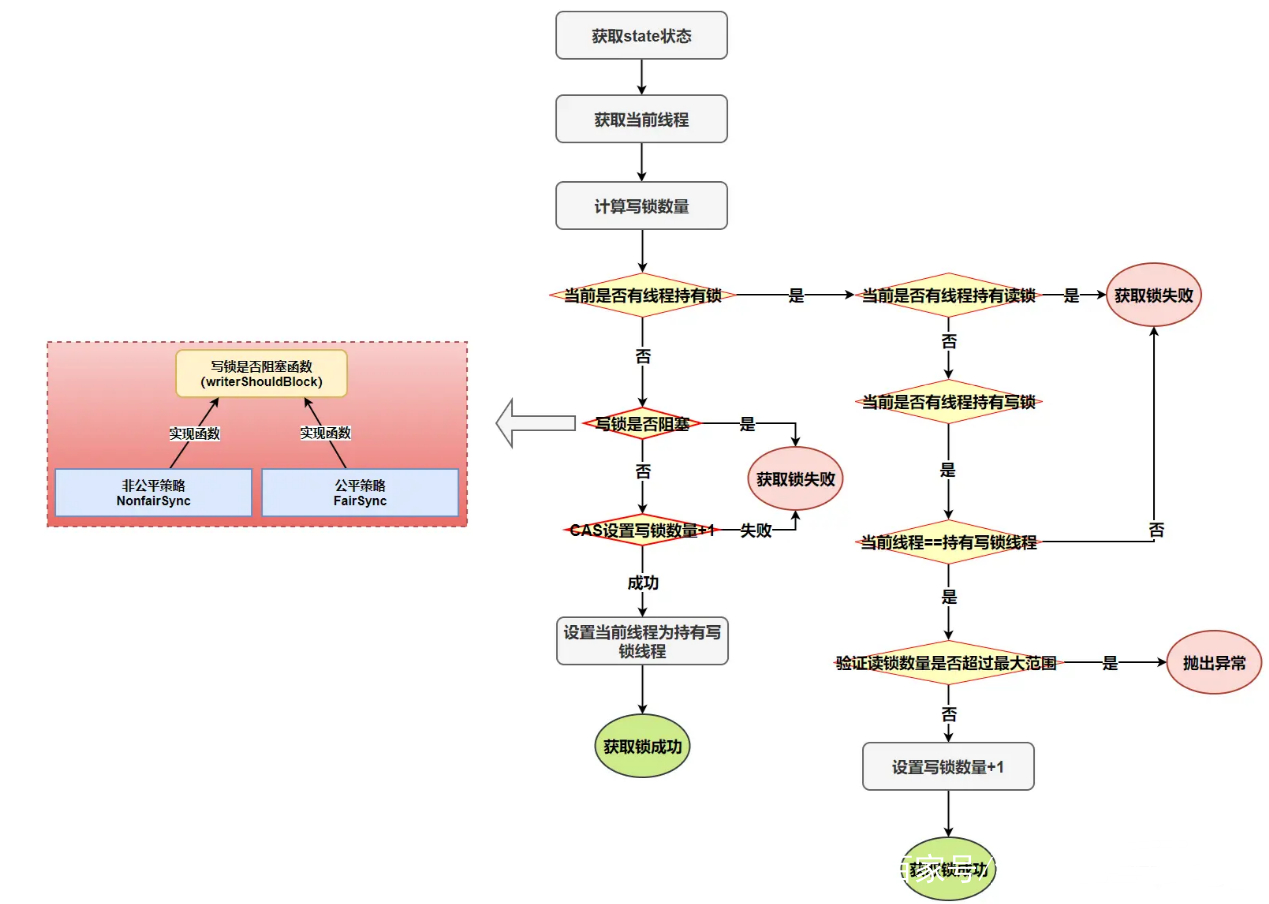
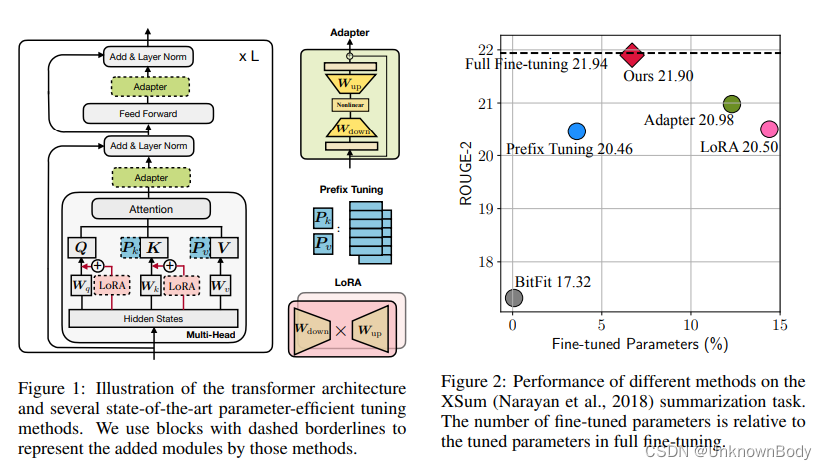
本文也是属于LLM系列的文章,针对《TOWARDS A UNIFIED VIEW OF PARAMETER-EFFICIENT TRANSFER LEARNING》的翻译。
关于参数有效迁移学习的统一观点
- 摘要
- 1 引言
- 2 前言
- 2.1 Transformer结构综述
- 2.2 之前的参数高效调优方法综述
- 3 弥合差距-统一的视角
- 3.1 仔细观察Prefix Tuning
- 3.2 统一框架
- 3.3 迁移的设计元素
- 4 实验
- 4.1 一般设置
- 4.2 当前方法的结果
- 4.3 哪种插入形式-顺序的还是并行的?
