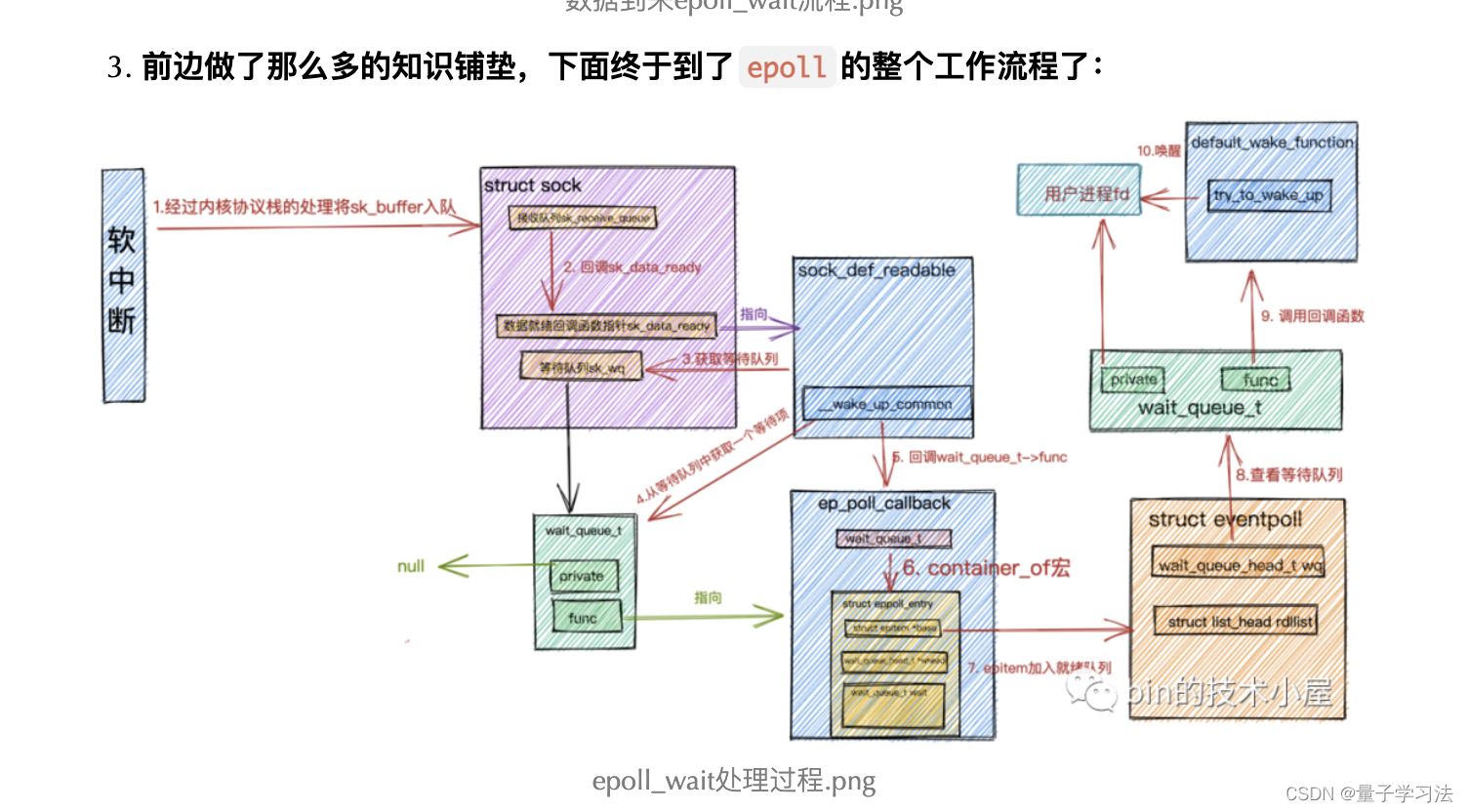
网络配置在后台迅速完成,但让我们退后一步,尝试理解为什么运行容器需要上述动作?在 Linux 中,网络命名空间是独立的、隔离的逻辑空间,可以将网络命名空间视为,将物理网络接口分割小块之后的独立部分,每个部分都可以单独配置,并拥有自己的网络规则和资源,这些包括防火墙规则、接口(虚拟的或物理的)、路由以及与网络相关的所有内容。
物理网络接口持有根网络命名空间:
也可以使用 Linux 网络命名空间来创建独立的网络,每个网络都是独立的,除非进行配置,默认不会与其他网络互通:
但最终,还是需要物理接口处理所有真实的数据包,所有虚拟接口都是基于物理接口创建的。网络命名空间可以通过 ip-netns 进行管理,使用 ip netns list 可以列出主机上的命名空间。
$ ip netns exec cni-0f226515-e28b-df13-9f16-dd79456825ac ip a
# output truncated
3: eth0@if12:<BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 16:a4:f8:4f:56:77 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.244.4.40/32 brd 10.244.4.40 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::14a4:f8ff:fe4f:5677/64 scope link
valid_lft forever preferred_lft forever
这个 IP 就是 Pod 的 IP 地址!通过查找 @if12 中的 12 找到网络接口
$ ip link | grep -A1^1212: vethweplb3f36a0@if16: mtu 1376 qdisc noqueue master weave state UP mode DEFAULT group default
link/ether 72:1c:73:d9:d9:f6 brd ff:ff:ff:ff:ff:ff link-netnsid 1
还可以验证 Nginx 容器是否监听了来自该命名空间内的 HTTP 流量:
$ ip netns exec cni-0f226515-e28b-df13-9f16-dd79456825ac netstat -lnp
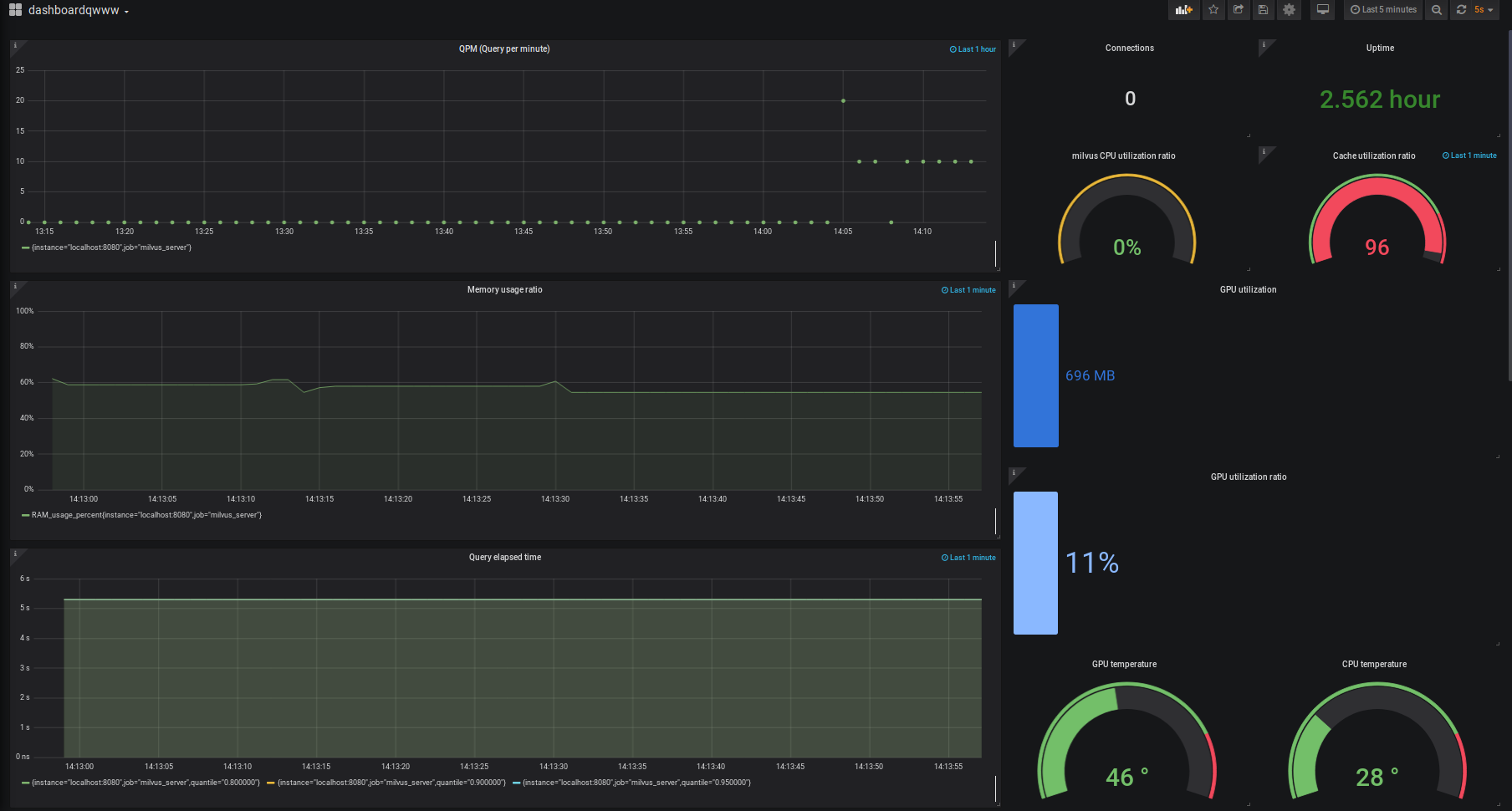
