先序文章请看
从裸机启动开始运行一个C++程序(四)
从裸机启动开始运行一个C++程序(三)
从裸机启动开始运行一个C++程序(二)
从裸机启动开始运行一个C++程序(一)
把MBR和内核源码拆开
拆分MBR和Kernel
前面章节中我们已经可以成功把硬盘里除第一扇区外的其他扇区正常加载到内存中了,但之前的做法是把后续的代码和MBR源码挤在同一个文件中,这显然是不方便后续管理的。
从架构设计的角度上来说,MBR以外的这些代码属于OS内核,因此对于「MBR」和「OS内核」这两部分的内容,还是应该拆开的。MBR由BIOS引导,而内核由MBR引导。
做法也很简单,把MBR和内核的代码分别拆到两个文件中:
mbr.nas:
; 调用0x10号BIOS中断,清屏
mov al, 0x03
mov ah, 0x00
int 0x10
; ...省略中间代码...
jmp 0x0800:0x0000 ; 跳转到内核代码
times 510-($-$$) db 0 ; MBR剩余部分用0填充
dw 0xaa55
; 到此,只会有512字节的二进制文件生成
kernel.nas:
begin:
mov ax, 0xb800
mov ds, ax
mov [0x0000], byte 'H'
; ...省略中间代码...
hlt
times 1024-($-$$) db 0 ; 由于begin已经在此文件中定投了,所以这里改成了$$
它们可以分别汇编成独立的二进制,使用如下指令:
nasm mbr.nas -o mbr.bin
nasm kernel.nas -o kernel.bin
从而生成mbr.bin和kernel.bin两份二进制。接下来的问题就在于,如何把这两份二进制拼成一份完整的磁盘镜像(a.img)。如果有读者在前面对于笔者总是要节外生枝,把mbr.bin复制一份作为a.img的行为不理解的话,相信此时应该能够理解了。
考虑到后续可能发展到不止两个二进制,而且文件体积会变大,因此,我们采取的方式是,先生成一个空的磁盘镜像文件,再向这个镜像文件的合适位置里写入二进制。(想象真机的场景,我们应当是首先拥有一块硬盘或者软盘,然后再往这个硬盘中写入数据。而不是直接拿着数据去定制生产一块硬盘。)
