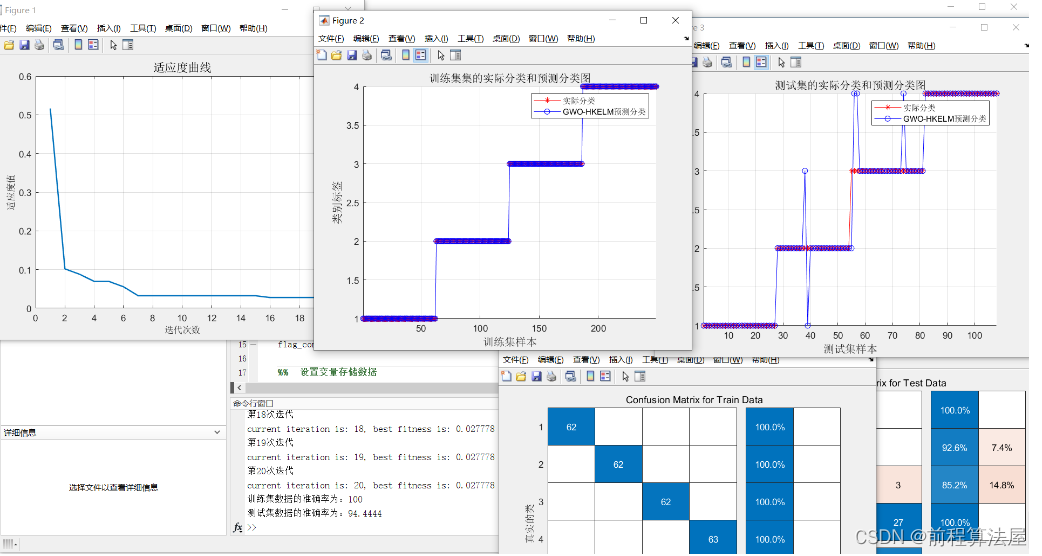
一、内存屏障简介
现在大多数现代计算机为了提高性能而采取乱序执行,这可能会导致程序运行不符合我们预期,内存屏障就是一类同步屏障指令,是CPU或者编译器在对内存随机访问的操作中的一个同步点,只有在此点之前的所有读写操作都执行后才可以执行此点之后的操作。
内存屏障,也称内存栅栏,内存栅障,屏障指令等, 是一类同步屏障指令,是CPU或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。
大多数现代计算机为了提高性能而采取乱序执行,这使得内存屏障成为必须。
语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。因此,对于敏感的程序块,写操作之后、读操作之前可以插入内存屏障。
大多数处理器提供了内存屏障指令:
- 完全内存屏障(full memory barrier)保障了早于屏障的内存读写操作的结果提交到内存之后,再执行晚于屏障的读写操作。
- 内存读屏障(read memory barrier)仅确保了内存读操作;
- 内存写屏障(write memory barrier)仅保证了内存写操作。
内核代码里定义了这三种内存屏障,如x86平台:arch/x86/include/asm/barrier.h
#define mb() asm volatile("mfence":::"memory")
#define rmb() asm volatile("lfence":::"memory")
#define wmb() asm volatile("sfence" ::: "memory")
个人理解:就类似于我们喝茶的时候需要先把水煮开(限定条件),然后再切茶,而这一整套流程都是限定特定环节的先后顺序(内存屏障),保障切出来的茶可以更香。
1.1内存屏障是什么
- 硬件层的内存屏障分为两种:Load Barrier 和 Store Barrier即读屏障和写屏障。
- 内存屏障有两个作用:
阻止屏障两侧的指令重排序;
强制把写缓冲区/高速缓存中的脏数据等写回主内存,让缓存中相应的数据失效。
- 对于Load Barrier来说,在指令前插入Load Barrier,可以让高速缓存中的数据失效,强制从新从主内存加载数据;
- 对于Store Barrier来说,在指令后插入Store Barrier,能让写入缓存中的最新数据更新写入主内存,让其他线程可见。
1.2不同场景内存屏障
java内存屏障
- java的内存屏障通常所谓的四种即LoadLoad,StoreStore,LoadStore,StoreLoad实际上也是上述两种的组合,完成一系列的屏障和数据同步功能。
- LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
- StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
- LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
- StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能
volatile语义中的内存屏障
volatile的内存屏障策略非常严格保守,非常悲观且毫无安全感的心态:
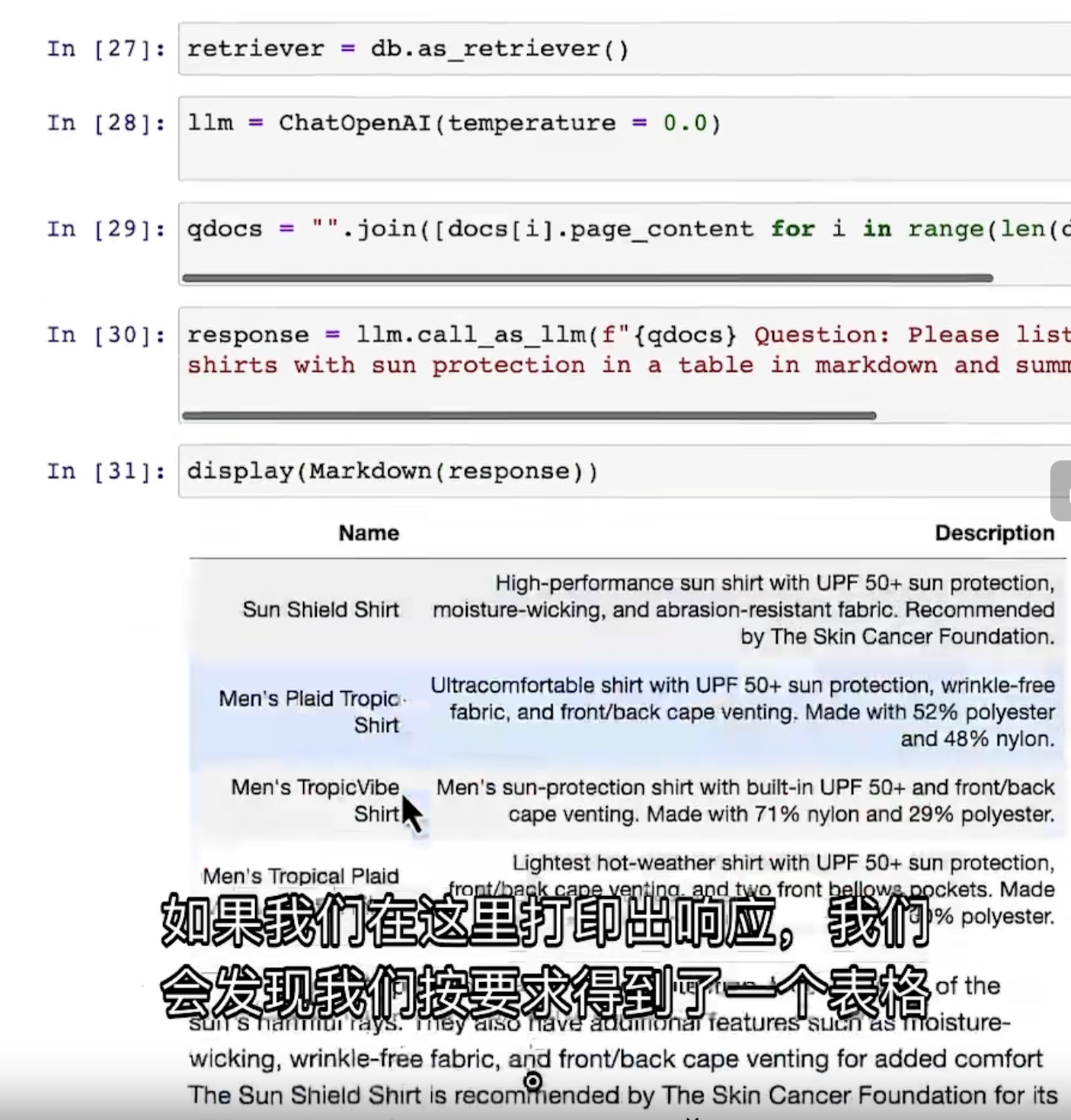
- 在每个volatile写操作前插入StoreStore屏障,在写操作后插入StoreLoad屏障;
- 在每个volatile读操作前插入LoadLoad屏障,在读操作后插入LoadStore屏障;
由于内存屏障的作用,避免了volatile变量和其它指令重排序、线程之间实现了通信,使得volatile表现出了锁的特性。
final语义中的内存屏障
对于final域,编译器和CPU会遵循两个排序规则:
新建对象过程中,构造体中对final域的初始化写入和这个对象赋值给其他引用变量,这两个操作不能重排序;
初次读包含final域的对象引用和读取这个final域,这两个操作不能重排序;(意思就是先赋值引用,再调用final值)
总之上面规则的意思可以这样理解,必需保证一个对象的所有final域被写入完毕后才能引用和读取。这也是内存屏障的起的作用:
写final域:在编译器写final域完毕,构造体结束之前,会插入一个StoreStore屏障,保证前面的对final写入对其他线程/CPU可见,并阻止重排序。
读final域:在上述规则2中,两步操作不能重排序的机理就是在读final域前插入了LoadLoad屏障。
X86处理器中,由于CPU不会对写-写操作进行重排序,所以StoreStore屏障会被省略;而X86也不会对逻辑上有先后依赖关系的操作进行重排序,所以LoadLoad也会变省略。
二、为什么会出现内存屏障
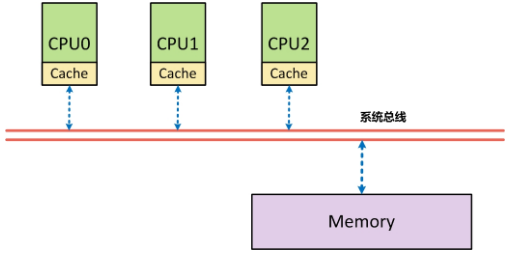
由于现在计算机存在多级缓存且多核场景,为了保证读取到的数据一致性以及并行运行时所计算出来的结果一致,在硬件层面实现一些指令,从而来保证指定执行的指令的先后顺序。比如上图:双核cpu,每个核心都拥有独立的一二级缓存,而缓存与缓存之间需要保证数据的一致性所以这里才需要加添屏障来确保数据的一致性。三级缓存为各CPU共享,最后都是主内存,所以这些存在交互的CPU都需要通过屏障手段来保证数据的唯一性。
内存屏障存在的意义就是为了解决程序在运行过程中出现的内存乱序访问问题,内存乱序访问行为出现的理由是为了提高程序运行时的性能,Memory Bariier能够让CPU或编译器在内存访问上有序。
在进一步剖析为什么会出现内存屏障之前,如果你对Cache原理还不了解,强烈建议先阅读一下这篇文章,对Cache有了一定的了解之后,再阅读下面的内容。
2.1、内存屏障出现的背景(内存乱序是怎么出现的?)
