目录
前言
布隆过滤器的原理
插入编辑
查询
删除
布隆过滤器优缺点
优点:
缺点:
代码实现
方式一: Google Guava 提供的 BloomFilter 类来实现布隆过滤器
到底经过几次哈希计算
解决缓存穿透
方式二:手写
前言
在学习Reids时,关于缓存的三大问题:缓存雪崩、缓存穿透、缓存击穿,其中缓存穿透最好的解决办法就是依靠布隆过滤器,什么是布隆过滤器呢?
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。——百度百科
布隆过滤器的原理

布隆过滤器本质上是一个很长的二进制数组,主要用来判断一个数据存不存在数组里,如果存在就用1表示,不存在用0表示,如何表示呢?看下面这张图
插入
比如我们把java这行字符存入到布隆过滤器中,首先进过3次哈希函数,分别得到3个哈希值,然后将哈希值根据下标映射到数组中,将对应的0改成1,那么1、3、5这三个位置就存储了java字符。这就是布隆过滤器的插入原理
问题来了:为什么要经历三次哈希计算呢?
其实不一定就是三次哈希计算,这里我只是举例子而已,到底要进行多少次哈希计算。莫急,待会结合实际情况和代码讲解
查询
讲完插入,再看查询,其实查询和插入原理差不多,当我们查询(java)字符存不存在布隆过滤器中,首先依然进行哈希函数,计算出来的哈希值对应的数组下标,如果对应的1、3、5数组中都是1,那么表示java存在,要是有任意一个位置不为1,那么(java)字符就不存在。
这就是布隆过滤器的主要优势,那么他的缺点之一的就是删除困难,请看详细讲解
删除

插入java字符时,经过一系列的哈希计算,将下标为1的位置用来储存它,此时jvm字符也经过一系列哈希计算,也得到下标为1的位置来存储它,那么这个1即表示java字符存在又表示jvm字符存在,若要进行删除操作,很难确认你删除的是java还是jvm或许两者同时被删除,所以布隆过滤器不做删除处理
布隆过滤器优缺点
优点:
1.它是由二进制数组组成,所占空间小
2.基于数组的特性,它的查询和插入是非常快的,它只需要根据哈希计算出来的值找相应的角标就行,时间复杂度是O(m);m=哈希计算的个数,比如存入java字符,进行一个哈希计算就是O(1),进行三个哈希计算就是O(3)。
缺点:
1.不能进行删除操作;
2.存在误判,因为不同的数据计算出来的哈希值可能相同,比如上方的java字符存在于布隆过滤器中,jvm字符不存在,但是他俩的哈希值相同,所以查询jvm时会发生误判。
