转载自原文地址: https://www.cnblogs.com/zjacky/p/16529648.html
重采样:
将音频进行SDL播放的时候,因为当前的SDL2.0不支持plannar格式,也不支持浮点型的,而最新的FFpemg会将音频解码为AV_SAMPLE_FMT_FLTP,这个时候进行对它重采样的话,就可以在SDL2.0上进行播放这个音频了。
重采样参数
1、sample rate(采样率):采样设备每秒抽取样本的次数
2、sample format(采样格式)和量化精度:每种⾳频格式有不同的量化精度(位宽),位数越多,表示值就越精确,声⾳表现⾃然就越精准。
3、channel layout(通道布局,也就是声道数):这个就是采样的声道数
在FFmpeg里面主要有两种采样格式:floating-point formats 和 planar sample formats;具体采样参数如下(在(libavutil/samplefmt.h头文件里面):
enum AVSampleFormat {
AV_SAMPLE_FMT_NONE = -1,
AV_SAMPLE_FMT_U8, ///< unsigned 8 bits
AV_SAMPLE_FMT_S16, ///< signed 16 bits
AV_SAMPLE_FMT_S32, ///< signed 32 bits
AV_SAMPLE_FMT_FLT, ///< float
AV_SAMPLE_FMT_DBL, ///< double
AV_SAMPLE_FMT_U8P, ///< unsigned 8 bits, planar
AV_SAMPLE_FMT_S16P, ///< signed 16 bits, planar
AV_SAMPLE_FMT_S32P, ///< signed 32 bits, planar
AV_SAMPLE_FMT_FLTP, ///< float, planar
AV_SAMPLE_FMT_DBLP, ///< double, planar
AV_SAMPLE_FMT_S64, ///< signed 64 bits
AV_SAMPLE_FMT_S64P, ///< signed 64 bits, planar
AV_SAMPLE_FMT_NB ///< Number of sample formats. DO NOT USE if linking dynamically
};
说明:
1.U8(无符号整型8bit)、S16(整型16bit)、S32(整型32bit)、FLT(单精度浮点类型)、DBL(双精度浮点类型)、S64(整型64bit),不以P为结尾的都是interleaved(packed)结构,以P为结尾的是planar结构。
2.Planar模式是FFmpeg内部存储模式,我们实际使用的音频文件都是Packed模式的。
3.FFmpeg解码不同格式的音频输出的音频采样格式不是一样。测试发现,其中AAC解码输出的数据为浮点型的 AV_SAMPLE_FMT_FLTP 格式,MP3解码输出的数据为 AV_SAMPLE_FMT_S16P 格式(使用的mp3文件为16位深)。具体采样格式可以查看解码后的AVFrame中的 format 成员或解码器的AVCodecContext中的 sample_fmt 成员。
还有就是声道分布参数,这个在FFmpeg也有说明(声道分布在FFmpeg\libavutil\channel_layout.h中有定义,⼀般来说⽤的⽐较多的是 AV_CH_LAYOUT_STEREO(双声道)和AV_CH_LAYOUT_SURROUND(三声道),这两者的定义如下):
#define AV_CH_LAYOUT_STEREO (AV_CH_FRONT_LEFT|AV_CH_FRONT_RIGHT)
#define AV_CH_LAYOUT_SURROUND (AV_CH_LAYOUT_STEREO|AV_CH_FRONT_CENTER)
FFmpeg重采样流程
重采样的处理流程: 1、创建上下文环境:重采样过程上下文环境为SwrContext数据结构。 2、参数设置:转换的参数设置到SwrContext中。SwrContext初始化:swr_init()。 3、分配样本数据内存空间:使用av_samples_alloc_array_and_samples、av_samples_alloc等工具函数。 4、开启重采样转换:通过重复地调用swr_convert来完成。 5、重采样转换完成, 释放相关资源:通过swr_free()释放SwrContext。
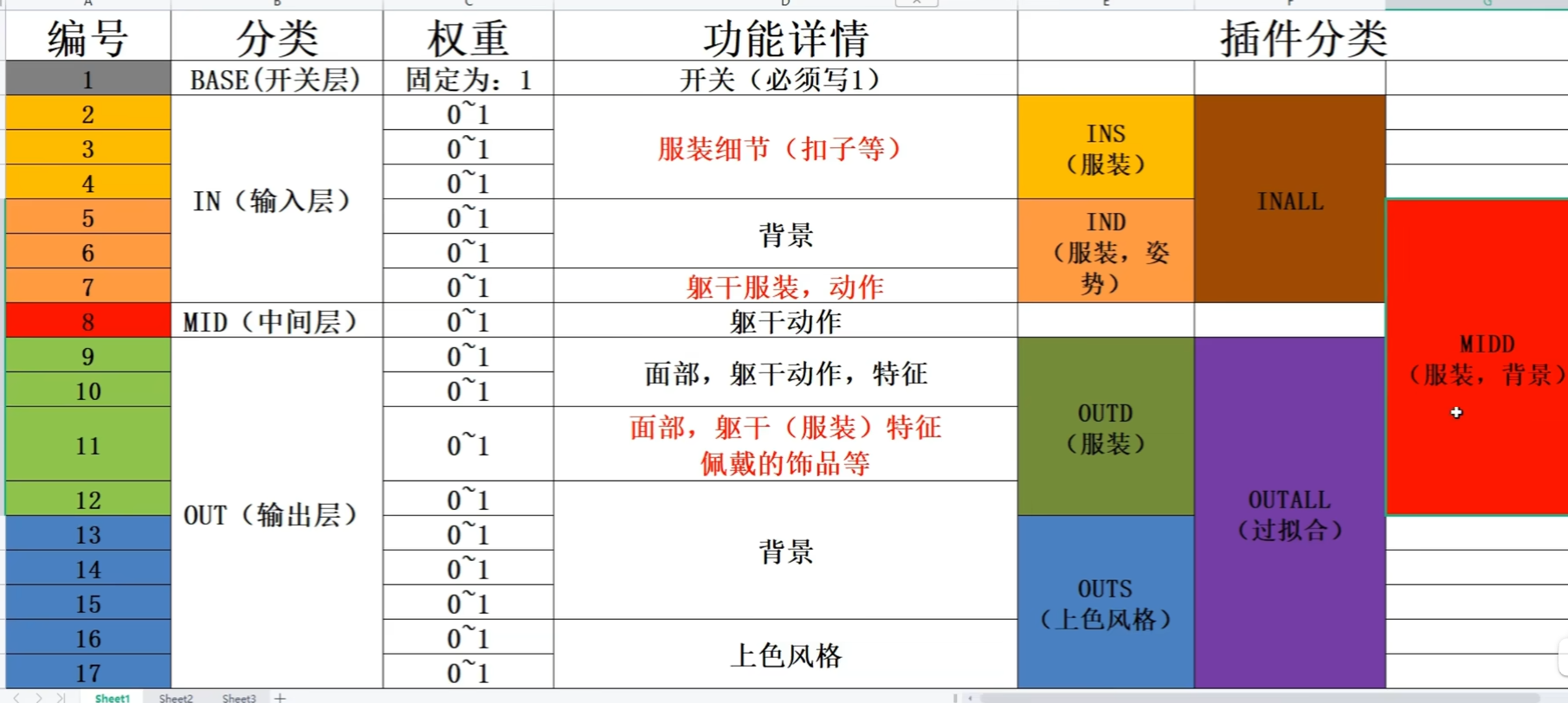
流程图如下:
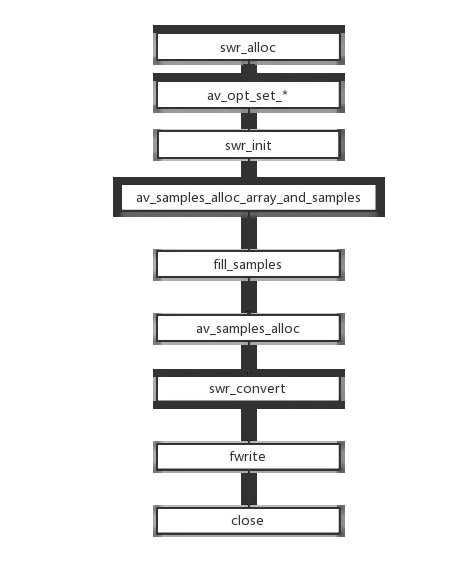
编辑
添加图片注释,不超过 140 字(可选)
FFmpeg重采样流程(方法二)(采用swr_convert_frame()进行重采样)
