目录
1、功能说明
2、API使用说明
3、代码示例
1、功能说明
从Flink1.1开始提供了DataGen连接器,它提供了Source类的实现(可并行的源算子),用来生成测试数据,在本地开发或者无法访问外部系统(如kafka)时,它就会非常有用。
DataGen连接器是内置的,不需要额外的依赖项。
2、API使用说明
方法定义:
public DataGeneratorSource(
DataGenerator<T> generator, long rowsPerSecond, @Nullable Long numberOfRows)
参数说明:
DataGenerator<T> generator : 指定数据生成器对象
long rowsPerSecond : 指定数据发射速率(每秒发射的记录数),默认值为Long.MAX_VALUE
@Nullable Long numberOfRows : 指定指定输出数据的总行数(为null时,表示一直输出)
关于DataGenerator类
public interface DataGenerator<T> extends Serializable, Iterator<T>
功能说明:
继承了Iterator,利用迭代器来构造测试数据 3、代码示例
Flink版本说明:flink_1.13.0、scala_2.12
定义User类:
package com.baidu.bean
case class User(id: Long, name: String)
测试代码:
test("DataGen 连接器") {
// 1. 获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(4)
// 自定义 DataGenerator实现类(用来随机生成User对象)
val userGenerator = new DataGenerator[User]() {
// 定义随机数数据生成器
var generator: RandomDataGenerator = _
// 初始化数据生成器
override def open(name: String, context: FunctionInitializationContext, runtimeContext: RuntimeContext): Unit = {
generator = new RandomDataGenerator
}
// 判断迭代器是否有值
override def hasNext: Boolean = true
// 生成随机字符串,并返回
override def next(): User = {
User(generator.nextLong(1, 99) // 生成1~99区间的随机整数
, generator.nextHexString(4) // 生成4位字符串
)
}
}
// 自定义字符串数据生成器
val stringGenerator = new DataGenerator[String]() {
// 定义随机数数据生成器
var generator: RandomDataGenerator = _
// 初始化数据生成器
override def open(name: String, context: FunctionInitializationContext, runtimeContext: RuntimeContext): Unit = {
generator = new RandomDataGenerator
}
// 是否有下一个值
override def hasNext: Boolean = true
// 生成随机字符串,并返回
override def next(): String = generator.nextHexString(3)
}
val dataGenSource = new DataGeneratorSource(
userGenerator // 指定数据生成器
, 2L // 指定发射速率(每秒发射的记录数)
, null // 指定输出数据的总行数(为null时,表示一直输出)
)
// 将DataGeneratorSource做为数据源
val ds = env.addSource(dataGenSource)
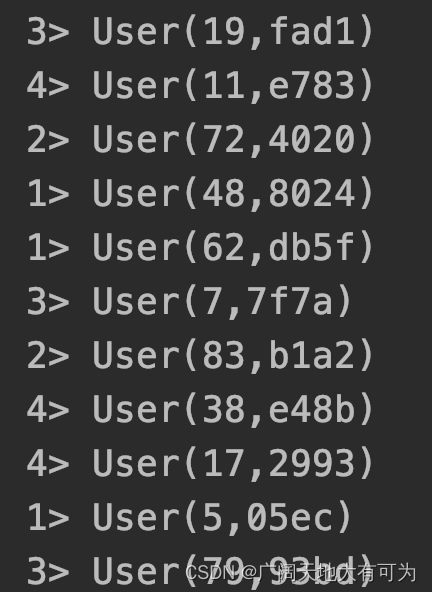
println(s"并行度: ${ds.parallelism}")
// 打印DataStream
ds.print()
// 出发程序执行
env.execute()
}
执行结果: