目录
Day_58符号型数据的 NB 算法
一. 关于NB算法的介绍
1. 条件概率
2. 独立性假设
3. 以上式子的分析
4. Laplacian 平滑
5. 问题的回顾
二. 代码实现
1. 代码的符号说明
2. 构造函数和基础函数
3. 计算结果的分布情况
4. 核心代码
5. 分类
三. 符号型数据的运行结果
Day_59数值型数据的 NB 算法
一. 数值型数据的特点
二. 代码实现
1. 计算期望和方差
2. 高斯类
3. 预测结果
三. 运行结果
Day_58符号型数据的 NB 算法
一. 关于NB算法的介绍
这里闵老师写的博客很清楚了,主要是介绍NB算法的基础理论,这里我只是稍微写一下我自己过程中遇到的问题和重要的只是总结
1. 条件概率
对于这一部分概率论的知识我们简单回顾一下,待会NB算法要用的到。学习过概率论的同学都知道一个条件概率的东西,具体的公式如下:
——(1)
其中表示A事件发生的概率,
表示B事件的概率,
表示在事件B发生的前提下事件A发生的概率。对于如下的数据:我们有
P(outlook =sunny)= 5/14(所有数据中晴天的概率),P(humidity =high∣outlook =sunny )= 3/5(在晴天的数据中,湿度高的概率),P(outlook =sunny∧humidity =high)= 3/14(在所有的数据中,既是晴天又是湿度高的概率是3/14),并且他们之间有这样的关系:P(outlook =sunny)P(humidity =high∣outlook =sunny )= P(outlook =sunny∧humidity =high)
@relation weather.symbolic
@attribute outlook {sunny, overcast, rainy}
@attribute temperature {hot, mild, cool}
@attribute humidity {high, normal}
@attribute windy {TRUE, FALSE}
@attribute play {yes, no}@data
sunny,hot,high,FALSE,no
sunny,hot,high,TRUE,no
overcast,hot,high,FALSE,yes
rainy,mild,high,FALSE,yes
rainy,cool,normal,FALSE,yes
rainy,cool,normal,TRUE,no
overcast,cool,normal,TRUE,yes
sunny,mild,high,FALSE,no
sunny,cool,normal,FALSE,yes
rainy,mild,normal,FALSE,yes
sunny,mild,normal,TRUE,yes
overcast,mild,high,TRUE,yes
overcast,hot,normal,FALSE,yes
rainy,mild,high,TRUE,no
2. 独立性假设
首先我们根据(1)式,
——(2)
由于我们1.1是对于条件是1维的情况做的条件概率,那么条件是n维呢?即P(D|X),这里的X表示n个条件,例如(在天气为晴朗,温度为热,湿度为高,无风的情况下去玩的概率是100%(从数据得出,可能是由于数据集太小导致))
这里我们思考一下,若条件这些都不是相互独立的会怎么样?答案显而易见那么就不能直接从数据里面得到它的结果,所以这里我们引入一个独立性假设(上面是独立性,欢迎参考这篇文章),假设条件与条件之间是完全相互独立的,
那么我们现在就可以将其化简成为:
——(3)
联立(2)(3)
——(4)
3. 以上式子的分析
对于(4)式我们观察一下,对于需要计算的结果它的等价式:
可以由数据中计算得到,对于每一个
也可以有数据计算得到,但是对于P(X)我们不能计算(例如:天气晴朗且温度为热且湿度为高且无风的情况下概率无法计算)好在我们并不需要计算P(X)的值,只需要比较分子的大小就可以预测是“去玩”还是“不去玩”了。
4. Laplacian 平滑
现在看起来上面的式子(4)是不是很合理?好像我们只需要计算(4)式左边的所有项就可以得到去玩或者不去玩的概率了,但是这里存在一个很严重的问题——(4)的左边项有没有可能某一个式子为0?(例如在去玩的情况下,天气为阴天的概率为0)那么无论左边的其余项为什么计算得到的结果永远是0了。
怎么处理这里的式子呢?这里将式子改造一下
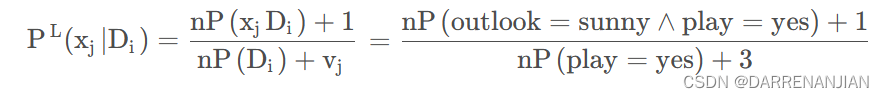
n是所有数据的数量,是这个
对应的属性的数量,这里由于P都是概率所以乘n将概率转化为具体的数据,对于相加的
是为了使
+
+...