重采样的处理流程: 1、创建上下文环境:重采样过程上下文环境为SwrContext数据结构。(和上面一样) 2、参数设置:转换的参数设置到SwrContext中。SwrContext初始化:swr_init()。 3、直接采用swr_convert_frame()对输入帧和输出帧进行重采样。(不需要提前申请空间,详细看函数介绍) 4、重采样转换完成, 释放相关资源:通过swr_free()释放SwrContext。
FFmpeg采样流程相关api介绍
【第一】音频重采样上下文——结构体SwrContext
【结构声明】
struct SwrContext {
const AVClass *av_class; ///< AVClass used for AVOption and av_log()
int log_level_offset; ///< logging level offset
void *log_ctx; ///< parent logging context
enum AVSampleFormat in_sample_fmt; ///< input sample format
enum AVSampleFormat int_sample_fmt; ///< internal sample format (AV_SAMPLE_FMT_FLTP or AV_SAMPLE_FMT_S16P)
enum AVSampleFormat out_sample_fmt; ///< output sample format
int64_t in_ch_layout; ///< input channel layout
int64_t out_ch_layout; ///< output channel layout
int in_sample_rate; ///< input sample rate
int out_sample_rate; ///< output sample rate
int flags; ///< miscellaneous flags such as SWR_FLAG_RESAMPLE
float slev; ///< surround mixing level
float clev; ///< center mixing level
float lfe_mix_level; ///< LFE mixing level
float rematrix_volume; ///< rematrixing volume coefficient
float rematrix_maxval; ///< maximum value for rematrixing output
int matrix_encoding; /**< matrixed stereo encoding */
const int *channel_map; ///< channel index (or -1 if muted channel) map
int used_ch_count; ///< number of used input channels (mapped channel count if channel_map, otherwise in.ch_count)
int engine;
int user_in_ch_count; ///< User set input channel count
int user_out_ch_count; ///< User set output channel count
int user_used_ch_count; ///< User set used channel count
int64_t user_in_ch_layout; ///< User set input channel layout
int64_t user_out_ch_layout; ///< User set output channel layout
enum AVSampleFormat user_int_sample_fmt; ///< User set internal sample format
int user_dither_method; ///< User set dither method
struct DitherContext dither;
int filter_size; /**< length of each FIR filter in the resampling filterbank relative to the cutoff frequency */
int phase_shift; /**< log2 of the number of entries in the resampling polyphase filterbank */
int linear_interp; /**< if 1 then the resampling FIR filter will be linearly interpolated */
int exact_rational; /**< if 1 then enable non power of 2 phase_count */
