🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章
| 大数据分析案例-基于随机森林算法预测人类预期寿命 |
| 大数据分析案例-基于随机森林算法的商品评价情感分析 |
| 大数据分析案例-用RFM模型对客户价值分析(聚类) |
| 大数据分析案例-对电信客户流失分析预警预测 |
| 大数据分析案例-基于随机森林模型对北京房价进行预测 |
| 大数据分析案例-基于RFM模型对电商客户价值分析 |
| 大数据分析案例-基于逻辑回归算法构建垃圾邮件分类器模型 |
| 大数据分析案例-基于决策树算法构建员工离职预测模型 |
| 大数据分析案例-基于KNN算法对茅台股票进行预测 |
| 大数据分析案例-基于多元线性回归算法构建广告投放收益模型 |
| 大数据分析案例-基于随机森林算法构建返乡人群预测模型 |
| 大数据分析案例-基于决策树算法构建金融反欺诈分类模型 |
目录
1.项目背景
2.项目简介
2.1项目说明
2.2数据说明
2.3技术工具
3.算法原理
4.项目实施步骤
4.1理解数据
4.2数据预处理
4.3确定参数k
4.4训练模型
4.5聚类结果可视化
4.6模型分析
5.实验总结
源代码
1.项目背景
在当今竞争激烈的商业环境中,了解客户需求和行为对于企业的成功至关重要。通过对客户进行细分和分群分析,企业可以更好地理解客户的差异性和特点,并为不同群体的客户提供个性化的产品和服务,从而提高客户满意度和市场竞争力。
KMeans聚类算法是一种常用的无监督学习算法,广泛应用于数据挖掘和分析领域。该算法通过将数据点分配到不同的簇(群组)中,以最小化簇内数据点之间的平方距离,从而实现对数据的聚类。KMeans算法简单且高效,能够处理大规模数据集,并且结果易于解释和理解,因此在客户分群分析中得到了广泛应用。
通过应用KMeans聚类算法对客户进行分群分析,可以将客户划分为不同的群组,每个群组具有类似的特征和行为模式。这种分析可以揭示客户群体的隐藏模式和关联,帮助企业识别潜在的市场细分和目标客户群体,并制定针对性的市场策略。例如,企业可以根据不同群组的特点,设计定制化的营销活动,提供个性化的产品推荐或定价策略,以更好地满足客户需求,并提升客户忠诚度和购买力。
因此,基于KMeans聚类算法的客户分群分析具有重要的实际意义和应用前景,可以帮助企业优化市场营销策略,提升客户关系管理效果,增强竞争力,并取得商业成功。
2.项目简介
2.1项目说明
本项目旨在分析客户消费数据,找出不同类型消费者特征,使用聚类算法实现客户分群,进而实现精准营销,提高顾客满意度,增加企业创收。
2.2数据说明
本数据集来源于kaggle,原始数据集共有200条,共5条变量特征,具体变量解释如下:
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
KMeans算法是一种常用的聚类分析算法,它的原理可以简单描述如下:
-