相加为1。例如对于上面的天气数据,P(outlook =sunny | play =yes)的变换为
同样的道理对于也进行变形:
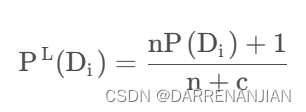
接着我们对于(4)式子可以进行取log(原因在于数据较大时防止溢出),再将P(x)去掉,故现在求概率的等式为
5. 问题的回顾
问题的构建:算了这么大一堆公式不要忘记了我们原本最初的目的是什么,我们的问题是判断在X的条件下D发生的概率。以天气数据为例,我们输入训练集(数据),接着对每一个数据做leave-out-leave测试,判断在每一个条件下的P(D|X)的概率,接着根据概率的大小判断是去玩还是不去玩。而这个P(D|X)就是由我们上面的推导过程计算出来的。
二. 代码实现
这里先写出符号型数据的处理
1. 代码的符号说明
dataset数据处理的实例,可以把想象成一堆数据构成的对象;numClasses表示判定结果有多少种的数量;numInstances表示数据有多少个;numConditions表示条件有几个;predicts表示预测的结果(对应的预测结果有numClasses种,选其中一种);classDistribution表示结果数据的占比;classDistributionLaplacian表示经过Laplacian变换之后的结果数据的占比;conditionalCounts三维数组:第一维表示结果的种类数量,第二维表示条件的数量,第三维表示在某一个结果的情况下,某个条件对应的某个属性的个数;conditionalProbabilitiesLaplacian表示conditionalCounts经过Laplacian变换的个数;dataType,NOMINAL,NUMERICAL表示是符号型数据还是数值型数据。
/**
* The data.
*/
Instances dataset;
/**
* The number of classes. For binary classification it is 2.
*/
int numClasses;
/**
* The number of instances.
*/
int numInstances;
/**
* The number of conditional attributes.
*/
int numConditions;
/**
* The prediction, including queried and predicted labels.
*/
int[] predicts;
/**
* Class distribution.
*/
double[] classDistribution;
/**
* Class distribution with Laplacian smooth.
*/
double[] classDistributionLaplacian;
/**
* To calculate the conditional probabilities for all classes over all
* attributes on all values.
*/
double[][][] conditionalCounts;
/**
* The conditional probabilities with Laplacian smooth.
*/
double[][][] conditionalProbabilitiesLaplacian;
/**
* The Guassian parameters.
*/
GaussianParamters[][] gaussianParameters;
/**
* Data type.
*/
int dataType;
/**
* Nominal.
*/
public static final int NOMINAL = 0;
/**
* Numerical.
*/
public static final int NUMERICAL = 1;
2. 构造函数和基础函数
就是打开文件,传入数据,然后统计条件数numConditions,数据的个数numInstances,结果的种类数numClasses
public NaiveBayes(String paraFilename) {
dataset = null;
try {
FileReader fileReader = new FileReader(paraFilename);
dataset = new Instances(fileReader);
fileReader.close();
} catch (Exception ee) {
System.out.println("Cannot read the file: " + paraFilename + "\r\n" + ee);
System.exit(0);
} // Of try
dataset.setClassIndex(dataset.numAttributes() - 1);
numConditions = dataset.numAttributes() - 1;
numInstances = dataset.numInstances();
numClasses = dataset.attribute(numConditions).numValues();
}// Of the constructor这里设定是数值型还是符号型
/**
********************
* Set the data type.
********************
*/
public void setDataType(int paraDataType) {
dataType = paraDataType;
}// Of setDataType3. 计算结果的分布情况
第一个for循环的tempCounts用于记录每一种结果的个数,将它写入tempCounts;第二个for循环的classDistribution用于计算最直接的分布(结果1占总数据个数的多少,结果2占总数据个数的多少...),classDistributionLaplacian用于计算classDistribution经过Laplacian变换后的结果,背后的数学逻辑详见上文(一.关于NB算法的介绍)
/**
********************
* Calculate the class distribution with Laplacian smooth.
