2022年Python面试题汇总【常问】
- 1、请你讲讲python获取输入的方式,以及python如何打开文件
- 2、Python数据处理的常用函数
- 3、请你说说python传参传引用
- 4、请你说说python和java的区别
- 5、Python你常用的包有哪些?
- 6、简单说明如何选择正确的Python版本。
- 7、简述python是如何进行内存管理的。
- 8、请你简要介绍一下python的生成器是什么
- 9、Python的list和numpy的array有什么区别
- 10、如何在Python中实现多线程?
- 11、请说明一下python中is和==的区别
- 12、什么是python的生成器?
- 13、Python异常处理结构有哪几种形式?
- 14、简单解释Python的字符串驻留机制。
- 15、简单解释Python中以下划线开头的变量名特点。
- 16、在Python中导入模块中的对象有哪几种方式?
- 17、使用pdb模块进行Python程序调试主要有哪几种用法?
- 18、在python的类的方法定义中,请描述'self'参数的作用?
- 19、在Python程序中,局部变量会隐藏同名的全局变量吗?请编写代码进行验证。
- 20、解释Python脚本程序的“__name__”变量及其作用。
- 21、Python解释“re”模块的 split(), sub(), subn()方法。
- 22、用Python编写一个函数,获得当前目录下的所有文件名(包含子目录中的子文件,假设当前用户有所有文件的访问权限)
- 23、解释 Python 中的运算符 “/” 和 “//” 的区别。
- 24、在Python 2.7中,执行下列语句后的显示结果是什么?
- 25、在Python 2.7中,执行下列语句后,显示结果是什么?
🏠个人主页:@编程ID
🧑个人简介:大家好,我是编程ID,一个想要与大家共同进步的程序员儿🧑如果各位哥哥姐姐在准备面试,找工作,刷算法,前后端编程题选择题都有,可以使用我找工作前用的刷题神器哦!刷题神器点这里哟🎁检测自己的学习程度,提升自己都不错呢!
💕欢迎大家:这里是CSDN,我总结知识的地方,欢迎来到我的博客,望能帮到各位想要找工作或者提高自己的小伙伴儿们,如果有什么需要改进的地方,还请大佬不吝赐教🤞🤞
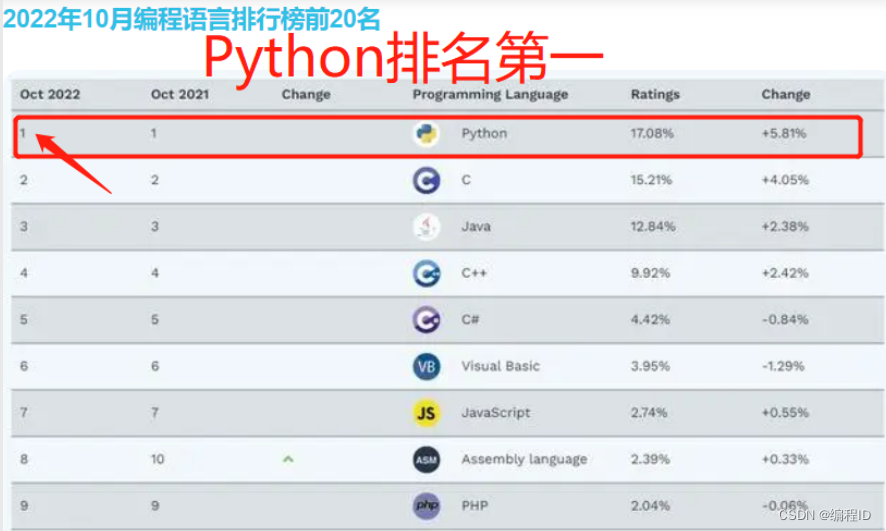
⭐️相信大家也知道Python近年来的热度一直稳居前列,今天分享一篇Python的知识点,喜欢的宝子们点赞👍收藏 🌟哦!