- 4.4 哪种修改的表征-attention或者FFN?
- 4.5 哪种合成函数?
- 4.6 通过传递有利的设计元素实现有效集成
- 5 讨论
摘要
在下游任务上微调大型预训练语言模型已经成为NLP中事实上的学习范式。然而,传统的方法对预训练模型的所有参数进行微调,随着模型大小和任务数量的增长,这变得令人望而却步。最近的工作提出了各种参数有效的迁移学习方法,这些方法只微调少量(额外)参数以获得强大的性能。虽然有效,但人们对成功的关键因素以及各种方法之间的联系知之甚少。在本文中,我们分解了最先进的参数有效迁移学习方法的设计,并提出了一个统一的框架,在它们之间建立联系。具体来说,我们将它们重新定义为对预训练模型中特定隐藏状态的修改,并定义一组不同方法变化的设计维度,例如计算修改的函数和应用修改的位置。通过对机器翻译、文本摘要、语言理解和文本分类基准的全面实证研究,我们利用统一的观点来确定以前方法中的重要设计选择。此外,我们的统一框架能够在不同的方法之间传递设计元素,因此,我们能够实例化新的参数有效的微调方法,这些方法比以前的方法调整更少的参数,同时更有效,实现了与微调所有四个任务的所有参数相当的结果。
1 引言
从预先训练的语言模型(PLM)中进行迁移学习现在是自然语言处理中的主流范式,在许多任务上都有很强的表现。使通用PLM适应下游任务的最常见方法是微调所有模型参数(完全微调)。然而,这导致每个任务都有一个单独的微调模型参数副本,当为执行大量任务的模型提供服务时,这是非常昂贵的。随着PLM规模的不断扩大,这一问题尤为突出,目前PLM的规模从数亿到数千亿,甚至数万亿的参数。
为了缓解这个问题,已经提出了一些轻量级的替代方案,只更新少量额外的参数,同时保持大多数预训练的参数冻结。例如,适配器调整将称为适配器的小型神经模块插入到预训练网络的每一层,并且在微调时仅训练适配器。受通过文本提示控制PLM的提示方法的成功启发、前缀调整和提示调整为输入或隐藏层准备了额外的
l
l
l个可调前缀标记,并且仅在对下游任务进行微调时训练这些软提示。最近,Hu等人学习低秩矩阵来近似参数更新。我们在图1中说明了这些方法。据报道,这些方法通常通过更新不到1%的原始模型参数,在不同的任务集上表现出与完全微调相当的性能。除了参数节省之外,参数有效调整还可以在没有灾难性遗忘的情况下快速适应新任务,并且在分布外评估中往往表现出优越的鲁棒性。
然而,我们认为,对这些参数有效调整方法取得成功的重要因素知之甚少,它们之间的联系仍不清楚。在本文中,我们旨在回答三个问题:(1)这些方法是如何连接的?(2) 这些方法是否共享对其有效性至关重要的设计元素?它们是什么?(3) 每种方法的有效成分能否迁移到其他方法中,以产生更有效的变体?
为了回答这些问题,我们首先推导了一种前缀调整的替代形式,揭示了前缀调整与适配器的密切联系(§3.1)。在此基础上,我们设计了一个统一的框架,将上述方法框定为修改冻结PLM的隐藏表示的不同方法(§3.2)。我们的统一框架沿着一组共享的设计维度分解了以前的方法,例如用于执行修改的功能、实施该修改的位置以及如何整合该修改。该框架允许我们跨方法转移设计选择,以提出新的变体,如具有多个头的适配器(§3.3)。在实验中,我们首先表明,现有的参数有效调整方法在更高资源和具有挑战性的任务上仍然落后于完全微调(§4.2),如图2所示。然后,我们利用统一的框架来识别关键的设计选择,并实证验证所提出的变体(§4.3-4.6)。我们在四个NLP基准上进行的实验,包括文本摘要、机器翻译(MT)、文本分类和一般语言理解,表明所提出的变体比现有方法使用更少的参数,同时更有效,匹配所有四项任务的完全微调结果。
2 前言
2.1 Transformer结构综述
Transformer模型现在是大多数最先进的PLM背后的主力架构。在本节中,为了完整性,我们回顾了该模型的方程。Transformer模型由L个堆叠块组成,其中每个块(图1)包含两种类型的子层:多头自注意和全连接前馈网络(FFN)。传统的注意函数映射查询
Q
∈
R
n
×
d
k
Q\in\mathbb{R}^{n\times d_k}
Q∈Rn×dk和键值对
K
∈
R
m
×
d
k
,
V
∈
R
m
×
d
v
:
K\in\mathbb{R}^{m\times d_k},V\in\mathbb{R}^{m\times d_v}:
K∈Rm×dk,V∈Rm×dv:
A
t
t
n
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
,
\begin{gather}Attn(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V, \end{gather}
Attn(Q,K,V)=softmax(dkQKT)V,
其中n和m分别是查询和键值对的数量。多头注意力在
N
h
N_h
Nh个头上并行执行注意力函数,其中每个头分别由
W
q
(
i
)
,
W
k
(
i
)
,
W
v
(
i
)
W_q^{(i)},W^{(i)}_k,W^{(i)}_v
Wq(i),Wk(i),Wv(i)参数化,以将输入投影到查询、键和值。给定我们想要在其上执行注意力的m个向量序列
C
