文章目录
- 1. unordered系列的容器封装
- 1.1 改造1:模版参数类型的改造
- 1.1.1 HashNode改造
- 1.1.2 HashTable改造
- 1.2 改造2:迭代器的增加与封装
- 1.2.1 迭代器类的实现
- 1.2.2 迭代器的封装
- 1.3 改造3:insert的改写封装
- 1.4 析构函数的实现
- 1.5 unordered_map&unordered_set的封装实现
- 2. 哈希的应用
- 2.1 位图
- 2.1.1 位图的概念
- 2.2.2 位图的代码实现
- 2.2 布隆过滤器
- 2.2.1 布隆过滤器的概念
- 2.2.2 布隆过滤器代码实现
- 2.2.3 布隆过滤器的评价
- 3. 面试题实战
- 3.1 哈希切割
- 3.2 位图的应用
- 3.3 布隆过滤器
1. unordered系列的容器封装
在C++11中,增加了unordered系列的容器,其底层就是哈希原理。在之前的博客内容中,我们实现了哈希的代码部分,包括闭散列和开散列两种。由于闭散列的局限性,所以C++11标准库是采用开散列的方式封装了unordered系列容器,接下来我们将使用之前实现的**哈希桶(开散列)**代码对unordered系列的容器进行改写与封装。
1.1 改造1:模版参数类型的改造
1.1.1 HashNode改造
//改造前
template<class K, class V>
struct HashNode
{
std::pair<K, V> _kv;
HashNode* _next;
HashNode(const std::pair<K, V>& kv)
:_kv(kv)
,_next(nullptr)
{}
};
由于unordered_set是K模型,而unordered_map是KV模型,为了让底层的哈希桶能够同时支持两种不同的模型,所以这里需要对哈希节点进行改造,改造后的结果如下:
//改造后
template<class T>//将模板参数变成T,对于K模型来说,传入的类型就是<Key,Key>键值对,对于KV模型来说,传入的就是<Key,Value>键值对
struct HashNode
{
T _data;
HashNode* _next;
HashNode(const T& data)
:_data(data)
,_next(nullptr)
{}
};
1.1.2 HashTable改造
//改造前
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
typedef HashNode<K, V> Node;
public:
bool Insert(const std::pair<K,V>& kv);
bool Erase(const K& key);
Node* Find(const K& key);
private:
std::vector<Node*> _tables;
size_t _n = 0;
}
这里由于节点的模板类型已经更改,所以之前的KV也需要进行更改,同时传入仿函数KeyOfT用来从键值对T中提取出key。
//修改后
template<class K, class T, class KeyOfT, class Hash = HashFunc<K>>
class HashTable
{
typedef HashNode<T> Node;//这里节点传入的类型是T
public:
HashTable()
:_n(0)
{
_tables.resize(10);
}
bool Insert(const T& data);
bool Erase(const K& key);
Node* Find(const K& key);
private:
std::vector<Node*> _tables;
size_t _n = 0;
};
1.2 改造2:迭代器的增加与封装
