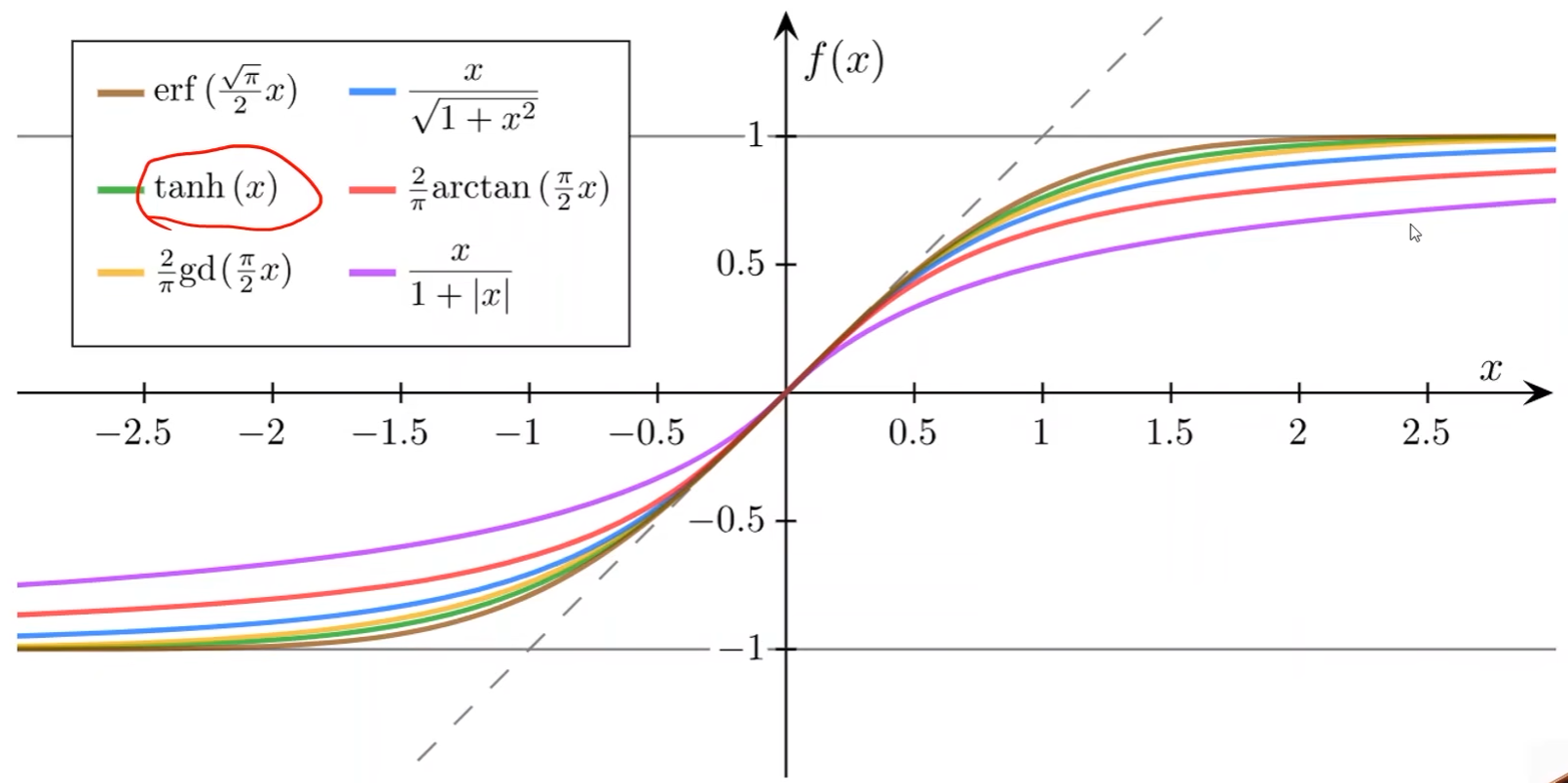
其他的sigmoid function
Logistic Regression Model
Loss Function for Binary Classification
- 原来的线性回归中的Loss函数是计算两个实数之间的差值,即在一个数轴上计算 y y y和 y ^ \hat{y} y^的距离
- 在二分类中输出的不再是一个数值,而是一个分布,表示 y ^ \hat{y} y^分类为1的概率是多少, 1 − y ^ 1-\hat{y} 1−y^就是分类为0的概率

-
在上述问题中,所想要比较的是两个分布之间的差异
-
KL散度(相对熵):用来衡量两个分布之间的差异程度,若两者差异越小,KL散度越小,反之亦反。当两分布一致时,其KL散度为0
- 衡量的是当用一个分布Q来拟合真实分布P时所需要的额外信息的平均量
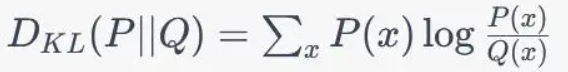
- https://zhuanlan.zhihu.com/p/365400000
- KL散度通常用于无监督学习任务中,如聚类、降维和生成模型等。在这些任务中,我们没有相应的标签信息,因此无法使用交叉熵来评估模型的性能,所以需要一种方法来衡量模型预测的分布和真实分布之间的差异,这时就可以使用KL散度来衡量模型预测的分布和真实分布之间的差异。
-
交叉熵:衡量了模型预测的概率分布与真实概率分布之间的差异,即模型在预测上的不确定性与真实情况的不确定性之间的差距
- P(x)和Q(x)分别表示真实概率分布和模型预测的概率分布中事件x的概率
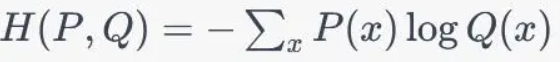
- https://en.wikipedia.org/wiki/Cross_entropy
- 在机器学习中,交叉熵通常用于衡量模型预测和真实标签之间的差异。例如,在分类任务中,交叉熵被用作损失函数,以衡量模型预测的类别分布和真实标签之间的差。
-
区别:https://baijiahao.baidu.com/s?id=1763841223452070719&wfr=spider&for=pc
-

目的是让 y y y和 y ^ \hat{y} y^之间的差异最小
上述函数也被称为BCE

代码实现:
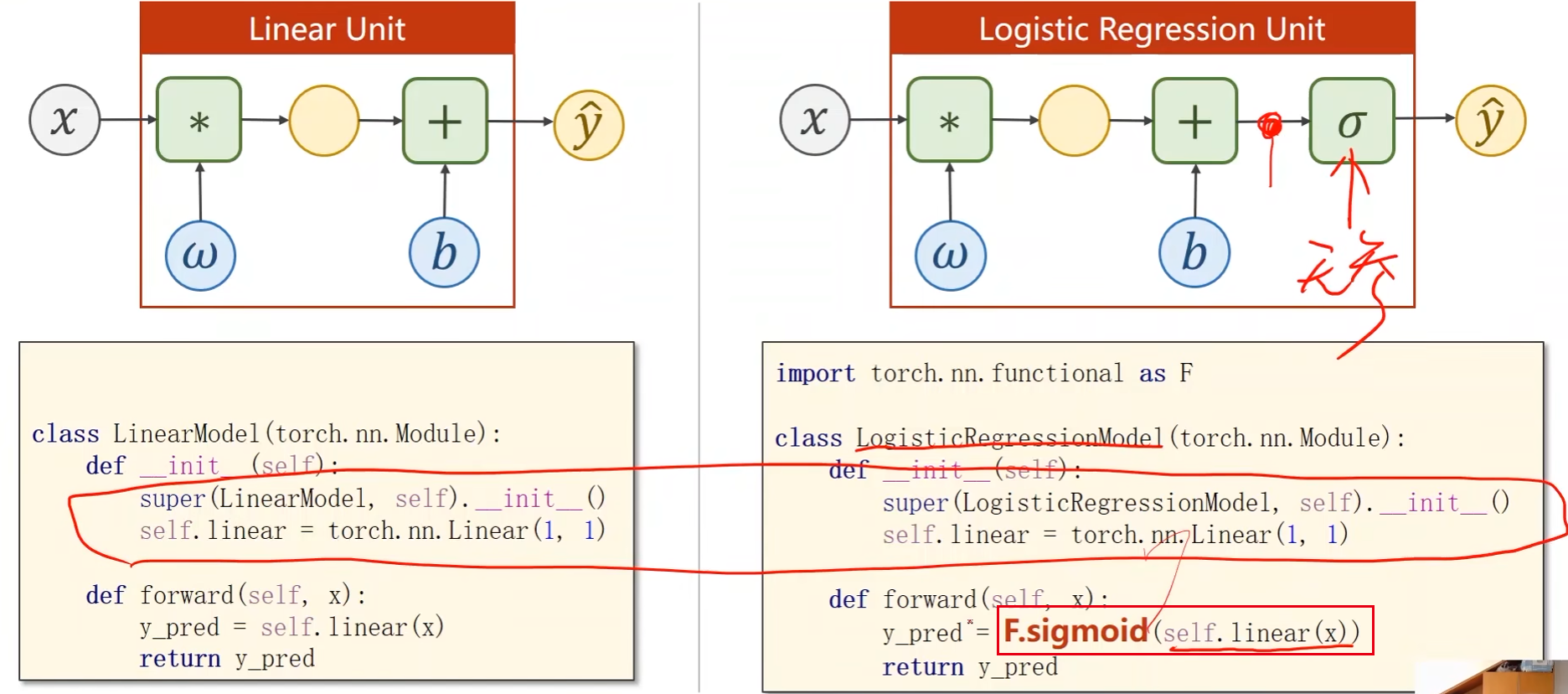

- size_average设置是否求均值,这个会影响到学习率的设置
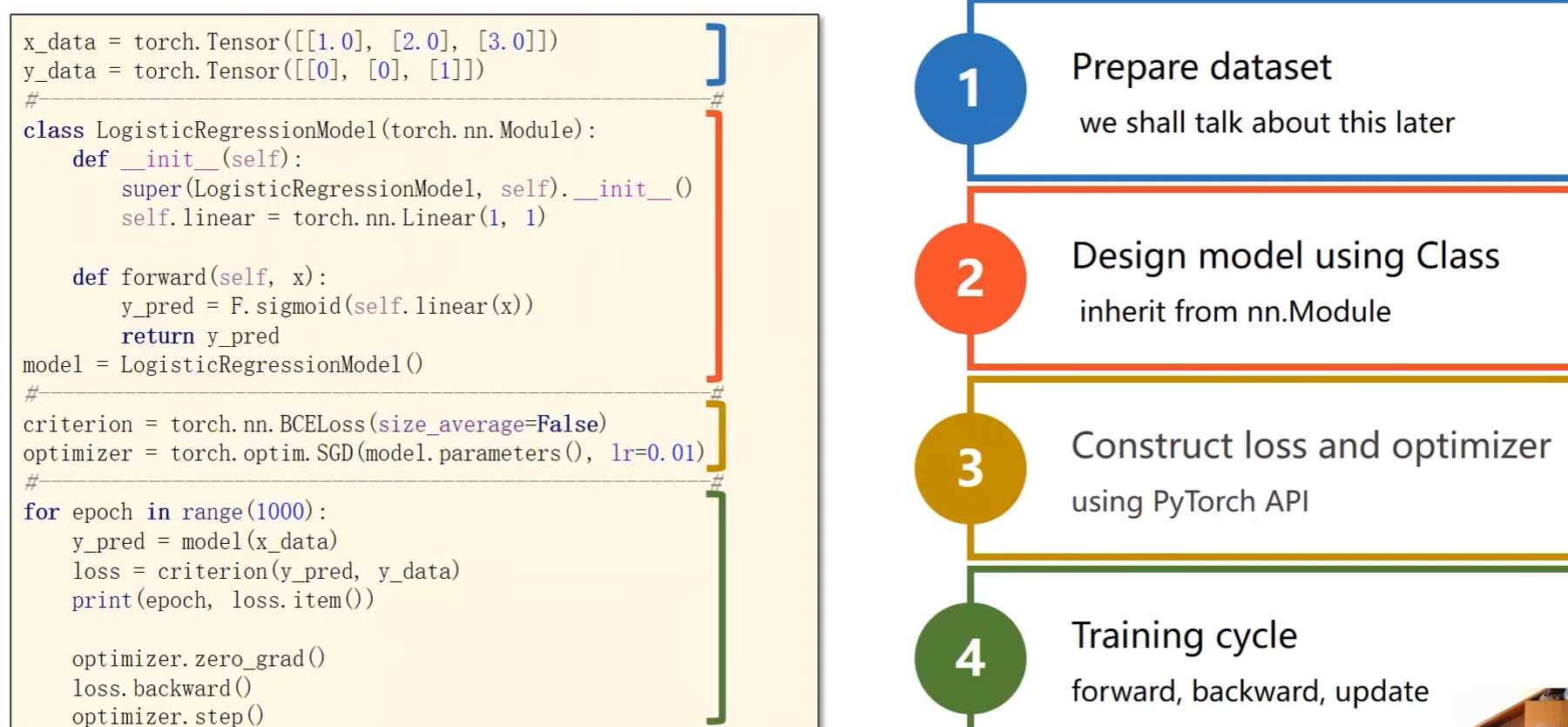
完整代码:
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
# 数据集
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = F.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
# criterion = torch.nn.MSELoss(size_average=False) pytorch更新后被弃用了
criterion = torch.nn.BCELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练过程
for epoch in range(1000):
y_pred = model(x_data) # 前馈:计算y_hat
loss = criterion(y_pred, y_data) # 前馈:计算损失
print(epoch, loss.item())
optimizer.zero_grad() # 反馈:在反向传播开始将上一轮的梯度归零
loss.backward() # 反馈:反向传播(计算梯度)
optimizer.step() # 更新权重w和偏置b
# 输出权重和偏置
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
# 测试模型
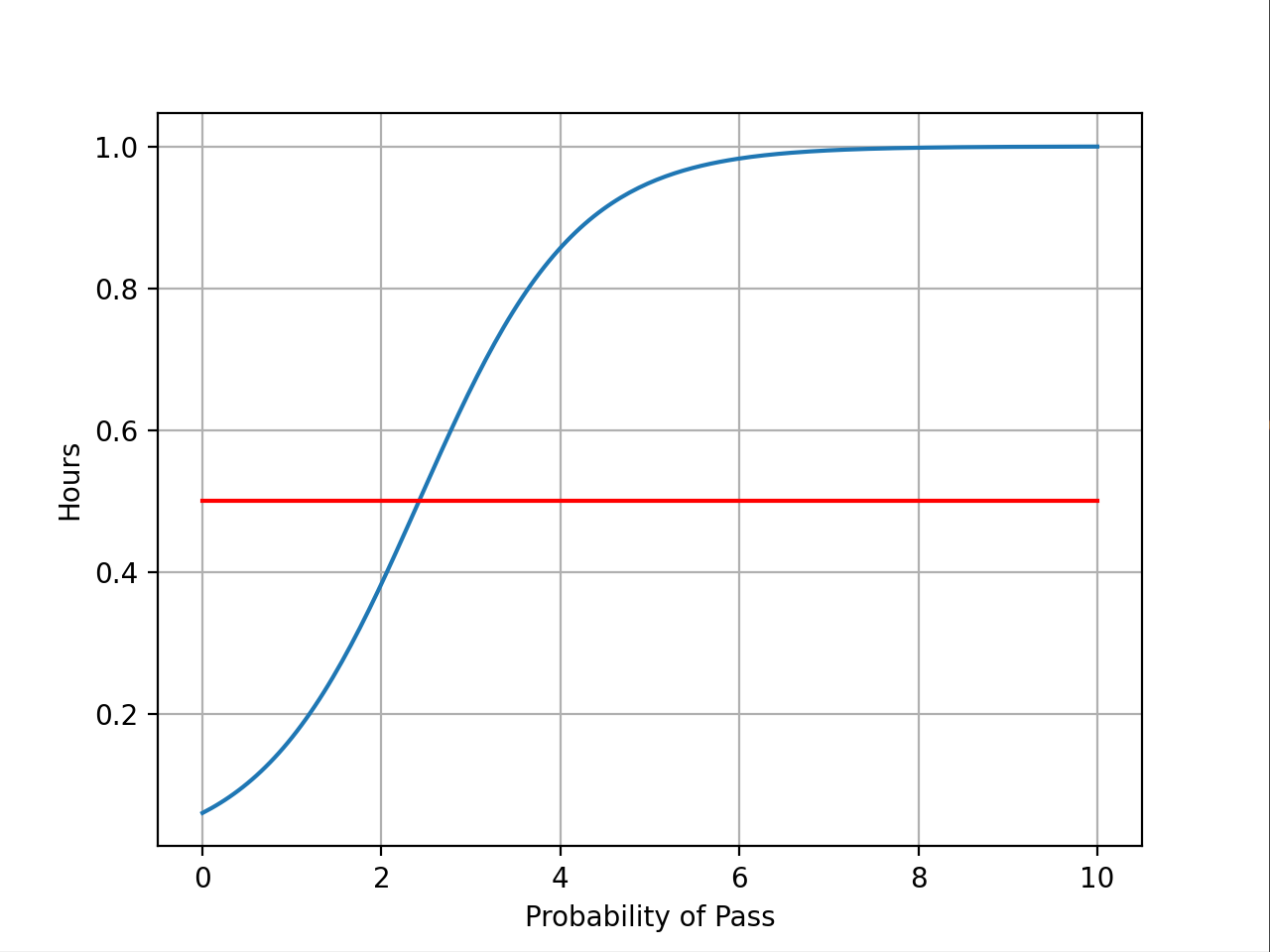
x = np.linspace(0, 10, 200) # 每周学习时间从0 ~ 10小时采样200个点
x_t = torch.Tensor(x).view((200, 1)) # 将学习时间x转成200行1列的张量,view类似numpy中的reshape
y_t = model(x_t) # 输给模型
y = y_t.data.numpy() # 将y_t的数据拿出来
plt.plot(x, y)
plt.plot([0, 10], [0.5, 0.5], c='r')
plt.ylabel('Hours')
plt.xlabel('Probability of Pass')
plt.grid()
plt.show()