早期的处理器为有序处理器(In-order processors),有序处理器处理指令通常有以下几步:
- 指令获取
- 如果指令的输入操作对象(input operands)可用(例如已经在寄存器中了),则将此指令分发到适当的功能单元中。如果一个或者多个操 作对象不可用(通常是由于需要从内存中获取),则处理器会等待直到它们可用
- 指令被适当的功能单元执行
- 功能单元将结果写回寄存器堆(Register file,一个 CPU 中的一组寄存器)
相比之下,乱序处理器(Out-of-order processors)处理指令通常有以下几步:
- 指令获取
- 指令被分发到指令队列(Invalidate Queues,后面会讲到)
- 指令在指令队列中等待,直到输入操作对象可用(一旦输入操作对象可用,指令就可以离开队列,即便更早的指令未被执行)
- 指令被分配到适当的功能单元并执行
- 执行结果被放入队列(放入到store buffer中,而不是直接写到cache中,后面也会讲到)
- 只有所有更早请求执行的指令的执行结果被写入cache后,指令执行的结果才被写入cache(执行结果重排序,让执行看起来是有序的)
已经了解了cache的同学应该可以知道,如果CPU需要读取的地址中的数据已经已经缓存在了cache line中,即使是cpu需要对这个地址重复进行读写,对CPU性能影响也不大,但是一旦发生了cache miss(对这个地址进行第一次写操作),如果是有序处理器,CPU在从其他CPU获取数据或者直接与主存进行数据交互的时候需要等待不可用的操作对象,这样就会非常慢,非常影响性能。举个例子:
如果CPU0发起一次对某个地址的写操作,但是其local cache中没有数据,这个数据存放在CPU1的local cache中。为了完成这次操作,CPU0会发出一个invalidate的信号,使其他CPU的cache数据无效(因为CPU0需要重新写这个地址中的值,说明这个地址中的值将被改变,如果不把其他CPU中存放的该地址的值无效,那么就有可能会出现数据不一致的问题)。只有当其他之前就已经存放了改地址数据的CPU中的值都无效了后,CPU0才能真正发起写操作。需要等待非常长的时间,这就导致了性能上的损耗。
但是乱序处理器山就不需要等待不可用的操作对象,直接把invalidate message放到invalidate queues中,然后继续干其他事情,提高了CPU的性能,但也带来了一个问题,就是程序执行过程中,可能会由于乱序处理器的处理方式导致内存乱序,程序运行结果不符合我们预期的问题。
2.2理解内存屏障
不少开发者并不理解一个事实 — 程序实际运行时很可能并不完全按照开发者编写的顺序访问内存。例如:
x = r;
y = 1;
这里,y = 1很可能先于x = r执行。这就是内存乱序访问。内存乱序访问行为出现的理由是为了提升程序运行时的性能。编译器和CPU都可能引起内存乱序访问:
编译时,编译器优化进行指令重排而导致内存乱序访问;运行时,多CPU间交互引入内存乱序访问。
编译器和CPU引入内存乱序访问通常不会带来什么问题,但在一些特殊情况下(主要是多线程程序中),逻辑的正确性依赖于内存访问顺序,
这时,内存乱序访问会带来逻辑上的错误,例如:
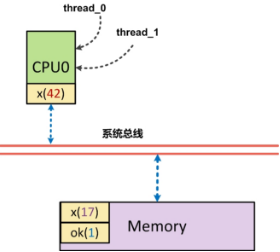
// thread 1
while(!ok);
do(x);
// thread 2
x = 42;
ok = 1;
Ok初始化为0, 线程1等待ok被设置为1后执行do函数。
假如,线程2对内存的写操作乱序执行,也就是x赋值晚于ok赋值完成,那么do函数接受的实参很有可能出乎开发者的意料,不为42。
我们可以引入内存屏障来避免上述问题的出现。内存屏障能让CPU或者编译器在内存访问上有序。一个内存屏障之前的内存访问操作必定先于其之后的完成。
内存屏障包括两类:编译器屏障和CPU内存屏障。
编译时内存乱序访问
编译器对代码做出优化时,可能改变实际执行指令的顺序(例如g++下O2或者O3都会改变实际执行指令的顺序),看一个例子:
int x, y, r;
void f()
{
x = r;
y = 1;
}
首先直接编译次源文件:g++ -S test.cpp。我们得到相关的汇编代码如下:
movl r(%rip), %eax
movl %eax, x(%rip)
movl $1, y(%rip)
这里我们可以看到,x = r和y = 1并没有乱序执行。现使用优化选项O2(或O3)编译上面的代码(g++ -O2 –S test.cpp),生成汇编代码如下:
movl r(%rip), %eax
movl $1, y(%rip)
movl %eax, x(%rip)
我们可以清楚地看到经过编译器优化之后,movl $1, y(%rip)先于movl %eax, x(%rip)执行,这意味着,编译器优化导致了内存乱序访问。
避免次行为的办法就是使用编译器屏障(又叫优化屏障)。
Linux内核提供了函数barrier(),用于让编译器保证其之前的内存访问先于其之后的内存访问完成。
(这个强制保证顺序的需求在哪里?换句话说乱序会带来什么问题内?—
一个线程执行了 y =1 , 但实际上x=r还没有执行完成,此时被另一个线程抢占,另一个线程执行,发现y=1,以为此时x必定=r,执行相应逻辑,造成错误)
内核实现barrier()如下:
#define barrier() __asm__ __volatile__("": : :"memory")
现在把此编译器barrier加入代码中:
int x, y, r;
void f()
{
x = r;
__asm__ __volatile__("": : :"memory")
y = 1;
}
再编译,就会发现内存乱序访问已经不存在了。
除了barrier()函数外,本例还可以使用volatile这个关键字来避免编译时内存乱序访问
(且仅能避免编译时的乱序访问,为什么呢,可以参考前面部分的说明,编译器对于volatile声明究竟做了什么–
volatile关键字对于编译器而言,是开发者告诉编译器,这个变量内存的修改,可能不再你可视范围内,不要对这个变量相关的代码进行优化)。
(ps:不同语言的volatile语义是存在一定差异的,比如这里volatile和java中)
volatile关键字能让volatile变量之间的内存访问上有序,这里可以修改x和y的定义来解决问题:
volatile int x, y, r;
通过volatile关键字,使得x相对y、y相对x在内存访问上是有序的。
实际上,Linux内核中,宏ACCESS_ONCE能避免编译器对于连续的ACCESS_ONCE实例进行指令重排,其就是通过volatile实现的:
#define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x))
此代码只是将变量x转换为volatile的而已。现在我们就有了第三个修改方案:
int x, y, r;
void f()
{
ACCESS_ONCE(x) = r;
ACCESS_ONCE(y) = 1;
}
到此,基本上就阐述完成了编译时内存乱序访问的问题。下面看看CPU会有怎样的行为。
运行时内存乱序访问
运行时,CPU本身是会乱序执行指令的。早期的处理器为有序处理器(in-order processors),总是按开发者编写的顺序执行指令, 如果指令的输入操作对象(input operands)不可用(通常由于需要从内存中获取), 那么处理器不会转而执行那些输入操作对象可用的指令,而是等待当前输入操作对象可用。
相比之下,乱序处理器(out-of-order processors)会先处理那些有可用输入操作对象的指令(而非顺序执行) 从而避免了等待,提高了效率。现代计算机上,处理器运行的速度比内存快很多, 有序处理器花在等待可用数据的时间里已可处理大量指令了。即便现代处理器会乱序执行, 但在单个CPU上,指令能通过指令队列顺序获取并执行,结果利用队列顺序返回寄存器堆(详情可参考http:// http://en.wikipedia.org/wiki/Out-of-order_execution),这使得程序执行时所有的内存访问操作看起来像是按程序代码编写的顺序执行的, 因此内存屏障是没有必要使用的(前提是不考虑编译器优化的情况下)。
SMP架构需要内存屏障的进一步解释:
从体系结构上来看,首先在SMP架构下,每个CPU与内存之间,都配有自己的高速缓存(Cache),以减少访问内存时的冲突
采用高速缓存的写操作有两种模式:
(1). 穿透(Write through)模式,每次写时,都直接将数据写回内存中,效率相对较低;
(2). 回写(Write back)模式,写的时候先写回告诉缓存,然后由高速缓存的硬件再周转复用缓冲线(Cache Line)时自动将数据写回内存,
或者由软件主动地“冲刷”有关的缓冲线(Cache Line)。
出于性能的考虑,系统往往采用的是模式2来完成数据写入。
正是由于存在高速缓存这一层,正是由于采用了Write back模式的数据写入,才导致在SMP架构下,对高速缓存的运用可能改变对内存操作的顺序。
已上面的一个简短代码为例:
// thread 0 -- 在CPU0上运行
x = 42;
ok = 1;
// thread 1 – 在CPU1上运行
while(!ok);
print(x);
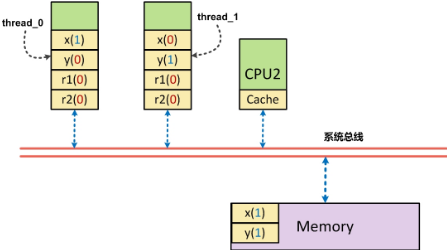
这里CPU1执行时, x一定是打印出42吗?让我们来看看以下图为例的说明:
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
假设,正好CPU0的高速缓存中有x,此时CPU0仅仅是将x=42写入到了高速缓存中,
另外一个ok也在高速缓存中,但由于周转复用高速缓冲线(Cache Line)而导致将ok=1刷会到了内存中,
此时CPU1首先执行对ok内存的读取操作,他读到了ok为1的结果,进而跳出循环,读取x的内容,
而此时,由于实际写入的x(42)还只在CPU0的高速缓存中,导致CPU1读到的数据为x(17)。
程序中编排好的内存访问顺序(指令序:program ordering)是先写入x,再写入y。
而实际上出现在该CPU外部,即系统总线上的次序(处理器序:processor ordering),却是先写入y,再写入x(这个例子中x还未写入)。
在SMP架构中,每个CPU都只知道自己何时会改变内存的内容,但是都不知道别的CPU会在什么时候改变内存的内容,也不知道自己本地的高速缓存中的内容是否与内存中的内容不一致。
反过来,每个CPU都可能因为改变了内存内容,而使得其他CPU的高速缓存变的不一致了。在SMP架构下,由于高速缓存的存在而导致的内存访问次序(读或写都有可能书序被改变)的改变很有可能影响到CPU间的同步与互斥。
因此需要有一种手段,使得在某些操作之前,把这种“欠下”的内存操作(本例中的x=42的内存写入)全都最终地、物理地完成,就好像把欠下的债都结清,
然后再开始新的(通常是比较重要的)活动一样。这种手段就是内存屏障,其本质原理就是对系统总线加锁。
回过头来,我们再来看看为什么非SMP架构(UP架构)下,运行时内存乱序访问不存在。
在单处理器架构下,各个进程在宏观上是并行的,但是在微观上却是串行的,因为在同一时间点上,只有一个进程真正在运行(系统中只有一个处理器)。
在这种情况下,我们再来看看上面提到的例子:
线程0和线程1的指令都将在CPU0上按照指令序执行。thread0通过CPU0完成x=42的高速缓存写入后,再将ok=1写入内存,此后串行的将thread0换出,thread1换入,及时此时x=42并未写入内存,但由于thread1的执行仍然是在CPU0上执行,他仍然访问的是CPU0的高速缓存,因此,及时x=42还未写回到内存中,thread1势必还是先从高速缓存中读到x=42,再从内存中读到ok=1。
综上所述,在单CPU上,多线程执行不存在运行时内存乱序访问,我们从内核源码也可得到类似结论(代码不完全摘录)
#define barrier() __asm__ __volatile__("": : :"memory")
#define mb() alternative("lock; addl $0,0(%%esp)", "mfence", X86_FEATURE_XMM2)
#define rmb() alternative("lock; addl $0,0(%%esp)", "lfence", X86_FEATURE_XMM2)
#ifdef CONFIG_SMP
#define smp_mb() mb()
#define smp_rmb() rmb()
#define smp_wmb() wmb()
#define smp_read_barrier_depends() read_barrier_depends()
#define set_mb(var, value) do { (void) xchg(&var, value); } while (0)
#else
#define smp_mb() barrier()
#define smp_rmb() barrier()
#define smp_wmb() barrier()
#define smp_read_barrier_depends() do { } while(0)
#define set_mb(var, value) do { var = value; barrier(); } while (0)
#endif
这里可看到对内存屏障的定义,如果是SMP架构,smp_mb定义为mb(),mb()为CPU内存屏障(接下来要谈的),而非SMP架构时(也就是UP架构),直接使用编译器屏障,运行时内存乱序访问并不存在。
为什么多CPU情况下会存在内存乱序访问?
