自己总结一下,
三元组如果正负样本足够开,距离足够远,loss为0,因为模型已经学的不错了,不需要继续学习。
最好的负样本是,model预测负样本的把握不太大的。
如果负样本是很难分的,例如d(a,p)>=d(a,n),即负样本和anchor离的更近,loss是最大的,但模型不容易学出来。
并且三元组loss每次只对一条样本(a,p,n)进行loss计算,不考虑其他的负样本。
CLIP则是batch_size个样本一起做对比loss的,可以看到bs-1个负样本。【论文&模型讲解】CLIP(Learning Transferable Visual Models From Natural Language Supervision)_clip 数据集_friedrichor的博客-CSDN博客
对比loss都是bs-1个负样本一起计算的吗?
目录
contrastive loss
Softmax
Triplet Loss(三元loss)
为什么要设置margin?
triplets loss该如何构造训练集?
contrastive loss
contrastive loss的表达式如下:
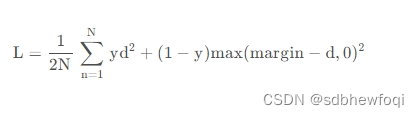
其中 ,代表两个样本特征的欧氏距离,y为两个样本是否匹配的标签,y=1代表两个样本相似或者匹配,y=0则代表不匹配,margin为设定的阈值。
很好的表达成对样本的匹配程度。
- 当y=1(即样本相似)时,损失函数只剩下
,即原本相似的样本,如果在特征空间的欧式距离较大,则说明当前的模型不好,因此加大损失。
- 当y=0时(即样本不相似)时,损失函数为
,即当样本不相似时,其特征空间的欧式距离反而小的话,损失值会变大,这也正好符号我们的要求。其中margin是一个超参,相当于是给loss定了一个上届(margin平方),如果d大于等于margin,那么说明已经优化的很好了,loss=0了。
Softmax
Softmax是确定的分类,需要有真实的标注label。而有的时候我们不一定知道label,但是知道正样本对和负样本对——比如两张照片是同一个人,或者不是同一个人。
Triplet Loss(三元loss)
输入是一个三元组 <a, p, n>
- a: anchor,表示一个基准样本
- p: positive, 与 a 是同一类别的样本,比如就是同一个人的照片
- n: negative, 与 a 是不同类别的样本,比如就是不同人的照片
triplet loss的表达式如下:
其中 d 表示距离函数,一般指在Embedding下的欧式距离计算。很显然,Triplet-Loss是希望让a和p的距离尽可能小,而a和n的距离尽可能大,但是具体而言 d(a,p) 和 d(a,n) 的数值是多少,并没有规定,只要考察他们之间的相对距离。网上有一张图片说明了几种相对关系。
如果我们给定了一个a和p,以及参数 margin > 0,那么我们就可以考察negative点的位置,会出现三种case(如果是Easy negative的三元组我们叫做Easy triplet,其他类似):
Easy negatives(绿色区域): 即
,这种情况不需要优化(无法优化,Loss为0),天然a, p的距离很近, a, n的距离远。
hard negatives(红色区域):,也就是说negative点反而比较近,说明距离估计的不准,这个时候loss比较大。
Semi-hard negatives(橙色区域):, 即a, n的距离靠的很近,但是因为我们有一个margin,使得loss依然是正的。这种情况下,其实是说在这个三元组里面比较p和n离a的距离差不多,比较容易混淆。
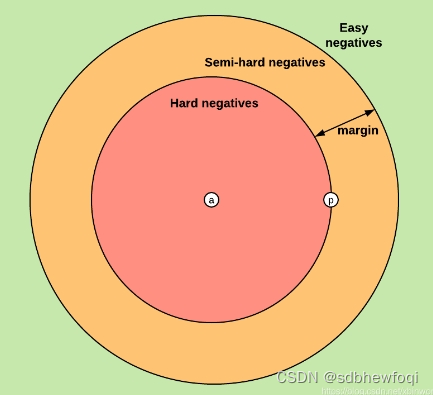
解释一下这个图:
红色圈指的是负样本落在这里面,黄色圆环指的是负样本落在这里面,绿色区域指的是负样本落在这里面。
如果负样本落在绿色区域,说明负样本和正样本就足够的分离了,model已经学到了,不需要再优化,loss为0。
如果负样本落在黄色圆环,说明负样本虽然和正样本有一定的区别,model能分开他们,但是把握不大,我们需要继续更新model,让model有足够多的把握区分正负样本。
在线训练时产生样本:
其实也可以离线把triplet数据都产生(配对)好。
但一般采用的方式是,即在线对一个Batch去产生。产生时又分为两种策略Batch All和Batch Hard (是在一篇行人重识别的论文中提到的[7],假设一个batch中有 B=PK 张图片, 其中 P 个身份的人,每个身份的人 K 张图片(比如 K=4 )。
我的想法:其实就是p个类别,每个类目k张图。或者说p个商品,每个商品k张不同角度的图。
- Batch All:计算batch_size中所有valid的hard triplet 和 semi-hard triplet(valid是指a,p,n三个都不能相同,需要是不同图片), 然后取平均得到Loss。理论上最多可以产生 PK(K−1)(PK−K) 个 triplets:PK个 anchor,K-1 个 positive,PK-K 个 negative。但是因为很多是easy triplets的情况,所以平均会导致Loss很小,easy triplets对我们是不需要的。所以是对所有valid的hard triplet和semi-hard triplet对求平均。
- Batch Hard:对于每一个anchor,选择距离最大的 d(a,p) 和距离最大的 d(a,n),所以只有 PK 个三元组triplets来求loss。
为什么要设置margin?