这个误判是一定存在的,不能避免,但是能减少误判的概率。上代码:
代码实现
方式一: Google Guava 提供的 BloomFilter 类来实现布隆过滤器
导入依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1-jre</version>
</dependency>
创建 BloomFilter 对象并添加元素
public class BloomFilterCase {
/**
* 预计要插入多少数据
*/
private static int size = 1000000;
/**
* 期望的误判率
*/
private static double fpp = 0.01;
/**
* 布隆过滤器
*/
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
public static void main(String[] args) {
// 插入10万样本数据
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
// 用另外十万测试数据,测试误判率
int count = 0;
for (int i = size; i < size + 100000; i++) {
if (bloomFilter.mightContain(i)) {
count++;
System.out.println(i + "误判了");
}
}
System.out.println("总共的误判数:" + count);
}
}private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
三个参数:第一个是默认的;存入数据的大小;误判率
测试一下设置的误判率是否准确
/**
* 期望的误判率
*/
private static double fpp = 0.01;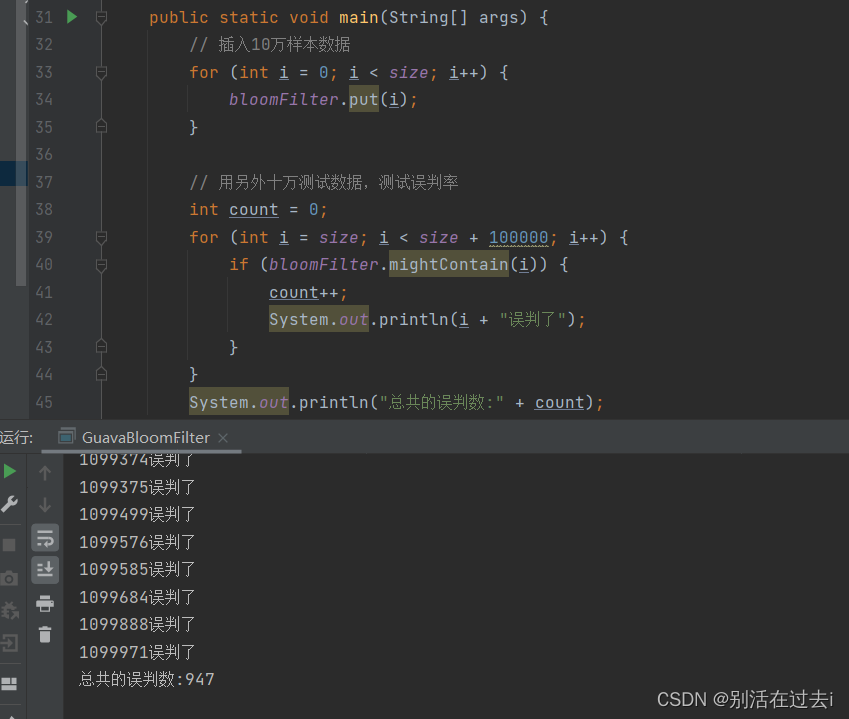
这里误判了947个约等于1000除以10万=1%,所以说这个设置的误判率是正确的,可以多设几个值验证一下
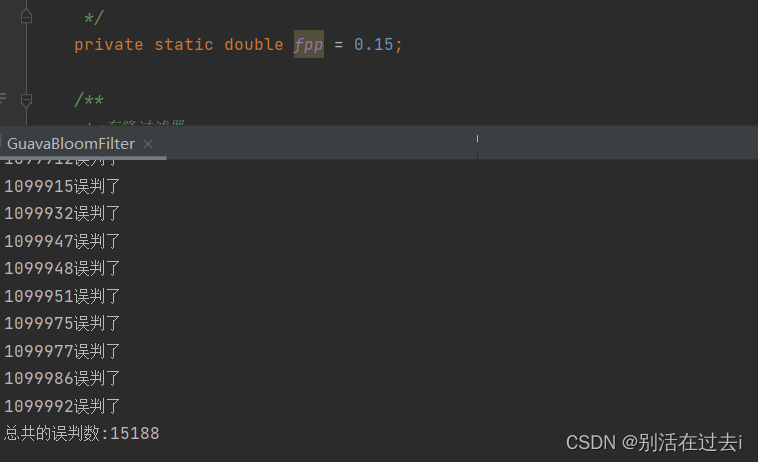
可以看到误判率设定的越小,出现误判的概率越小,那是不是把误判率设置的非常非常小就更好呢?这里没办法展示,大家可以自行实践一下,当误判率设定的太小,结果输出延迟会很大,不能实时展示结果,误判率太小,计算量时间长,性能就非常差!