********************
*/
public void calculateClassDistribution() {
classDistribution = new double[numClasses];
classDistributionLaplacian = new double[numClasses];
double[] tempCounts = new double[numClasses];
for (int i = 0; i < numInstances; i++) {
int tempClassValue = (int) dataset.instance(i).classValue();
tempCounts[tempClassValue]++;
} // Of for i
for (int i = 0; i < numClasses; i++) {
classDistribution[i] = tempCounts[i] / numInstances;
classDistributionLaplacian[i] = (tempCounts[i] + 1) / (numInstances + numClasses);
} // Of for i
System.out.println("Class distribution: " + Arrays.toString(classDistribution));
System.out.println("Class distribution Laplacian: " + Arrays.toString(classDistributionLaplacian));
}// Of calculateClassDistribution4. 核心代码
介绍conditionalCounts和conditionalProbabilitiesLaplacian;说白了conditionalCounts就是记录在结果i的情况下,对应的某一个条件的不同情况的数据个数(例如当去玩的情况下,对于天气属性为晴天,雨天,多云;这几种情况下数据的个数(其他条件在这里不考虑),当然还有不去玩的情况下,同理可得)。
第一个for循环即分配大小,conditionalCounts不是现在只有结果和条件的维度吗,再添加维度是某一个条件下的各个属性的值。
第二个for循环,循环遍历每一个数据,再遍历每一个条件记录这个时候的数据值,将它对应的conditionalCounts矩阵的对应值加1(这里一定要记住conditionalCounts是记录数量的矩阵),接着计算出conditionalCounts经过Laplacian变换条件矩阵即可
/**
********************
* Calculate the conditional probabilities with Laplacian smooth. ONLY scan
* the dataset once. There was a simpler one, I have removed it because the
* time complexity is higher.
********************
*/
public void calculateConditionalProbabilities() {
conditionalCounts = new double[numClasses][numConditions][];
conditionalProbabilitiesLaplacian = new double[numClasses][numConditions][];
// Allocate space
for (int i = 0; i < numClasses; i++) {
for (int j = 0; j < numConditions; j++) {
int tempNumValues = (int) dataset.attribute(j).numValues();
conditionalCounts[i][j] = new double[tempNumValues];
conditionalProbabilitiesLaplacian[i][j] = new double[tempNumValues];
} // Of for j
} // Of for i
// Count the numbers
int[] tempClassCounts = new int[numClasses];
for (int i = 0; i < numInstances; i++) {
int tempClass = (int) dataset.instance(i).classValue();
tempClassCounts[tempClass]++;
for (int j = 0; j < numConditions; j++) {
int tempValue = (int) dataset.instance(i).value(j);
conditionalCounts[tempClass][j][tempValue]++;
} // Of for j
} // Of for i
// Now for the real probability with Laplacian
for (int i = 0; i < numClasses; i++) {
for (int j = 0; j < numConditions; j++) {
int tempNumValues = (int) dataset.attribute(j).numValues();
for (int k = 0; k < tempNumValues; k++) {
conditionalProbabilitiesLaplacian[i][j][k] = (conditionalCounts[i][j][k] + 1)
/ (tempClassCounts[i] + tempNumValues);
// I wrote a bug here. This is an alternative approach,
// however its performance is better in the mushroom dataset.
// conditionalProbabilitiesLaplacian[i][j][k] =
// (numInstances * conditionalCounts[i][j][k] + 1)
// / (numInstances * tempClassCounts[i] + tempNumValues);
} // Of for k
} // Of for j
} // Of for i
System.out.println("Conditional probabilities: " + Arrays.deepToString(conditionalCounts));
}// Of calculateConditionalProbabilities5. 分类
分类的框架函数,这里要考虑是数值型数据还是符号型数据,这两个(准确来说是一个,重载)函数没什么要写的,很简单,就是对于每个数据做leave-out-leave测试。
/**
********************
* Classify all instances, the results are stored in predicts[].