我们知道每个CPU都存在Cache,当一个特定数据第一次被其他CPU获取时,此数据显然不在对应CPU的Cache中(这就是Cache Miss)。
这意味着CPU要从内存中获取数据(这个过程需要CPU等待数百个周期),此数据将被加载到CPU的Cache中,这样后续就能直接从Cache上快速访问。
当某个CPU进行写操作时,他必须确保其他CPU已将此数据从他们的Cache中移除(以便保证一致性),只有在移除操作完成后,此CPU才能安全地修改数据。
显然,存在多个Cache时,必须通过一个Cache一致性协议来避免数据不一致的问题,而这个通信的过程就可能导致乱序访问的出现,也就是运行时内存乱序访问。
受篇幅所限,这里不再深入讨论整个细节,有兴趣的读者可以研究《Memory Barriers: a Hardware View for Software Hackers》这篇文章,它详细地分析了整个过程。
现在通过一个例子来直观地说明多CPU下内存乱序访问的问题:
volatile int x, y, r1, r2;
//thread 1
void run1()
{
x = 1;
r1 = y;
}
//thread 2
void run2
{
y = 1;
r2 = x;
}
变量x、y、r1、r2均被初始化为0,run1和run2运行在不同的线程中。
如果run1和run2在同一个cpu下执行完成,那么就如我们所料,r1和r2的值不会同时为0,而假如run1和run2在不同的CPU下执行完成后,由于存在内存乱序访问的可能,这时r1和r2可能同时为0。我们可以使用CPU内存屏障来避免运行时内存乱序访问(x86_64):
void run1()
{
x = 1;
//CPU内存屏障,保证x=1在r1=y之前执行
__asm__ __volatile__("mfence":::"memory");
r1 = y;
}
//thread 2
void run2
{
y = 1;
//CPU内存屏障,保证y = 1在r2 = x之前执行
__asm__ __volatile__("mfence":::"memory");
r2 = x;
}
里mfence的含义是什么?
x86/64系统架构提供了三中内存屏障指令:
(1) sfence; (2) lfence; (3) mfence。
sfence我认为其动作,可以看做是一定将数据写回内存,而不是写到高速缓存中。
lfence的动作,可以看做是一定将数据从高速缓存中抹掉,从内存中读出来,而不是直接从高速缓存中读出来。
mfence则正好结合了两项操作。
sfence只确保写者在将数据(A->B)写入内存的顺序,并不确保其他人读(A,B)数据时,一定是按照先读A更新后的数据,再读B更新后的数据这样的顺序,
很有可能读者读到的顺序是A旧数据,B更新后的数据,A更新后的数据(只是这个更新后的数据出现在读者的后面,他并没有“实际”去读);
同理,lfence也就只能确保读者在读入顺序时,按照先读A最新的在内存中的数据,再读B最新的在内存中的数据的顺序,
但如果没有写者sfence的配合,显然,即使顺序一致,内容还是有可能乱序。
为什么仅通过保证了写者的写入顺序(sfence), 还是有可能有问题?还是之前的例子
void run1()
{
x = 1;
//CPU内存屏障,保证x=1在r1=y之前执行
__asm__ __volatile__("sfence":::"memory");
r1 = y;
}
//thread 2
void run2
{
y = 1;
//CPU内存屏障,保证y = 1在r2 = x之前执行
__asm__ __volatile__("sfence":::"memory");
r2 = x;
}
如果仅仅是对“写入”操作进行顺序化,实际上,还是有可能使的上面的代码出现r1,r2同时为0(初始值)的场景:
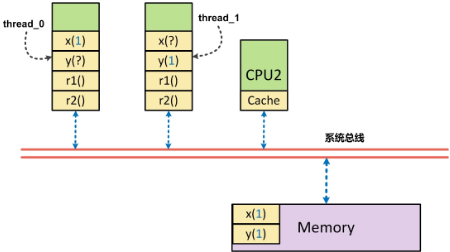
当CPU0上的thread0执行时,x被先行写回到内存中,但如果此时y在CPU0的高速缓存中,这时y从缓存中读出,并被赋予r1写回内存,此时r1为0。
同理,CPU1上的thread1执行时,y被先行写回到内存中,如果此时x在CPU1的高速缓存中存在,则此时r2被赋予了x的(过时)值0,同样存在了r1, r2同时为0。
这个现象实际上就是所谓的r1=y的读顺序与x=1的写顺序存在逻辑上的乱序所致(或者是r2 = x与y=1存在乱序) —
读操作与写操作之间存在乱序。而mfence就是将这类乱序也屏蔽掉。
如果是通过mfence,是怎样解决该问题的呢?
当thread1在CPU0上对x=1进行写入时,x=1被刷新到内存中,由于是mfence,他要求r1的读取操作从内存读取数据,而不是从缓存中读取数据,
因此,此时如果y更新为1,则r1 = 1; 【原文此处错误】.