这里我们使用bximage工具来创建磁盘镜像,这个工具是bochs自带的,所以只要正确安装了bochs,就不需要单独安装它。
使用以下命令来创建磁盘镜像:
bximage -q -func=create -hd=16M a.img
这里的-q表示安静模式,如果参数错误会直接报错,而不是进入交互模式。-func-create表示创建镜像。-hd=16M表示创建一个大小是16MB的硬盘(注意这里最小是16M)。最后的a.img是文件名。
默认情况下,扇区大小是标准的512B,所以我们相当于生成了一个C/H/S=32/16/64规格的硬盘,控制台也会有提示:
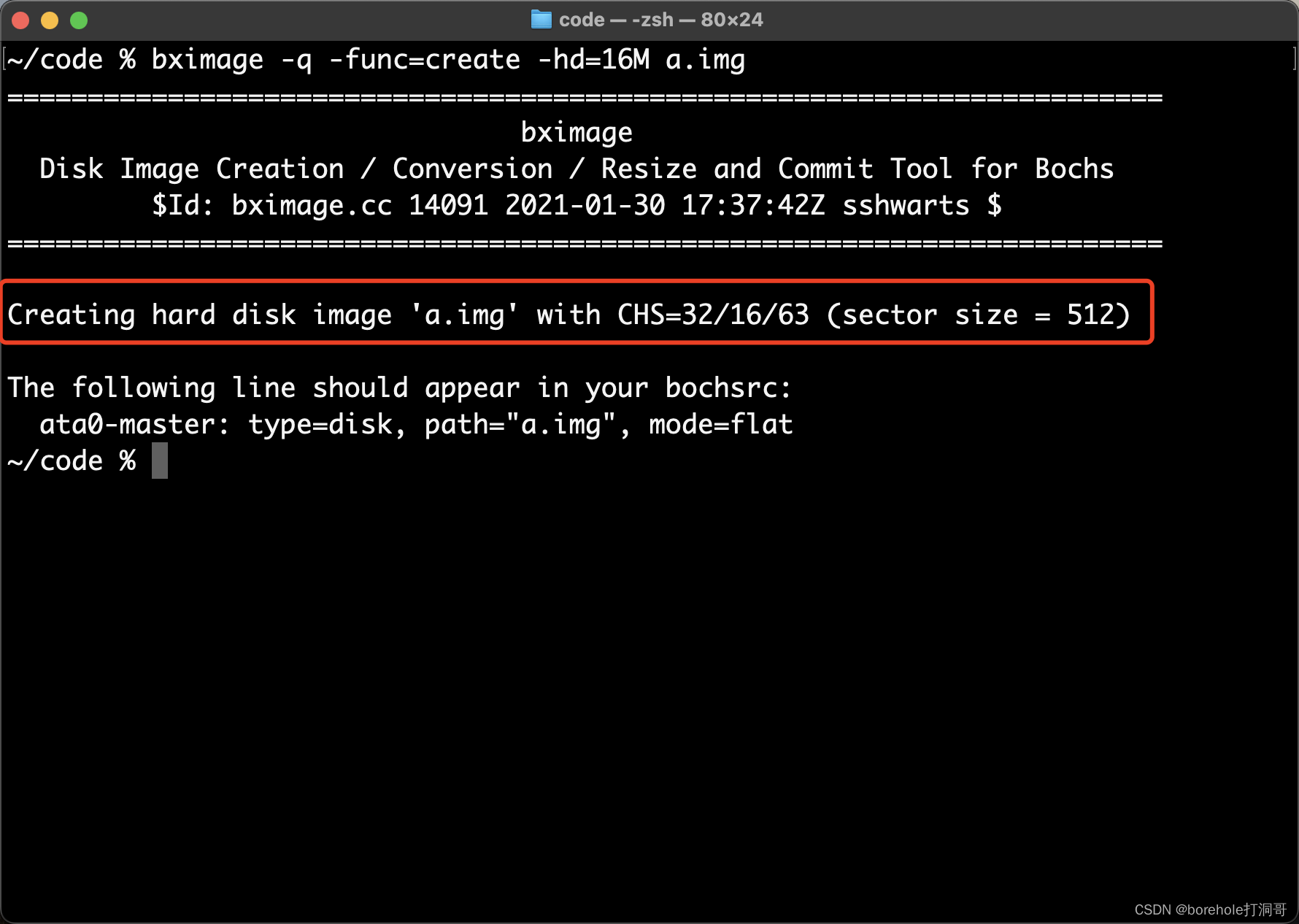
哎?不是说S=64嘛,怎么变63了?这就是前面我们提到过的有一个小问题,就是说0号扇区是留空的,真正的扇区要从1号开始。所以如果表示扇区号的寄存器预留了6位,那么实际可用的扇区应该是
2
6
−
1
=
63
2^{6}-1=63
26−1=63个。因此用bximage工具的时候,实际生成的磁盘大小会比我们输入的值略小,也就是每个柱面都会少一个扇区。
所以这里按照C/H/S=32/16/63来计算,磁盘大小应该是
32
×
16
×
63
×
512
B
=
16515072
B
=
15.75
M
B
32\times16\times63\times512B=16515072B=15.75MB
32×16×63×512B=16515072B=15.75MB才对。
注意在macOS中,数据单位的换算是按1000来换算的(不知道苹果为什么这么搞……),所以会显示16.5MB,因此不要信任这个数字(Windows中的换算是对的),而是应当看实际以「字节」为单位的数字是否正确。
生成好磁盘镜像以后,我们使用dd工具,把MBR和内核的二进制分别写在磁盘镜像的第一个和第二、三个扇区中:
dd if=mbr.bin of=a.img conv=notrunc
dd if=kernel.bin of=a.img bs=512 seek=1 conv=notrunc