在之前使用红黑树封装map&set的时候已经说明,我们对于map&set的迭代器的处理,使用的是红黑树实现的迭代器。所以这里同样的,使用的是哈希桶封装的迭代器,那么我们首先就改写哈希桶
1.2.1 迭代器类的实现
和红黑树的迭代器一样,原生指针不能支持迭代器行为,所以我们需要自己手动实现一个迭代器类,然后进行一些运算符重载。
在迭代器类的实现中,最重要的一个运算符就是++运算符的重载。
template<class _K, class _T, class _KeyOfT, class _Hash = HashFunc<_K>>
class HashTable;//由于在迭代器类里面使用了HashTable,同时在HashTable中也使用了迭代器类,所以需要进行提前声明类模板
template<class K, class T, class KeyOfT, class Hash = HashFunc<K>>
struct __HTIterator
{
typedef HashTable<K, T, KeyOfT, Hash> HT;
typedef __HTIterator<K,T,KeyOfT,Hash> Self;
typedef HashNode<T> Node;
Node* _node;
HT* _ht;
__HTIterator(Node* node, HT* ht)
:_node(node)
,_ht(ht)
{}
//这里的思路是按照table的顺序遍历哈希桶,在哈希桶里面单向遍历桶内的每个数据
Self& operator++()
{
if(_node->_next)//当前桶还有元素
{
_node = _node->_next;
}
else//当前桶走完了,找下一个桶
{
size_t hashi = Hash()(KeyOfT()(_node->_data)) % _ht->_tables.size();//找到当前桶的哈希地址
//找到下一个有元素的哈希桶对应的哈希地址,并将其第一个元素赋值给node
++hashi;
while(hashi < _ht->_tables.size())
{
if(_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];
break;
}
else
{
++hashi;
}
}
//后面没有桶了
if(hashi == _ht->_tables.size())
_node = nullptr;
}
return *this;
}
//其他的重载在之前的文章中有详细说明,这里道理是一样的,就不再赘述了
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
bool operator== (const Self& s)
{
return _node==s._node;
}
};
注:
- 类模板的声明方法:
template<class type_name> class class_name;同时,这里需要调用HashTable中的私有成员,所以需要给出友元类。
- 友元类的声明方法:
template<class type_name> friend class class_name这里有一个点需要注意:
- 由于在clang下,使用同一个模版参数名会出现报错:
Declaration of '模版参数名' shadows template parameter,所以本次实现时在迭代器类的模版参数前加上_以示区分(详细代码见后文)。
1.2.2 迭代器的封装
实现了迭代器类之后,就可以在HashTable中封装迭代器接口
typedef __HTIterator<K, T, KeyOfT, Hash> iterator;
//迭代器
iterator begin()
{
//遍历,找到第一个有元素的桶
for(size_t i = 0; i < _tables.size(); ++i)
{
if(_tables[i])
{