同时此时由于x更新为1, r2必须从内存中读取数据,则此时r2 = 1。总而言之是r1, r2, 都为1。
Full Barrier
mfence指令实现了Full Barrier,相当于StoreLoad Barriers。mfence指令综合了sfence指令与lfence指令的作用,强制所有在mfence指令之前的store/load指令,都在该mfence指令执行之前被执行;所有在mfence指令之后的store/load指令,都在该mfence指令执行之后被执行。即,禁止对mfence指令前后store/load指令的重排序跨越mfence指令,使所有Full Barrier之前发生的操作,对所有Full Barrier之后的操作都是可见的。
mfence指令对所有CPU都可见。
2.3内存屏障的分类
编译屏障
编译屏障只是告诉编译器,不要对当前代码进行过度的优化,保证生成的汇编代码的次序与当前高级语言的次序保持一致。编译屏障对CPU执行时产生的重排序没有任何作用。
写内存屏障
一个写内存屏障可以提供这样的保证,站在系统中的其它组件的角度来看,在屏障之前的写操作看起来将在屏障后的写操作之前发生。
如果映射到上面的例子来说,首先,写内存屏障会对处理器指令重排序做出一些限制,也就是在写内存屏障之前的写入指令一定不会被重排序到写内存屏障之后的写入指令之后。其次,在执行写内存屏障之后的写入指令之前,一定要保证清空当前CPU存储缓冲中的所有写操作,将它们全部“提交”到缓存中。这样的话系统中的其它组件(包括别的CPU),就可以保证在看到写内存屏障之后的写入数据之前先看到写内存屏障之前的写入数据。
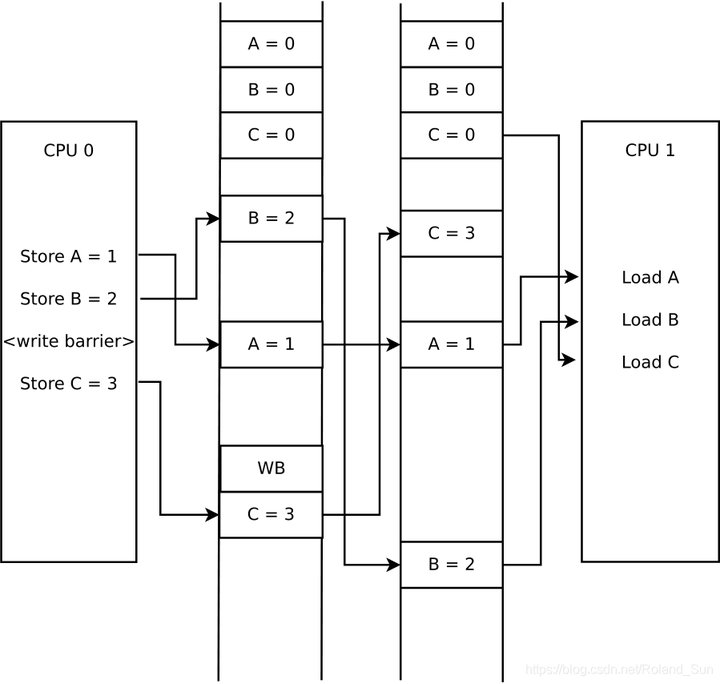
写内存屏障仅仅限制了CPU对写操作的排序,对加载操作没有任何效果,对其它的指令也没有作用。而且,写内存屏障只是保证在写内存屏障之后的写入操作一定是在写内存屏障之前的写入操作之后被系统其它组件感知,它并不能保证在写内存屏障之前的所有写入操作的顺序,也不能保证在写内存屏障之后的所有写入操作的顺序。
写内存屏障只管自己CPU上的写入操作能够按照一定次序被系统中其它部件感知,但是如果其它部件有缓存将旧数据缓存下来了,这它管不着。这个是下面介绍的读内存屏障要管的事,因此一般写内存屏障要和读内存屏障配对使用。
读内存屏障
一个读内存屏障可以提供这样的保证,站在系统中其它组件的角度来看,所有在读内存屏障之前的加载操作将在读内存屏障之后的加载操作之前发生。
还是用上面的例子来说明,首先,读内存屏障也会对处理器指令重排做出一些限制,也就是在读内存屏障之前的读取指令一定不会被重排序到读内存屏障之后的读取指令之后。其次,在执行读内存屏障之后的读取指令之前,一定要保证处理完当前CPU的无效队列。这样的话,当前CPU的缓存状态将完全遵照MESI协议,可以保证缓存数据一致性。
读内存屏障仅仅限制了CPU对加载操作的排序,对存储操作没有任何效果,对其它指令也没有任何作用。而且,读内存屏障只是保证在读内存屏障之后的读取操作一定是在读内存屏障之前的读取操作之后才去感知内存数据变化的,它并不能保证读内存屏障之前的所有读取操作顺序,也不能保证读内存屏障之后的所有读取操作的顺序。
读内存屏障只管自己CPU上的读取操作能够按照一定次序去感知系统内存中的值,但是对于其它CPU写入系统内存的次序没有任何约束。这个是上面介绍的写内存屏障要管的事,因此一般读内存屏障要和写内存屏障配对使用。
通用内存屏障(读写内存屏障)
一个通用内存屏障可以提供这样的保证,站在系统中其它组件的角度来看,通用内存屏障之前的加载、存储操作都将在通用内存屏障之后的加载、存储操作之前发生。
还是用上面的例子来说明,首先,通用内存屏障也会对处理器指令重排做出一些限制,也就是在通用内存屏障之前的写入和读取指令一定不会被重排序到通用内存屏障之后的写入和读取指令之后。其次,在执行通用内存屏障之后的任何写入和读取取指令之前,一定要保证清空当前CPU存储缓冲中的所有写操作,并且还要处理完当前CPU的无效队列。
通用内存屏障等同于同时包含了读和写内存屏障的功能,因此也可以替换它们中的任何一个,只不过可能会一定程度上影响性能。
通用内存屏障同时限制了CPU对加载操作和存储操作的排序,但是对其它指令没有任何作用。而且,通用内存屏障只是保证在通用内存屏障之后的所有写入和读取操作一定是在通用内存屏障之前的写入和读取操作之后才执行,它并不能保证通用内存屏障之前的所有读取和写入操作的顺序,也不能保证通用内存屏障之后的所有读取和写入操作的顺序。
一般写内存屏障、读内存屏障和通用内存屏障都会默认包含编译屏障。
其实还有一种叫做数据依赖屏障的东西,但这个只是在Alpha架构下才有用,这里不做讨论了。
三、为什么要有内存屏障
为了解决cpu,高速缓存,主内存带来的的指令之间的可见性和重序性问题。
我们都知道计算机运算任务需要CPU和内存相互配合共同完成,其中CPU负责逻辑计算,内存负责数据存储。CPU要与内存进行交互,如读取运算数据、存储运算结果等。由于内存和CPU的计算速度有几个数量级的差距,为了提高CPU的利用率,现代处理器结构都加入了一层读写速度尽可能接近CPU运算速度的高速缓存来作为内存与CPU之间的缓冲:将运算需要使用
的数据复制到缓存中,让CPU运算可以快速进行,计算结束后再将计算结果从缓存同步到主内存中,这样处理器就无须等待缓慢的内存读写了。就像下面这样:
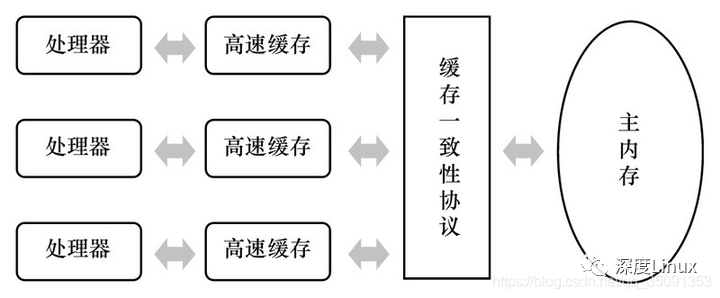
每个CPU都会有自己的缓存(有的甚至L1,L2,L3),缓存的目的就是为了提高性能,避免每次都要向内存取,但是这样的弊端也很明显:不能实时的和内存发生信息交换,会使得不同CPU执行的不同线程对同一个变量的缓存值不同。
用volatile关键字修饰变量可以解决上述问题,那么volatile是如何做到这一点的呢?那就是内存屏障,内存屏障是硬件层的概念,不同的硬件平台实现内存屏障的手段并不是一样,java通过屏蔽这些差异,统一由jvm来生成内存屏障的指令。
volatile的有序性和可见性
volatile的内存屏障策略非常严格保守,非常悲观且毫无安全感的心态:在每个volatile写操作前插入StoreStore屏障,在写操作后插入StoreLoad屏障;在每个volatile读操作前插入LoadLoad屏障,在读操作后插入LoadStore屏障;由于内存屏障的作用,避免了volatile变量和其它指令重排序、实现了线程之间通信,使得volatile表现出了锁的特性。
重排序:代码的执行顺序不按照书写的顺序,为了提升运行效率,在不影响结果的前提下,打乱代码运行
int a=1;
int b=2;
int c=a+b;
int c=5;
这里的int c=5这个赋值操作可能发生在int a=1这个操作之前
内存屏障的引入,本质上是由于CPU重排序指令引起的。重排序问题无时无刻不在发生,主要源自以下几种场景:
- 编译器编译时的优化;
- 处理器执行时的多发射和乱序优化;
- 读取和存储指令的优化;
- 缓存同步顺序(导致可见性问题)。
3.1编译器优化
编译器在不改变单线程程序语义的前提下,也就是保证单线程程序执行结果正确的情况下,可以重新安排语句的执行顺序。编译器在优化的时候是不知道当前程序是在哪个线程中执行的,因此它只能保证单线程的正确性。
例如,有如下程序:
if (a)
b = a;
else
b = 42;
在经过编译器优化后可能变成:
b = 42;
if (a)
b = a;
这种优化在单线程下是没有问题的,但是如果有另外一个线程要读取变量b的值时,有可能会有问题。前面的程序只有当变量a的值为0时,才会将b赋值42,后面的程序无论变量a的值是多少,都有一段时间会将b赋值为42。
造成这个问题的原因是,编译器优化的时候只注重“结果”,不注重“过程”。这种优化在单线程程序中没有问题,代码一直都是自己运行,只要结果对就可以了,但是在多线程程序下,代码执行过程中的某些状态可能会对别的线程产生影响,这个是编译器优化无法考虑到的。
3.2处理器执行时的多发射和乱序优化
现代处理器基本上都是支持多发射的,也就是在一个指令周期内可以同时执行多条指令。但是,处理器的资源就那么多,可能不能同时满足处理这些指令的要求。比如,处理器就只有一个加法器,如果同时有两条指令都需要算加法,那么有一条指令必须等待。如果这时候再下一条指令是读取指令,并且和前两条指令无关,那么这条指令将在前面某条加法指令之前完成。还有一种可能,就是前后指令之间具有相关性,比如对同一个地址先读取再写入,后面的写入操作必须等待前面的读取操作完成后才能执行。但是如果这时候第三条指令是写入一个无关的地址,那它可以在前面的写入操作之前被执行,执行顺序再次被打乱了。
所以,一般情况下指令乱序并不是CPU在执行指令之前刻意去调整顺序。CPU总是顺序的去内存里面取指令,然后将其顺序的放入指令流水线。但是指令执行时的各种条件,指令与指令之间的相互影响,可能导致顺序放入流水线的指令,最终不是按照放入的顺序执行完成,在外边看起来仿佛是“乱序”一样,这就是所谓的“顺序流入,乱序流出”。
3.3读取和存储指令的优化