初始化:首先选择要分成的簇的数量K,然后从数据集中随机选择K个点作为初始的聚类中心。
-
分配数据点:对于每个数据点,计算它与每个聚类中心的距离,并将数据点分配给距离最近的聚类中心所对应的簇。
-
更新聚类中心:对于每个簇,计算该簇中所有数据点的平均值(即新的聚类中心)。
-
重复步骤2和3:重复执行步骤2和3,直到聚类中心不再发生显著变化,或达到预定的迭代次数。
-
输出结果:最终得到K个簇,每个簇包含一组数据点,这些数据点具有相似的特征或属性。
KMeans算法的目标是最小化簇内数据点之间的平方距离的总和,也就是最小化簇内的方差。通过迭代的过程,KMeans算法寻找最优的聚类中心,使得每个簇内的数据点相似度最高,而不同簇之间的相似度最低。
KMeans算法的优点包括简单、易于实现和高效,适用于处理大规模数据集。然而,它也有一些限制,比如对初始聚类中心的选择敏感,对噪声和异常值比较敏感,以及需要预先指定簇的数量K等。
为了解决KMeans算法的一些限制,还有一些改进的变体算法被提出,如K-Means++、Mini-Batch KMeans和层次KMeans等,它们对初始聚类中心的选择、计算效率等方面进行了改进和优化。
具体原理可以参考文章机器学习之KMeans聚类算法原理(附案例实战)
4.项目实施步骤
4.1理解数据
首先导入本次实验用到的第三方库并加载数据

查看数据大小,数据基本信息

4.2数据预处理
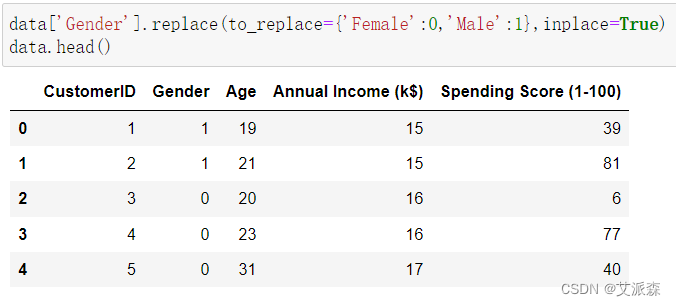
将性别列中的Female和Male用0 1 表示
4.3确定参数k
首先使用肘部法则,也就是使用损失分数来评估K的取值

接着再使用轮廓分数来确定K值,轮廓分数是用于评估该算法创建的簇的质量的方法。轮廓分数在-1到+1之间。轮廓分数越高,模型越好。轮廓分数度量同一簇中所有数据点之间的距离。这个距离越小,轮廓分数就越好。
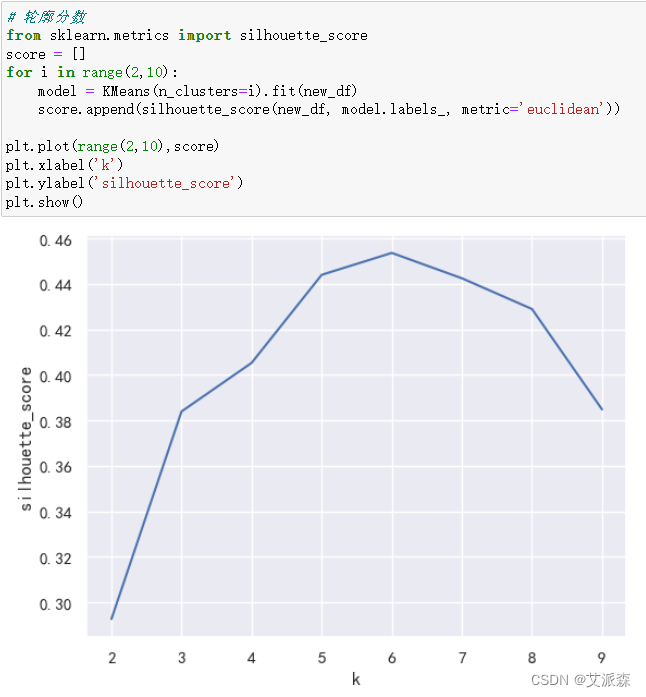
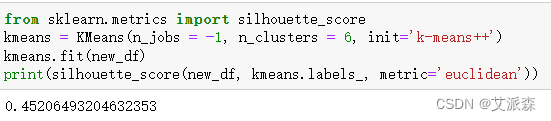
结合肘部法则和轮廓分数,最终确定最佳K值为6。
4.4训练模型
接着使用KMeans算法训练模型
4.5聚类结果可视化
将聚类结果在3d图中进行展示
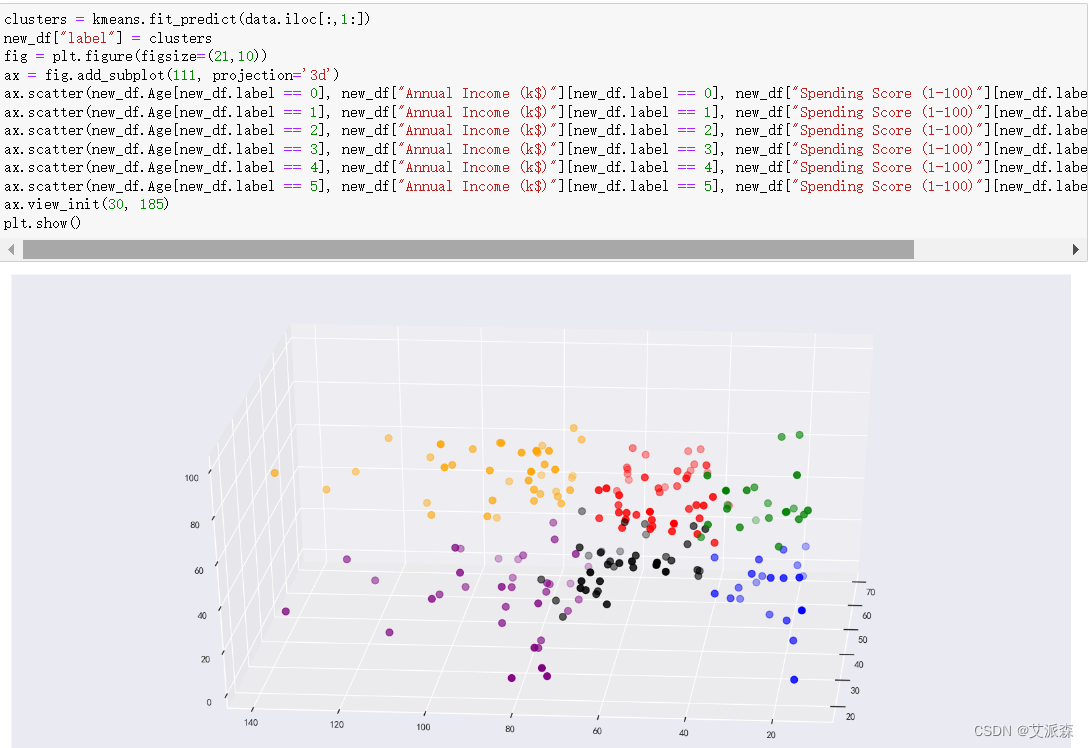
从可视化可以看出,紫色、黑色、红色交叉的较多,聚类效果一般,还有待提高。
4.6模型分析
打印各聚类便签的个数
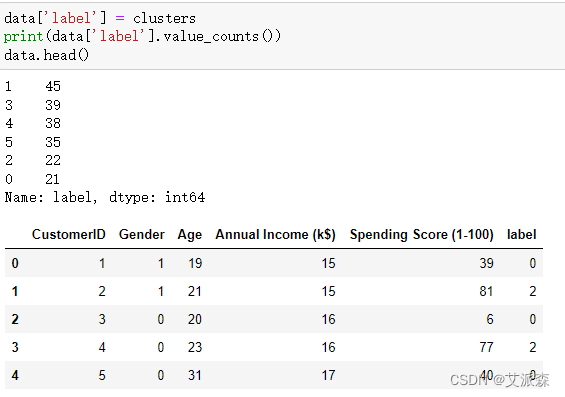
计算各类别的年龄、收入、消费均值

将上面结果可视化展示

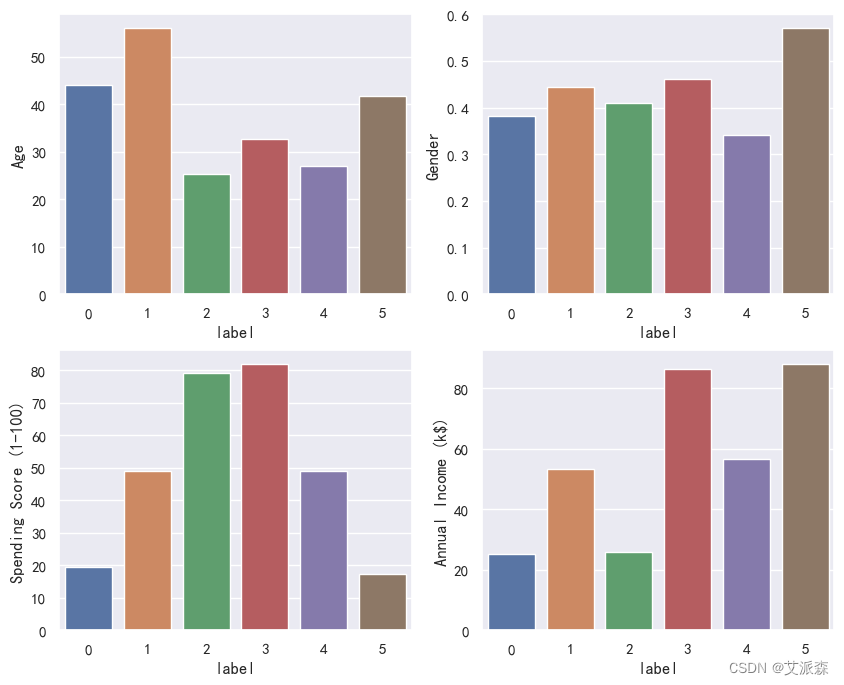
各细分市场的主要特点
簇类0:
低收入,低消费能力。
平均年龄在40岁左右,性别以女性为主。
簇类1:
中等收入,中等消费能力。
平均年龄在55岁左右,性别以女性为主。
簇类2:
低收入,高消费能力。
平均年龄在25岁左右,性别以女性为主。