这里的if参数是输入文件,of参数是输出文件,conv=notrunc表示不改变输出文件的大小。bs=512 seek=1表示扇区大小是512B,跳过1个扇区后开始(因为内核要从第二个扇区开始写)。
由于dd是类UNIX自带指令,使用macOS的话可以直接使用,而如果使用Windows则需要额外安装(下一节介绍Windows上安装dd的方法)。
由于这里磁盘镜像的结构发生了变化,所以我们同步调整bochsrc,如下:
ata0: enabled=1, ioaddr1=0x1f0, ioaddr2=0x3f0, irq=14 # 主盘端口映射为1f0,从盘映射为3f0,中断号设置为14(虽然这几个参数都可以定制化,但这个参数是业界标准的,不建议更改)
ata0-master: type=disk, mode=flat, path=a.img, cylinders=32, heads=16, spt=63 # 主盘位置加载一块规格为C32H16S63的硬盘,镜像使用a.img
boot: disk # 设置为硬盘启动
启动bochs可以看到效果:
bochs -qf bochsrc
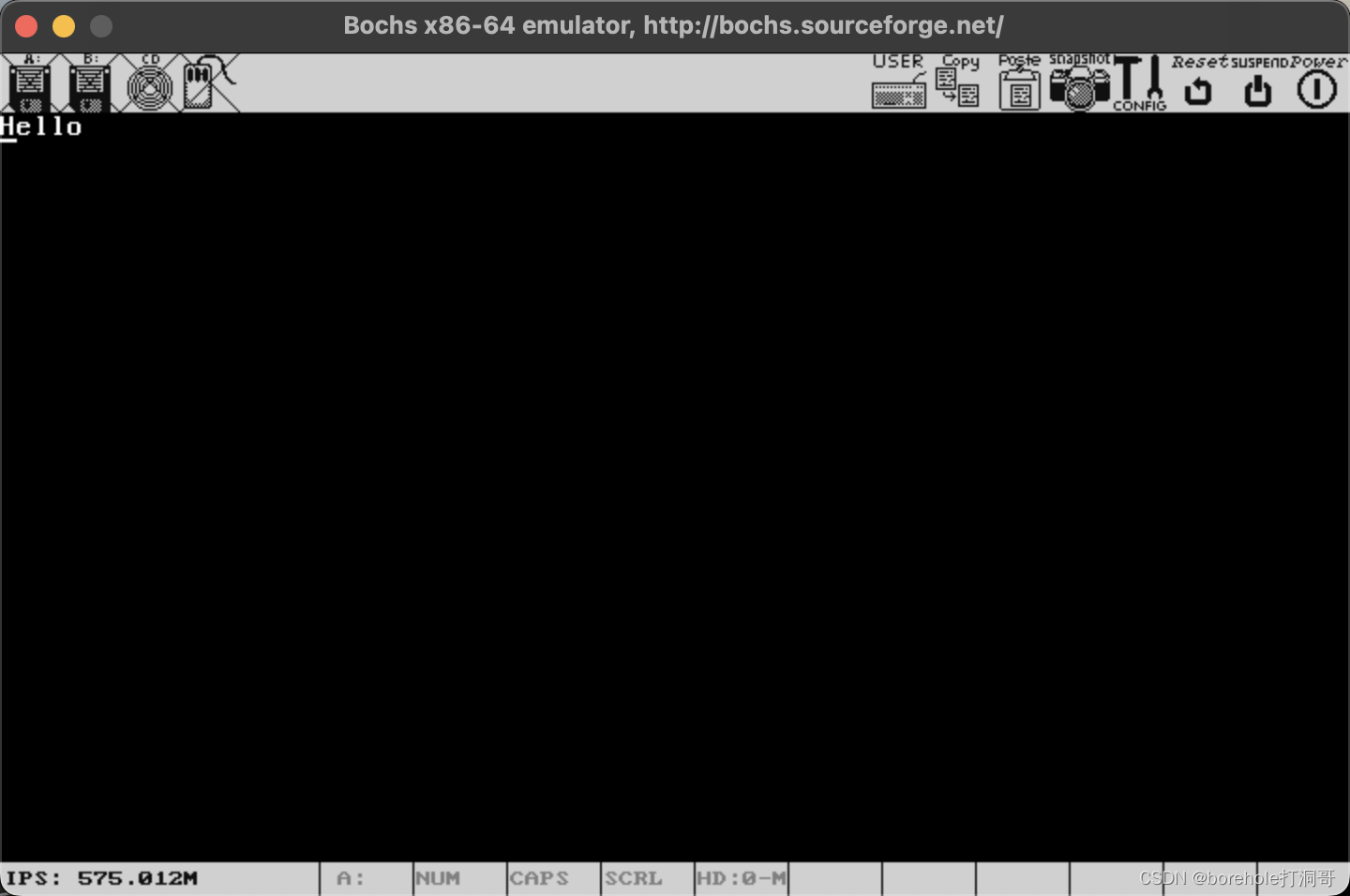
证明我们的加载是成功的。
在Windows上安装dd工具
macOS和Linux中有很多非常方便的工具,毕竟他们同属于类UNIX家族。但Windows和他们并不同源,所以需要单独来安装。当然,Windows上也有原生的同作用的工具可用,如果读者熟悉的话当然没问题。但本篇文章为了保证多平台的一致性,还是会使用dd工具,因此这里介绍一下如何在Windows上安装dd工具。
在chrysocome官网上下载dd工具,注意这里下载列表里的东西比较多,不要下载错了,要找到``ddrelease64.exe`。

这个工具没有安装包,下载下来直接就是可用的工具,我们把它放到一个方便自己管理的路径下,然后把这个路径配置到环境变量中(方法可以参考前面配置nasm的方法)。
更简单的方法是直接把这个程序复制到C:\Windows\下,因为这个路径本来就在环境变量中。
建议把ddrelease64.exe重命名为dd.exe,这样命令会统一,使用更方便。
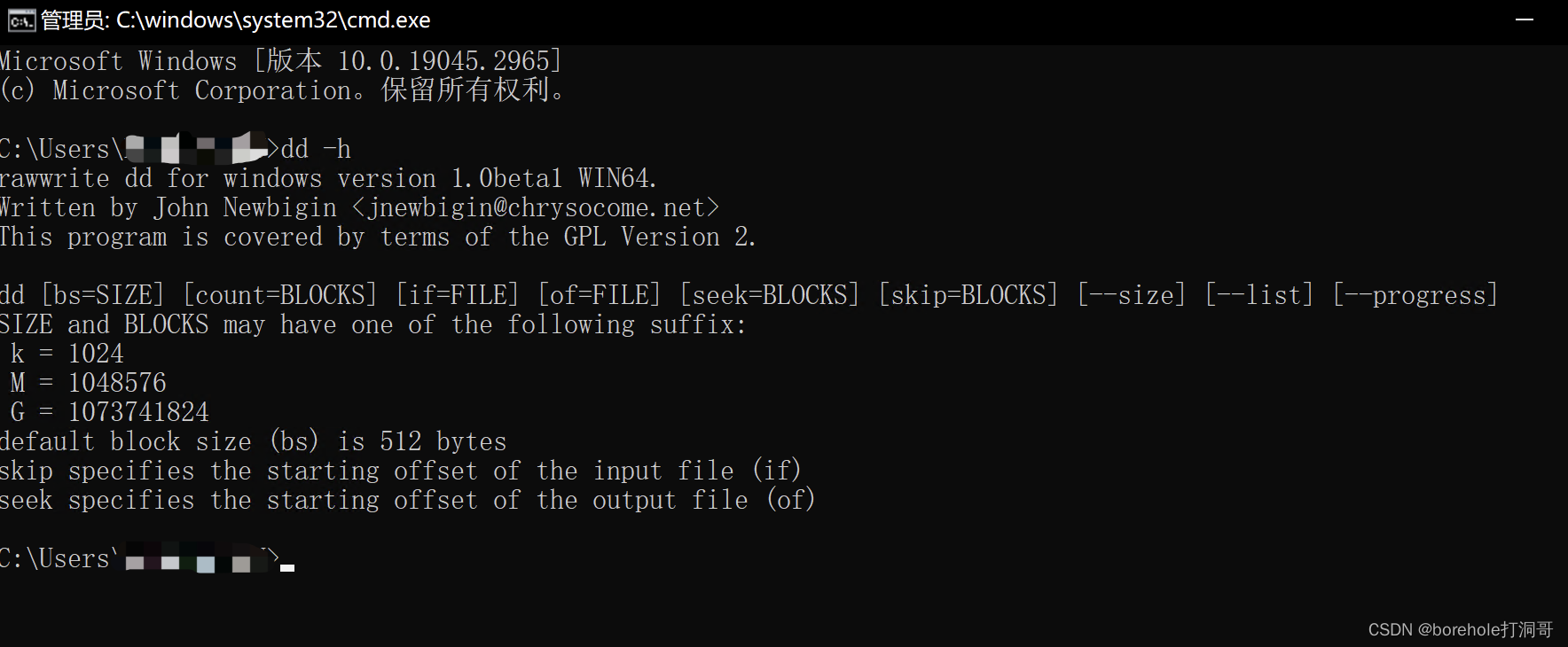
