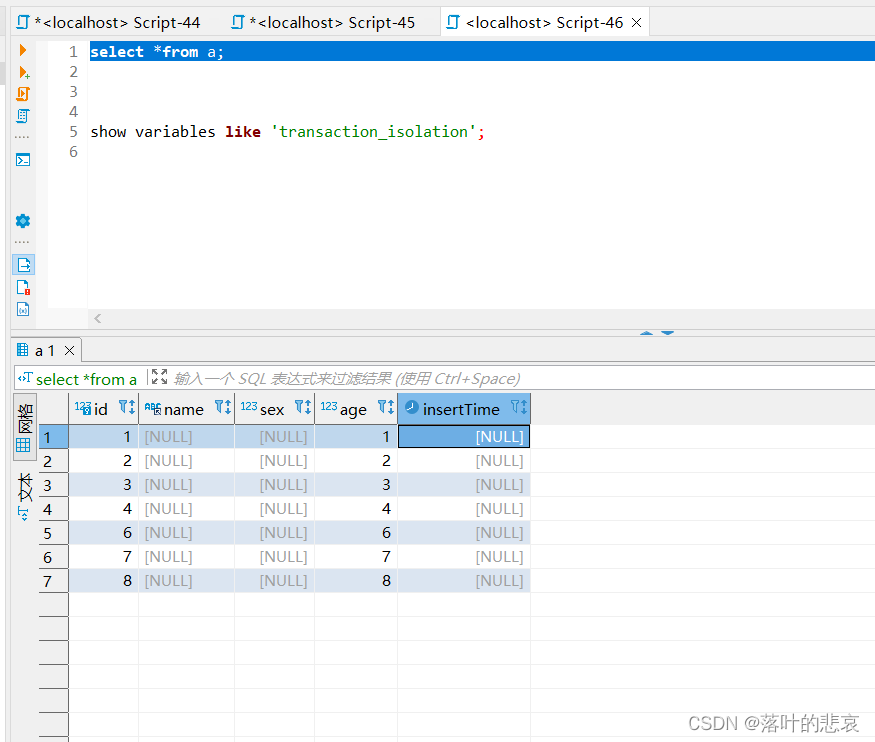
目录
一、Concurrent类型的容器
二、HashMap多线程死链问题
三、Concurrenthashmap8原理
1、构造器
2、get流程
3、put流程
4、initTable
5、addCount方法
6、size流程
四、Concurrenthashmap7原理
1、put流程
2、rehash扩容流程
3、get流程
一、Concurrent类型的容器
内部很多操作使用cas优化,一般可以提高较高吞吐量
弱一致性:
- 遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生改变,迭代器仍然可以继续进行遍历,这时内容是旧的
- 求容器大小size()弱一致性,size操作未必是100%准确的
- 读数据的时弱一致性
遍历时如果发生了修改,对于非安全容器来讲,使用fail-fast机制,让便利立刻失败,抛出ConcurrentModificationException,不再继续便利
二、HashMap多线程死链问题
在JDK7以下的版本中才会出现,原本hashmap的数组超过0.75的阈值就会发生扩容,当扩容的时候多线程可能会出现并发死链的问题。
死链复现:初始数组长度是16,刚好添加到0.75,然后启动两个线程去put第13个元素让他扩容。我们在transfer这个方法就能看出问题
这个方法是转移的方法,把原本数组的节点转移到新的数组中,扩容的过程就是遍历数组中的每个节点然后一个个移动,外面的for循环是循环数组,里面有个while循环来遍历移动链表每个节点
在单线程的情况下,他会指向这个节点然后记录他的next,把这个节点移动过去,然后把原来数组节点为next,重复循环,这个next的next保存,然后把这个next移动过头指向前一个移动过去的节点,原数组改为next的next。
多线程的情况下,当线程1在去移动的时候先赋值拿到了A和B,A指向B,然后某些原因导致堵塞,线程2扩容完毕后1复活,这个时候B指向A了实际上,但是1的前还是A后是B因为已经赋值了,然后他依然会先移动前面的A过去,然后数组位置变B然后next改为B的下一个又是A了这个时候就循环了,在一次移动的话B的下一个又是a了

三、Concurrenthashmap8原理
1、构造器
第一个参数初始容量,第二个参数是负载因子(0.75),第三个是并发度
上来如果初始容量小于并发度,那么会把初始容量改为并发度,最少得保证并发度这么大
他实现了懒惰初始化,他前面仅仅是大小的计算没有真正的创建,将来用到的时候才创建,这个jdk8的优化,jdk7中的是一上来就直接创建个数组
在他算好size的大小之后他还会做计算,保证最终的大小一定是2的幂次方,所以我们设置的初始化大小不一定是实际的大小