return iterator(_tables[i], this);
}
}
return iterator(nullptr, this);
}
//这里采用空指针当作最后一个节点的下一个元素指针
iterator end()
{
return iterator(nullptr, this);
}
1.3 改造3:insert的改写封装
//改造前
bool Insert(const std::pair<K,V>& kv)
{
if(Find(kv.first))
return false;
if(_n == _tables.size())
{
std::vector<Node*> newTables;
newTables.resize(2* _tables.size(), nullptr);
for(size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while(cur)
{
Node* next = cur->_next;
size_t hashi = Hash()(cur->_kv.first) % newTables.size();
cur->_next = newTables[hashi];
newTables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newTables);
}
size_t hashi = Hash()(kv.first) % _tables.size();
Node* newnode = new Node(kv);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return true;
}
为了实现[]重载,所以这里和之前的map&set一样,需要对底层数据结构的insert进行改写,这里需要让返回值变成一个pair,其中的第一个成员是迭代器,第二个成员是原来的bool类型,所以代码如下
//改造后代码
std::pair<iterator, bool> Insert(const T& data)//这里将返回值修改为std::pair类型
{
iterator it = Find(KeyOfT()(data));//使用仿函数从data中提取到key
if(it != end())
return make_pair(it, false);//如果当前对应的key存在,那么就返回当前key的迭代器类型和false组成的pair
if(_n == _tables.size())
{
std::vector<Node*> newTables;
newTables.resize(2* _tables.size(), nullptr);
for(size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while(cur)
{
Node* next = cur->_next;
size_t hashi = Hash()(KeyOfT()(cur->_data)) % newTables.size();//使用仿函数从data中提取到key
cur->_next = newTables[hashi];
newTables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newTables);
}
size_t hashi = Hash()(KeyOfT()(data)) % _tables.size();//使用仿函数从data中提取到key
Node* newnode = new Node(data);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return make_pair(iterator(newnode, this), true);//使用newnode和this构造一个迭代器,将这个迭代器和插入情况构造成一个pair返回。