之后打开控制台,输入dd -h,如果能正常输出,说明dd工具已经配置就绪。
使用makefile
当文件拆开后,每次生成a.img需要好几条命令,并且后续会逐渐增多,所以搞一个项目工程生成的配置文件是一个比较好的方法。这里我们使用make工具。
make工具是GNU工具集中的一部分,在macOS下可通过Home Brew安装,在Windows下可通过MinGW来安装。
在macOS上安装make
在安装并配置好Home Brew的前提下,输入下面命令:
brew install make
等待安装流程结束后输入make -v,如果能出现版本号,证明安装成功。

在Windows上安装make
刚才介绍过,make工具属于GNU工具集中的,在Windows上安装GNU工具集需要用到MinGW工具,以后我们安装gcc相关工具也会用到MinGW。
首先进入sourceforge官网下载MinGW。
同样,安装参数保持默认即可。
安装完毕后点击「continue」。
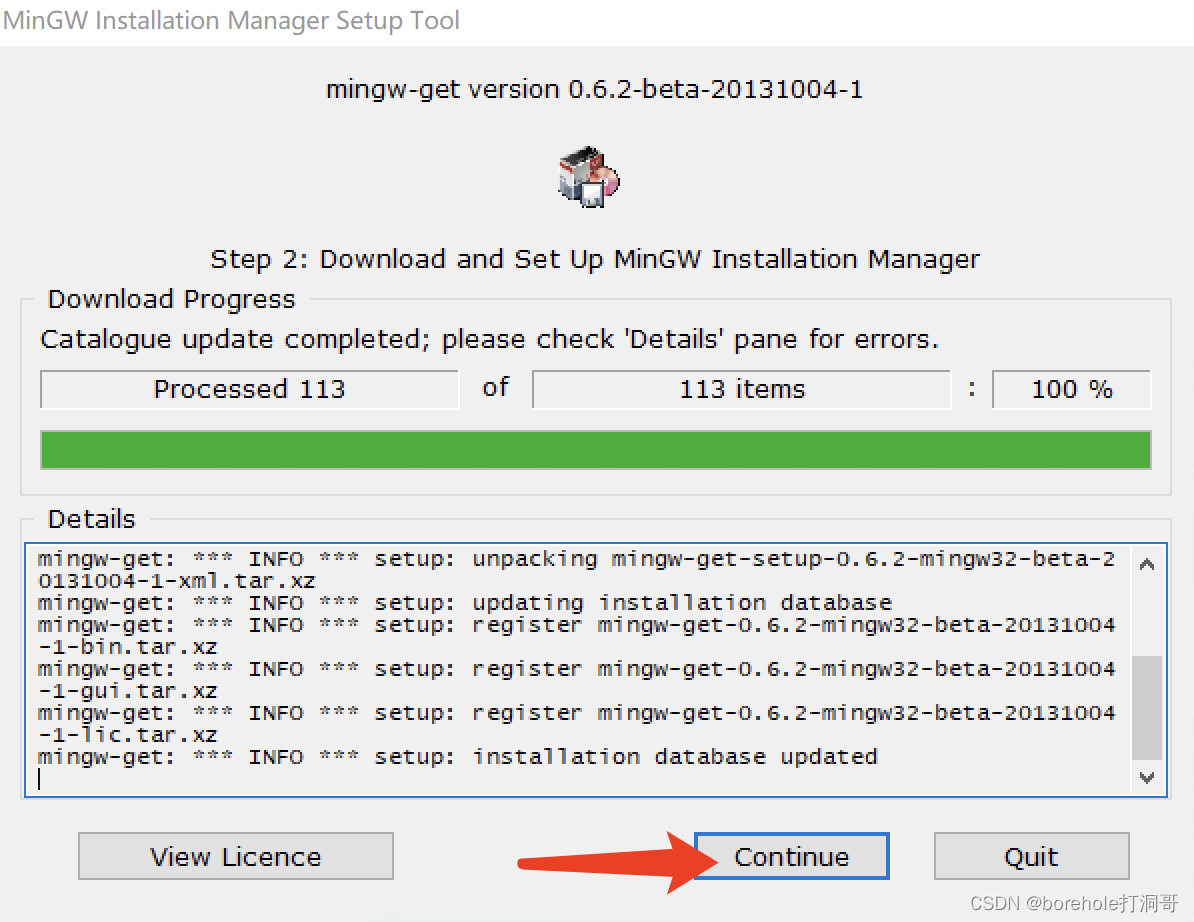
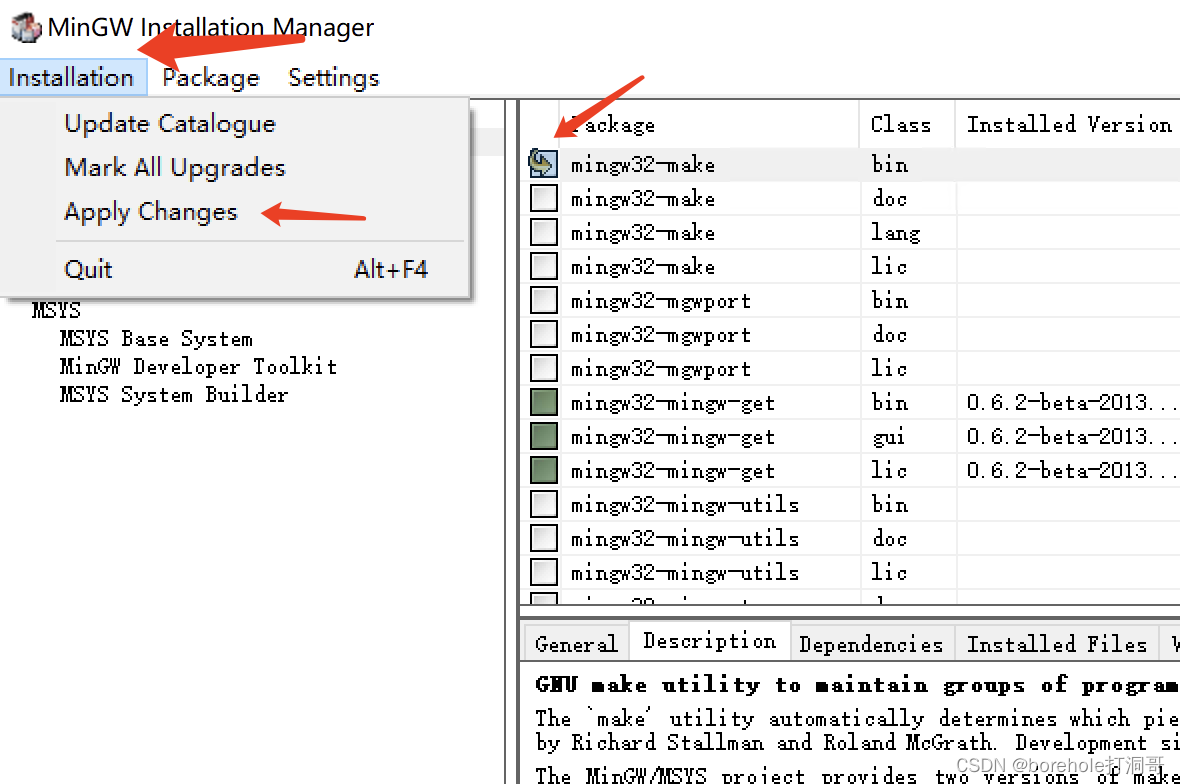
之后会弹出MinGW的管理界面,选择「All Package」,然后找到mingw32-make的bin文件(注意要找bin文件,这才是程序,其他的是文档),点击后选「Mark to installation」
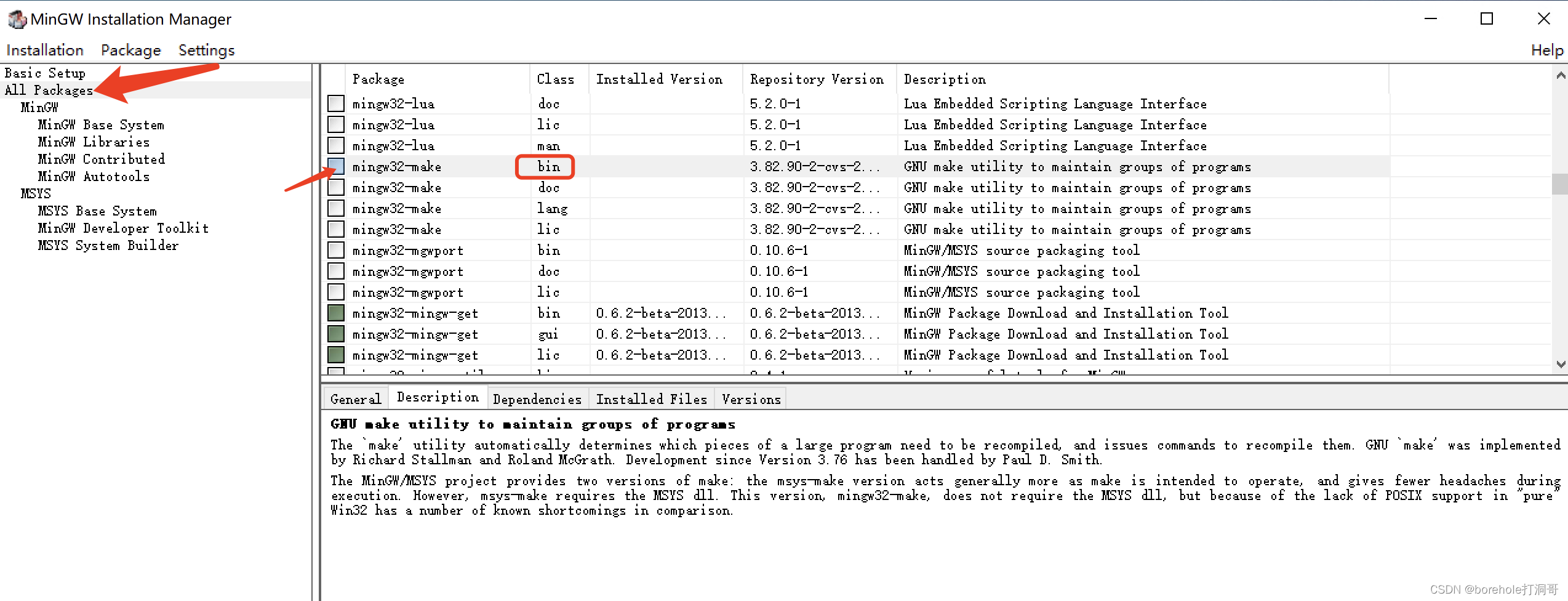
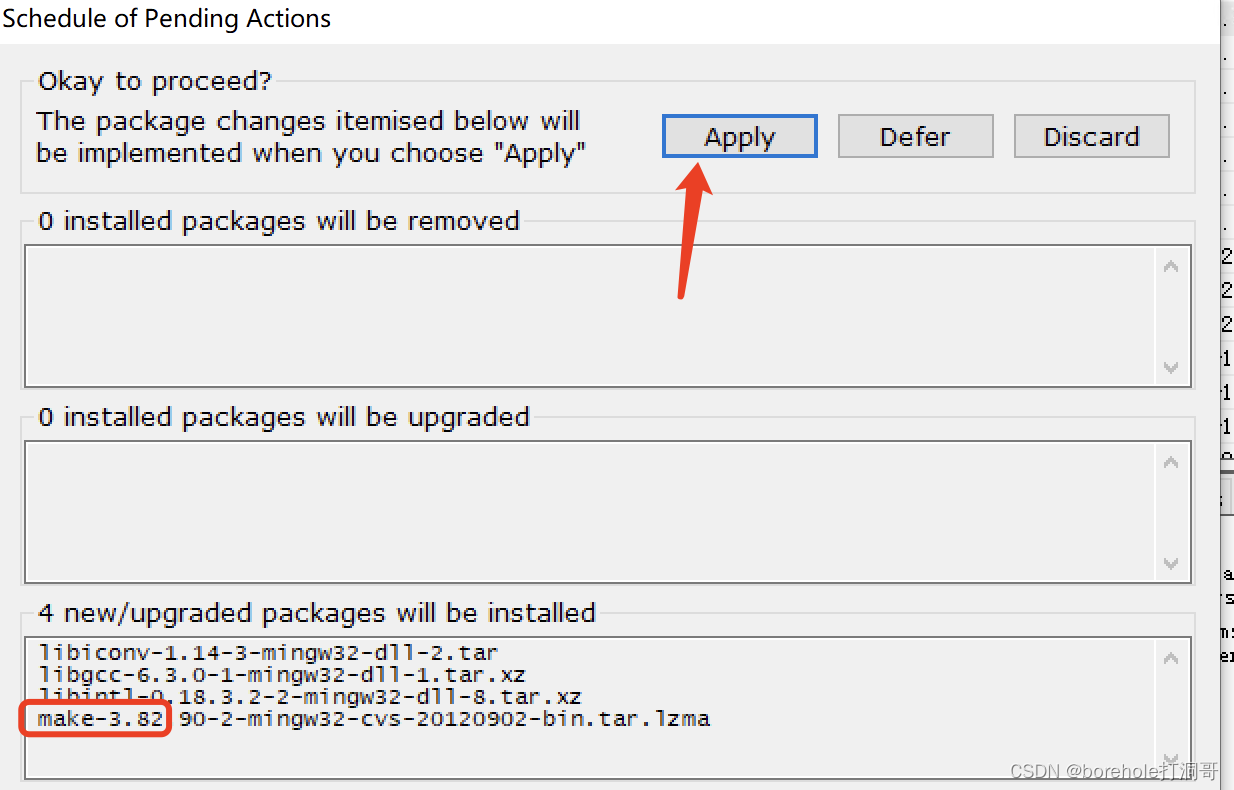
确认它被选中的情况下,点击「Installation」,选择「Apply Changes」,随后点击「Apply」即可开始安装make。
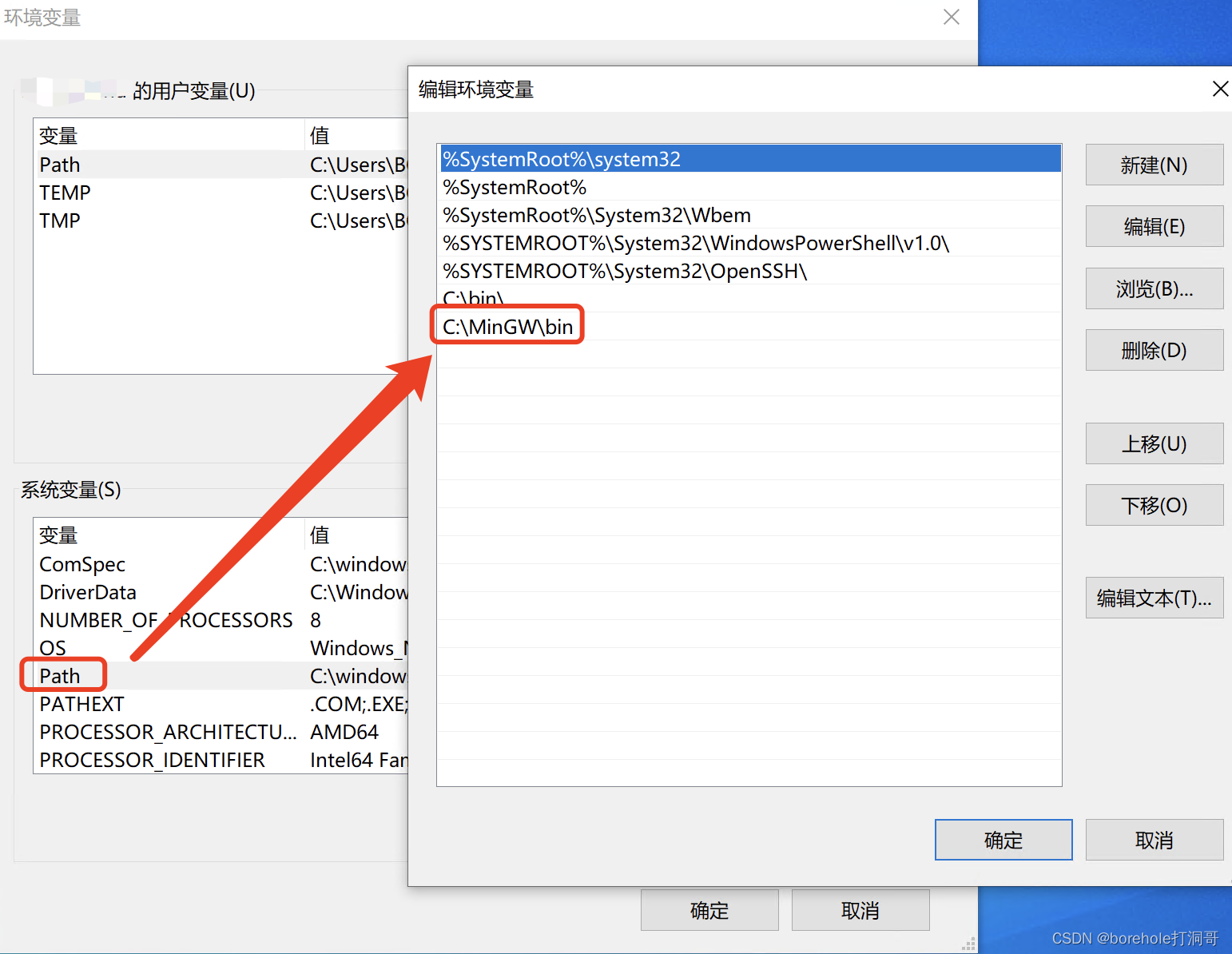
之后就是配置环境变量,默认情况下MinGW安装的程序会放在C:\MinGW\bin中。

我们把这个路径配置到环境变量中(详细方法可以看前面章节):
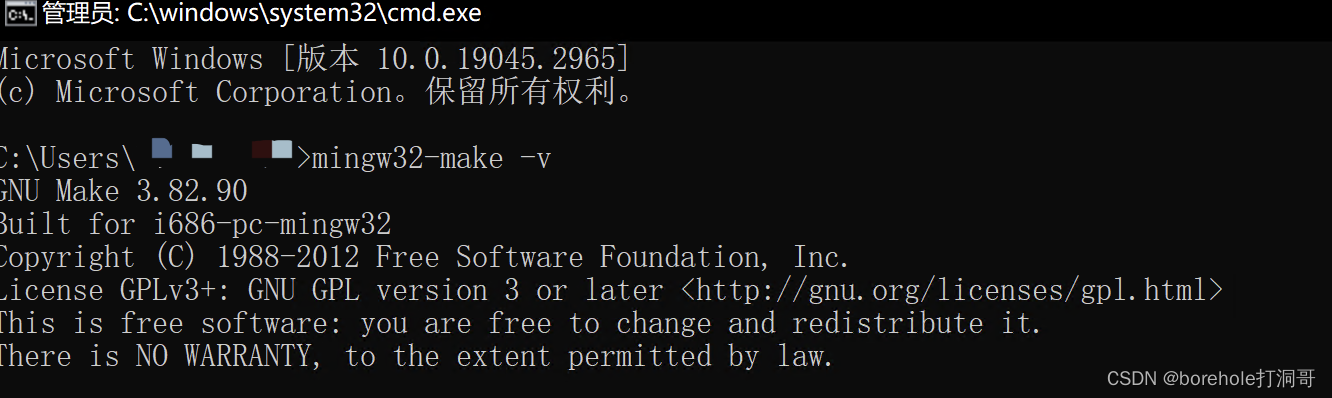