CPU有可能根据情况,将相临的两条读取或写入操作合并成一条。
例如,对于如下的两条读取操作:
X = *A; Y = *(A + 4);
可能被合并成一条读取操作:
{X, Y} = LOAD {*A, *(A + 4) };
同样的,对于如下两条写入操作:
*A = X; *(A + 4) = Y;
有可能会被合并成一条:
STORE {*A, *(A + 4) } = {X, Y};
以上这几种情况,由于编译器或CPU,出于“优化”的目的,按照某种规则将指令重新排序的行为称作“真”重排序。不同的是,编译器重排序是在编译程序时进行的,一旦编译成功后执行次序就定下来了。而后面几种是在CPU运行程序时实时进行的,CPU架构不同可能起到的效果完全不同。
编译器或CPU在执行各种优化的时候,都有一些必须的前提,就是至少在单一CPU上执行不能出现问题。有一些数据访问明显是相互依赖的,就不能打乱它们的执行顺序。比如:
1)在一个给定的CPU上,有依赖的内存访问:
比如如下两条指令:
A = Load B;
C = Load *A
第二条加载指令的地址是由第一条指令加载的,第二条指令要能正确执行,必须要等到第一条指令执行完成后才行,也就是说第二条指令依赖于第一条指令。这种情况下,无论如何处理器是不会打乱这两条指令的执行次序的。不过,有可能会在这两条指令间插入别的指令,但必须保证第二条指令在第一条指令执行完后才能执行。
2)在一个给定的CPU上,交叉的加载和存储操作,它们访问的内存地址有重叠:
例如,先存储后加载同一个内存地址上的内容:
Store *X = A;
B = Load *X;
或者先加载后读取同一个内存地址上的内容:
A = Load *X;
Store *X = B;
对同一个内存地址的存取,如果两条指令执行次序被打乱了,那肯定会发生错误。但是,如果是两条加载或两条存储指令(中间没有加载),哪怕是对同一个内存地址的操作,也可能由于优化产生变化。
有了上面两条限制,很容易想到,那如果所有加载或存储指令都没有相关性呢?这时候就要看CPU的心情了,可以以任何次序被执行,可以完全不按照它们在程序中出现的次序。
3.4缓存同步顺序
上面的几种情况都比较好理解,最诡异的是所谓的缓存同步顺序的问题。要把这个问题说清楚首先要说一下缓存是什么。
现代CPU的运算速度比现代内存系统的速度快得多,它们的速度差了几个数量级,那怎么办呢?硬件设计者想到了在内存和CPU之间加入一个速度足够快,但空间不是很大的存储空间,这个就是所谓的缓存。缓存的速度足够快,但是它一般是某个或某些CPU核独享的,而不像计算机的主存,一般认为是系统中所有CPU共享的。
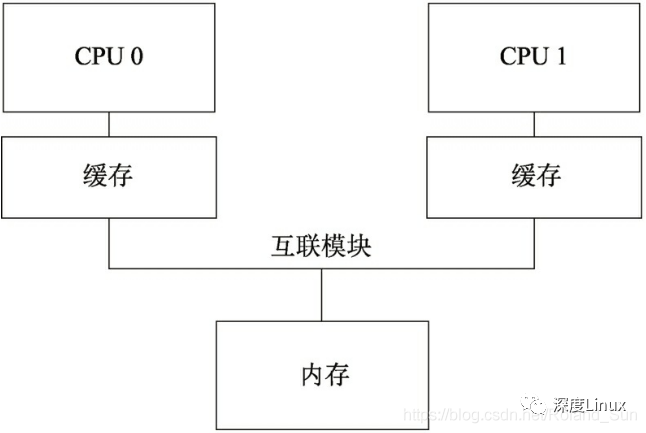
一旦引入了缓存,就会引入多个地方存放同一个数据的问题,就有可能出现数据不一致的问题。假设变量X所在内存同时被两个CPU都缓存了,但是这时候CPU0对变量X的值做出了修改,这之后CPU1如果试图读取变量X的值时,其实读到的是老的值。
这个时候就需要所谓的缓存一致性协议了,一般常用的是MESI协议。MESI代表“Modified”、“Exclusive”、“Shared”和“Invalid”四种状态的缩写,特定缓存行可以处在该协议采用的这四种状态上:
-
处于“Modified”状态的缓存行:当前CPU已经对缓存行的数据进行了修改,但是该缓存行的内容并没有在其它CPU的缓存中出现。因此,处于该状态的缓存行可以认为被当前CPU所“拥有”。这就是所谓的“脏”行,它的内容和内存中的内容不一样。由于只有当前CPU的缓存持有最新的数据,因此要么将“脏”数据写回到内存,要么将该数据“转移”给其它缓存。
-
处于“Exclusive”状态的缓存行:该状态非常类似于“Modified”状态,缓存的内容确保没有在其它CPU的缓存中出现。唯一的差别是,该缓存行还没有被当前的CPU修改,也就是说缓存行内容和内存中的是一样,是对内存数据的最新复制。但是,由于当前CPU能够在任何时刻将数据存储到该缓存行而不考虑其它CPU,因此处于“Exclusive”状态的缓存行也可以认为被当前CPU所“拥有”。
-
处于“Shared”状态的缓存行:表示缓存行的数据和主存中的一样,并且可能已经被复制到至少一个其它CPU的缓存中。但是,在没有得到其他CPU“许可”的情况下,任何CPU不能向该缓存行存储数据。与“Exclusive”状态相同,由于内存中的值是最新的,因此当需要丢弃该缓存行时,可以不用向内存回写。
-
处于“Invalid”状态的缓存行:表示该缓存行已经失效了,不能再被继续使用了。当有新数据进入缓存时,它可以直接放置到一个处于“Invalid”状态的缓存行上,不需要做其它的任何处理。
为了维护这个状态机,需要各个CPU之间进行通信**,会引入下面几种类型的消息:**
- 读消息:该消息包含要读取的缓存行的物理地址。
- 读响应消息:该消息包含较早前的读消息所请求的数据,这个读响应消息要么由物理内存提供,要么由某一个其它CPU上的缓存提供。例如,如果某一个CPU上的缓存拥有处于“Modified”状态的目标数据,那么该CPU上的缓存必须提供读响应消息。
- 使无效消息:该消息包含要使无效的缓存行的物理地址,所有其它CPU上的缓存必须移除相应的数据并且响应此消息。
- 使无效应答消息:一个接收到使无效消息的CPU必须在移除指定数据后响应一个使无效应答消息。
- 读使无效消息:该消息包含要被读取的缓存行的物理地址,同时指示其它CPU上的缓存移除对应的数据。因此,正如名字所示,它将读消息和使无效消息合并成了一条消息。读使无效消息同时需要一个读响应消息及一组使无效应答消息进行应答。
- 写回消息:该包含要回写到物理内存的地址和数据。这个消息允许缓存在必要时换出处于“Modified”状态的数据,以便为其它数据腾出空间。
通过上面的介绍可以看到,MESI缓存一致性协议可以保证系统中的各个CPU核上的缓存都是一致的。但是也带来了一个很大的问题,由于所有的操作都是“同步”的,必须要等待远端CPU完成指定操作后收到响应消息才能真正执行对应的存储或加载操作,这样会极大降低系统的性能。比如说,如果CPU0和CPU1上同时缓存了同一段数据,如果CPU0想对其进行更改,那么必须先发送使无效消息给CPU1,等到CPU1真的将该缓存的数据段标记成“Invalid”状态后,会向CPU0发送使无效应答消息,理论上只有CPU0收到这个消息后,才可以真的更改数据。但是,从要更改到真的能更改已经经过了好几个阶段了,这时CPU0只能等在那里。
鱼和熊掌都兼得是不可能的,想提高性能,只能稍微放松一下对缓存一致性的要求。
具体的,会引入如下两个模块:
存储缓冲:前面提到过,在写数据之前我们先要得到缓存段的独占权,如果当前CPU没有独占权,要先让系统中别的CPU上缓存的同一段数据都变成无效状态。为了提高性能,可以引入一个叫做存储缓冲(Store Buffer)的模块,将其放置在每个CPU和它的缓存之间。当前CPU发起写操作,如果发现没有独占权,可以先将要写入的数据放在存储缓冲中,并继续运行,仿佛独占权瞬间就得到了一样。当然,存储缓冲中的数据最后还是会被同步到缓存中的,但就相当于是异步执行了,不会让CPU等了。并且,当前CPU在读取数据的时候应该首先检查其是否存在于存储缓冲中。
无效队列:如果当前CPU上收到一条消息,要使某个缓存段失效,但是此时缓存正在处理其它事情,那这个消息可能无法在当前的指令周期中得到处理,而会将其放入所谓的无效队列(Invalidation Queue)中,同时立即发送使无效应答消息。那个待处理的使无效消息将保存在队列中,直到缓存有空为止。
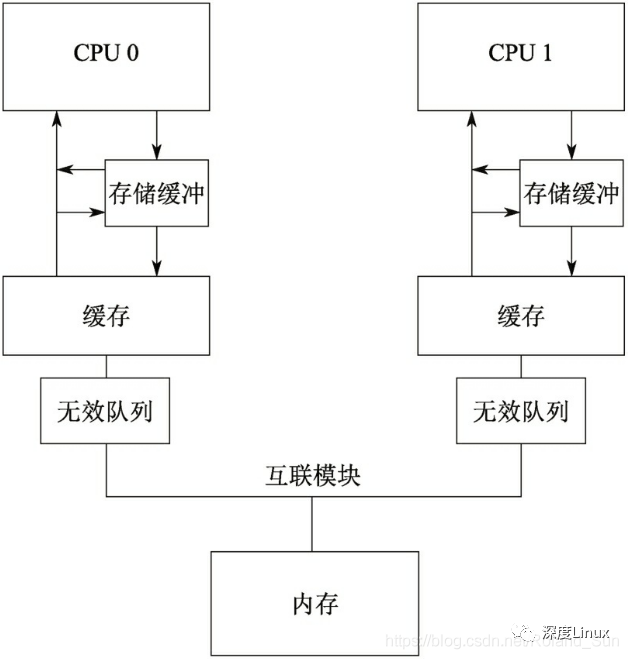
加入了这两个模块之后,CPU的性能是提高了,但缓存一致性就遭到了一定程度的破坏。假设变量X所在内存同时被两个CPU都缓存了,但是这时候CPU0对变量X的值做出了修改,这之后CPU1如果试图读取变量X的值时,有可能读到的是老的值,当然也有可能读到的是新的值。但是,在经过一段不确定的时间后,CPU1一定是可以读到变量X新的值,可以理解为满足所谓的最终一致性。
但这只是对单个变量来说的,如果程序中有多个变量,那么在其它CPU看来,它们之间的读写次序将完全无法得到保证。
假设有CPU0上要执行对三个变量的写操作:
Store A = 1;
Store B = 2;
Store C = 3;
但是,这三个变量在缓存中的状态不一样,假设A变量和B变量在CPU0和CPU1中的缓存都存在,也就是处于“Shared”状态,而C变量是CPU0独占的,也就是处于“Exclusive”状态。假设系统经历了如下几个步骤:
在对变量A和B赋值时,CPU0发现其实别的CPU也缓存了,因此会将它们临时放到存储缓冲中。
在对变量C赋值时,CPU0发现是独占的,那么可以直接修改缓存的值,该缓存行的状态被切换成了“Modified”。注意,这个时候,如果在CPU1上执行了读取变量C的操作,其实已经可以读到变量C的最新值了,CPU1发送读消息,CPU0发送读响应消息,包含最新的数据,同时将缓存行的状态都切换成“Shared”。但是,如果这个时候如果CPU1尝试读取变量A或者变量B的数据,将会获得老的数据,应为CPU1上对应变量A和B的缓存行的状态仍然是“Shared”。