到底经过几次哈希计算
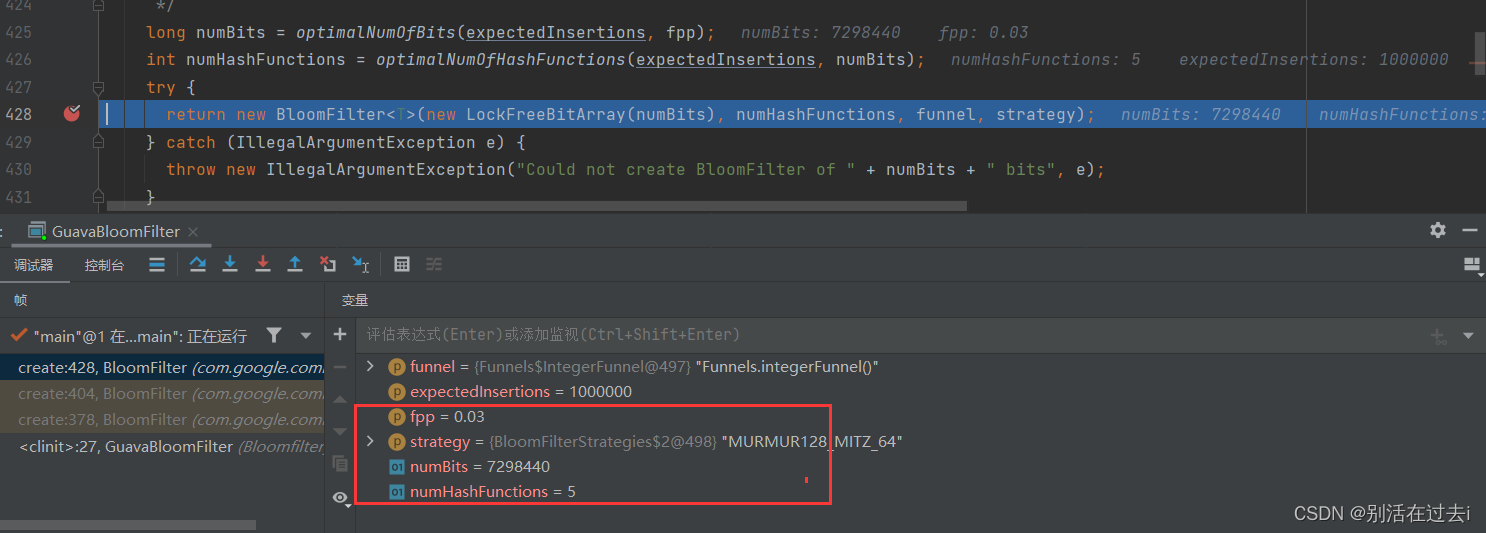
fpp=0.03
fpp=0.01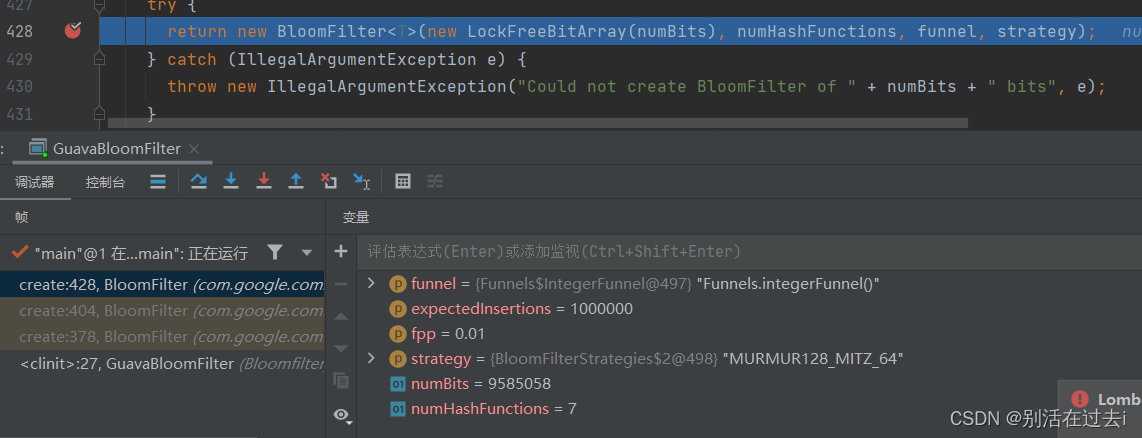
这两张图中
fpp是我们设置的误判率;
numBits是指表示存一百万个int类型数字,需要的位数为7298440,700多万位。理论上存一百万个数,一个int是4字节32位,需要481000000=3200万位。如果使用HashMap去存,按HashMap50%的存储效率,需要6400万位。可以看出BloomFilter的存储空间很小,只有HashMap的1/10左右
numHashFunctions表示需要几个哈希函数去计算数据的哈希值
所以,当fpp越小,所需要的存储空间越大,需要的哈希函数个数越多
解决缓存穿透
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://120.48.17.2");
config.useSingleServer().setPassword("123456");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("随便起个名");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%
bloomFilter.tryInit(100000000L,0.03);
//将号码10086插入到布隆过滤器中
bloomFilter.add("10086");
//判断下面号码是否在布隆过滤器中
//输出false
System.out.println(bloomFilter.contains("123456"));
//输出true
System.out.println(bloomFilter.contains("10086"));
}方式二:手写
package Bloomfilter;
import java.io.*;
import java.util.BitSet;
import java.util.Random;
import java.util.concurrent.atomic.AtomicInteger;
/**
* Created by Intellij IDEA.
* User: LYX
* Date: 2023/6/24
*/
public class BloomFilter {
/**
* 位数组,用于存储布隆过滤器的状态
*/
private BitSet bitSet;
/**
* 位数组的长度
*/
private int bitSetSize;
/**
* 预期元素数量
*/
private int expectedNumberOfElements;
/**
* 哈希函数数量
*/
private int numberOfHashFunctions;
/**
* 用于生成哈希种子的伪随机数生成器
*/
private Random random = new Random();
public BloomFilter(int bitSetSize, int expectedNumberOfElements) {
this.bitSetSize = bitSetSize;
this.expectedNumberOfElements = expectedNumberOfElements;
// 根据公式计算哈希函数数量