然后我们打开控制台,输入mingw32-make -v,如果能出现版本号说明配置成功。
配置项目的makefile
make工具的运行依赖于makefile文件,我们在工程路径下创建一个名为makefile的文件,注意,这个文件没有任何后缀。然后编写以下内容:
.PHONY: all
all: sys
.PHONY: run
run: bochsrc sys
bochs -qf bochsrc
a.img:
rm -f a.img
bximage -q -func=create -hd=16M $@
sys: a.img mbr.bin kernel.bin
dd if=mbr.bin of=a.img conv=notrunc
dd if=kernel.bin of=a.img bs=512 seek=1 conv=notrunc
mbr.bin: mbr.nas
nasm mbr.nas -o mbr.bin
kernel.bin: kernel.nas
nasm kernel.nas -o kernel.bin
.PHONY: clean
clean:
-rm -f *.bin
要注意,上面的行前缩进都必须是制表符('\t',也就是按TAB键),而不可以是空格,否则无法正常运行。
保存之后,直接在项目路径下输入make run(如果是MinGW安装的则应当输入mingw32-make run,后文都同理,不再特别标注),即可全自动生成a.img,并且启动bochs运行:
接下来我们来解释一下makefile中的内容代表什么含义。
大致上来说,makefile的写法是:
目标: 依赖1 依赖2 ...
[Tab] 生成指令
比如说前面的:
mbr.bin: mbr.nas
nasm mbr.nas -o mbr.bin
就表示,要生成mbr.bin文件,则需要mbr.nas文件,生成的指令是nasm mbr.nas -o mbr.bin。与此同时,它自带依赖,比如说生成sys需要mbr.bin,那么它就会先去生成mbr.bin。
对于这个.PHONY:run则表示后面的run并不是实际文件,而是一个标签。