CPU0开始处理对应变量A和B的存储缓冲,将它们更新进缓存,但之前必须要向CPU1发送使无效消息。这里再次假设变量A的缓存正忙,而变量B的可以立即处理。那么变量A的使无效消息将存放在CPU1的无效队列中,而变量B的缓存行已经失效。这时,如果CPU1尝试获得变量B,是可以获得最新的数据的,而变量A还是不行。
CPU1对应变量A的缓存已经空闲了,可以处理当前无效队列的请求,因此变量A对应的缓存行将失效。直到这时CPU1才可以真正的读到变量A的最新值。
通过以上的步骤可以看到,虽然在CPU0上是先对变量A赋值,接着对B赋值,最后对C赋值,但是在CPU1上“看到”的顺序刚好是相反的,先“看到”C,接着“看到”B,最后看到“C”。在CPU1上会产生一种错觉,方式CPU0是先对C赋值,再对B赋值,最后对A赋值一样。这种由于缓存同步顺序的问题,让程序看起来好像指令被重排序了的情况,称作“伪”重排序。
四、内存一致性模型
内存一致性模型(Memory Consistency Model)是用来描述多线程对共享存储器的访问行为,在不同的内存一致性模型里,多线程对共享存储器的访问行为有非常大的差别。这些差别会严重影响程序的执行逻辑,甚至会造成软件逻辑问题。
不同的处理器架构,使用了不同的内存一致性模型,目前有多种内存一致性模型,从上到下模型的限制由强到弱:
- 顺序一致性(Sequential Consistency)模型
- 完全存储定序(Total Store Order)模型
- 部分存储定序(Part Store Order)模型
- 宽松存储(Relax Memory Order)模型
注意,这里说的内存模型是针对可以同时执行多线程的平台,如果只能同时执行一个线程,也就是系统中一共只有一个CPU核,那么它一定是满足顺序一致性模型的。
对于内存的访问,我们只关心两种类型的指令的顺序,一种是读取,一种是写入。对于读取和加载指令来说,它们两两一起,一共有四种组合:
- LoadLoad:前一条指令是读取,后一条指令也是读取。
- LoadStore:前一条指令是读取,后一条指令是写入。
- StoreLoad:前一条指令是写入,后一条指令是读取。
- StoreStore:前一条指令是写入,后一条指令也是写入。
顺序一致性模型
顺序存储模型是最简单的存储模型,也称为强定序模型。CPU会按照代码来执行所有的读取与写入指令,即按照它们在程序中出现的次序来执行。同时,从主存储器和系统中其它CPU的角度来看,感知到数据变化的顺序也完全是按照指令执行的次序。也可以理解为,在程序看来,CPU不会对指令进行任何重排序的操作。在这种模型下执行的程序是完全不需要内存屏障的。但是,带来的问题就是性能会比较差,现在已经没有符合这种内存一致性模型的系统了。
为了提高系统的性能,不同架构都会或多或少的对这种强一致性模型进行了放松,允许对某些指令组合进行重排序。注意,这里处理器对读取或写入操作的放松,是以两个操作之间不存在数据依赖性为前提的,处理器不会对存在数据依赖性的两个内存操作做重排序。
完全存储定序模型
这种内存一致性模型允许对StoreLoad指令组合进行重排序,如果第一条指令是写入,第二条指令是读取,那么有可能在程序看来,读取指令先于写入指令执行。但是,对于其它另外三种指令组合还是可以保证按照顺序执行。
这种模型就相当于前面提到的,在CPU和缓存中间加入了存储缓冲,而且这个缓冲还是一个满足先入先出(FIFO)的队列。先入先出队列就保证了对StoreStore这种指令组合也能保证按照顺序被感知。
我们非常熟悉的X86架构就是使用的这种内存一致性模型。
部分存储定序模型
这种内存一致性模型除了允许对StoreLoad指令组合进行重排序外,还允许对StoreStore指令组合进行重排序。但是,对于其它另外两种指令组合还是可以保证按照顺序执行。
这种模型就相当于也在CPU和缓存中间加入了存储缓冲,但是这个缓冲不是先入先出的。
宽松存储模型
这种内存一致性模型允许对上面说的四种指令组合都进行重排序。
这种模型就相当于前面说的,既有存储缓冲,又有无效队列的情况。
这种内存模型下其实还有一个细微的差别,就是所谓的数据依赖性的问题。例如下面的程序,假设变量A初始值是0:
| CPU 0 | CPU 1 |
|---|---|
| A = 1; | Q = P; |
| B = *Q; | |
| P = &A; |
五、内存屏障的使用规则
前面提到过了,读、写内存屏障应该配对使用,或者换做通用内存屏障也需要成对的使用,否则起不到想要的效果。
配对使用场景
首先,来看最常用的组合,一个CPU上执行两个写入操作,中间用写内存屏障分割,另一个CPU上执行两个读取操作,中间用读内存屏障分割:
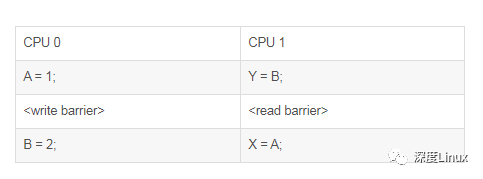
注意,在这种场景下写入变量的顺序和读取变量的顺序刚好要是相反的。加了这一对读、写内存屏障后,可以保证,在两个CPU都执行完上面的代码后,如果Y的值等于2,那么X的值一定等于1。Y的值等于2,意味着在CPU0上对B赋值2的语句已经执行过了,由于有写内存屏障的存在,也就意味着对A赋值1的语句在之前肯定也被执行过了。在CPU1上,由于有读内存屏障的存在,表示读取变量A值的语句一定在读取变量B值的语句之后被执行,也就可以保证,这时候变量A的值一定已经被赋值成了1。
第二种场景,两个CPU上都执行一个读取操作,接着一个写入操作,中间用通用内存屏障分割:
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
假设变量A和B的初始值都是0,当两个CPU都执行完上面的代码后,如果有Y等于2,那么X一定等于0。如果Y等于2,也就意味着在CPU1上对A赋值1的语句,一定在CPU0上读取变量A值的语句之后被执行。同时,由于对称性,如果有X等于1,那么X一定等于0。
最后一种场景,一个 CPU 执行一个读取操作,后面跟一个通用内存屏障,再后面是一个写入操作;而另外一个CPU执行一对由
写内存屏障分开的写入操作:

这种情况下,如果X的值等于1,那么必然有B的值等于1。如果X的值等于1,就意味着在这之前CPU1上已经执行过了对A赋值1的语句,由于写内存屏障的存在,也就能够保证在CPU1上已经执行过了对B赋值2的语句,而在CPU0上由于有通用内存屏障的存在,那么对B赋值1的语句一定会在对X赋值的语句之后执行。也就是说,可以保证在CPU0上对B赋值1的语句,一定会在CPU1上对B赋值2的语句之后被执行。
为什么在单核系统上没有乱序的问题
还要说明一下,无论如何,即使某一个体系的内存模型再弱,有一些基本规则还是必须要遵守的(当然,对于编译器优化来说也要遵循这些规则。):
单个CPU总是按照编程顺序来感知它自己的内存访问。
仅仅在操作不同地址时,CPU才对给定的存储操作进行“真”重新排序。
还有,如果程序一直可以保证只在单个CPU核上执行,也就不存在所谓的缓存一致性问题。因此,仅仅在两个CPU之间或者CPU与设备之间存在需要交互的可能性时,才需要内存屏障。任何代码只要能够保证没有这样的交互就不需要使用内存屏障。也就是说,如果当前系统中只有一个CPU核,并且程序没有和设备打交道,即使是多线程的,也不需要使用内存屏障。
第一个规则从直观上说感觉和前面讲的重排序有点矛盾,不是说可以按照任何次序执行嘛,怎么又可以保证按照编程顺序来感知了。我们还是用前面的例子来说,代码如下:
thread0(void)
{
A = 1;
B = 2;
}
thread1(void)
{
while (B != 2)
continue;
assert(A != 0);
}
这段程序在没有编译器优化重排序的情况下,在单CPU系统上其实是可以正确运行的。CPU在执行的时候是不知道所谓的线程的,线程是操作系统的概念,CPU执行的时候只能感知到的是一个指令序列。对于上面的例子,这个指令序列应该是这样的:
Store A = 1;
Store B = 2;
......
Back:
Load B;
Test B != 2;
Jump Back If True;
Load A;
Test A != 0;
中间省略的是一些可能的线程切换的代码。然后,CPU会对这组指令序列进行重排序优化。但是,前面说了重排序优化是有前提条件的,因此无论如何不会将前面的将变量A赋值为1的语句重排序到后面读取变量A的语句之后,当然也不会将变量B赋值为2的语句重排序到后面读取变量B的语句之后,从而保证了这个两线程程序的正确运行。所以,前面的第一个规则其实和所谓的指令重排序是不矛盾的。
因此,在单CPU核的系统下,硬件保证程序至少看上去是按照指令的顺序被执行的,唯一可能更改指令顺序的就是编译器了,这时候所有内存屏障都将退化成编译器屏障。
但是,不使用内存屏障不代表不使用相应的同步机制。如果某个操作不是原子的,那么多线程访问它即使在单CPU的系统上也会出现问题,只不过这个问题不是因为重排序引起的。
六、有什么优化方法?