簇类3:
高收入,高消费能力。
平均年龄在30岁左右,性别以女性为主。
簇类4:
中等收入,中等消费能力。
平均年龄在30岁左右,性别以女性为主。
簇类5:
高收入,低消费能力。
平均年龄在40岁左右,性别以男性为主。
针对不同群体实施不同的营销方案
簇类0: 低收入,低消费能力,平均年龄在40岁左右,性别以女性为主。 对于这个客户群,你可以提供具有良好性价比的产品或服务,以吸引他们的购买力。例如,可以提供价格实惠的基本生活用品或经济型旅游套餐。此外,可以通过折扣、促销和积分奖励等手段,鼓励他们保持忠诚度。
簇类1: 中等收入,中等消费能力,平均年龄在55岁左右,性别以女性为主。 这个客户群的消费能力相对较稳定,你可以关注他们的需求和兴趣,提供适合他们年龄段和性别的产品或服务。例如,可以推出健康养生产品、休闲娱乐活动或度假旅游线路等。此外,与该群体建立信任和亲近感的营销活动可能也会产生积极的效果。
簇类2: 低收入,高消费能力,平均年龄在25岁左右,性别以女性为主。 尽管收入较低,但这个客户群在消费能力上表现出一定的潜力。你可以提供具有时尚、个性化和实用性的产品或服务,满足他们对时尚、社交和自我表达的需求。例如,可以推出经济实惠的时尚服饰、个性化配饰或社交媒体营销活动,吸引他们的关注和消费。
簇类3: 高收入,高消费能力,平均年龄在30岁左右,性别以女性为主。 这个客户群的消费能力较高,你可以提供高端、奢侈或定制化的产品或服务,满足他们对品质和独特性的追求。例如,可以推出豪华旅游套餐、高端时尚品牌、定制化家居装饰等。同时,与该群体建立个性化的沟通和关系可能会增加他们的忠诚度。
簇类4: 中等收入,中等消费能力,平均年龄在30岁左右,性别以女性为主。 这个客户群的特点较为平衡,你可以提供中档价格但具有良好品质和实用性的产品或服务。例如,可以推出中档时尚品牌衣物、家居用品或个人护理产品等。此外,与该群体建立良好的客户关系,通过定期的促销活动和个性化推荐,可以增加他们的购买意愿。
簇类5: 高收入,低消费能力,平均年龄在40岁左右,性别以男性为主。 对于这个客户群,尽管他们拥有高收入,但消费能力有限。你可以提供高端产品或服务的体验,但注重经济实惠和实用性。例如,可以推出高质量的生活用品、奢侈品折扣活动或投资理财咨询服务。此外,针对男性客户,可以关注他们的兴趣爱好,如体育、科技或汽车等,提供相应的产品或服务。
需要注意的是,以上营销策略仅是一些建议,具体的营销方案应根据实际情况和市场调研进行定制。同时,随着市场和客户需求的变化,营销策略也需要灵活调整和优化,以保持竞争力和持续吸引不同客户群体的关注和消费。
5.实验总结
本次实验通过对企业客户数据进行分析,找出了各类型的客户特征,最后使用聚类算法对客户进行分群,模型效果还不错,但也有待提高的地方,分群之后企业应该要针对不同类型的客户采用不同的营销策略。
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font='SimHei')