∈
R
m
×
d
C\in\mathbb{R}^{m\times d}
C∈Rm×d和查询向量
x
∈
R
d
x\in\mathbb{R}^d
x∈Rd,多头注意力(MHA)计算每个头上的输出并将它们连接起来:
MHA
(
C
,
x
)
=
Concat
(
h
e
a
d
1
,
⋯
,
h
e
a
d
h
)
W
o
,
h
e
a
d
i
=
A
t
t
n
(
x
W
q
(
i
)
,
C
W
k
(
i
)
,
C
W
v
(
i
)
)
,
\begin{gather} \text{MHA}(C,x)=\text{Concat}(head_1,\cdots,head_h)W_o,head_i=Attn(xW_q^{(i)},CW^{(i)}_k,CW^{(i)}_v), \end{gather}
MHA(C,x)=Concat(head1,⋯,headh)Wo,headi=Attn(xWq(i),CWk(i),CWv(i)),
其中,
W
o
∈
R
d
×
d
W_o\in\mathbb{R}^{d\times d}
Wo∈Rd×d。d是模型维度,并且在MHA中,
d
h
d_h
dh通常被设置为
d
/
N
h
d/N_h
d/Nh以保存参数,这指示每个注意力头在较低维度空间上操作。另一个重要的子层是全连接前馈网络(FFN),它由两个线性变换组成,ReLU激活函数介于两者之间:
FFN
(
x
)
=
Relu
(
x
W
1
+
b
1
)
W
2
+
b
2
,
\begin{gather} \text{FFN}(x)=\text{Relu}(xW_1+b_1)W_2+b_2, \end{gather}
FFN(x)=Relu(xW1+b1)W2+b2,
其中
W
1
∈
R
d
×
d
m
,
W
2
∈
R
d
m
×
d
W_1\in\mathbb{R}^{d\times d_m},W_2\in\mathbb{R}^{d_m\times d}
W1∈Rd×dm,W2∈Rdm×d。Transformer通常使用大
d
m
d_m
dm,例如
d
m
=
4
d
d_m=4d
dm=4d。最后,使用残差连接,然后进行层正则化。
2.2 之前的参数高效调优方法综述
下面和图1中,我们介绍了几种最先进的参数有效调整方法。除非另有说明,否则它们只在PLM冻结时调整添加的参数。
适配器:适配器方法在Transformer层之间插入小型模块(适配器)。适配器层通常使用
W
d
o
w
n
∈
R
d
×
r
W_{down}\in\mathbb{R}^{d\times r}
Wdown∈Rd×r的向下投影将输入
h
h
h投影到由瓶颈维数r指定的低维空间,然后跟着非线性激活函数
f
(
⋅
)
f(\cdot)
f(⋅),以及
W
u
p
∈
R
r
×
d
W_{up}\in\mathbb{R}^{r\times d}
Wup∈Rr×d的向上投影。这些适配器被一个残差连接包围,从而形成最终的形式:
h
←
h
+
f
(
h
W
d
o
w
n
)
W
u
p
.
\begin{gather}h\leftarrow h+f(hW_{down})W_{up}. \end{gather}
h←h+f(hWdown)Wup.
Houlsby等人将两个适配器依次放置在Transformer的一层内,一个放置在多头注意力之后,一个放在FFN子层之后。Pfeiffer等人提出了一种更有效的适配器变体,仅在FFN“add & layer norm”子层之后插入。
前缀调整:受文本提示方法成功的启发,前缀调整将
l
l
l个可调前缀向量预先添加到每一层多头注意力的键和值中。具体地,两组前缀向量
P
k
,
P
v
∈
R
l
×
d
P_k,P_v\in\mathbb{R}^{l\times d}
Pk,Pv∈Rl×d与原始键K和值V拼接。然后,对新的带前缀的键和值进行多头关注。公式2中
head
i
\text{head}_i
headi的计算变为:
head
i
=
Attn
(
x
W
q
(
i
)
,
concat
(
P
k
(
i
)
,
C
W
k
(
i
)
)
,
concat
(
P
v
(
i
)
,
C
W
v
(
i
)
)
)
,
\begin{gather}\text{head}_i=\text{Attn}(xW^{(i)}_q,\text{concat}(P^{(i)}_k,CW^{(i)}_k),\text{concat}(P^{(i)}_v,CW^{(i)}_v)), \end{gather}
headi=Attn(xWq(i),concat(Pk(i),CWk(i)),concat(Pv(i),CWv(i))),
P
k
P_k
Pk和
P
v
P_v
Pv分别划分为
N
h
N_h
Nh个头向量,
P
k
(
i
)
,
P
v
(
i
)
∈
R
l
×
d
/
N
h
P^{(i)}_k,P^{(i)}_v\in\mathbb{R}^{l\times d/N_h}
Pk(i),Pv(i)∈Rl×d/Nh表示第i个头向量。提示调整通过仅对第一层中的输入单词嵌入进行预处理来简化前缀调整;类似的工作还包括P-调整。