【建议收藏文章】
Python知识点手册下载
1、请你讲讲python获取输入的方式,以及python如何打开文件
获取输入用input()接收 文件打开方式:①file =open(‘文件名’,‘打开方式’)最后读写完需要用file.close()关闭文件,且有可能会有异常抛出 ②用with: with open(‘文件名’,打开方式)as f:比较方便,不需要再进行关闭文件和担心异常的问题,with都封装好了,建议使用这种方式打开文件
2、Python数据处理的常用函数
数据处理主要用的就是pandas里面的函数。 去重:drop_duplicates() 填充缺失值:fillna() 处理某列:apply(), lambda函数 替换函数:replace()
3、请你说说python传参传引用
[参考回答] Python中对象与对象之间的传递分为两种。 第一种是引用传递,对于可变的数据类型数组、字典、集合的传递是引用传递。比如a是一个数组,b=a,现在修改b,b.clear(),那么原数组a也将被清空。 第二种是只传递,对于不可变的数据类型数字、字符、元组的传递就是值传递。比如a是一个数字,b=a,现在修改b,b=0,那么原数字a并不会改变。
4、请你说说python和java的区别
- 1、运行方式而言,Python是解释型语言,java是编译型语言
- 2、面向对象而言,虽然都是面向对象语言,但是java是纯面向对象的,所有java程序都是基于类,而Python则灵活一些,可以单独写个函数,就可以运行
- 3、java是强数据类型语言,Python是弱数据类型语言,也就是java定义变量必须明确数据类型,好开辟对应的内存空间,Python是传啥数据类型就是啥数据类型跟node.js类似
- 4、个人感觉:由于java是纯面向对象的,所以就面向对象的理解上来说,java面向对象的语法跟容易理解,例如java做的抽象类,接口这些很容易理解,做的也更好一些;
- 5、Python是支持多重继承,java是单继承
- 6、java支持switch语法和三目运算,Python不支持
- 7、java跟接近底层,所以执行效率高,Python由于更抽象,则是编程效率高,代码更简洁
【建议收藏文章】
5、Python你常用的包有哪些?
numpy,用来做多维数组的运算的,之前在xx项目中用numpy做一些数据运算的工作。 pandas,用来处理表格和复杂数据的,我主要用它在数据清洗这一步。 matplotlib,用来数据可视化,在对处理好的数据我想简单看一下频数分布或者相关性之类的很轻松的可以画出图片。 sklearn,用户机器学习建模,在数据建模这部分用到,我经常用的模型有随机森林和xgb(引导面试官问这两者的区别)。
答案解析 用过的包+用途+用这个做了什么
6、简单说明如何选择正确的Python版本。
在选择Python的时候,一定要先考虑清楚自己学习Python的目的是什么,打算做哪方面的开发,有哪些扩展库可用,这些扩展库最高支持哪个版本的Python,是Python 2.x还是Python 3.x,最高支持到Python 2.7.6还是Python 2.7.9。这些问题都确定以后,再做出自己的选择,这样才能事半功倍,而不至于把大量时间浪费在Python的反复安装和卸载上。同时还应该注意,当更新的Python版本推出之后,不要急于更新,而是应该等确定自己所必须使用的扩展库也推出了较新版本之后再进行更新。
尽管如此,Python 3毕竟是大势所趋,如果您暂时还没想到要做什么行业领域的应用开发,或者仅仅是为了尝试一种新的、好玩的语言,那么请毫不犹豫地选择Python 3.x系列的最高版本(目前是Python 3.4.3)。
7、简述python是如何进行内存管理的。
参考答案:从三个方面来说,一对象的引用计数机制,二垃圾回收机制,三内存池机制
①对象的引用计数机制
Python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数。数情况下,引用计数比你猜测得要大得多。对于不可变数据(如数字和字符串),解释器会在程序的不同部分共享内存,以便节约内存。
②垃圾回收
当一个对象的引用计数归零时,它将被垃圾收集机制处理掉。
当两个对象a和b相互引用时,del语句可以减少a和b的引用计数,并销毁用于引用底层对象的名称。然而由于每个对象都包含一个对其他对象的应用,因此引用计数不会归零,对象也不会销毁。(从而导致内存泄露)。为解决这一问题,解释器会定期执行一个循环检测器,搜索不可访问对象的循环并删除它们。
③内存池机制
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
Pymalloc机制。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的malloc。
对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
8、请你简要介绍一下python的生成器是什么
python生成器是一个返回可以迭代对象的函数,可以被用作控制循环的迭代行为。生成器类似于返回值为数组的一个函数,这个函数可以接受参数,可以被调用,一般的函数会返回包括所有数值的数组,生成器一次只能返回一个值,这样消耗的内存将会大大减小。
9、Python的list和numpy的array有什么区别
- 1.list可以存放不同类型的数据,比如int、float和str,甚至布尔型;而一个numpy数组中存放的数据类型必须全部相同,例如int或float。
- 2.在索引方式上,numpy.array支持比list更多的索引方式。
10、如何在Python中实现多线程?