6.1硬件上的优化
store buffer
有一种可以阻止CPU进入阻塞状态的方法,就是在CPU和cache之间加入一个store buffer的硬件结构,如下图:
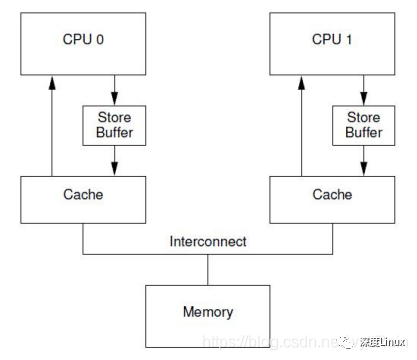
加入了这个硬件结构后,但CPU0需要往某个地址中写入一个数据时,它不需要去关心其他的CPU的local cache中有没有这个地址的数据,它只需要把它需要写的值直接存放到store buffer中,然后发出invalidate的信号,等到成功invalidate其他CPU中该地址的数据后,再把CPU0存放在store buffer中的数据推到CPU0的local cache中。每一个CPU core都拥有自己私有的store buffer,一个CPU只能访问自己私有的那个store buffer。
store buffer的弊端
先看看下面的代码,思考一下会不会出现什么问题
a = 1;
b = a + 1;
assert(b = 2);
我们假设变量a的数据存放在CPU1的local cache line中,变量b在CPU0的cache line中,如果我们单纯使用CPU来运行上面这段程序,应该是正常运行的,但是如果加入了store buffer这个硬件结构,就会出现assert失败的问题,到底是为什么呢?我们来走一走程序的流程。
CPU0执行a=1这条命令,由于CPU0本地没有数据,会发出read invalidate消息从CPU1那获得数据,并发出invalidate命令
- CPU0把要写入的数据放到store buffer中
- CPU1接收到了CPU0发来的read invalidate信号,将其local cache line 中的数据发送给CPU0,并把自己本地cache line中的数据设置为无效
- CPU0执行b=a+1
- CPU0接收到CPU1返回回来的a的值,等于0,b=0+1=1
- CPU0将store buffer中的a=1的值推入到cache中,造成了数据不一致性
store forwarding
硬件上出现一种新的设计,为了解决优化上面所说的store buffer的弊端, 具体结构如下图:

当CPU执行load操作的时候,不但要看cache,还要看store buffer中是否有内容,如果store buffer有该数据,那么就采用store buffer中的值。
但是这样,就能保证程序的正确运行,就能保证数据的一致性了吗?并不是!!
6.2软件上的优化
我们先来分析分析一个例子,看看下面的例子有可能会出现什么问题
void foo(void)
{
a = 1;
b = 1;
}
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
同样,我们假设a和b都是初始化为0,CPU0执行foo函数,CPU1执行bar函数,a变量在CPU1的cache中,b在CPU0的cache中
CPU0执行a=1的操作,由于a不在local cache中,CPU0会将a的值写入到store buffer中,然后发出read invalidate信号从其他CPU获取a 的值
CPU1执行while(b == 0),由于b不在local cache中,CPU发送一个read message到总线上,看看是否可以从其他CPU的local cache中或者memory中获取数据
CPU0继续执行b=1,由于b就在自己的local cache中,所以CPU0可以直接把b=1直接写入到local cache
CPU0收到read message,将最新的b=1的值回送到CPU1,同时把存放b数据的cache line在状态设置为sharded
CPU1收到来自CPU0的read response消息,将b变量的最新值1写入自己的cachelline,并设置为sharded。
由于b的值为1,CPU1跳出while循坏,继续执行
CPU1执行assert(a1),由于CPU1的local cache中a的值还是旧的值为0,assert(a1)失败。
这个时候,CPU1收到了CPU 0的read invalidate消息(执行了a=1),清空了自己local cache中a的值,但是已经太晚了
CPU0收到CPU1的invalidate ack消息后,将store buffer中的a的最新值写入到cache line,然并卵,CPU1已经assertion fali了。
这个时候,就需要加入一些memory barrier的操作了。说了这么久,终于说到了内存屏障了,我们把代码修改成下面这样:
void foo(void)
{
a = 1;
smp_mb();
b = 1;
}
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
可以看到我们在foo函数中增加了一个smp_mb()的操作,smp_mb有什么作用呢?
它主要是为了让数据在local cache中的操作顺序服务program order的顺序,那么它又是怎么让store buffer中存储的数据按照program order的顺序写入到cache中的呢?我们看看数据读写流程跟上面没有加smp_mb的时候有什么区别
- CPU0执行a=1的操作,由于a不在local cache中,CPU0会将a的值写入到store buffer中,然后发出read invalidate信号从其他CPU获取a 的值
- CPU1执行while(b == 0),由于b不在local cache中,CPU发送一个read message到总线上,看看是否可以从其他CPU的local cache中或者memory中获取数据
- CPU0在执行b=1前,我们先执行了smp_mb操作,给store buffer中的所有数据项做了一个标记marked,这里也就是给a做了个标记
- CPU0继续执行b=1,虽然b就在自己的local cache中,但是由于store buffer中有marked entry,所遇CPU0并没有把b的值直接写到cache中,而是把它写到了store buffer中
- CPU0收到read message,将最新的b=1的值回送到CPU1,同时把存放b数据的cache line在状态设置为sharded
- CPU1收到来自CPU0的read response消息,将b变量的值0写入自己的cachelline(因为b的最新值1还存放在store buffer中),并设置为sharded。
- 完成了bus transaction之后,CPU1可以load b到寄存器中了,当然,这个时候b的指还是0
- CPU1收到了来自CPU0的read invalidate消息(执行了a=1),清空了自己local cache中a的值
- CPU0将存放在store buffer中的a=1的值写入cache line中,并设置为modified
- 由于store buffer中唯一一个marked的entry已经写入到cache line中了,所以b也可以进入cache line。不过需要注意的是,当前b对应的cache line状态还是sharded(因为在CPU1中的cache line中还保留有b的数据)
- CPU0发送invalidate消息,CPU1清空自己的b cacheline,CPU0将b cacheline设置为exclusive
你以为这样就完了吗????NONONONO!!!!太天真了
6.3Invalidate Queues
不幸的是:每个CPU的store buffer不能实现地太大,其存储队列的数目也不会太多。当CPU以中等的频率执行store操作的时候(假设所有的store操作都导致了cache miss),store buffer会很快的呗填满。在这种情况下,CPU只能又进入阻塞状态,直到cacheline完成invalidation和ack的交互后,可以将store buffer的entry写入cacheline,从而让新的store让出空间之后,CPU才可以继续被执行。
这种情况也可能发生在调用了memory barrier指令之后,因为一旦store buffer中的某个entry被标记了,那么随后的store都必须等待invalidation完成,因此不管是否cache miss,这些store都必须进入store buffer。
这个时候,invalidate queues就出现了,它可也缓解这个情况。store buffer之所以很容易被填满,主要是因为其他CPU在回应invalidate acknowledge比较慢,如果能加快这个过程,让store buffer中的内容尽快写入到cacheline,那么就不会那么容易被填满了。
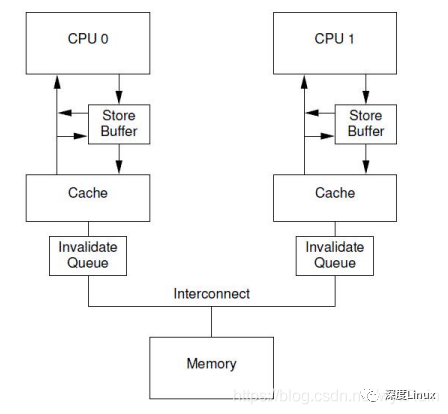
而invalidate acknowledge不能尽快回复的主要原因,是因为invalidate cacheline的操作没有那么块完成,特别是在cache比较繁忙的时候,如果再收到其他CPU发来的invalidate请求,只有在完成了invalidate操作后,本CPU才会发送invalidate acknowledge。
然而,CPU其实不需要完成invalidate就可以回送acknowledgement消息,这样就不会阻止发送invalidate的那个CPU进去阻塞状态。CPU可以将这些接收到的invalidate message存放到invalidate queues中,然后直接回应acknowledge,表示自己已经收到请求,随后会慢慢处理,当时前提是必须在发送invalidate message的CPU发送任何关于某变量对应cacheline的操作到bus之前完成。结构如下图:
七、关于内存屏障的一些补充
在实际的应用程序开发中,开发者可能完全不知道内存屏障就写出了正确的多线程程序,
这主要是因为各种同步机制中已隐含了内存屏障(但和实际的内存屏障有细微差别),使得不直接使用内存屏障也不会存在任何问题。但如果你希望编写诸如无锁数据结构,那么内存屏障意义重大。
在Linux内核中,除了前面说到的编译器屏障—barrier()和ACESS_ONCE(),还有CPU内存屏障:
通用屏障,保证读写操作有序,包括mb()和smp_mb(); 写操作屏障,仅保证写操作有序,包括wmb()和smp_wmb(); 读操作屏障,仅保证读操作有序,包括rmb()和smp_rmb();
注意,所有的CPU内存屏障(除了数据依赖屏障外)都隐含了编译器屏障(也就是使用CPU内存屏障后就无需再额外添加编译器屏障了)。
这里的smp开通的内存屏障会根据配置在单处理器上直接使用编译器屏障,而在SMP上才使用CPU内存屏障(即mb()、wmb()、rmb())。
还需要注意一点是,CPU内存屏障中某些类型的屏障需要成对使用,否则会出错,
详细来说就是:一个写操作屏障需要和读操作(或者数据依赖)屏障一起使用(当然,通用屏障也是可以的),反之亦然。
通常,我们是希望在写屏障之前出现的STORE操作总是匹配度屏障或者数据依赖屏障之后出现的LOAD操作。以之前的代码示例为例:
// thread 1
x = 42;
smb_wmb();
ok = 1;
// thread 2
while(!ok);
smb_rmb();
do(x);
我们这么做,是希望在thread2执行到do(x)时(在ok验证的确=1时),x = 42的确是有效的(写屏障之前出现的STORE操作),此时do(x),的确是在执行do(42)(读屏障之后出现的LOAD操作)
利用内存屏障实现无锁环形缓冲区
最后,以一个使用内存屏障实现的无锁环形缓冲区(只有一个读线程和一个写线程时)来结束本文。
本代码源于内核FIFO的一个实现,内容如下(略去了非关键代码):
代码来源:linux-2.6.32.63\kernel\kfifo.c
unsigned int __kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/*
* Ensure that we sample the fifo->out index -before- we
* start putting bytes into the kfifo.
* 通过内存屏障确保先读取fifo->out后,才将buffer中数据拷贝到
* 当前fifo中
*/
smp_mb();
/* first put the data starting from fifo->in to buffer end */
/* 将数据拷贝至fifo->in到fifo结尾的一段内存中 */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
/* 如果存在剩余未拷贝完的数据(此时len – l > 0)则拷贝至
* fifo的开始部分
*/
memcpy(fifo->buffer, buffer + l, len - l);
/*
* Ensure that we add the bytes to the kfifo -before-
* we update the fifo->in index.
*/
/*
* 通过写操作屏障确保数据拷贝完成后才更新fifo->in
*/
smp_wmb();
fifo->in += len;
return len;
unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->in - fifo->out);
/*
* Ensure that we sample the fifo->in index -before- we
* start removing bytes from the kfifo.