make规则会默认按照第一个规则,也就是说,如果我们直接输入make,就相当于输入了make all,匹配makefile中的all标签。一般情况下还会在最后设置一个clean标签用做清理。
详细的makefile写法就不在本篇内容中介绍了,如果读者感兴趣可以自行查阅。为了降低门槛,笔者在本篇文章中也不会使用复杂的makefile语法(类似于$<, $@之类的),所以读者无需担心。
从8086到80286
到目前为止,我们已经从裸机启动开始,加载了mbr,又通过mbr加载了kernel。真的要说起来,再往后就应该是用kernel来调度用户程序了,但目前我们还没办法走到这一步,因为有一个很严重的问题,就是目前整个理论和流程,都是8086上的。
要想继续进行,咱们得先进入一个正常的模式,至少要先进入IA32模式,我们才能聊加载C/C++程序的事。但想从8086模式进入IA32模式并不是件容易的事,我们得串一遍架构发展的流程。这件事还蛮有意思的,因为我觉得跟生物进化如出一辙。比如说人类在母体内的发育过程,就很像一个极速版的人类从原始海洋生物不断进化的过程。类比到程序启动这里也是一样的,Intel从8086开始,到推出286、386、再到后面64位CPU的历史发展过程,也会浓缩在计算机启动的过程中。
在计算机启动时,CPU就是以8086模式工作的(当然,如果Intel推出x86S模式以后,情况可能会发生变化,但至少本文编写时,以常规AMD64架构方式设计的CPU还是会以8086模式开始启动的),然后要通过一些配置进入286模式,再进入IA-32模式,再进入AMD-64模式。
所以,我们还是需要了解一下中间这些历史发展情况,然后来指导我们如何配置和进入更高层的模式。
A20使能端
之前我们提到过8086机器有20位地址总线,但是却是用了2个16位寄存器来表示内存地址的。但是,用2个16位来拼凑一个20位地址,其实是有盈余的。
我们计算一下就可以知道,这种表示方式的范围应该是0x0000:0x0000~0xffff:0xffff,也就是0x00000~0x10ffef。我们发现最大值已经超过了20位的范围0xfffff。那么如果我真的把寄存器配成0x10000~0x10ffef之间的部分会怎么样?还记得前面解释内存地址拼接时的那张图吗?