-
答: Python有一个multi-threading包,但是如果你想让multi-thread加速你的代码,那么使用它通常不是一个好主意。
-
Python有一个名为Global Interpreter Lock(GIL)的结构。 GIL确保只有一个“线程”可以在任何时候执行。一个线程获取GIL,做一点工作,然后将GIL传递到下一个线程。
-
这种情况很快发生,因此对于人眼看来,您的线程似乎并行执行,但它们实际上只是轮流使用相同的CPU核心。
所有这些GIL传递都增加了执行的开销。这意味着如果您想让代码运行得更快,那么使用线程包通常不是一个好主意。
【建议收藏文章】
11、请说明一下python中is和==的区别
is是用来判断两个变量引用的对象是否为同一个,==用于判断引用对象的值是否相等。可以通过id()函数查看引用对象的地址。
12、什么是python的生成器?
python生成器是一个返回可以迭代对象的函数,可以被用作控制循环的迭代行为。生成器类似于返回值为数组的一个函数,这个函数可以接受参数,可以被调用,一般的函数会返回包括所有数值的数组,生成器一次只能返回一个值,这样消耗的内存将会大大减小。
13、Python异常处理结构有哪几种形式?
比较常用的形式有:
(1)标准异常处理结构
try:
try块 #被监控的语句,可能会引发异常
except Exception[, reason]:
except块 #处理异常的代码
如果需要捕获所有异常时,可以使用BaseException,代码格式如下:
try:
……
except BaseException, e:
except块 #处理所有错误
上面的结构可以捕获所有异常,尽管这样做很安全,但是一般并不建议这样做。对于异常处理结构,一般的建议是尽量显式捕捉可能会出现的异常并且有针对性地编写代码进行处理,因为在实际应用开发中,很难使用同一段代码去处理所有类型的异常。当然,为了避免遗漏没有得到处理的异常干扰程序的正常执行,在捕捉了所有可能想到的异常之后,您也可以使用异常处理结构的最后一个except来捕捉BaseException。
(2)另外一种常用的异常处理结构是try…except…else…语句。
(3)在实际开发中,同一段代码可能会抛出多个异常,需要针对不同的异常类型进行相应的处理。为了支持多个异常的捕捉和处理,Python提供了带有多个except的异常处理结构,这类似于多分支选择结构,一旦某个except捕获了异常,则后面剩余的except子句将不会再执行。语法为:
try:
try块 #被监控的语句
except Exception1:
except块1 #处理异常1的语句
except Exception2:
except块2 #处理异常2的语句
(4)将要捕获的异常写在一个元组中,可以使用一个except语句捕获多个异常,并且共用同一段异常处理代码,当然,除非确定要捕获的多个异常可以使用同一段代码来处理,并不建议这样做。
(5)最后一种常用的异常处理结构是try…except…finally…结构。在该结构中,finally子句中的内存无论是否发生异常都会执行,常用来做一些清理工作以释放try子句中申请的资源。语法如下:
try:
……
finally:
… #无论如何都会执行的代码
14、简单解释Python的字符串驻留机制。
Python支持字符串驻留机制,即:对于短字符串,将其赋值给多个不同的对象时,内存中只有一个副本,多个对象共享该副本。这一点不适用于长字符串,即长字符串不遵守驻留机制,下面的代码演示了短字符串和长字符串在这方面的区别。
复制代码
>>> a = '1234'
>>> b = '1234'
>>> id(a) == id(b)
True
>>> a = '1234'*50
>>> b = '1234'*50
>>> id(a) == id(b)
False
15、简单解释Python中以下划线开头的变量名特点。
在Python中,以下划线开头的变量名有特殊的含义,尤其是在类的定义中。用下划线作为变量前缀和后缀来表示类的特殊成员:
_xxx:这样的对象叫做保护变量,不能用’from module import *'导入,只有类对象和子类对象能访问这些变量;
xxx:系统定义的特殊成员名字;
__xxx:类中的私有成员,只有类对象自己能访问,子类对象也不能访问到这个成员,但在对象外部可以通过“对象名._类名__xxx”这样的特殊方式来访问。Python中没有纯粹的C++意义上的私有成员。
16、在Python中导入模块中的对象有哪几种方式?
