参考文献:
33、完整讲解PyTorch多GPU分布式训练代码编写_哔哩哔哩_bilibili
pytorch进程间通信 - 文举的博客 (liwenju0.com)
前言
2023年,训练模型时,使用DDP(DistributedDataParallel)已经成为Pytorch炼丹师的标准技能。本文主要讲述实现Pytorch分布式要做哪些事情,以及如何理解Pytorch分布式训练背后的通信原理(不会很深入)。
分布式训练流程
单机多卡训练流程
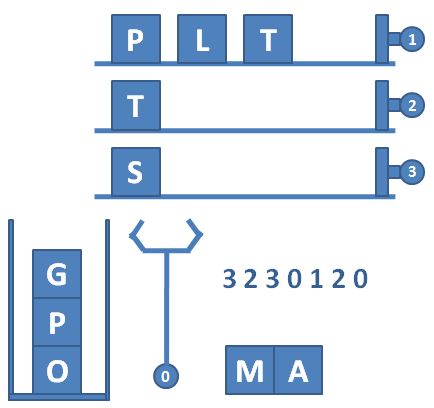
算法工程师实现单机多卡训练流程的思维导图如下:
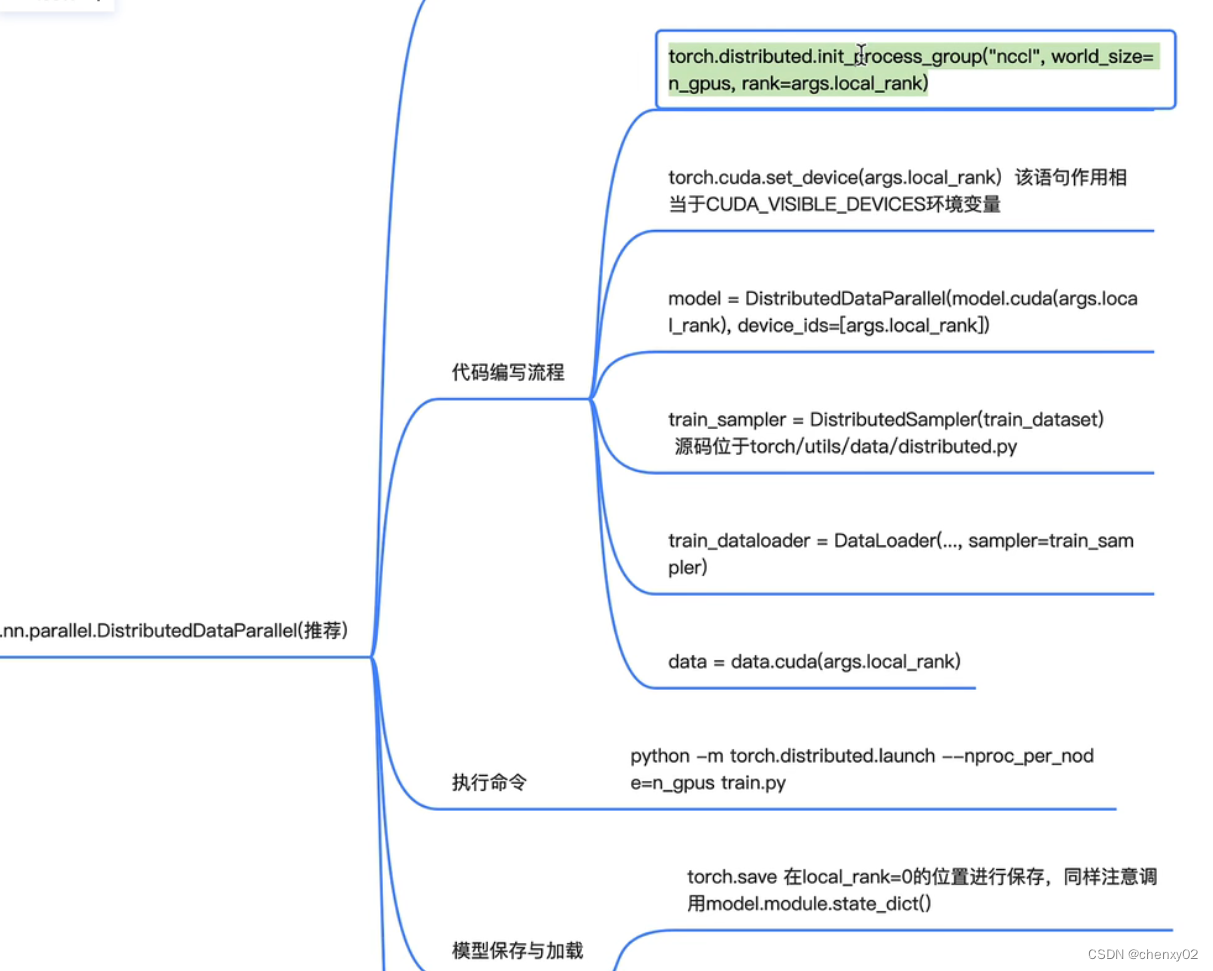
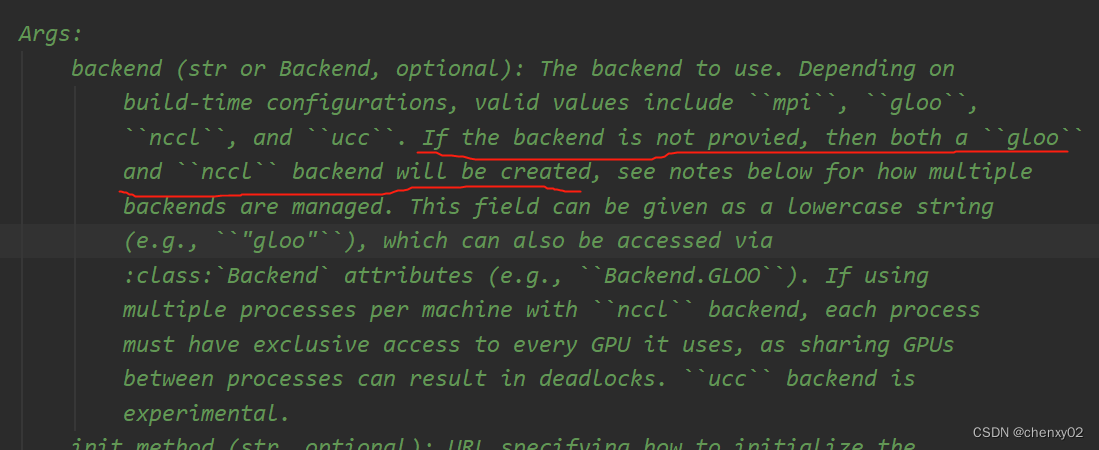
其中 init_process_proup(初始化进程组) 是实现整个训练的前提,其中比较重要的 world_size、rank 等参数的意义 我们后面会讲解,而像 backend 参数(指定通信库),如算法工程师没有进行指定,则 pytorch做出默认选择(在较低版本的 pytorch,如V1.0.0中,backend参数为必传)。
多机多卡训练流程
代码编写单机多卡一致,可复用代码。
Pytorch进程间通信
DDP 本身是依赖 torch.distributed 提供的进程间通信能力。所以理解torch.distributed提供的进程间通信的原理,对理解DDP的运行机制有很大的帮助。官方的tutorial中,实现了依靠torch.distributed实现DDP功能的demo代码,学习一下,很有裨益。
这部分,其实就两件事儿,建立进程组和实现进程组之间的通信。
创建进程组
说到底,就是建立多个进程,并且将这些进程归并到一起,成为一个group,在group内,每个进程一个id,用于标识自己。
建立多个进程,归根到底,还是一个进程一个进程建立。 那我们想,建立一个进程时,需要怎么做才能实现进程间的寻址呢。 torch.distributed给我们答案是四个参数:
- MASTER_ADDR
- MASTER_PORT
- WORLD_SIZE
- RANK
MASTER_PORT和MASTER_ADDR的目的是告诉进程组中负责进程通信协调的核心进程的IP地址和端口。当然如果该进程就是核心进程,它会发现这就是自己。 RANK参数是该进程的id,WORLD_SIZE是说明进程组中进程的个数。
了解以上这些知识,就可以看一下创建进程组的代码:
"""run.py:"""
#!/usr/bin/env python
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank, size):
""" Distributed function to be implemented later. """
pass
def init_process(rank, size, fn, backend='nccl'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size) #这段代码就是将该进程加入到进程组中的核心代码
fn(rank, size)
if __name__ == "__main__":
size = 2
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()观察代码,可以看到, MASTER_ADDR 和 MASTER_PORT 是通过在代码中设置环境变量传递给 torch.distributed 的, RANK 和 WORLD_SIZE 是通过参数传递的,其实也可以通过设置环境变量的方式传递。如下方法:
# 一般分布式GPU训练使用nccl后端,分布式CPU训练使用gloo后端
# init_method的值设为"env://",表示需要的四组参数信息都在环境变量里取。
dist.init_process_group(backend="nccl", init_method="env://")上面代码中的run就是在初始化好进程组之后执行的函数,这里之所以传入rank 和size,是想在执行过程中根据不同的rank,来给不同的进程赋予不同的行为,比如,日志只在rank==0的进程中打印等。实际上,如果已经初始化了进程组,也可以通过如下两个函数获取相应的值,避免在函数中传递这两个参数。
def get_world_size() -> int:
"""Return the number of processes in the current process group."""
if not dist.is_available() or not dist.is_initialized():
return 1
return dist.get_world_size()
def get_rank() -> int:
"""Return the rank of the current process in the current process group."""
