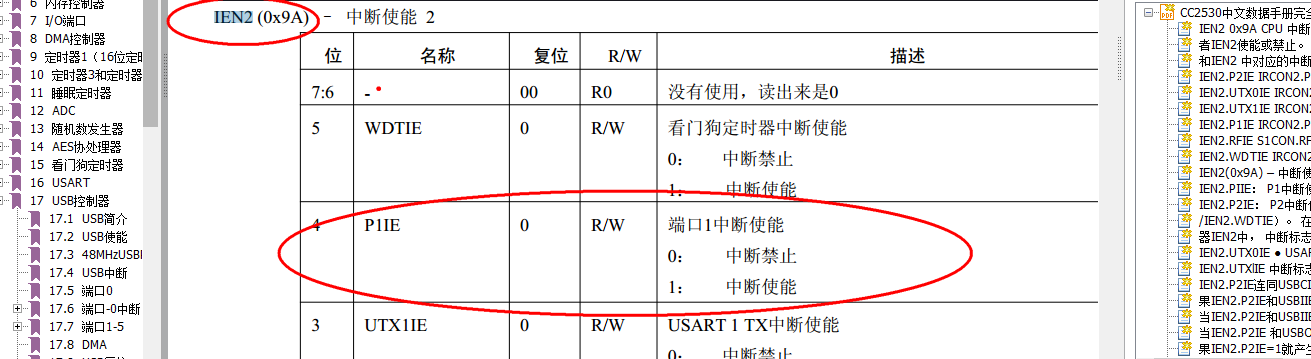
大家好,我是带我去滑雪!
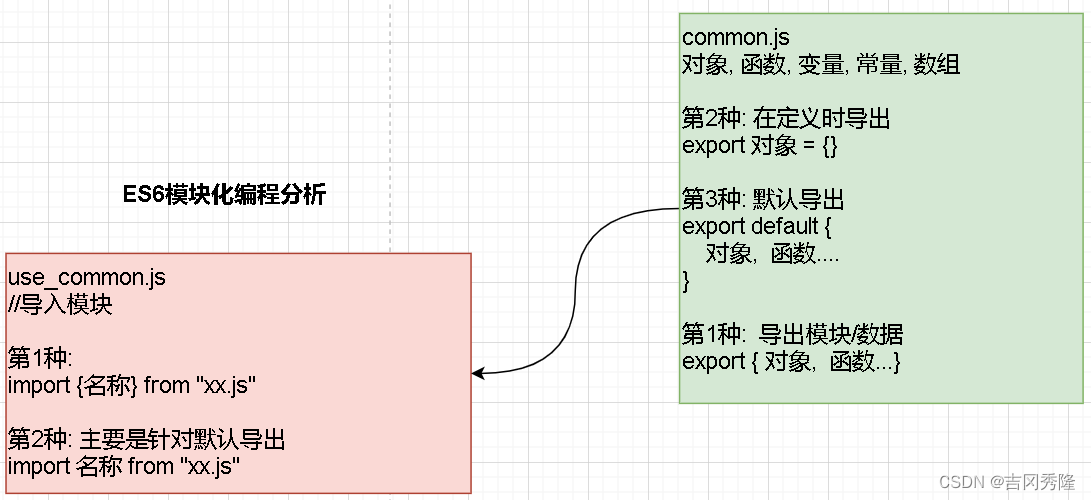
SVD 是一种矩阵分解技术,通过将空间维数从 N 维降到 K 维(其中K<N)来减少数据集的特征数。在推荐系统中,SVD 被用作一种协同过滤技术。使用矩阵结构,其中行表示用户,列表示电影。这个矩阵的对应位置数值是用户给项目的评分。该矩阵的分解是通过奇异值分解完成的。从高级(用户项评级)矩阵的因子分解中找到矩阵的子矩阵。奇异值分解是将一个矩阵 A 分解为 U, S,V 三个其他矩阵的方法。
本期利用抓取IMDB的英文网站上的电影相关数据,实现基于SVD矩阵分解的电影推荐系统设计。
目录
1、抓取IMDB网站上电影相关数据
(1)爬取的步骤
(2)代码
(3)部分数据展示
2、基于SVD矩阵分解的电影推荐系统设计
(1)导入相关模块与数据
(2)构建用户与电影的评分矩阵
(3)实现矩阵分解,求奇异值
(4)SVD评分估计
(5)使用SVD模型为用户推荐电影
1、抓取IMDB网站上电影相关数据
抓取的是一个叫IMDB的英文网站,因为国内没有找到那种有用户分别对电影打分的,比如豆瓣、腾讯等等。介绍一下什么是IMDB:IMDB,全称为Internet Movie Database,中文意为“互联网电影数据库”,是世界上最大的、最具权威性的电影、电视剧和演员等相关信息的在线数据库之一,也是全球电影和电视节目工作者与业内人士交流、沟通和分享资源的重要平台,同时也是广大电影爱好者、编剧和导演等获取电影、电视剧资料和资源的重要来源之一。
IMDB数据库由Col Needham于1990年创办,在1996年被Amazon.com公司收购。这个在线电影数据库包括了全球 绝大多数电影、电视剧、电视综艺以及演员、制片人、导演等电影从业人员的信息资料,包括电影/电视剧的剧情、演职员表、评分、票房、影评等信
(1)爬取的步骤
步骤1:获取IMDB的数据源URL
对于IMDB的电影信息,可以通过IMDB提供的API进行调用,也可以通过获取IMDB的数据源URL来进行爬取。获取IMDB的数据源URL的方法有很多,最简单的方法是在IMDB网站上手动搜索你想要爬取的电影信息,然后将搜索结果页URL中的信息复制下来。
步骤2:爬取IMDB电影信息页面
获取了IMDB电影的数据源URL,可以使用爬虫程序爬取电影信息页面了,可以使用Python编程语言中的一个叫做“Requests”的库来进行页面请求和数据获取。爬虫程序需要发送GET请求包含电影ID的URL,并用BeautifulSoup等Web解析器来解析该电影页面源代码,以获取电影信息。可获取的信息包括电影、主演、上映年份、电影链接、电影类型、用户ID以及电影评分等信息。
步骤3:数据存储
完成电影信息的爬取,可以将这些信息存储在本地计算机的数据库、Excel文件或其他文本文件中,以备之后的分析和使用。
步骤4:保证爬虫正常进行
在爬取IMDB电影信息时,需要注意到IMDB会不时地更新网站的结构和数据,需要根据页面结构和网站API的更新来进行相应的调整,以保证成功爬取数据。此外,需要保证爬虫程序的请求限制和频率合理,以防止影响IMDB网站和本地计算机的性能。
(2)代码
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
movie_name = []
movie_url = []
movie_star = []
movie_star_people = []
movie_director = []
movie_actor = []
movie_year = []
movie_country = []
movie_type = []
def get_movie_info(url, headers):
