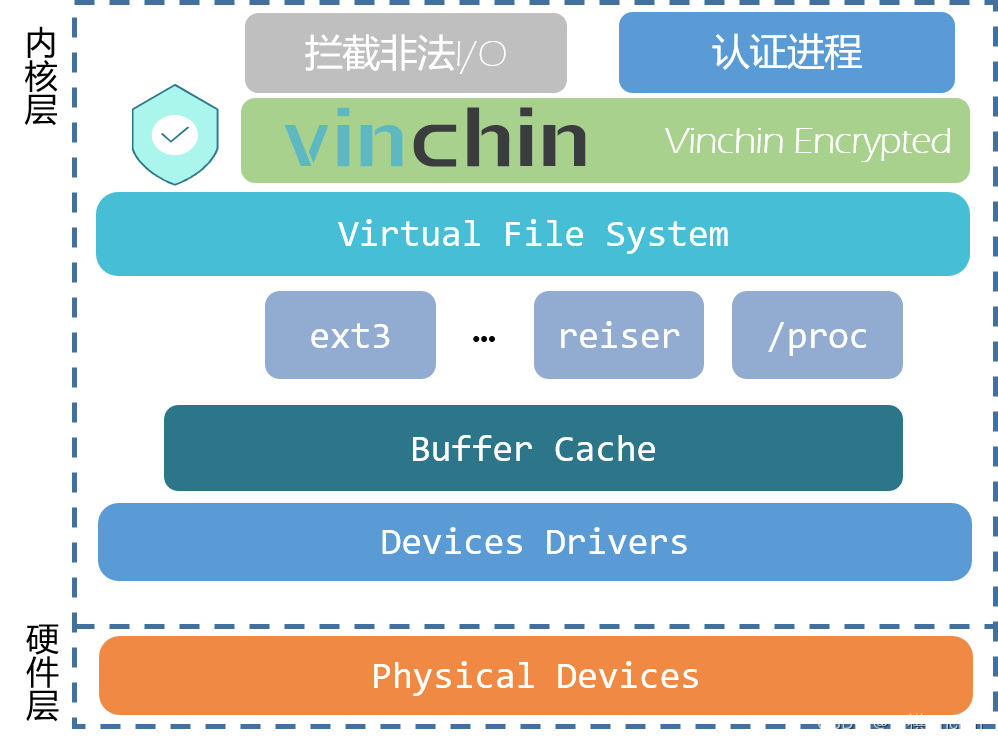
BlazePose: On-device Real-time Body Pose tracking
论文地址:https://arxiv.org/pdf/2006.10204.pdf
GoogleBolg:https://ai.googleblog.com/2020/08/on-device-real-time-body-pose-tracking.html
模型下载地址:https://github.com/PINTO0309/PINTO_model_zoo/tree/main/053_BlazePose
姿势估计在视频中起着至关重要的作用,它可以将数字内容和信息覆盖在物理世界的扩增实境、手语识别、全身姿势控制,甚至量化身体锻炼,从而形成瑜伽、舞蹈和健身应用的基础。由于各种可能的姿势(例如数百种瑜伽体式) ,无数的自由度,闭塞(例如身体或其他物体遮挡从相机看到的四肢)以及各种外观或服装,健身应用的姿势估计特别具有挑战性。
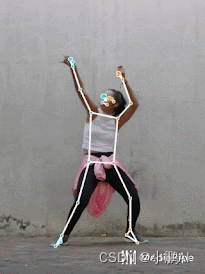
BlazePose,是谷歌在 CVPR 2020 CV4ARVR 研讨会上提出的。该方法通过使用机器学习(ML)框架推断人类的姿态跟踪。与当前基于标准 COCO 拓扑的姿势模型相比,BlazePose 精确地定位了更多的关键点,使其独特地适合于健身应用程序。此外,目前最先进的方法主要依赖于强大的硬件环境进行推理,而该方法能够通过 CPU 推理在移动端上实现了实时性能。如果利用 GPU 推理,BlazePose 可以实现超实时性能,使其能够运行后续的机器学习模型,如人脸或手部跟踪。

目前人体姿势的标准是 COCO 拓扑结构,它包括横跨躯干、手臂、腿和脸部的17个坐标。然而,COCO 的关键点只局限于踝关节和腕关节,缺乏手和脚的尺度和方向信息,这对于像健身和舞蹈这样的实际应用是至关重要的。包括更多的关键点是至关重要的后续应用领域特定的姿势估计模型,如那些为手,脸,或脚。
BlazePose:提出了一个由33个人体关键点组成的新拓扑,它是 COCO、 BlazeFace 和 BlazePalm 拓扑的超集。这使我们能够确定身体语义从姿势预测本身是一致的面部和手模型
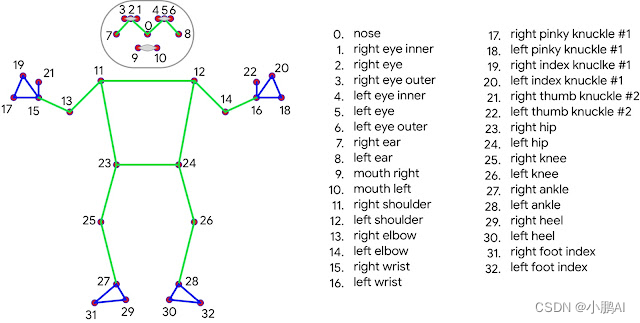
