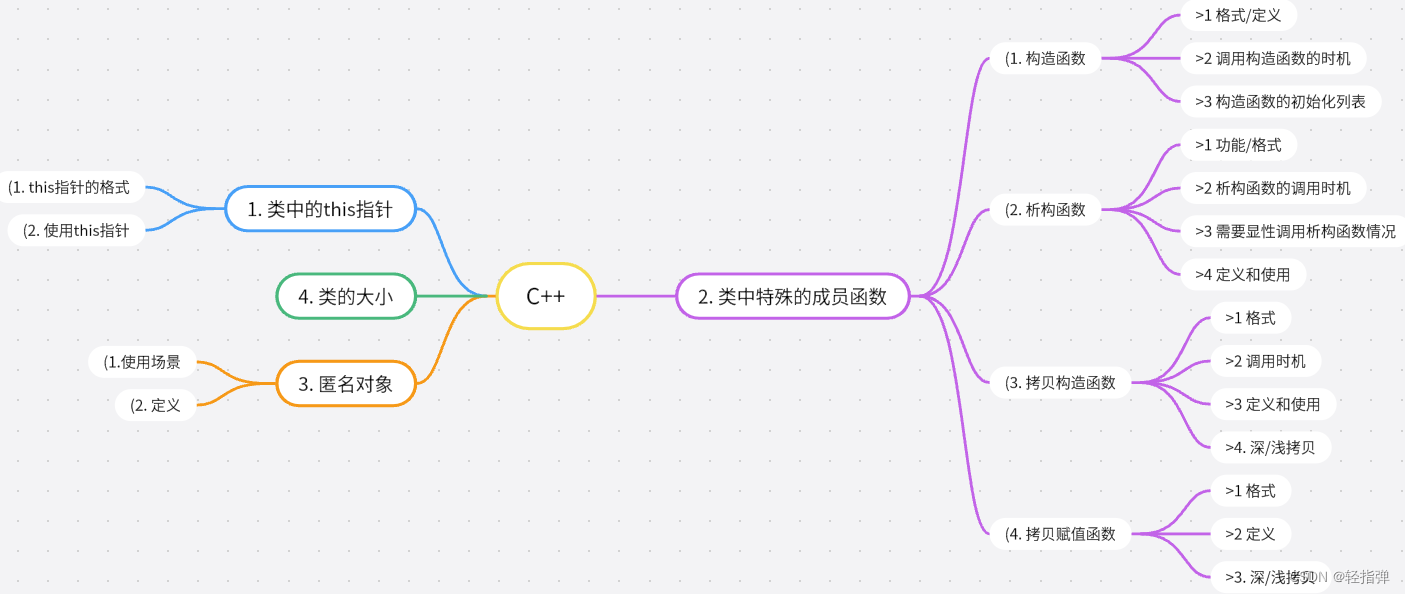
作者:Luca Wintergerst

在最近的一篇博客文章中,我们讨论了 ChatGPT 和 Elasticsearch® 如何协同工作以帮助更有效地管理专有数据。 通过利用 Elasticsearch 的搜索功能和 ChatGPT 的上下文理解,我们演示了如何改进结果。
在这篇文章中,我们讨论如何通过添加分面(facets)、过滤和附加上下文来进一步增强用户体验。 通过提供 ChatGPT 等工具附加上下文,你可以增加获得更准确结果的可能性。 了解 Elasticsearch 的分面和过滤框架如何允许用户优化搜索并降低使用 ChatGPT 的成本。
比较 ChatGPT 和 Elasticsearch 结果
为了改善示例应用程序的用户体验,我们添加了一项功能,可以在 ChatGPT 创建的响应旁边显示原始结果。 这将帮助用户更好地了解 ChatGPT 的工作原理。
由于我们的源数据集仅是爬行的,因此文档中的结构使得人类难以阅读。 为了显示这种差异以及 ChatGPT 可以带来的价值,我们在 GPT 创建的响应旁边添加了原始结果。

目前,此示例应用程序仅返回单个结果。 即使我们使用向量搜索和 BM25 进行混合评分,这个结果也可能并不完美。 如果我们将这个不完美的结果传递给 ChatGPT,我们得到的响应很可能也不会很好,因为上下文缺少重要信息。
理想情况下,我们只需将更多上下文传递到 ChatGPT 中,但当前的 GPT 3.5-turbo 模型仅限于 4,096 个 tokens(这包括你期望获得的响应,因此实际限制要低得多)。 未来的模型可能会有更大的限制,但这也是有代价的。
截至目前,GPT-3.5-turbo 的成本为 0.002 美元/1K 代币,而即将推出的具有 32K 上下文的 GPT-4 成本为 0.06 美元/1K 代币 — 这是 30 倍以上。 即使未来几年出现更强大的模型,对于所有用户案例来说,这样做在经济上也可能不可行。
因此,我们现在不会使用 GPT-4,而是通过发送多个并发请求并为用户提供更灵活的过滤结果来解决 GPT-3.5 的最大 token 限制。
聚合、分面(facets)和过滤
为了解决这一限制,Elasticsearch 的最大优势之一是其强大的分面和过滤框架。 当用户搜索某些内容时,他们可能会提供额外的偏好或上下文,以显着增加获得正确结果的可能性。 通过利用 Elasticsearch 的分面和过滤框架,我们可以允许用户根据各种参数(例如日期、位置或其他相关条件)优化搜索。
同样重要的是要注意,许多用户已经习惯在搜索某些内容时使用分面过滤选项。 让我们看一个例子。
搜索 “How can I parse a message with Grok(如何使用 Grok 解析消息)?” 导致摄取管道的文档作为顶部结果返回。 这并没有错,因为摄取管道也支持 Grok 表达式,但是如果用户有兴趣使用 Logstash 解析他的数据怎么办?
