阅读原文
研究某一类餐饮产品的市场概况,并在不同地区和品牌之间进行对比
一、数据需求
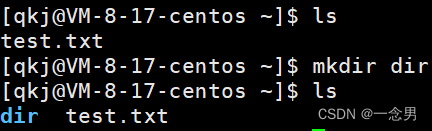
使用美团搜索商品返回的数据。
首先进入美团首页,切换到对应城市,并搜索感兴趣的关键词。接下来尝试翻页获取更多数据,点击下一页时发现页面地址没变,并且浏览器发送了一批请求。选定对应的范围,容易找到下图中的数据就是加载出来的商家信息,以 .json 格式返回。

该数据的请求地址为: https://apimobile.meituan.com/group/v4/poi/pcsearch/30 ,参数有:
uuid=8639d6b8d8bf457691b9.1594807338.1.0.0
userid=-1
limit=32
offset=32
cateId=-1
q=%E5%A5%B6%E8%8C%B6
尝试在浏览器请求 API,发现美团会进行 IP 验证,而且 URL 参数 uuid 对请求不产生影响。如果一个 IP 首次访问该 API,会跳转到人机验证。对此,可以使用selenium 完成首次的验证,然后在一段时间内便可以进行 GET 请求。参考以下文章: https://www.cnblogs.com/test_home_c/p/9619542.html
又或者可以获取 Cookies,并传入详细的 headers 参数,经过尝试,在 Cookie 中传入 uuid 参数即可跳过验证。

二、数据获取
具体的脚本可以分成几个步骤。首先是根据给定的城市名称和搜索关键词,获取对应城市的入口链接和城市 ID,后者用于 API 的拼接。得到 API 链接后,再获取 Cookie 字段,组成 headers,然后便可以发起请求获得数据。
需要注意的问题:
- 城市 ID 可以在网页源码中的 Script 脚本中得到,但是直接 GET 请求时不加载脚本,需要给定 headers 参数;
- 获取 Cookies 时并不返回完整的 Cookies 字段,但是经过测试,仅有的字段可以起作用;
- 当出现 Exception 时,可能是偏移量超出范围或者会话 Expired,需要跳出循环更新 Cookies 重新获取数据;
- 返回的 json 数据层次较复杂,分成两个关系表储存。
主要代码速览:
class MtSpider:
def __init__(self, cityname, keyword):
self.name = cityname
self.keyword = urllib.parse.quote(keyword)
self.linux_headers = ...
self.windows_headers = ...
self.citylink = self.get_city_link() # Searching URL
self.host = self.citylink.split('/')[2] # City Hostname
self.cityid = self.get_city_id()
self.cookies = self.get_cookies()
def get_city_link(self):
res = rq.get('https://www.meituan.com/changecity/', headers=self.windows_headers)
soup = BeautifulSoup(res.text, features='lxml')
cities = soup.find_all('a', {'class': 'link city'})
for c in cities:
if self.name in c.text or c.text in self.name:
link = 'https:' + c.attrs['href'] + '/s/' + self.keyword
return link
def get_city_id(self):
headers = dict(self.windows_headers, Host=self.host)
res = rq.get(self.citylink, headers=headers)
id = re.findall(r'{"id":(\d+),"name"', res.text)[0]
return id
def get_cookies(self):
jar = http.cookiejar.CookieJar()
processor = urllib.request.HTTPCookieProcessor(jar)
_ = urllib.request.build_opener(processor).open(self.citylink)
cookies = []
for i in jar:
cookies.append(i.name + '=' + i.value)
return '; '.join(cookies)
def get_json(self, page):
'''Get data of one page'''
url = 'https://apimobile.meituan.com/group/v4/poi/pcsearch/{}?userid=-1&limit=32&offset={}&cateId=-1&q={}'
url = url.format(self.cityid, page*32, self.keyword) # self.cityid
headers = {
'Cookie': self.cookies, # self.cookies
'Host': 'apimobile.meituan.com',
'Origin': 'https://' + self.host, # self.host
'Referer': self.citylink, # self.citylink
'User-Agent': self.windows_headers['User-Agent']
}
res = rq.get(url, headers=headers)
data = json.loads(res.text)
return data['data']['searchResult']
def parse_data(self, data):
...
def main(self, pages):
'''Entry'''
...
for p in range(pages):
try:
df1, df2 = self.parse_data(self.get_json(p))
...
except Exception as e:
print('ERROR: ' + str(e))
self.cookies = self.get_cookies() # Update Cookie
continue
...
if __name__ == "__main__":
...
这里选择“奶茶”作为关键词,获取主要的省会城市的数据。获取的数据分成两个表,一个是商店列表,一个是推荐的热销商品,两表以 shop_id 作为外键连接。下图为某一个城市的数据:

三、数据清洗
在 MtSpider 中的 parse_data 环节已经进行简单的清洗,主要根据返回的 json 文档的数据结构,将其分割成两个表,方便处理。
获取数据时选择每个城市的数据作为单独的 csv 文件保存,这样出现问题容易处理。因此首先要对数据进行合并汇总。又由于数据较多较复杂,只进行简单的清理,保留大部分的有用信息。在后续进行分析时在根据具体需要重整数据。
df = pd.read_csv(f'{PATH}{city}{KEYWORD}_shops.csv')
# 删除店铺标题中的括号内容,例如:一点点(XXX店)
df['title'] = df.title.map(lambda s: s.split('(')[0])
# 替换店铺标题中的特殊字符
df['title'] = df.title.str.replace(S, '·')
df['title'] = df.title.str.replace('一点点', '1點點')
# 提取地址中的区号生成新字段(先大致提取,有些城市可能会出现脏数据,无法全部兼顾)
df['region'] = df.address.map(lambda s: s.split('区')[0] + '区')
# 发现有些不是主营茶饮的,例如深圳的尊宝披萨;但是它又有茶饮产品,不好直接去掉
# 于是增加一个布尔型字段区分一下是否主营奶茶
df['isMain'] = df.backCateName.map(lambda cat: KEYWORD in cat)
# 然后将所有城市的数据汇总得到总的 shops 和 deals 两个表
下一步进行可视化分析前还需要对表格某些数据进行重构处理:
# 商品标题字段,通过分词得到高频词列表
text = ' '.join(deals.title)
words = pd.Series(jieba.cut(text, cut_all=False))
stopwords = ...
wc = wordcloud.WordCloud(..., stopwords=stopwords)
wc.generate_from_text(' '.join(words))
# 借助 WordCloud 对象生成的高频词筛选源列表
level = ' '.join(list(wc.words_.keys())).split(' ')
new_words = words.loc[words.isin(level)]
# 联合两表计算每个店铺的推荐商品平均销量(作为该店铺的销量指数)
sales = deals.groupby('shop_id').sales.mean().reset_index().rename({'shop_id': 'id'}, axis=1)
shops.merge(sales, on='id', inplace=True)
四、可视化分析
对获得的数据进行初步的简单分析,看是否能得到有用的结论。接下来就是全国各地奶茶大赏!
- 下面图表如无说明,均为全国范围的数据
- 仅包含已入驻美团的商家数据
- 关于价格的信息仅包含部分热销商品,仅做参考
- 最后更新日期为 2022.08.03
(1)CoCo都可 分布最广、口碑最佳
评分这一点,众所周知,水分很大。不过也是可以反映一些信息的,毕竟哪怕是刷的分,也是要成本的。

(2)郑州 —— 杀出来的黑马
具体到每个城市的分布如下,可以看到郑州(2019 GDP 排名 16)的主要品牌奶茶店分布数量领先绝大部分城市。从图中还可以清楚看到每个品牌青睐哪个城市,例如郑州是蜜雪冰城的天下,而天津则被沪上阿姨占领。

(3)奈雪的茶 —— 高端大气
接下来看价格的分布,图中大小表示店铺的数量,颜色表示产品均价。从图中可以看到哪些品牌价格比较亲民,哪些比较高端。奈雪的茶荣登榜首(忽略部分分布数量较少的品牌)。明显的趋势是:价格亲民的品牌,有遍地开花的趋势,反之价格高的品牌店铺数量较少。

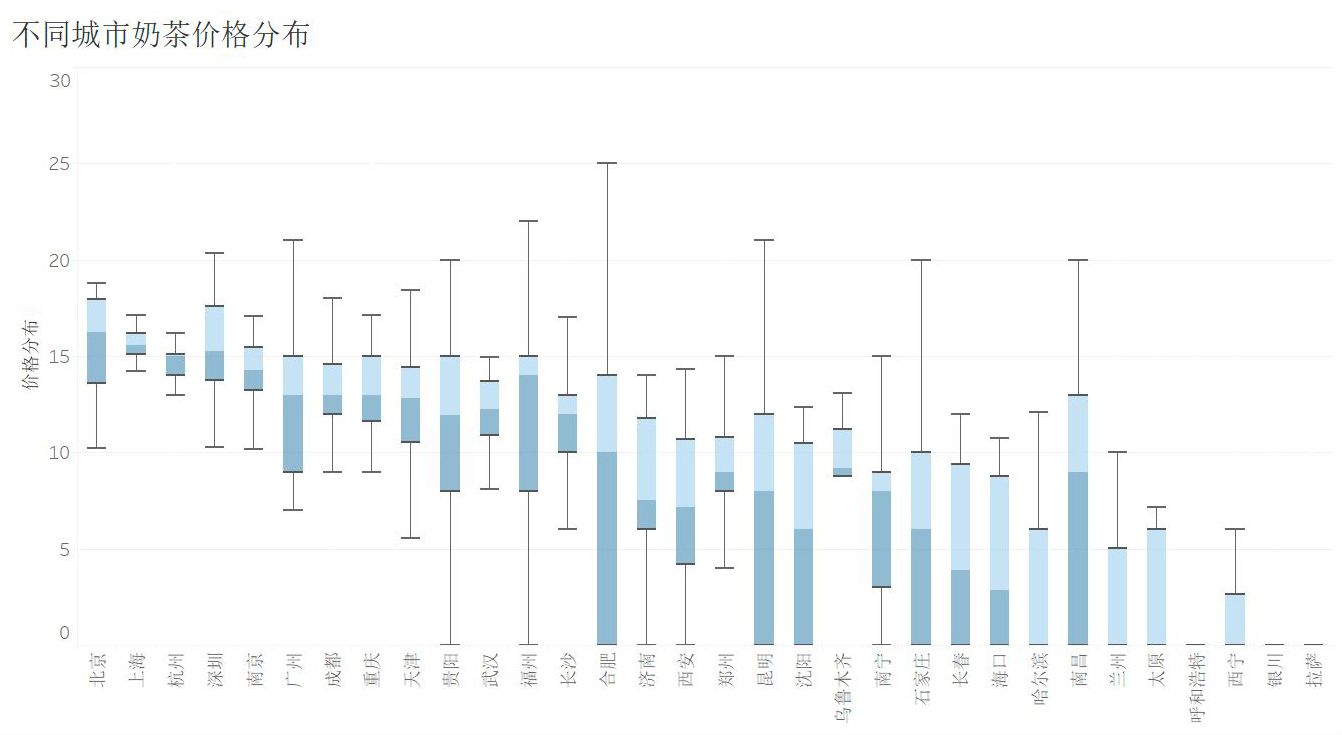
(4)沿江沿海地区消费水平较高
这个趋势还是比较明显的,深色数据点主要围绕着北上广和长江沿岸。按照这个结论,有两个省会城市就脱离了趋势,一个是中西部的陕西西安,一个是西南的贵州贵阳。