import warnings
warnings.filterwarnings('ignore')
# 读取数据
data = pd.read_csv('Mall_Customers.csv')
data.head()
data.shape
data.info()
data['Gender'].replace(to_replace={'Female':0,'Male':1},inplace=True)
data.head()
from sklearn.cluster import KMeans
new_df = data.drop('CustomerID',axis=1)
# 肘部法则
loss = []
for i in range(2,10):
model = KMeans(n_clusters=i).fit(new_df)
loss.append(model.inertia_)
plt.plot(range(2,10),loss)
plt.xlabel('k')
plt.ylabel('loss')
plt.show()
# 轮廓分数
from sklearn.metrics import silhouette_score
score = []
for i in range(2,10):
model = KMeans(n_clusters=i).fit(new_df)
score.append(silhouette_score(new_df, model.labels_, metric='euclidean'))
plt.plot(range(2,10),score)
plt.xlabel('k')
plt.ylabel('silhouette_score')
plt.show()
from sklearn.metrics import silhouette_score
kmeans = KMeans(n_jobs = -1, n_clusters = 6, init='k-means++')
kmeans.fit(new_df)
print(silhouette_score(new_df, kmeans.labels_, metric='euclidean'))
clusters = kmeans.fit_predict(data.iloc[:,1:])
new_df["label"] = clusters
fig = plt.figure(figsize=(21,10))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(new_df.Age[new_df.label == 0], new_df["Annual Income (k$)"][new_df.label == 0], new_df["Spending Score (1-100)"][new_df.label == 0], c='blue', s=60)