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'html.parser')
for movie in soup.select('.item'):
name = movie.select('.hd a')[0].text.replace('\n', '') movie_name.append(name)
url = movie.select('.hd a')[0]['href']
movie_url.append(url)
star = movie.select('.rating_num')[0].text
movie_star.append(star)
star_people = movie.select('.star span')[3].text
star_people = star_people.strip().replace('', '')
movie_star_people.append(star_people)
movie_infos = movie.select('.bd p')[0].text.strip()
director = movie_infos.split('\n')[0].split(' ')[0]
movie_director.append(director)
try:
actor = movie_infos.split('\n')[0].split(' ')[1]
movie_actor.append(actor)
except:
movie_actor.append(None)
if name == ' / The Monkey King':
year0 = movie_infos.split('\n')[1].split('/')[0].strip()
year1 = movie_infos.split('\n')[1].split('/')[1].strip()
year2 = movie_infos.split('\n')[1].split('/')[2].strip()
year = year0 + '/' + year1 + '/' + year2
movie_year.append(year)
country = movie_infos.split('\n')[1].split('/')[3].strip()
movie_country.append(country)
type = movie_infos.split('\n')[1].split('/')[4].strip()
movie_type.append(type)
else:
year = movie_infos.split('\n')[1].split('/')[0].strip()
movie_year.append(year)
country = movie_infos.split('\n')[1].split('/')[1].strip()
movie_country.append(country)
type = movie_infos.split('\n')[1].split('/')[2].strip()
movie_type.append(type)
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['电影名称'] = movieId
df['电影评分'] = ratings
df['电影链接'] = 电影链接
df['主演'] = movie_actor
df['上映年份'] = movie_year
df['用户名称 '] =userId
df['电影类型'] =电影类型
df.to_csv(csv_name, encoding='utf_8_sig') # 分别将将数据保存到csv文件