if not dist.is_available() or not dist.is_initialized():
return 0
return dist.get_rank()这段代码是官方给的demo,看过之后,不免有些疑惑。这个代码似乎只适用于单机多卡的情况。 对于多机多卡的情况,在不同的机器上执行这个代码,MASTER_PORT 和MASTER_ADDR不用变,WORLD_SIZE需要调整为4,因为我们的代码每台机器上都启动两个进程, RANK这个时候就会发生冲突,不同的机器上的进程有相同的编号。解决方法就是在执行初始化函数时,传递一个NODE_RANK和NPROC_PER_NODE的参数,通过NODE_RANK和NPROC_PER_NODE计算出各个进程的RANK值,就可以保证不冲突了。 代码示例如下。
for r in range(NPROC_PER_NODE):
RANK = NODE_RANK*NPROC_PER_NODE + r实际上,torch已经将上面这些计算过程帮我们封装好了。代码如下所示:
python -m torch.distributed.launch \
--master_port 12355 \ #主节点的端口
--nproc_per_node=8 \ #每个节点启动的进程数
--nnodes=nnodes \ #节点总数
--node_rank=1 \ # 当前节点的rank
--master_addr=master_addr \ #主节点的ip地址
--use_env \ #在环境变量中设置LOCAL_RANK
train.py使用这段代码启动train.py时,原先的
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = "29500"
os.environ["RANK"] = str(rank)
os.environ["WORLD_SIZE"] = str(size)
# 一般分布式GPU训练使用nccl后端,分布式CPU训练使用gloo后端
dist.init_process_group(backend="nccl", init_method="env://")
fn(rank, size)可以简单改成:
dist.init_process_group(backend="nccl", init_method="env://")
fn()需要的四个环境变量参数,torch.distributed.launch都会帮我们设置好。fn中需要rank和size的地方,使用上面的两个便利函数即可。