文章目录
- 引言
- HTTP协议与请求方法
- HTTP协议
- 请求方法
- 使用Python进行网络请求
- 安装Requests库
- 发送GET请求
- 发送POST请求
- 反爬虫与应对策略
- IP限制
- 使用代理IP:
- 用户代理检测
- 设置User-Agent头部:
- 验证码
- 参考方案
- 动态页面
- 请求频率限制
- 未完待续....
引言
在当今信息时代,网络请求已成为了人们获取数据的重要方式。然而,同时也产生了大量的爬虫行为,这些爬虫可能会对网站的正常运行造成影响,甚至会引发一系列的反爬虫措施。本文将详细介绍网络请求与反爬虫的知识点,以及如何使用Python进行网络请求和应对常见的反爬虫策略。
HTTP协议与请求方法

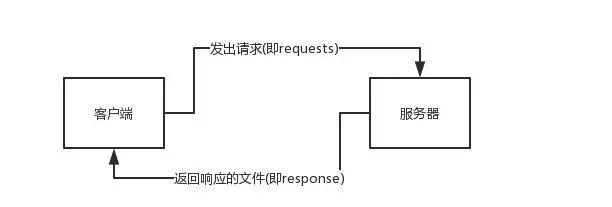
HTTP(Hypertext Transfer Protocol)是一种用于传输超文本的应用层协议。它定义了客户端和服务器之间进行通信时的格式和规则。HTTP使用请求-响应模型,客户端发送请求给服务器,服务器返回响应给客户端。
HTTP协议
HTTP协议由请求和响应组成。请求包括请求行、请求头和请求体,用于向服务器发送信息。响应包括状态行、响应头和响应体,用于从服务器接收信息。
请求方法
HTTP定义了多种请求方法,常见的有:
- GET:用于获取资源,不对服务器端数据做任何修改。
- POST:用于提交数据,向服务器提交信息并请求服务器进行处理。
- PUT:用于更新资源,将请求的数据存储到指定的URL。
- DELETE:用于删除资源,从服务器上删除指定的URL。
- HEAD:类似于GET请求,但只返回响应头部信息而不返回具体内容。
使用Python进行网络请求

Python提供了多种库用于发送网络请求,其中常用的是Requests库。
安装Requests库
使用pip命令安装Requests库:
pip install requests
发送GET请求
import requests
response = requests.get('https://www.example.com')
print(response.text)
代码中,我们使用
requests.get方法发送了一个GET请求,并将服务器的响应内容输出到控制台。你可以尝试将https://www.example.com替换为你想要访问的网址进行测试。
发送POST请求
import requests
data = {'username': 'my_username', 'password': 'my_password'}
response = requests.post('https://www.example.com/login', data=data)
print(response.text)
代码中,我们使用
requests.post方法发送了一个POST请求,并将提交的表单数据传递给服务器。同样地,你可以将https://www.example.com/login替换为你想要访问的登录接口进行测试。
反爬虫与应对策略

为了保护网站的数据和服务质量,很多网站采取了反爬虫措施。以下是一些常见的反爬虫策略及相应的应对方法:
IP限制
网站会根据IP地址对请求进行限制或封禁。解决方法之一是使用代理IP,通过切换IP地址发送请求,绕过IP限制。
使用代理IP:
import requests
proxies = {
'http': 'http://代理IP:端口',
'https': 'https://代理IP:端口'
}
url = '目标网址'
response = requests.get(url, proxies=proxies)
将“代理IP”和“端口”替换为有效的代理IP地址和相应端口。通过传递proxies参数,可以使用代理IP进行请求。
用户代理检测
网站可能会检查请求中的User-Agent头部信息,以判断请求是否来自爬虫。我们可以设置合理的User-Agent头部,使其看起来更像常见的浏览器请求。
设置User-Agent头部:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
url = '目标网址'
response = requests.get(url, headers=headers)
将headers参数中的User-Agent值设置为常见浏览器的User-Agent,使其看起来更像浏览器请求。
验证码
为了确认请求的真实性,网站可能会要求用户输入验证码。处理验证码是一个挑战,可以借助第三方的验证码识别服务或使用机器学习算法进行验证码识别。
参考方案
- 使用第三方验证码识别服务:有一些在线服务提供自动识别验证码的功能,你可以将验证码图片提交给这些服务进行识别。
- 使用机器学习算法进行验证码识别:通过训练机器学习模型来识别常见的验证码类型,这需要一定的数据集和算法知识。
动态页面
有些网站使用JavaScript动态加载页面内容,使得简单的爬虫无法获取完整数据。在这种情况下,可以使用工具如Selenium模拟浏览器行为,动态渲染页面并获取完整数据。
案例如下
from selenium import webdriver
# 使用Selenium
driver = webdriver.Chrome()
driver.get(url)
# 对动态页面执行操作,如滚动、点击等
# ...
# 获取完整页面内容
page_source = driver.page_source
# 关闭浏览器驱动
driver.quit()
请求频率限制
请求频率限制: 为了防止恶意爬虫过度占用服务器资源,网站可能会对请求的频率进行限制。为了应对请求频率限制,可以采用以下方法
- 设置合理的请求间隔时间:在发送请求之间增加固定的延迟,例如每个请求之间间隔1秒,以避免过于频繁的请求。
- 引入随机延迟:在设置请求间隔时间的基础上,再引入一个随机的延迟,模拟人类的操作行为,使得请求看起来更加自然。
import time
import requests
# 设置合理的请求间隔时间
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
for page in range(1, 11):
response = requests.get(f'http://example.com?page={page}', headers=headers)
# 处理响应数据
# ...
time.sleep(1) # 间隔1秒
import time
import random
import requests
# 引入随机延迟
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
for page in range(1, 11):
response = requests.get(f'http://example.com?page={page}', headers=headers)
# 处理响应数据
# ...
delay = random.uniform(0.5, 1.5) # 随机延迟,范围为0.5到1.5秒
time.sleep(delay)
未完待续…