********************
*/
public void classify() {
predicts = new int[numInstances];
for (int i = 0; i < numInstances; i++) {
predicts[i] = classify(dataset.instance(i));
} // Of for i
}// Of classify
/**
********************
* Classify an instances.
********************
*/
public int classify(Instance paraInstance) {
if (dataType == NOMINAL) {
return classifyNominal(paraInstance);
} else if (dataType == NUMERICAL) {
return classifyNumerical(paraInstance);
} // Of if
return -1;
}// Of classify以下是分类的核心代码,对于一个实例paraInstance,tempPseudoProbability记录概率结果,第一重for循环计算是否去玩的情况下的概率值,第二重for循环计算条件概率的log相加值,最后判断得到的两个概率值,谁大就选哪一种结果,判断完毕。
/**
********************
* Classify an instances with nominal data.
********************
*/
public int classifyNominal(Instance paraInstance) {
// Find the biggest one
double tempBiggest = -10000;
int resultBestIndex = 0;
for (int i = 0; i < numClasses; i++) {
double tempPseudoProbability = Math.log(classDistributionLaplacian[i]);
for (int j = 0; j < numConditions; j++) {
int tempAttributeValue = (int) paraInstance.value(j);
tempPseudoProbability += Math.log(conditionalProbabilitiesLaplacian[i][j][tempAttributeValue]);
} // Of for j
if (tempBiggest < tempPseudoProbability) {
tempBiggest = tempPseudoProbability;
resultBestIndex = i;
} // Of if
} // Of for i
return resultBestIndex;
}// Of classifyNominal三. 符号型数据的运行结果
这里用的是天气的数据只有14条数据,准确率还是不错的0.928

接着使用mushroom数据对应的结果如下,准确率仍然不错

Day_59数值型数据的 NB 算法
一. 数值型数据的特点
对于字符型数据我们直接计算每一个属性的个数就是了(例如outlook属性有3个);但是对于数值型数据(比如iris数据的sepalwidth属性,全是数值型值,怎么计算个数?不能计算),这里我们首先想到能不能积分?(意思就是将比如5.0-6.0sepalwidth属性统计为一类,然后sepalwidth就可以计数了),但是这样做有一个坏处,计算太麻烦了,假如sepalwidth的数值跨度太大,那么要分多少类才能统计完毕?
所以这里我们思考能不能直接计算?答案是——可以!因为最终我们都是比对这些概率条件下的大小问题,因此我们可以让所有的数据列都适用一种概率评价指标。这里我们使用正态分布(因为这种假设对于通常的未知数据是可靠的,稳定的。)来模拟iris数据的每一个属性。用p(x)表示概率密度函数,p(x)是我们需要计算的用于模拟的结果。
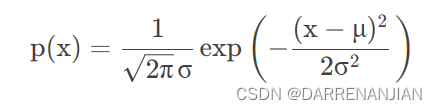
对于昨天计算出的Naive Bayes公式在经过Laplacian平滑的环境下有公式
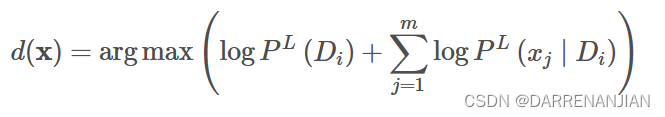
这里将拿出来,这里
的含义是确定某一个结果,对应的
的属性的概率,对应到概率密度函数里面就是:其中
不改变,对应的用
代替
,接着下面公式里面的对应的方差和期望都是关于确定结果
,计算对应的属性的值。
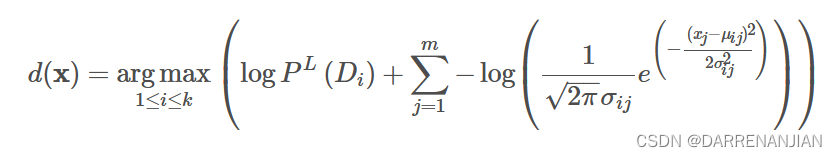
这样我们就将离散的数值型变量用统一的计算方式表示出来了,这个式子就是数值型Naive Bayes的推导式了,因为一般都采用正态分布带描述一般的数值数据,而正态分布又叫做高斯分布,所以一般的数值型Naive Bayes又称之为Gaussian Naive Bayes算法。
二. 代码实现
这里我只写和符号型代码不一样的地方
1. 计算期望和方差
当确定结果和属性之后,计算每一个的期望,期望=所有值相加/个数,方差=(每一个值-期望)的平方/个数在开根号。
/**
********************
* Calculate the conditional probabilities with Laplacian smooth.