if __name__ == "__main__":
# 定义一个请求头(防止反爬)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
for i in range(390): # 爬取共390页,每页25条数据
page_url = 'https://www.imdb.com/start={}'.format(str(i *390))
print('开始爬取第{}页,地址是:{}'.format(str(i + 1), page_url))
get_movie_info(page_url, headers)
sleep(1) # 等待1秒(防止反爬)
(3)部分数据展示
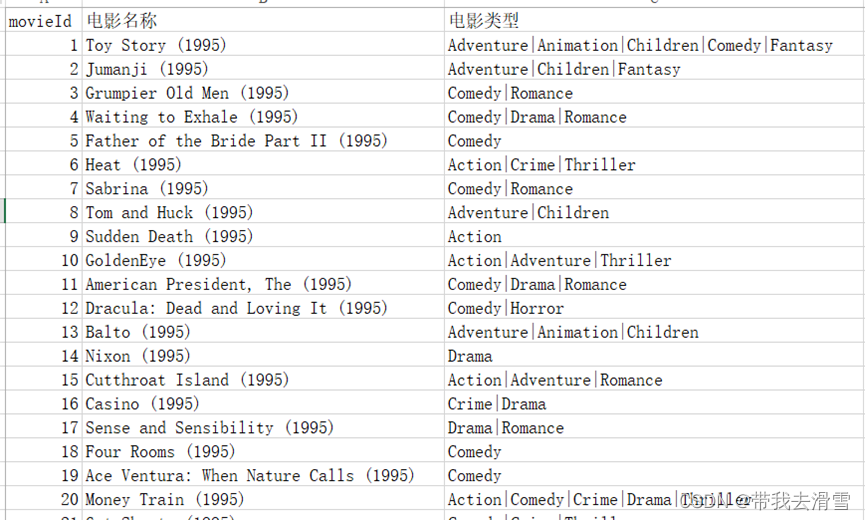
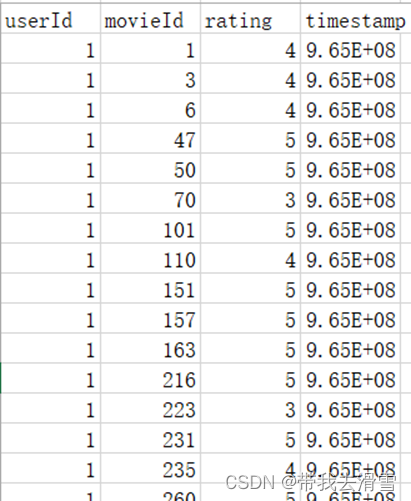
2、基于SVD矩阵分解的电影推荐系统设计
(1)导入相关模块与数据
import numpy as np
import pandas as pd
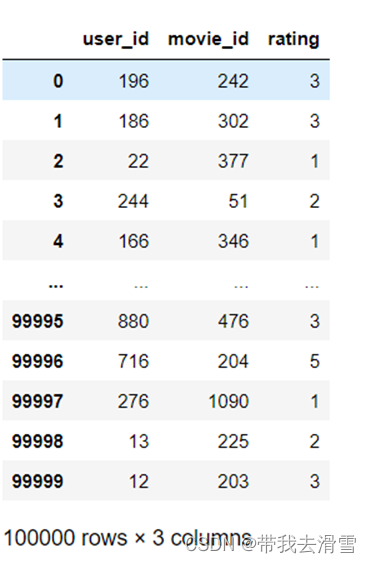
data = pd.read_csv('data.txt', sep='\t', header=None)
data.drop(3, inplace=True, axis=1) # 去掉时间戳
data.columns = ['user_id', 'movie_id', 'rating']
data
输出结果:
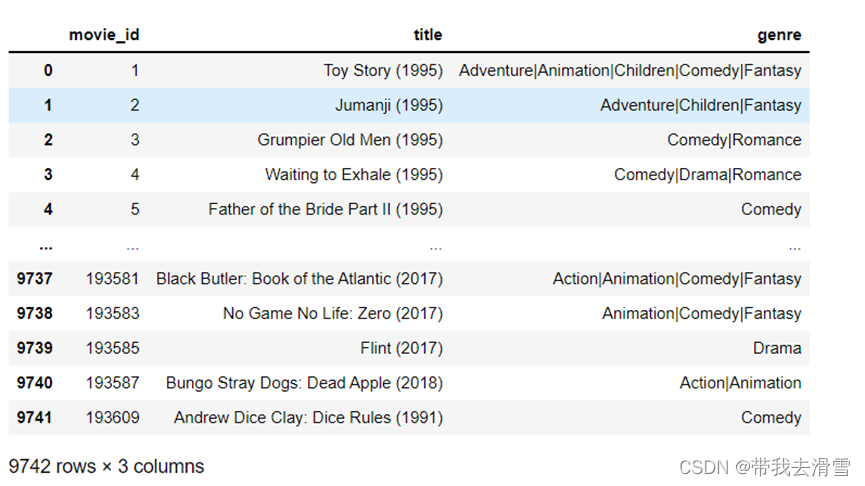
movie_data= pd.read_csv('movie_data.txt', sep='\t',encoding="UTF-16LE")
movie_data
输出结果:
(2)构建用户与电影的评分矩阵
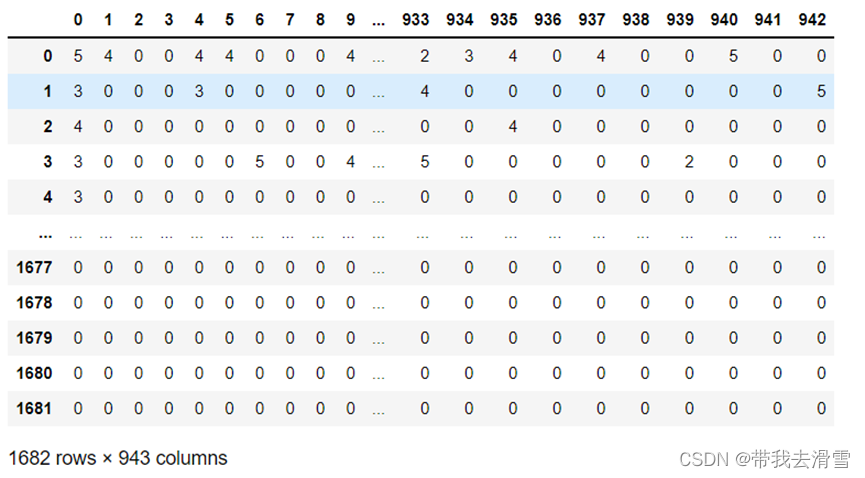
创建行为电影 id,列为用户 id 的矩阵,每一个 x行和列交叉的位置是用户对电影评分,这是一个稀疏矩阵,其中很多 0 位置表示用户没有给该电影打过分数 。
ratings_mat = np.ndarray(shape=(np.max(data.movie_id.values),np.max(data.user_id.values)),dtype=np.uint8)
ratings_mat[data.movie_id.values-1,data.user_id.values-1] = data.rating.values
pd.DataFrame(ratings_mat)
输出结果:
(3)实现矩阵分解,求奇异值
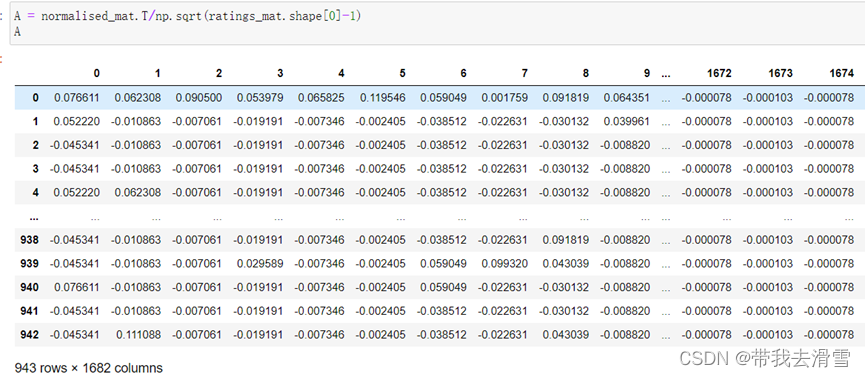
计算A:
normalised_mat = ratings_mat - np.asarray([(np.mean(ratings_mat, 1))]).T
normalised_mat
A = normalised_mat.T/np.sqrt(ratings_mat.shape[0]-1)
A
输出结果:
计算U、V、的值:
U,S,V= np.linalg.svd(A)
U,S,V
(4)SVD评分估计
def top_cosine_similarity(data,movie_id,top_n=10):
index = movie_id - 1
movie_row = data[index,:]
magnitude = np.sqrt(np.einsum('ij, ij -> i', data, data))
similarity = np.dot(movie_row, data.T) / (magnitude[index] * magnitude)
sort_indexes = np.argsort(-similarity)