常用的有三种方式,分别为
import 模块名 [as 别名]
from 模块名 import 对象名[ as 别名]
from math import *
17、使用pdb模块进行Python程序调试主要有哪几种用法?
主要有三种方式,
(1)在交互模式下使用pdb模块提供的功能可以直接调试语句块、表达式、函数等多种脚本。
(2)在程序中嵌入断点来实现调试功能
在程序中首先导入pdb模块,然后使用pdb.set_trace()在需要的位置设置断点。如果程序中存在通过该方法调用显式插入的断点,那么在命令提示符环境下执行该程序或双击执行程序时将自动打开pdb调试环境,即使该程序当前不处于调试状态。
(3)使用命令行调试程序
在命令行提示符下执行“python –m pdb 脚本文件名”,则直接进入调试环境;当调试结束或程序正常结束以后,pdb将重启该程序。
18、在python的类的方法定义中,请描述’self’参数的作用?
self在Python里不是关键字。self代表当前对象的地址。
self能避免非限定调用造成的全局变量。
self在定义时需要定义,但是在调用时会自动传入。
self的名字并不是规定死的,但是最好还是按照约定是用self
self总是指调用时的类的实例
19、在Python程序中,局部变量会隐藏同名的全局变量吗?请编写代码进行验证。
会。
>>> def demo():
a=3
print a
>>> a=5
>>> demo()
3
>>> a
5
20、解释Python脚本程序的“name”变量及其作用。
每个Python脚本在运行时都有一个“name”属性。如果脚本作为模块被导入,则其“name”属性的值被自动设置为模块名;如果脚本独立运行,则其“name”属性值被自动设置为“main”。利用“name”属性即可控制Python程序的运行方式。
21、Python解释“re”模块的 split(), sub(), subn()方法。
要修改字符串,Python的“re”模块提供了3种方法。他们是:
· split() - 使用正则表达式将“split”给定字符串放入列表中。
· sub() - 查找正则表达式模式匹配的所有子字符串,然后用不同的字符串替换它们
· subn() - 它类似于 sub(),并且还返回新字符串和替换的序号。
22、用Python编写一个函数,获得当前目录下的所有文件名(包含子目录中的子文件,假设当前用户有所有文件的访问权限)
参考答案:两种思路
①os类的使用,文件及文件夹的判断,文件路径的处理
os.listdir()
os.path.join()
os.path.isdir()判断传入的文件是否为文件夹
②用commands等第三方包调用shell命令(find)
23、解释 Python 中的运算符 “/” 和 “//” 的区别。
在Python 2.x中,“/”为普通除法,当两个数值对象进行除法运算时,最终结果的精度与操作数中精度最高的一致;在Python 3.x中,“/”为真除法,与除法的数学含义一致。
在Python 2.x和Python 3.x中,“//”表示整除,对整数或浮点数进行该运算时,结果为数学除法的整数部分。
24、在Python 2.7中,执行下列语句后的显示结果是什么?
a = 1
b = 2 * a / 4
a = "none"
print a,b
none 0
25、在Python 2.7中,执行下列语句后,显示结果是什么?
from __future__ importdivision
print 1//2, 1/2
0 0.5
【建议收藏文章】
结束语 🥇🥇🥇
发现非常好用的一个刷题网站,可以检测大家的基础!大家一起努力!加油!!!
包含数据库、Java、C++、C、Python、前端等等题目,难度可以自行选择
在线编程出答案,(也可自行查看答案),也有选择题,非常方便
程序员刷题神器网站点击链接注册即可刷题
祝大家早日找到满意的工作!

![[附源码]JAVA毕业设计社区生活超市管理系统(系统+LW)](https://img-blog.csdnimg.cn/059b0fc131f34d8aac06848d6e8014f1.png)
![[附源码]Python计算机毕业设计SSM计算机学院课程设计管理系统(程序+LW)](https://img-blog.csdnimg.cn/145a2059650c4ae3886217ceb278088d.png)