double cutoff; /**< resampling cutoff frequency (swr: 6dB point; soxr: 0dB point). 1.0 corresponds to half the output sample rate */
int filter_type; /**< swr resampling filter type */
double kaiser_beta; /**< swr beta value for Kaiser window (only applicable if filter_type == AV_FILTER_TYPE_KAISER) */
double precision; /**< soxr resampling precision (in bits) */
int cheby; /**< soxr: if 1 then passband rolloff will be none (Chebyshev) & irrational ratio approximation precision will be higher */
float min_compensation; ///< swr minimum below which no compensation will happen
float min_hard_compensation; ///< swr minimum below which no silence inject / sample drop will happen
float soft_compensation_duration; ///< swr duration over which soft compensation is applied
float max_soft_compensation; ///< swr maximum soft compensation in seconds over soft_compensation_duration
float async; ///< swr simple 1 parameter async, similar to ffmpegs -async
int64_t firstpts_in_samples; ///< swr first pts in samples
int resample_first; ///< 1 if resampling must come first, 0 if rematrixing
int rematrix; ///< flag to indicate if rematrixing is needed (basically if input and output layouts mismatch)
int rematrix_custom; ///< flag to indicate that a custom matrix has been defined
AudioData in; ///< input audio data
AudioData postin; ///< post-input audio data: used for rematrix/resample
AudioData midbuf; ///< intermediate audio data (postin/preout)
AudioData preout; ///< pre-output audio data: used for rematrix/resample
AudioData out; ///< converted output audio data
AudioData in_buffer; ///< cached audio data (convert and resample purpose)
AudioData silence; ///< temporary with silence
AudioData drop_temp; ///< temporary used to discard output
int in_buffer_index; ///< cached buffer position
int in_buffer_count; ///< cached buffer length
int resample_in_constraint; ///< 1 if the input end was reach before the output end, 0 otherwise
int flushed; ///< 1 if data is to be flushed and no further input is expected
int64_t outpts; ///< output PTS
int64_t firstpts; ///< first PTS
int drop_output; ///< number of output samples to drop
double delayed_samples_fixup; ///< soxr 0.1.1: needed to fixup delayed_samples after flush has been called.