ActiveInternetconnections(only servers)ProtoRecv-QSend-QLocalAddressForeignAddressStatePID/Program name
tcp 000.0.0.0:800.0.0.0:*LISTEN692698/nginx: master
tcp6 00:::80:::*LISTEN692698/nginx: master
整个工作流依赖于虚拟接口对和网桥,为了让一个 Pod 与其他 Pod 通信,它必须先访问节点的根命名空间。通过虚拟以太网对来实现 Pod 和根命名空间的连接,这些虚拟接口设备(veth 中的 v)连接并充当两个命名空间之间的隧道,使用此 veth 设备,你将一端连接到 Pod 的命名空间,另一端连接到根命名空间。
CNI 可以执行这些操作,但也可以手动执行:
$ ip link add veth1 netns Pod-namespace typeveth peer veth2 netns root
现在 Pod 的命名空间有一个可以访问根命名空间的隧道,节点上新建的每一个 Pod 都会设置这样的 veth 对,一个是创建接口对,另一个是为以太网设备分配地址并配置默认路由。
如下所示,在 Pod 的命名空间中设置 veth1 接口:
$ ip netns exec cni-0f226515-e28b-df13-9f16-dd79456825ac ip addr add 10.244.4.40/24 dev veth1
$ ip netns exec cni-0f226515-e28b-df13-9f16-dd79456825ac ip link set veth1 up
$ ip netns exec cni-0f226515-e28b-df13-9f16-dd79456825ac ip route add default via 10.244.4.40
在节点上,创建另一个 veth2 对:
$ ip addr add 169.254.132.141/16 dev veth2
$ ip link set veth2 up
可以像前面一样检查现有的 veth 对,在 Pod 的命名空间中,检索 eth0 接口的后缀:
$ ip netns exec cni-0f226515-e28b-df13-9f16-dd79456825ac ip link show typeveth3: eth0@if12:<BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default
link/ether 16:a4:f8:4f:56:77 brd ff:ff:ff:ff:ff:ff link-netnsid 0
在这种情况下,可以使用命令 grep -A1 ^12 查找(或滚动到目标所在处):