2、get流程
get也是亮点,因为全程没有加锁。他首先用spread计算hashcode,这个方法可以保证返回是正数,然后判断table是不是空,然后跟刚刚的len按位&,看看那个桶是不是空,如果是就返回null
如果头结点就是我们要找的key直接返回,他会先比hashcode,如果相等比key是不是一样和equals不,如果是相等直接返回。
如果头结点的hash是负数,则改桶已经被扩容了或者转化为treebin了,调用find方法来查询。如果不是负数,那就是链表了,直接while循环遍历一个个比较

3、put流程
他进来会先判断key和value是不是null,如果是就抛出异常了(之前面试就被问到hashmap的key和value能不能为null,cur呢,还是小厂面试)
先有个死循环,然后先判断这个表是不是为空,为空就要初始化,懒惰初始化的put的时候才初始化,初始化这个过程是用cas来保证不会用多个线程来创建的
如果计算出来的下标桶内没有元素要创建,就会用cas创建,如果成功就break,失败就重新循环
如果在扩容的时候cur会把头节点的变量cas改为-1,表示这个链表正在扩容,其他线程看到就知道有人在扩容了,他就会锁住后面即将扩容的链表,帮助该线程扩容
最后如果冲突了,就会对这个桶链表的头节点加synchronized,然后判断fh变量是不是>=0,大于就说明是链表,直接遍历链表有key就更新,没有就追加;如果是小于0就判断是不是红黑树,如果是就转化为tree节点来添加

4、initTable
初始化数组的时候会调用的方法,先判断这个哈希表有没有被创建,没有被创建进入while循环不断尝试,先尝试用cas把属性值改为-1,改为-1代表有人正在创建哈希表,如果成功了就会进入里面创建,其他线程cas失败就会循环,当下次进来就会发现这个值已经为-1说明有人创建,就会礼让cpu的使用权,yield,等创建好之后他们再次循环也会退出循环因为table不为null了

5、addCount方法
增加哈希表元素当中的计算数量,增加完之后就会把我们的size()也加1,用了我们之前的longArr的思想,设置多个累加单元从而减少他们cas的冲突,增加性能
首先先判断看看累加单元是否为空,如果没有累加单元就cas创建,有就拿累加单元cas拿原来的值+1,没有累加单元数组就创建数组,累加失败就重试。
累加完成之后如果链表长度小于等于1说明不用扩容直接结束返回,如果不是就判断要不要扩容,扩容会把变量属性cas变为负数,然后调扩容方法进行扩容;如果已经变了负数变量,就知道新的table已经被创建了锁后面链表帮忙扩容