return sort_indexes[:top_n]
def print_similar_movies(movie_data, movie_id, top_indexes):
print('Recommendations for {0}: \n'.format(
movie_data[movie_data.movie_id == movie_id].title.values[0]))
for id in top_indexes + 1:
print(movie_data[movie_data.movie_id == id].title.values[0])
import numpy as np
import pandas as pd
# 用DataFrame来储存数据,格式为userid, itemid, rating
df = pd.read_csv('data.txt', sep='\t', header=None)
df.drop(3, inplace=True, axis=1) # 去掉时间戳
df.columns = ['uid', 'iid', 'rating']
# 随机打乱划分训练和测试集
df = df.sample(frac=1, random_state=0)
train_set = df.iloc[:int(len(df)*0.75)]
test_set = df.iloc[int(len(df)*0.75):]
n_users = max(df.uid)+1
n_items = max(df.iid)+1
class SVD(object):
def __init__(self, n_epochs, n_users, n_items, n_factors, lr, reg_rate, random_seed=0):
self.n_epochs = n_epochs
self.lr = lr
self.reg_rate = reg_rate
np.random.seed(random_seed)
self.pu = np.random.randn(n_users, n_factors) / np.sqrt(n_factors) # 参数初始化不能太大
self.qi = np.random.randn(n_items, n_factors) / np.sqrt(n_factors)
def predict(self, u, i):
return np.dot(self.qi[i], self.pu[u])
def fit(self, train_set, verbose=True):
for epoch in range(self.n_epochs):
mse = 0
for index, row in train_set.iterrows():
u, i, r = row.uid, row.iid, row.rating
error = r - self.predict(u, i)
mse += error**2
tmp = self.pu[u]
self.pu[u] += self.lr * (error * self.qi[i] - self.reg_rate * self.pu[u])
self.qi[i] += self.lr * (error * tmp - self.reg_rate * self.qi[i])
if verbose == True:
rmse = np.sqrt(mse / len(train_set))
print('epoch: %d, rmse: %.4f' % (epoch, rmse))
return self
def test(self, test_set):
predictions = test_set.apply(lambda x: self.predict(x.uid, x.iid), axis=1)