struct AudioConvert *in_convert; ///< input conversion context
struct AudioConvert *out_convert; ///< output conversion context
struct AudioConvert *full_convert; ///< full conversion context (single conversion for input and output)
struct ResampleContext *resample; ///< resampling context
struct Resampler const *resampler; ///< resampler virtual function table
double matrix[SWR_CH_MAX][SWR_CH_MAX]; ///< floating point rematrixing coefficients
float matrix_flt[SWR_CH_MAX][SWR_CH_MAX]; ///< single precision floating point rematrixing coefficients
uint8_t *native_matrix;
uint8_t *native_one;
uint8_t *native_simd_one;
uint8_t *native_simd_matrix;
int32_t matrix32[SWR_CH_MAX][SWR_CH_MAX]; ///< 17.15 fixed point rematrixing coefficients
uint8_t matrix_ch[SWR_CH_MAX][SWR_CH_MAX+1]; ///< Lists of input channels per output channel that have non zero rematrixing coefficients
mix_1_1_func_type *mix_1_1_f;
mix_1_1_func_type *mix_1_1_simd;
mix_2_1_func_type *mix_2_1_f;
mix_2_1_func_type *mix_2_1_simd;
mix_any_func_type *mix_any_f;
/* TODO: callbacks for ASM optimizations */
};
比较重要的参数: + 采样格式 + 声道类型
【结构体定义和申请空间】
SwrContext* audio_convert_ctx = NULL;
audio_convert_ctx = swr_alloc();
【第二】上下文结构体参数设置
参数设置有两种方式: 【方法一】:采用AVOptions的api,举例如下
av_opt_set_channel_layout(audio_convert_ctx, "in_channel_layout", AV_CH_LAYOUT_5POINT1, 0);
av_opt_set_channel_layou(audio_convert_ctx, "out_channel_layout", AV_CH_LAYOUT_STEREO, 0);
av_opt_set_int(audio_convert_ctx, "in_sample_rate", 44100, 0);
av_opt_set_int(audio_convert_ctx, "out_sample_rate", 16000, 0);
av_opt_set_sample_fmt(audio_convert_ctx, "in_sample_fmt", AV_SAMPLE_FMT_FLPT, 0);
av_opt_set_sample_fmt(audio_convert_ctx, "out_sample_fmt", AV_SAMPLE_FMT_S16, 0);
【方法二】:采用swr_alloc_set_opts():如果第一个参数为NULL则创建一个新的SwrContext,否则对已有的SwrContext进行参数设置。
struct SwrContext *swr_alloc_set_opts(struct SwrContext *s, // ⾳频重采样上下⽂
int64_t out_ch_layout, // 输出的layout, 如:5.1声道
enum AVSampleFormat out_sample_fmt, // 输出的采样格式。
Float, S16,⼀般 选⽤是s16 绝⼤部分声卡⽀持
int out_sample_rate, //输出采样率
int64_t in_ch_layout, // 输⼊的layout
enum AVSampleFormat in_sample_fmt, // 输⼊的采样格式
int in_sample_rate, // 输⼊的采样率
int log_offset, // ⽇志相关,不⽤管先,直接为0 void *log_ctx // ⽇志相关,不⽤管先,直接为NULL
);
【第三】初始化SwrContext结构体
参数设置好之后必须调用swr_init()对SwrContext进行初始化。
int swr_init(struct SwrContext *s);
如果需要修改转换的参数:
- 1、重新进行参数设置。
- 2、再次调用swr_init()。