LoRA:LoRA将可训练的低秩矩阵注入到Transformer层中,以近似权重更新。对于预训练的权重矩阵
W
∈
R
d
×
k
W\in\mathbb{R}^{d\times k}
W∈Rd×k,LoRA用低秩分解
W
+
Δ
W
=
W
+
W
d
o
w
n
W
u
p
W+\Delta W=W+W_{down}W_{up}
W+ΔW=W+WdownWup表示其更新,其中
W
d
o
w
n
∈
R
d
×
r
,
W
u
p
∈
R
r
×
k
W_{down}\in\mathbb{R}^{d\times r},W_{up}\in\mathbb{R}^{r\times k}
Wdown∈Rd×r,Wup∈Rr×k是可调参数。LoRA将此更新应用于多头注意力子层中的查询和值投影矩阵
(
W
q
,
W
v
)
(W_q,W_v)
(Wq,Wv),如图1所示。对于多头注意力中线性投影的特定输入
x
x
x,LoRA将投影输出
h
h
h修改为:
h
←
h
+
s
⋅
x
W
d
o
w
n
W
u
p
,
\begin{gather}h\leftarrow h+s\cdot xW_{down}W_{up}, \end{gather}
h←h+s⋅xWdownWup,
其中
s
≥
1
s\geq 1
s≥1是一个可调节的标量超参数。
其他:其他参数有效的调整方法包括BitFit,它只对预训练模型中的偏差向量进行微调,以及diff修剪,它学习稀疏参数更新向量。
3 弥合差距-统一的视角
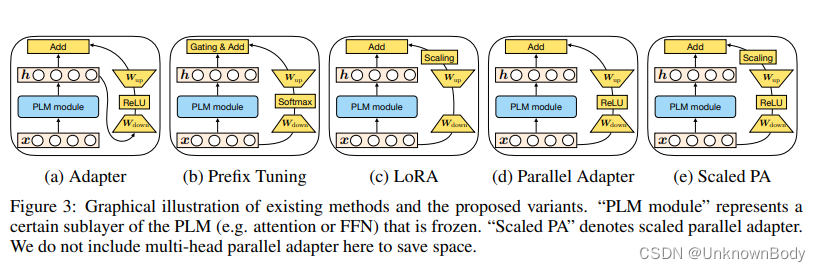
我们首先推导出一种等价形式的前缀调优,以建立其与适配器的连接。然后,我们提出了一个用于参数有效调整的统一框架,其中包括几个最先进的方法作为实例。
3.1 仔细观察Prefix Tuning
等式5描述了前缀调整的机制,该机制通过将
l
l
l个可学习向量预先添加到原始注意力键和值来改变注意力模块。在这里,我们导出了等式5的等效形式,并提供了前缀调整的替代视图:
head
=
Attn
(
x
W
q
,
concat
(
P
k
,
C
W
k
)
,
concat
(
P
v
,
C
W
v
)
)
=
softmax
(
x
W
q
concat
(
P
k
,
C
W
k
)
⊤
)
[
P
v
C
W
v
]
=
(
1
−
λ
(
x
)
)
softmax
(
x
W
q
W
k
⊤
C
⊤
)
C
W
v
+
λ
(
x
)
softmax
(
x
W
q
W
k
⊤
)
P
v
=
(
1
−
λ
(
x
)
)
Attn
(
x
W
q
,
C
W
k
,
C
W
v
)
⏟
standard attention
+
λ
(
x
)
Atn
(
x
W
q
,
P
k
,
P
v
)
⏟
independent of C
,
\begin{gather}\text{head}=\text{Attn}(xW_q,\text{concat}(P_k,CW_k),\text{concat}(P_v,CW_v)) \notag \\ =\text{softmax}(xW_q \text{concat}(P_k,CW_k)^\top)\begin{bmatrix} P_v \\ CW_v \end{bmatrix} \notag \\ =(1-\lambda(x))\text{softmax}(xW_qW_k^\top C^\top)CW_v+\lambda(x)\text{softmax}(xW_qW_k^\top)P_v \notag \\ =(1-\lambda(x))\underbrace{\text{Attn}(xW_q,CW_k,CW_v)}_{\text{standard attention}}+\lambda(x)\underbrace{\text{Atn}(xW_q,P_k,P_v)}_{\text{independent of C}}, \end{gather}
head=Attn(xWq,concat(Pk,CWk),concat(Pv,CWv))=softmax(xWqconcat(Pk,CWk)⊤)[PvCWv]=(1−λ(x))softmax(xWqWk⊤C⊤)CWv+λ(x)softmax(xWqWk⊤)Pv=(1−λ(x))standard attention
Attn(xWq,CWk,CWv)+λ(x)independent of C
Atn(xWq,Pk,Pv),
其中
λ
(
x
)
\lambda(x)
λ(x)是表示前缀上归一化注意力权重之和的标量:
λ
(
x
)
=
∑
i
exp
(
x
W
q
P
k
⊤
)
i
∑
i
exp
(
x
W
q
P
k
⊤
)
i
+
∑
j
exp
(
x
W
q
W
k
⊤
C
⊤
)
j
.
\begin{gather}\lambda(x)=\frac{\sum_i\exp(xW_qP_k^\top)_i}{\sum_i\exp(xW_qP_k^\top)_i+\sum_j\exp(xW_qW_k^\top C^\top)_j}. \end{gather}
λ(x)=∑iexp(xWqPk⊤)i+∑jexp(xWqWk⊤C⊤)j∑iexp(xWqPk⊤)i.