rmse = np.sqrt(np.sum((test_set.rating - predictions)**2) / len(test_set))
return rmse
svd = SVD(n_epochs=20, n_users=n_users, n_items=n_items, n_factors=35, lr=0.005, reg_rate=0.02)
svd.fit(train_set, verbose=True)
svd.test(test_set)
输出结果:
0.932
funk_svd.predict(299, 282)
#测试集中的某一条数据,真实评分为4,预测为3.3946690868636873
输出结果:
epoch: 0, rmse: 3.6946
epoch: 1, rmse: 3.0856
epoch: 2, rmse: 1.8025
epoch: 3, rmse: 1.3196
epoch: 4, rmse: 1.1282
epoch: 5, rmse: 1.0339
epoch: 6, rmse: 0.9791
epoch: 7, rmse: 0.9426
epoch: 8, rmse: 0.9155
epoch: 9, rmse: 0.8936
epoch: 10, rmse: 0.8748
epoch: 11, rmse: 0.8579
epoch: 12, rmse: 0.8424
epoch: 13, rmse: 0.8279
epoch: 14, rmse: 0.8140
epoch: 15, rmse: 0.8008
epoch: 16, rmse: 0.7881
epoch: 17, rmse: 0.7758
epoch: 18, rmse: 0.7640
epoch: 19, rmse: 0.7524
3.3946690868636873
解读:经过20次迭代后,测试集中的(用户id为299,电影id为282)一条数据,真实评分为4,预测为3.3946690868636873,模型的得分达到0.932。
(5)使用SVD模型为用户推荐电影
k = 2
movie_id =15
top_n =5
sliced = V.T[:, :k]
indexes = top_cosine_similarity(sliced, movie_id, top_n)
print_similar_movies(movie_data, movie_id, indexes)
输出结果:
Recommendations for Cutthroat Island (1995):
Cutthroat Island (1995)
Strictly Ballroom (1992)
Fish Called Wanda, A (1988)
2 Days in the Valley (1996)
Right Stuff, The (1983)
解读:设置参考k为2,使用SVD模型计算出该用户对所有电影的评分,按照预测分值大小,将排名前5的电影推荐给用户。通过输出结果可以看见,SVD模型给我们推荐的5部电影分别为Cutthroat Island (1995)、Strictly Ballroom (1992)、Fish Called Wanda, A (1988)、2 Days in the Valley (1996)、Right Stuff, The (1983)。
需要数据集的家人们可以去百度网盘(永久有效)获取:
链接:https://pan.baidu.com/s/1E59qYZuGhwlrx6gn4JJZTg?pwd=2138
提取码:2138
更多优质内容持续发布中,请移步主页查看,若有问题可私信博主!
博主weixin:TCB1736732074
点赞+关注,下次不迷路!