搭建集群所需要安装包
虚拟机、ubuntu镜像文件、jdk安装包、hadoop安装包
百度云盘地址:
- 链接:https://pan.baidu.com/s/1ejVamlrlyoWtJRo1QQqlsA
- 提取码:fcqm
本文的环境是两台windows笔记本,在每台笔记本上安装一个虚拟机,并安装一个ubuntu系统,将其中一台主机作为master结点,另一台作为slave结点(或者使用一台主机,安装一个虚拟机,复制多个ubuntu子系统出来)
安装虚拟机
找到虚拟机可执行程序,点击运行

点击下一步

新建一个虚拟Ubuntu子系统
- 打开VMware Workstation

- 点击左上角新建文件,选择典型配置,并点击下一步

- 首先浏览文件夹,找到ubuntu镜像文件所在位置,点击确定;然后点击下一步

- 创建虚拟机名称和系统用户名称和密码,然后点击下一步。

- 创建虚拟机名称并选择虚拟机安装在本机的位置,然后点击下一步

- 修改内存,并将虚拟内存存为单个文件,然后点击下一步

- 点击确认并在安装后开启此虚拟机,会帮您自动安装,安装过程需要一个小时左右,耐心等待。
安装jdk和hadoop环境
- 打开虚拟机,登录ubuntu系统。
- 使用快捷键 Ctrl+Alt+T调出命令行窗口
登陆后先更新一下 apt,后续使用apt安装软件安装不了,可以执行以下下面的命令
sudo apt-get update
方便后面执行ifconfig,查看该虚拟机ip地址
sudo apt-get install net-tools
安装一下vim,后续需要修改很多文件
sudo apt-get install vim
vim有多种模式
- 正常模式
执行vi命令修改文本时,打开的文本都是只读文件,不可修改,即正常模式。 - 插入编辑模式
在正常模式下,输入i键,即可修改文本内容 - 推出vim
当我们修改好文本文件后,可以先按Esc键,退回到正常模式,然后输入:wq就可以保存文件并退回到命令行模式。
虚拟主机互联
点击虚拟机中的设置选项

点击网络适配器,改为桥接模式

ifconfig
显示以下信息就ok了

修改hostname配置信息
我有两台虚拟机主机,其中一台命名为master,另一台命名为slave01。在master这台主机上修改hostname为master,在slave01这台主机上修改hostname为slave01。注意:下面这条命令要分别在两台主机上执行。
sudo vim /etc/hostname
修改好后,重启两台主机,我们就可以看到以下的变化

在两台主机上分别测试是否可以互相ping的通
在主机master上输入
ping slave01
在主机slave01上输入
ping master
出现下面画面,说明可以互通

修改hosts信息
分别在两台主机中输入下面命令并修改内容
sudo vi /etc/hosts
我们通过在master和slave01上执行ifconfig后得到了两台主机的ip地址分别为192.168.1.103和192.168.1.107,j将主机名和ip地址映射起来。

安装SSH,配置免密登录
ssh命令可以远程登录其他主机,默认情况下是需要密码验证的,为了方便配置一下无密码登录
首先安装ssh server
sudo apt-get install openssh-server
安装后执行
ssh localhost
会提示输入密码,我们接下来配置一下无密码模式
先退出ssh登录,执行
exit
然后执行,注意两台主机上都要执行下面操作
cd ~/.ssh/
ssh-keygen -t rsa #有提示信息,就按回车
cat ./id_rsa.pub >> ./authorized_keys # 将密钥信息加入授权
配置过后再次执行ssh localhost,就不需要密码了
主机master连接slave01配置
将主机master上的id_rsa.pub传送给主机slave01
scp ~/.ssh/id_rsa.pub hadoop@slave01:/home/hadoop/
将master的公钥加入slave01主机,在主机slave01上执行
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
在主机master上测试
ssh slave01
这是主机界面会切换为主机slave01
JDK和Hadoop安装与配置
采用只在主机master上安装与配置Hadoop,然后压缩发送给主机slave01,最后同时在两台主机上修改编辑~/.bashrc文件,将安装的JDK和Hadoopan路径加入进去,方便主机能够检索到java和hadoop。
JDK安装与配置
jdk安装
首先需要有安装包,安装包是本机与虚拟机通过Xftp传送过来的。
- 注意jdk的安装与配置,两台机器要保持一样的操作,即主机master上配置一遍,主机slave上配置一遍。
进入/usr/lib,创建一个jvm路径,并将jdk压缩包解压缩到该目录下
cd /usr/lib
sudo mkdir jvm
#然后利用cd命令进入到jdk压缩包所在路径,每个人的路径不一样,我的压缩包在~、software目录下
cd ~/software
sudo -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm
jdk路径配置
执行下面命令
cd ~
vim ~/.bashrc
在配置文件里添加几行路径信息
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存并退出编辑模式,然后输入source ~/.bashrc,让配置文件立即生效。
source ~/.bashrc
下面信息表示安装与配置正确