【第四】分配采样内存空间
转换之前需要分配内存空间用于保存重采样的输出数据,内存空间的大小跟通道个数、样本格式需要、容纳的样本个数都有关系。主要有两种方式: 【方式一】:输出目标是Frame->data 采用av_frame_get_buffer()函数,举例如下:
AVFrame* pFrame_new;
pFrame_new = av_frame_alloc();
pFrame_new->channel_layout = audio_decodec_ctx->channel_layout;
pFrame_new->channels = av_get_channel_layout_nb_channels(audio_decodec_ctx->channel_layout);
pFrame_new->format = t->inner_sample_format;
pFrame_new->sample_rate = t->inner_sample_rate;
int64_t nb_samples = av_rescale_rnd(pFrame->nb_samples, pFrame_new->sample_rate, pFrame->sample_rate, AV_ROUND_UP);
pFrame_new->nb_samples = nb_samples; //该帧采样点数
av_frame_get_buffer(pFrame_new, 0);
pFrame_new->pts = av_rescale_rnd(pFrame->pts, pFrame_new->sample_rate, pFrame->sample_rate, AV_ROUND_UP);
【方式二】:输出目标直接是内存空间
libavutil中的samples处理API提供了一些函数方便管理样本数据,例如av_samples_alloc()函数用于分配存储sample的buffer。
/**
* @param[out] audio_data 输出数组,每个元素是指向一个通道的数据的指针。
* @param[out] linesize aligned size for audio buffer(s), may be NULL
* @param nb_channels 通道的个数。
* @param nb_samples 每个通道的样本个数。
* @param align buffer size alignment (0 = default, 1 = no alignment)
* @return 成功返回大于0的数,错误返回负数。
*/
int av_samples_alloc(uint8_t **audio_data, int *linesize, int nb_channels,
int nb_samples, enum AVSampleFormat sample_fmt, int align);
也有计算所需内存空间的函数av_samples_get_buffer_size()
/*
*获取给定音频参数所需的缓冲区大小。
* @param [out] linesize计算的lineize,可能为NULL
* @param nb_channels频道数
* @param nb_samples单个通道中的样本数
* @param sample_fmt样本格式
* @param对齐缓冲区大小对齐(0 =默认,1 =无对齐)
* @return需要缓冲区大小,或失败时出现负错误代码
*/
int av_samples_get_buffer_size(int *linesize, int nb_channels, int nb_samples,
enum AVSampleFormat sample_fmt, int align);
【第五-1】将输⼊的⾳频按照定义的参数进⾏转换并输出 Swr_convert()
【函数定义】
int swr_convert(struct SwrContext *s, // ⾳频重采样的上下⽂
uint8_t **out, // 输出的指针。传递的输出的数组(frame的数据指针)
int out_count, //输出缓冲区每通道样本数据数量(对于音频,每个通道数据长度都相同),注意这里不是以字节为单位
const uint8_t **in , //输⼊的数组,AVFrame解码出来的DATA
int in_count // 输⼊的单通道的样本数量。这里填入frame->nb_samples即可
);
【函数说明】
0、返回值:转换成功后每个通道的输出样本数,出错则为负值
1、如果没有提供足够的空间用于保存输出数据,采样数据会缓存在swr中。可以通过 swr_get_out_samples()来获取下一次调用swr_convert在给定输入样本数量下输出样本数量的上限,来提供足够的空间。
2、如果是采样频率转换,转换完成后采样数据可能会缓存在swr中,它期待你提供更多的输入数据。
3、如果实际上并不需要更多输入数据,通过调用swr_convert(),其中参数in_count设置为0来获取缓存在swr中的数据。
4、转换结束之后需要冲刷swr_context的缓冲区,通过调用swr_convert(),其中参数in设置为NULL,参数in_count设置为0。 注释里面有一句: in and in_count can be set to 0 to flush the last few samples out at the end.
