大家好,在当今数据驱动的世界中,将信息可视化到地图上可以提供有价值的见解,帮助有效地传达复杂的模式。GeoPandas是一个建立在pandas和shapely之上的Python库,使用户能够通过将地理空间数据与各种变量合并来创建令人惊叹的地图。在本文中,我们将使用在印度卡纳塔克邦绘制变量地图的示例来探索GeoPandas的功能。最终,你将具备使用丰富数据叠加创建自己令人印象深刻的地图的知识。
GeoPandas是GeoPandas是一个强大的库,通过添加地理空间数据类型和操作扩展了pandas的功能。它允许我们处理空间数据,如shapefiles,并执行合并、连接和绘图等空间操作。
1.设置环境
在开始之前,请确保你已经在Python环境中安装了GeoPandas及其依赖项。你可以使用pip或conda安装GeoPandas,包括pandas和matplotlib在内的依赖项将会自动安装。
pip install geopandas2.获取Shapefile
在演示中,使用从KGIS网站获取的卡纳塔克邦州的shapefile,其包含空间要素的几何和属性数据。
3.加载和探索Shapefile
使用GeoPandas,我们可以将卡纳塔克邦的shapefile加载到一个GeoDataFrame中,这实际上是一个带有几何列的pandas DataFrame。几何列存储了shapefile中每个要素的空间信息。
# 导入GeoPandas库
import geopandas as gpd
# 加载shapefile
gdf_districts = gpd.read_file('District.shp')
数据帧
4.绘制地图
使用GeoPandas,创建基本地图就像在GeoDataFrame上调用plot()函数一样简单。这将生成卡纳塔克邦边界的可视化表示。
# 绘制地图
gdf_districts.plot()
5.将数据与地图合并
要将数据变量添加到我们的地图中,我们需要将GeoDataFrame与包含我们要可视化的变量的另一个DataFrame合并。这个合并过程通常使用一个共同的标识符,比如独特的地理代码或名称来完成。
# 数据将在地图中被可视化
import pandas as pd
df = pd.read_excel("dist_population.xlsx")
人口数据
我们可以看到我们需要两个数据帧gdf_districts和df,其中有一个共同的列,即区名,但在两个数据帧中,区名的命名方式不同,因此我们将在merge()函数中传递left_on='KGISDist_1'和right_on='District Name'参数并执行left join。
# 将shapefile与districts相关的varibale进行合并
# KGISDist_1是我们在gdf_districts数据框架中的地区名称
# District是我们在df数据框架中的地区名称
gdf_merged = gdf_districts.merge(df, left_on='KGISDist_1', right_on='District Name', how='left')合并后,我们可以看到两个新列出现在末尾District Name和Population。
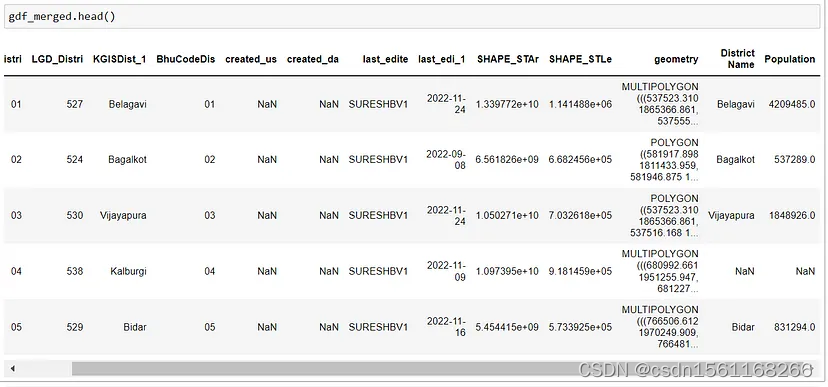
合并后的数据帧
6.在地图上绘制变量数据
一旦数据合并,就可以利用GeoPandas的功能在地图上绘制变量。通过选择适当的颜色调色板、图例和标签,可以增强视觉表现效果,将地图变得更加易于阅读和理解,有效地传达有意义的信息。
import matplotlib.pyplot as plt