- 避免模型走捷径,将negative和positive的embedding训练成很相近,因为如果没margin,triplets loss公式就变成了
,那么只要
就可以满足上式,也就是锚点a和正例p与锚点a和负例n的距离一样即可,这样模型很难正确区分正例和负例。
- 设定一个margin常量,可以迫使模型努力学习,能让锚点a和负例n的distance值更大,同时让锚点a和正例p的distance值更小。
- 由于margin的存在,使得triplets loss多了一个参数,margin的大小需要调参。如果margin太大,则模型的损失会很大,而且学习到最后,loss也很难趋近于0,甚至导致网络不收敛,但是可以较有把握的区分较为相似的样本,即a和p更好区分;如果margin太小,loss很容易趋近于0,模型很好训练,但是较难区分a和p。
triplets loss该如何构造训练集?
首先能看到,对于triplet loss的损失公式,要有3个输入,即锚点a,正例p和负例n。对于样本来讲,有3种,即easy triplets、hard triplets和semi-hard triplets。
理论上讲,使用hard triplets训练模型最好,因为这样模型能够有很好的学习能力,但由于margin的存在,这类样本可能模型没法很好的拟合,训练比较困难;其次是使用semi-hard triplet,这类样本是实际使用中最优选择,因为这类样本损失不为0,而且损失不大,模型既可以学习到样本之间的差异,又较容易收敛;至于easy triplet,损失为0,不用拿来训练。
contrastive loss 和 triplet loss 的作用类似,都是想办法拉近同类样本距离,拉远异类样本距离。
triplet loss 的痛点在于每次只看一个负类的距离,没有考虑其他所有负类的情况,这就导致了在随机产生的数据对中,每一个数据对并不能有效的保证当前优化的方向能够拉远所有负类样本的距离,
这就导致了往往训练过程中的收敛不稳定或者陷入局部最优。原文链接:https://blog.csdn.net/qq_35455503/article/details/108748355
针对不同的业务,其实构造的原则也不一样,比如人脸识别场景,样本的选择应该满足 d(a,p) 和d(a,n) 尽可能接近,其实就是选择semi-hard triplets样本,这样一来,损失函数的公式不容易满足,也就意味着损失值不够低,模型必须认真训练和更新自己的参数,从而努力让d(a,n) 的值尽可能变大,同时让 d(a,p)的值尽可能变小。
针对搜索引擎场景,比如dssm,正样本是用户query搜索点击的doc做正例,负例是采用随机采样的策略,一般随机采样的策略是不可控的,既可能采样到easy triplet,又可能采样到hard triple,要看采样的池子怎么确定。
Facebook最近提出的EBR也指出,在随机采样的策略上,要增加semi-hard triplets,选取搜索曝光页面第101~500,也就是让模型看到这些模糊的样本,有些相似但没那么相似,这样模型才能更好的学习到样本之间的差异。(作为负样本)
参考:
深度学习方法(十九):一文理解Contrastive Loss,Triplet Loss,Focal Loss_大饼博士X的博客-CSDN博客
triplet loss 损失函数 - 233彭于晏的文章 - 知乎 https://zhuanlan.zhihu.com/p/171627918