1. 32位系统一个进程最多有多少堆内存
对 32 位操作系统而言,它的寻址空间是4G(2的32次方),Linux把它分为两部分:最高的1G(虚拟地址从0xC0000000到0xffffffff)用做内核本身,成为“内核空间”,而较低的3G字节(从0x00000000到0xbffffff)用作各进程的“用户空间”。每个进程可以使用的用户空间是3G。虽然各个进程拥有其自己的3G用户空间,系统空间却由所有的进程共享。从具体进程的角度看,则每个进程都拥有4G的虚拟空间,较低的3G为自己的用户空间,最高的1G为所有进程以及内核共享的系统空间。实际上有人做过测试也就2G左右。
2.为什么要有内核态和用户态
当我们在写程序是,凡是涉及到IO读写、内存分配等硬件资源的操作时,往往不能直接操作,而是通过一种叫系统调用的过程,让程序陷入到内核态运行,然后内核态的CPU执行有关硬件资源操作指令,得到相关的硬件资源后在返回到用户态继续执行,之间还要进行一系列的数据传输。
假设没有这种内核态和用户态之分,程序随随便便就能访问硬件资源,比如说分配内存,程序能随意的读写所有的内存空间,如果程序员一不小心将不适当的内容写到了不该写的地方,就很可能导致系统崩溃。
由于需要限制不同的程序之间的访问能力, 防止他们获取别的程序的内存数据, 或者获取外围设备的数据, 并发送到网络, CPU划分出两个权限等级 – 用户态和内核态
3. 内核态和用户态的区别
当进程运行在内核空间时就处于内核态,而进程运行在用户空间时则处于用户态,
在内核态下,进程运行在内核地址空间中,此时 CPU 可以执行任何指令。运行的代码也不受任何的限制,可以自由地访问任何有效地址,也可以直接进行端口的访问。
在用户态下,进程运行在用户地址空间中,被执行的代码要受到 CPU 的诸多检查,它们只能访问映射其地址空间的页表项中规定的在用户态下可访问页面的虚拟地址,且只能对任务状态段(TSS)中 I/O 许可位图(I/O Permission Bitmap)中规定的可访问端口进行直接访问。
对于 Linux 来说,通过区分内核空间和用户空间的设计,隔离了操作系统代码(操作系统的代码要比应用程序的代码健壮很多)与应用程序代码。即便是单个应用程序出现错误也不会影响到操作系统的稳定性,这样其它的程序还可以正常的运行(Linux 可是个多任务系统啊!)。
4. 如何从用户空间进入内核空间
其实所有的系统资源管理都是在内核空间中完成的。比如读写磁盘文件,分配回收内存,从网络接口读写数据等等。
我们的应用程序是无法直接进行这样的操作的。但是我们可以通过内核提供的接口来完成这样的任务。
比如应用程序要读取磁盘上的一个文件,它可以向内核发起一个 "系统调用" 告诉内核:"我要读取磁盘上的某某文件"。
其实就是通过一个特殊的指令让进程从用户态进入到内核态(到了内核空间),在内核空间中,CPU 可以执行任何的指令,当然也包括从磁盘上读取数据。具体过程是先把数据读取到内核空间中,然后再把数据拷贝到用户空间并从内核态切换到用户态。
此时应用程序已经从系统调用中返回并且拿到了想要的数据,可以开开心心的往下执行了。简单说就是应用程序把高科技的事情(从磁盘读取文件)外包给了系统内核,系统内核做这些事情既专业又高效。
对于一个进程来讲,从用户空间进入内核空间并最终返回到用户空间,这个过程是十分复杂的。举个例子,比如我们经常接触的概念 "堆栈",其实进程在内核态和用户态各有一个堆栈。
运行在用户空间时进程使用的是用户空间中的堆栈,而运行在内核空间时,进程使用的是内核空间中的堆栈。所以说,Linux 中每个进程有两个栈,分别用于用户态和内核态。
下图简明的描述了用户态与内核态之间的转换:
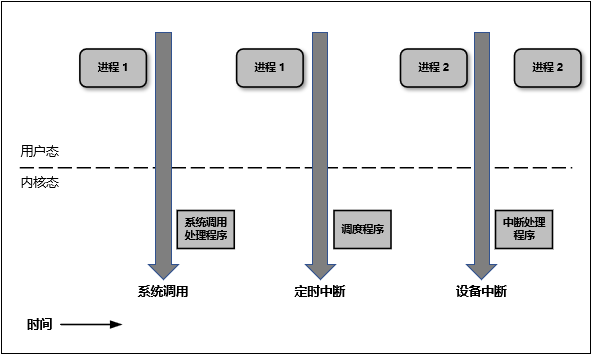
既然用户态的进程必须切换成内核态才能使用系统的资源,那么我们接下来就看看进程一共有多少种方式可以从用户态进入到内核态。