$ ip link show typeveth
# output truncated
12: cali97e50e215bd@if3:<BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-0f226515-e28b-df13-9f16-dd79456825ac
也可以使用 ip -n cni-0f226515-e28b-df13-9f16-dd79456825ac link show type veth.命令。
需要注意: 3: eth0@if12和12: cali97e50e215bd@if3 接口上的符号,从 Pod 命名空间,该 eth0 接口连接到根命名空间的 12 号接口,因此是 @if12。在 veth 对的另一端,根命名空间连接到 Pod 命名空间的 3 号接口,接下来是连接 veth 对两端的桥接器。
六、Pod 网络命名空间连接到以太网桥
网桥会汇聚位于根命名空间中的每一个虚拟接口,这个网桥允许虚拟 pair 之间的流量,也允许穿过公共根命名空间的流量。其相关的原理是:以太网桥位于 OSI 网络模型 的第 2 层,可以将网桥视为接受来自不同命名空间和接口的连接的虚拟交换机,以太网桥可以连接节点上的多个可用网络。
因此,可以使用网桥连接两个接口,即 Pod 命名空间的 veth 连接到同一节点上另一个 Pod 的 veth:
由于 Pod 在 Kubernetes 中是动态的,分配给 Pod 的 IP 地址不是静态的,Pod 的 IP 是短暂的,每次创建或删除 Pod 时都会发生变化。Kubernetes 中的 Service 解决了这个问题,为连接一组 Pod 提供了可靠的机制:
默认情况下,在 Kubernetes 中创建 Service 时,被分配一个虚拟 IP。在 Service 中,可以使用选择器将 Service 与目标 Pod 相关联。当删除或添加一个 Pod 时会发生什么呢?Service 的虚拟 IP 保持静态不变。但流量可以再无需干预的情况下,到达新创建的 Pod。换句话说,Kubernetes 中的 Service 类似于负载均衡器,但它们是如何工作的呢?
十二、使用 Netfilter 和 Iptables 拦截和重写流量
Kubernetes 中的 Service 是基于 Linux 内核中的两个组件构建的:网络过滤器和iptables。Netfilter 是一个可以配置数据包过滤、创建 NAT 、端口转发规则以及管理网络中流量的框架。此外,它可以屏蔽和禁止未经同意的访问。另一方面,iptables 是一个用户态程序,可以用来配置 Linux 内核防火墙的 IP 数据包过滤规则。