对于姿态估计,谷歌利用两步检测器即:跟踪器 ML 流水线。使用检测器,该流水线首先在帧内定位姿态感兴趣区域(ROI)。该跟踪器随后预测所有33个姿势的关键点从这个ROI区域。注意,对于视频用例,检测器仅在第一帧上运行。对于后续的帧,需要从前一帧的姿态关键点得到 ROI,如下图:
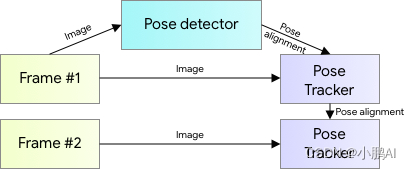
为了实现由姿态检测和跟踪模型组成的完整 ML 流水线的实时性能,每个组件必须非常快,每帧只使用几毫秒。对神经网络而言,关于躯干位置的最强信号是人的面部(由于其高对比度的特征和相对较小的外观变化)。因此,谷歌实现了一个快速和轻量级的姿态检测器,并假设对于其设定的单人用例,头部应该是可检测的。
因此,受到亚毫秒 BlazeFace 模型的启发,训练了一个人脸检测器作为姿态检测器的代理。注意,这个模型只检测一个人在框架中的位置,不能用来识别个人。与从预测的关键点获得 ROI 的 Face Mesh 和 MediaPipeHand 跟踪管道相反,对于人体姿势跟踪,明确预测两个额外的虚拟关键点,它们将人体中心,旋转和缩放描述为一个圆。灵感来自达芬奇的维特鲁威人,预测一个人的臀部中点,一个圆的半径限制整个人,以及连接肩部和臀部中点的线的倾斜角度。这导致了持续的跟踪甚至非常复杂的情况下,如特定的瑜伽体式。下图说明了这种方法。

该管道的姿态估计组件预测所有33个人关键点的位置,每个关键点具有三个自由度(x,y 位置和可见性) ,再加上上面描述的两个虚拟对齐关键点。与目前使用计算密集型热图预测的方法不同,模型使用回归方法,由所有关键点的热图/偏移量联合预测监督,如下所示
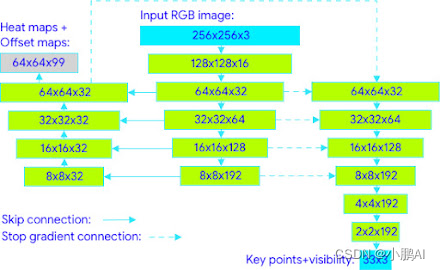
具体来说,在训练期间,我们首先使用热图和偏移损失来训练网络的中心和左分支。然后删除热图输出并训练回归编码器(右分支) ,从而有效地利用热图监督轻量级嵌入
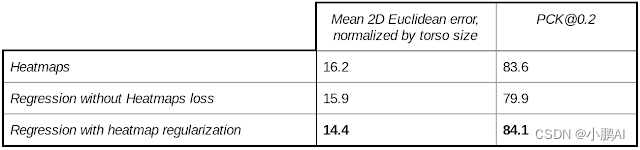
下表显示了由不同训练策略引起的模型质量的消融研究。作为一个评估指标,使用20% 公差的正确点百分比(PCK@0.2)(假设2D 欧几里得误差小于相应人体尺寸的20% 时,正确点被检测到)。为了获得一个人类基线,要求注释者对几个样本进行冗余注释,得到的平均 PCK@0.2为97.2。训练和验证已完成的地理多样性数据集的各种姿势,均匀采样。
为了覆盖广泛的客户硬件,谷歌提出了两个姿态跟踪模型: 轻型和全型,它们在速度和质量的平衡上有所区别。对于 CPU 的性能评估,使用 XNNPACK; 对于移动 GPU,使用 TFLite GPU 后端。