注意,等式7中的第一项
Attn
(
x
W
q
,
C
W
k
,
C
W
v
)
\text{Attn}(xW_q,CW_k,CW_v)
Attn(xWq,CWk,CWv)是没有前缀的原始注意力,而第二项是独立于C的按位置的修改。等式7给出了前缀调整的替代视图,其基本上通过线性插值对原始头部注意力输出
h
h
h应用按位置的改变:
h
←
(
1
−
λ
(
x
)
)
h
+
λ
(
x
)
Δ
h
,
Δ
h
:
=
softmax
(
x
W
q
P
k
⊤
)
P
v
.
\begin{gather}h\leftarrow(1-\lambda(x))h+\lambda(x)\Delta h,\Delta h:=\text{softmax}(xW_qP_k^\top)P_v. \end{gather}
h←(1−λ(x))h+λ(x)Δh,Δh:=softmax(xWqPk⊤)Pv.
与适配器的连接:我们定义了
W
1
=
W
q
P
k
⊤
,
W
2
=
P
v
,
f
=
softmax
W_1=W_qP_k^\top,W_2=P_v,f=\text{softmax}
W1=WqPk⊤,W2=Pv,f=softmax,然后重写了等式9:
h
←
(
1
−
λ
(
x
)
)
h
+
λ
(
x
)
f
(
x
W
1
)
W
2
,
\begin{gather}h\leftarrow(1-\lambda(x))h+\lambda(x)f(xW_1)W_2, \end{gather}
h←(1−λ(x))h+λ(x)f(xW1)W2,
它达到了与等式4中的适配器函数非常相似的形式,除了前缀调优正在执行加权加法,而适配器函数是未加权的。图3b从这个视图展示了前缀调优的计算图,它允许将前缀调优抽象为像适配器一样的插件模块。此外,我们注意到,当
l
l
l很小时,
W
1
∈
R
d
h
×
l
W_1\in\mathbb{R}^{d_h\times l}
W1∈Rdh×l和
W
2
∈
R
l
×
d
h
W_2\in\mathbb{R}^{l\times d_h}
W2∈Rl×dh是低秩矩阵,因此它们的函数类似于适配器中的
W
d
o
w
n
W_{down}
Wdown和
W
u
p
W_{up}
Wup矩阵。这种观点还表明,前缀向量的数量
l
l
l与适配器中的瓶颈维度
r
r
r起着类似的作用:它们都表示计算修改向量
Δ
h
\Delta h
Δh的秩限制。因此,我们也将
l
l
l称为瓶颈维度。直观地说,秩限制意味着
Δ
h
\Delta h
Δh是任何
x
x
x的相同
l
l
l(或
≤
l
\leq l
≤l)基向量的线性组合。
与适配器的区别:除了增加门变量
λ
\lambda
λ之外,我们还强调前缀调整和适配器之间的三个区别。(1) 如图3所示,前缀调整使用PLM层的输入
x
x
x来计算
Δ
h
\Delta h
Δh,而适配器使用PLM层输出
h
h
h。因此,前缀调整可以被认为是PLM层的“并行”计算,而典型的适配器是“顺序”计算。(2) 适配器在插入位置方面比前缀调整更灵活:适配器通常修改注意力或FFN输出,而前缀调整仅修改每个头部的注意力输出。根据经验,这产生了很大的差异,正如我们将在§4.4中所示。(3) 等式10适用于每个注意力头部,而适配器总是单头的,这使得前缀调整更具表现力:头部注意力的维度为
d
/
N
h
d/N_h
d/Nh——基本上,如果
l
≥
d
/
N
h
l\geq d/N_h
l≥d/Nh,我们对每个注意力头部都有全秩更新,但如果
r
≥
d
r\geq d
r≥d,我们只对适配器的整个注意力输出进行全秩更新。值得注意的是,当
l
=
r
l=r
l=r时,前缀调整不会添加比适配器更多的参数。我们在§4.4中实证验证了这种多头影响。
3.2 统一框架
受前缀调整和适配器之间联系的启发,我们提出了一个通用框架,旨在统一几种最先进的参数高效调优方法。具体来说,我们将它们投射为学习修改向量
Δ
h
\Delta h
Δh,该向量应用于各种隐藏表示。形式上,我们将要直接修改的隐藏表示表示为
h
h
h,并将计算
h
h
h的PLM子模块的直接输入表示为
x
x
x(例如,
h
h
h和
x
x
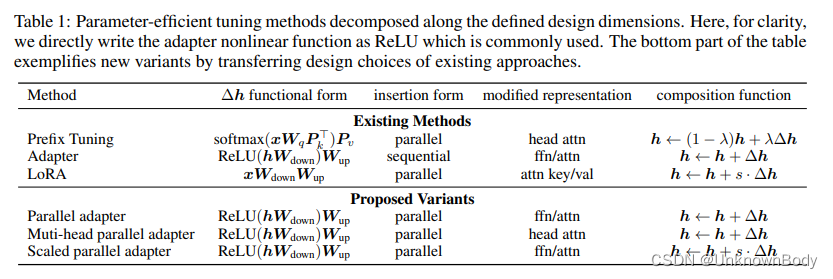
x可以分别是注意力输出和输入)。为了描述这个修改过程,我们定义了一组设计维度,可以通过沿着这些维度改变值来实例化不同的方法。我们详细介绍了以下设计维度,并在表1中说明了适配器、前缀调优和LoRA是如何实现的:
函数形式是计算
Δ
h
\Delta h
Δh的特定函数。我们在等式4、6和10中分别详细介绍了适配器、前缀调整和LoRA的功能形式。所有这些方法的功能形式与
proj_down
→
nonlinear
→
proj_up