具体到不同城市的分布如下图。注意到箱形图部分城市的四分位已经到零点,主要是部分商家首页没有推荐的折扣商品,导致计算产品的参考均值的时候得到缺失值。这个后续再进一步处理,目前仅作简单的分析。可以重点看一下北上广深的分布情况,感觉越看越有房价内味儿~
 ### **(5)各品牌销量均值**
### **(5)各品牌销量均值**
这里是对每个店铺的推荐商品销量求均值,然后再对该品牌的店铺求均值,作为销量的参考指标。这里在此前名不见经传的天御皇茶扳下一城,领先大部分品牌。但是,这个销量数据同样还是水分满满,可能需要另找一个替代的指标。

(6)舔屏 —— 推荐商品中出现最多的元素

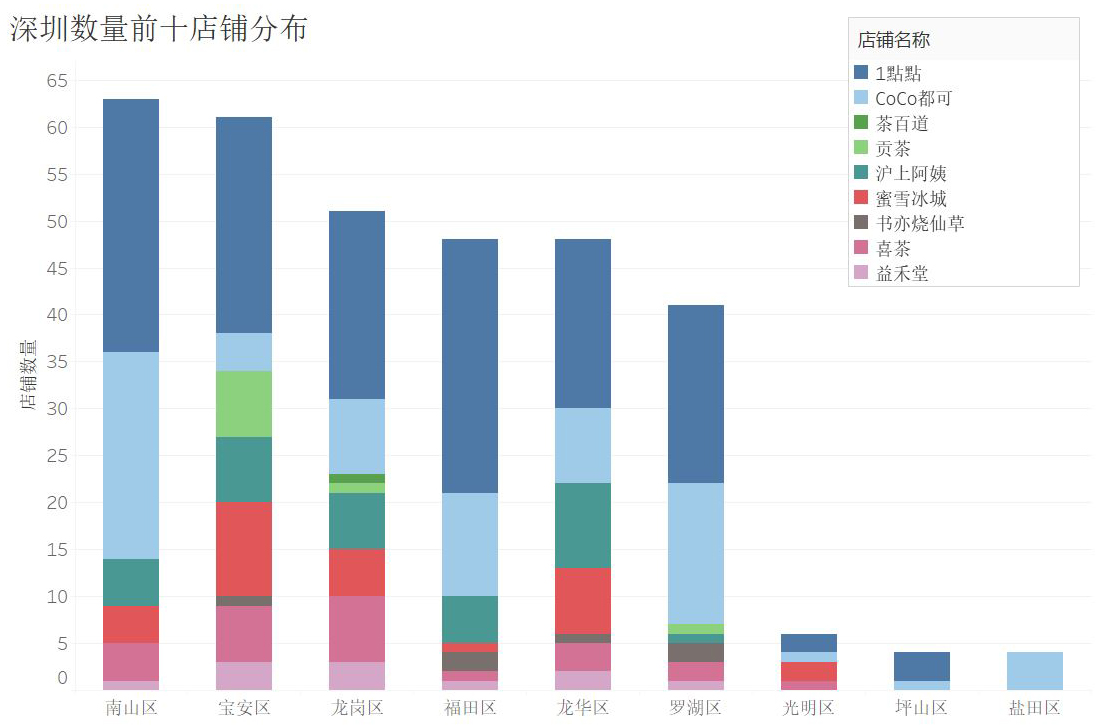
(7)具体看一下深圳的数据
首先看一下各区的分布(绘制这个图的时候都没发现,现在才惊觉有个逻辑上的错误,影响不大,懒得改了)。
最后来个热力图压压惊。可以看到深圳湾“店满为患”。