*/
/*
* 通过读操作屏障确保先读取fifo->in后,才执行另一个读操作:
* 将fifo中数据拷贝到buffer中去
*/
smp_rmb();
/* first get the data from fifo->out until the end of the buffer */
/* 从fifo->out开始拷贝数据到buffer中 */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
/* 如果需要数据长度大于fifo->out到fifo结尾长度,
* 则从fifo开始部分拷贝(此时len – l > 0)
*/
memcpy(buffer + l, fifo->buffer, len - l);
/*
* Ensure that we remove the bytes from the kfifo -before-
* we update the fifo->out index.
*/
/* 通过内存屏障确保数据拷贝完后,才更新fifo->out */
smp_mb();
fifo->out += len;
return len;
}
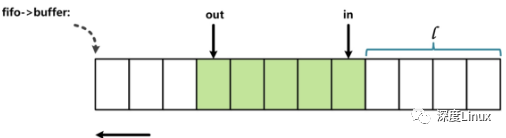
这里__kfifo_put被一个线程用于向fifo中写入数据,另外一个线程可以安全地调用__kfifo_get,从此fifo中读取数据。代码中in和out的索引用于指定环形缓冲区实际的头和尾。
具体的in和out所指向的缓冲区的位置通过与操作来求取(例如:fifo->in & (fifo->size -1)),这样相比取余操作来求取下表的做法效率要高不少。使用与操作求取下表的前提是环形缓冲区的大小必须是2的N次方,
换而言之,就是说环形缓冲区的大小为一个仅有一个1的二进制数,那么index & (size – 1)则为求取的下标(这不难理解)。
索引in和out被两个线程访问。in和out指明了缓冲区中实际数据的边界,也就是in和out同缓冲区数据存在访问上的顺序关系,由于不适用同步机制,那么保证顺序关系就需要使用到内存屏障了。索引in和out都分别只被一个线程修改,而被两个线程读取。__kfifo_put先通过in和out来确定可以向缓冲区中写入数据量的多少,这时,out索引应该先被读取,才能真正将用户buffer中的数据写入缓冲区,因此这里使用到了smp_mb(),对应的,__kfifo_get也使用smp_mb()来确保修改out索引之前缓冲区中数据已被成功读取并写入用户buffer中了。(我认为在__kfifo_put中添加的这个smp_mb()是没有必要的。
理由如下,kfifo仅支持一写一读,这是前提。在这个前提下,in和out两个变量是有着依赖关系的,这的确没错,并且我们可以看到在put中,in一定会是最新的,因为put修改的是in的值,而在get中,out一定会是最新的,因为get修改out的值。这里的smp_mb()显然是希望在运行时,遵循out先load新值,in再load新值。的确,这样做是没错,但这是否有必要呢?out一定要是最新值吗?out如果不是最新值会有什么问题?如果out不是最新值,实际上并不会有什么问题,仅仅是在put时,fifo的实际可写入空间要大于put计算出来的空间(因为out是旧值,导致len在计算时偏小),这并不影响程序执行的正确性。
从最新linux-3.16-rc3 kernel的代码:lib\kfifo.c的实现:
__kfifo_in中也可以看出memcpy(fifo->data + off, src, l);
memcpy(fifo->data, src + l, len – l);
之前的那次smb_mb()已经被省去了,当然更新in之前的smb_wmb()还是在kfifo_copy_in中被保留了。之所以省去这次smb_mb()的调用,我想除了省去调用不影响程序正确性外,是否还有对于性能影响的考虑,尽量减少不必要的mb调用)。
对于in索引,在__kfifo_put中,通过smp_wmb()保证先向缓冲区写入数据后才修改in索引, 由于这里只需要保证写入操作有序,所以选用写操作屏障,在__kfifo_get中,通过smp_rmb()保证先读取了in索引(这时in索引用于确定缓冲区中实际存在多少可读数据)才开始读取缓冲区中数据(并写入用户buffer中),由于这里指需要保证读取操作有序,故选用读操作屏障。
什么时候需要注意考虑内存屏障(补充)
从上面的介绍我们已经可以看出,在SMP环境下,内存屏障是如此的重要,
在多线程并发执行的程序中,一个数据读取与写入的乱序访问,就有可能导致逻辑上错误,而显然这不是我们希望看到的。
作为系统程序的实现者,我们涉及到内存屏障的场景主要集中在无锁编程时的原子操作。
执行这些操作的地方,就是我们需要考虑内存屏障的地方。
从我自己的经验来看,使用原子操作,一般有如下三种方式:
- (1). 直接对int32、int64进行赋值;
- (2). 使用gcc内建的原子操作内存访问接口;
- (3). 调用第三方atomic库:libatomic实现内存原子操作。
对于第一类原子操作方式,显然内存屏障是需要我们考虑的,例如kernel中kfifo的实现,就必须要显示的考虑在数据写入和读取时插入必要的内存屏障,以保证程序执行的顺序与我们设定的顺序一致。,对于使用gcc内建的原子操作访问接口,基本上大多数gcc内建的原子操作都自带内存屏障,他可以确保在执行原子内存访问相关的操作时,执行顺序不被打断。
当然,其中也有几个并未实现full barrier,具体情况可以参考gcc文档对对应接口的说明。同时,gcc还提供了对内存屏障的封装接口:__sync_synchronize (…),这可以作为应用程序使用内存屏障的接口(不用写汇编语句)。,对于使用libatomic库进行原子操作,原子访问的程序。Libatomic在接口上对于内存屏障的设置粒度更新,他几乎是对每一个原子操作的接口针对不同平台都有对应的不同内存屏障的绑定。
接口实现上分别添加了_release/_acquire/_full等各个后缀,分别代表的该接口的内存屏障类型,具体说明可参见libatomic的README说明。如果是调用最顶层的接口,已AO_compare_and_swap为例,最终会根据平台的特性以及宏定义情况调用到:AO_compare_and_swap_full或者AO_compare_and_swap_release或者AO_compare_and_swap_release等。
我们可以重点关注libatomic在x86_64上的实现,libatomic中,在x86_64架构下,也提供了应用层的内存屏障接口:AO_nop_full404 Not Found,对于第一类原子操作方式,显然内存屏障是需要我们考虑的,例如kernel中kfifo的实现,就必须要显示的考虑在数据写入和读取时插入必要的内存屏障,以保证程序执行的顺序与我们设定的顺序一致。
对于使用gcc内建的原子操作访问接口,基本上大多数gcc内建的原子操作都自带内存屏障,他可以确保在执行原子内存访问相关的操作时,执行顺序不被打断。
当然,其中也有几个并未实现full barrier,具体情况可以参考gcc文档对对应接口的说明。同时,gcc还提供了对内存屏障的封装接口:__sync_synchronize (…),这可以作为应用程序使用内存屏障的接口(不用写汇编语句)。,对于使用libatomic库进行原子操作,原子访问的程序。Libatomic在接口上对于内存屏障的设置粒度更新,他几乎是对每一个原子操作的接口针对不同平台都有对应的不同内存屏障的绑定。
接口实现上分别添加了_release/_acquire/_full等各个后缀,分别代表的该接口的内存屏障类型,具体说明可参见libatomic的README说明。如果是调用最顶层的接口,已AO_compare_and_swap为例,最终会根据平台的特性以及宏定义情况调用到:AO_compare_and_swap_full或者AO_compare_and_swap_release或者AO_compare_and_swap_release等。我们可以重点关注libatomic在x86_64上的实现,libatomic中,在x86_64架构下,也提供了应用层的内存屏障接口:AO_nop_full。
综合上述三点,总结下来便是:
如果你在程序中是裸着写内存,读内存,则需要显式的使用内存屏障确保你程序的正确性,gcc内建不提供简单的封装了内存屏障的内存读写。
因此,如果只是使用gcc内建函数,你仍然存在裸读,裸写,此时你还是必须显式使用内存屏障。如果你通过libatomic进行内存访问,在x86_64架构下,使用AO_load/AO_store,你可以不再显式的使用内存屏障(但从实际使用的情况来看,libatomic这类接口的效率不是很高)。
版权声明:本文为微信公众号「深度Linux」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
ap_release或者AO_compare_and_swap_release等。
我们可以重点关注libatomic在x86_64上的实现,libatomic中,在x86_64架构下,也提供了应用层的内存屏障接口:AO_nop_full404 Not Found,对于第一类原子操作方式,显然内存屏障是需要我们考虑的,例如kernel中kfifo的实现,就必须要显示的考虑在数据写入和读取时插入必要的内存屏障,以保证程序执行的顺序与我们设定的顺序一致。
对于使用gcc内建的原子操作访问接口,基本上大多数gcc内建的原子操作都自带内存屏障,他可以确保在执行原子内存访问相关的操作时,执行顺序不被打断。
当然,其中也有几个并未实现full barrier,具体情况可以参考gcc文档对对应接口的说明。同时,gcc还提供了对内存屏障的封装接口:__sync_synchronize (…),这可以作为应用程序使用内存屏障的接口(不用写汇编语句)。,对于使用libatomic库进行原子操作,原子访问的程序。Libatomic在接口上对于内存屏障的设置粒度更新,他几乎是对每一个原子操作的接口针对不同平台都有对应的不同内存屏障的绑定。
接口实现上分别添加了_release/_acquire/_full等各个后缀,分别代表的该接口的内存屏障类型,具体说明可参见libatomic的README说明。如果是调用最顶层的接口,已AO_compare_and_swap为例,最终会根据平台的特性以及宏定义情况调用到:AO_compare_and_swap_full或者AO_compare_and_swap_release或者AO_compare_and_swap_release等。我们可以重点关注libatomic在x86_64上的实现,libatomic中,在x86_64架构下,也提供了应用层的内存屏障接口:AO_nop_full。
综合上述三点,总结下来便是:
如果你在程序中是裸着写内存,读内存,则需要显式的使用内存屏障确保你程序的正确性,gcc内建不提供简单的封装了内存屏障的内存读写。
因此,如果只是使用gcc内建函数,你仍然存在裸读,裸写,此时你还是必须显式使用内存屏障。如果你通过libatomic进行内存访问,在x86_64架构下,使用AO_load/AO_store,你可以不再显式的使用内存屏障(但从实际使用的情况来看,libatomic这类接口的效率不是很高)。
版权声明:本文为微信公众号「深度Linux」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://mp.weixin.qq.com/s?__biz=Mzg4NDQ0OTI4Ng==&mid=2247485107&idx=1&sn=c508bddeb5c0184a818a707dbb870b5c&chksm=cfb94fdaf8cec6cc72aebcce13ed06f54232f31928a91d04d1ab4be52be5e905014be97f966c#rd