\text{proj\_down}\rightarrow\text{nonlinear}\rightarrow\text{proj\_up}
proj_down→nonlinear→proj_up架构,而“非线性”退化为LoRA中的单位函数。
修改的表示法指示直接修改哪个隐藏的表示法。
插入形式是将添加的模块插入网络的方式。如前一节所述,如图3所示,传统上,适配器以顺序的方式插入在一个位置,其中输入和输出都是
h
h
h。前缀调整和LoRA——尽管最初没有以这种方式描述——结果相当于并行插入,其中
x
x
x是输入。
合成函数是修改后的向量
Δ
h
\Delta h
Δh如何与原始隐藏表示
h
h
h合成,以形成新的隐藏表示。例如,适配器执行简单的加法合成,前缀调整使用门加法合成,如等式所示10,LoRA通过常数因子缩放
Δ
h
\Delta h
Δh,并将其添加到原始隐藏表示中,如等式6所示。
我们注意到,表1中没有列出的许多其他方法也适用于该框架。例如,提示调整以类似于前缀调整的方式修改第一层中的头部注意力,并且各种适配器变体可以以类似于适配器的方式表示。至关重要的是,统一框架使我们能够沿着这些设计维度研究参数有效的调整方法,确定关键的设计选择,并潜在地跨方法传递设计元素,如下节所示。
3.3 迁移的设计元素
在这里,以及在图3中,我们只描述了一些新颖的方法,这些方法可以通过我们上面的统一视图通过在方法之间传递设计元素来派生:(1)Parallel Adapter是通过将前缀调优的并行插入传递到适配器中的变体。有趣的是,尽管我们由于并行适配器与前缀调整的相似性而激励它,但并行工作独立提出了这种变体并对其进行了实证研究;(2) 多头并行适配器是使适配器更类似于前缀调优的又一步:我们应用并行适配器将头部注意力输出修改为前缀调优。通过这种方式,变体通过利用我们在§3.1中讨论的多头投影来提高免费容量。(3) Scaled Parallel Adapter是将LoRA的组成和插入形式转移到适配器中的变体,如图3e所示。
到目前为止,我们的讨论和公式提出了几个问题:改变上述设计元素的方法是否表现出不同的特性?哪些设计维度特别重要?上述新方法是否产生更好的性能?我们接下来回答这些问题。
4 实验
4.1 一般设置
数据集:我们研究了四个下游任务:(1)XSum是一个英语摘要数据集,其中模型预测给定新闻文章的摘要;(2) 使用WMT 2016 en-ro数据集进行英语到罗马尼亚语翻译;(3) MNLI是一个英语自然语言推理数据集,模型预测一个句子是否包含、矛盾或与另一个句子无关。(4) SST2是一个英语情感分类基准,模型预测句子的情感是积极的还是消极的。
设置:我们使用BARTLARGE和它的多语言版本mBARTLARGO分别作为XSum和en-ro翻译的基础预训练模型,我们使用RoBERTaBASE用于MNLI和SST2。如果需要,我们会在{1,30,200,512,1024}范围内改变瓶颈维度。我们主要研究适配器、前缀调整(前缀)和LoRA,它们在我们的实验中大大优于bitfit和提示调整。在分析部分(§4.3-4.5)中,我们在注意力层或FFN层插入适配器,以便于分析,但在最终比较中包括在两个位置插入的结果(§4.6)。我们根据各自的公共代码重新实现这些方法。我们使用huggingface transformers库来实现。完整的设置细节见附录A。
评估:我们报告了XSum测试集上的ROUGE 1/2/L分数(R-1/2/L),en-ro测试集上BLEU分数,以及MNLI和SST2开发集的准确性。对于MNLI和SST2,我们取五次随机运行的中值。我们还报告了相对于完全微调(#params)中的微调参数的数量。
可调整参数的数量:BART和mBART具有编码器-解码器结构,具有三种类型的注意力:编码器自注意力、解码器自注意力和解码器交叉注意力。RoBERTa只有编码器的自注意力。对于每个注意力子层,每个方法使用的参数数量为:(1)前缀调优将
l
l
l个向量前置到键和值,并使用
2
×
l
×
d
2\times l\times d
2×l×d个参数;(2) 适配器具有
W
d
o
w
n
W_{down}
Wdown和
W
u
p
W_{up}
Wup,因此使用
2
×
r
×
d
2\times r\times d
2×r×d参数;(3) LoRA使用一对
W
d
o
w
n
W_{down}
Wdown和
W
u
p
W_{up}
Wup进行查询和值投影,因此使用
4
×
r
×
d
4\times r\times d
4×r×d参数。对于ffn处的适配器修改,它使用
2
×
r
×
d
2\times r\times d
2×r×d参数,这与注意的适配器相同。因此,对于
r
r
r或
l
l
l的特定值,前缀调优使用与适配器相同数量的参数,而LoRA使用更多的参数。更多详细信息见附录B。
4.2 当前方法的结果
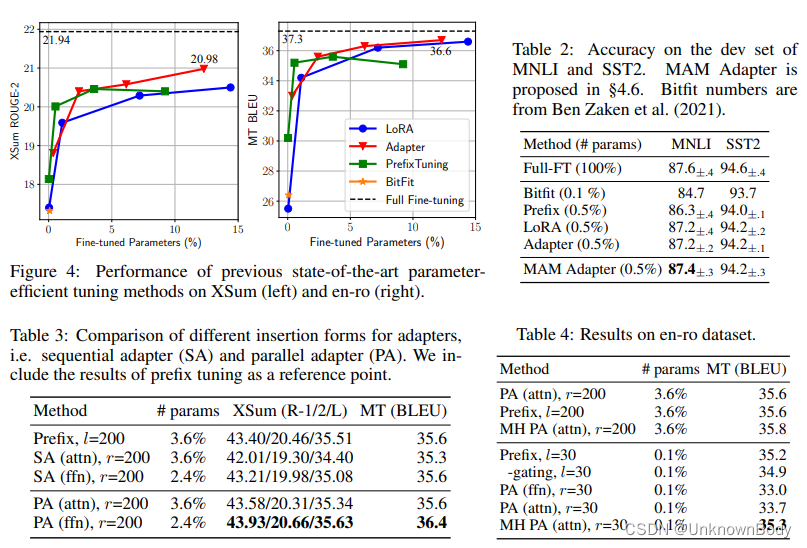