}
1.4 析构函数的实现
由于在构造或者插入的过程中使用new创建节点了,所以需要对new的资源进行手动释放,所以为了避免内存泄漏,需要进行析构函数的实现。
析构函数的实现原理就是:遍历哈希桶,依次释放节点。
所以代码就显而易见了:
~HashTable()
{
//遍历整个哈希表,依次释放节点
for(size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while(cur)
{
Node* next = cur->_next;//保存下个节点,防止出现当前节点释放,找不到下个节点的情况
delete cur;
cur = next;
}
_tables[i] = nullptr;//将当前桶的指针置空,防止出现野指针的情况
}
}
1.5 unordered_map&unordered_set的封装实现
在上文中,我们完善了unordered系列容器的底层:哈希桶的代码,现在哈希桶的底层就能够通过传出的参数类型不行而同时支持map和set的实现了。
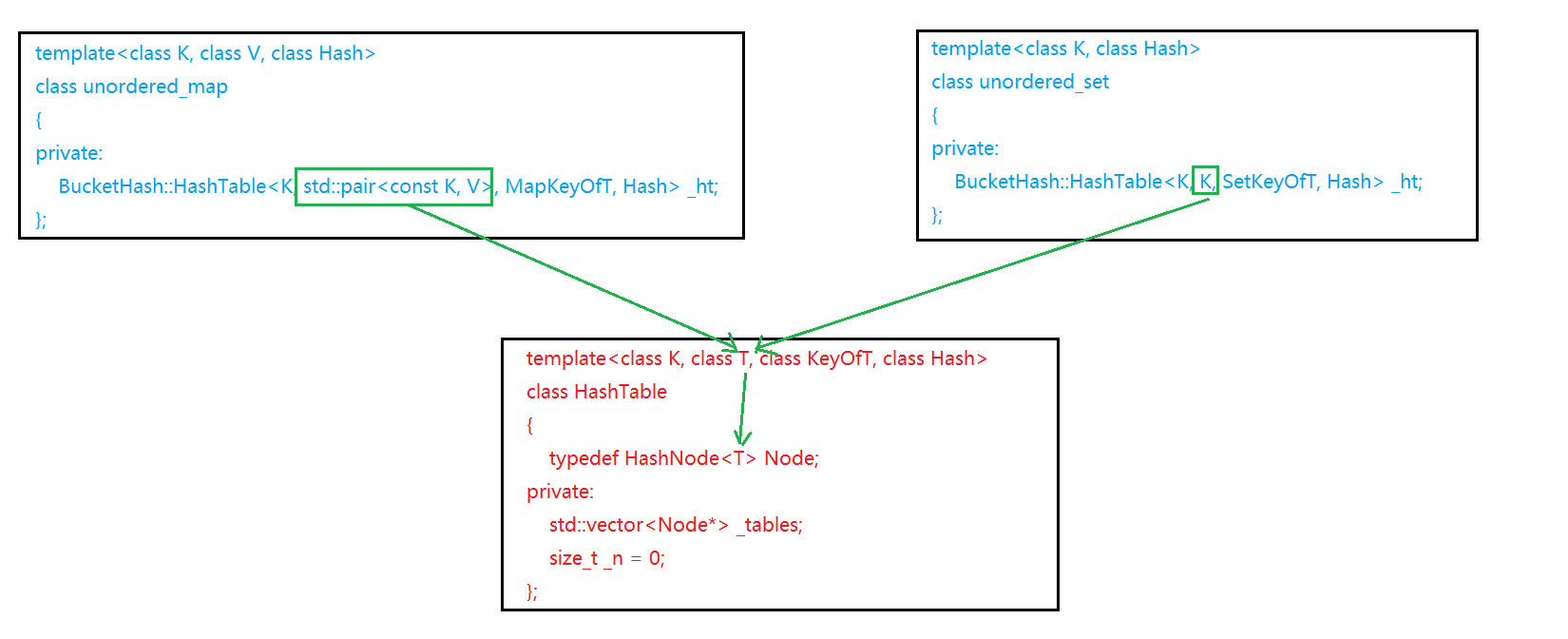
现在简易实现unordered系列容器就非常简单了,直接调用接口即可
//unordered_map
#pragma once
#include "BucketHash.hpp"
namespace zht
{
template<class K, class V, class Hash>
class unordered_map
{
struct MapKeyOfT//在unoredred_map的层面我们知道传入的V的类型是一个pair,所以这里对于仿函数的实现就和清晰了,直接拿到kv的first即可。
{
const K operator()(const std::pair<const K,V>& kv)
{
return kv.first;
}
};
public:
//迭代器类直接使用哈希桶的迭代器类
typedef typename zht::BucketHash::HashTable<K, std::pair<const K, V>, MapKeyOfT>::iterator iterator;
//迭代器直接调用哈希桶的迭代器封装即可
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
//insert直接调用哈希桶的insert
std::pair<iterator, bool> insert(const std::pair<K, V>& data)
{
return _ht.Insert(data);
}
//这里对于[]的重载可以去看博主的红黑树封装map和set,原理是相同的,链接在附在下面了
V& operator[](const K& key)
{
std::pair<iterator,bool> ret = _ht.Insert(make_pair(key, V()));
return ret.first->second;
}
private:
BucketHash::HashTable<K, std::pair<const K, V>, MapKeyOfT, Hash> _ht;//底层容器直接使用哈希桶
};
}
红黑树封装map和set
//unordered_set
#pragma once
#include "BucketHash.hpp"
namespace zht
{
template<class K, class Hash>
class unordered_set
{
struct SetKeyOfT//这里KV结构中的V的类型就是Key本身,所以直接返回key即可
{
const K operator()(const K& key)
{
return key;
}
};
public:
//迭代器类直接使用哈希桶的迭代器类