this.numberOfHashFunctions = (int) Math.round((bitSetSize / expectedNumberOfElements) * Math.log(2.0));
// 创建位数组并初始化所有位为0
this.bitSet = new BitSet(bitSetSize);
}
public void add(Object element) {
// 对元素进行多次哈希,并将对应的位设置为1
for (int i = 0; i < numberOfHashFunctions; i++) {
long hash = computeHash(element.toString(), i);
int index = getIndex(hash);
bitSet.set(index, true);
}
}
public boolean contains(Object element) {
// 对元素进行多次哈希,并检查所有哈希值所对应的位是否都被设置为1
for (int i = 0; i < numberOfHashFunctions; i++) {
long hash = computeHash(element.toString(), i);
int index = getIndex(hash);
if (!bitSet.get(index)) {
return false;
}
}
return true;
}
private int getIndex(long hash) {
// 将哈希值映射到位数组的下标(需要确保下标非负)
return Math.abs((int) (hash % bitSetSize));
}
private long computeHash(String element, int seed) {
// 使用伪随机数生成器生成不同的哈希种子
random.setSeed(seed);
// 将元素转换为字节数组,并计算其哈希值
byte[] data = element.getBytes();
long hash = 0x7f52bed27117b5efL;
for (byte b : data) {
hash ^= random.nextInt();
hash *= 0xcbf29ce484222325L;
hash ^= b;
}
return hash;
}
}
测试
/**
* Created by Intellij IDEA.
* User: LYX
* Date: 2023/6/25
*/
public class BloomfilterTest {
public static void main(String[] args) {
List<String> strings = Arrays.asList("JAVA", "JVM", "Redis", "MySQL", "GG");
BloomFilter filter = new BloomFilter(1000, 5);
// 将所有字符串添加到布隆过滤器中
for (String s : strings) {
filter.add(s);
}
String[] queries = {"GG", "MySQL", "JVM", "java"};
for (String query : queries) {
System.out.println("是否包含:" + query + "-" + filter.contains(query));
}
}
}
运行结果