我们首先概述了现有方法在这四项任务上的结果。如图4和表2所示,虽然现有方法可以通过调整不到1%的参数在MNLI和SST2上实现有竞争力的性能,但如果我们在XSum和en-ro中添加5%的参数,仍然存在很大的差距。尽管我们将相对参数大小增加到>10%,但差距仍然很大。Raffel等人在高资源MT任务方面观察到了更大的差距。这表明,许多声称结果与仅使用编码器模型的GLUE基准上的完全微调结果相当的方法,或在相对简单的生成基准上,如使用编码器-解码器模型的E2E可能无法很好地推广到其他标准基准。影响因素可能很复杂,包括训练样本的数量、任务复杂性或模型架构。因此,我们主张未来对这一领域进行研究,以报告更多样化基准的结果,从而更全面地了解其绩效状况。下面,我们的分析将主要集中在XSum和en-ro数据集上,以更好地区分不同的设计选择。我们注意到,这两个基准是使用编码器-解码器模型(BART)执行的相对较高的资源,而我们将在§4.6中讨论仅使用编码器模型(RoBERTa)的MNLI和SST2的结果。
4.3 哪种插入形式-顺序的还是并行的?
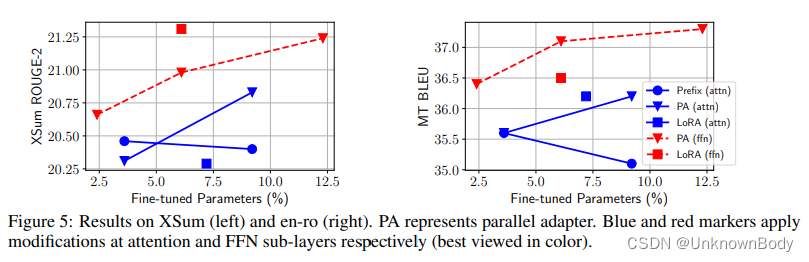
我们首先研究了插入形式的设计维度,在注意力(att)和FFN修改上,将所提出的并行适配器(PA)变体与传统的顺序适配器(SA)进行了比较。我们还将前缀调优作为参考点。如表3所示,使用并行插入的前缀调优优于注意力顺序适配器。此外,并行适配器在所有情况下都能够击败顺序适配器,其中PA(ffn)在XSum上分别比SA(ffn)高1.7个R-2点,在en-ro上高0.8个BLEU点。鉴于并行适配器的结果优于顺序适配器,我们将在下面的小节中重点介绍并行适配器结果。
4.4 哪种修改的表征-attention或者FFN?
设置:我们现在研究修改不同表示的效果。我们主要比较注意力和FFN修饰。为了便于分析,我们将修改注意力子层中任何隐藏表示的方法(如头部输出、查询等)归类为修改注意力模块。我们比较了注意力、FFN和前缀调优方面的并行适配器。我们还将FFN修改转移到LoRA,以具有LoRA(FFN)变体,用于完全比较。具体地,我们使用LoRA来近似FFN权重
W
1
∈
R
d
×
d
m
W_1\in\mathbb{R}^{d\times d_m}
W1∈Rd×dm和
W
2
∈
R
d
m
×
d
W_2\in\mathbb{R}^{d_m\times d}
W2∈Rdm×d的参数更新。在这种情况下,
W
1
W_1
W1的LoRA中的
W
u
p
W_{up}
Wup(类似于
W
2
W_2
W2的
W
d
o
w
n
W_{down}
Wdown)的尺寸为
r
×
d
m
r\times d_m
r×dm,其中
d
m
=
4
d
d_m=4d
dm=4d,如§2.1所述。因此,在以后的实验中,我们通常使用比其他方法更小的
r
r
r来匹配它们的总体参数大小。
结果:如图5所示,任何具有FFN修饰的方法在所有情况下都优于所有具有注意力修饰的方法(红色标记通常高于所有蓝色标记,唯一的例外是具有2.4%参数的FFN-PA),通常参数较少。其次,在FFN中应用的相同方法总是比其注意力对等方法有所改进。例如,LoRA(ffn)在XSum上将LoRA(attn)提高了1R-2个点。我们还强调,当我们进一步增加容量时,前缀调整并没有持续改进,这也在Li&Liang中观察到。这些结果表明,无论功能形式或组成功能是什么,FFN修饰都可以比注意力更有效地利用添加的参数。我们假设这是因为FFN学习特定于任务的文本模式,而注意力学习不需要大容量适应新任务的成对位置交互。
当我们使用0.1%的参数时,情况会有所不同吗?在§3.1中,我们认为前缀调优比适配器(attn)更具表现力,然而,这并没有反映在图5中。我们推测这是因为只有当参数预算很小时,多头注意力才是优越的。为了验证这一假设,我们将前缀调整与并行适配器进行比较,当它们添加0.1%的预训练参数时。为了消除合成函数的影响,我们还将前缀调整中去除门控的结果报告为
h
+
Δ
h
h+\Delta h
h+Δh。我们包括了§3.3中所述的多头并联适配器变体(MH-PA)的结果。如表4所示,当使用0.1%的参数时,多头方法——前缀调整和MH-PA(attn)——比所有其他方法至少高1.6个BLEU点。令人惊讶的是,将
l
l
l从200减少到30只会导致前缀调整的0.4 BLEU损失,而PA(attn)损失1.9分。前缀调整中的门控合成功能略微有助于结果0.3分。我们强调,MH并行适配器将单头版本改进了1.6点,这再次验证了多头形式的有效性。
结合图5和表4中的结果,我们得出结论,当参数预算非常小时,修改头部注意力显示出最佳结果,而FFN可以在更大的容量下更好地利用修改。这表明,为FFN修改分配更大的参数预算可能是有效的,而不是像Houlsby等人那样平等对待注意力和FFN。
4.5 哪种合成函数?