typedef typename zht::BucketHash::HashTable<K, K, SetKeyOfT>::iteraotr iterator;
//迭代器直接调用哈希桶的迭代器封装即可
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
//insert直接调用哈希桶的insert
std::pair<iterator,bool> insert(const K& key)
{
return _ht.Insert(key);
}
private:
BucketHash::HashTable<K, K, SetKeyOfT, Hash> _ht;
};
}
到这里我们的简化模拟实现基本就结束了。
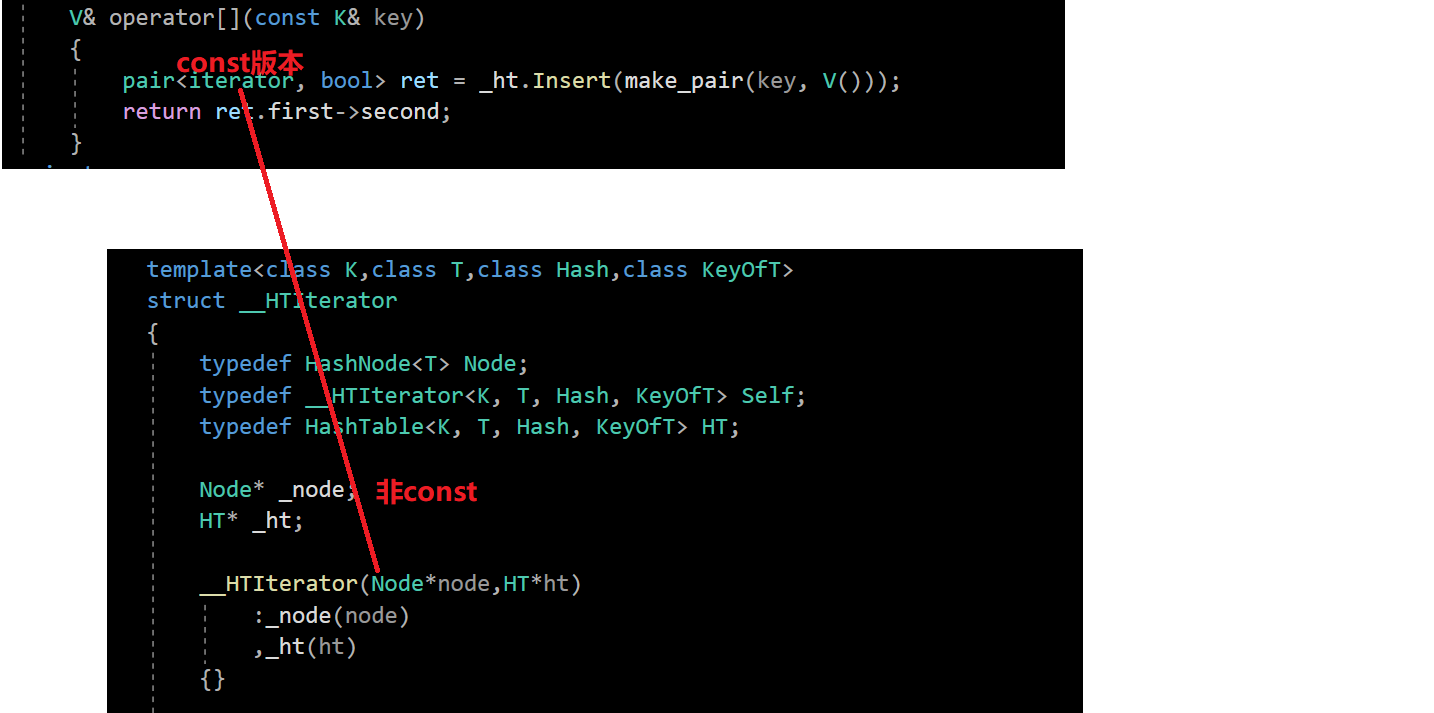
但是,如果我们去查看源码就会发现,对于const迭代器的实现,stl源码里面的实现方式并不是和之前的实现的容器的const迭代器一样,复用普通迭代器的代码

❓那么为什么不能够复用普通迭代器的代码嘞?
✅这是因为如果使用const版本,那么_tables使用[]返回的就是const版本,那么Node*就相当于是const Node*,就会导致权限放大,无法构造;如果改成const HT* _ht; const Node* _node;,又会导致[]不能修改的问题:
2. 哈希的应用
2.1 位图
2.1.1 位图的概念
接下来,我们通过一个面试题来里了解位图的概念
已知40亿个不重复的无符号整数,没有排过序。现在给你一个无符号整数,如何快速判断这个数是否在已知的40亿个数中
根据我们的所学知识,我们很轻松的能够想到如下的方法
- 遍历这40亿个数,时间复杂度为O(N)
- 排序(O(NlogN)),然后进行二分查找(O(logN))
但是,这个数据量是非常大的,大家想一下,40亿个不重复的无符号整数如果需要被存储起来,需要多大的空间?
一个整型需要4个字节,40亿个整型,为了方便计算,我们假设它是整型能够存放的最大值,也就是42亿9千万左右,即232,所以需要的大小为234 Byte = 224 KB = 214 MB = 24 GB = 16 GB。
所以上述的两种方法用来解决这个问题都是比较麻烦的,效率很低。在上文中,我们学习了哈希的思想,所以可以考虑使用哈希的方式来解决这个问题。
首先想到的就是直接映射,但是还是同样的问题,如果直接开辟一个整型数组的话,由于这些数据是不重复的,而且范围在无符号整数,所以需要开辟的数组的大小为16G左右,我们不可能把这个数组放进内存中。所以需要想办法优化它。注意审题,我们可以发现,这个数据只有在和不在两种状态,那么就可以考虑使用一个比特位来表示一个数据的状态,也就是说每个数据映射到一个比特位,那么这个数组的大小也就缩小了很多倍,经过计算可以得到数组大小为512MB。这种方式就是位图。
位图:就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的
2.2.2 位图的代码实现
在STL库中也实现了一个位图的容器

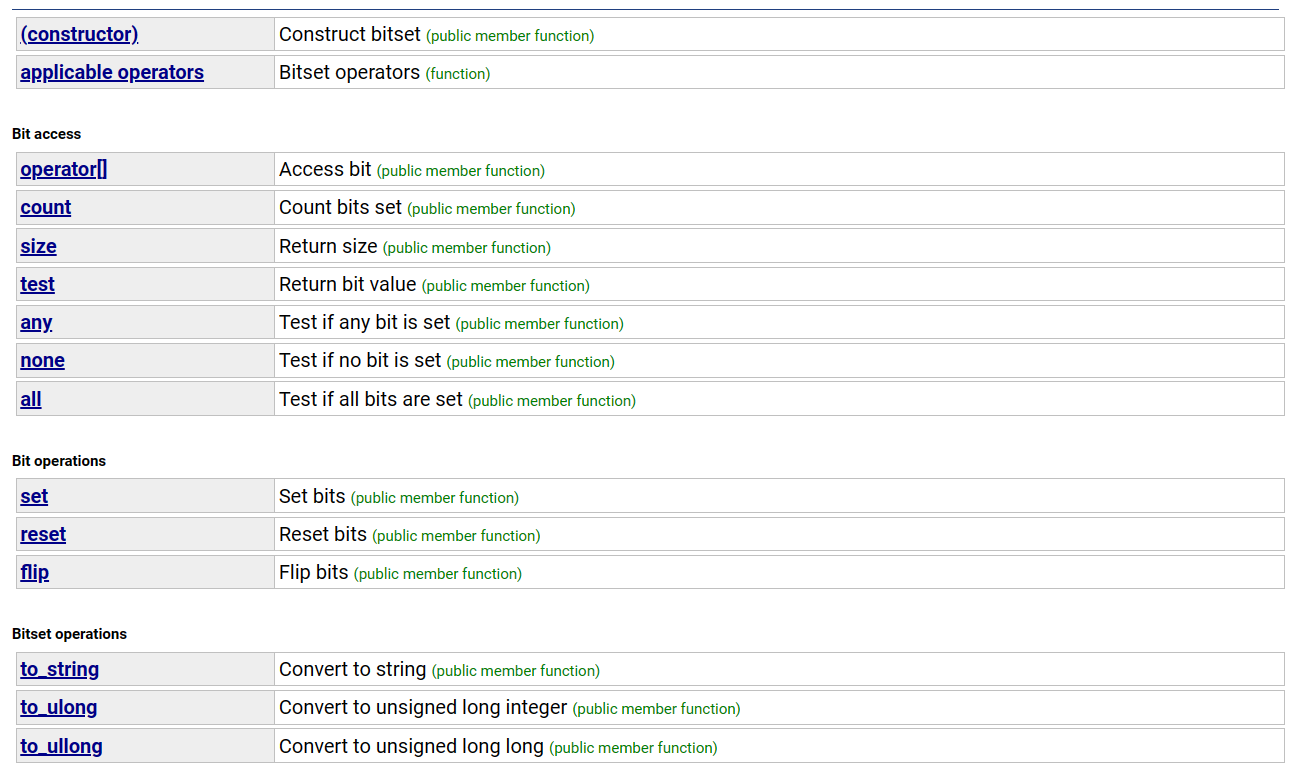
可以看到,这里有很多接口,实际上我们需要掌握的常用的接口只有一下几个
| 接口 | 说明 |
|---|---|
| void set (size_t x) | 标记x所处位置的位(值设为1) |
| void reset(size_t x) | 去除x所处位置的标记(值设为0) |
| bool test(size_t x) | 判断x是否存在(拿到x所处的位的值) |
那么现在我们模拟实现一下bitset,根据STL所提供的接口,所以这里我们尝试实现上述接口即可:
1. 结构设计
首先按照我们的设计思路,这里使用一个vector用来作为底层容器存放数据,在创建bitset类型的变量的时候,需要指定存放数据范围大小,所以这里使用一个非模板类型参数
template<size_t N>