Hadoop安装与配置
只在主机master上安装与配置Hadoop,最后打包发给slave01,然后解压缩,并将主机slave01上的~/.bashrc修改,将Hadoop路径信息添加进去就大功告成。
Hadoop安装与路径配置
进入hadoop安装包路径
cd ~/software
sudo tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local
cd /usr/local
sudo mv hadoop-3.1.3 hadoop #改名
sudo chown -R hadoop ./hadoop #将hadoop文件的权限给到hadoop用户,即目前登陆的用户
编辑~/.bashrc文件
vi ~/.bashrc
添加以下内容
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
输入source ~/.bashrc,让文件立即生效
source ~/.bashrc
测试hadoop是否可用
cd /usr/local/hadoop
./bin/hadoop version
出现下面画面说明配置成功

Hadoop集群信息配置
修改主机master中Hadoop的一些配置文件,配置文件均在
/usr/local/hadoop/etc/hadoop目录下:需要修改的文件都已经用红色框标出

- 修改workers
把里面的内容替换为slave01
2.修改core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
- 修改hdfs-site.xml
/usr/local/hadoop/dfs/name和/usr/local/hadoop/dfs/data需要自己指定和创建
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
</configuration>
- 修改mapred-site.xml(若没有,可复制mapred-site.xml.template,再修改文件名)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
配置好后,进入hadoop安装目录/usr/local,将hadoop整个打包发送给slave01主机,并在slave01主机上解压缩
主机master上执行
cd /usr/local
tar -zcf ~/hadoop.tar.gz ./hadoop
cd ~
scp ./hadoop.tar.gz slave01:/home/hadoop
主机slave01上执行
sudo tar -zxvf ~/hadoop.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop
最后一步要在主机slave01上配置一下hadoop路径信息
输入vi ~/.bashrc
vi ~/.bashrc
将hadoop路径加入进去
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
输入
source ~/.bashrc
让配置文件立即生效
启动hadoop集群
在master主机上执行
cd /usr/local/hadoop
bin/hdfs namenode -format
sbin/start-all.sh
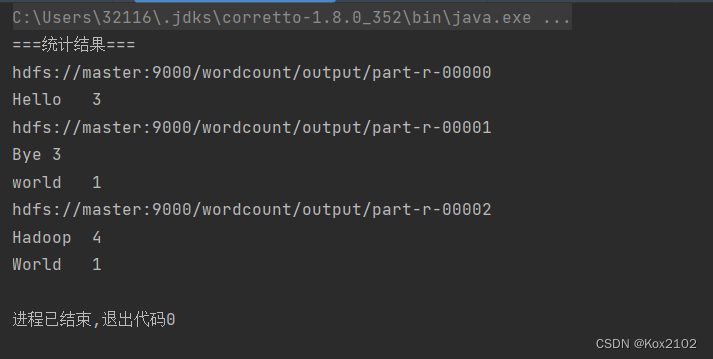
运行后,分别在master主机和slave01主机执行jps,查看进程
master主机页面

在master主机输入
ssh slave01
jps

自此,hadoop分布式集群环境搭建成功。
参考文献:
https://dblab.xmu.edu.cn/blog/1177/
https://dblab.xmu.edu.cn/blog/7/
https://blog.csdn.net/weixin_47677170/article/details/125668673
https://blog.csdn.net/a8131357leo/article/details/81281392
https://www.jianshu.com/p/d2b4a79d631b
https://www.likecs.com/show-204996897.html
https://blog.csdn.net/a6661314/article/details/124391249





![[激光原理与应用-41]:《光电检测技术-8》- 白光干涉仪](https://img-blog.csdnimg.cn/bb63d04a444e4a9f9c9dd8d5f655822a.png)