我们在§3.2中介绍了三个组合函数:简单加法(适配器)、门控加法(前缀调整)和缩放加法(LoRA)。由于在函数形式不使用softmax的方法中加入精确门控加法是不自然的,我们通过消融LoRA并与所提出的缩放并行适配器(缩放PA)进行比较来检查其他两种方法,我们将修改后的表示约束为FFN,因为它通常更有效,如§4.4所示。
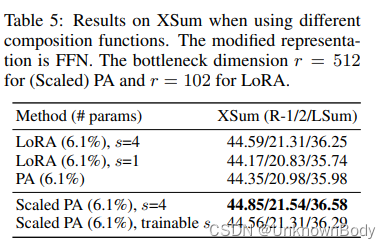
表5报告了XSum的结果。我们为适配器设置
r
r
r为512,为LoRA设置
r
r
r为102,以便它们的调整参数大小相同。我们根据开发集上的R-2分数来选择
s
s
s。我们观察到,LoRA(s=4)的性能优于并行适配器。但是,如果我们通过设置s=1来去除缩放,则优势将消失。通过将LoRA的合成函数插入到并行适配器中,得到的Scaled PA比普通并行适配器提高了0.56个ROUGE-2点。我们还用一个学习的标量进行了实验,它并没有给出更好的结果。因此,我们得出结论,缩放成分函数比普通加法函数更好,同时易于应用。
4.6 通过传递有利的设计元素实现有效集成
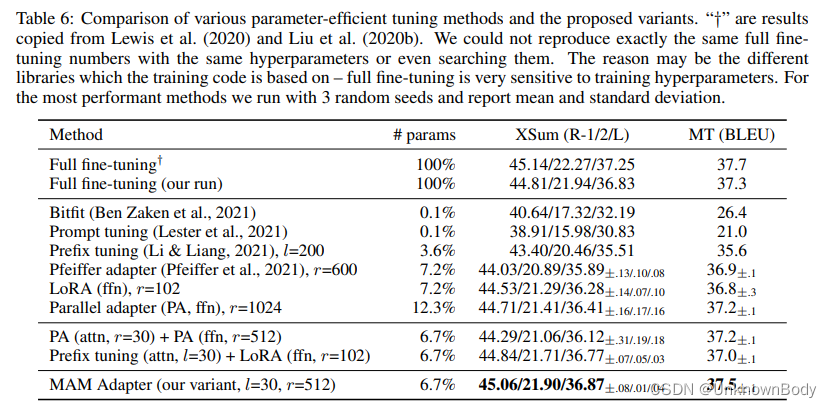
我们在前几节中首先强调了三个发现:(1)缩放并行适配器是修改FFN的最佳变体;(2) FFN可以更好地利用更大容量的修改;和(3)修改头部注意,如前缀调整,只需0.1%的参数就可以获得强大的性能。受他们的启发,我们混合并匹配了这些发现背后的有利设计:特别是,我们在注意力子层使用具有小瓶颈维度(
l
l
l=30)的前缀调整,并分配更多的参数预算来使用缩放的并行适配器修改FFN表示(r=512)。由于前缀调优在我们的统一框架中可以被视为适配器的一种形式,因此我们将这种变体命名为Mix-And-Match适配器(MAM-adapter)。在表6中,我们将MAM适配器与各种参数有效的调整方法进行了比较。为了完整性,我们还在表6中展示了其他组合版本的结果:在注意力层和FFN层使用并行适配器,并将前缀调整(attn)与LoRA(FFN)相结合——这两个组合版本都可以在各自的原型基础上进行改进。然而,MAM Adapter在这两项任务上都实现了最佳性能,并且仅更新6.7%的预训练参数就能够与我们的完全微调结果相匹配。在表2中,我们还展示了MAM-Adapter在MNLI和SST2上的结果,其中MAM-Adapter通过仅添加0.5%的预训练参数实现了与完全微调相当的结果。
5 讨论
我们为几种性能参数调整方法提供了一个统一的框架,这使我们能够通过跨方法迁移技术来实例化一个更有效的模型,该模型与完全微调方法的性能相匹配。我们希望我们的工作能够为未来参数有效调整的研究提供见解和指导。