本文是 Elasticsearch官方博客文档 阅读笔记记录,详细内容请访问官方链接,本文只做重点记录
index索引
对于经常看 Elastic 英文官方文档的开发者来说,我们经常会看到 index 这个词。在英文中,它即可以做动词,表示建立索引的意思,但同时它也用作名词,称作索引。很多刚开始学习 Elasticsearch 的开发者有时有点弄不明白。
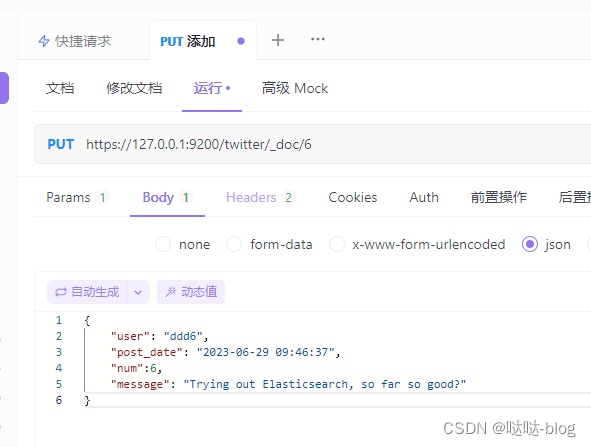
添加 PUT
twitter 索引,_doc 文档端点,6文档id
搜索
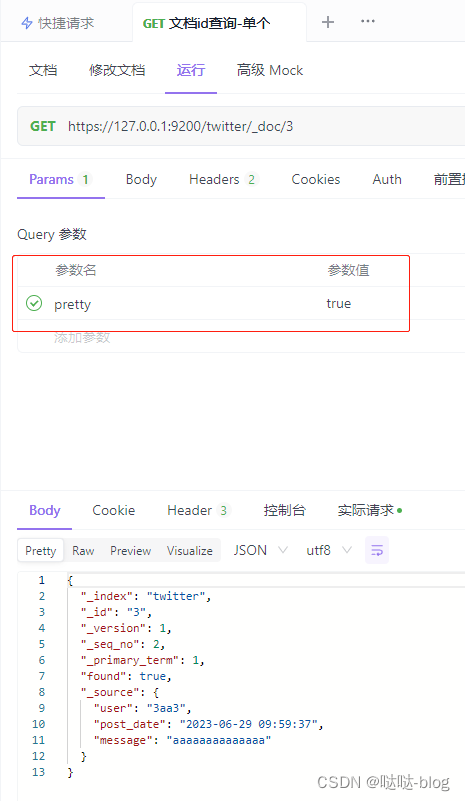
id查询 - 单个
/twitter/_doc/3?pretty=true
twitter 索引
3 id
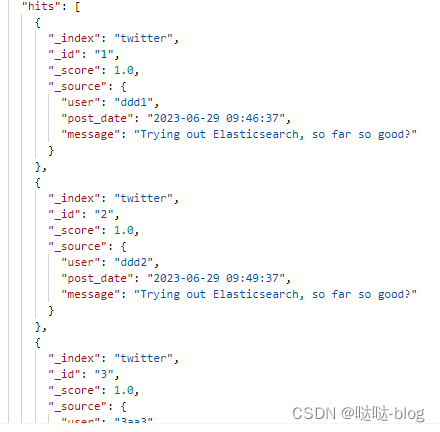
指定字段搜索-单个
/twitter/_search?pretty=true
{
"query": {
"match":{"user":"3aa3"}
}
}
查询所有
/twitter/_search?pretty=true 去掉索引就是查询所有
{
"query": {
"match_all":{}
}
}
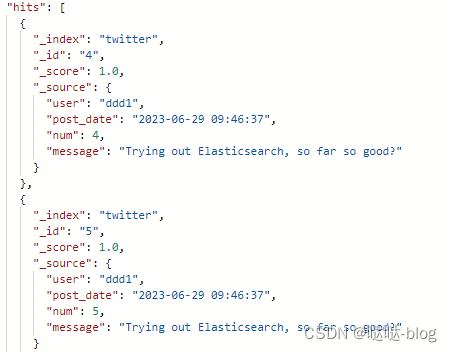
范围查询
/twitter/_search?pretty=true
{
"query": {
"range":{
"num":{
"from":4,
"to":5
}
}
}
}
多租户 - 索引和类型
上面的例子是以twitter为索引,可能会导致索引数据量过于庞大,可以用 用户做索引。为每个用户提供不同的索引。
添加数据
/user1/_doc/1?pretty
/user1/_doc/2?pretty
{
"user": "user1",
"post_date": "2023-06-29 09:46:37",
"message": "Trying out Elasticsearch, so far so good?",
"status":2
}
#分开添加
{
"user": "user1",
"post_date": "2023-06-29 09:46:37",
"message": "Trying out Elasticsearch, so far so good?",
"status":22
}
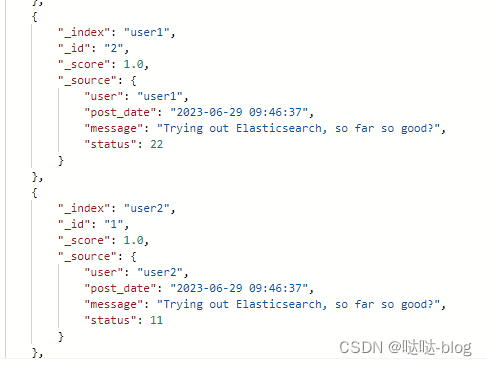
每个用户有自己的索引
搜索多个 index
允许完全控制索引级别。 例如,在上面的情况中,我们可能希望从每个索引1个副本的默认1分片更改为每个索引1个副本的2个分片(因为此用户推文很多)。 以下是如何做到这一点(配置也可以是在 yaml 文件里配置):
开启:/another_user
{
"settings" : {
"index.number_of_shards" : 2,
"index.number_of_replicas" : 1
}
}
查询
user3,user2,user1 这几个是index
/user3,user2,user1/_search
{
"query" : {
"match_all" : {}
}
}