class bitset
{
public:
//...
private:
vector<char> _bit;
};
2. 接口设计
bitset()
{
//由于底层存储使用的是vector<char>,所以一个char中可以存放8个数据,因为N需要左移3位,又因为N不一定是8的倍数,所以需要再开一个char的大小用于存储余数部分
_bit.resize((N >> 3) + 1, 0);
}
void set(size_t x)//将表示的位的值置为1
{
//i表示在第几个char中,j表示在这个char中的偏移量
int i = x / 8;
int j = x % 8;
_bit[i] |= (1 << j);
}
void reset(size_t x) // 将表示的位的值置为1
{
//i表示在第几个char中,j表示在这个char中的偏移量
int i = x / 8;
int j = x % 8;
_bit[i] &= ~(1 << j);
}
bool test(size_t x)
{
int i = x / 8;
int j = x % 8;
return _bit[i] & (1 << j);
}
2.2 布隆过滤器
虽然位图能够做到快速判断某个数是否在一个集合中,但是仍然存在一些缺点:
- 位图更适合数据范围较集中的情况:当数据范围比较分散的时候,位图需要开辟的空间会大很多,但是真正使用到的比较少,会造成空间浪费
- 位图只能针对整型家族:对于非整型类型的数据(例如字符串)不能处理。
为了解决这个问题,我们可以考虑使用哈希的思想:将字符串通过哈希转换成整型,再进行映射。但是使用哈希方法必然会遇到哈希冲突的问题,这里由于我们想要使用位图的思想,必然不能进行开散列,所以一定会出现误判的情况。
此时,布隆过滤器就诞生了。
2.2.1 布隆过滤器的概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
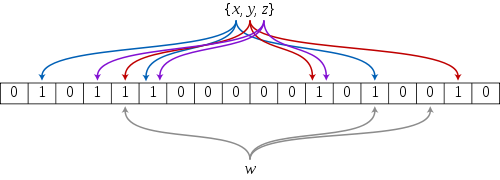
2.2.2 布隆过滤器代码实现
布隆过滤器的插入原理是通过多个哈希函数将同一个元素进行多次插入,这样就能显著的降低误判的概率。
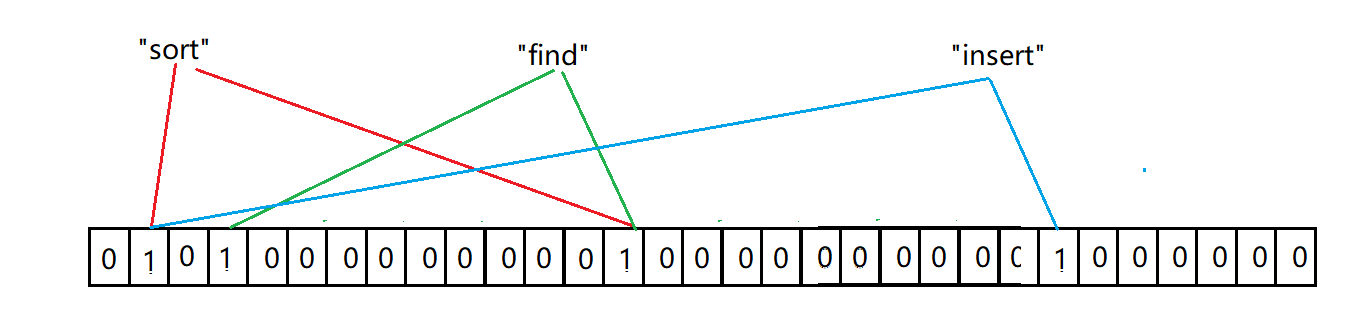
但是这种方式只能降低误判的概率,不能完全避免误判,唯一能够确认的就是有0的地方对应的一定是没有出现过的。
1. 类结构构造
布隆过滤器的插入元素可能是字符串,也可能是其他类型,只要提供对应的哈希函数将该类型的数据转换成整型就可以了。
一般情况下布隆过滤器都是用来处理字符串的,所以布隆过滤器可以实现为一个模板类,将模板参数 T 的缺省类型设置为 string:
template <size_t N, size_t X = 5, class K = string,
class HashFunc1,
class HashFunc2,
class HashFunc3>//模板参数中HashFunc的个数就是映射时哈希函数的个数
class BloomFilter
{
public:
//...
private:
bitset<N* X> _bs;
};
2. 插入
由于布隆过滤器底层使用的是bitset,因此插入可以复用
void set(const K& key)
{
//分别计算出对应的位置,然后进行将该位置的值置为1即可
size_t hash1 = HashFunc1()(key) % (N * X);
size_t hash2 = HashFunc2()(key) % (N * X);
size_t hash3 = HashFunc3()(key) % (N * X);
_bs.set(hash1);
_bs.set(hash2);
_bs.set(hash3);
}
3. 布隆过滤器的查找
通过三个哈希函数分别算出对应元素的三个哈希地址,得到对应的比特位,然后去判断这三个比特位是否都被设置成了1