【举例】
ret = swr_convert(audio_convert_ctx,
&outBuff, nb_samples,
(const uint8_t**)audio_frame->data, audio_frame->nb_samples);
while (ret > 0) { // 把最后几个样本冲洗出来
ret = swr_convert(audio_convert_ctx, &outBuff, nb_samples,
NULL, 0);
}
【第五-2】采用swr_convert_frame() 输入输出帧的转换
【函数定义】
int swr_convert_frame(SwrContext *swr,
AVFrame *output, const AVFrame *input);
【参数说明】 输入:
- swr:重采样上下文结构体
- output:输出帧
- input:输入帧 输出:
- 0 成功,AVERROR 失败或不匹配的配置。
【函数说明】
- 转换输入 AVFrame 中的样本,并将其写入输出 AVFrame。
- 输入和输出 AVFrames 必须设置 channel_layout、sample_rate 和 format。
- 如果输出 AVFrame 没有分配数据指针,则将自动调用 av_frame_get_buffer() 来设置 nb_samples 字段以分配帧。
- 输出的 AVFrame 可以为 NULL 或分配的样本少于所需的样本。在这种情况下,任何未写入输出的剩余样本将被添加到内部 FIFO 缓冲区,以在下次调用此函数或 swr_convert() 时返回。
- 如果转换采样率,内部重采样延迟缓冲区中可能有剩余数据。 swr_get_delay() 告诉剩余样本的数量。要将此数据作为输出,请使用 NULL 输入调用此函数或 swr_convert()。
- 如果 SwrContext 配置与输出和输入 AVFrame 设置不匹配,则不会进行转换,取决于哪个 AVFrame 不匹配 AVERROR_OUTPUT_CHANGED、AVERROR_INPUT_CHANGED 或它们的按位或结果。
【第六】释放资源
首先释放内存(frame->data可以通过av_frame_free()时释放):
av_freep(outBuffer);
在所有转换完成之后,释放上下文:
void swr_free(struct SwrContext **s)
音频重采样,采样格式转换和混合库
//
// 音频帧格式转换
//
int32_t AudioConvert(
const AVFrame* pInFrame, // 输入音频帧
AVSampleFormat eOutSmplFmt, // 输出音频格式
int32_t nOutChannels, // 输出音频通道数
int32_t nOutSmplRate, // 输出音频采样率
AVFrame** ppOutFrame) // 输出视频帧
{
struct SwrContext* pSwrCtx = nullptr;
AVFrame* pOutFrame = nullptr;
// 创建格式转换器,
int64_t nInChnlLayout = av_get_default_channel_layout(pInFrame->channels);
int64_t nOutChnlLayout = (nOutChannels == 1) ? AV_CH_LAYOUT_MONO : AV_CH_LAYOUT_STEREO;
pSwrCtx = swr_alloc();
if (pSwrCtx == nullptr)
{
LOGE("<AudioConvert> [ERROR] fail to swr_alloc()\n");
return -1;
}
swr_alloc_set_opts(pSwrCtx,
nOutChnlLayout, eOutSmplFmt, nOutSmplRate, nInChnlLayout,
(enum AVSampleFormat)(pInFrame->format), pInFrame->sample_rate,
0, nullptr );
// 计算重采样转换后的样本数量,从而分配缓冲区大小
int64_t nCvtBufSamples = av_rescale_rnd(pInFrame->nb_samples, nOutSmplRate, pInFrame->sample_rate, AV_ROUND_UP);
// 创建输出音频帧
pOutFrame = av_frame_alloc();
pOutFrame->format = eOutSmplFmt;
pOutFrame->nb_samples = (int)nCvtBufSamples;
pOutFrame->channel_layout = (uint64_t)nOutChnlLayout;