既然是全加器,它的输出端其实应该要有进位符的输出的。事实上在硬件中的确有这个进位输出端,只不过在8086的CPU中,结果被丢弃了而已。
因此,在8086中,超过了16位的部分会被丢弃,也就是说0x10000~0x10ffef的部分会变成0x0000~0x0ffef。
接下来我们做个实验来验证这个说法。将es:dx配置为0xff00:0xf000,结果应该是0x10e000,那么按照刚才的说法,这个地址其实应该会反转到0x0e000处。
把kernel.nas改为以下内容:
begin:
mov ax, 0xff00
mov es, ax
mov [es:0xf000], byte 0xaa ; 给这个位置写入0xaa
hlt
times 1024-($-begin) db 0
然后通过调试模式,查看写入内存这一句的前后,内存的情况。我们make run以后,输入pb 0x8000,在kernel处打断点,然后用c命令执行至kernel处。再执行2次n命令,到我们需要观察的位置:
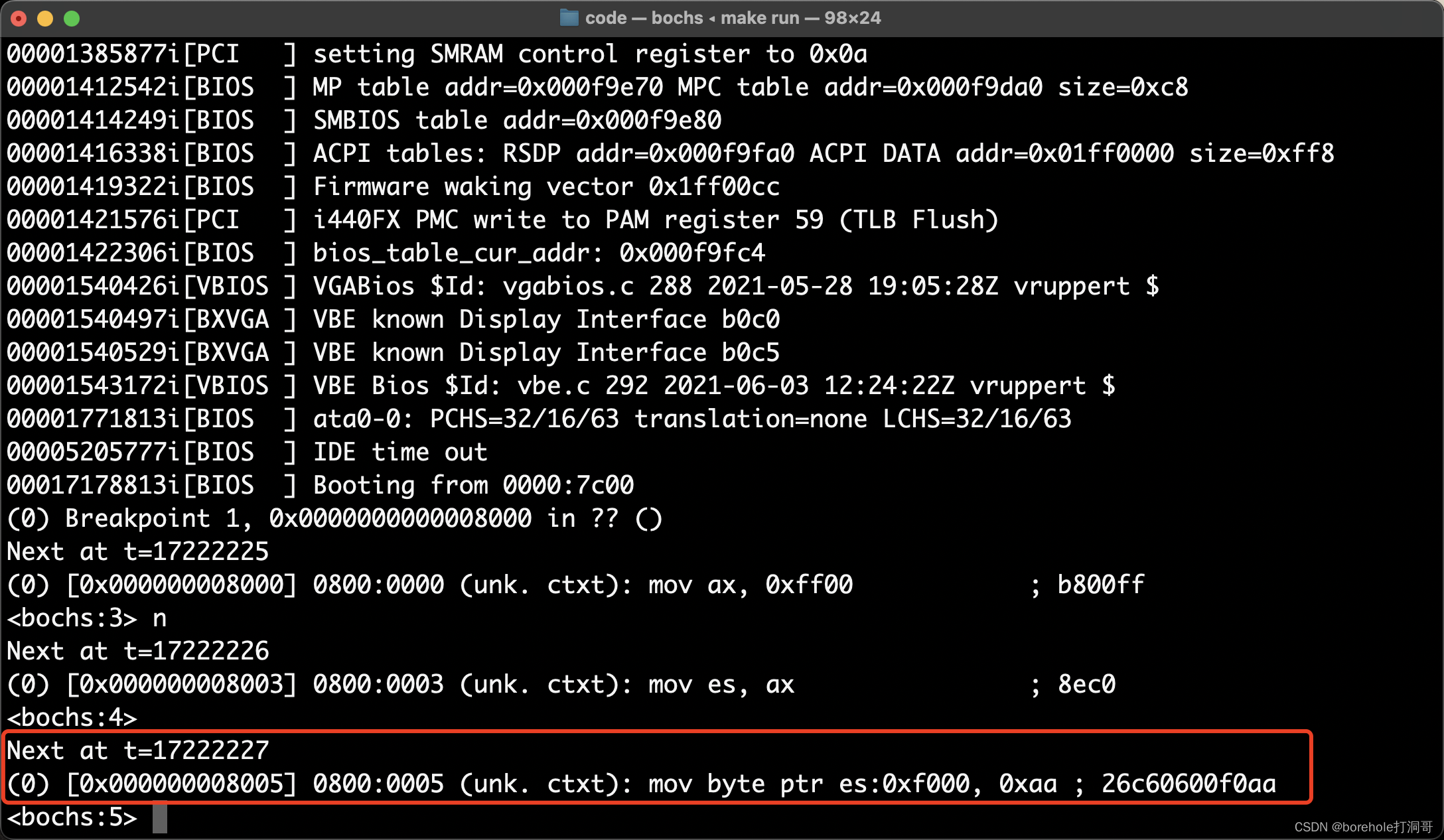
这时你可以通过x命令来看看此时的内存情况,现在不看,等一下执行完再看也行。
再执行一次n命令,让写入内存的指令生效,之后我们来看一下0xe000的内存情况,通过x 0xe000命令:

不对呀!这里的内存为什么没有被改呢?先不急,我们再来看一下0x10e000的情况:
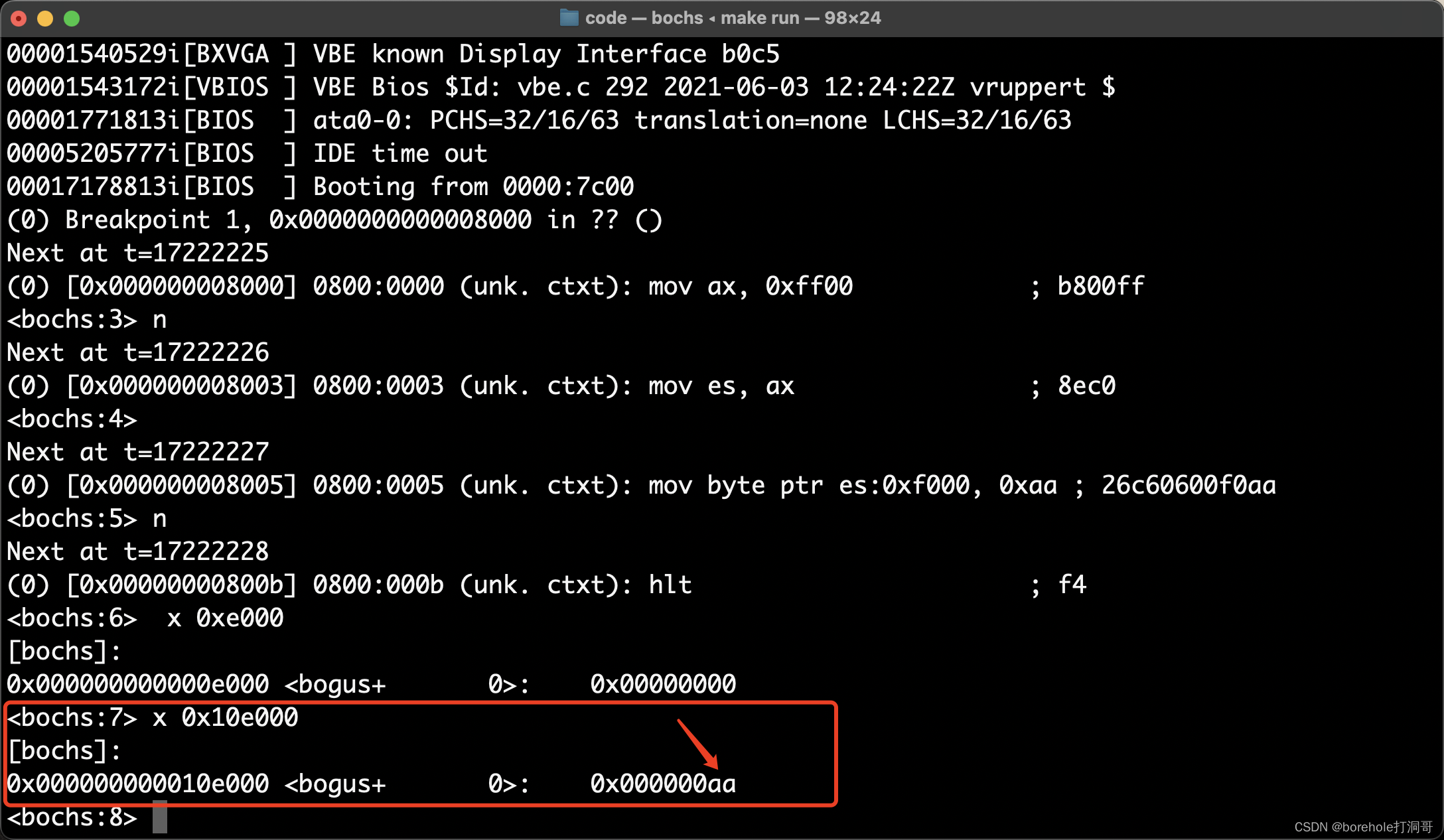
这里是生效的!那这件事就很奇怪了,它事实上并没有发生我们预料之中的反转情况,因为根据上面的实验,0x10e000并没有映射到0x0e000上。
所以这里必须要提醒大家,虽然前面我们一直在解释8086的各种情况,但bochs并不是8086模拟器!,而是AMD-64模拟器。换句话说,咱们现在的运行环境并不是真正的8086,只是一个AMD-64的CPU,运行在了8086模式下罢了。
刚才我们说,20位全加器的进位结果,在8086上是被丢弃的,这是因为8086只有20位地址线。但是,到了80286的时候,就已经升级为24位地址线了,那么当时Intel理所应当地认为,这个全加器的进位结果,就应该接到第20位地址线(或者叫A20)上。
也就是说,80286处理器运行在8086模式下时,会有21位地址是有效的,有效地址范围是0x00000~0x10ffef,超出0xfffff的部分并不会反转(因为进位标志是有效的)。这个特性同样在后续的IA-32架构和AMD-64架构上被延续了下来,所以,我们在模拟器上看不到内存地址的反转。
虽然说现在看起来,这种做法无可厚非,但是当年却爆炸了。据说,是因为一个比较重要的软件,程序员在编写的时候利用了这种反转特性进行了编码。那么在8086机器上是运行OK的,但是换到了80286机器上,程序就不能正常运行了。(这个故事也告诉我们,程序员编码的时候还是应当以软件方式来思考问题,不应当依赖这种非常特殊的硬件特性来实现功能,否则硬件兼容性就会很差。)
因此为了解决这个问题,主板厂商想了一个办法,就是用南桥芯片来控制CPU的A20使能。通过给特定端口的I/O发送消息,来间接控制A20地址线是否有效。如果要在80286上运行依赖于地址反转的8086程序的话,只需要先将A20地址线去使能,然后就可以正常运行。
这个功能被映射到了I/O的0x92端口上,这个端口控制器的第1位(注意是第1位而不是第0位,也就是从低向高的低二位)用于控制A20的使能,也被称为A20 Mask位,简称A20M。为1时,A20去使能,地址会反转;为0时,A20使能,地址不会反转。
所以,我们先将A20M开启,然后再去写内存,就也可以达成目的了,代码如下:
begin:
; 开启A20M,允许超1M的地址反转
in al, 0x92
and al, 11111101b
out 0x92, al
; 再尝试溢出地址中写入数据
mov ax, 0xff00
mov es, ax
mov [es:0xf000], byte 0xaa
hlt
times 1024-($-begin) db 0 ; 补满2个扇区
然后按照之前的方式重新实验,可以观察到这时,0xe000的内存是被实际操作的:
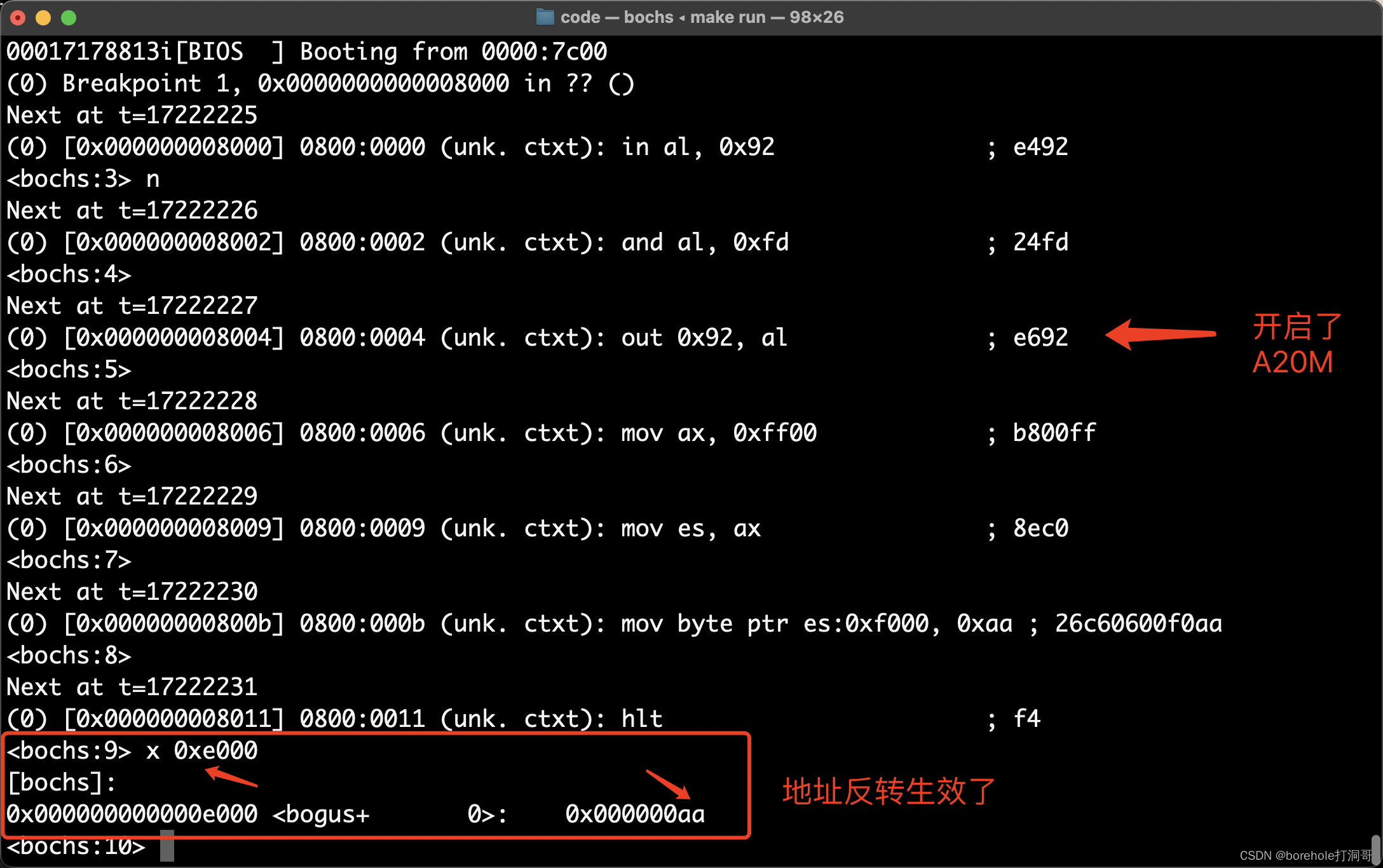
不过对于我们来说,正常情况下不用刻意控制A20M,因为它默认是关闭的(也就是说A20默认是使能的)。
所以,这个例子也是为了提醒大家,我们现在并不是真正的8086设备,而是以8086模式运行的AMD64设备。(当然,后面要介绍的80826模式、IA32模式也是同理)。
小结
这一篇我们首先将MBR和kernel代码进行了分离,之后介绍了要切换到80286模式时需要注意的问题(A20M的问题)。
80286主要引入了保护模式,引入了段选择子、段配置表等概念,这是不同于8086的寻址方式的。下一篇我们会继续介绍。