ax.scatter(new_df.Age[new_df.label == 1], new_df["Annual Income (k$)"][new_df.label == 1], new_df["Spending Score (1-100)"][new_df.label == 1], c='red', s=60)
ax.scatter(new_df.Age[new_df.label == 2], new_df["Annual Income (k$)"][new_df.label == 2], new_df["Spending Score (1-100)"][new_df.label == 2], c='green', s=60)
ax.scatter(new_df.Age[new_df.label == 3], new_df["Annual Income (k$)"][new_df.label == 3], new_df["Spending Score (1-100)"][new_df.label == 3], c='orange', s=60)
ax.scatter(new_df.Age[new_df.label == 4], new_df["Annual Income (k$)"][new_df.label == 4], new_df["Spending Score (1-100)"][new_df.label == 4], c='black', s=60)
ax.scatter(new_df.Age[new_df.label == 5], new_df["Annual Income (k$)"][new_df.label == 5], new_df["Spending Score (1-100)"][new_df.label == 5], c='purple', s=60)
ax.view_init(30, 185)
plt.show()
data['label'] = clusters
print(data['label'].value_counts())
data.head()
avg_df = data.groupby(['label'], as_index=False).mean()
avg_df
plt.figure(figsize=(10,8))
plt.subplot(2,2,1)
sns.barplot(x='label',y='Age',data=avg_df)
plt.subplot(2,2,2)
sns.barplot(x='label',y='Gender',data=avg_df)
plt.subplot(2,2,3)
sns.barplot(x='label',y='Spending Score (1-100)',data=avg_df)
plt.subplot(2,2,4)
sns.barplot(x='label',y='Annual Income (k$)',data=avg_df)
plt.show()