int res = av_frame_get_buffer(pOutFrame, 0); // 分配缓冲区
if (res < 0)
{
LOGE("<AudioConvert> [ERROR] fail to av_frame_get_buffer(), res=%d\n", res);
swr_free(&pSwrCtx);
av_frame_free(&pOutFrame);
return -2;
}
// 进行重采样转换处理,返回转换后的样本数量
int nCvtedSamples = swr_convert(pSwrCtx,
const_cast<uint8_t**>(pOutFrame->data),
(int)nCvtBufSamples,
const_cast<const uint8_t**>(pInFrame->data),
pInFrame->nb_samples);
if (nCvtedSamples <= 0)
{
LOGE("<AudioConvert> [ERROR] no data for swr_convert()\n");
swr_free(&pSwrCtx);
av_frame_free(&pOutFrame);
return -3;
}
pOutFrame->nb_samples = nCvtedSamples;
pOutFrame->pts = pInFrame->pts; // pts等时间戳沿用
pOutFrame->pkt_pts = pInFrame->pkt_pts;
(*ppOutFrame) = pOutFrame;
swr_free(&pSwrCtx); // 释放转换器
return 0;
}
delay
@ see swr_delay() @ see swr_convert() @ see swr_get_delay()
补充
channels 和 channel_layout 是啥
channels 为 音频的 通道数 1 2 3 4 5.....
channel_layout 为音频 通道格式类型 如 单通道 双通道 .....
相互之间获取
av_get_channel_layout_nb_channels()
av_get_default_channel_layout()
对应关系
channel_layout_map[]
{ "mono", 1, AV_CH_LAYOUT_MONO },
{ "stereo", 2, AV_CH_LAYOUT_STEREO },
{ "2.1", 3, AV_CH_LAYOUT_2POINT1 },
{ "3.0", 3, AV_CH_LAYOUT_SURROUND },
{ "3.0(back)", 3, AV_CH_LAYOUT_2_1 },
{ "4.0", 4, AV_CH_LAYOUT_4POINT0 },
{ "quad", 4, AV_CH_LAYOUT_QUAD },
{ "quad(side)", 4, AV_CH_LAYOUT_2_2 },
{ "3.1", 4, AV_CH_LAYOUT_3POINT1 },
{ "5.0", 5, AV_CH_LAYOUT_5POINT0_BACK },
{ "5.0(side)", 5, AV_CH_LAYOUT_5POINT0 },
{ "4.1", 5, AV_CH_LAYOUT_4POINT1 },
{ "5.1", 6, AV_CH_LAYOUT_5POINT1_BACK },
{ "5.1(side)", 6, AV_CH_LAYOUT_5POINT1 },
{ "6.0", 6, AV_CH_LAYOUT_6POINT0 },
{ "6.0(front)", 6, AV_CH_LAYOUT_6POINT0_FRONT },
{ "hexagonal", 6, AV_CH_LAYOUT_HEXAGONAL },
{ "6.1", 7, AV_CH_LAYOUT_6POINT1 },
{ "6.1", 7, AV_CH_LAYOUT_6POINT1_BACK },
{ "6.1(front)", 7, AV_CH_LAYOUT_6POINT1_FRONT },
{ "7.0", 7, AV_CH_LAYOUT_7POINT0 },
{ "7.0(front)", 7, AV_CH_LAYOUT_7POINT0_FRONT },
{ "7.1", 8, AV_CH_LAYOUT_7POINT1 },
{ "7.1(wide)", 8, AV_CH_LAYOUT_7POINT1_WIDE },
{ "octagonal", 8, AV_CH_LAYOUT_OCTAGONAL },
{ "downmix", 2, AV_CH_LAYOUT_STEREO_DOWNMIX, },
>>> 音视频开发 视频教程: https://ke.qq.com/course/3202131?flowToken=1031864
>>> 音视频开发学习资料、教学视频,免费分享有需要的可以自行添加学习交流群: 739729163 领取