from matplotlib import colors
import numpy as np
# 定义颜色比例尺
cmap = plt.cm.get_cmap('YlOrRd') # Red to green colormap (reversed)
cmap.set_bad('white') # Set NaN values to white
normalize = colors.Normalize(vmin=gdf_merged['Population'].min(), vmax=gdf_merged['Population'].max())
# 绘制地图
fig, ax = plt.subplots(figsize=(10, 10))
gdf_districts.plot(ax=ax, facecolor='none', edgecolor='black', linewidth=0.8) # Plot the district outlines
# 根据人口数量填充颜色
infes_values = gdf_merged['Population'].fillna(np.nanmin(gdf_merged['Population']) - 1) # Replace NaN values with a value lower than min
gdf_districts.plot(ax=ax, column=infes_values, cmap=cmap, linewidth=0, legend=False)
# 添加区域标签
for x, y, label in zip(gdf_merged.geometry.centroid.x, gdf_merged.geometry.centroid.y, gdf_merged['KGISDist_1']):
ax.text(x, y, label, fontsize=8, ha='center', va='center')
# 设置图表标题和轴标签
ax.set_title('Population in Karnataka Districts')
ax.set_xlabel('Longitude')
ax.set_ylabel('Latitude')
# 创建并添加颜色条
sm = plt.cm.ScalarMappable(cmap=cmap, norm=normalize)
sm.set_array([])
cbar = fig.colorbar(sm)
cbar.set_label('Population')
# 显示图表
plt.show()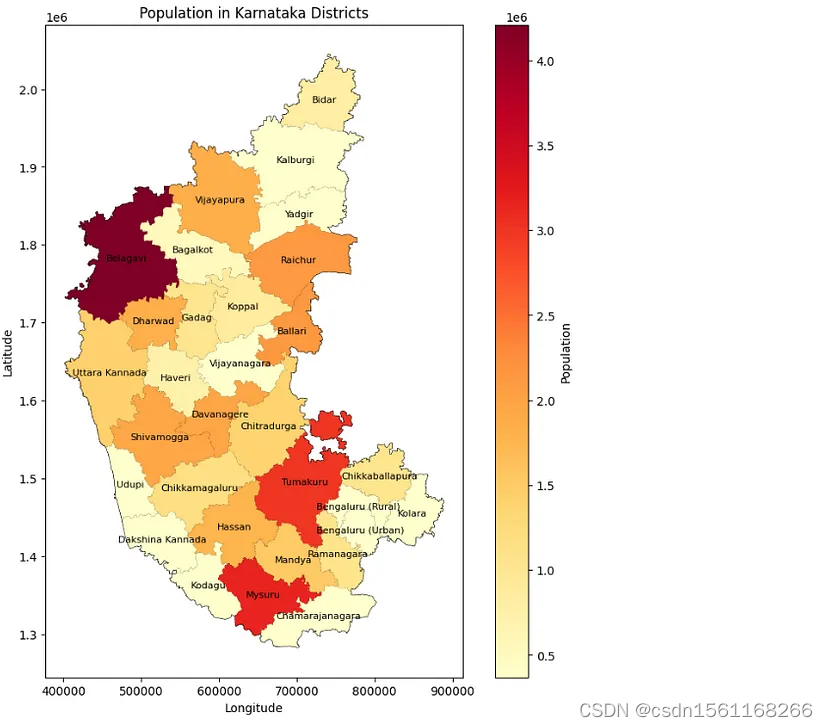
如图所示人口众多的班加罗尔在地图上看起来像消失了。因为班加罗尔在gdf_districts中被分为“班加罗尔(城市)”和“班加罗尔(乡村)”。但当合并区域时,合并函数有点混乱,在另一个数据帧中找不到完美匹配,这就是矩阵中产生的故障。
GeoPandas提供了各种自定义选项,使你的地图在视觉上更加吸引人。你可以调整颜色、应用主题样式、添加标签和包含其他元素,以提高地图的美学效果和清晰度。
总结
GeoPandas是一个多功能的库,使用户能够通过将地理空间数据与各种变量合并创建令人惊叹的地图。在本文中,我们探讨了使用GeoPandas在印度卡纳塔克邦地图上绘制变量的过程。通过遵循这里概述的步骤,你可以释放地理空间数据可视化的力量,并轻松创建自己引人入胜的地图。所以,继续探索各种可能性,让你的地图通过数据讲述引人入胜的故事。
请记住,GeoPandas的潜力远远超过这个例子。它可以用于分析和可视化来自不同领域的空间数据,使你能够发现隐藏的模式、了解各种关系并根据基于位置的洞见做出明智的决策。