如果出现一个比特位未被设置成1说明该元素一定不存在,也就是如果一个比特位为0就是false;而如果三个比特位全部都被设置,则return true表示该元素已经存在(注:可能会出现误判)
bool test(const K& key)
{
size_t hash1 = HashFunc1()(key) % (N * X);
if (!_bs.test(hash1))
return false;
size_t hash2 = HashFunc1()(key) % (N * X);
if (!_bs.test(hash2))
return false;
size_t hash1 = HashFunc3()(key) % (N * X);
if (!_bs.test(hash3))
return false;
return true;
}
4. 布隆过滤器的删除
布隆过滤器一般没有删除,因为布隆过滤器判断一个元素是会存在误判,此时无法保证要删除的元素在布隆过滤器中,如果此时将位图中对应的比特位清0,就会影响到其他元素了
为了实现删除这个目的,我们可以考虑给每个比特位加上一个计数器,当存在插入操作时,计数器++,有数据删除时,计数器--即可。
但是布隆过滤器的本来目的就是为了提高效率和节省空间,在每个比特位增加额外的计数器,空间消耗那就更多了,所以我们不考虑此方向
2.2.3 布隆过滤器的评价
优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无
关- 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
缺点
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除,可能会存在计数回绕问题
布隆过滤器参考博客:详解布隆过滤器的原理,使用场景和注意事项 - 知乎 (zhihu.com)
3. 面试题实战
3.1 哈希切割
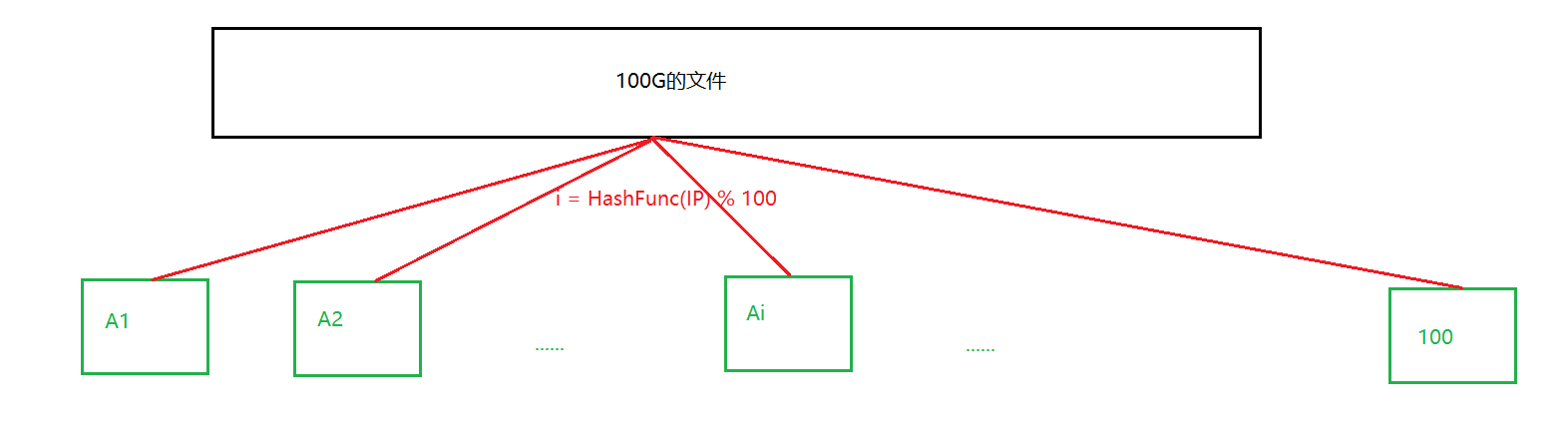
❓ 给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
✅ 找到次数这种问题,我们首先想到的就是map,但是IP地址一般是
127.0.0.1这种类型,超过100G的内容没办法放在一个map中,所以没有办法这样使用。那么我们需要做的事情就是将这内容进行切分,然后对切分的小文件进行次数统计。注意,这里的切分是有一些讲究的。如果直接对这些文件进行平均切分的话,是没有办法在一个小文件中计算出同一个IP地址出现的次数的。所以这里需要用到哈希切割。使用一个哈希函数将IP转换成整型,然后让出现哈希冲突的IP放进同一个小文件中,然后分别统计这些小文件中IP每个IP出现的次数。这种方法的巧妙之处在于利用哈希函数将所有相同的IP都放在了同一个文件中,所以统计每个小文件的时候都能够拿到当前IP出现的次数。注:可以将进行该方法之后的小文件当作一个一个的哈希桶来看。
❓如果分成的小文件也过大怎么办?
✅ 这里的小文件可以分成两种情况:
- 该文件中冲突的IP很多,大多都是不同的IP,此时直接使用map是统计不下的,对于这个问题我们的解决方案是:换一个哈希函数,再次进行切分
- 该文件的冲突IP很多,大多数都是相同的IP,此时直接使用map是可以统计的下的,直接使用map统计即可。
❓那么其实问题又来了:怎么区分这两种情况呢?
✅实际上这里不需要区分,直接使用map统计即可,如果map的insert出现报错(相当于new失败),new失败之后会抛异常,此时捕捉异常即可,然后对次异常的处理就是情况一的方案。
❓ 与上题条件相同,如何找到top K的IP?
✅ 首先进行上述的操作,然后能够得到所有IP的出现次数,然后对这个数据使用优先级队列来存放,然后popK次,所得到的就是top K的IP。
3.2 位图的应用
❓给定100亿个整数,设计算法找到只出现一次的整数?