概括的说,有三种方式:系统调用、软中断和硬件中断。这三种方式每一种都涉及到大量的操作系统知识,所以这里不做展开。
5.用户态访问内核态资源的方式
用户态的应用程序可以通过三种方式来访问内核态的资源:
1)系统调用(给变量分配内存空间)
2)库函数(open() wirte() ,read())
3)Shell脚本
3.1、系统调用
系统调用是操作系统的最小功能单位,根据不同的应用场景,不同的Linux发行版本提供的系统调用数量也不尽相同,大致在240-350之间。系统调用组成了用户态跟内核态交互的基本接口。
例如:用户态想要申请一块20K大小的动态内存,就需要brk系统调用,将数据段指针向下偏移,如果用户态多处申请20K动态内存,同时又释放呢?这个内存的管理就变得非常的复杂。
我们可以把系统调用看成是一种不能再化简的操作(类似于原子操作,但是不同概念),有人把它比作一个汉字的一个“笔画”,而一个“汉字”就代表一个上层应用,因此,有时候如果要实现一个完整的汉字(给某个变量分配内存空间),就必须调用很多的系统调用。
3.2、库函数
库函数就是屏蔽这些复杂的底层实现细节,减轻程序员的负担,从而更加关注上层的逻辑实现。它对系统调用进行封装,提供简单的基本接口给用户,这样增强了程序的灵活性,当然对于简单的接口,也可以直接使用系统调用访问资源,例如:open(),write(),read()等等。库函数根据不同的标准也有不同的版本,例如:glibc库,posix库等。
接着上面的系统调用继续说:
系统调用过多,这势必会加重程序员的负担,良好的程序设计方法是:重视上层的业务逻辑操作,而尽可能避免底层复杂的实现细节。
库函数正是为了将程序员从复杂的细节中解脱出来而提出的一种有效方法。它实现对系统调用的封装,将简单的业务逻辑接口呈现给用户,方便用户调用,从这个角度上看,库函数就像是组成汉字的“偏旁”。
如“人”,对于复杂操作,我们借助于库函数来实现,如“仁”。显然,这样的库函数依据不同的标准也可以有不同的实现版本,如ISO C标准库,POSIX标准库等。
3.3、Shell脚本
Shell是一个特殊的应用程序,俗称命令行,本质上是一个命令解释器,它下通系统调用,上通各种应用,通常充当着一种“胶水”的角色,来连接各个小功能程序,让不同程序能够以一个清晰的接口协同工作,从而增强各个程序的功能。
Shell 就是一个“中间商”,它在用户和内核之间“倒卖”数据,只是用户不知道罢了。
Shell 本身并不是内核的一部分,它只是站在内核的基础上编写的一个应用程序,它和 QQ、迅雷、Firefox等其它软件没有什么区别。然而Shell 也有着它的特殊性,就是开机立马启动,并呈现在用户面前;用户通过 Shell 来使用Linux,不启动 Shell 的话,用户就没办法使用 Linux。
Shell 是如何连接用户和内核的?
shell 能够接收用户输入的命令,并对命令进行处理,处理完毕后再将结果反馈给用户,比如输出到显示器、写入到文件等,这就是大部分读者对 Shell 的认知。
你看,我一直都在使用 Shell,哪有使用内核哦?我也没有看到 Shell 将我和内核连接起来呀?
其实,Shell 程序本身的功能是很弱的,比如文件操作、输入输出、进程管理等都得依赖内核。我们运行一个命令,大部分情况下 Shell 都会去调用内核暴露出来的接口,这就是在使用内核,只是这个过程被 Shell 隐藏了起来,它自己在背后默默进行,我们看不到而已。
接口其实就是一个一个的函数,使用内核就是调用这些函数。这就是使用内核的全部内容了吗?嗯,是的!除了函数,你没有别的途径使用内核。
原文链接:https://blog.csdn.net/JMW1407/article/details/107901155
参考链接:(314条消息) Linux操作系统常见面试题(持续更新)_linux操作系统面试问题_fanhuashuiyue的博客-CSDN博客