********************
*/
public void calculateGausssianParameters() {
gaussianParameters = new GaussianParamters[numClasses][numConditions];
double[] tempValuesArray = new double[numInstances];
int tempNumValues = 0;
double tempSum = 0;
for (int i = 0; i < numClasses; i++) {
for (int j = 0; j < numConditions; j++) {
tempSum = 0;
// Obtain values for this class.
tempNumValues = 0;
for (int k = 0; k < numInstances; k++) {
if ((int) dataset.instance(k).classValue() != i) {
continue;
} // Of if
tempValuesArray[tempNumValues] = dataset.instance(k).value(j);
tempSum += tempValuesArray[tempNumValues];
tempNumValues++;
} // Of for k
// Obtain parameters.
double tempMu = tempSum / tempNumValues;
double tempSigma = 0;
for (int k = 0; k < tempNumValues; k++) {
tempSigma += (tempValuesArray[k] - tempMu) * (tempValuesArray[k] - tempMu);
} // Of for k
tempSigma /= tempNumValues;
tempSigma = Math.sqrt(tempSigma);
gaussianParameters[i][j] = new GaussianParamters(tempMu, tempSigma);
} // Of for j
} // Of for i
System.out.println(Arrays.deepToString(gaussianParameters));
}// Of calculateGausssianParameters2. 高斯类
用于记录期望和方差。
/**
*************************
* An inner class to store parameters.
*************************
*/
private class GaussianParamters {
double mu;
double sigma;
public GaussianParamters(double paraMu, double paraSigma) {
mu = paraMu;
sigma = paraSigma;
}// Of the constructor
public String toString() {
return "(" + mu + ", " + sigma + ")";
}// Of toString
}// Of GaussianParamters3. 预测结果
由公式
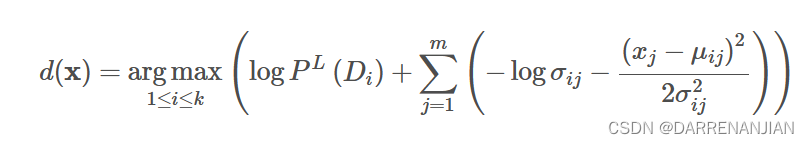
可以确定每一个条件对应的概率,最后根据概率的大小判断结论
/**
********************
* Classify an instances with numerical data.
********************
*/
public int classifyNumerical(Instance paraInstance) {
// Find the biggest one
double tempBiggest = -10000;
int resultBestIndex = 0;
for (int i = 0; i < numClasses; i++) {
double tempPseudoProbability = Math.log(classDistributionLaplacian[i]);
for (int j = 0; j < numConditions; j++) {
double tempAttributeValue = paraInstance.value(j);
double tempSigma = gaussianParameters[i][j].sigma;
double tempMu = gaussianParameters[i][j].mu;
tempPseudoProbability += -Math.log(tempSigma)
- (tempAttributeValue - tempMu) * (tempAttributeValue - tempMu) / (2 * tempSigma * tempSigma);
} // Of for j
if (tempBiggest < tempPseudoProbability) {
tempBiggest = tempPseudoProbability;
resultBestIndex = i;
} // Of if
} // Of for i
return resultBestIndex;
}// Of classifyNumerical
三. 运行结果
准确率为0.96还是相当准确的

这里补充一点可以和kNN算法做对比
kNN算法的运行结果:



![[Flask] Flask会话](https://img-blog.csdnimg.cn/c629a584c1284ba7a3056c77649bf667.png)