✅首先可以明确一点,就是对于100亿个整数,数据量过于大,因此这里考虑使用位图的方式来解决。题目要求我们找到只出现一次的数,分析一下,我们需要知道的数的状态,那么这个数的出现情况,我们需要关注的只有出现0次,出现1次,出现一次以上这三种情况,那么对于我们之前设计的位图来说,这里的改变就是两个位(00,01,10)来表示一个数的状态即可。
为了代码实现的方便,我们采用构建两个位图来做这件事情,第一个位图用来表示第一个位,第二个位图表示第二个位,那么就可以简单的手搓一个两个位图结合的类
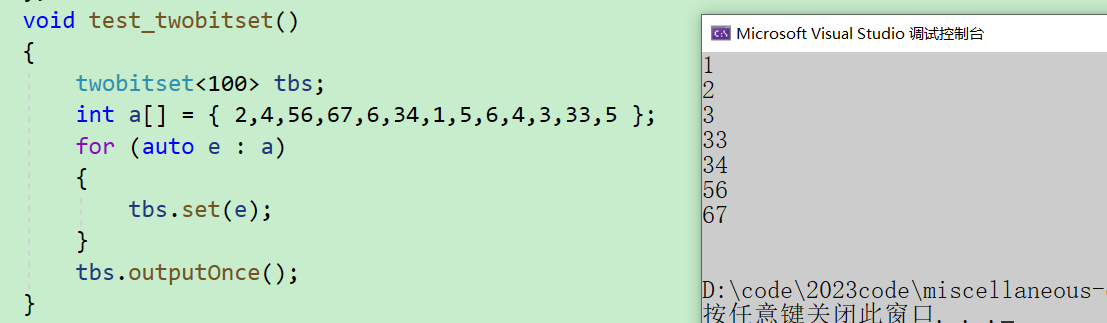
template<size_t N> class twobitset { public: void set(size_t x) { if (!_bs1.test(x) && !_bs2.test(x))//00 { _bs2.set(x);//变成01 } else if (!_bs1.test(x) && _bs2.test(x))//01 { //变成10 _bs1.set(x); _bs2.reset(x); } // 10 不变 } void outputOnce()//打印只出现一次的数 { for (size_t i = 0; i < N; ++i) { if (!_bs1.test(i) && _bs2.test(i)) { cout << i << endl; } } cout << endl; } private: bitset<N> _bs1; bitset<N> _bs2; };用这个类就可以很轻松的判断某个数是否只出现了一次,同时也实现了输出所有只出现了一次的数的接口,下面就简单写个测试函数试验一下
void test_twobitset() { twobitset<100> tbs; int a[] = { 2,4,56,67,6,34,1,5,6,4,3,33,5 }; for (auto e : a) { tbs.set(e); } tbs.outputOnce(); }
❓给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
✅拿到题目我们首先想到的就是使用位图的方式,将其中一个文件映射到位图中,然后遍历另一个文件确定在位图中是否存在。但是,对于这种方式,最终产生的结果需要进行一次去重,原因是当我们遍历的第二个文件中有重复的内容,此内容恰好又在交集中,那么此内容就将是重复的内容,因此需要对结果进行去重。
这里为了省略去重的部分,我们可以考虑使用两个位图,分别存放两个文件,然后遍历两个位图,当两个位图的某一位都是1时,此位对应的内容就是交集。
❓位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
✅看到此问题,就能立刻想到第一个问题,只是这里的有一点细微的差别就是需要找的时不超过2次的整数,那么我们的思路就是一样的,只是所对应的00表示0次,01表示1次,10表示2次,11表示3次及以上。
3.3 布隆过滤器
❓给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
✅query一般是查询指令,可能是一个网络请求,或者是一个SQL语句,这里假设平均每个query是50byte,100亿个query合计大概是500G的大小,所以这个数据量是非常巨大的。
那么我们的近似算法就能够想到使用布隆过滤器来进行操作,将两个文件分别放入到两个布隆过滤器中,然后查找相同位的值都为1的,它所对应的文件就是交集,当然由于布隆过滤器是一种概率模型,所以这里得到的只能是近似的内容。
如果要求精确算法的话,我们能够考虑到的思路就是上述3.1的第一个问题,将大文件进行哈希切割,然后拿到多个小文件,对这些小文件进行操作即可。
❓如何扩展BloomFilter使得它支持删除元素的操作
✅由于BloomFilter的插入思路是使用多个哈希函数,将值映射到多个位上,所以这里某一个位上的状态可能是多个值映射的,因此这里不能直接将要删除的值对应的哈希地址进行置0操作,这个时候我们可以考虑对每个位增加一个计数器,用来表示当前位被多少个值使用。
当然,这种方式会造成较大的空间浪费,违背了BloomFilter的初衷,所以我们是不建议对BloomFilter进行增加删除操作的。感兴趣的小伙伴可以参考一下这个博客,里面对删除进行了详细的讲解:博客链接
本章完……
ry,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法**
✅query一般是查询指令,可能是一个网络请求,或者是一个SQL语句,这里假设平均每个query是50byte,100亿个query合计大概是500G的大小,所以这个数据量是非常巨大的。
那么我们的近似算法就能够想到使用布隆过滤器来进行操作,将两个文件分别放入到两个布隆过滤器中,然后查找相同位的值都为1的,它所对应的文件就是交集,当然由于布隆过滤器是一种概率模型,所以这里得到的只能是近似的内容。
如果要求精确算法的话,我们能够考虑到的思路就是上述3.1的第一个问题,将大文件进行哈希切割,然后拿到多个小文件,对这些小文件进行操作即可。
❓如何扩展BloomFilter使得它支持删除元素的操作
✅由于BloomFilter的插入思路是使用多个哈希函数,将值映射到多个位上,所以这里某一个位上的状态可能是多个值映射的,因此这里不能直接将要删除的值对应的哈希地址进行置0操作,这个时候我们可以考虑对每个位增加一个计数器,用来表示当前位被多少个值使用。
当然,这种方式会造成较大的空间浪费,违背了BloomFilter的初衷,所以我们是不建议对BloomFilter进行增加删除操作的。感兴趣的小伙伴可以参考一下这个博客,里面对删除进行了详细的讲解:博客链接
本章完……