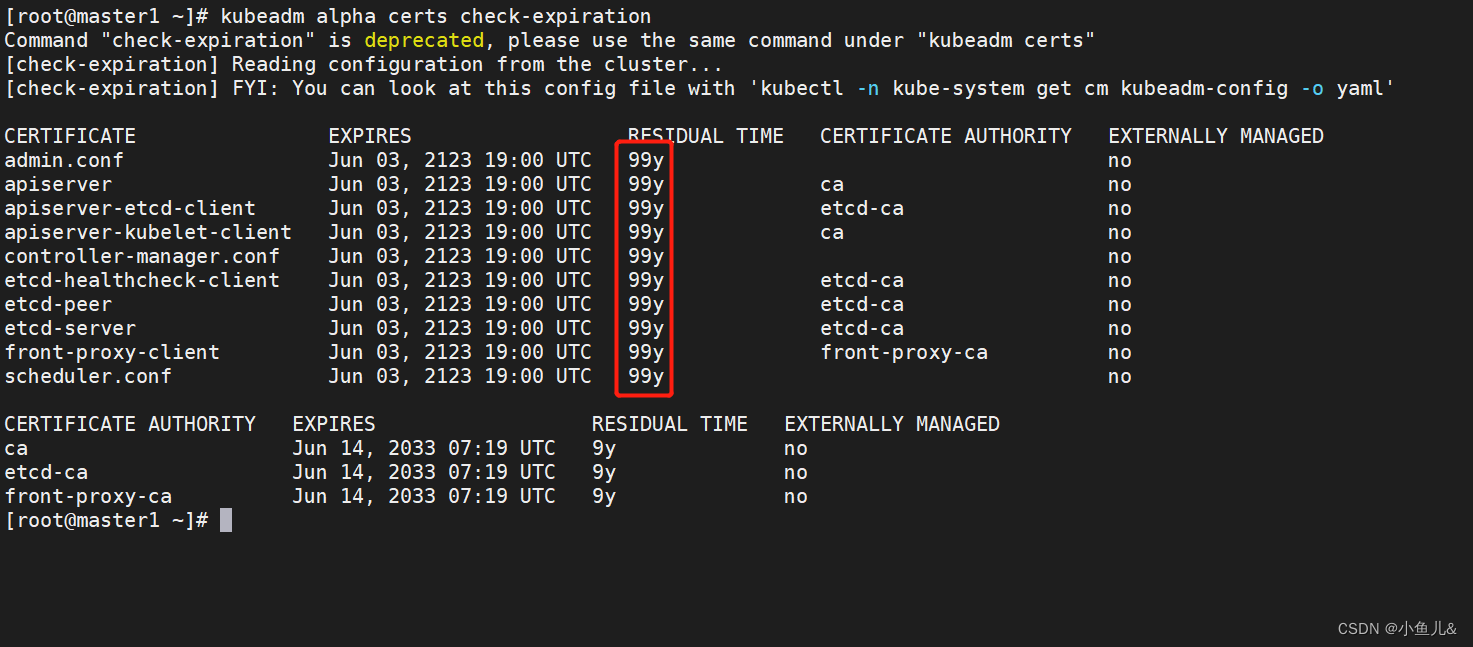
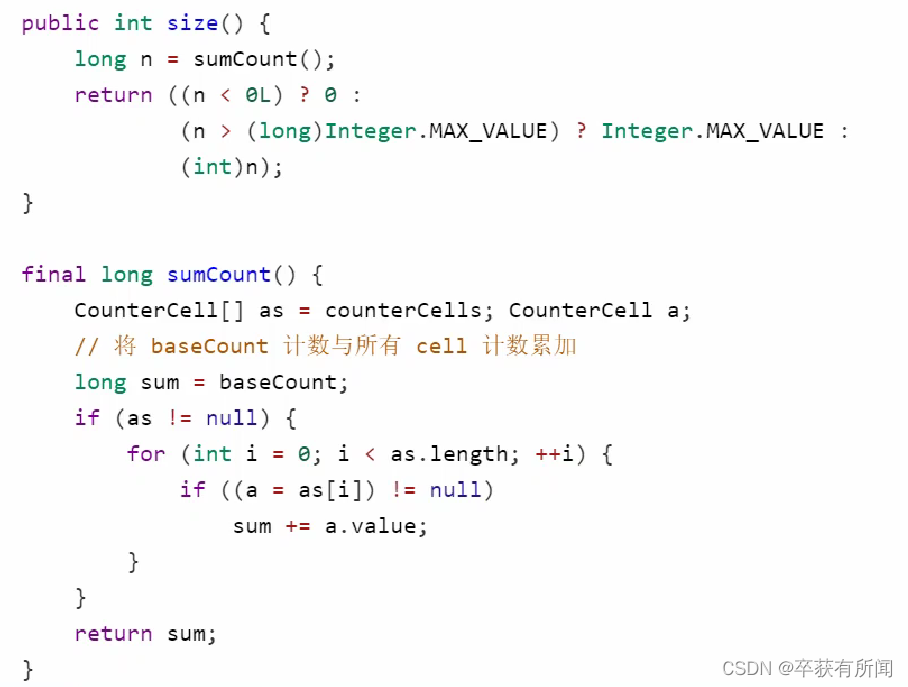
6、size流程
size计算发生在put和remove改变集合元素的操作中,没有竞争发生会向baseCount累加计数,有竞争发生,新建counterCells,向其中的一个cell累加计数,counterCells初始化有两个,如果竞争激烈还会创建。size就会调用遍历计算所有cell单元累加到sum返回。
四、Concurrenthashmap7原理
他维护了一个segment数组,每个segment对应一把锁,是继承reentrantlock的
优点:如果多个线程访问不同的segment,实际是没有冲突,与jdk8类似
缺点:segment数组默认大小为16,这个容量初始化后不能改变了,数组不是懒惰初始化
jdk8是把sync加在每个链表头,jdk7是加在segment数组上
1、put流程
上来先调用currenthashmap的put:如果value为null就抛异常,计算hash码,对哈希码进行移位和与运算得到下标,找到下标后看segment对象是不是null,如果没有就调用ensureSegment去尝试创建;有的话直接调用segment对象的put方法

segment对象的put:
上来做加锁的尝试,他如果失败会一直尝试,最多循环尝试64次,还失败就进入lock流程堵塞;加锁成功就进入segment然后用哈希表的长度和哈希码进行&找到桶,如果hash相等equals了那就找到了,直接用新的值替换旧的值,如果没有就新增指向原来的first,然后检查是否需要扩容,需要就走扩容,不需要就把新的节点变为链表头,退出循环。

2、rehash扩容流程
因为外层的put是在segment当中的已经加锁了,所以调用这个方法的一定是加锁安全的
如果没有下个节点,直接搬迁到新的下标去
如果不是一个节点就遍历链表,如果没有改变新的下标位置的,他全部都移动到新的原来下标,如果发生了改变原来是1到17这种的直接新建过去

rehash的扩容操作是发生在put的时候,在put的时候个数超过阈值才会发送rehash,注意是扩容完成之后,他才会加入新的节点
3、get流程
get也没有加锁,用unsafe方法保证了可见性,扩容过程中,get先发生就从旧表内容获取,get后发生就从新标取内容。数组内容的话直接加volatile修饰数组本身是不行的,他是数组的元素,必须配合unsafe保证他的可见性