使用简单的术语聚合作为获取点击的请求的一部分,我们可以获得前 10 个产品类别的列表,并将其作为用户的过滤选项提供。

如果用户现在选择左侧的 “Logstash”,则所有结果都将针对 Logstash 进行过滤。 值得注意的是,这一切都可以在仍然使用我们在上一篇博客中讨论过的相同混合查询模型的情况下实现。 我们仍然使用 BM25 和 kNN 搜索的组合来匹配我们的文档。

并行加载多个结果
我们之前简要提到了最大 token 限制。 简而言之,你发送到 API 的提示及其响应不能超过 4,096 个 tokens。 在搜索你的专有数据时,你希望提供尽可能多的具体上下文,以便模型可以为你提供最佳答案。 然而,4,096 个 token 并不算多,尤其是当你包含代码片段之类的内容时。
减轻限制的一个非常简单的第一步就是并行多次询问,每次给出不同的上下文。 使用我们的 Elasticsearch 方法,我们可以更改应用程序以加载前 10 个命中,然后使用相应的上下文提出问题,而不是仅获取前 1 个结果并将其发送到 OpenAI。
这为我们的问题提供了 10 个独特的答案,并大大增加了我们向最终用户提供相关答案的机会。 虽然我们增加了用户查看结果的负担,但它仍然为他们提供了更大的灵活性。
可以这样想:如果你尝试调试问题并在 Google 上搜索异常,你可以快速扫描 Google 显示的前四或五个结果列表,然后单击似乎最适合你的问题的结果。 向用户显示问题的多个答案与此类似。
虽然有一个正确答案是理想的选择,但一开始有多个答案可供选择也是一个很好的起点。 正如之前提到的,与使用更昂贵的模型(例如 GPT-4)相比,它可以更便宜。
我们还可以通过提示发挥更多创意,并要求 ChatGPT 在无法使用提供的上下文回答问题时向我们发送特定响应。 这将使我们能够稍后从 UI 中删除结果。
在我们的用例中效果很好的一个提示是:
prompt = f"Answer this question: {query}\n. Don’t give information not mentioned in the CONTEXT INFORMATION. If the CONTEXT INFORMATION contains code or API requests, your response should include code snippets. If the context does not contain relevant information, answer 'The provided page does not answer the question': \n {body}"
解决 ChatGPT 的最大 token 限制:从一组答案中回答一个问题
由于我们现在对问题有多个答案,因此我们可以尝试将它们总结为一个答案。 为此,我们将主要遵循与之前相同的方法,但我们不会在 Elasticsearch 中搜索上下文,而是将迄今为止收到的各个答案连接起来,排除模型响应但根据所提供的上下文无法回答的任何位置 。
请注意,此运行的提示与之前的提示略有不同,因此模型对上下文的处理略有不同。 这里提供的提示并不完美,还需要根据数据进一步调整和优化。
concatResult = ""
for resultObject in results:
if resultObject['choices'][0]["message"]["content"] != "The provided page does not answer the question.":
concatResult += resultObject['choices'][0]["message"]["content"]
if st.session_state['summarizeResults']['state']:
results = [None] * 1
tasks = []
prompt = f"I will give you {numberOfResults} answers to this question.: \"{query}\"\n. They are ordered by their likelyhood to be correct. Come up with the best answer to the original question, using only the context I will provide you here. If the provided context contains code snippets or API requests, half of your response must be code snippets or API requests. \n {concatResult}"
element = None
with st.session_state['topResult']:
with st.container():
st.markdown(f"**Summary of all results:**")
element = st.empty()
with elasticapm.capture_span("top-result", "openai"):
task = loop.create_task(achat_gpt(prompt, results, counter, element))
tasks.append(task)
loop.set_exception_handler(handle_exception)
loop.run_until_complete(asyncio.wait(tasks))
loop.close()有了这个额外的 “减少阶段(reduce phase)”,我们的应用程序现在将:
- 在 Elasticsearch 中搜索前 10 名点击
- 10 次并行要求 OpenAI 回答问题,每次提供不同的上下文
- 连接 OpenAI 的回复并再次要求 OpenAI 回答问题
通过这种设置,我们可以使用近 40,000 个上下文令牌,同时只需支付相当便宜的 GPT-3.5 模型的费用。 在另一篇博客文章中,我们将更详细地探讨成本,并使用 Elastic APM 来跟踪我们的支出以及其他指标。
应该注意的是,GPT-4 的性能可能仍然比上述方法好得多,因此请使用最适合你和你期望的流量的方法。
Elasticsearch 及 ChatGPT - 搜索 summary frozen index
ChatGPT 结果的引用
大型语言模型(LLM)的缺点之一是过度自信和产生幻觉的倾向。 你提出问题,你就会得到答案。 答案是否正确由你决定。 该模型很少承认它不知道某些事情。 正如我们上面所做的那样,提供上下文并告诉它以特定答案进行响应有助于在一定程度上缓解这种情况。
但是,所提供的上下文以及让模型承认它无法回答问题的同时,也使我们能够为回答提供更准确的引用。
在上一节中,我们将 10 个答案总结为一个全局答案。 除了提供这个全局答案之外,我们还可以提供用于编译结果的所有源文档页面的列表 - 基本上是模型未响应 “The provided page does not answer the question(提供的页面未回答问题)” 的任何页面。
在此屏幕截图中,你可以看到 Elasticsearch 的一组 10 个结果的摘要答案。 尽管我们检查了 10 个结果,但我们仅显示与回答问题实际相关的三个文档链接。 在这种情况下,Elasticsearch 返回的其他七个文档与文档或索引有关,但他们没有具体讨论如何索引某些内容。
搜索专有数据
我们在之前的博客文章中提到,使用 Elasticsearch 和 OpenAI 搜索专有数据非常棒。 但是,我们确实使用网络爬虫来爬取公共文档。 这可能看起来有点违反直觉,但你仔细想想是对的! OpenAI 在网络数据上训练 GPT 模型,因此我们假设它已经知道我们的文档。 那么除了这些数据之外我们为什么还需要 Elasticsearch 呢? 此设置实际上适用于非公开数据吗? 确实如此 —— 让我们证明一下。
使用现有的设置,我们将把有关内部项目的单个超级机密文档推送到我们的索引中。
PUT search-elastic-docs/_doc/1?pipeline=search-elastic-docs@ml-inference
{
"title": "Project LfQg832p6Jx040809WZc",
"product_name": "SuperSecret",
"url": "https://www.example.com",
"body_content": """What is Project LfQg832p6Jx040809WZc? Project LfQg832p6Jx040809WZc is an internal project that's not public information. This is the plan for the project: Step 1 is writing a blog post about OpenAi and Elasticsearch for private data. Step 2 is noticing that we didn't actually include any private data. Step 3 is including an example about private data
We also have some super secret API requests as part of this project:
PUT project/_doc/hello-world
{
"secret": "don't share this with anyone!"
}
"""
}接下来,我们将转到我们的应用程序并搜索 “What are the steps for the internal project(内部项目的步骤是什么)?”
Elasticsearch 及 ChatGPT - 搜索 internal project
总之,对于某些用例,我们使用分面和过滤来减少与 ChatGPT 交互所需的上下文标记数量。 通过在查询时提供额外的上下文,我们表明还可以提高搜索结果的准确性。
详细了解 Elasticsearch 和 AI 的可能性。
在这篇博文中,我们可能使用了第三方生成式人工智能工具,这些工具由其各自所有者拥有和运营。 Elastic 对第三方工具没有任何控制权,我们对其内容、操作或使用不承担任何责任,也不对你使用此类工具可能产生的任何损失或损害负责。 使用人工智能工具处理个人、敏感或机密信息时请务必谨慎。 你提交的任何数据都可能用于人工智能培训或其他目的。 无法保证你提供的信息将得到安全或保密。 在使用之前,你应该熟悉任何生成式人工智能工具的隐私惯例和使用条款。
本文提到的成本基于当前的 OpenAI API 定价以及我们在加载示例应用程序时调用它的频率。
Elastic、Elasticsearch 和相关标志是 Elasticsearch N.V. 在美国和其他国家/地区的商标、徽标或注册商标。 所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。